本文将为您提供关于如何在Python3.6的ssl模块中实现FIPS_mode的详细介绍,我们还将为您解释和FIPS_mode_set的相关知识,同时,我们还将为您提供关于django_models_
本文将为您提供关于如何在Python 3.6的ssl模块中实现FIPS_mode的详细介绍,我们还将为您解释和FIPS_mode_set的相关知识,同时,我们还将为您提供关于django_models_Meta 字段详解、Eclipse 下忽略掉 node_modules 目录相关配置、Eclipse下忽略掉node_modules目录相关配置、es function_score查询及field_value_factor,boost_mode,max_mode,score_Mode的实用信息。
本文目录一览:- 如何在Python 3.6的ssl模块中实现FIPS_mode()和FIPS_mode_set()?(python ssl模块用法详解)
- django_models_Meta 字段详解
- Eclipse 下忽略掉 node_modules 目录相关配置
- Eclipse下忽略掉node_modules目录相关配置
- es function_score查询及field_value_factor,boost_mode,max_mode,score_Mode
和FIPS_mode_set()?(python ssl模块用法详解)")
如何在Python 3.6的ssl模块中实现FIPS_mode()和FIPS_mode_set()?(python ssl模块用法详解)
我正在尝试在Python的ssl模块中实现FIPS_mode和FIPS_mode_set函数,因为默认情况下不存在这些函数。由于各种使用原因,已经提交并拒绝了Python
3.4的补丁程序。
以此补丁为灵感,我进行了一些修改,并在 ssl.py中 添加了以下代码:
try:
from _ssl import FIPS_mode,FIPS_mode_set
except ImportError:
pass
以及 _ssl.c中 的以下代码:
#define EXPORT_FIPSMODE_FUNCS
#ifdef EXPORT_FIPSMODE_FUNCS
static PyObject *
_ssl_FIPS_mode_impl(PyObject *module) {
return PyLong_FromLong(FIPS_mode());
}
static PyObject *
_ssl_FIPS_mode_set_impl(PyObject *module,int n) {
if (FIPS_mode_set(n) == 0) {
_setSSLError(ERR_error_string(ERR_get_error(),NULL),__FILE__,__LINE__);
return NULL;
}
Py_RETURN_NONE;
}
#endif //EXPORT_FIPSMODE_FUNCS
/* List of functions exported by this module. */
static PyMethodDef PySSL_methods[] = {
_SSL__TEST_DECODE_CERT_METHODDEF
_SSL_RAND_ADD_METHODDEF
_SSL_RAND_BYTES_METHODDEF
_SSL_RAND_PSEUDO_BYTES_METHODDEF
_SSL_RAND_EGD_METHODDEF
_SSL_RAND_STATUS_METHODDEF
_SSL_GET_DEFAULT_VERIFY_PATHS_METHODDEF
_SSL_ENUM_CERTIFICATES_METHODDEF
_SSL_ENUM_CRLS_METHODDEF
_SSL_TXT2OBJ_METHODDEF
_SSL_NID2OBJ_METHODDEF
_SSL_FIPS_MODE_SET_METHODDEF
_SSL_FIPS_MODE_METHODDEF
{NULL,NULL} /* Sentinel */
};
但是,这将引发以下错误:
./Modules/_ssl.c:5060:5: error: '_SSL_FIPS_MODE_SET_METHODDEF' undeclared here (not in a function)
_SSL_FIPS_MODE_SET_METHODDEF
./Modules/_ssl.c:5061:5: error: expected '}' before '_SSL_FIPS_MODE_METHODDEF'
_SSL_FIPS_MODE_METHODDEF
./Modules/_ssl.c:4641:1: warning: '_ssl_FIPS_mode_impl' defined but not used [-Wunused-function] _ssl_FIPS_mode_impl(PyObject
*module) {
./Modules/_ssl.c:4646:1: warning: '_ssl_FIPS_mode_set_impl' defined but not used [-Wunused-function]
_ssl_FIPS_mode_set_impl(PyObject *module,int n) { ^
我很确定我在这里错过了一些非常琐碎的事情,但是我似乎无法弄清楚到底是什么。任何帮助,将不胜感激!谢谢!
更新:
一个大的大喊答题节目环节以 @CristiFati 谁指出,我错过了需要加以定义的宏,我能解决这个问题。如果其他人需要在Python
3.6中实现FIPS模式,请添加以下代码:
_ssl.c:
static PyObject *
_ssl_FIPS_mode_impl(PyObject *module) {
return PyLong_FromLong(FIPS_mode());
}
static PyObject *
_ssl_FIPS_mode_set_impl(PyObject *module,__LINE__);
return NULL;
}
Py_RETURN_NONE;
}
static PyMethodDef PySSL_methods[] = {
_SSL__TEST_DECODE_CERT_METHODDEF
_SSL_RAND_ADD_METHODDEF
_SSL_RAND_BYTES_METHODDEF
_SSL_RAND_PSEUDO_BYTES_METHODDEF
_SSL_RAND_EGD_METHODDEF
_SSL_RAND_STATUS_METHODDEF
_SSL_GET_DEFAULT_VERIFY_PATHS_METHODDEF
_SSL_ENUM_CERTIFICATES_METHODDEF
_SSL_ENUM_CRLS_METHODDEF
_SSL_TXT2OBJ_METHODDEF
_SSL_NID2OBJ_METHODDEF
_SSL_FIPS_MODE_METHODDEF
_SSL_FIPS_MODE_SET_METHODDEF
{NULL,NULL} /* Sentinel */
};
_ssl.ch:
PyDoc_STRVAR(_ssl_FIPS_mode__doc__,"FIPS Mode");
#define _SSL_FIPS_MODE_METHODDEF \
{"FIPS_mode",(PyCFunction)_ssl_FIPS_mode,METH_NOARGS,_ssl_FIPS_mode__doc__},static PyObject *
_ssl_FIPS_mode_impl(PyObject *module);
static PyObject *
_ssl_FIPS_mode(PyObject *module,PyObject *Py_UNUSED(ignored))
{
return _ssl_FIPS_mode_impl(module);
}
PyDoc_STRVAR(_ssl_FIPS_mode_set_doc__,"FIPS Mode Set");
#define _SSL_FIPS_MODE_SET_METHODDEF \
{"FIPS_mode_set",(PyCFunction)_ssl_FIPS_mode_set,METH_O,_ssl_FIPS_mode_set_doc__},static PyObject *
_ssl_FIPS_mode_set_impl(PyObject *module,int n);
static PyObject *
_ssl_FIPS_mode_set(PyObject *module,PyObject *arg)
{
PyObject *return_value = NULL;
int n;
if (!PyArg_Parse(arg,"i:FIPS_mode_set",&n)) {
goto exit;
}
return_value = _ssl_FIPS_mode_set_impl(module,n);
exit:
return return_value;
}
ssl.py:
try:
from _ssl import FIPS_mode,FIPS_mode_set
print('successful import')
except ImportError as e:
print('error in importing')
print(e)

django_models_Meta 字段详解
Django 模型类的 Meta 是一个内部类,它用于定义一些 Django 模型类的行为特性。而可用的选项大致包含以下几类
abstract
这个属性是定义当前的模型是不是一个抽象类。所谓抽象类是不会对应数据库表的。一般我们用它来归纳一些公共属性字段,然后继承它的子类可以继承这些字段。
Options.abstract
如果 abstract = True 这个 model 就是一个抽象类
app_label
这个选型只在一种情况下使用,就是你的模型不在默认的应用程序包下的 models.py 文件中,这时候需要指定你这个模型是哪个应用程序的。
Options.app_label
如果一个 model 定义在默认的 models.py,例如如果你的 app 的 models 在 myapp.models 子模块下,你必须定义 app_label 让 Django 知道它属于哪一个 app
app_label = ''myapp''
db_table
db_table 是指定自定义数据库表明的。Django 有一套默认的按照一定规则生成数据模型对应的数据库表明。
Options.db_table
定义该 model 在数据库中的表名称
db_table = ''Students''
如果你想使用自定义的表名,可以通过以下该属性
table_name = ''my_owner_table''
db_teblespace
Options.db_teblespace
定义这个 model 所使用的数据库表空间。如果在项目的 settin 中定义那么它会使用这个值
get_latest_by
Options.get_latest_by
在 model 中指定一个 DateField 或者 DateTimeField。这个设置让你在使用 model 的 Manager 上的 lastest 方法时,默认使用指定字段来排序
managed
Options.managed
默认值为 True,这意味着 Django 可以使用 syncdb 和 reset 命令来创建或移除对应的数据库。默认值为 True, 如果你不希望这么做,可以把 manage 的值设置为 False
order_with_respect_to
这个选项一般用于多对多的关系中,它指向一个关联对象,就是说关联对象找到这个对象后它是经过排序的。指定这个属性后你会得到一个 get_xxx_order () 和 set_xxx_order () 的方法,通过它们你可以设置或者回去排序的对象
ordering
这个字段是告诉 Django 模型对象返回的记录结果集是按照哪个字段排序的。这是一个字符串的元组或列表,没有一个字符串都是一个字段和用一个可选的表明降序的 ''-'' 构成。当字段名前面没有 ''-'' 时,将默认使用升序排列。使用 ''?'' 将会随机排列
- ordering=[''order_date''] # 按订单升序排列
- ordering=[''-order_date''] # 按订单降序排列,- 表示降序
- ordering=[''?order_date''] # 随机排序,?表示随机
- ordering=[''-pub_date'',''author''] # 以 pub_date 为降序,在以 author 升序排列
permissions
permissions 主要是为了在 Django Admin 管理模块下使用的,如果你设置了这个属性可以让指定的方法权限描述更清晰可读。Django 自动为每个设置了 admin 的对象创建添加,删除和修改的权限。
permissions = ((''can_deliver_pizzas'',''Can deliver pizzas''))
proxy
这是为了实现代理模型使用的,如果 proxy = True, 表示 model 是其父的代理 model
unique_together
unique_together 这个选项用于:当你需要通过两个字段保持唯一性时使用。比如假设你希望,一个 Person 的 FirstName 和 LastName 两者的组合必须是唯一的,那么需要这样设置:
unique_together = (("first_name", "last_name"),)
一个 ManyToManyField 不能包含在 unique_together 中。如果你需要验证关联到 ManyToManyField 字段的唯一验证,尝试使用 signal (信号) 或者明确指定 through 属性。
verbose_name
verbose_name 的意思很简单,就是给你的模型类起一个更可读的名字一般定义为中文,我们:
verbose_name = "学校"
verbose_name_plural
这个选项是指定,模型的复数形式是什么,比如:
verbose_name_plural = "学校"
如果不指定 Django 会自动在模型名称后加一个’s’

Eclipse 下忽略掉 node_modules 目录相关配置

https://blog.csdn.net/yzf913214/article/details/72872523

Eclipse下忽略掉node_modules目录相关配置
1.背景
Eclipse项目中的静态资源采用webpack来打包,在项目中的webapp目录下会生成node_modules目录,里面包含node相关模块。由于资源文件较多,会造成Eclipse编译缓慢,另外这些文件不需要发不到运行服务器上,且不需要做版本控制。
2.相关配置
2.1 编译Eclipse项目时忽略掉node_modules目录
选中项目右键-properties,如下图所示

2.2 SVN版本管理时忽略掉node_modules目录
当使用Eclipse中的SVN来来就行版本控制时,选择node_modules目录后,发现添加至svn:ignore为灰色,不可用,无法忽略相关文件。可以通过如下配置来解决该问题。

2.3 项目打包发布时去掉node_modules目录
在项目的maven pom.xml中build下的配置如下
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-war-plugin</artifactId>
<version>2.6</version>
<configuration>
<packagingExcludes>
node_modules/**
</packagingExcludes>
</configuration>
</plugin>
es function_score查询及field_value_factor,boost_mode,max_mode,score_Mode
es function_score查询及field_value_factor,boost_mode,max_mode,score_Mode 博客分类: 搜索引擎,爬虫function_score查询
function_score查询是处理分值计算过程的终极工具。它让你能够对所有匹配了主查询的每份文档调用一个函数来调整甚至是完全替换原来的_score。
实际上,你可以通过设置过滤器来将查询得到的结果分成若干个子集,然后对每个子集使用不同的函数。这样你就能够同时得益于:高效的分值计算以及可缓存的过滤器。
它拥有几种预先定义好了的函数:
weight
对每份文档适用一个简单的提升,且该提升不会被归约:当weight为2时,结果为2 * _score。
field_value_factor
使用文档中某个字段的值来改变_score,比如将受欢迎程度或者投票数量考虑在内。
random_score
使用一致性随机分值计算来对每个用户采用不同的结果排序方式,对相同用户仍然使用相同的排序方式。
衰减函数(Decay Function) - linear,exp,gauss
将像publish_date,geo_location或者price这类浮动值考虑到_score中,偏好最近发布的文档,邻近于某个地理位置(译注:其中的某个字段)的文档或者价格(译注:其中的某个字段)靠近某一点的文档。
script_score
使用自定义的脚本来完全控制分值计算逻辑。如果你需要以上预定义函数之外的功能,可以根据需要通过脚本进行实现。
没有function_score查询的话,我们也许就不能将全文搜索得到分值和近因进行结合了。我们将不得不根据_score或者date进行排序;无 论采用哪一种都会抹去另一种的影响。function_score查询让我们能够将两者融合在一起:仍然通过全文相关度排序,但是给新近发布的文档,或者 流行的文档,或者符合用户价格期望的文档额外的权重。你可以想象,一个拥有所有这些功能的查询看起来会相当复杂。我们从一个简单的例子开始,循序渐进地对 它进行介绍。
根据人气来提升(Boosting by Popularity)
假设我们有一个博客网站让用户投票选择他们喜欢的文章。我们希望让人气高的文章出现在结果列表的头部,但是主要的排序依据仍然是全文搜索分值。我们可以通过保存每篇文章的投票数量来实现:
PUT /blogposts/post/1
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 6
}
在搜索期间,使用带有field_value_factor函数的function_score查询将投票数和全文相关度分值结合起来:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes"
}
}
}
}
function_score查询会包含主查询(Main Query)和希望适用的函数。先会执行主查询,然后再为匹配的文档调用相应的函数。每份文档中都必须有一个votes字段用来保证function_score能够起作用。
在前面的例子中,每份文档的最终_score会通过下面的方式改变:
new_score = old_score * number_of_votes
它得到的结果并不好。全文搜索的_score通常会在0到10之间。而从下图我们可以发现,拥有10票的文章的分值大大超过了这个范围,而没有被投票的文章的分值会被重置为0。
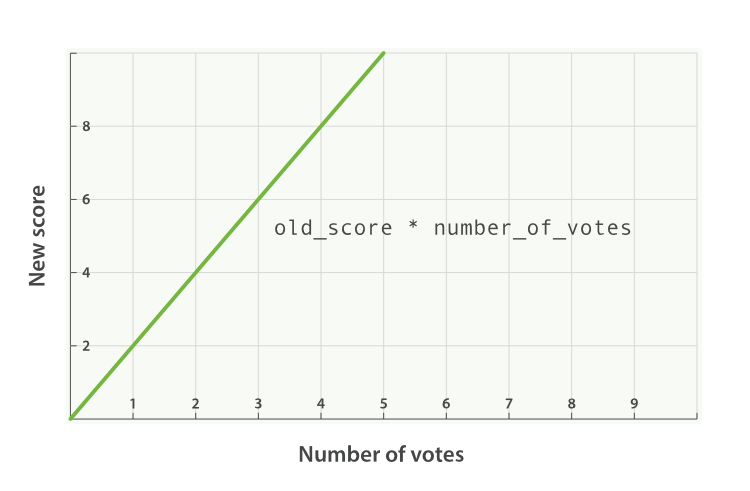
modifier
为了让votes值对最终分值的影响更缓和,我们可以使用modifier。换言之,我们需要让头几票的效果更明显,其后的票的影响逐渐减小。0票和1票的区别应该比10票和11票的区别要大的多。
一个用于此场景的典型modifier是log1p,它将公式改成这样:
new_score = old_score * log(1 + number_of_votes)
log函数将votes字段的效果减缓了,其效果类似下面的曲线:
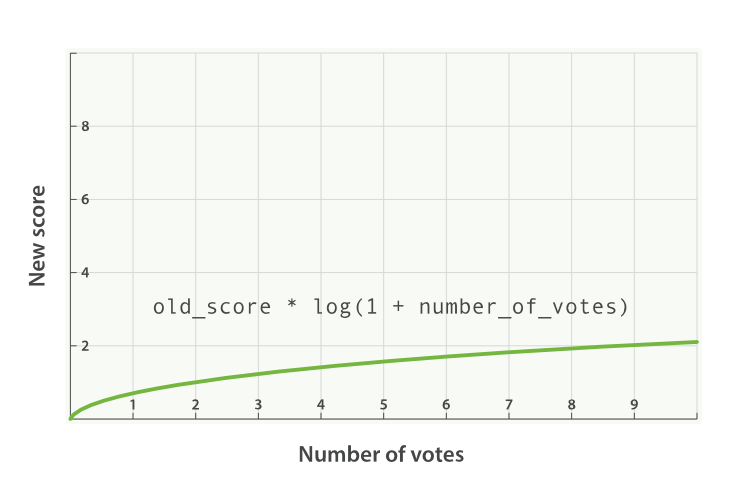
使用了modifier参数的请求如下:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p"
}
}
}
}
可用的modifiers有:none(默认值),log,log1p,log2p,ln,ln1p,ln2p,square,sqrt以及reciprocal。它们的详细功能和用法可以参考field_value_factor文档。
factor
可以通过将votes字段的值乘以某个数值来增加该字段的影响力,这个数值被称为factor:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 2
}
}
}
}
添加了factor将公式修改成这样:
new_score = old_score * log(1 + factor * number_of_votes)
当factor大于1时,会增加其影响力,而小于1的factor则相应减小了其影响力,如下图所示:
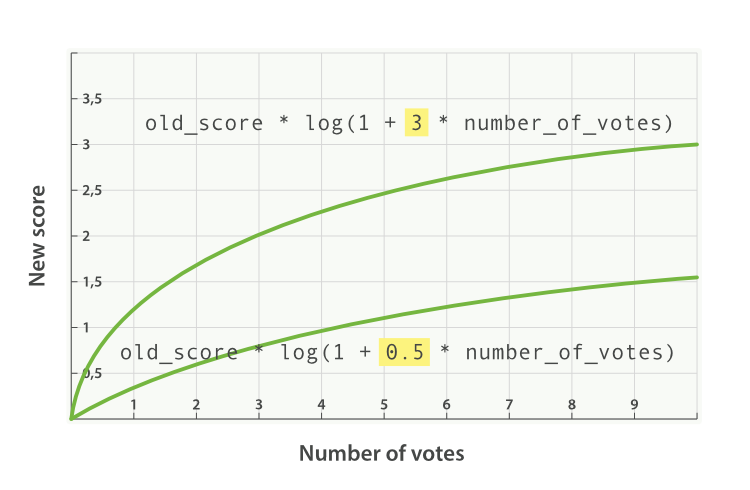
boost_mode
将全文搜索的相关度分值乘以field_value_factor函数的结果,对最终分值的影响可能太大了。通过boost_mode参数,我们可以控制函数的结果应该如何与_score结合在一起,该参数接受下面的值:
- multiply:_score乘以函数结果(默认情况)
- sum:_score加上函数结果
- min:_score和函数结果的较小值
- max:_score和函数结果的较大值
- replace:将_score替换成函数结果
如果我们是通过将函数结果累加来得到_score,其影响会小的多,特别是当我们使用了一个较低的factor时:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 0.1
},
"boost_mode": "sum"
}
}
}
上述请求的公式如下所示:
new_score = old_score + log(1 + 0.1 * number_of_votes)
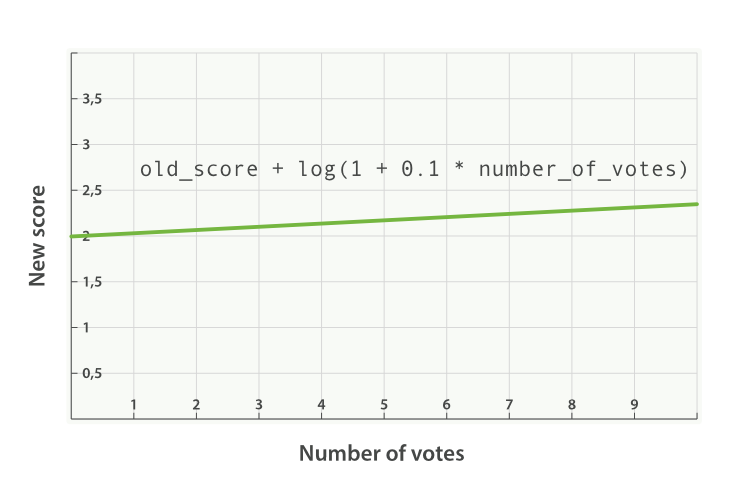
max_boost
最后,我们能够通过制定max_boost参数来限制函数的最大影响:
GET /blogposts/post/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p",
"factor": 0.1
},
"boost_mode": "sum",
"max_boost": 1.5
}
}
}
无论field_value_factor函数的结果是多少,它绝不会大于1.5。
NOTE
max_boost只是对函数的结果有所限制,并不是最终的_score。
score_mode
每个函数都会返回一个结果,我们需要某种方法将多个结果归约成一个,然后将它合并到原始的_score中去。score_mode参数指定了该归约操作,它可以取下面的值:
- multiply: 函数结果会相乘(默认行为)
- sum:函数结果会累加
- avg:得到所有函数结果的平均值
- max:得到最大的函数结果
- min:得到最小的函数结果
- first:只使用第一个函数的结果,该函数可以有过滤器,也可以没有
上例中,我们希望对每个函数的结果进行相加来得到最终的分值,因此使用的是score_mode是sum。
没有匹配任何过滤器的文档会保留它们原本的_score,即为1。
http://blog.csdn.net/dm_vincent/article/details/42201721
http://blog.csdn.net/dm_vincent/article/details/42201789
https://www.elastic.co/guide/en/elasticsearch/reference/1.7/query-dsl-function-score-query.html#query-dsl-function-score-query
关于如何在Python 3.6的ssl模块中实现FIPS_mode和和FIPS_mode_set的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于django_models_Meta 字段详解、Eclipse 下忽略掉 node_modules 目录相关配置、Eclipse下忽略掉node_modules目录相关配置、es function_score查询及field_value_factor,boost_mode,max_mode,score_Mode等相关内容,可以在本站寻找。
本文标签:




