如果您对Python-从字符串创建PandasDataFrame感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于Python-从字符串创建PandasDataFrame的详细
如果您对Python-从字符串创建Pandas DataFrame感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于Python-从字符串创建Pandas DataFrame的详细内容,我们还将为您解答python字符串创建方法的相关问题,并且为您提供关于Pandas - 使用一个 Dataframe 列的子字符串比较两个 Dataframe、pandas dataframe-python检查字符串是否在另一列中忽略大写/小写、pandas.DataFrame.from_dict直接从字典构建DataFrame的方法、Python 处理 Pandas DataFrame 中的行和列的有价值信息。
本文目录一览:- Python-从字符串创建Pandas DataFrame(python字符串创建方法)
- Pandas - 使用一个 Dataframe 列的子字符串比较两个 Dataframe
- pandas dataframe-python检查字符串是否在另一列中忽略大写/小写
- pandas.DataFrame.from_dict直接从字典构建DataFrame的方法
- Python 处理 Pandas DataFrame 中的行和列
")
Python-从字符串创建Pandas DataFrame(python字符串创建方法)
为了测试某些功能,我想DataFrame从字符串创建一个。假设我的测试数据如下:
TESTDATA="""col1;col2;col31;4.4;992;4.5;2003;4.7;654;3.2;140"""将数据读入熊猫的最简单方法是什么DataFrame?
答案1
小编典典一种简单的方法是使用StringIO.StringIO(python2)或io.StringIO(python3)并将其传递给pandas.read_csv函数。例如:
import sysif sys.version_info[0] < 3: from StringIO import StringIOelse: from io import StringIOimport pandas as pdTESTDATA = StringIO("""col1;col2;col3 1;4.4;99 2;4.5;200 3;4.7;65 4;3.2;140 """)df = pd.read_csv(TESTDATA, sep=";")
Pandas - 使用一个 Dataframe 列的子字符串比较两个 Dataframe
我能够使用下面的方法获得所需的输出
df1.merge(df2,left_on = df2.prod_ref.str.extract(''(\d+)'',expand = False),right_on = df1.prod_id.str.extract(''(\d+)'',how = ''left'')

pandas dataframe-python检查字符串是否在另一列中忽略大写/小写
使用.lower()使其与大小写无关:
df[df.apply(lambda x: x['Name'].lower() in x['Description'].lower(),axis=1)]
请注意,这会将"am"视为"amy"上的匹配项。您可能希望使用单词边界来防止这种情况:
>>> def filter(x):
... return bool(re.search(rf"(?i)\b{x['Name']}\b",x["Description"]))
...
>>> df[df.apply(filter,axis=1)]
Name Description
0 Am Owner of Am
1 BQ Employee at bq
或者split可以更好地处理正则表达式特殊字符:
df[df.apply(lambda x: x["Name"].lower() in x["Description"].lower().split(),axis=1)]
您应该使用
df[df.apply(lambda x: x['Name'] in x['Description'].split(' '),axis = 1)]
您可以使用lower,split和isin:
msk=df.Description.str.lower().str.split(expand=True).isin(df.Name.str.lower()).any(1)
df[msk]
输出:
Name Description
0 Am Owner of Am
1 BQ Employee at bq
详细信息
首先,我们使用str.lower将字符串转换为小写字母
print(df.Description.str.lower())
0 owner of am
1 employee at bq
2 employee somewhere
Name: Description,dtype: object
然后我们分割字符串并展开列表:
print(df.Description.str.lower().str.split(expand=True))
0 1 2
0 owner of am
1 employee at bq
2 employee somewhere None
然后我们用df.name来检查isin的值
print(df.Description.str.lower().str.split(expand=True).isin(df.Name.str.lower()))
0 1 2
0 False False True
1 False False True
2 False False False
最后使any在第1轴上(行),以查看是否至少有一个单词匹配:
print(df.Description.str.lower().str.split(expand=True).isin(df.Name.str.lower()).any(1))
0 True
1 True
2 False
dtype: bool

pandas.DataFrame.from_dict直接从字典构建DataFrame的方法
pandas函数中pandas.DataFrame.from_dict 直接从字典构建DataFrame 。
参数解析
DataFrame from_dict()方法用于将Dict转换为DataFrame对象。 此方法接受以下参数。
- data: dict or array like object to create DataFrame.data :字典或类似数组的对象来创建DataFrame。
- orient: The orientation of the data. The allowed values are (‘columns’, ‘index’), default is the ‘columns’. orient :数据的方向。 允许值为(“列”,“索引”),默认值为“列”。 Specify orient=''index'' to create the DataFrame using dictionary keys as rows:。 当参数orient为index值时,会将字典的keys作为DataFrame的行。(默认是keys变为列)
- columns: a list of values to use as labels for the DataFrame when orientation is ‘index’. If it’s used with columns orientation, ValueError is raised. columns :当方向为“索引”时,用作DataFrame标签的值的列表。 如果与列方向一起使用,则会引发ValueError 。
实例
1)By default the keys of the dict become the DataFrame columns:
默认是将字典的keys作为列
data = {''col_1'': [3, 2, 1, 0], ''col_2'': [''a'', ''b'', ''c'', ''d'']}
pd.DataFrame.from_dict(data)
col_1 col_2
0 3 a
1 2 b
2 1 c
3 0 d
2) Specify orient=''index'' to create the DataFrame using dictionary keys as rows: 参数orient为index值时,会将字典的keys作为DataFrame的行
data = {''row_1'': [3, 2, 1, 0], ''row_2'': [''a'', ''b'', ''c'', ''d'']}
pd.DataFrame.from_dict(data, orient=''index'')
0 1 2 3
row_1 3 2 1 0
row_2 a b c d
3) orient为index值时, 可以手动命名列名
pd.DataFrame.from_dict(data, orient=''index'',
columns=[''A'', ''B'', ''C'', ''D''])
A B C D
row_1 3 2 1 0
row_2 a b c d
参考: pandas.DataFrame.from_dict — pandas 1.3.4 documentation
到此这篇关于pandas.DataFrame.from_dict直接从字典构建DataFrame的方法的文章就介绍到这了,更多相关pandas字典构建DataFrame内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- Pandas DataFrame转换为字典的方法
- pandas通过字典生成dataframe的方法步骤
- 从列表或字典创建Pandas的DataFrame对象的方法
- pandas 实现字典转换成DataFrame的方法

Python 处理 Pandas DataFrame 中的行和列
前言:
数据框是一种二维数据结构,即数据以表格的方式在行和列中对齐。我们可以对行/列执行基本操作,例如选择、删除、添加和重命名。在本文中,我们使用的是nba.csv文件。
处理列
为了处理列,我们对列执行基本操作,例如选择、删除、添加和重命名。
列选择:为了在 Pandas DataFrame 中选择一列,我们可以通过列名调用它们来访问这些列。
# Import pandas package
import pandas as pd
# 定义包含员工数据的字典
data = {''Name'':[''Jai'', ''Princi'', ''Gaurav'', ''Anuj''],
''Age'':[27, 24, 22, 32],
''Address'':[''Delhi'', ''Kanpur'', ''Allahabad'', ''Kannauj''],
''Qualification'':[''Msc'', ''MA'', ''MCA'', ''Phd'']}
# 将字典转换为 DataFrame
df = pd.DataFrame(data)
# 选择两列
print(df[[''Name'', ''Qualification'']])输出:

列添加:为了在 Pandas DataFrame 中添加列,我们可以将新列表声明为列并添加到现有数据框。
# Import pandas package
import pandas as pd
# 定义包含学生数据的字典
data = {''Name'': [''Jai'', ''Princi'', ''Gaurav'', ''Anuj''],
''Height'': [5.1, 6.2, 5.1, 5.2],
''Qualification'': [''Msc'', ''MA'', ''Msc'', ''Msc'']}
# 将字典转换为 DataFrame
df = pd.DataFrame(data)
# 声明要转换为列的列表
address = [''Delhi'', ''Bangalore'', ''Chennai'', ''Patna'']
# 使用“地址”作为列名并将其等同于列表
df[''Address''] = address
# 观察结果
print(df)输出:

有关更多示例,请参阅在 Pandas列删除中向现有 DataFrame 添加新列:为了删除 Pandas DataFrame 中的列,我们可以使用该方法。通过删除具有列名的列来删除列。drop()
# importing pandas module
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除通过的列
data.drop(["Team", "Weight"], axis = 1, inplace = True)
# 展示
print(data)输出:如输出图像所示,新输出没有传递的列。这些值被删除,因为轴设置为等于 1,并且由于 inplace 为 True,因此在原始数据框中进行了更改。
删除列之前的数据框- 删除列:
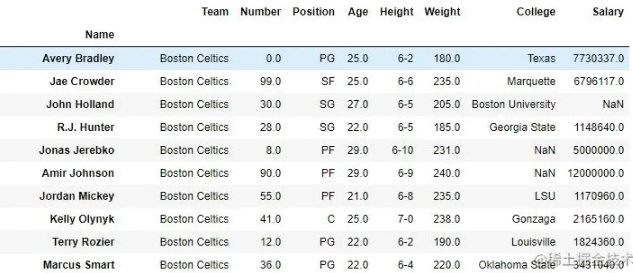
之后的数据框:

处理行
为了处理行,我们可以对行执行基本的操作,例如选择、删除、添加和重命名。
行选择Pandas 提供了一种从数据框中检索行的独特方法。DataFrame.loc[]方法用于从 Pandas DataFrame 中检索行。也可以通过将整数位置传递给 iloc[] 函数来选择行。
# importing pandas package
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name")
# 通过 loc 方法检索行
first = data.loc["Avery Bradley"]
second = data.loc["R.J. Hunter"]
print(first, "\n\n\n", second)输出:如输出图像所示,由于两次都只有一个参数,因此返回了两个系列。
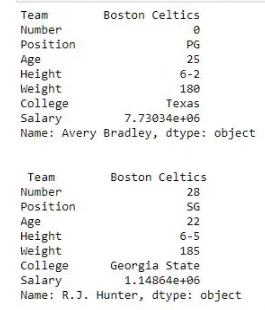
有关更多示例,请参阅Pandas 使用 .loc Row Addition提取行:为了在 Pandas DataFrame 中添加一行,我们可以将旧数据帧与新数据帧连接。
# importing pandas module
import pandas as pd
# 制作数据框
df = pd.read_csv("nba.csv", index_col ="Name")
df.head(10)
new_row = pd.DataFrame({''Name'':''Geeks'', ''Team'':''Boston'', ''Number'':3,
''Position'':''PG'', ''Age'':33, ''Height'':''6-2'',
''Weight'':189, ''College'':''MIT'', ''Salary'':99999},
index =[0])
# 简单地连接两个数据框
df = pd.concat([new_row, df]).reset_index(drop = True)
df.head(5)输出:添加行前的数据框- 添加行
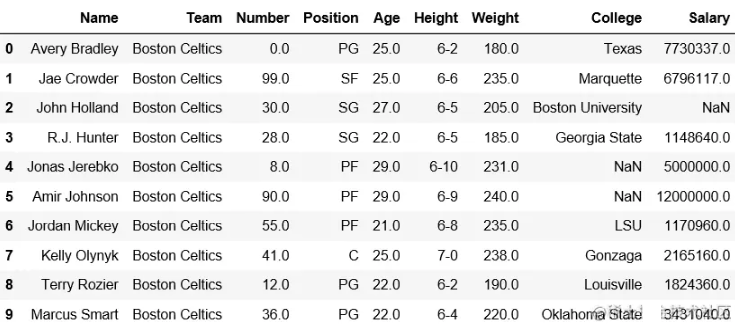
后的数据框-

删除行:为了删除 Pandas DataFrame 中的一行,我们可以使用 drop() 方法。通过按索引标签删除行来删除行。
# importing pandas module
import pandas as pd
# 从csv文件制作数据框
data = pd.read_csv("nba.csv", index_col ="Name" )
# 删除传递的值
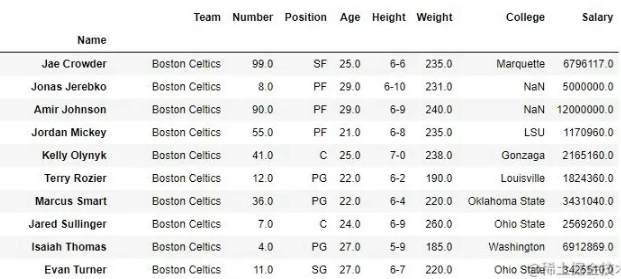
data.drop(["Avery Bradley", "John Holland", "R.J. Hunter",
"R.J. Hunter"], inplace = True)
# 展示
data输出:如输出图像所示,新输出没有传递的值。由于 inplace 为 True,因此删除了这些值并在原始数据框中进行了更改。
删除值之前的数据框- 删除值

后的数据框:
到此这篇关于Python 处理 Pandas DataFrame 中的行和列的文章就介绍到这了,更多相关Python Pandas DataFrame 内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- Python pandas按行、按列遍历DataFrame的几种方式
- Python Pandas 修改表格数据类型 DataFrame 列的顺序案例
- python读取和保存为excel、csv、txt文件及对DataFrame文件的基本操作指南
- python Dataframe 合并与去重详情
- 解读Python中的frame是什么
关于Python-从字符串创建Pandas DataFrame和python字符串创建方法的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于Pandas - 使用一个 Dataframe 列的子字符串比较两个 Dataframe、pandas dataframe-python检查字符串是否在另一列中忽略大写/小写、pandas.DataFrame.from_dict直接从字典构建DataFrame的方法、Python 处理 Pandas DataFrame 中的行和列的相关知识,请在本站寻找。
本文标签:




