本文将介绍运行Python3.5解释器需要哪些标准库模块?的详细情况,。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于、pycharm终端解释器与Python
本文将介绍运行Python 3.5解释器需要哪些标准库模块?的详细情况,。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于<编译原理 - 函数绘图语言解释器(3)解释器 - python>、pycharm终端解释器与Python解释器配置、Python - 标准库 (常用模块)、Python 新提案:“废除”全局解释器锁 GIL | CPython 解释器或许会变得更快的知识。
本文目录一览:- 运行Python 3.5解释器需要哪些标准库模块?
- <编译原理 - 函数绘图语言解释器(3)解释器 - python>
- pycharm终端解释器与Python解释器配置
- Python - 标准库 (常用模块)
- Python 新提案:“废除”全局解释器锁 GIL | CPython 解释器或许会变得更快

运行Python 3.5解释器需要哪些标准库模块?
这是一个CPython程序,尝试使用空初始化初始化解释器sys.path:
#include <Python.h>
int main(int argc,char** argv)
{
wchar_t* program = NULL;
wchar_t* sys_path = NULL;
Py_NoSiteFlag = 1;
program = Py_DecodeLocale(argv[0],NULL);
Py_SetProgramName(program);
sys_path = Py_DecodeLocale("",NULL);
Py_SetPath(sys_path);
Py_Initialize();
PyMem_RawFree(program);
PyMem_RawFree(sys_path);
Py_Finalize();
}
执行上面的程序会引发以下错误:
Fatal Python error: Py_Initialize: Unable to get the locale encoding
ImportError: No module named 'encodings'
Current thread 0x00007ffff7fc6700 (most recent call first):
Signal: SIGABRT (Aborted)
那么,除了encodings包之外,Python
3.5标准库中的哪个包和模块绝对是运行Python3.5解释器所必需的?在我看来,文档中没有此信息。
解释器 - python>")
<编译原理 - 函数绘图语言解释器(3)解释器 - python>
<编译原理 - 函数绘图语言解释器(3)解释器 - python>
-
<编译原理 - 函数绘图语言解释器(1)词法分析器 - python>
-
<编译原理 - 函数绘图语言解释器(2)语法分析器 - python>
背景
-
编译原理上机实现一个对函数绘图语言的解释器 - 用除 C 外的不同种语言实现
-
设计思路:
-
将语法分析器并入绘图功能
-
继承语法分析器覆盖重写
-
-
用 Pycharm 写了一个.py 文件:
-
semanticfunc.py
-
输入流是语法分析器得到的语法树,输出流是绘制的图像
-
测试文本序列:
-
//----------------测试程序1:分别测试------------------------
ORIGIN IS (100,300); // Sets the offset of the origin
ROT IS 0; // Set rotation Angle.
SCALE IS (1,1); // Set the abscissa and ordinate scale.
FOR T FROM 0 TO 200 STEP 1 DRAW (T,0); // The trajectory of the x-coordinate.
FOR T FROM 0 TO 150 STEP 1 DRAW (0,-T); // The trajectory of the y-coordinate.
FOR T FROM 0 TO 120 STEP 1 DRAW (T,-T); // The trajectory of the function f[t]=t.
FOR T FROM 0 TO 2*PI STEP PI/50 DRAW(COS(T),SIN(T));
//---------测试程序2----------
ORIGIN IS (20, 200);
ROT IS 0;
SCALE IS (40, 40);
FOR T FROM 0 TO 2*PI STEP PI/50 DRAW (T, -SIN(T));
ORIGIN IS (20, 240);
FOR T FROM 0 TO 2*PI STEP PI/50 DRAW (T, -SIN(T));
ORIGIN IS (20, 280);
FOR T FROM 0 TO 2*PI STEP PI/50 DRAW (T, -SIN(T));
//-----------------测试程序3--------------
ORIGIN IS (380, 240);
SCALE IS (80, 80/3);
ROT IS PI/2+0*PI/3 ;
FOR T FROM -PI TO PI STEP PI/50 DRAW (COS(T), SIN(T));
ROT IS PI/2+2*PI/3;
FOR T FROM -PI TO PI STEP PI/50 DRAW (COS(T), SIN(T));
ROT IS PI/2-2*PI/3;
FOR T FROM -PI TO PI STEP PI/50 DRAW (COS(T), SIN(T));
//-------------------测试程序4-------------
ORIGIN IS(580, 240);
SCALE IS (80, 80);
ROT IS 0;
FOR T FROM 0 TO 2*PI STEP PI/50 DRAW(COS(T),SIN(T));
FOR T FROM 0 TO PI*20 STEP PI/50 DRAW((1-1/(10/7))*COS(T)+1/(10/7)*COS(-T*((10/7)-1)),(1-1/(10/7))*SIN(T)+1/(10/7)*SIN(-T*((10/7)-1)));
//-------------------测试程序5------------
//------------ 函数复杂度图形:-----------
ROT IS 0; -- 不旋转
ORIGIN IS (50, 400); -- 设置新原点(距系统默认原点的偏移量)
SCALE IS (2,1); -- 设置比例
FOR T FROM 0 TO 300 STEP 1 DRAW (T,0); -- 横坐标
FOR T FROM 0 TO 300 STEP 1 DRAW (0,-T); -- 纵坐标
SCALE IS (2,1); -- 设置比例
FOR T FROM 0 TO 300 STEP 1 DRAW (T,-T); -- 函数F(T)=T的轨迹
SCALE IS (2,0.1); -- 设置比例
FOR T FROM 0 TO 55 STEP 1 DRAW (T,-T*T); -- 函数F(T)=T*T的轨迹
SCALE IS (10,5); -- 设置比例
FOR T FROM 0 TO 60 STEP 1 DRAW (T,-SQRT(T)); -- 函数F(T)=SQRT(T)的轨迹
SCALE IS (20,0.1); -- 设置比例
FOR T FROM 0 TO 8 STEP 0.1 DRAW (T,-EXP(T)); -- 函数F(T)=EXP(T)的轨迹
SCALE IS (2,20); -- 设置比例
FOR T FROM 0 TO 300 STEP 1 DRAW (T,-LN(T)); -- 函数F(T)=LN(T)的轨迹
Step 1 :semanticfunc.py - 继承语法分析器并入绘制功能
#!/usr/bin/env python
# encoding: utf-8
''''''
@author: 黄龙士
@license: (C) Copyright 2019-2021,China.
@contact: iym070010@163.com
@software: xxxxxxx
@file: semanticfunc.py.py
@time: 2019/11/30 10:47
@desc:
''''''
import parserfunc as pf
import scannerclass as sc
import numpy as np
import turtle
import sys
import matplotlib
import matplotlib.pyplot as plt
class semantic(pf.Parsef):
def initPaint(self): # 初始化画布
self.fig = plt.figure()
self.ax = self.fig.add_subplot(111)
def Errmsg(self): #出错处理
sys.exit(1)
def CalcCoord(self,x,y): # 计算点坐标 即比例旋转平移变换 x,y都是二元组
x = x * self.Scale_x
y = y * self.Scale_y ## 进行比例变换
tmp_x = x * np.cos(self.Rot_angle) + y * np.sin(self.Rot_angle)
y = y * np.cos(self.Rot_angle) - x * np.sin(self.Rot_angle)
x= tmp_x ## 旋转变换
x = x + self.Origin_x
y = y + self.Origin_y ## 进行平移变换
return x,y
def DrawLoop(self):
x,y = self.CalcCoord(self.x_ptr,self.y_ptr)
self.ax.scatter(x,y)
def Statement(self): ## 重写statement ,让每次ForStatement执行完毕后画图
self.enter("Statement")
if self.token.type == sc.Token_Type.ORIGIN:
self.OriginStatement()
elif self.token.type == sc.Token_Type.SCALE:
self.ScaleStatement()
elif self.token.type == sc.Token_Type.ROT:
self.RotStatement()
elif self.token.type == sc.Token_Type.FOR:
self.ForStatement()
self.DrawLoop()
# elif self.token.type == sc.Token_Type.CONST_ID or self.token.type == sc.Token_Type.L_BRACKET or \
# self.Expression()
else: self.SyntaxError(2)
self.back("Statement")
# 绘图语言解释器入口(与主程序的外部接口)
def Parser(self): # 语法分析器的入口
self.enter("Parser")
if (self.scanner.fp == None): # 初始化词法分析器
print("Open Source File Error !\n")
else:
self.FetchToken() # 获取第一个记号
self.Program() # 递归下降分析
plt.show()
self.scanner.CloseScanner() # 关闭词法分析器
self.back("Parser")
Step 2 :semanticmain.py - 解释器主函数入口
#!/usr/bin/env python
# encoding: utf-8
''''''
@author: 黄龙士
@license: (C) Copyright 2019-2021,China.
@contact: iym070010@163.com
@software: xxxxxxx
@file: parsermain.py
@time: 2019/11/26 22:31
@desc:
''''''
import scannerfunc as sf
# import parserfunc as pf
import semanticfunc as paint
import os
file_name = ''test.txt''
scanner = sf.scanner(file_name)
semantic = paint.semantic(scanner)
semantic.initPaint()
semantic.Parser()
# parser = pf.Parsef(scanner)
# parser.Parser()
# os.system("pause")
实现结果
- 对于测试程序(1):
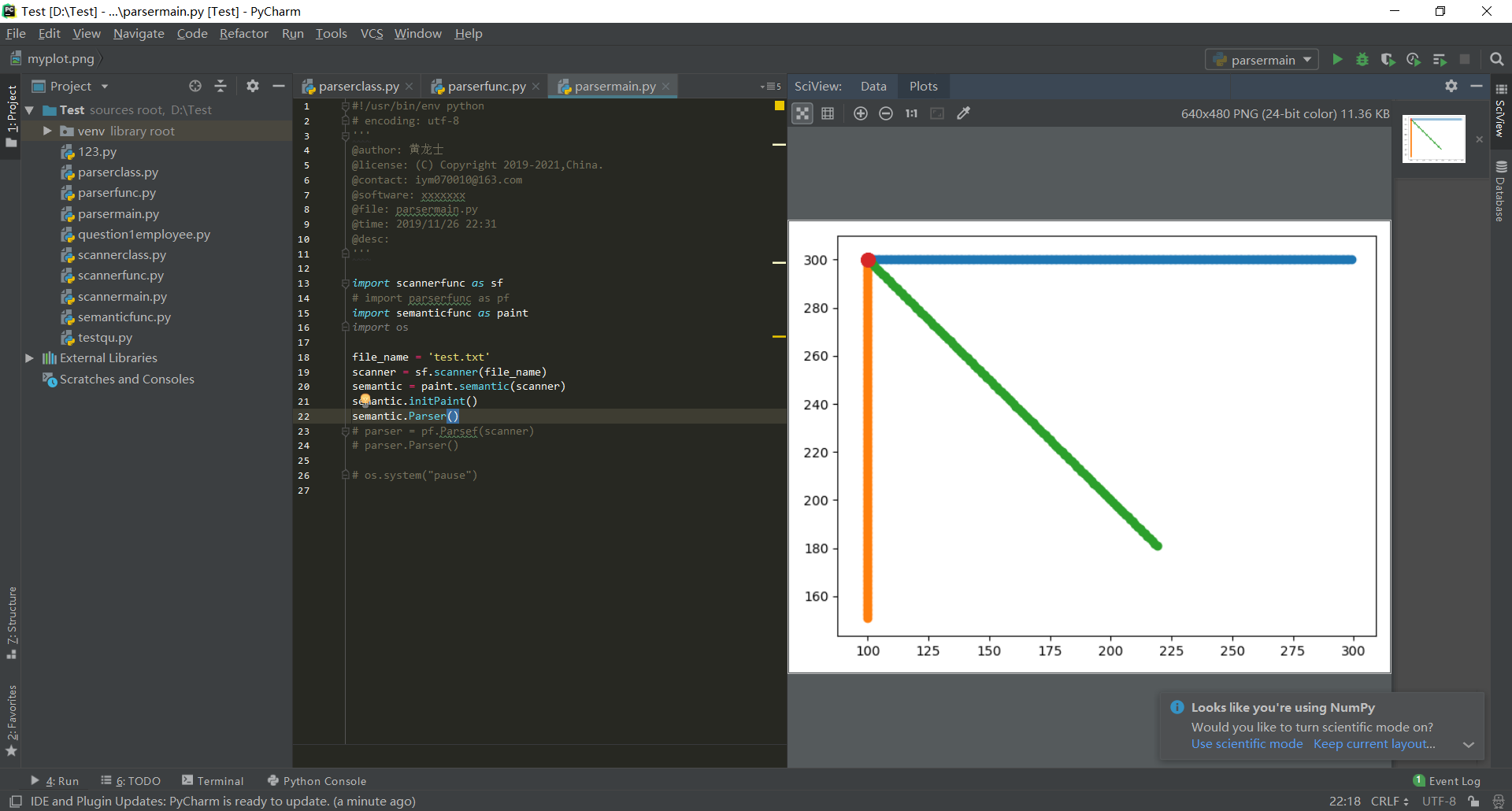
- 对于测试程序(2):
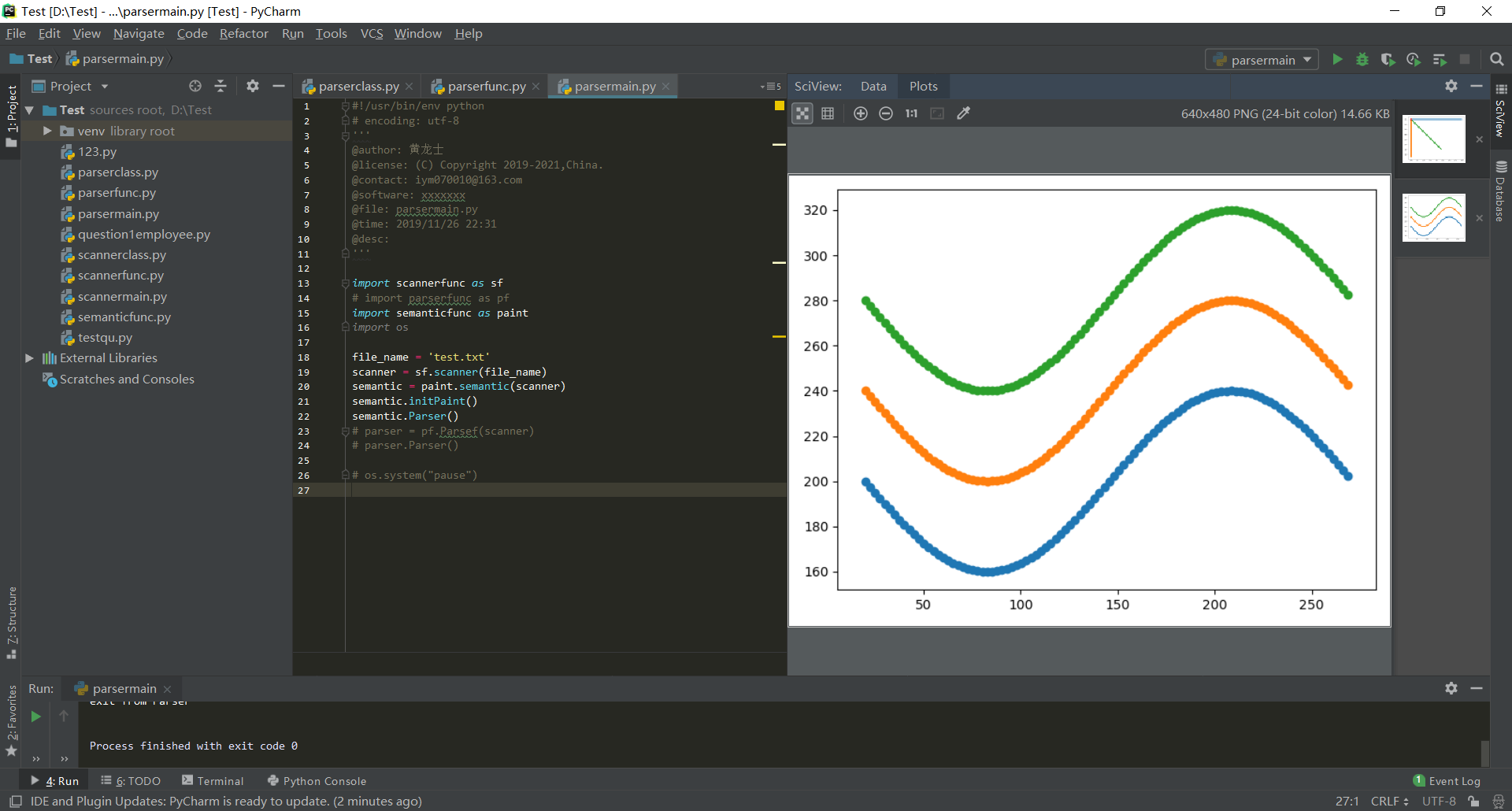
- 对于测试程序(3):
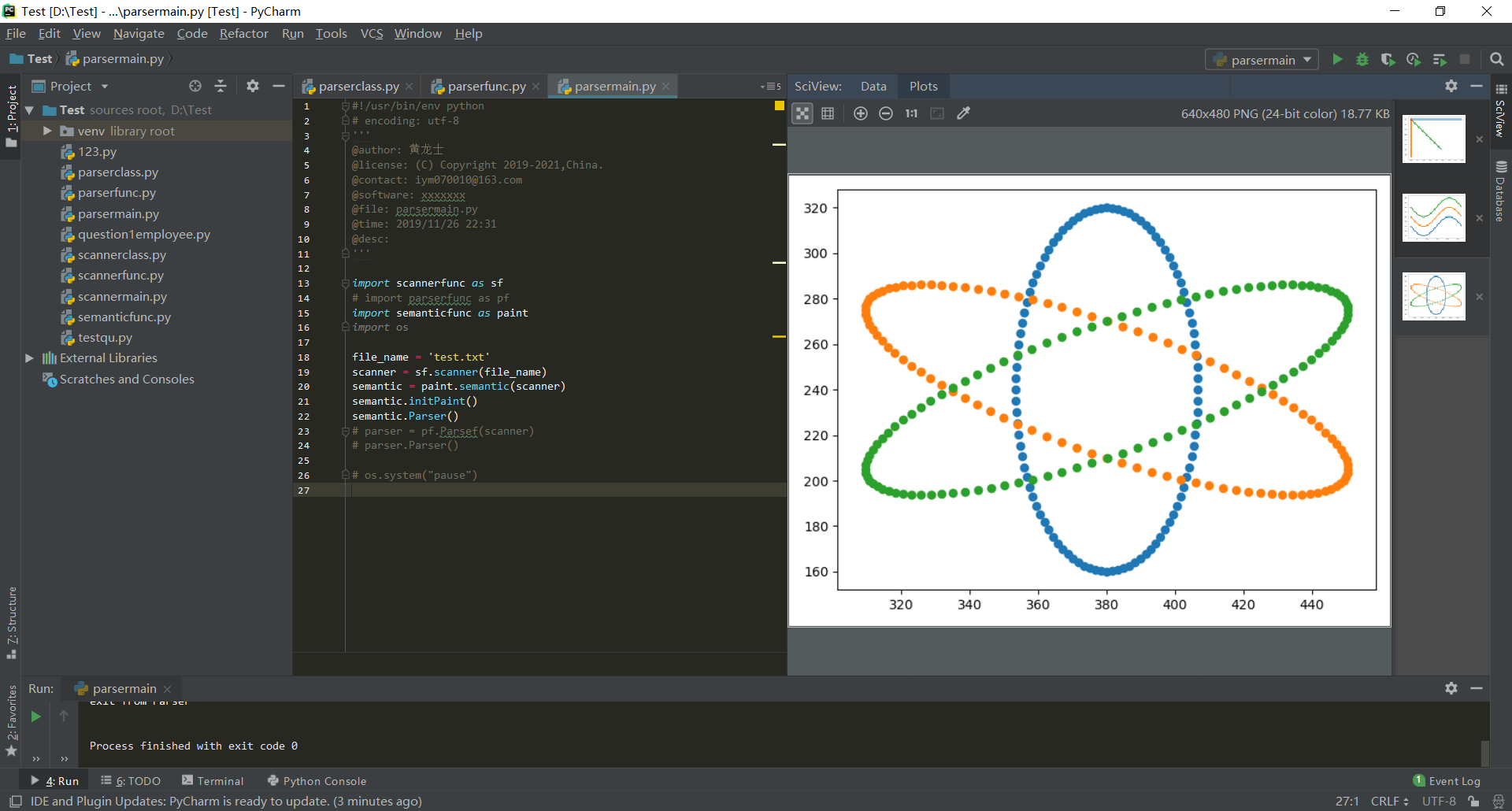
- 对于测试程序(4):
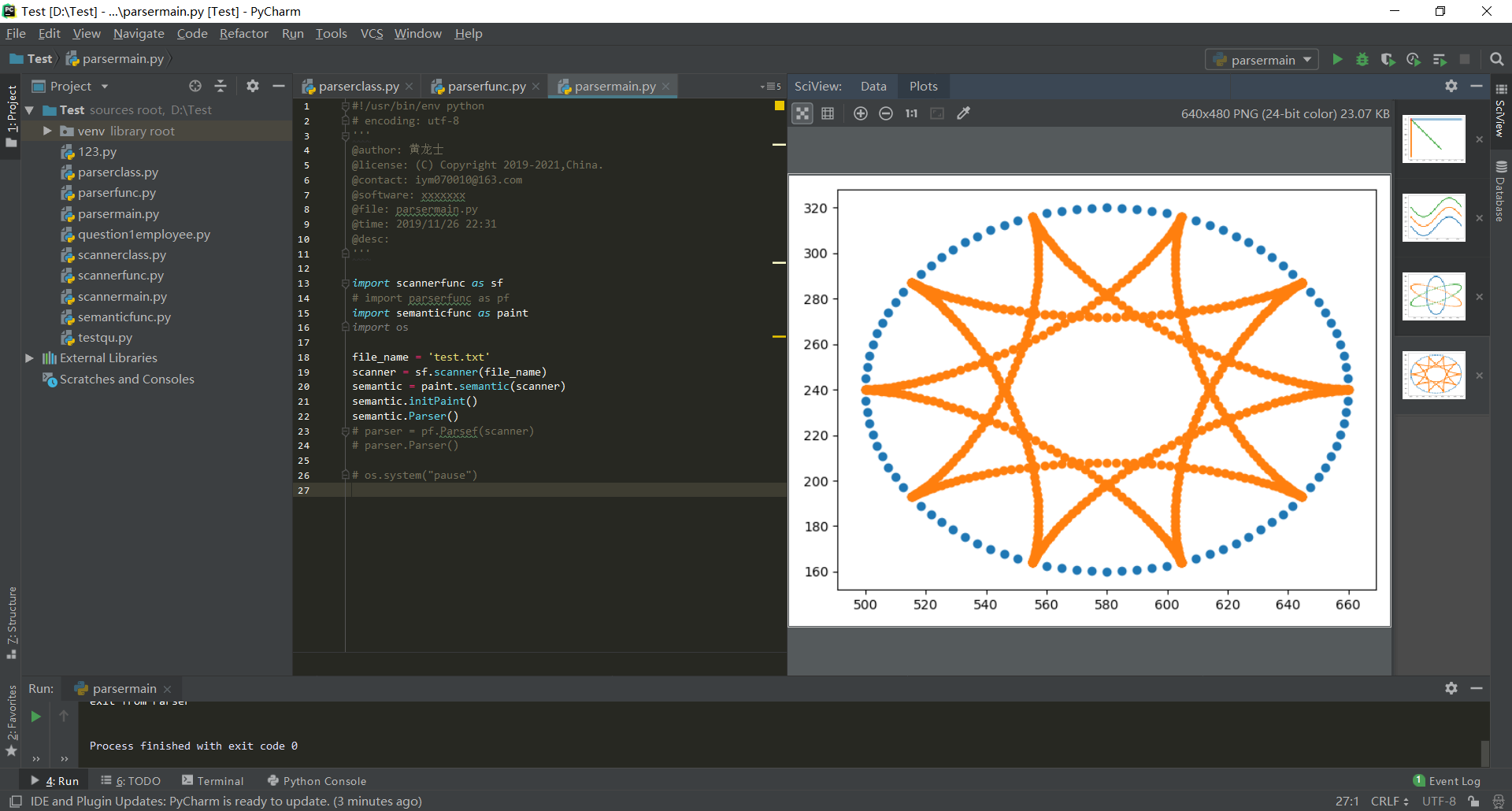
- 对于测试程序(5):

pycharm终端解释器与Python解释器配置
1、pycharm终端运行
pycharm终端运行的时候前面带有PS,是什么意思,怎么变成cmd?
PS表示pycharm用的终端是powershell.exe,如果需要转换为cmd.exe则可以通过以下实现:
1)File——settings

2)tools——terminal——shellPath

将终端路径由powershell修改成cmd.exe即可
2、pycharm怎么切换不同的Python解释器?
1)File——settings

2)project——Python interpreter
在右边里面会显示所有的Python解释器,选择后,点击OK即可完成解释器的切换

3、解释器切换成功
解释器切换成功了,但是运行却还是报错,好像运行的时候没有运行指定的解释器?
在一个py文件中,右键后选择如下操作,将运行解释器模式由指定解释器修改为和项目解释器一样

总结:
到此这篇关于pycharm终端解释器与Python解释器配置的文章就介绍到这了,更多相关 Python解释器 内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
- Windows系统下实现pycharm运行.sh文件(本地运行和打开服务器终端)
- Pycharm安装scrapy及初始化爬虫项目的完整步骤
- PyCharm Terminal终端命令行Shell设置方式
")
Python - 标准库 (常用模块)
一.logging 模块
logging 翻译为日志记录
那问题是什么是日志?
日志实际上是日记的一种,用于记录某个时间点发生了什么事情,比如大学老师的教学日志,工作日志等
为什么要记录日志?
在实际生活中记录日志主要为了日后复查,
比如某个大学老师每天记录自己讲的什么内容,后面有学生某科成绩优异获奖了,校长想要奖励对应的老师,但由于每个老师教的班级都很多,并不一定记得是谁教的,这时候就可以查看教学日志来获取需要的信息了
再比如,工厂的生产日志,如果某个产品除了因为某个零件出现了故障,通过生成日志,可以找到与这个产品同批次的其他产品,进行返工,或是通过日志找到该零件的供应商,进行沟通解决!
程序中的日志
我们的程序开发完成后会被不同系统环境的用户下载使用,期间可能就会出现问题,直接把错误信息展示给用户看是没有任何意义的,用户看不懂也不会解决,那这时候就可以将用户执行的所有操作,以及代码运行的过程,记录到日志中,程序员通过分析日志内容,可以快速的定位问题
综上:日志就是用来记录发生的事件的
日志并不会立即产生作用,而是当程序出现了问题时在去分析日志文件提取有用信息
什么是 logging 模块
logging 模块是 python 提供的用于记录日志的模块
为什么需要 logging
我们完全可以自己打开文件然后,日志写进去,但是这些操作重复且没有任何技术含量,所以 python 帮我们进行了封装,有了 logging 后我们在记录日志时 只需要简单的调用接口即可,非常方便!
日志级别
在开始记录日志前还需要明确,日志的级别
随着时间的推移,日志记录会非常多,成千上万行,如何快速找到需要的日志记录这就成了问题
解决的方案就是 给日志划分级别
logging 模块将日志分为了五个级别,从高到低分别是:
1.info 常规信息
2.debug 调试信息
3.warning 警告信息
4.error 错误信息
5.cretical 严重错误
本质上他们使用数字来表示级别的,从高到低分别是 10,20,30,40,50
logging 模块的使用
#1.导入模块
import logging
#2.输出日志
logging.info("info")
logging.debug("debug")
logging.warning("warning")
logging.error("error")
logging.critical("critical")
#输出 WARNING:root:warning
#输出 ERROR:root:error
#输出 CRITICAL:root:critical
我们发现 info 和 debug 都没有输出,这是因为它们的级别不够,
默认情况下:
logging 的最低显示级别为 warning, 对应的数值为 30
日志被打印到了控制台
日志输出格式为:级别 日志生成器名称 日志消息
如何修改这写默认的行为呢?,这就需要我们自己来进行配置
自定义配置
import logging
logging.basicConfig()
"""可用参数
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
"""
#案例:
logging.basicConfig(
filename="aaa.log",
filemode="at",
datefmt="%Y-%m-%d %H:%M:%S %p",
format="%(asctime)s - %(name)s - %(levelname)s - %(module)s: %(message)s",
level=10
)
格式化全部可用名称
%(name)s:Logger的名字,并非用户名,详细查看
%(levelno)s:数字形式的日志级别
%(levelname)s:文本形式的日志级别
%(pathname)s:调用日志输出函数的模块的完整路径名,可能没有
%(filename)s:调用日志输出函数的模块的文件名
%(module)s:调用日志输出函数的模块名
%(funcName)s:调用日志输出函数的函数名
%(lineno)d:调用日志输出函数的语句所在的代码行
%(created)f:当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d:输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s:字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d:线程ID。可能没有
%(threadName)s:线程名。可能没有
%(process)d:进程ID。可能没有
%(message)s:用户输出的消息
至此我们已经可以自己来配置一 写基础信息了,但是当我们想要将同一个日志输出到不同位置时,这些基础配置就无法实现了,
例如 有一个登录注册的功能 需要记录日志,同时生成两份 一份给程序员看,一份给老板看,作为程序员应该查看较为详细的日志,二老板则应该简单一些,因为他不需要关心程序的细节
要实现这样的需要我们需要系统的了解 loggin 模块
logging 模块的四个核心角色
1.Logger 日志生成器 产生日志
2.Filter 日志过滤器 过滤日志
3.Handler 日志处理器 对日志进行格式化,并输出到指定位置 (控制台或文件)
4.Formater 处理日志的格式
一条日志完整的生命周期
1. 由 logger 产生日志 -> 2. 交给过滤器判断是否被过滤 -> 3. 将日志消息分发给绑定的所有处理器 -> 4 处理器按照绑定的格式化对象输出日志
其中 第一步 会先检查日志级别 如果低于设置的级别则不执行
第二步 使用场景不多 需要使用面向对象的技术点 后续用到再讲
第三步 也会检查日志级别,如果得到的日志低于自身的日志级别则不输出
生成器的级别应低于句柄否则给句柄设置级别是没有意义的,
例如 handler 设置为 20 生成器设置为 30
30 以下的日志压根不会产生
第四步 如果不指定格式则按照默认格式
logging 各角色的使用 (了解)
# 生成器
logger1 = logging.getLogger("日志对象1")
# 文件句柄
handler1 = logging.FileHandler("log1.log",encoding="utf-8")
handler2 = logging.FileHandler("log2.log",encoding="utf-8")
# 控制台句柄
handler3 = logging.StreamHandler()
# 格式化对象
fmt1 = logging.Formatter(
fmt="%(asctime)s - %(name)s - %(levelname)s: %(message)s",
datefmt="%m-%d %H:%M:%S %p")
fmt2 = logging.Formatter(
fmt="%(asctime)s - %(levelname)s : %(message)s",
datefmt="%Y/%m/%d %H:%M:%S")
# 绑定格式化对象与文件句柄
handler1.setFormatter(fmt1)
handler2.setFormatter(fmt2)
handler3.setFormatter(fmt1)
# 绑定生成器与文件句柄
logger1.addHandler(handler1)
logger1.addHandler(handler2)
logger1.addHandler(handler3)
# 设置日志级别
logger1.setLevel(10) #生成器日志级别
handler1.setLevel(20) #句柄日志级别
# 测试
logger1.debug("debug msessage")
logger1.info("info msessage")
logger1.warning("warning msessage")
logger1.critical("critical msessage")
到此我们已经可以实现上述的需求了,但是这并不是我们最终的实现方式,因为每次都要编写这样的代码是非常痛苦的
logging 的继承 (了解)
可以将一个日志指定为另一个日志的子日志 或子孙日志
当存在继承关系时 子孙级日志收到日志时会将该日志向上传递
指定继承关系:
import logging
log1 = logging.getLogger("mother")
log2 = logging.getLogger("mother.son")
log3 = logging.getLogger("mother.son.grandson")
# handler
fh = logging.FileHandler(filename="cc.log",encoding="utf-8")
# formatter
fm = logging.Formatter("%(asctime)s - %(name)s -%(filename)s - %(message)s")
# 绑定
log1.addHandler(fh)
log2.addHandler(fh)
log3.addHandler(fh)
# 绑定格式
fh.setFormatter(fm)
# 测试
# log1.error("测试")
# log2.error("测试")
log3.error("测试")
# 取消传递
log3.propagate = False
# 再次测试
log3.error("测试")
通过字典配置日志模块 (重点)
每次都要编写代码来配置非常麻烦,我们可以写一个完整的配置保存起来,以便后续直接使用
import logging.config
logging.config.dictConfig(LOGGING_DIC)
logging.getLogger("aa").debug("测试")
LOGGING_DIC 模板
standard_format = ''[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]'' \
''[%(levelname)s][%(message)s]'' #其中name为getlogger指定的名字
simple_format = ''[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s''
id_simple_format = ''[%(levelname)s][%(asctime)s] %(message)s''
logfile_path = "配置文件路径"
LOGGING_DIC = {
''version'': 1,
''disable_existing_loggers'': False,
''formatters'': {
''standard'': {
''format'': standard_format
},
''simple'': {
''format'': simple_format
},
},
''filters'': {},
''handlers'': {
#打印到终端的日志
''console'': {
''level'': ''DEBUG'',
''class'': ''logging.StreamHandler'', # 打印到屏幕
''formatter'': ''simple''
},
#打印到文件的日志,收集info及以上的日志
''default'': {
''level'': ''DEBUG'',
''class'': ''logging.handlers.RotatingFileHandler'', # 保存到文件
''formatter'': ''standard'',
''filename'': logfile_path, # 日志文件
''maxBytes'': 1024*1024*5, # 日志大小 5M
''backupCount'': 5, #日志文件最大个数
''encoding'': ''utf-8'', # 日志文件的编码
},
},
''loggers'': {
#logging.getLogger(__name__)拿到的logger配置
''aa'': {
''handlers'': [''default'', ''console''], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
''level'': ''DEBUG'',
''propagate'': True, # 向上(更高level的logger)传递
},
},
}
补充:
getLogger 参数就是对应字典中 loggers 的 key , 如果没有匹配的 key 则返回系统默认的生成器,我们可以在字典中通过空的 key 来将一个生成器设置为默认的
''loggers'': {
# 把key设置为空
'''': {
''handlers'': [''default'', ''console''], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
''level'': ''DEBUG'',
''propagate'': True, # 向上(更高level的logger)传递
},
},
, 往后在使用时可以这调用模块提供的函数,来输出日志
logging.info ("测试信息!")
另外我们在第一次使用日志时并没有指定生成器,但也可以使用,这是因为系统有默认的生成器名称就叫 root
最后来完成之前的需求:
有一个登录注册的功能 需要记录日志,同时生成两份 一份给程序员看,一份给老板看,作为程序员应该查看较为详细的日志,二老板则应该简单一些,因为他不需要关心程序的细节
# 程序员看的格式
standard_format = ''[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]'' \
''[%(levelname)s][%(message)s]'' #其中name为getlogger指定的名字
logfile_path1 = "coder.log"
# 老板看的格式
simple_format = ''[%(levelname)s][%(asctime)s]%(message)s''
logfile_path2 = "boss.log"
LOGGING_DIC = {
''version'': 1,
''disable_existing_loggers'': False,
''formatters'': {
''standard'': {
''format'': standard_format
},
''simple'': {
''format'': simple_format
},
},
''filters'': {},
''handlers'': {
#打印到终端的日志
''console'': {
''level'': ''DEBUG'',
''class'': ''logging.StreamHandler'', # 打印到屏幕
''formatter'': ''simple''
},
#打印到文件的日志,收集info及以上的日志
''std'': {
''level'': ''DEBUG'',
''class'': ''logging.handlers.RotatingFileHandler'', # 保存到文件
''formatter'': ''standard'',
''filename'': logfile_path1, # 日志文件
''maxBytes'': 1024*1024*5, # 日志大小 5M
''backupCount'': 5, #日志文件最大个数
''encoding'': ''utf-8'', # 日志文件的编码
},
''boss'': {
''level'': ''DEBUG'',
''class'': ''logging.handlers.RotatingFileHandler'', # 保存到文件
''formatter'': ''simple'',
''filename'': logfile_path2, # 日志文件
''maxBytes'': 1024 * 1024 * 5, # 日志大小 5M
''backupCount'': 5, # 日志文件最大个数
''encoding'': ''utf-8'', # 日志文件的编码
}
},
''loggers'': {
#logging.getLogger(__name__)拿到的logger配置
''aa'': {
''handlers'': [''std'', ''console'',"boss"], # 这里把上面定义的handler都加上,即log数据会同时输出到三个位置
''level'': ''INFO'',
''propagate'': True, # 向上(更高level的logger)传递
},
},
}
二.os 模块
os 翻译过来就是操作系统,os 模块提供了与操作系统打交道需要用到的函数,
那我们什么时候需要与操作系统打交道呢?
在操作系统中,我们最最常用的操作就是,对文件及文件夹的操作,所以 当你需要与操作文件时,就应该想到 os 模块了
os 提供一下函数
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: (''.'')
os.pardir 获取当前目录的父目录字符串名:(''..'')
os.makedirs(''dirname1/dirname2'') 可生成多层递归目录
os.removedirs(''dirname1'') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(''dirname'') 生成单级目录;相当于shell中mkdir dirname
os.rmdir(''dirname'') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(''dirname'') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat(''path/filename'') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->''nt''; Linux->''posix''
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
三.os.path 模块
该模块用于处理路径,我们知道 python 是一门跨平台的语言,二每种操作系统,文件路径是截然不同的,为了使程序可以在不同平台生正确运行,python 提供了该模块,使用该模块可以实现路径在不同品台下的自动转换,从而实现跨平台,
今后只要涉及到文件或文件夹路径,就应该使用该模块
提供的函数:
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
normcase函数
在Linux和Mac平台上,该函数会原样返回path,在windows平台上会将路径中所有字符转换为小写,并将所有斜杠转换为饭斜杠。
>>> os.path.normcase(''c:/windows\\system32\\'')
''c:\\windows\\system32\\''
normpath函数
规范化路径,如..和/
>>> os.path.normpath(''c://windows\\System32\\../Temp/'')
''c:\\windows\\Temp''
>>> a=''/Users/jieli/test1/\\\a1/\\\\aa.py/../..''
>>> print(os.path.normpath(a))
/Users/jieli/test1
四.subprocess
subprocess 称之为子进程,进程是一个正在运行的程序
为什么要使用子进程,因为之前的 os.system () 函数无法获取命令的执行结果,另一个问题是当我们启动了某一其他进程时无法与这个子进程进行通讯,
当要在 python 程序中执行系统指令时 就应该使用 subprocess 自动化运维经常会使用
#测试
res = os.system("python")
print(res)
# res结果为执行状态
subprocess 的使用
import subprocess
p = subprocess.Popen("ls",shell=True)
#shell=True 告诉系统这是一个指令 而不是某个文件名
#此时效果与sys.system()没有任何区别,都是将结果输出到控制台
# 那如何与这个进程交互数据呢,这需要用到三个参数
1.stdin 表示输入交给子进程的数据
2.stdout 表示子进程返回的数据
3.stderr 表示子进程发送的错误信息
#这三个参数,的类型都是管道,(管道本质就是一个文件,可以进行读写操作),使用subprocess.PIPE来获取一个管道
案例:
理解了三个参数的意义后让我们来实现一个小功能
一个子进程执行 tasklist 命令获取所有的任务信息,然后将结果交给另一个进程进行查找
另一个子进程执行 findstr 查找某个任务信息
p1 = subprocess.Popen("tasklist",shell=True,stdout=subprocess.PIPE)
p2 = subprocess.Popen("findstr smss",shell=True,stdin=p1.stdout,stdout=subprocess.PIPE)
print(p2.stdout.read())
总结: subprocess 主要用于执行系统命令,对比 sys.system 区别在于可以在进程间交换数据
五.sys 模块
sys 是 system 的缩写,表示系统,但是要注意
sys 指的是解释器自身,而非操作系统
所以该模块主要是处理与解释器相关的操作的
提供的函数和属性:
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
其中提供了有一个 arg 属性用于接收从控制台传入的参数,当你要开发一款命令行程序时,该属性非常重要
案例:开发一款命令行界面的文件复制工具
思路:第一个参数是当前执行文件本身,第二个参数用于接收源文件,第三个参数用于接收目标文件
import sys
source_path = sys.argv[1]
target_path = sys.argv[2]
print(source_path)
print(target_path)
with open(source_path, "rb") as f1:
with open(target_path, "wb") as f2:
while True:
data = f1.read(1024)
if not data:
break
f2.write(data)
六.confiparser
confiparser, 翻译为配置解析,很显然,他是用来解析配置文件的,
何为配置文件?
用于编写程序的配置信息的文件
何为配置信息?
为了提高程序的扩展性,我们会把一些程序中需要用到的值交给用户来确定,比如迅雷的下载目录,同时下载数,qq 的提示音等等,
作为配置信息的数据 应满足两个条件
1. 数据的值不是固定的
2. 可以由用户来指定的
例如我们做一个登录功能,为了方便使用我们可以将用户的用户名密码写到配置文件中,可以不需要每次都输入
配置文件编写格式
在使用该模块前必须要先知道其配置文件的格式,由于读写文件的代码是模块封装好的,所以必须按照固定的方式来边编写,才能被正常解析,当然并不是只有 python 有配置文件,其他任何语言都有,但是格式是相同的!
格式:
配置文件中只允许出现两种类型的数据
第一种 section 分区 方括号中是分区的名称 例如:[ATM]
第二种 option 选项 名称 = 值
注意:
不能出现重复的分区名
同一个分区下不能有相同的选项名
值可以是任何类型 且字符串不需要加引号
confiparser 的使用
读取数据
import configparser
#获取解析器对象
config=configparser.ConfigParser()
# 读取某个配置文件
config.read(''a.cfg'')
#查看所有的分区
res=config.sections() #[''section1'', ''section2'']
print(res)
#查看标题section1下所有key=value的key
options=config.options(''section1'')
print(options) #[''k1'', ''k2'', ''user'', ''age'', ''is_admin'', ''salary'']
#查看标题section1下所有key=value的(key,value)格式
item_list=config.items(''section1'')
print(item_list) #[(''k1'', ''v1''), (''k2'', ''v2''), (''user'', ''egon''), (''age'', ''18''), (''is_admin'', ''true''), (''salary'', ''31'')]
#查看标题section1下user的值=>字符串格式
val=config.get(''section1'',''user'')
print(val) #egon
#由于使用前需要进行转换,所以模块封装了转换类型的功能,只需要调用对应的函数即可,如下:
val1=config.getint(''section1'',''age'')
val2=config.getboolean(''section1'',''is_admin'')
val3=config.getfloat(''section1'',''salary'')
#是否存在某选项
print(cfg.has_option("mysql","name"))
#是否存在某分区
print(cfg.has_section("db"))
添加,删除,修改
import configparser
config=configparser.ConfigParser()
config.read(''a.cfg'',encoding=''utf-8'')
#删除整个标题section2
config.remove_section(''section2'')
#删除标题section1下的某个k1和k2
config.remove_option(''section1'',''k1'')
config.remove_option(''section1'',''k2'')
#判断是否存在某个标题
print(config.has_section(''section1''))
#判断标题section1下是否有user
print(config.has_option(''section1'',''user''))
#添加一个标题
config.add_section(''jack'')
#在标题egon下添加name=egon,age=18的配置
config.set(''jack'',''name'',''egon'') # 如果已存则覆盖原来的值
#config.set(''jack'',''age'',18) #报错,必须是字符串
#最后将修改的内容写入文件,完成最终的修改
config.write(open(''a.cfg'',''w''))
代码创建生成文件
import configparser
config = configparser.ConfigParser()
config.add_section("setion1")
config.set("setion1","name","zhangsn")
with open("test.config","w") as f:
config.write(f)
总结 configparser 用于解析配置文件,虽然可以修改和,创建,配置文件,但是并不常用,解析才是其核心功能!
七.shevle 模块
该模块用于序列化 python 中的数据,但是序列化已经有 pickle 了为什么出现了 shevle?
因为 shevle 更加简单,封装了文件的读写操作.load 和 dump 操作,
只有一个 open 函数,返回类似字典的对象,可读可写;key 必须为字符串,而值可以是 python 所支持的数据类型
完全可以将其看做是一个带有持久存储功能的字典来看待,操作方式与字典没有任何区别
#保存数据
s = shelve.open("shv.shv")
s["name"] = "jack"
#取出数据
s = shelve.open("shv.shv")
print(s["name"])
#输出 jack
#关闭资源
s.close
八.shutil
该模块提供了更加丰富的文件操作功能,压缩,解压缩,获取文件信息等
提供的功能:
shutil.copyfileobj 拷贝文件 提供两个文件对象 长度表示缓冲区大小
shutil.copyfile(src, dst) 拷贝文件 提供两个文件路径
shutil.copymode() 拷贝文件权限 提供两个文件路径
shutil.copystat(src, dst) 拷贝文件状态信息 最后访问 最后修改 权限 提供两个文件路径
shutil.copy(src, dst) 拷贝文件和权限 提供两个文件路径
shutil.copy2(src, dst) 拷贝文件和状态信息 提供两个文件路径
shutil.ignore_patterns("mp3","*.py")
shutil.copytree(src, dst, symlinks=False, ignore=None) 拷贝目录
symlinks默认False将软连接拷贝为硬链接 否则拷贝为软连接
shutil.rmtree 删除目录 可以设置忽略文件
shutil.move(src, dst) 移动目录和文件
压缩与解压缩测试
import shutil
#压缩, 文件名 格式 需要压缩的文件所在文件夹
shutil.make_archive("压缩测试","zip",r"/Users/jerry/PycharmProjects/备课/常用模块五期")
#解压缩 #压缩, 文件名 解压后的文件存放目录
shutil.unpack_archive("压缩测试.zip",r"/Users/jerry/PycharmProjects/备课/常用模块五期/
# #压缩当前执行文件所在文件夹内容到当前目录
# shutil.make_archive("test","zip")
#
# #压缩root_dir指定路径的文件到当前目录
# shutil.make_archive("test","zip",root_dir=r"/Users/jerry/PycharmProjects/work/re模块")
#
# #压缩root_dir指定路径的文件到base_name指定路径
# shutil.make_archive("/Users/jerry/PycharmProjects/work/压缩文件/test","zip",root_dir=r"/Users/jerry/PycharmProjects/work/re模块")
# #压缩root_dir指定路径的文件到base_name指定的压缩文件 压缩文件仅包含re模块下的的内容
# shutil.make_archive("test",
# "zip",
# root_dir=r"/Users/jerry/PycharmProjects/work",)
# 当指定base_dir时 则优先使用base_dir 与root_dir不同的是 压缩文件不仅包含re模块下的内容 还包括re模块的完整文件夹层级
# # 解压后得到Users ->jerry -> PycharmProject->work->re模块
# shutil.make_archive("test",
# "zip",
# root_dir=r"/Users/jerry/PycharmProjects/work/re模块",
# base_dir=r"/Users/jerry/PycharmProjects/work/re模块")

Python 新提案:“废除”全局解释器锁 GIL | CPython 解释器或许会变得更快
近日,开发者 Alex Waygood 在 Python 基金会博客中提到了上周刚刚举办的Python 语言峰会上关于 Python 语言的重大议题 —— “废除” Python 语言的全局解释器锁(GIL)。

“双刃剑”:CPython —— 解释器和编译器
众所周知,Python 动态语言的灵活性是把“双刃剑”。这意味着可以有不同的运行时,例如 Pyston、Cinder、MicroPython、pypypy 等,它们可能支持整个语言、特定版本或子集。但如果你使用的是 Python,那么你可能正在运行 CPython。
CPython 是用 C 语言编写的标准 Python 解释器,它同时还充当着编译器,因为它的任务是在实际的解释阶段之前以字节码的形式编译 Python 代码。
CPython 有一种称为全局解释器锁 GIL(Global Interpreter Lock)的东西,可以影响线程代码,即一次只能在解释器中运行一个线程。因此,GIL 一直被看做是该语言发展的固有限制。
之前,也一直有提案想要解决这个问题,例如将性能关键部分移到 C 或使用多个解释器。但要满足以上期望,解释器用户的受众可能会扩大。目前有几种替代方案,例如通过专用于 JVM(Java 虚拟机)和 CLR(公共语言运行时)的方案,但以上多数现有的解决方案都有相当大的缺点。
所以基于以上背景,“不带全局解释器锁的 Python” 的支持声逐渐受到关注。
多次尝试被废除:GIL 究竟该如何摆脱掉
直到此次的 Python 语言峰会上,Meta 高级工程总监 Sam Gross 在有关 “nogil”项目的主题中,提出了“废除 GIL ”的相关议题。
据悉,该提议是基于之前在 Python 中废除 GIL 的想法。Gross 最初在使用第三方代码的 Python 项目中遇到了问题,因此开始思考“如果没有 GIL”的话如何使得线程安全的进行。
前面提到过,全局解释器锁 GIL 一次只能在解释器中运行一个线程,所以当你可以保证一次只运行一个线程时,程序状态或许会更容易推理。但如果没有 GIL,引用计数、内存分配、方法解析顺序缓存和垃圾收集线程则会变得不安全。
那么,该如何摆脱 GIL 呢?
据报道,早前 Sam Gross 就专门对这一演变进行了讨论。由于 CPython 中的设计是“线程安全”,但它依赖于 GIL。想要摆脱 GIL,首先,就要对参考计数进行重大更改。

为了知道垃圾收集器是否可以释放内存中的对象,它会统计对该对象的所有引用。目前,引用计数是非原子性的,将所有引用计数操作更改为原子性操作会对性能造成巨大影响。
Sam Gross 在该提案中使用了一种称为“有偏引用计数”(biased reference counting )的技术,用于获取本地和共享引用。本地引用可以利用非原子性操作,拥有线程将本地引用和共享引用结合起来以跟踪所有权。这种方法非常适用于单线程对象,或者只被几个线程少量使用的对象。
在程序的生命周期中存在几个对象,如插入字符串、True、False 和 None,它们可以被标记为“不朽”(immortal),从而将它们的引用计数开销减少到零。通过利用引用计数字段中的最低有效位,对象被标记为“不朽”。经常访问但不能保证“不朽”的对象延迟了引用计数,这意味着唯一需要的引用计数是当引用存储在堆上时,此更改的一个副作用是无法立即回收对象,因为需要扫描堆栈以查找任何剩余的引用。
Sam Gross 用 mimalloc 替换了标准的 pymalloc 内存分配器,mimalloc 是 malloc 的一个替代品,提供了线程安全和性能。这种交换的好处是,这个分配器允许运行时在没有显式列表的情况下查找 GC 跟踪的对象。这是一个显著的性能提升,但这意味着不能只交换另一个与 malloc 兼容的分配器,而期望垃圾收集和收集具有相同的线程安全性。
Python 尚未决定是否删除 GIL
关于为何要删除 GIL 的问题,Python 基金会博客中解释称,“为了让 Python 在没有 GIL 的情况下有效地工作,必须向大多数代码中添加新锁,以确保其保持线程安全,但向现有代码中添加新锁可能非常困难,因为在某些领域可能会出现大幅放缓。”
此次,Sam Gross “删除 GIL”的新提议似乎已经受到了 Python 核心开发团队其他成员的“热情”欢迎。现在,要解决的主要问题是如何在 CPython 上实施如此巨大的变革。
据悉,CPython 的下一个版本(或为 CPython 3.11)预计将于 2022 年 10 月发布,不知道届时会不会有大更新,但报道称开发人员们尤其希望通过此更新获得更高的性能和对在 web 浏览器上下文中运行的支持的集成。
过去的一段时间里,由于 GIL 阻碍了语言的进发,开发者曾多次尝试在标准实现 CPython 中废除这种技术。此次,“删除 GIL”的新提议终于来了,尽管 Python 官方尚未就实施作出最终决定,但一切依旧值得期待。
我们今天的关于运行Python 3.5解释器需要哪些标准库模块?的分享已经告一段落,感谢您的关注,如果您想了解更多关于<编译原理 - 函数绘图语言解释器(3)解释器 - python>、pycharm终端解释器与Python解释器配置、Python - 标准库 (常用模块)、Python 新提案:“废除”全局解释器锁 GIL | CPython 解释器或许会变得更快的相关信息,请在本站查询。
本文标签:




