如果您对Python正则表达式可过滤与模式匹配的字符串列表感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于Python正则表达式可过滤与模式匹配的字符串列表的详细内容,我们还
如果您对Python正则表达式可过滤与模式匹配的字符串列表感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于Python正则表达式可过滤与模式匹配的字符串列表的详细内容,我们还将为您解答python正则过滤掉英文和数字的相关问题,并且为您提供关于python – 正则表达式匹配字符串上的正则表达式匹配返回无、python中正则表达式与模式匹配、Python学习笔记模式匹配与正则表达式之用正则表达式匹配更多模式、python正则表达式(?=)匹配的问题的有价值信息。
本文目录一览:- Python正则表达式可过滤与模式匹配的字符串列表(python正则过滤掉英文和数字)
- python – 正则表达式匹配字符串上的正则表达式匹配返回无
- python中正则表达式与模式匹配
- Python学习笔记模式匹配与正则表达式之用正则表达式匹配更多模式
- python正则表达式(?=)匹配的问题
")
Python正则表达式可过滤与模式匹配的字符串列表(python正则过滤掉英文和数字)
我使用R的次数更多,而在R中执行起来更容易:
> test <- c('bbb','ccc','axx','xzz','xaa')
> test[grepl("^x",test)]
[1] "xzz" "xaa"
但是如果test是列表,如何在python中执行呢?
PS我正在使用谷歌的Python练习学习Python。而且我更喜欢使用回归表达式。

python – 正则表达式匹配字符串上的正则表达式匹配返回无
我正在为一个subreddit制作一个小机器人.为此,我从trakt.tv中删除了一些数据.报废后我跑了一点正则表达式
obituarySecondary = re.match(r"^([\w \,\.\"]+,\d{4} ?- ?\w+ \d+,?\d{4})",obituaryRaw).group(0)
我得到了Nathaniel Fisher,Sr.1943-2000所需的结果
现在我在obituarySecondary上运行了另一个正则表达式
timeline = "\n\n" + re.match(r'(\d{4} ?- ?\d{4})',obituarySecondary).group(0)
但这总是回归.
我在https://regex101.com/上运行了相同的正则表达式以确保我正确处理并且字符串匹配,但不在我的系统上.
解决方法
有关更多详细信息,请查看this StackOverflow问题

python中正则表达式与模式匹配
一、前言
在之前找工作过程中,面试时经常被问到会不会python,懂不懂正则表达式。心里想:软件的东西和芯片设计有什么关系?咱也不知道因为啥用这个,咱也不敢问啊!在网上搜索到了一篇关于脚本在ASIC领域中应用的文章(原文见参考文献1),里边提到了python的用武之地:

本文以《Python编程快速上手——让繁琐工作自动化》书中的示例,讲述利用python实现文本中特定内容提取的方式。
二、提取特定内容示例
需求:找出文本中所有的电话号码和邮件地址。设计方案:在剪贴板的文本中提取出所有与电话号码和邮件地址格式匹配的字符串。有了需求和设计方案,现根据电话号码和邮箱地址格式编写正则表达式。先来看看程序代码,再做讲解。


1 import pyperclip,re
2
3 #phoneNumber:415-555-4242 x331
4 #email address:info@nostarch.com
5
6 phoneRegex = re.compile(r''''''( #0 all
7 (\d{3}|\(\d{3}\))? #1 area code
8 (\s|-|\.)? #2 separator
9 (\d{3}) #3 first 3 digits
10 (\s|-|\.) #4 separator
11 (\d{4}) #5 last 4 digits
12 (\s*(ext|x|ext\.)\s*(\d{2,5}))? #6 7 8extension
13 )'''''',re.VERBOSE)
14
15 emailRegex = re.compile(r''''''( #0 all
16 [a-zA-Z0-9._%+-]+ # username
17 @ # @ symbol
18 [a-zA-Z0-9.-]+ # domain name
19 (\.[a-zA-Z]{2,4}) #1 dot-something
20 )'''''',re.VERBOSE)
21
22 #Find matches in clipboard text.
23 text = str(pyperclip.paste())
24 mo1 = phoneRegex.findall(text)
25 mo2 = emailRegex.findall(text)
26 print(mo1)
27 print(mo2)
28 matches = []
29 for groups in phoneRegex.findall(text):
30 phoneNum = ''-''.join([groups[1],groups[3],groups[5]])
31 if groups[8] != '''':
32 phoneNum += '' x'' + groups[8]
33 matches.append(phoneNum)
34
35 for groups in emailRegex.findall(text):
36 matches.append(groups[0])
37
38 #Copy results to the clipboard
39 if len(matches) > 0:
40 pyperclip.copy(''\n''.join(matches))
41 print(''Copied to clipboard:'')
42 print(''\n''.join(matches))
43 else:
44 print(''No phone numbers or email address found.'')此处电话号码的格式是:三个数字组成的区号(可选),三个数字,四个数字,任意数空格+ext/x/ext.+任意数空格+2到5个数字组成的分机号(可选)。每个部分间以“-”号连接。邮箱地址格式:由字母、数字以及_%+-符号组成的用户名,@符号以及.后的域名,域名由2-4个字母和数字集合组成。根据上述模式可编写对应的正则表达式。
python的模式匹配有一个简单固定的套路,import导入re包,regex = re.compile(''''''<正则表达式>'''''')。<模式匹配的内容列表> = regex.findall(<待搜索字符串>)。三步搞定。编写正则表达式时,在字符串前加r防止字符转义。将各个部分分组并换行以提高代码的可读性,此时需要将re.VERBOSE作为re.compile()函数的第二个参数传入来忽略表达式中的空白和换行。
三、运行结果
复制代码首部注释掉的文本,然后运行程序。结果如下:

前两行打印出了匹配内容的列表,之后以自定义的统一格式打印欲搜索的内容。程序运行结果正确。本文以一个小例子测试了python正则表达式提取文本特定内容的功能,之后想尝试利用python自动生成verilogHDL中module的例化模板。
参考文献:
1 ExASIC https://mp.weixin.qq.com/s/qhG9f0WTzUruHgzgldEHSQ
原文出处:https://www.cnblogs.com/moluoqishi/p/10825221.html

Python学习笔记模式匹配与正则表达式之用正则表达式匹配更多模式
随笔记录方便自己和同路人查阅。
#------------------------------------------------我是可耻的分割线-------------------------------------------
既然你已知道用 Python 创建和查找正则表达式对象的基本步骤,就可以尝试一些更强大的模式匹配功能了。
#------------------------------------------------我是可耻的分割线-------------------------------------------
1、利用括号分组,示例代码:
#! python 3
# -*- coding:utf-8 -*-
# Autor: Li Rong Yang
import re#用 import re 导入正则表达式模块。
phoneNumregex = re.compile(r''(\d{3})-(\d{3}-\d{4})'')#使用括号进行分组。
text = phoneNumregex.search(''My number is 415-555-4242'')#向 Regex 对象的 search()方法传入想查找的字符串。它返回一个 Match 对象。
print(text.group(1))#调用 Match 对象的 group()方法,返回分组1的内容。运行结果:

2、用管道匹配多个分组,示例代码:
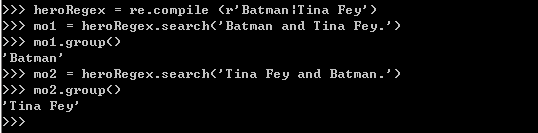
字符|称为“管道”。希望匹配许多表达式中的一个时,就可以使用它。例如,正则表达式 r''Batman|Tina Fey''将匹配''Batman''或''Tina Fey''。
如果 Batman 和 Tina Fey 都出现在被查找的字符串中,第一次出现的匹配文本,将作为 Match 对象返回。
3、用问号实现可选匹配,示例代码:

有时候,想匹配的模式是可选的。就是说,不论这段文本在不在,正则表达式都会认为匹配。字符?表明它前面的分组在这个模式中是可选的。
4、用星号匹配零次或多次,示例代码:
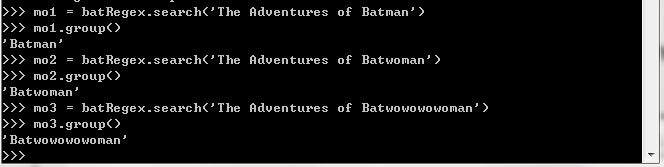
*(称为星号)意味着“匹配零次或多次”,即星号之前的分组,可以在文本中出Python 编程快速上手——让繁琐工作自动化现任意次。它可以
完全不存在,或一次又一次地重复。
对于''Batman'',正则表达式的(wo)*部分匹配 wo 的零个实例。对于''Batwoman'',(wo)*匹配 wo 的一个实例。对于''Batwowowowoman'',(wo)*匹配
wo 的 4 个实例。
如果需要匹配真正的星号字符,就在正则表达式的星号字符前加上倒斜杠,即\*。
5、用加好匹配一次或多次,示例代码:
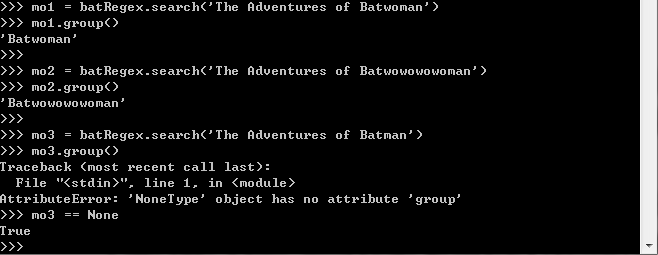
*意味着“匹配零次或多次”,+(加号)则意味着“匹配一次或多次”。星号不要求分组出现在匹配的字符串中,但加号不同,加号前面的分组必须“至少
出现一次”。这不是可选的。
正则表达式 Bat(wo)+man 不会匹配字符串''The Adventures of Batman'',因为加号要求 wo 至少出现一次。
如果需要匹配真正的加号字符,在加号前面加上倒斜杠实现转义:\+。
6、用花括号匹配特定次数,示例代码:
#! python 3
# -*- coding:utf-8 -*-
# Autor: Li Rong Yang
import re#用 import re 导入正则表达式模块。
phoneNumregex = re.compile(r''(\d{3})-(\d{3}-\d{4})'')#使用括号进行分组。
text = phoneNumregex.search(''My number is 415-555-4242'')#向 Regex 对象的 search()方法传入想查找的字符串。它返回一个 Match 对象。
print(text.group(1))#调用 Match 对象的 group()方法,返回分组1的内容。
phoneNumregex = re.compile(r''(\d\d\d)-(\d\d\d-\d\d\d\d)'')#使用括号进行分组。
text = phoneNumregex.search(''My number is 415-555-4242'')#向 Regex 对象的 search()方法传入想查找的字符串。它返回一个 Match 对象。
print(text.group(1))#调用 Match 对象的 group()方法,返回分组1的内容。运行结果:

根据结果可以看出,两段代码效果完全一致,花括号只是匹配相同内容的次数。
匹配的问题")
python正则表达式(?=)匹配的问题
#!/usr/local/easyops/python/bin/python#-*- coding: utf-8 -*-
import re
string = "/usr/local/bin"
pattern = re.compile(r"\S*(?=/)(.*)$")
list1 = pattern.findall(string)
print list1
结果list1[0]的结果是''/bin'',为什么不是''bin''呢,我认为结果应该是bin,因为我匹配的是/后的bin呀
我们今天的关于Python正则表达式可过滤与模式匹配的字符串列表和python正则过滤掉英文和数字的分享已经告一段落,感谢您的关注,如果您想了解更多关于python – 正则表达式匹配字符串上的正则表达式匹配返回无、python中正则表达式与模式匹配、Python学习笔记模式匹配与正则表达式之用正则表达式匹配更多模式、python正则表达式(?=)匹配的问题的相关信息,请在本站查询。
本文标签:




