对于如何将NumPy中的数组归一化为单位向量?感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍numpy归一化数组,并为您提供关于Keras中的组归一化和权重标准化、numpy中的数字求和数组、
对于如何将NumPy中的数组归一化为单位向量?感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍numpy 归一化数组,并为您提供关于Keras 中的组归一化和权重标准化、numpy中的数字求和数组、numpy实现数组(ndarray)归一化、NumPy数据的归一化的有用信息。
本文目录一览:")
如何将NumPy中的数组归一化为单位向量?(numpy 归一化数组)
我想将NumPy数组转换为单位向量。更具体地说,我正在寻找此功能的等效版本
def normalize(v):
norm = np.linalg.norm(v)
if norm == 0:
return v
return v / norm
skearn或中有类似的东西numpy吗?
此函数在v向量为0的情况下起作用。

Keras 中的组归一化和权重标准化
在我看来,将 ws_reg 函数传递给 kernel_regularizer 中的 Conv2D 是执行 WeightStandartization 的错误方式。
根据 TF 和 Keras,kernel_regularizer 的 docs 输出被添加到 损失,而不是应用于内核。正确的方法看起来像这样:
class WSConv2D(tf.keras.layers.Conv2D):
def __init__(self,*args,**kwargs):
super(WSConv2D,self).__init__(kernel_initializer="he_normal",**kwargs)
def standardize_weight(self,weight,eps):
mean = tf.math.reduce_mean(weight,axis=(0,1,2),keepdims=True)
var = tf.math.reduce_variance(weight,keepdims=True)
fan_in = np.prod(weight.shape[:-1])
gain = self.add_weight(
name="gain",shape=(weight.shape[-1],),initializer="ones",trainable=True,dtype=self.dtype,)
scale = (
tf.math.rsqrt(
tf.math.maximum(var * fan_in,tf.convert_to_tensor(eps,dtype=self.dtype))
)
* gain
)
return weight * scale - (mean * scale)
def call(self,inputs,eps=1e-4):
self.kernel.assign(self.standardize_weight(self.kernel,eps))
return super().call(inputs)

numpy中的数字求和数组
假设我有一个numpy数组,例如:[1,2,3,4,5,6]和另一个数组:[0,0,1,2,2,1]我想按组对第一个数组中的项求和(第二个数组)并按组号顺序获得n个组的结果(在这种情况下,结果将为[3,9,9])。我该如何在numpy中执行此操作?
答案1
小编典典有多种方法可以做到这一点,但这是一种方法:
import numpy as npdata = np.arange(1, 7)groups = np.array([0,0,1,2,2,1])unique_groups = np.unique(groups)sums = []for group in unique_groups: sums.append(data[groups == group].sum())您 可以对 事物 进行
矢量化处理,以便根本没有for循环,但是我建议不要这样做。它变得不可读,并且将需要几个2D临时数组,如果您有大量数据,则可能需要大量内存。
编辑:这是您可以完全向量化的一种方法。请记住,这可能(并且可能会)比上述版本慢。(也许有更好的方法将其向量化,但是已经晚了,我很累,所以这只是浮现在脑海的第一件事……)
但是,请记住,这是一个不好的例子…在上述循环中,您的确在速度和可读性方面都更好。
import numpy as npdata = np.arange(1, 7)groups = np.array([0,0,1,2,2,1])unique_groups = np.unique(groups)# Forgive the bad naming here...# I can''t think of more descriptive variable names at the moment...x, y = np.meshgrid(groups, unique_groups)data_stack = np.tile(data, (unique_groups.size, 1))data_in_group = np.zeros_like(data_stack)data_in_group[x==y] = data_stack[x==y]sums = data_in_group.sum(axis=1)归一化")
numpy实现数组(ndarray)归一化
numpy是python的一个数值计算库。功能很强大,但是遗憾的是,它竟然不能对它自己最常用的数据结构--数组(ndarray)进行归一化操作。既然如此,那我自己来写一个异化函数。使用的是numpy的frompyfunc函数实现。
ufunc是universal function的缩写,它是一种能对数组的每个元素进行操作的函数。NumPy内置的许多ufunc函数都是在C语言级别实现的,因此它们的计算速度非常快。过组合标准的ufunc函数的调用,可以实现各种算式的数组计算。不过有些时候这种算式不易编写,而针对每个元素的计算函数却很容易用Python实现,这时可以用frompyfunc函数将一个计算单个元素的函数转换成ufunc函数。这样就可以方便地用所产生的ufunc函数对数组进行计算了。
注意:frompyfunc得到的结果是一个ufunc object ndarray,要使用的话,需要用astype函数转换为其他类型(例如float类型)。
参考:http://blog.csdn.net/alvine008/article/details/35988395
一、环境
操作系统:windows 8.1 64bit专业版
Python版本:2.7.9 32bit
numpy版本:1.9.2
二、实现
1. 将ndarray实现归一化
将数组data归一化到[0,1]。
data:(类型ndarray)
[ [0 1 2]
[3 4 5] ]
得到结果:
[ [ 0. 0.2 0.4]
[ 0.6 0.8 1. ] ]
代码:
from __future__ import division
import numpy as np
data = np.arange(6).reshape(2,3)
print(data)
# normalize ndarray
def normalize_func(minVal, maxVal, newMinValue=0, newMaxValue=1 ):
def normalizeFunc(x):
r=(x-minVal)*newMaxValue/(maxVal-minVal) + newMinValue
return r
return np.frompyfunc(normalizeFunc,1,1)
minVal = np.amin(data)
maxVal = np.amax(data)
outufuncXArray = normalize_func(minVal,maxVal,0,1)(data) #the result is a ufunc object
dataXArray = outufuncXArray.astype(float) # cast ufunc object ndarray to float ndarray
print(dataXArray)注意到上面的代码中有一行from __future__ import division,这是因为python 2.x系列的除法问题。
在python 2.x中,如下:
1/2 结果:0
1.0/2 结果:0.5
在Python 3.x中,如下:
1/2 结果:0.5
1//2 结果:0
也就是:在Python 3.x中,“/”运算符结果会保留小数,而“//”是取整。为了使得Python 2.x系列的代码能够兼容3.x系列,加入from __future__ import division,这样,在2.x系列中,“/”的运算结果也会带有小数。
2. 将字典形式的数组进行归一化
上面的ndarray中,每一个元素都是一个数字。这里,每一个元素都是一个字典。
dictData:
[
{1: 61.31441116333008, 2: 2599.13134765625, 3: 82.65876007080078, 4: 0.06607530266046524, 5: 9.092870712280273, 6: 28.75792694091797},
{1: 57.24428939819336, 2: 2597.411865234375, 3: 76.23033142089844, 4: -0.13408033549785614, 5: 9.330583572387695, 6: 27.760543823242188}
]
结果:
[
{1: 1.0, 2: 1.0, 3: 1.0, 4: 1.0, 5: 0.97452325910129634, 6: 1.0}
{1: 0.93361883955315694, 2: 0.99933843958158342, 3: 0.92222931187939283, 4: 0.0, 5: 1.0, 6: 0.96531797581498602}
]
代码:
from __future__ import division
import numpy as np
def normalizeByArray(featureNum, minmaxArray, newMinValue=0, newMaxValue=1 ):
def normalizeFunc(x):
r = {}
for i in range(featureNum):
val = ( x[i+1] - minmaxArray[i,0] ) * newMaxValue / (minmaxArray[i,1] - minmaxArray[i,0] ) + newMinValue
r[i+1] = val
return r
return np.frompyfunc(normalizeFunc,1,1)
dictData = np.array([
{1: 61.31441116333008, 2: 2599.13134765625, 3: 82.65876007080078, 4: 0.06607530266046524, 5: 9.092870712280273, 6: 28.75792694091797},
{1: 57.24428939819336, 2: 2597.411865234375, 3: 76.23033142089844, 4: -0.13408033549785614, 5: 9.330583572387695, 6: 27.760543823242188}
])
firstEle = dictData[0]
featureNum = len(firstEle) # here we have 6 feature
minmaxValues = np.zeros((featureNum,2))
for xDict in dictData:
for i in range(featureNum):
if xDict[i+1]<minmaxValues[i,0]:
minmaxValues[i,0] = xDict[i+1]
elif xDict[i+1] > minmaxValues[i,1]:
minmaxValues[i,1] = xDict[i+1]
outDictufuncXArray = normalizeByArray(featureNum,minmaxValues,0,1)(dictData) #the result is a ufunc object ndarray
dictDataXArray = outDictufuncXArray.astype(dict) # cast ufunc object ndarray to dict ndarray
print(dictDataXArray)
NumPy数据的归一化
数据的归一化
首先我们来看看归一化的概念:
数据的标准化(normalization)和归一化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上。
目前数据标准化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的标准化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据标准化方法的选择上,还没有通用的法则可以遵循。
归一化的目标
1 把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
2 把有量纲表达式变为无量纲表达式
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。 比如,复数阻抗可以归一化书写:Z = R + jωL = R(1 + jωL/R) ,复数部分变成了纯数量了,没有量纲。
另外,微波之中也就是电路分析、信号系统、电磁波传输等,有很多运算都可以如此处理,既保证了运算的便捷,又能凸现出物理量的本质含义。
归一化后有两个好处
1. 提升模型的收敛速度
如下图,x1的取值为0-2000,而x2的取值为1-5,假如只有这两个特征,对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢,相比之下,右图的迭代就会很快(理解:也就是步长走多走少方向总是对的,不会走偏)
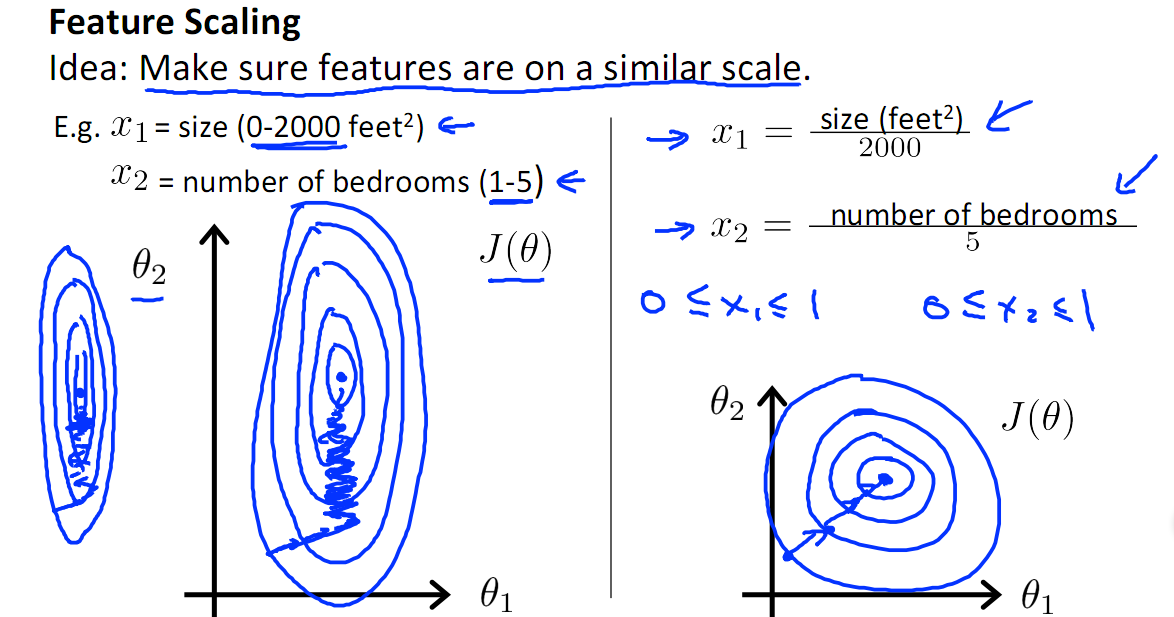
2.提升模型的精度
归一化的另一好处是提高精度,这在涉及到一些距离计算的算法时效果显著,比如算法要计算欧氏距离,上图中x2的取值范围比较小,涉及到距离计算时其对结果的影响远比x1带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同。
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。
从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。

现在我们再来看看基础的NumPy代码是如何实现的:
>>> x=np.random.random((10,3))
>>> x
array([[0.44951388, 0.58974524, 0.43980589],
[0.3082853 , 0.71042825, 0.02617535],
[0.10836115, 0.66774964, 0.85824697],
[0.01442332, 0.76459011, 0.75151452],
[0.64054078, 0.02121539, 0.87271819],
[0.75971598, 0.4268253 , 0.66039724],
[0.11865255, 0.14679259, 0.53782096],
[0.85085254, 0.26284603, 0.00246512],
[0.41957758, 0.96842006, 0.65555725],
[0.70227785, 0.78120928, 0.54771033]])
>>> x.mean(0)
array([0.43722009, 0.53398219, 0.53524118])
>>> xc=x-x.mean(0)
>>> xc
array([[ 0.01229379, 0.05576305, -0.0954353 ],
[-0.1289348 , 0.17644606, -0.50906583],
[-0.32885894, 0.13376745, 0.32300579],
[-0.42279677, 0.23060792, 0.21627333],
[ 0.20332068, -0.5127668 , 0.33747701],
[ 0.32249589, -0.10715689, 0.12515606],
[-0.31856754, -0.3871896 , 0.00257978],
[ 0.41363245, -0.27113616, -0.53277606],
[-0.01764252, 0.43443787, 0.12031607],
[ 0.26505776, 0.24722709, 0.01246915]])
>>> xc.mean(0)
array([ 5.55111512e-18, 3.33066907e-17, -4.44089210e-17])因为最后归一化的均值在0附近,因此在机器精度范围之内,该均值为0。
今天关于如何将NumPy中的数组归一化为单位向量?和numpy 归一化数组的介绍到此结束,谢谢您的阅读,有关Keras 中的组归一化和权重标准化、numpy中的数字求和数组、numpy实现数组(ndarray)归一化、NumPy数据的归一化等更多相关知识的信息可以在本站进行查询。
本文标签:




