针对如何使用Python在OpenCV中裁剪图像和pythonopencv裁剪图片这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展OpenCVPython:旋转图像而不裁剪边、opencv-
针对如何使用Python在OpenCV中裁剪图像和python opencv裁剪图片这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展OpenCV Python:旋转图像而不裁剪边、opencv- python:如何从车牌图像裁剪白色区域?、OpenCV-Python OpenCV中的K-Means聚类 | 五十八、opencv-python与c++ opencv中的一些区别和基础的知识等相关知识,希望可以帮助到你。
本文目录一览:- 如何使用Python在OpenCV中裁剪图像(python opencv裁剪图片)
- OpenCV Python:旋转图像而不裁剪边
- opencv- python:如何从车牌图像裁剪白色区域?
- OpenCV-Python OpenCV中的K-Means聚类 | 五十八
- opencv-python与c++ opencv中的一些区别和基础的知识
")
如何使用Python在OpenCV中裁剪图像(python opencv裁剪图片)
我如何像以前在PIL中一样使用OpenCV裁剪图像。
PIL的工作示例
im = Image.open(''0.png'').convert(''L'')im = im.crop((1, 1, 98, 33))im.save(''_0.png'')但是我如何在OpenCV上做到这一点?
这是我尝试的:
im = cv.imread(''0.png'', cv.CV_LOAD_IMAGE_GRAYSCALE)(thresh, im_bw) = cv.threshold(im, 128, 255, cv.THRESH_OTSU)im = cv.getRectSubPix(im_bw, (98, 33), (1, 1))cv.imshow(''Img'', im)cv.waitKey(0)但这是行不通的。
我认为我使用不正确getRectSubPix。如果是这种情况,请说明如何正确使用此功能。
答案1
小编典典非常简单。使用numpy切片。
import cv2img = cv2.imread("lenna.png")crop_img = img[y:y+h, x:x+w]cv2.imshow("cropped", crop_img)cv2.waitKey(0)
OpenCV Python:旋转图像而不裁剪边

我希望左边的图像像中间的图像一样旋转,而不是正确的图像.我如何使用Python和OpenCV来做到这一点.我查看了getRotationMatrix2D和warpAffine,但有关它的示例将我的图像转换为正确的图像.
解决方法

opencv- python:如何从车牌图像裁剪白色区域?
如何解决opencv- python:如何从车牌图像裁剪白色区域??
嘿,我想从图像中裁剪出白色区域,并在屏幕上显示用白色区域书写的字符。这是我的代码
import cv2
from PyTesseract import PyTesseract
import imutils
# Read input image
img = cv2.imread(r''111.jpg'')
hsv = cv2.cvtColor(img,cv2.COLOR_BGR2HSV)
s = hsv[:,:,2]#saturation
cv2.imshow("HSV Image",hsv)#hsv
cv2.waitKey(0)
cv2.imshow("Saturated Image",s)
cv2.waitKey(0)
ret,thresh = cv2.threshold(s,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU) #threshold
cv2.imshow("threshold Image",thresh)
cv2.waitKey(0)
cnts = cv2.findContours(thresh,cv2.RETR_EXTERNAL,cv2.CHAIN_APPROX_NONE)#contors find
cnts = imutils.grab_contours(cnts)
# print(cnts)
c = max(cnts,key=cv2.contourArea)
cv2.drawContours(img,cnts,-1,(255,0),2)
x,y,w,h = cv2.boundingRect(c)
out = img[y:y+h,x:x+w,:].copy()
# print(out)
cv2.imshow(''crop'',out)
cv2.imwrite(''tryv.jpg'',out)
PyTesseract.tesseract_cmd = r''C:\Users\HP\AppData\Local\Tesseract-OCR\tesseract.exe''
from PIL import Image as i
config = (''-l eng --oem 3 --psm 11'')
print(PyTesseract.image_to_string(''tryv.jpg'',config = config))
cv2.waitKey(0)
这是图片 ImageOfNumberPlate
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

OpenCV-Python OpenCV中的K-Means聚类 | 五十八
目标
- 了解如何在OpenCV中使用cv.kmeans()函数进行数据聚类
理解参数
输入参数
-
sample:它应该是np.float32数据类型,并且每个功能都应该放在单个列中。
-
nclusters(K):结束条件所需的簇数
-
criteria:这是迭代终止条件。满足此条件后,算法迭代将停止。实际上,它应该是3个参数的元组。它们是
(type,max_iter,epsilon): a. 终止条件的类型。它具有3个标志,如下所示:- cv.TERM_CRITERIA_EPS-如果达到指定的精度epsilon,则停止算法迭代。
- cv.TERM_CRITERIA_MAX_ITER-在指定的迭代次数max_iter之后停止算法。
- cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER-当满足上述任何条件时,停止迭代。
b. max_iter-一个整数,指定最大迭代次数。 c. epsilon-要求的精度
-
attempts:该标志用于指定使用不同的初始标签执行算法的次数。该算法返回产生最佳紧密度的标签。该紧凑性作为输出返回。
-
flags:此标志用于指定初始中心的获取方式。通常,为此使用两个标志:cv.KMEANS_PP_CENTERS和cv.KMEANS_RANDOM_CENTERS。
输出参数
- 紧凑度:它是每个点到其相应中心的平方距离的总和。
- 标签:这是标签数组(与上一篇文章中的“代码”相同),其中每个元素标记为“0”,“ 1” .....
- 中心:这是群集中心的阵列。 现在,我们将通过三个示例了解如何应用K-Means算法。
1. 单特征数据
考虑一下,你有一组仅具有一个特征(即一维)的数据。例如,我们可以解决我们的T恤问题,你只用身高来决定T恤的尺寸。因此,我们首先创建数据并将其绘制在Matplotlib中
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
x = np.random.randint(25,100,25)
y = np.random.randint(175,255,25)
z = np.hstack((x,y))
z = z.reshape((50,1))
z = np.float32(z)
plt.hist(z,256,[0,256]),plt.show()
因此,我们有了“ z”,它是一个大小为50的数组,值的范围是0到255。我将“z”重塑为列向量。 如果存在多个功能,它将更加有用。然后我制作了np.float32类型的数据。 我们得到以下图像:

现在我们应用KMeans函数。在此之前,我们需要指定标准。我的标准是,每当运行10次算法迭代或达到epsilon = 1.0的精度时,就停止算法并返回答案。
# 定义终止标准 = ( type, max_iter = 10 , epsilon = 1.0 )
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
# 设置标志
flags = cv.KMEANS_RANDOM_CENTERS
# 应用K均值
compactness,labels,centers = cv.kmeans(z,2,None,criteria,10,flags)
这为我们提供了紧凑性,标签和中心。在这种情况下,我得到的中心分别为60和207。标签的大小将与测试数据的大小相同,其中每个数据的质心都将标记为“ 0”,“ 1”,“ 2”等。现在,我们根据标签将数据分为不同的群集。
A = z[labels==0]
B = z[labels==1]
现在我们以红色绘制A,以蓝色绘制B,以黄色绘制其质心。
# 现在绘制用红色''A'',用蓝色绘制''B'',用黄色绘制中心
plt.hist(A,256,[0,256],color = ''r'')
plt.hist(B,256,[0,256],color = ''b'')
plt.hist(centers,32,[0,256],color = ''y'')
plt.show()
得到了以下结果: 
2. 多特征数据
在前面的示例中,我们仅考虑了T恤问题的身高。在这里,我们将同时考虑身高和体重,即两个特征。 请记住,在以前的情况下,我们将数据制作为单个列向量。每个特征排列在一列中,而每一行对应于一个输入测试样本。 例如,在这种情况下,我们设置了一个大小为50x2的测试数据,即50人的身高和体重。第一列对应于全部50个人的身高,第二列对应于他们的体重。第一行包含两个元素,其中第一个是第一人称的身高,第二个是他的体重。类似地,剩余的行对应于其他人的身高和体重。查看下面的图片:
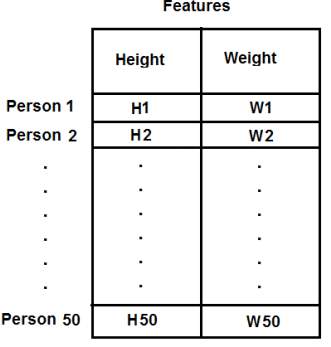
现在,我直接转到代码:
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
X = np.random.randint(25,50,(25,2))
Y = np.random.randint(60,85,(25,2))
Z = np.vstack((X,Y))
# 将数据转换未 np.float32
Z = np.float32(Z)
# 定义停止标准,应用K均值
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret,label,center=cv.kmeans(Z,2,None,criteria,10,cv.KMEANS_RANDOM_CENTERS)
# 现在分离数据, Note the flatten()
A = Z[label.ravel()==0]
B = Z[label.ravel()==1]
# 绘制数据
plt.scatter(A[:,0],A[:,1])
plt.scatter(B[:,0],B[:,1],c = ''r'')
plt.scatter(center[:,0],center[:,1],s = 80,c = ''y'', marker = ''s'')
plt.xlabel(''Height''),plt.ylabel(''Weight'')
plt.show()
我们得到如下结果: 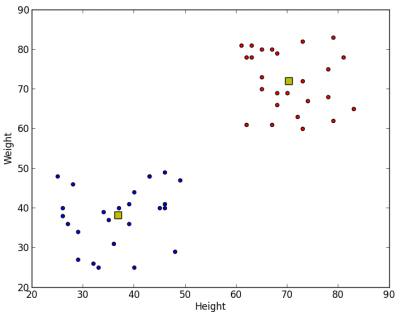
3.颜色量化
颜色量化是减少图像中颜色数量的过程。这样做的原因之一是减少内存。有时,某些设备可能会受到限制,因此只能产生有限数量的颜色。同样在那些情况下,执行颜色量化。在这里,我们使用k均值聚类进行颜色量化。
这里没有新内容要解释。有3个特征,例如R,G,B。因此,我们需要将图像重塑为Mx3大小的数组(M是图像中的像素数)。在聚类之后,我们将质心值(也是R,G,B)应用于所有像素,以使生成的图像具有指定数量的颜色。再一次,我们需要将其重塑为原始图像的形状。下面是代码:
import numpy as np
import cv2 as cv
img = cv.imread(''home.jpg'')
Z = img.reshape((-1,3))
# 将数据转化为np.float32
Z = np.float32(Z)
# 定义终止标准 聚类数并应用k均值
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 10, 1.0)
K = 8
ret,label,center=cv.kmeans(Z,K,None,criteria,10,cv.KMEANS_RANDOM_CENTERS)
# 现在将数据转化为uint8, 并绘制原图像
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((img.shape))
cv.imshow(''res2'',res2)
cv.waitKey(0)
cv.destroyAllWindows()
我们可以看的K=8的结果

欢迎关注磐创AI博客站: http://panchuang.net/
OpenCV中文官方文档: http://woshicver.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/

opencv-python与c++ opencv中的一些区别和基础的知识
使用opencv-python一段时间了,因为之前没有大量接触过c++下的opencv,在网上看c++的一些程序想改成python遇到了不少坑,正好在这里总结一下。
-
1.opencv 中x,y,height, width,rows,cols 的关系(转自http://blog.csdn.net/ikerpeng/article/details/41846259)
opencv中图像的x,y 坐标以及 height, width,rows,cols 他们的关系经常混淆。
rows 其实就是行,一行一行也就是y 啦。height高度也就是y啦。
cols 也就是列,一列一列也就是x啦。width宽度也就是x啦。
-
2.补充(以下均为原创):
- opencv python中的rows cols分别为img.shape[0](height)和img.shape[1](width)
- opencv c++中的图像对象访问像素可使用.at :cv::mat的成员函数: .at(int y, int x),可以用来存取图像中对应坐标为(x,y)的元素坐标。但是在使用它时要注意,在编译期必须要已知图像的数据类型.但在opencv-python中访问像素可直接使用例如img[x][y] 的方法进行实现
原因:和opencv不同,目前opencv-python中的数组均为numpy array形式。
-
3.函数上的应用的不同处
在opencv-python中,有很多函数的应用方法都与opencv中不同,下面简单的分析一下最不同的地方
1)python中使用cv2.方法名或变量名来调用方法/变量
2)对于具有同样作用的函数的不同调用方法,例如
//c++
cvtColor(srcImg, binaryImg, COLOR_BGR2GRAY);
#python
binaryImg = cv2.cvtColor(srcImg,cv2.COLOR_BGR2GRAY)当然对于每个具体的函数的具体用法,可以自行上网搜索
3)python中对于变量的类型是不需要声明的,所以将c++中代码修改为python时需要注意很多(缩进虽然很便于查看,但是还是感觉写{}的感觉很爽233)
4)python中函数参数可以为array形式,所以c++ opencv中的很多类型都是不存在的,切记使用cv2.类型名()去使用,例如
//c++
circle(srcImg, Point(x, y), 3, Scalar(255, 0, 255), 2, 8, 0);#python
cv2.circle(srcImg, (x, y), 3, (255, 100, 255), 1, 8, 0)其他的小坑估计还很多,多Google吧。
关于如何使用Python在OpenCV中裁剪图像和python opencv裁剪图片的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于OpenCV Python:旋转图像而不裁剪边、opencv- python:如何从车牌图像裁剪白色区域?、OpenCV-Python OpenCV中的K-Means聚类 | 五十八、opencv-python与c++ opencv中的一些区别和基础的知识的相关知识,请在本站寻找。
本文标签:




