本篇文章给大家谈谈Openpyxl:只读模式,如何获取超链接,以及openpyxl可以读取xls文件吗的知识点,同时本文还将给你拓展13:openpyxl读写xlsx文件、25.xlrd、xlwt和o
本篇文章给大家谈谈Openpyxl:只读模式,如何获取超链接,以及openpyxl可以读取xls文件吗的知识点,同时本文还将给你拓展13: openpyxl 读写 xlsx 文件、25.xlrd、xlwt和openpyxl模块的比较和使用、openpyxl、Openpyxl 1.8.5:使用openpyxl读取在单元格中键入的公式的结果等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- Openpyxl:只读模式,如何获取超链接(openpyxl可以读取xls文件吗)
- 13: openpyxl 读写 xlsx 文件
- 25.xlrd、xlwt和openpyxl模块的比较和使用
- openpyxl
- Openpyxl 1.8.5:使用openpyxl读取在单元格中键入的公式的结果
")
Openpyxl:只读模式,如何获取超链接(openpyxl可以读取xls文件吗)
如何解决Openpyxl:只读模式,如何获取超链接?
在常规(非只读模式)中,我可以使用以下方法从单元格获取超链接:
if not sheet.cell(row=i_row,column=i_col).hyperlink == None:
print(cell.hyperlink.location)
但是当我以只读模式执行此操作时,出现错误(预期):
<class ''AttributeError''> ''ReadOnlyCell'' object has no attribute ''hyperlink''
有什么方法可以让我在只读模式下从单元格获取超链接?
我必须使用只读模式,因为我正在尝试解析工作簿中的辅助工作表(~200 行),其中主工作表是 ~100k 行,我不能一直花时间加载整个工作簿在处理之前。我的其余代码在只读模式下运行良好。
对可以解决类似问题的替代模块开放。如果没有 RO 模式,我的代码每个文件需要 4 秒,使用它需要 0.25 秒。
感谢您抽出宝贵时间。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

13: openpyxl 读写 xlsx 文件
1.1 openpyxl 基本使用
1、openpyxl 将 xlsx 读成 json 格式


#! /usr/bin/env python
# -*- coding: utf-8 -*-
# -*- coding: utf-8 -*-
import json
from openpyxl import load_workbook
def read_xlsx_to_json(file_home):
wb = load_workbook(filename= file_home)
sheet_ranges = wb[''Sheet1'']
ws = wb[''Sheet1'']
rows = ws.rows #获取表格所有行和列,两者都是可迭代的
thead = [col.value for col in rows.next()] # 表格中第一行作为key
data = []
for row in rows:
line = [col.value for col in row]
tmp_dic = {}
for index, val in enumerate(thead):
tmp_dic[val] = line[index]
data.append(tmp_dic)
return json.dumps(data, ensure_ascii=False,indent=4)
# print read_xlsx_to_json(''dd.xlsx'')
''''''
[
{
"员工编号": null,
"部门名称": "HLT集团",
"手机号": 1393999934,
"角色": null,
"直属上级": null,
"职位": "CEO",
"企业微信唯一标识": null,
"相关部门": null,
"姓名": "王五",
"邮箱": "zhangsan@qq.com",
"职能": null,
"性别": "男"
},
{
"员工编号": null,
"部门名称": "政府事业部",
"手机号": 61616116161616,
"角色": null,
"直属上级": "王五",
"职位": "首席运营官",
"企业微信唯一标识": null,
"相关部门": null,
"姓名": "李四",
"邮箱": "lisi@qq.com",
"职能": null,
"性别": "女"
}
]
''''''2、openpyxl 创建一个 xlsx 文件


#! /usr/bin/env python
# -*- coding: utf-8 -*-
import json
from openpyxl import Workbook
# 创建 一个 xlsx 文件
def create_xlsx(data_list):
wb = Workbook() # 创建工作簿
ws = wb.active # 激活工作表
ws1 = wb.create_sheet("Mysheet") # 创建mysheet表
ws.title = "New Title" # 表明改为New Title
ws.sheet_properties.tabColor = "1072BA" # 颜色
for row_index, row in enumerate(data_list):
thead_list = data_list[0] # [''id'', ''name'', ''sex'', ''age'']
row_index += 1 # excel中 行是从 1 开始计算的
for column_index, thead in enumerate(thead_list):
column_index += 1 # excel中 行是从 1 开始计算的
if row_index == 1: #第一步: 填充第一行数据,表头(id name sex age)
d = ws.cell(row=1, column=column_index, value=thead)
else: #第二步: 新建表中数据
d = ws.cell(row=row_index, column=column_index, value=row[column_index-1])
wb.save(''test.xlsx'')#保存
data_list = [
[''id'',''name'',''sex'',''age''],
[''1'',''张三'',''男'',''18''],
[''2'',''李四'',''男'',''19''],
[''3'',''王五'',''女'',''20''],
]
create_xlsx(data_list) 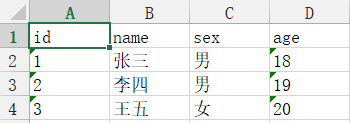
3、openpyxl 修改 第十列的值


#! /usr/bin/env python
# -*- coding: utf-8 -*-
import json
from openpyxl import load_workbook
# 将表中第十行的值统一修改为 ‘new val’
def change_xlsx(file_home):
wb = load_workbook(filename= file_home)
sheet_ranges = wb[''Sheet1'']
ws = wb[''Sheet1'']
rows = ws.rows #获取表格所有行和列,两者都是可迭代的
for row, line in enumerate(rows):
if row != 0:
row += 1
ws.cell(row=row, column=10).value = ''new val''
wb.save(''f5.xlsx'')
change_xlsx(''dd.xlsx'')

#! /usr/bin/env python
# -*- coding: utf-8 -*-
from openpyxl import load_workbook
file_home = ''f5.xlsx''
wb = load_workbook(filename= file_home)
sheet_ranges = wb[''Sheet1'']
ws = wb[''Sheet1'']
# 将第二行,第二列的值修改成 ''修改后的值''
ws.cell(row=2, column=2).value = ''修改后的值''
wb.save(''f6.xlsx'')4、在 xlsx 文件后面添加新的内容(插入时按照数据顺序)


#! /usr/bin/env python
# -*- coding: utf-8 -*-
import json, sys
from openpyxl import load_workbook
# 在xlsx文件最后添加新的数据,会按照顺序插入到xlsx文件对应位置
def append_xlsx(file_home, data_list):
''''''
:param file_home: xlsx文件路径
:param data_list: 插入的数据
''''''
wb = load_workbook(filename= file_home)
sheet_ranges = wb[''Sheet1'']
ws = wb[''Sheet1'']
print data_list
ws.append(data_list)
wb.save(''f7.xlsx'')
data_list = [''邮箱'', '''', ''手机号'', ''性别'']
append_xlsx(''dd.xlsx'',data_list)

25.xlrd、xlwt和openpyxl模块的比较和使用
xlrd、xlwt和openpyxl模块的比较:
1)xlrd:对xls、xlsx、xlsm文件进行读操作–读操作效率较高,推荐
2)xlwt:对xls文件进行写操作–写操作效率较高,但是不能执行xlsx文件
3)openpyxl:对xlsx、xlsm文件进行读、写操作–xlsx写操作推荐使用
一、xlrd:对xls、xlsx文件进行读操作
1.获取工作簿对象:xlrd.open_workbook()
workBook = xlrd.open_workbook(filemname):打开Excel文件读取数据
注:filemname为文件名以及路径,如果路径或者文件名有中文给前面加一个r表示原生字符。
import xlrd
filename=r''D:\360极速浏览器下载\文件阅读记录表.xls''
workBook=xlrd.open_workbook(filename)2.获取工作表(sheet)对象
1)workBook.sheet_names():获取所有sheet页的名字,返回一个列表
2)sheetName = workBook.sheet_by_name(‘sheet1’):根据sheet页的名字获取指定表名的表,返回的是一个对象
3)sheetName = workbook.sheet_by_index(0):根据sheet索引获取对应sheet表(索引是从0开始的),返回的是一个对象
3.获取sheet的名称:name
sheetName.name:获取sheet的名称
4.获取行数和列数:nrows、ncols
sheetName.nrows:获取表格的总行数
sheetName.ncols:获取表格的总列数
5.获取整行或整列的值(数组):row_values、col_values
rows = sheetName.row_values(0) # 获取第一行内容,返回一个列表
cols = sheetName.col_values(0) # 获取第一列内容,返回一个列表
6.获取指定单元格的值:cell(a,b).value、row(1)[0].value
sheetName.cell(1,0).value:获取第2行第一列的单元格数据
sheetName.row(1)[0].value:获取第2行第一列的单元格数据
7.获取单元格内容的数据类型:ctype
sheetName.cell(1,0).ctype
注:返回为代表数据类型的值,编码分别代表:ctype : 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 error
二、xlwt:对xls文件进行写操作
1.新建工作簿:xlwt.Workbook()
workBook = xlwt.Workbook() :新建工作簿
2.在工作簿中新建sheet页:add_sheet()
table = workBook .add_sheet(‘Over’,cell_overwrite_ok=True) # 如果对同一单元格重复操作会发生overwrite Exception,cell_overwrite_ok为可覆盖
sheet = workBook .add_sheet(sheet_name):新增sheet表
import xlwt
wb=xlwt.Workbook(encoding=''utf-8'') # 创建一个工作薄
sheet=wb.add_sheet(''文件阅读记录信息表'') # 创建一个工作表3.向表格中写入数据:write(i,j,value)
sheet.write(i,j,value) :向单元格(i,j)写入数据value
4.保存工作簿:save()
workBook.save(path)
三、openpyxl:对xlsx文件进行写操作
1.新建工作簿:openpyxl.Workbook()
workBook = openpyxl.Workbook() :新建工作簿
2.在工作簿中新建sheet页:create_sheet()
sheet = workBook .create_sheet(sheet_name):新增sheet表:sheet_name
3.向表格中写入数据:cell(i,j,value) --索引从1计数
sheet= workBook .active :获得当前活跃的工作页,默认为第一个工作页
sheet.cell(i,j,value) :向单元格(i,j)第i行第j列写入数据value
注意:行号和列号都从1开始计数,即(1,1)为第一行第一列
4.保存工作簿:save()
workBook .save(path)
四、openpyxl:对xlsx文件进行读操作
1.获取工作簿对象:openpyxl.load_workbook()
workBook = openpyxl.load_workbook(filemname):读取xlsx文件
注:filemname为文件名以及路径,如果路径或者文件名有中文给前面加一个r表示原生字符。
2.获取工作表(sheet)对象
1)workBook.get_sheet_names():获取所有sheet页的名字(所有工作表名)
2)sheetName = workBook.get_sheet_by_name(‘sheet1’):根据sheet页的名字获取指定表名的表
3)sheetName = workBook.worksheets[0]:根据sheet索引获取对应sheet表
3.获取sheet的名称:title
sheetName.title:获取sheet的名称
4.获取行数和列数:max_row、max_column
sheetName.max_row:获取表格的总行数
sheetName.max_column:获取表格的总列数
5.获取整行或整列的值(数组):rows[i]、columns[i]
rows = sheetName.rows:获取每一行内容,这是一个生成器,里面是每一行数据,每一行数据由一个元组类型包裹
cols = sheetName.columns :获取每一列内容,同上
sheetName.rows[0]:获取第一行内容–索引从0计数
sheetName.columns[0]:获取第一列内容–索引从0计数
6.获取指定单元格的值:cell(a,b).value–索引从1计数
sheetName[‘A1’].value:获取第1行第一(A)列的单元格数据
sheetName.cell(1,1).value:获取第1行第一列的单元格数据
注:此处的行数和列数都是从1开始计数的,而在xlrd中是由0开始计数的

openpyxl
参考连接:https://openpyxl.readthedocs.io/en/stable/
openpyxl是一个Python库,用于读取/写入Excel xlsx / xlsm / xltx / xltm文件
安装 pip install openpyxl
在文件中插入图片的文件(缩略图) 需要安装 PIL 模块 我在另一篇博客有提
写入的方式
wb = Workbook() 创建文件对象
ws = wb.active 获取第一个 sheet 对其名字以及单元格的格式都可以进行控制
单个单元格中写入数据(用处不大 可以用于修改数据)
ws[''A2'']=数字 字符串 时间
多个单元个写入 可使用列表进行写入
比如 : 要写入的数据为
file_data = [[''姓名'', ''性别'', ''写入时间'', ''得分'']
[''张三'', ''男'', ''2019-5.20'', ''90'']
[''李四'', ''女'', ''2019-5-20'', ''98'']
。。。]
from openpyxl import Workbook
def export_fract_excel(data: list, file_name):
wb = Workbook() # 创建文件
ws = wb.active # 创建 sheet
# 列表导入
for i in data:
ws.append(i)
# 拼接导出名 可以自行拼接 可选
name = ''''.join([random.choice(string.ascii_letters) for _ in range(2)])
name = ''{}_{}.xlsx''.format(name,file_name)
try:
Bir_path = os.path.join(DefaultConfig.PATH, ''Bir'')
if not os.path.exists(Bir_path):
os.mkdir(Bir_path)
file_name = os.path.join(Bir_path, name)
wb.save(file_name )
return file_name
except Exception as e:
file_name = ''''
return file_name
def make_excel(file_data, file_name):
now = datetime.now()
fn = export_fract_excel(file_data, file_name)
r = make_response(send_file(fn, as_attachment=True))
return r导出的数据格式

Openpyxl 1.8.5:使用openpyxl读取在单元格中键入的公式的结果
我在一张Excel工作表中打印一些公式:
wsOld.cell(row = 1, column = 1).value = "=B3=B4"但是我不能将其结果用于实现其他一些逻辑,例如:
if((wsOld.cell(row=1, column=1).value)=''true''): # copy the 1st row to another sheet即使当我尝试在命令行中打印结果时,我最终也会打印公式:
>>> print(wsOld.cell(row=1, column=1))>>> =B3=B4如何在单元格中而不是公式本身中获得公式的结果?
答案1
小编典典openpyxl支持公式或公式的值。您可以data_only在打开工作簿时使用该标志选择哪个。但是,openpyxl不会也不会计算公式的结果。有一些像pycel这样的库,据称可以做到这一点。
我们今天的关于Openpyxl:只读模式,如何获取超链接和openpyxl可以读取xls文件吗的分享就到这里,谢谢您的阅读,如果想了解更多关于13: openpyxl 读写 xlsx 文件、25.xlrd、xlwt和openpyxl模块的比较和使用、openpyxl、Openpyxl 1.8.5:使用openpyxl读取在单元格中键入的公式的结果的相关信息,可以在本站进行搜索。
本文标签:




