本文将分享Lookup()和Dictionary(Oflist())的区别的详细内容,并且还将对lookup和searchfor区别进行详尽解释,此外,我们还将为大家带来关于.netRedis分布式锁
本文将分享Lookup() 和 Dictionary(Of list()) 的区别的详细内容,并且还将对lookup和searchfor区别进行详尽解释,此外,我们还将为大家带来关于.net Redis分布式锁,Dictionary,ConcurrentDictionary 介绍、.Net数据结构:ArrayList、List、HashTable、Dictionary、SortedList、SortedDictionary——速度、内存以及何时使用它们?、C# ArrayList、HashSet、HashTable、List、Dictionary 的区别、C# ArrayList、HashSet、HashTable、List、Dictionary的区别详解的相关知识,希望对你有所帮助。
本文目录一览:- Lookup() 和 Dictionary(Of list()) 的区别(lookup和searchfor区别)
- .net Redis分布式锁,Dictionary,ConcurrentDictionary 介绍
- .Net数据结构:ArrayList、List、HashTable、Dictionary、SortedList、SortedDictionary——速度、内存以及何时使用它们?
- C# ArrayList、HashSet、HashTable、List、Dictionary 的区别
- C# ArrayList、HashSet、HashTable、List、Dictionary的区别详解
 和 Dictionary(Of list()) 的区别(lookup和searchfor区别)")
Lookup() 和 Dictionary(Of list()) 的区别(lookup和searchfor区别)
我试图围绕哪些数据结构最有效以及何时/何地使用哪些数据结构。
现在,可能是我只是对结构不够了解,但是ILookup(of key,...)a 与 a 有什么不同Dictionary(of key,list(of ...))?
另外,我想在ILookup哪里使用以及在程序速度/内存/数据访问等方面会更有效?

.net Redis分布式锁,Dictionary,ConcurrentDictionary 介绍
1、背景
在计算机世界里,对于锁大家并不陌生,在现代所有的语言中几乎都提供了语言级别锁的实现,为什么我们的程序有时候会这么依赖锁呢?这个问题还是要从计算机的发展说起,随着计算机硬件的不断升级,多核cpu,多线程,多通道等技术把计算机的计算速度大幅度提升,原来同一时间只能执行一条cpu指令的时代已经过去。随着多条cpu指令可以并行执行的原因,原来不曾出现的资源竞争随着出现,在程序中的体现就是随处可见的多线程环境。比如要更新数据库的一个信息,如果没有并发控制,多个线程同时操作的话,就会出现互相覆盖的现象发生。
锁要解决的就是资源竞争的问题,也就是要把执行的指令顺序化。
在互联网背景下,电商行业是普遍都是多线程执行,并发量大。比如下单秒杀抢购商品活动,属于高并发情况,库存的保证就尤其重要了,不能出现超卖现象。程序员所要做的事情就是需要单线程执行获取库存,再减库存操作,保证数据原子性。
在多台服务器中,锁就是重点。
2、应用
我们先来介绍下单线程下的情况,假设有个商品A,库存500件,假设每次购买1件,单价1元,这样就只有是500次下单时成功的,其他都不能下单。
2.1 Store商品存储-Dictionary
数据库不存在的情况下,用Dictionary来代替
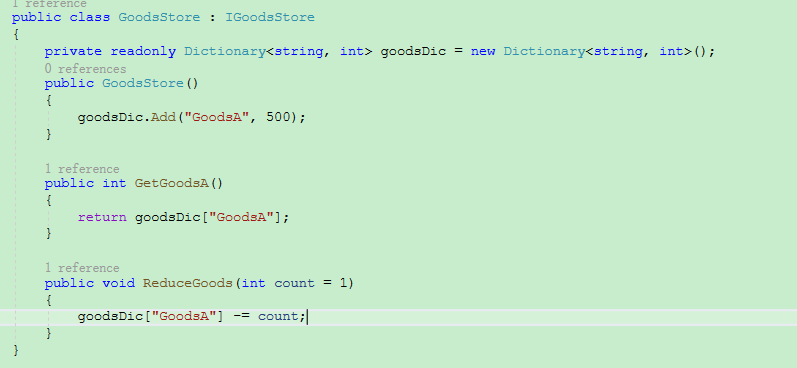
创建了Store后,主程序创建下单,单线程执行。

执行结果:
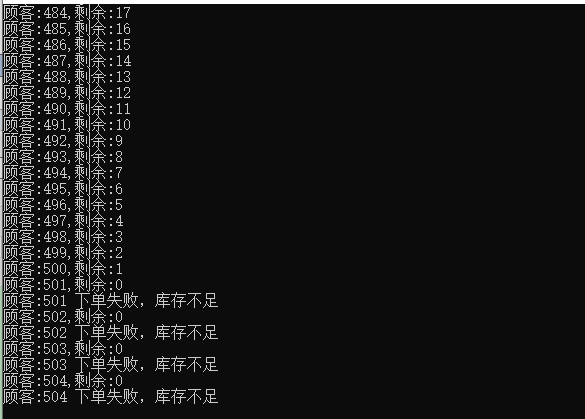
执行正常,4人不能下单。
改成多线程执行,直接出现超卖现象,其中用Task.Run 模拟多线程,其中Order(int i) i变量注意,不能直接填写i,异步中上下文不存在,因为主线程以及跑完了,再运行异步Task线程,这时变量已是最后一个被覆盖。
解决方案是重复赋值变量替换

结果:
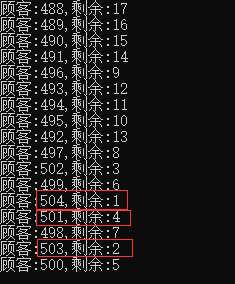
500多的人都买了。
解决方案:
2.1.1 lock 加锁
lock很明显影响性能。
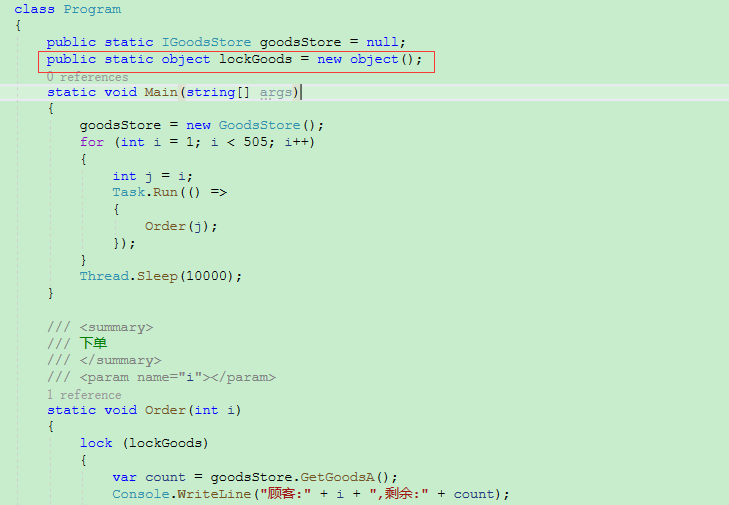

执行结果:

正常。
2.1.2 使用ConcurrentDictionary
ConcurrentDictionary 本身是线程安全的,源代码就是加了lock


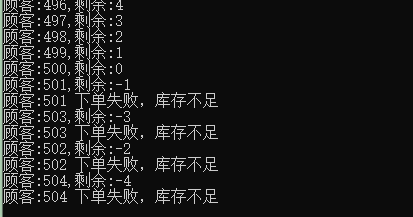
执行结果符合。
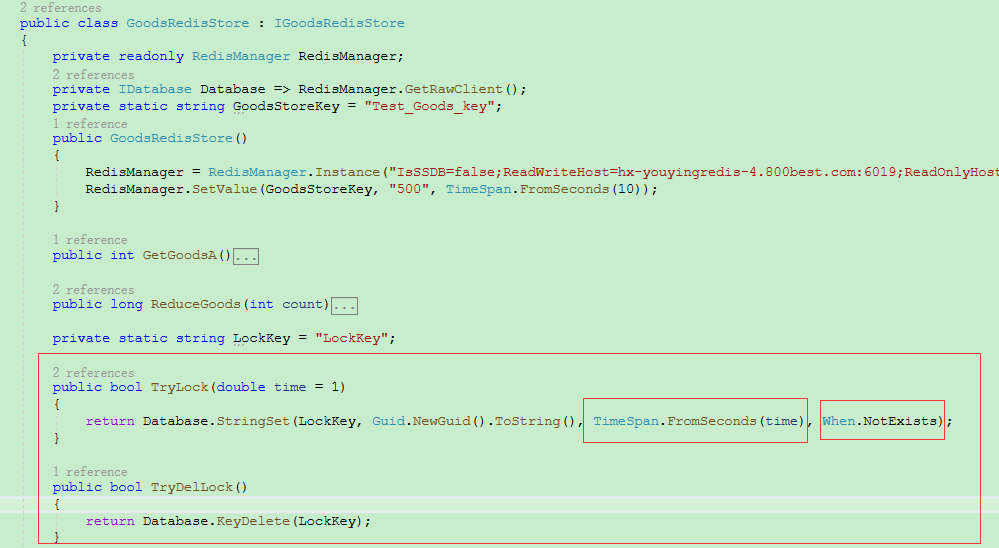
2.2 用Redis分布式锁
redis是单线程运行,所以适合。原理也很简单,运用redis以下指令
1、SETNX
SETNX key val:当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。
2、expire
expire key timeout:为key设置一个超时时间,单位为second,超过这个时间锁会自动释放,避免死锁。
3、delete
delete key:删除key
在使用Redis实现分布式锁的时候,主要就会使用到这三个命令。
原理如下:
1、先获取redis锁,设置一个随机字符串
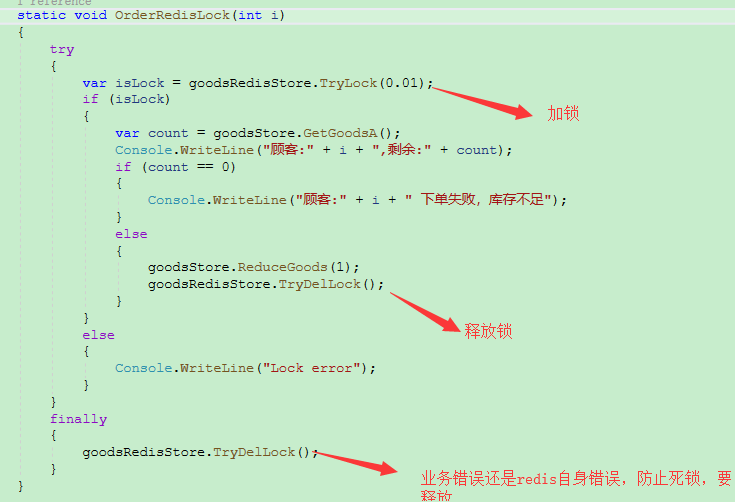
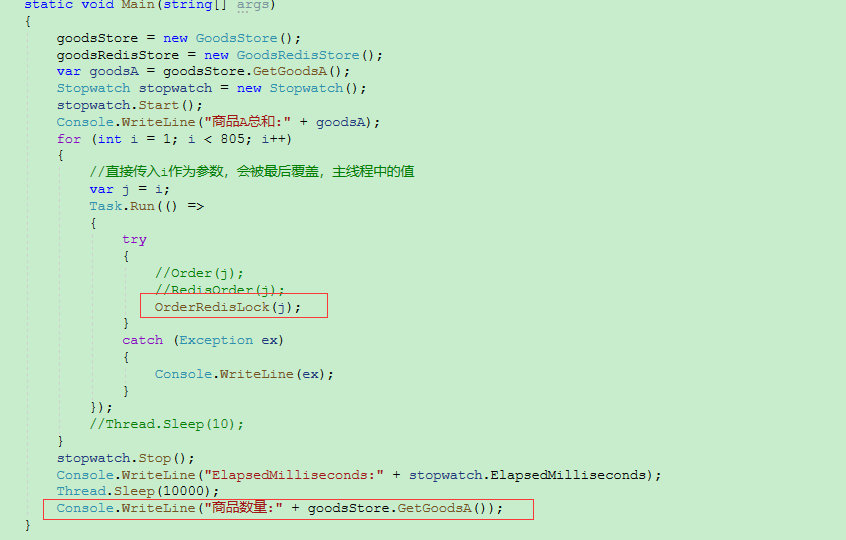
执行了805次,看下输出最后数量有没有小于0

结果显示0,正确,没超卖

.Net数据结构:ArrayList、List、HashTable、Dictionary、SortedList、SortedDictionary——速度、内存以及何时使用它们?
.NET 有很多复杂的数据结构。不幸的是,其中一些非常相似,我并不总是确定什么时候使用一个,什么时候使用另一个。我的大部分 C# 和 VB
书籍都在一定程度上谈到了它们,但它们从未真正深入任何真正的细节。
Array、ArrayList、List、Hashtable、Dictionary、SortedList 和 SortedDictionary 有什么区别?
哪些是可枚举的(IList – 可以执行“foreach”循环)?哪些使用键/值对(IDict)?
内存占用呢?插入速度?检索速度?
还有其他值得一提的数据结构吗?
我仍在寻找有关内存使用和速度的更多详细信息(Big-O 表示法)
答案1
小编典典在我的头顶上:
Array* - 代表一个老式的内存数组 - 有点像普通type[]数组的别名。可以列举。不能自动生长。我会假设非常快的插入和检索速度。ArrayList- 自动增长的数组。增加更多开销。可以枚举,可能比普通数组慢,但仍然相当快。这些在 .NET 中被大量使用List- 我的最爱之一 - 可以与泛型一起使用,因此您可以拥有一个强类型数组,例如List<string>. 除此之外,行为非常像ArrayListHashtable- 普通的旧哈希表。O(1) 到 O(n) 最坏的情况。可以枚举 value 和 keys 属性,并做 key/val 对Dictionary- 与上述相同,仅通过泛型进行强类型化,例如Dictionary<string, string>SortedList- 排序的通用列表。插入速度变慢,因为它必须弄清楚把东西放在哪里。可以枚举,在检索时可能相同,因为它不必求助,但删除会比普通的旧列表慢。
我倾向于一直使用List-Dictionary一旦你开始使用泛型强类型的它们,就很难回到标准的非泛型。
还有很多其他的数据结构——KeyValuePair你可以用它来做一些有趣的事情,还有一个SortedDictionary也很有用。

C# ArrayList、HashSet、HashTable、List、Dictionary 的区别
在 C# 中,数组由于是固定长度的,所以常常不能满足我们开发的需求。
由于这种限制不方便,所以出现了 ArrayList。
ArrayList、List<T>
ArrayList 是可变长数组,你可以将任意多的数据 Add 到 ArrayList 里面。其内部维护的数组,当长度不足时,会自动扩容为原来的两倍。
但是 ArrayList 也有一个缺点,就是存入 ArrayList 里面的数据都是 Object 类型的,所以如果将值类型存入和取出的时候会发生装箱、拆箱操作 (就是值类型与引用类型之间的转换),这个会影响程序性能。在.Net 2.0 泛型出现以后,就提供了 List<T>。
List<T> 是 ArrayList 的泛型版本,它不再需要装箱拆箱,直接取,直接用,它基本与 ArrayList 一致,不过在使用的时候要先设置好它的类型,而设置好类型之后,不是这种类型的数据,是不允许 Add 进去的。
就性能来说,如果要存进数组的只有一种数据,那么无疑 List<T> 是最优选择。
List<int> ListInt = new List<int>();如果一个变长数组,又要存 int,又要存 string。那么就只能用 ArrayList。
HashTable (哈希表)、Dictionary<T,T>
HashTable 是一种根据 key 查找非常快的键值数据结构,不能有重复 key,而且由于其特点,其长度总是一个素数,所以扩容后容量会比 2 倍大一点点,加载因子为 0.72f。
当要大量使用 key 来查找 value 的时候,HashTable 无疑是最有选择,HashTable 与 ArrayList 一样,是非泛型的,value 存进去是 object, 存取会发生装箱、拆箱,所以出现了 Dictionary<T,T>。
Dictionary<T,T> 是 HashTable 的泛型版本,存取同样快,但是不需要装箱和拆箱了。而且,其优化了算法,Hashtable 是 0.72,它的浪费容量少了很多。
Dictionary<string,Person> Dic = new Dictionary<string,Person>();HashSet<T>
HashSet<T> 类,算法,存储结构都与哈希表相同,主要是设计用来做高性能集运算的,例如对两个集合求交集、并集、差集等。集合中包含一组不重复出现且无特定顺序的元素。
Queue、Queue<T>
Queue 队列,Queue<T> 泛型队列,大学都学过,队列,先进先出,很有用。
Stack、Stack<T>
Stack 堆栈,先进后出。
SortedList、SortedList<TKey,TValue>
SortedList 集合中的数据是有序的。可以通过 key 来匹配数据,也可以通过 int 下标来获取数据。
添加操作比 ArrayList,Hashtable 略慢;查找、删除操作比 ArrayList 快,比 Hashtable 慢。
SortedDictionary<TKey,TValue>
SortedDictionary<TKey,TValue> 相比于 SortedList<TKey,TValue > 其性能优化了,SortedList<TKey,TValue > 其内部维护的是数组而 SortedDictionary<TKey,TValue > 内部维护的是红黑树 (平衡二叉树) 的一种,因此其占用的内存,性能都好于 SortedDictionary<TKey,TValue>。唯一差在不能用下标取值。
ListDictionary (单向链表),LinkedList<T>(双向链表)
List<T>,ArrayList,Hashtable 等容器类,其内部维护的是数组 Array 来,ListDictionary 和 LinkedList<T > 不用 Array,而是用链表的形式来保存。链表最大的好处就是节约内存空间。
ListDictionary 是单向链表。
LinkedList<T> 双向链表。双向链表的优势,可以插入到任意位置。
HybridDictionary
HybridDictionary 的类,充分利用了 Hashtable 查询效率高和 ListDictionary 占用内存空间少的优点,内置了 Hashtable 和 ListDictionary 两个容器,添加数据时内部逻辑如下:
当数据量小于 8 时,Hashtable 为 null,用 ListDictionary 保存数据。
当数据量大于 8 时,实例化 Hashtable,数据转移到 Hashtable 中,然后将 ListDictionary 置为 null。
BitArray
BitArray 这个东东是用于二进制运算,"或"、"非"、"与"、"异或非" 等这种操作,只能存 true 或 false;
应用场景
ArrayList,List<T>:变长数组;
HashTable,Dictionary<T,T>:频繁根据 key 查找 value;
HashSet<T>:集合运算;
Queue、Queue<T>:先进先出;
Stack、Stack<T>:堆栈,先进先出;
SortedList、SortedList<TKey,TValue>:哈希表,要通过下标,又要通过 key 取值时,可选用;
ListDictionary:单向链表,每次添加数据时都要遍历链表,数据量大时效率较低,数据量较大且插入频繁的情况下,不宜选用。
LinkedList<T>:双向链表;
HybridDictionary:未知数据量大小时,可用。
SortedDictionary<TKey,TValue>:SortedList<TKey,TValue > 的优化版,内部数组转平衡二叉树。
BitArray:二进制运算时可选用;
引用于 https://blog.csdn.net/wildlifeking/article/details/58605587

C# ArrayList、HashSet、HashTable、List、Dictionary的区别详解
在C#中,数组由于是固定长度的,所以常常不能满足我们开发的需求。
由于这种限制不方便,所以出现了ArrayList。
ArrayList、List<T>
ArrayList是可变长数组,你可以将任意多的数据Add到ArrayList里面。其内部维护的数组,当长度不足时,会自动扩容为原来的两倍。
但是ArrayList也有一个缺点,就是存入ArrayList里面的数据都是Object类型的,所以如果将值类型存入和取出的时候会发生装箱、拆箱操作(就是值类型与引用类型之间的转换),这个会影响程序性能。在.Net 2.0泛型出现以后,就提供了List<T>。
List<T>是ArrayList的泛型版本,它不再需要装箱拆箱,直接取,直接用,它基本与ArrayList一致,不过在使用的时候要先设置好它的类型,而设置好类型之后,不是这种类型的数据,是不允许Add进去的。
就性能来说,如果要存进数组的只有一种数据,那么无疑List<T>是最优选择。
List<int> ListInt = new List<int>();
如果一个变长数组,又要存int,又要存string。那么就只能用ArrayList。
HashTable(哈希表)、Dictionary<T,T>
HashTable是一种根据key查找非常快的键值数据结构,不能有重复key,而且由于其特点,其长度总是一个素数,所以扩容后容量会比2倍大一点点,加载因子为0.72f。
当要大量使用key来查找value的时候,HashTable无疑是最有选择,HashTable与ArrayList一样,是非泛型的,value存进去是object,存取会发生装箱、拆箱,所以出现了Dictionary<T,T>。
Dictionary<T,T>是HashTable的泛型版本,存取同样快,但是不需要装箱和拆箱了。而且,其优化了算法,Hashtable是0.72,它的浪费容量少了很多。
Dictionary<string,Person> Dic = new Dictionary<string,Person>();
HashSet<T>
HashSet<T>类,算法,存储结构都与哈希表相同,主要是设计用来做高性能集运算的,例如对两个集合求交集、并集、差集等。集合中包含一组不重复出现且无特定顺序的元素。
Queue、Queue<T>
Queue队列,Queue<T>泛型队列,大学都学过,队列,先进先出,很有用。
Stack、Stack<T>
Stack堆栈,先进后出。
SortedList、SortedList<TKey,TValue>
SortedList集合中的数据是有序的。可以通过key来匹配数据,也可以通过int下标来获取数据。
添加操作比ArrayList,Hashtable略慢;查找、删除操作比ArrayList快,比Hashtable慢。
SortedDictionary<TKey,TValue>
SortedDictionary<TKey,TValue>相比于SortedList<TKey,TValue>其性能优化了,SortedList<TKey,TValue>其内部维护的是数组而SortedDictionary<TKey,TValue>内部维护的是红黑树(平衡二叉树)的一种,因此其占用的内存,性能都好于SortedDictionary<TKey,TValue>。唯一差在不能用下标取值。
ListDictionary(单向链表),LinkedList<T>(双向链表)
List<T>,ArrayList,Hashtable等容器类,其内部维护的是数组Array来,ListDictionary和LinkedList<T>不用Array,而是用链表的形式来保存。链表最大的好处就是节约内存空间。
ListDictionary是单向链表。
LinkedList<T>双向链表。双向链表的优势,可以插入到任意位置。
HybridDictionary
HybridDictionary的类,充分利用了Hashtable查询效率高和ListDictionary占用内存空间少的优点,内置了Hashtable和ListDictionary两个容器,添加数据时内部逻辑如下:
当数据量小于8时,Hashtable为null,用ListDictionary保存数据。
当数据量大于8时,实例化Hashtable,数据转移到Hashtable中,然后将ListDictionary置为null。
BitArray
BitArray这个东东是用于二进制运算,"或"、"非"、"与"、"异或非"等这种操作,只能存true或false;
应用场景
ArrayList,List<T>:变长数组;
HashTable,Dictionary<T,T>:频繁根据key查找value;
HashSet<T>:集合运算;
Queue、Queue<T>:先进先出;
Stack、Stack<T>:堆栈,先进先出;
SortedList、SortedList<TKey,TValue>:哈希表,要通过下标,又要通过key取值时,可选用;
ListDictionary:单向链表,每次添加数据时都要遍历链表,数据量大时效率较低,数据量较大且插入频繁的情况下,不宜选用。
LinkedList<T>:双向链表;
HybridDictionary:未知数据量大小时,可用。
SortedDictionary<TKey,TValue>:SortedList<TKey,TValue>的优化版,内部数组转平衡二叉树。
BitArray:二进制运算时可选用;
以上就是本次介绍的全部知识点内容,感谢大家对的支持。
- 轻松学习C#的ArrayList类
- 的区别、共性与相互转换" target="_blank">详解c#中Array,ArrayList与List<T>的区别、共性与相互转换
- C#入门教程之集合ArrayList用法详解
- C#中数组、ArrayList、List、Dictionary的用法与区别浅析(存取数据)
- C# 中 Array和 ArrayList详解及区别
- C#中数组、ArrayList和List三者的区别详解
- C#中数组Array,ArrayList,泛型List详细对比
- C#中ArrayList 类的使用详解
我们今天的关于Lookup() 和 Dictionary(Of list()) 的区别和lookup和searchfor区别的分享就到这里,谢谢您的阅读,如果想了解更多关于.net Redis分布式锁,Dictionary,ConcurrentDictionary 介绍、.Net数据结构:ArrayList、List、HashTable、Dictionary、SortedList、SortedDictionary——速度、内存以及何时使用它们?、C# ArrayList、HashSet、HashTable、List、Dictionary 的区别、C# ArrayList、HashSet、HashTable、List、Dictionary的区别详解的相关信息,可以在本站进行搜索。
本文标签:




