如果您想了解DeepStream5.1pythonversion:kafka,无法打开共享库和kafkapython客户端的知识,那么本篇文章将是您的不二之选。我们将深入剖析DeepStream5.1
如果您想了解DeepStream5.1 pythonversion:kafka,无法打开共享库和kafka python客户端的知识,那么本篇文章将是您的不二之选。我们将深入剖析DeepStream5.1 pythonversion:kafka,无法打开共享库的各个方面,并为您解答kafka python客户端的疑在这篇文章中,我们将为您介绍DeepStream5.1 pythonversion:kafka,无法打开共享库的相关知识,同时也会详细的解释kafka python客户端的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- DeepStream5.1 pythonversion:kafka,无法打开共享库(kafka python客户端)
- aiokafka,一个非常实用的 Python 库!
- Exception in thread "main" org.apache.kafka.common.KafkaException: Failed to construct kafka consumer
- Kafka Cached zkVersion [62] not equal to that in zookeeper, skip updating ISR (kafka.cluster.Part...
- Kafka Connect 使用 REST API 和 Stramzi 类型:KafkaConnector
")
DeepStream5.1 pythonversion:kafka,无法打开共享库(kafka python客户端)
如何解决DeepStream5.1 pythonversion:kafka,无法打开共享库?
我在deepstream5.1测试deepstream-test-4时,C版本的程序可以成功运行,但是python版本报错如下(我用的参数相同):
Error: gst-library-error-quark: Could not initialize supporting library. (3): gstnvmsgbroker.c(359): legacy_gst_nvmsgbroker_start (): /GstPipeline:pipeline0/GstNvMsgbroker:nvmsg-broker:
unable to open shared library
请问为什么会这样?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

aiokafka,一个非常实用的 Python 库!
大家好,我是涛哥,本文内容来自 涛哥聊Python ,转载请标原创。
今天为大家分享一个非常实用的 Python 库 - aiokafka
Github地址:https://github.com/aio-libs/aiokafka
aiokafka是一个用于与Apache Kafka消息队列进行异步交互的Python库,基于asyncio框架实现了高效的异步IO操作。本文将介绍如何安装aiokafka库、其特性、基本功能、高级功能、实际应用场景,并对其进行总结和分析。
安装
安装aiokafka库非常简单,可以通过pip工具进行安装:
pip install aiokafka安装完成后,即可开始使用aiokafka库与Kafka消息队列进行异步交互。
特性
- 异步IO操作:基于asyncio框架实现了高效的异步IO操作,提高了程序的性能和并发能力。
- 支持Kafka协议:完整支持Kafka协议,可以与Kafka消息队列进行稳定可靠的通信。
- 高可靠性:提供了消息确认和重试机制,保证了消息传递的可靠性和一致性。
基本功能
1. 连接Kafka集群
aiokafka库可以方便地连接到Kafka集群,并进行生产者和消费者的创建和管理。
以下是一个简单的连接Kafka集群的示例:
import asyncio
from aiokafka import AIOKafkaProducer
async def main():
# 连接到Kafka集群
producer = AIOKafkaProducer(bootstrap_servers=''localhost:9092'')
await producer.start()
# 发送消息到Kafka主题
await producer.send_and_wait(''my_topic'', b''Hello, Kafka!'')
# 关闭连接
await producer.stop()
# 运行主函数
asyncio.run(main())在上述代码中,通过创建AIOKafkaProducer对象连接到Kafka集群,并使用send_and_wait方法发送消息到指定主题。
2. 消费消息
aiokafka库可以创建消费者,从Kafka主题中消费消息。
以下是一个简单的消费消息的示例:
import asyncio
from aiokafka import AIOKafkaConsumer
async def main():
# 连接到Kafka集群
consumer = AIOKafkaConsumer(''my_topic'', bootstrap_servers=''localhost:9092'')
await consumer.start()
# 消费消息
async for message in consumer:
print(message.value)
# 关闭连接
await consumer.stop()
# 运行主函数
asyncio.run(main())在上述代码中,通过创建AIOKafkaConsumer对象连接到Kafka集群,并使用异步迭代器消费消息。
高级功能
1. 批量发送和消费
aiokafka库支持批量发送和消费消息,提高了消息传递的效率。
以下是一个批量发送和消费消息的示例:
import asyncio
from aiokafka import AIOKafkaProducer, AIOKafkaConsumer
async def main():
# 连接到Kafka集群
producer = AIOKafkaProducer(bootstrap_servers=''localhost:9092'')
await producer.start()
# 批量发送消息到Kafka主题
await producer.send_messages(''my_topic'', [b''Message1'', b''Message2'', b''Message3''])
# 关闭生产者连接
await producer.stop()
# 连接到Kafka集群
consumer = AIOKafkaConsumer(''my_topic'', bootstrap_servers=''localhost:9092'')
await consumer.start()
# 批量消费消息
async for messages in consumer.batches():
for message in messages:
print(message.value)
# 关闭消费者连接
await consumer.stop()
# 运行主函数
asyncio.run(main())在上述代码中,通过创建AIOKafkaProducer和AIOKafkaConsumer对象实现了批量发送和消费消息的操作。
2. 异步提交偏移量
aiokafka库支持异步提交消费者的偏移量,可以确保消息消费的可靠性和一致性。
以下是一个异步提交偏移量的示例:
import asyncio
from aiokafka import AIOKafkaConsumer
async def main():
# 连接到Kafka集群
consumer = AIOKafkaConsumer(''my_topic'', bootstrap_servers=''localhost:9092'')
await consumer.start()
# 消费消息并异步提交偏移量
async for message in consumer:
print(message.value)
await consumer.commit()
# 关闭连接
await consumer.stop()
# 运行主函数
asyncio.run(main())在上述代码中,通过异步提交偏移量可以确保消费者消费消息的可靠性和一致性。
实际应用场景
1. 异步消息处理
在异步消息处理系统中,aiokafka 可以作为消息队列的一部分,处理大量的异步消息。例如,一个在线游戏服务器可以使用 aiokafka 来处理玩家的游戏事件,如玩家加入游戏、获取游戏信息等。
import asyncio
from aiokafka import AIOKafkaConsumer
async def game_server():
consumer = AIOKafkaConsumer(''game_events'', bootstrap_servers=''localhost:9092'')
await consumer.start()
async for event in consumer:
# 处理游戏事件逻辑
handle_game_event(event)
await consumer.stop()
async def handle_game_event(event):
# 处理游戏事件的逻辑
print(f"Received game event: {event}")
asyncio.run(game_server())2. 实时数据流处理
aiokafka 在实时数据流处理中发挥着关键作用,允许应用程序从 Kafka 主题中读取数据并进行实时处理。例如,一个实时监控系统可以使用 aiokafka 来处理传感器数据,实时分析并采取相应的措施。
import asyncio
from aiokafka import AIOKafkaConsumer
async def realtime_monitoring():
consumer = AIOKafkaConsumer(''sensor_data'', bootstrap_servers=''localhost:9092'')
await consumer.start()
async for data in consumer:
# 实时处理传感器数据
process_sensor_data(data)
await consumer.stop()
async def process_sensor_data(data):
# 处理传感器数据的逻辑
print(f"Processing sensor data: {data}")
asyncio.run(realtime_monitoring())3. 分布式系统通信
在分布式系统中,各个节点之间需要进行异步通信和数据传输,aiokafka 可以作为分布式系统通信的可靠工具。例如,一个分布式任务调度系统可以使用 aiokafka 来发送任务和接收执行结果。
import asyncio
from aiokafka import AIOKafkaProducer, AIOKafkaConsumer
async def distributed_scheduler():
producer = AIOKafkaProducer(bootstrap_servers=''localhost:9092'')
await producer.start()
# 发送任务
await producer.send_and_wait(''tasks'', b''Execute task 1'')
consumer = AIOKafkaConsumer(''task_results'', bootstrap_servers=''localhost:9092'')
await consumer.start()
async for result in consumer:
# 处理任务执行结果
handle_task_result(result)
await consumer.stop()
await producer.stop()
async def handle_task_result(result):
# 处理任务执行结果的逻辑
print(f"Received task result: {result}")
asyncio.run(distributed_scheduler())总结
Python 的 aiokafka 库是一个强大的异步 Kafka 客户端库,基于 asyncio 框架,能够高效地处理异步消息和实时数据流。该库提供了完整的 Kafka 协议支持,包括消息确认、重试机制等功能,使得与 Kafka 集群的通信稳定可靠。在实际应用中,aiokafka 可以用于异步消息处理、实时数据流处理和分布式系统通信等场景,为开发者提供了灵活可靠的异步通信能力。总之,aiokafka 是 Python 开发者在构建异步应用时的重要选择之一,具有广泛的应用前景和实用价值。

Exception in thread "main" org.apache.kafka.common.KafkaException: Failed to construct kafka consumer
Exception in thread "main" org.apache.kafka.common.KafkaException: Failed to construct kafka consumer
at org.apache.kafka.clients.consumer.KafkaConsumer.<init>(KafkaConsumer.java:702)
at org.apache.kafka.clients.consumer.KafkaConsumer.<init>(KafkaConsumer.java:557)
at org.apache.kafka.clients.consumer.KafkaConsumer.<init>(KafkaConsumer.java:540)
at org.apache.spark.sql.kafka010.SubscribeStrategy.createConsumer(ConsumerStrategy.scala:62)
at org.apache.spark.sql.kafka010.KafkaOffsetReader.createConsumer(KafkaOffsetReader.scala:314)
at org.apache.spark.sql.kafka010.KafkaOffsetReader.<init>(KafkaOffsetReader.scala:78)
at org.apache.spark.sql.kafka010.KafkaSourceProvider.createContinuousReader(KafkaSourceProvider.scala:130)
at org.apache.spark.sql.kafka010.KafkaSourceProvider.createContinuousReader(KafkaSourceProvider.scala:43)
at org.apache.spark.sql.streaming.DataStreamReader.load(DataStreamReader.scala:185)
at com.structured.APP.structuredJava.main(structuredJava.java:24)
Caused by: org.apache.kafka.common.config.ConfigException: No resolvable bootstrap urls given in bootstrap.servers
at org.apache.kafka.clients.ClientUtils.parseAndValidateAddresses(ClientUtils.java:59)
at org.apache.kafka.clients.consumer.KafkaConsumer.<init>(KafkaConsumer.java:620)
... 9 more
![Kafka Cached zkVersion [62] not equal to that in zookeeper, skip updating ISR (kafka.cluster.Part...](http://www.gvkun.com/zb_users/upload/2025/03/8c74bb6d-321b-44a8-847c-53e71aeda6011742625916771.jpg "Kafka Cached zkVersion [62] not equal to that in zookeeper, skip updating ISR (kafka.cluster.Part...")
Kafka Cached zkVersion [62] not equal to that in zookeeper, skip updating ISR (kafka.cluster.Part...
我司业务Kafka集群是3节点(broker分别为10,20,30),每个Topic 3 Partition,3 Repilication的配置,早上起床突然发现所有Topic的Broker节点都变为2个了,然后监控发现仍然活着的Broker个数还是3个。那这是怎么回事呢? 通过KafkaManager监控发现,每个Topic的Leader为10的Partition的ISR只有10了,20,30都消失了,而其他Partition的ISR中也都缺少了10。直觉告诉我,10这个节点实际已经被整个集群抛弃了,查看10节点的日志文件,发现日志仍然在增长,并且其他节点的信息也都在正常同步,也就是说10节点还在工作,但是对于整个集群来说,并没有认可,那么问题是什么呢?由于我们对于Kafka和ZK没有最基本的监控,所以只能通过有限的监控来判断问题发生的时间点,然后找到对应的log日志进行排查。 首先需要确认问题发生的时间点,既然kafka级别的监控不全,那么首先从主机级别的流量开始查吧: 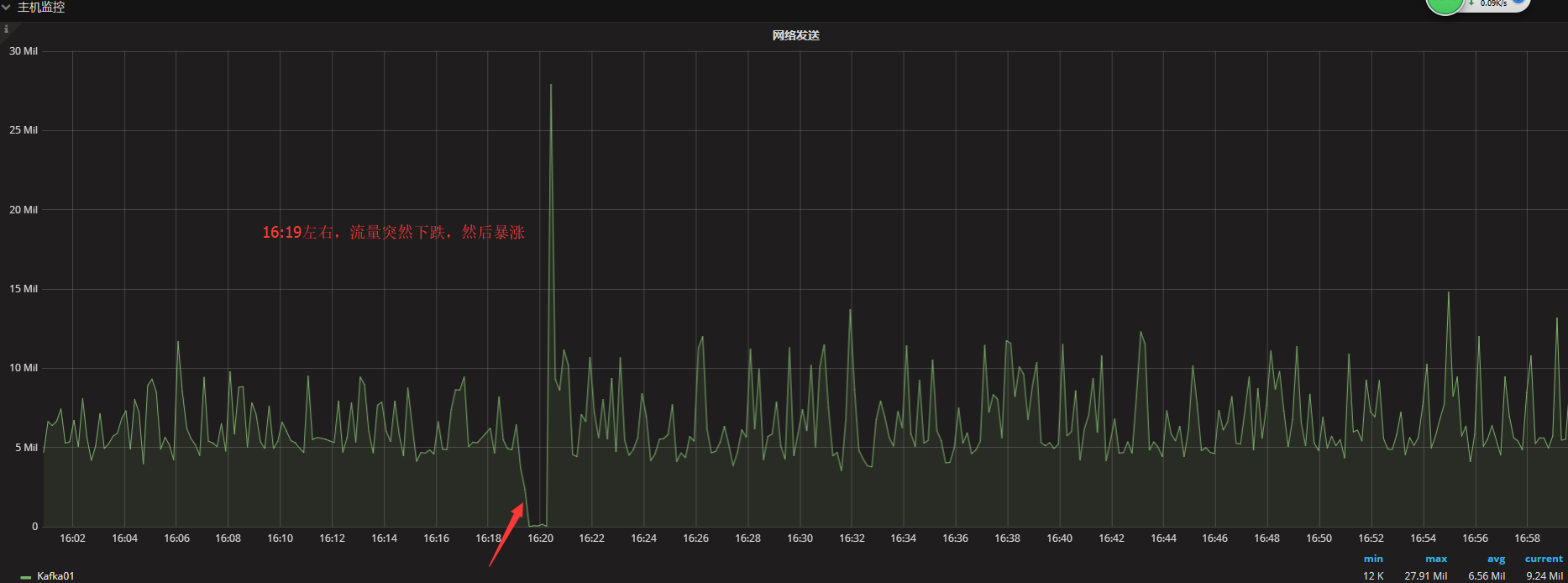 比较幸运的是,发现16:19分左右,10节点的流量有个突变,首先是大幅降低,直至为0,然后突然暴涨,后续恢复正常,很明显是一个10节点离线,然后上线的过程。定位到这个时间点,然后去翻日志,发现20,30节点的日志出奇的类似:
比较幸运的是,发现16:19分左右,10节点的流量有个突变,首先是大幅降低,直至为0,然后突然暴涨,后续恢复正常,很明显是一个10节点离线,然后上线的过程。定位到这个时间点,然后去翻日志,发现20,30节点的日志出奇的类似: 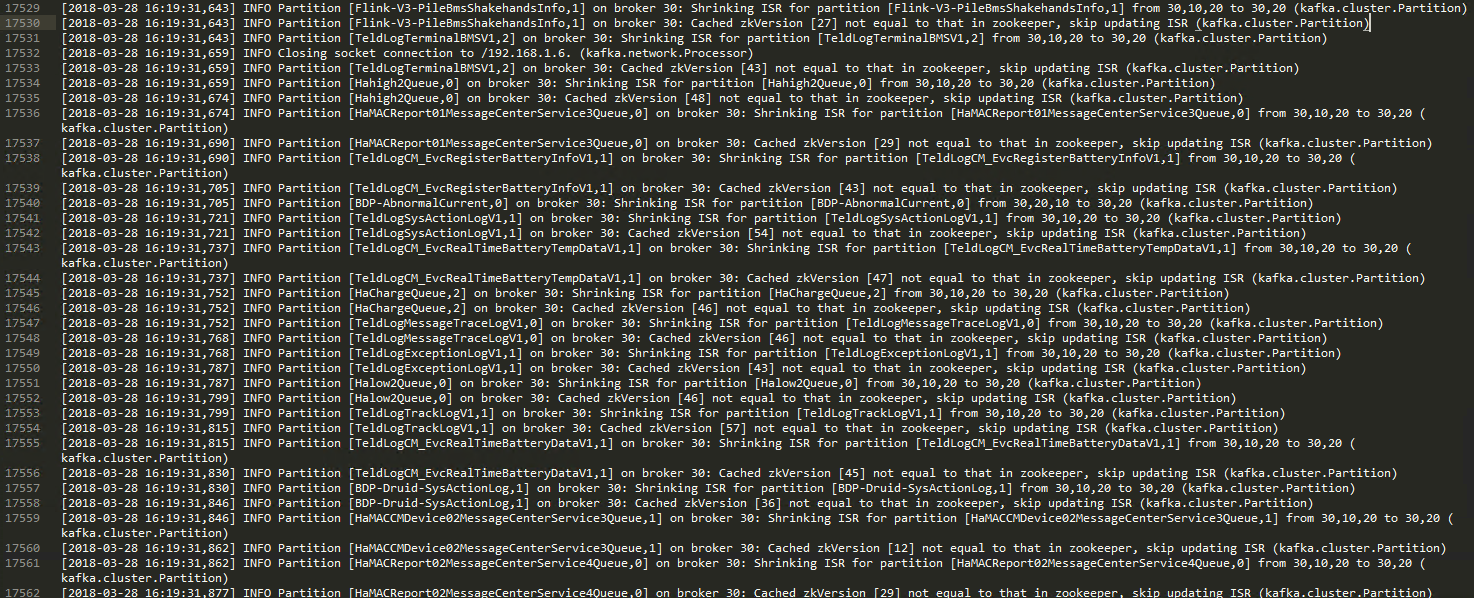 10节点首先被踢出了集群,Shrinking ISR for partition [XXXXXXX,1] from 30,10,20 to 30,20 然后更新ISR的时候报错:Cached zkVersion [27] not equal to that in zookeeper, skip updating ISR (kafka.cluster.Partition) 这个基本符合我们的猜测,10节点短暂离线,然后上线后,因为20,30update ISR时判断ZKversion错误,中断更新,导致10节点只是接管了自己是Leader的那些Partition,对于20,30是Leader的那些,很遗憾,认为10一直死着。这真是一个天大的悲剧啊! 那么为什么会产生这个问题呢?通过一阵google,发现这么一篇文章:https://issues.apache.org/jira/browse/KAFKA-2729 。 Kafka-2729Bug,摘抄几个回复:
10节点首先被踢出了集群,Shrinking ISR for partition [XXXXXXX,1] from 30,10,20 to 30,20 然后更新ISR的时候报错:Cached zkVersion [27] not equal to that in zookeeper, skip updating ISR (kafka.cluster.Partition) 这个基本符合我们的猜测,10节点短暂离线,然后上线后,因为20,30update ISR时判断ZKversion错误,中断更新,导致10节点只是接管了自己是Leader的那些Partition,对于20,30是Leader的那些,很遗憾,认为10一直死着。这真是一个天大的悲剧啊! 那么为什么会产生这个问题呢?通过一阵google,发现这么一篇文章:https://issues.apache.org/jira/browse/KAFKA-2729 。 Kafka-2729Bug,摘抄几个回复: 
 ok,我们得出几个结论,这种问题确实是Kafka与ZK连接短暂中断引起,并且这个只能通过重启Kafka节点解决,然后这个在1.1.0版本才得以修复。。。。。。 没其他办法,我们只能择日重启了10节点的kafka,问题解决。 对于升级这件事情,短期内我们是无法解决的,我们应该如何避免或者第一时间知道此类问题的发生呢? 1. 首先Kafka跟ZK的连接为什么中断呢?原因很多,比如网络闪断,比如ZK繁忙,比如ZKGC时间过长。那么我们需要加大Kafka与ZK连接的超时时间:默认6秒,我们增加到30秒。更新位置:Kafka配置文件,两个参数更新如下: zookeeper.session.timeout.ms=30000 zookeeper.connection.timeout.ms=30000 2. 比如对Kafka,ZK建立全面的监控,结合预警,第一时间知晓问题,然后根据监控指标进行分析,而不是撞大运,人工翻日志 如何建立全面的kafka,ZK监控体系呢?别急,下篇揭晓,先上个图吧:
ok,我们得出几个结论,这种问题确实是Kafka与ZK连接短暂中断引起,并且这个只能通过重启Kafka节点解决,然后这个在1.1.0版本才得以修复。。。。。。 没其他办法,我们只能择日重启了10节点的kafka,问题解决。 对于升级这件事情,短期内我们是无法解决的,我们应该如何避免或者第一时间知道此类问题的发生呢? 1. 首先Kafka跟ZK的连接为什么中断呢?原因很多,比如网络闪断,比如ZK繁忙,比如ZKGC时间过长。那么我们需要加大Kafka与ZK连接的超时时间:默认6秒,我们增加到30秒。更新位置:Kafka配置文件,两个参数更新如下: zookeeper.session.timeout.ms=30000 zookeeper.connection.timeout.ms=30000 2. 比如对Kafka,ZK建立全面的监控,结合预警,第一时间知晓问题,然后根据监控指标进行分析,而不是撞大运,人工翻日志 如何建立全面的kafka,ZK监控体系呢?别急,下篇揭晓,先上个图吧:  3. 当然是熟读源码,然后知其所以然,然后。。。。由于业务重心不在这一块,所以这个目标对我而言有点难,各位大牛如果知道此问题的前因后果,欢迎告诉小弟,感激不尽!
3. 当然是熟读源码,然后知其所以然,然后。。。。由于业务重心不在这一块,所以这个目标对我而言有点难,各位大牛如果知道此问题的前因后果,欢迎告诉小弟,感激不尽!

Kafka Connect 使用 REST API 和 Stramzi 类型:KafkaConnector
如何解决Kafka Connect 使用 REST API 和 Stramzi 类型:KafkaConnector?
我正在尝试使用 Kafka Connect REST API 来管理连接器,为简单起见,请考虑以下 pause 实现:
def pause(): Unit = {
logger.info(s"pause() Triggered")
val response = HttpClient.newHttpClient.send({
HttpRequest
.newBuilder(URI.create(config.connectUrl + s"/connectors/${config.connectorName}/pause"))
.PUT(BodyPublishers.noBody)
.timeout(Duration.ofMillis(config.timeout.toMillis.toInt))
.build()
},BodyHandlers.ofString)
if (response.statusCode() != HTTPStatus.Accepted) {
throw new Exception(s"Could not pause connector: ${response.body}")
}
}
由于我使用 KafkaConnector 作为资源,因此我无法使用 Kafka Connect REST API,因为连接器操作员将 KafkaConnetor 资源作为其唯一的真实来源,直接进行了诸如 pause 之类的手动更改使用 Kafka Connect REST API 被集群运营商恢复。
所以要暂停连接器,我需要以某种方式编辑资源。
我正在努力改变当前函数的逻辑,如果有一些如何处理KafkaConnetor资源的实际例子会很棒。
我查看了 Using Strimzi 文档,但找不到任何实际示例
谢谢!
在@Jakub 的帮助下,我设法创建了我的新客户端:
class KubernetesService(config: Configuration) extends StrictLogging {
private[this] val client = new DefaultKubernetesClient(Config.autoConfigure(config.connectorContext))
def setPause(pause: Boolean): Unit = {
logger.info(s"[KubernetesService] - setPause($pause) Triggered")
val connector = getConnector()
connector.getSpec.setPause(pause)
Crds.kafkaConnectorOperation(client).inNamespace(config.connectorNamespace).withName(config.connectorName).replace(connector)
Crds.kafkaConnectorOperation(client)
.inNamespace(config.connectorNamespace)
.withName(config.connectorName)
.waitUntilCondition(connector => {
connector != null &&
connector.getSpec.getPause == pause && {
val desiredState = if (pause) "Paused" else "Running"
connector.getStatus.getConditions.stream().anyMatch(_.getType.equalsIgnoreCase(desiredState))
}
},config.timeout.toMillis,TimeUnit.MILLISECONDS)
}
def delete(): Unit = {
logger.info(s"[KubernetesService] - delete() Triggered")
Crds.kafkaConnectorOperation(client).inNamespace(config.connectorNamespace).withName(config.connectorName).delete
Crds.kafkaConnectorOperation(client)
.inNamespace(config.connectorNamespace)
.withName(config.connectorName)
.waitUntilCondition(_ == null,TimeUnit.MILLISECONDS)
}
def create(oldKafkaConnect: KafkaConnector): Unit = {
logger.info(s"[KubernetesService] - create(${oldKafkaConnect.getMetadata}) Triggered")
Crds.kafkaConnectorOperation(client).inNamespace(config.connectorNamespace).withName(config.connectorName).create(oldKafkaConnect)
Crds.kafkaConnectorOperation(client)
.inNamespace(config.connectorNamespace)
.withName(config.connectorName)
.waitUntilCondition(connector => {
connector != null &&
connector.getStatus.getConditions.stream().anyMatch(_.getType.equalsIgnoreCase("Running"))
},TimeUnit.MILLISECONDS)
}
def getConnector(): KafkaConnector = {
logger.info(s"[KubernetesService] - getConnector() Triggered")
Try {
Crds.kafkaConnectorOperation(client).inNamespace(config.connectorNamespace).withName(config.connectorName).get
} match {
case Success(connector) => connector
case Failure(_: NullPointerException) => throw new NullPointerException(s"Failure on getConnector(${config.connectorName}) on ns: ${config.connectorNamespace},context: ${config.connectorContext}")
case Failure(exception) => throw exception
}
}
}
解决方法
要暂停连接器,您可以编辑 KafkaConnector 资源并将 pause 中的 .spec 字段设置为 true(请参阅 kubectl {3}})。有几种方法可以做到这一点。您可以使用 kubectl apply 并从文件 (kubectl edit) 应用新的 YAML,或者使用 api 以交互方式执行此操作。
如果您想以编程方式执行此操作,则需要使用 Kubernetes 客户端来编辑资源。在 Java 中,您还可以使用 Strimzi 的 api 模块,该模块具有用于编辑资源的所有结构。我整理了一个简单的示例,用于使用 Fabric8 Kubernetes 客户端和 package cz.scholz.strimzi.api.examples;
import io.fabric8.kubernetes.client.DefaultKubernetesClient;
import io.fabric8.kubernetes.client.KubernetesClient;
import io.fabric8.kubernetes.client.dsl.MixedOperation;
import io.fabric8.kubernetes.client.dsl.Resource;
import io.strimzi.api.kafka.Crds;
import io.strimzi.api.kafka.KafkaConnectorList;
import io.strimzi.api.kafka.model.KafkaConnector;
public class PauseConnector {
public static void main(String[] args) {
String namespace = "myproject";
String crName = "my-connector";
KubernetesClient client = new DefaultKubernetesClient();
MixedOperation<KafkaConnector,KafkaConnectorList,Resource<KafkaConnector>> op = Crds.kafkaConnectorOperation(client);
KafkaConnector connector = op.inNamespace(namespace).withName(crName).get();
connector.getSpec().setPause(true);
op.inNamespace(namespace).withName(crName).replace(connector);
client.close();
}
}
模块在 Java 中暂停 Kafka 连接器:
{
"student": {
name : "Rahul",age : 18,department : "CSE",section : "B"
},"sequence": 0,"student_ref": "AUTCSE024","college" : "AUT"
}
{
"student": {
name : "Rahul",section : "A"
},"sequence": 1,"college" : "AUT"
}
{
"student": {
name : "Kumar",department : "IT","student_ref": "AUTITE011",section : "C"
},"college" : "AUT"
}
{
"student": {
name : "Praveen","student_ref": "AUTITE016","college" : "AUT"
}
(请参阅 docs 了解完整项目)
我不是 Scala 用户 - 但我认为它应该也可以从 Scala 使用,但我将它从 Java 重写为 Scala 留给您。
关于DeepStream5.1 pythonversion:kafka,无法打开共享库和kafka python客户端的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于aiokafka,一个非常实用的 Python 库!、Exception in thread "main" org.apache.kafka.common.KafkaException: Failed to construct kafka consumer、Kafka Cached zkVersion [62] not equal to that in zookeeper, skip updating ISR (kafka.cluster.Part...、Kafka Connect 使用 REST API 和 Stramzi 类型:KafkaConnector的相关知识,请在本站寻找。
本文标签:




