本文将为您提供关于运行简单pyspark作业的异常的详细介绍,我们还将为您解释请阐述pyspark在启动时的相关知识,同时,我们还将为您提供关于Kafka与Pyspark结构化流作业的集成卡在[*](
本文将为您提供关于运行简单 pyspark 作业的异常的详细介绍,我们还将为您解释请阐述pyspark在启动时的相关知识,同时,我们还将为您提供关于Kafka 与 Pyspark 结构化流作业的集成卡在 [*](使用 jupyter)、org.apache.spark.SparkException:无效的Spark URL:spark:// HeartbeatReceiver @ xxxx_LPT-324:51380 PySpark、PyCharm搭建Spark开发环境 + 第一个pyspark程序、PySpark - 使用 Python 在 Spark 上编程的实用信息。
本文目录一览:- 运行简单 pyspark 作业的异常(请阐述pyspark在启动时)
- Kafka 与 Pyspark 结构化流作业的集成卡在 [*](使用 jupyter)
- org.apache.spark.SparkException:无效的Spark URL:spark:// HeartbeatReceiver @ xxxx_LPT-324:51380 PySpark
- PyCharm搭建Spark开发环境 + 第一个pyspark程序
- PySpark - 使用 Python 在 Spark 上编程
")
运行简单 pyspark 作业的异常(请阐述pyspark在启动时)
如何解决运行简单 pyspark 作业的异常?
按照 these 指令,我到了要执行 pyspark 的地方。首先,一些关于正在发生的事情的可能有用的信息:
idf@ubvm:~/docker-hadoop-spark$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
0d3a7c199e40 bde2020/spark-worker:3.0.0-hadoop3.2 "/bin/bash /worker.sh" 39 minutes ago Up 18 minutes 0.0.0.0:8081->8081/tcp spark-worker-1
c57ee3c4c30e bde2020/hive:2.3.2-postgresql-metastore "entrypoint.sh /bin/\u2026" 50 minutes ago Up 20 minutes 0.0.0.0:10000->10000/tcp,10002/tcp hive-server
f7bbeb786585 bde2020/spark-master:3.0.0-hadoop3.2 "/bin/bash /master.sh" 50 minutes ago Up 18 minutes 0.0.0.0:7077->7077/tcp,6066/tcp,0.0.0.0:8080->8080/tcp spark-master
8d3abafb37f3 shawnzhu/prestodb:0.181 "./bin/launcher run" 50 minutes ago Up 20 minutes 8080/tcp,0.0.0.0:8089->8089/tcp presto-coordinator
0d7000870e53 bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8 "/entrypoint.sh /run\u2026" 50 minutes ago Up 24 minutes (healthy) 8188/tcp historyserver
3bd51169b93f bde2020/hive:2.3.2-postgresql-metastore "entrypoint.sh /opt/\u2026" 50 minutes ago Up 20 minutes 10000/tcp,0.0.0.0:9083->9083/tcp,10002/tcp hive-metastore
d8e985e7b87e bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8 "/entrypoint.sh /run\u2026" 50 minutes ago Up 24 minutes (healthy) 0.0.0.0:9870->9870/tcp,0.0.0.0:9010->9000/tcp namenode
58dd60c1351a bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8 "/entrypoint.sh /run\u2026" 50 minutes ago Up 24 minutes (healthy) 0.0.0.0:9864->9864/tcp datanode
90903000c711 bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8 "/entrypoint.sh /run\u2026" 50 minutes ago Up 24 minutes (healthy) 8042/tcp nodemanager
862f9e47013b bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8 "/entrypoint.sh /run\u2026" 50 minutes ago Up 23 minutes (healthy) 8088/tcp resourcemanager
82e030c312ec bde2020/hive-metastore-postgresql:2.3.0 "/docker-entrypoint.\u2026" 50 minutes ago Up 20 minutes 5432/tcp hive-metastore-postgresql
idf@ubvm:~/docker-hadoop-spark$ docker network list
docker network list
NETWORK ID NAME DRIVER ScopE
308e4ed694e9 bridge bridge local
c0399541541f docker-hadoop-spark_default bridge local
bb18b01bbfd7 host host local
4eb838dc0cbd none null local
175504e46998 wikipedia-playground_default bridge local
idf@ubvm:~/docker-hadoop-spark$
我正在执行指令的点:
>>> brewfile = spark.read.csv("hdfs://namenode:8020/data/openbeer/breweries/breweries.csv")
但我得到一个例外:
Traceback (most recent call last):
File "<stdin>",line 1,in <module>
File "/spark/python/pyspark/sql/readwriter.py",line 535,in csv
return self._df(self._jreader.csv(self._spark._sc._jvm.PythonUtils.toSeq(path)))
File "/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py",line 1305,in __call__
File "/spark/python/pyspark/sql/utils.py",line 131,in deco
return f(*a,**kw)
File "/spark/python/lib/py4j-0.10.9-src.zip/py4j/protocol.py",line 328,in get_return_value
py4j.protocol.Py4JJavaError: An error occurred while calling o48.csv.
: java.net.ConnectException: Call From f7bbeb786585/172.21.0.11 to namenode:8020 Failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:831)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:755)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1515)
at org.apache.hadoop.ipc.Client.call(Client.java:1457)
at org.apache.hadoop.ipc.Client.call(Client.java:1367)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy19.getFileInfo(UnkNown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:903)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy20.getFileInfo(UnkNown Source)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1665)
at org.apache.hadoop.hdfs.distributedFileSystem$29.doCall(distributedFileSystem.java:1582)
at org.apache.hadoop.hdfs.distributedFileSystem$29.doCall(distributedFileSystem.java:1579)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.distributedFileSystem.getFileStatus(distributedFileSystem.java:1594)
at org.apache.hadoop.fs.FileSystem.isDirectory(FileSystem.java:1700)
at org.apache.spark.sql.execution.streaming.FileStreamSink$.hasMetadata(FileStreamSink.scala:47)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:361)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:279)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$2(DataFrameReader.scala:268)
at scala.Option.getorElse(Option.scala:189)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:268)
at org.apache.spark.sql.DataFrameReader.csv(DataFrameReader.scala:705)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.ConnectException: Connection refused
at sun.nio.ch.socketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.socketChannelImpl.finishConnect(SocketChannelImpl.java:714)
at org.apache.hadoop.net.socketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:690)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:794)
at org.apache.hadoop.ipc.Client$Connection.access$3700(Client.java:411)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1572)
at org.apache.hadoop.ipc.Client.call(Client.java:1403)
... 39 more
>>>
Traceback (most recent call last):
File "/spark/python/pyspark/context.py",line 274,in signal_handler
raise KeyboardInterrupt()
KeyboardInterrupt
我不明白为什么这不起作用? firewall 网络中是否存在 docker 问题?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
](http://www.gvkun.com/zb_users/upload/2025/03/e8161cfe-0b9b-466c-b7ba-d39ed9f11c371742625981740.jpg "Kafka 与 Pyspark 结构化流作业的集成卡在 [*](使用 jupyter)")
Kafka 与 Pyspark 结构化流作业的集成卡在 [*](使用 jupyter)
如何解决Kafka 与 Pyspark 结构化流作业的集成卡在 [*](使用 jupyter)?
在安装 Pyspark 并对其进行测试后,它工作正常并为 kafka 集成添加了正确的连接器,现在当我尝试从同一网络中的另一台机器从 kafka 加载日期并开始工作时,它卡在 [* ],没有错误,没有什么,我不明白这里的问题,所以请如果有人可以帮助我,这是我的代码:
import os
os.environ[''PYSPARK_SUBMIT_ARGS''] = f''--packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.1.2 pyspark-shell''
import findspark
findspark.init()
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
import time
kafka_topic_name = "test-spark"
kafka_bootstrap_servers = ''192.168.1.3:9092''
spark = SparkSession \
.builder \
.appName("PySpark Structured Streaming with Kafka and Message Format as JSON") \
.master("local[*]") \
.getorCreate()
# Construct a streaming DataFrame that reads from TEST-SPARK
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers",kafka_bootstrap_servers) \
.option("subscribe",kafka_topic_name) \
.load()
print("Printing Schema of df: ")
df.printSchema()
df1 = df.selectExpr("CAST(value AS STRING)","timestamp")
df1.printSchema()
schema = StructType() \
.add("name",StringType()) \
.add("type",StringType())
df2 = df1\
.select(from_json(col("value"),schema)\
.alias("records"),"timestamp")
df3 = df2.select("records.*","timestamp")
print("Printing Schema of records_df3: ")
df3.printSchema()
records_write_stream = df3 \
.writeStream \
.trigger(processingTime=''5 seconds'') \
.outputMode("update") \
.option("truncate","false")\
.format("console") \
.start()
records_write_stream.awaitTermination()
print("Stream Data Processing Application Completed.")

- the command for kafka console producer that i tried with
$ ./bin/kafka-console-producer --broker-list localhost:9092 --topic test_spark \
--property value.schema=''{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}''
>{"f1": "value1"}
>{"f1": "value2"}
>{"f1": "value3"}
- 当我尝试引导 kafka 时,它没有显示任何错误并继续 但是当我尝试开始工作时它卡住了
- PS:奇怪的是,我试图在托管 kafka 的机器停机时运行此代码,并且它加载了 kafka,即:此代码没有错误:
# Construct a streaming DataFrame that reads from TEST-SPARK
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers",kafka_topic_name) \
.load()
- 并继续直到它再次卡在最后一段代码中,如上所示,这很奇怪
- 请问有什么建议吗?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

org.apache.spark.SparkException:无效的Spark URL:spark:// HeartbeatReceiver @ xxxx_LPT-324:51380 PySpark
如何解决org.apache.spark.SparkException:无效的Spark URL:spark:// HeartbeatReceiver @ xxxx_LPT-324:51380 PySpark?
尝试使用PySpark创建SparkConf,但出现错误
代码
from pyspark.python.pyspark.shell import spark
from pyspark import SparkConf,SparkContext
from pyspark.shell import sqlContext
from pyspark.sql import SparkSession
conf = SparkConf().setAppName("Test-1 ETL").setMaster("local[*]").set("spark.driver.host","localhost").set("spark.sql.execution.arrow.pyspark.enabled","true")
sc = SparkContext(conf=conf)
错误
org.apache.spark.SparkException: Invalid Spark URL: spark://HeartbeatReceiver@xxxx_LPT-324:51380
我还设置了set SPARK_LOCAL_HOSTNAME=localhost
有人可以帮助我吗?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

PyCharm搭建Spark开发环境 + 第一个pyspark程序
一, PyCharm搭建Spark开发环境
Windows7, Java 1.8.0_74, Scala 2.12.6, Spark 2.2.1, Hadoop 2.7.6
通常情况下,Spark开发是基于Linux集群的,但这里作为初学者并且囊中羞涩,还是在windows环境下先学习吧。
参照这个配置本地的Spark环境。
之后就是配置PyCharm用来开发Spark。本人在这里浪费了不少时间,因为百度出来的无非就以下两种方式:
1. 在程序中设置环境变量
import os
import sys
os.environ[''SPARK_HOME''] = ''C:\xxx\spark-2.2.1-bin-hadoop2.7''
sys.path.append(''C:\xxx\spark-2.2.1-bin-hadoop2.7\python'')2. 在Edit Configuration中添加环境变量
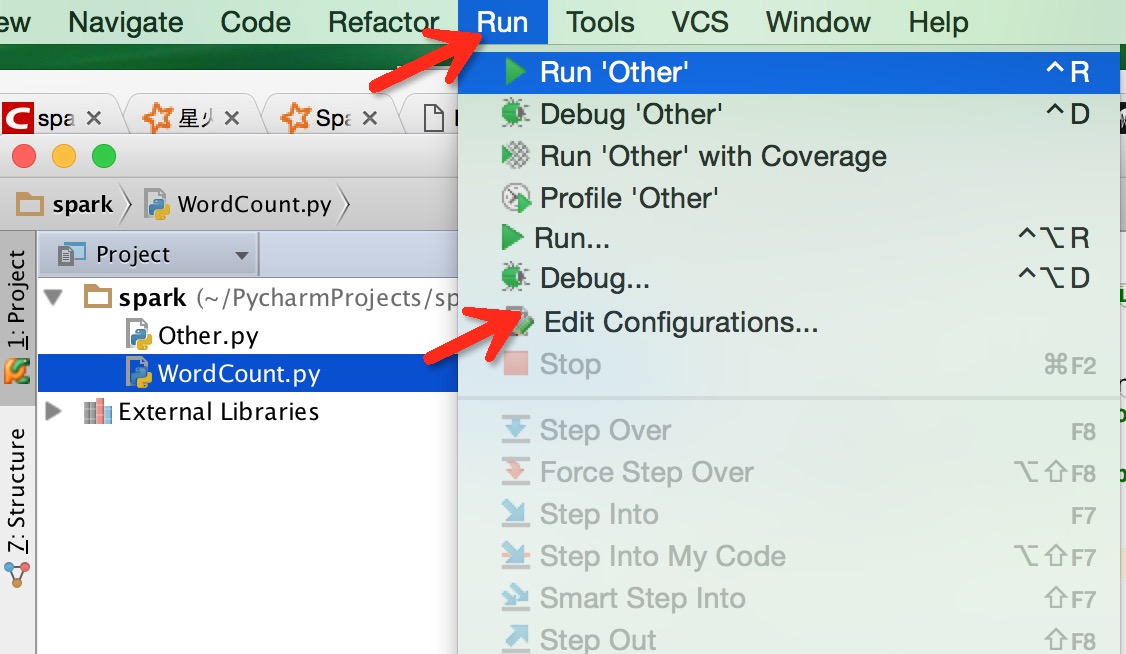
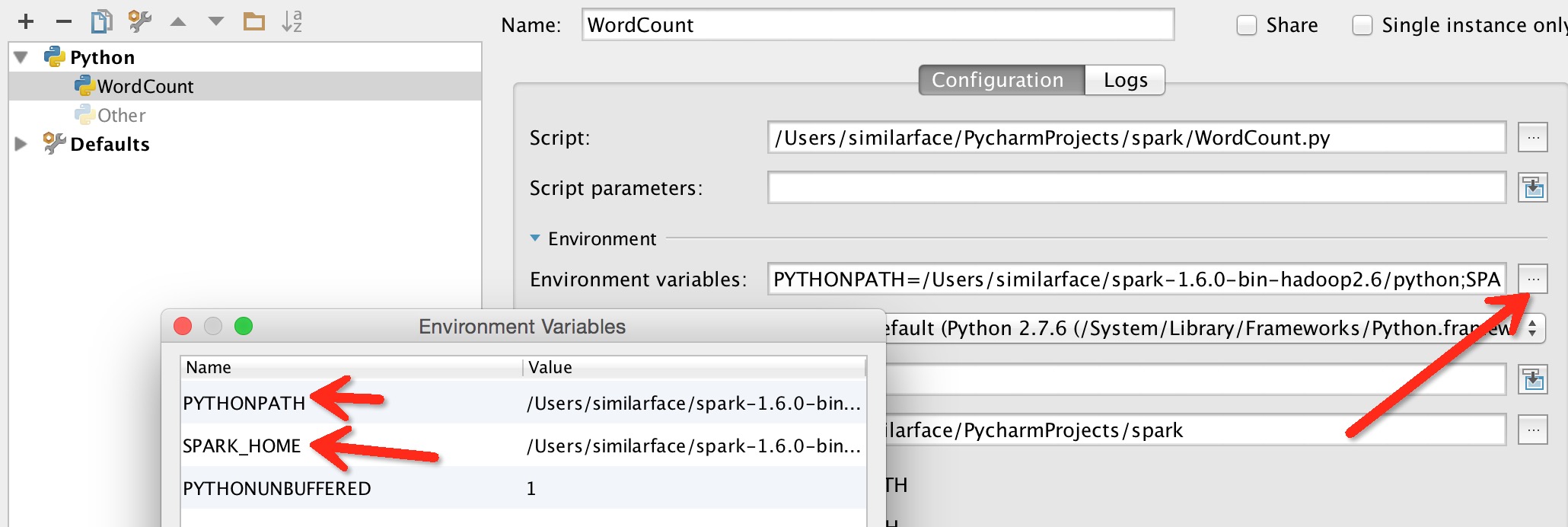
不过还是没有解决程序中代码自动补全。
想了半天,观察到spark提供的pyspark很像单独的安装包,应该可以考虑将pyspark包放到python的安装目录下,这样也就自动添加到之前所设置的python path里了,应该就能实现pyspark的代码补全提示。
将spark下的pyspark包放到python路径下(注意,不是spark下的python!)
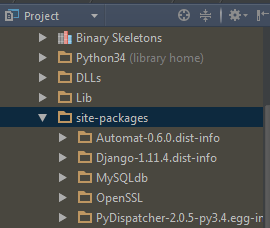
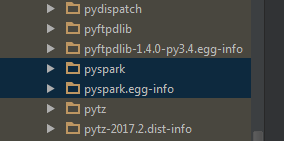
最后,实现了pyspark代码补全功能。
二. 第一个pyspark程序
作为小白,只能先简单用下python+pyspark了。
数据: Air Quality in Madrid (2001-2018)
需求: 根据历史数据统计出每个月平均指标值
import os
import re
from pyspark.sql import SparkSession
if __name__ == "__main__":
spark = SparkSession.builder.getOrCreate()
df_array = []
years = []
air_quality_data_folder = "C:/xxx/spark/air-quality-madrid/csvs_per_year"
for file in os.listdir(air_quality_data_folder):
if ''2018'' not in file:
year = re.findall("\d{4}", file)
years.append(year[0])
file_path = os.path.join(air_quality_data_folder, file)
df = spark.read.csv(file_path, header="true")
# print(df.columns)
df1 = df.withColumn(''yyyymm'', df[''date''].substr(0, 7))
df_final = df1.filter(df1[''yyyymm''].substr(0, 4) == year[0]).groupBy(df1[''yyyymm'']).agg({''PM10'': ''avg''})
df_array.append(df_final)
pm10_months = [0] * 12
# print(range(12))
for df in df_array:
for i in range(12):
rows = df.filter(df[''yyyymm''].contains(''-''+str(i+1).zfill(2))).first()
# print(rows[1])
pm10_months[i] += (rows[1]/12)
years.sort()
print(years[0] + '' - '' + years[len(years)-1] + ''年,每月平均PM10统计'')
m_index = 1
for data in pm10_months:
print(str(m_index).zfill(2) + ''月份: '' + ''||'' * round(data))
m_index += 1运行结果:
2001 - 2017年,每月平均PM10统计
01月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
02月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
03月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
04月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
05月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
06月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
07月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
08月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
09月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
10月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
11月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
12月份: ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||由以上统计结果,可以看出4月份的PM10最低。
Done!

PySpark - 使用 Python 在 Spark 上编程
Python Programming Guide
The Spark Python API (PySpark) exposes the Spark programming model to Python. To learn the basics of Spark, we recommend reading through theScala programming guide first; it should be easy to follow even if you don’t know Scala. This guide will show how to use the Spark features described there in Python.
Key Differences in the Python API
There are a few key differences between the Python and Scala APIs:
Python is dynamically typed, so RDDs can hold objects of multiple types.
PySpark does not yet support a few API calls, such as
lookupand non-text input files, though these will be added in future releases.
In PySpark, RDDs support the same methods as their Scala counterparts but take Python functions and return Python collection types. Short functions can be passed to RDD methods using Python’s lambda syntax:
logData = sc.textFile(logFile).cache()
errors = logData.filter(lambda line: "ERROR" in line)You can also pass functions that are defined with the def keyword; this is useful for longer functions that can’t be expressed using lambda:
def is_error(line):
return "ERROR" in lineerrors = logData.filter(is_error)Functions can access objects in enclosing scopes, although modifications to those objects within RDD methods will not be propagated back:
error_keywords = ["Exception", "Error"]
def is_error(line):
return any(keyword in line for keyword in error_keywords)
errors = logData.filter(is_error)PySpark will automatically ship these functions to workers, along with any objects that they reference. Instances of classes will be serialized and shipped to workers by PySpark, but classes themselves cannot be automatically distributed to workers. The Standalone Use section describes how to ship code dependencies to workers.
In addition, PySpark fully supports interactive use—simply run ./bin/pyspark to launch an interactive shell.
Installing and Configuring PySpark
PySpark requires Python 2.6 or higher. PySpark applications are executed using a standard CPython interpreter in order to support Python modules that use C extensions. We have not tested PySpark with Python 3 or with alternative Python interpreters, such as PyPy or Jython.
By default, PySpark requires python to be available on the system PATH and use it to run programs; an alternate Python executable may be specified by setting the PYSPARK_PYTHON environment variable in conf/spark-env.sh (or .cmd on Windows).
All of PySpark’s library dependencies, including Py4J, are bundled with PySpark and automatically imported.
Standalone PySpark applications should be run using the bin/pyspark script, which automatically configures the Java and Python environment using the settings in conf/spark-env.sh or .cmd. The script automatically adds the bin/pyspark package to the PYTHONPATH.
Interactive Use
The bin/pyspark script launches a Python interpreter that is configured to run PySpark applications. To use pyspark interactively, first build Spark, then launch it directly from the command line without any options:
$ sbt/sbt assembly
$ ./bin/pysparkThe Python shell can be used explore data interactively and is a simple way to learn the API:
>>> words = sc.textFile("/usr/share/dict/words")
>>> words.filter(lambda w: w.startswith("spar")).take(5)
[u''spar'', u''sparable'', u''sparada'', u''sparadrap'', u''sparagrass'']
>>> help(pyspark) # Show all pyspark functionsBy default, the bin/pyspark shell creates SparkContext that runs applications locally on a single core. To connect to a non-local cluster, or use multiple cores, set the MASTER environment variable. For example, to use the bin/pyspark shell with a standalone Spark cluster:
$ MASTER=spark://IP:PORT ./bin/pysparkOr, to use four cores on the local machine:
$ MASTER=local[4] ./bin/pysparkIPython
注意:此部分已过时,请参考 http://www.jupyter.org/
It is also possible to launch PySpark in IPython, the enhanced Python interpreter. PySpark works with IPython 1.0.0 and later. To use IPython, set the IPYTHON variable to 1 when running bin/pyspark:
$ IPYTHON=1 ./bin/pysparkAlternatively, you can customize the ipython command by setting IPYTHON_OPTS. For example, to launch the IPython Notebook with PyLab graphing support:
$ IPYTHON_OPTS="notebook --pylab inline" ./bin/pysparkIPython also works on a cluster or on multiple cores if you set the MASTER environment variable.
Standalone Programs
PySpark can also be used from standalone Python scripts by creating a SparkContext in your script and running the script using bin/pyspark. The Quick Start guide includes a complete example of a standalone Python application.
Code dependencies can be deployed by listing them in the pyFiles option in the SparkContext constructor:
from pyspark import SparkContext
sc = SparkContext("local", "App Name", pyFiles=[''MyFile.py'', ''lib.zip'', ''app.egg''])Files listed here will be added to the PYTHONPATH and shipped to remote worker machines. Code dependencies can be added to an existing SparkContext using its addPyFile() method.
You can set configuration properties by passing aSparkConf object to SparkContext:
from pyspark import SparkConf, SparkContext
conf = (SparkConf()
.setMaster("local")
.setAppName("My app")
.set("spark.executor.memory", "1g"))
sc = SparkContext(conf = conf)API Docs
API documentation for PySpark is available as Epydoc. Many of the methods also contain doctests that provide additional usage examples.
Libraries
MLlib is also available in PySpark. To use it, you’ll needNumPy version 1.7 or newer, and Python 2.7. The MLlib guide contains some example applications.
Where to Go from Here
PySpark also includes several sample programs in the python/examples folder. You can run them by passing the files to pyspark; e.g.:
./bin/pyspark python/examples/wordcount.pyEach program prints usage help when run without arguments.
今天关于运行简单 pyspark 作业的异常和请阐述pyspark在启动时的介绍到此结束,谢谢您的阅读,有关Kafka 与 Pyspark 结构化流作业的集成卡在 [*](使用 jupyter)、org.apache.spark.SparkException:无效的Spark URL:spark:// HeartbeatReceiver @ xxxx_LPT-324:51380 PySpark、PyCharm搭建Spark开发环境 + 第一个pyspark程序、PySpark - 使用 Python 在 Spark 上编程等更多相关知识的信息可以在本站进行查询。
本文标签:




