关于使Python的readline方法能够识别行尾的两种变化?和python中readlines读取指定行的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于ipython抱怨readlin
关于使Python的readline方法能够识别行尾的两种变化?和python中readlines读取指定行的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于ipython抱怨readline、python .readlines()、python 3.2中缺少readline和readlines方法?、Python File readlines() 使用方法等相关知识的信息别忘了在本站进行查找喔。
本文目录一览:- 使Python的readline方法能够识别行尾的两种变化?(python中readlines读取指定行)
- ipython抱怨readline
- python .readlines()
- python 3.2中缺少readline和readlines方法?
- Python File readlines() 使用方法
")
使Python的readline方法能够识别行尾的两种变化?(python中readlines读取指定行)
我正在编写一个Python文件,该文件需要读取多个不同类型的文件。我通过符合传统阅读在线文件for line in f使用后f =
open("file.txt","r")。
这似乎不适用于所有文件。我的猜测是某些文件以不同的编码结尾(例如\ r \ n与仅\ r)。我可以读取整个文件,并在\
r上进行字符串分割,但这非常昂贵,我宁愿不这样做。有没有一种方法可以使Python的readline方法识别行尾的两种变化?

ipython抱怨readline
当我在osx上安装ipython并运行它时,出现以下警告:
/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/
site-packages/IPython/utils/rlineimpl.py:96:
RuntimeWarning: Leopard libedit detected - readline will not be wel
behaved including some crashes on tab completion,and incorrect
history navigation. It is highly recommended that you install
readline,which is easy_installable with: 'easy_install readline'
我已经安装了readline,并且不使用最初安装在中的系统python
/Library/Frameworks/Python.framework/Versions/2.7/bin/python$。/usr/bin/python指向2.7版的要点如下所示
uname -a
Darwin macbook.local 10.8.0 Darwin Kernel Version 10.8.0: Tue Jun 7
16:33:36 PDT 2011; root:xnu-1504.15.3~1/RELEASE_I386 i386
$sudo pip install readline ipython
$ipython --version
0.11
$/usr/bin/python --version #
Python 2.7.1
$which python
/Library/Frameworks/Python.framework/Versions/2.7/bin/python
- 我已经阅读了Python sys.path修改中的问题,该问题无法正常工作-我添加`/Library/Frameworks/Python.framework/Versions/2.7/lib/python2.7/site-
- packages/readline-6.2.1-py2.7.egg-info`到,
/Library/Frameworks/Python.framework/Versions/2.7/bin/ipython因此现在看起来像这样:http- //pastebin.com/raw.php?i=dVnxufbS
但我不知道为什么会出现以下错误:
File
"/Library/Frameworks/Python.framework/Versions/2.7/bin/ipython",line 9
sys.path.insert(0,"/Library/Frameworks/Python.framework/Versions/2.7/lib/
python2.7/site-packages/readline-6.2.1-py2.7.egg-info")
我不认为上面的路径是一个问题,我的目标是使ipython正常工作而不会抱怨readline,即使它已正确安装和导入。
")
python .readlines()
filename = os.path.join(container_dir,"info.txt") #
with open(filename) as myfile:
lines = len(myfile.readlines()) #
os.path.join()
路径拼接 container_dir/info.txt
myfile.readlines()
一次性读取整个文件,自动将文件内容分析成一个行的列表。有几行列表里面就有几个元素,lines就是有几行

python 3.2中缺少readline和readlines方法?
解决方法
f.readline() and f.readlines().但实际上您不需要这些方法,因为它们可以被next替换(f)并列出(f).
 使用方法")
Python File readlines() 使用方法
readlines() 方法用于读取所有行(直到结束符 eof)并返回列表,该列表可以由
概述
readlines() 方法用于读取所有行(直到结束符 EOF)并返回列表,该列表可以由 Python 的 for... in ... 结构进行处理。
如果碰到结束符 EOF 则返回空字符串。
语法
立即学习“Python免费学习笔记(深入)”;
readlines() 方法语法如下:
fileObject.readlines( );
参数
无。
返回值
返回列表,包含所有的行。
实例
以下实例演示了 readline() 方法的使用:
文件jb51.txt 的内容如下:
1:www.jb51.net2:www.jb51.net3:www.jb51.net4:www.jb51.net5:www.jb51.net
循环读取文件的内容:
python2的写法
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 打开文件
fo = open("jb51.txt", "r")
print "文件名为: ", fo.name
for line in fo.readlines(): #依次读取每行
line = line.strip() #去掉每行头尾空白
print "读取的数据为: %s" % (line)
# 关闭文件
fo.close()python3的写法
# -*- coding: utf-8 -*-
# 打开文件
fo = open("jb51.txt", "r")
print("文件名为: ",fo.name)
for line in fo.readlines(): #依次读取每行
line = line.strip() #去掉每行头尾空白
print ("读取的数据为: %s" % (line))
# 关闭文件
fo.close()效果如下图所示
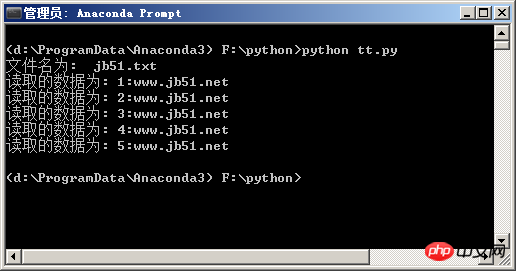
以上就是Python File readlines() 使用方法的详细内容,更多请关注php中文网其它相关文章!
今天关于使Python的readline方法能够识别行尾的两种变化?和python中readlines读取指定行的讲解已经结束,谢谢您的阅读,如果想了解更多关于ipython抱怨readline、python .readlines()、python 3.2中缺少readline和readlines方法?、Python File readlines() 使用方法的相关知识,请在本站搜索。
本文标签:




