对于如何在plotlychloropethmap(python)代码:感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍python中plotly,并为您提供关于2021-11-21:map[i]
对于如何在 plotly chloropeth map (python) 代码:感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍python中plotly,并为您提供关于2021-11-21:map [i][j] == 0,代表 (i,j) 是海洋,渡过的话代价是 2, map [i][j] == 1,代表 (i,j) 是陆地,渡过的话代价是 1, map [i][j] == 2,代表、2022-08-23:以下 go 语言代码输出什么?A:map [baz:2 foo:0];B:map [bar:1 baz:2];C:map [baz:2];D:不确定。 package main impo、chloropeth() 得到了一个意外的关键字参数“位置”、Java 8 Lambdas Map
- 如何在 plotly chloropeth map (python) 代码:(python中plotly)
- 2021-11-21:map [i][j] == 0,代表 (i,j) 是海洋,渡过的话代价是 2, map [i][j] == 1,代表 (i,j) 是陆地,渡过的话代价是 1, map [i][j] == 2,代表
- 2022-08-23:以下 go 语言代码输出什么?A:map [baz:2 foo:0];B:map [bar:1 baz:2];C:map [baz:2];D:不确定。 package main impo
- chloropeth() 得到了一个意外的关键字参数“位置”
- Java 8 Lambdas Map
 代码:(python中plotly)")
如何在 plotly chloropeth map (python) 代码:(python中plotly)
如何解决如何在 plotly chloropeth map (python) 代码:
我正在尝试使用他们在欧洲电视网中的结果来设置欧洲国家的地图。 我有一个按钮可以选择不同的国家(意大利、法国、葡萄牙、英国等...)
例如,如果我选择查看瑞典的结果,我想在地图上看到其他人根据色标给出的点数。我成功了!
但我想形象化瑞典,例如在地图上用黑色显示,以便更好地了解它的位置,以及“符号的邻域效应”。
fig3 = go.figure(data=go.Choropleth(locations=Euro_tr[''Country_code''],# Spatial coordinatesz = Euro_tr[''Italy''],# Data to be color-codedlocationmode = "ISO-3",colorbar_title = "Points donnés",text=Euro_tr[''Country''],))fig3.update_layout(title_text = ''score Eurovision'',margin={"r":55,"t":55,"l":55,"b":55},height=500,geo_scope="europe",)#Make a button for each countrybutton=[]for country in Euro_tr.columns[1:-1] :dico=dict (label=country,method="update",args = [{''z'': [ Euro_tr[country] ] }],)button.append(dico)fig3.update_layout(updatemenus=[dict(buttons=button,y=0.9,x=0,xanchor=''right'',yanchor=''top'',active=0,),])
正如您在显示给予瑞典分数的示例中所见,我希望瑞典采用特定颜色,与其他国家、给予分数的国家和未给予分数的国家无关。

感谢您的帮助!
解决方法
我遵循了@vestland 的回答,并通过使用 fig.add_traces(go.Choropleth)
为了能够根据我感兴趣的国家/地区更改数据和跟踪,我使用了流线型和按钮。
import streamlit as stimport pandas as pdimport numpy as npimport plotly.express as pximport plotly.graph_objects as go# Creation of graphes for each countryGraphes=[]for country in Euro_tr.columns[1:-1] : #To pass each countryGraphe=go.Figure(data=go.Choropleth(locations=Euro_tr[''Country_code''],# Spatial coordinatesz = Euro_tr[country],# Data to be color-codedlocationmode = "ISO-3",colorbar_title = "Points donnés",autocolorscale= False,colorscale="viridis",text=Euro_tr[''Country''],))# customisation : title according to the country and its pointsGraphe.update_layout(title_text = "Total :Points donnés à {fcountry} qui a remporté {fpoints} points".format(fcountry = country,fpoints = Eurovision_tot[''Result_tot''][Eurovision_tot["Country"]==country].values[0]),margin={"r":55,"t":55,"l":55,"b":55},height=500,))# block a specific zoom on the map ( scope "europe" isn''t complete for eurovision countries xD!)Graphe.update_geos(center=dict(lon= 23,lat= 54),lataxis_range=[31.0529,-40.4296],lonaxis_range=[-24,88.2421],projection_scale=3)# add trace for the specific country.Graphe.add_traces(go.Choropleth(locations=Country_df[''Country_code''][Country_df["Country"]==country],z = [1],colorscale = [[0,col_swe],[1,col_swe]],colorbar=None,showscale = False))Graphes.append(Graphe)#creation selectbox to select countrycol12,col22 = st.beta_columns([0.2,0.8]) # I use columns to put the selector on a side and the graph on other sidePays=list(Euro_tr.columns[1:-1]) # List containing country''s nameSelection_Pays = col12.selectbox('''',(Pays)) #create a multiple selector with the different countries as possible choice# define action according to the selection.for country in Pays :if Selection_Pays== country : #if country is selectedcol22.plotly_chart(Graphes[Pays.index(country)]) # plot the corresponding map.

即使您已经使用 px.express 构建您的等值线图,您始终可以使用带有 fig.add_traces(go.Choropleth) 的 plotly.graph_objects 添加跟踪,例如:
col_swe = ''Black''fig.add_traces(go.Choropleth(locations=df_swe[''iso_alpha''],showscale = False))
据我所知,不可能直接为单个国家/地区定义单一颜色,这就是为什么我指定 z=[1] 作为值和自定义比例 colorscale = [[0,col_swe]] 以确保瑞典始终显示为“黑色”。

代码:
import plotly.express as pximport plotly.graph_objects as godf = px.data.gapminder().query("year==2007")fig = px.choropleth(df,locations="iso_alpha",color="lifeExp",# lifeExp is a column of gapminderhover_name="country",# column to add to hover informationcolor_continuous_scale=px.colors.sequential.Plasma)df_swe = df[df[''country'']==''Sweden'']col_swe = ''Black''fig.add_traces(go.Choropleth(locations=df_swe[''iso_alpha''],showscale = False))f = fig.full_figure_for_development(warn=False)fig.show()
![2021-11-21:map [i][j] == 0,代表 (i,j) 是海洋,渡过的话代价是 2, map [i][j] == 1,代表 (i,j) 是陆地,渡过的话代价是 1, map [i][j] == 2,代表](http://www.gvkun.com/zb_users/upload/2025/04/d325dda2-e98d-46ef-9ff0-4dafe09d74291745342116497.jpg "2021-11-21:map [i][j] == 0,代表 (i,j) 是海洋,渡过的话代价是 2, map [i][j] == 1,代表 (i,j) 是陆地,渡过的话代价是 1, map [i][j] == 2,代表")
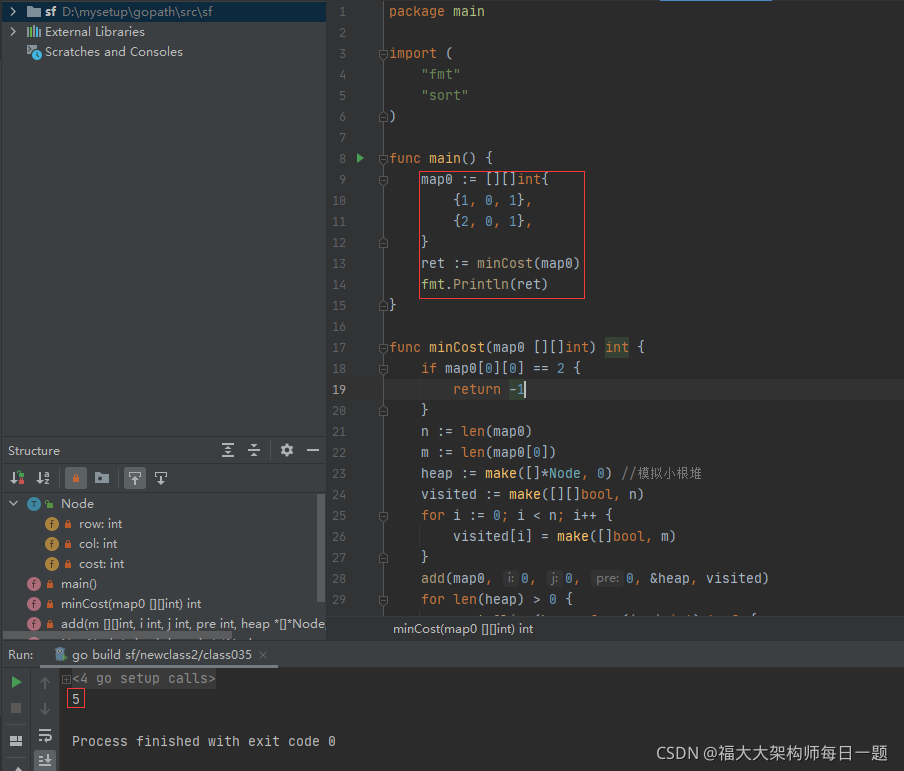
2021-11-21:map [i][j] == 0,代表 (i,j) 是海洋,渡过的话代价是 2, map [i][j] == 1,代表 (i,j) 是陆地,渡过的话代价是 1, map [i][j] == 2,代表
2021-11-21:map [i][j] == 0,代表 (i,j) 是海洋,渡过的话代价是 2,
map [i][j] == 1,代表 (i,j) 是陆地,渡过的话代价是 1,
map [i][j] == 2,代表 (i,j) 是障碍,无法渡过,
每一步上、下、左、右都能走,返回从左上角走到右下角最小代价是多少,如果无法到达返回 - 1。
来自网易。
答案 2021-11-21:
A * 算法。根据代价排小根堆,到最后就是最优解。小根堆空了,返回 - 1。
时间复杂度:O ((N2)*logN)。
额外空间复杂度:O (N2)。
代码用 golang 编写。代码如下:
package main
import (
"fmt"
"sort"
)
func main() {
map0 := [][]int{
{
1, 0, 1},
{
2, 0, 1},
}
ret := minCost(map0)
fmt.Println(ret)
}
func minCost(map0 [][]int) int {
if map0[0][0] == 2 {
return -1
}
n := len(map0)
m := len(map0[0])
heap := make([]*Node, 0) //模拟小根堆
visited := make([][]bool, n)
for i := 0; i < n; i++ {
visited[i] = make([]bool, m)
}
add(map0, 0, 0, 0, &heap, visited)
for len(heap) > 0 {
sort.Slice(heap, func(i, j int) bool {
a := heap[i]
b := heap[j]
return a.cost < b.cost
})
cur := heap[0]
heap = heap[1:]
if cur.row == n-1 && cur.col == m-1 {
return cur.cost
}
add(map0, cur.row-1, cur.col, cur.cost, &heap, visited)
add(map0, cur.row+1, cur.col, cur.cost, &heap, visited)
add(map0, cur.row, cur.col-1, cur.cost, &heap, visited)
add(map0, cur.row, cur.col+1, cur.cost, &heap, visited)
}
return -1
}
func add(m [][]int, i int, j int, pre int, heap *[]*Node, visited [][]bool) {
if i >= 0 && i < len(m) && j >= 0 && j < len(m[0]) && m[i][j] != 2 && !visited[i][j] {
*heap = append(*heap, NewNode(i, j, pre+twoSelectOne(m[i][j] == 0, 2, 1)))
visited[i][j] = true
}
}
type Node struct {
row int
col int
cost int
}
func NewNode(a, b, c int) *Node {
ret := &Node{
}
ret.row = a
ret.col = b
ret.cost = c
return ret
}
func twoSelectOne(c bool, a int, b int) int {
if c {
return a
} else {
return b
}
}执行结果如下:
左神 java 代码
![2022-08-23:以下 go 语言代码输出什么?A:map [baz:2 foo:0];B:map [bar:1 baz:2];C:map [baz:2];D:不确定。 package main impo](http://www.gvkun.com/zb_users/upload/2025/04/f97b4be5-5b4e-49cd-bfd4-6cba05f688b91745342117825.jpg "2022-08-23:以下 go 语言代码输出什么?A:map [baz:2 foo:0];B:map [bar:1 baz:2];C:map [baz:2];D:不确定。 package main impo")
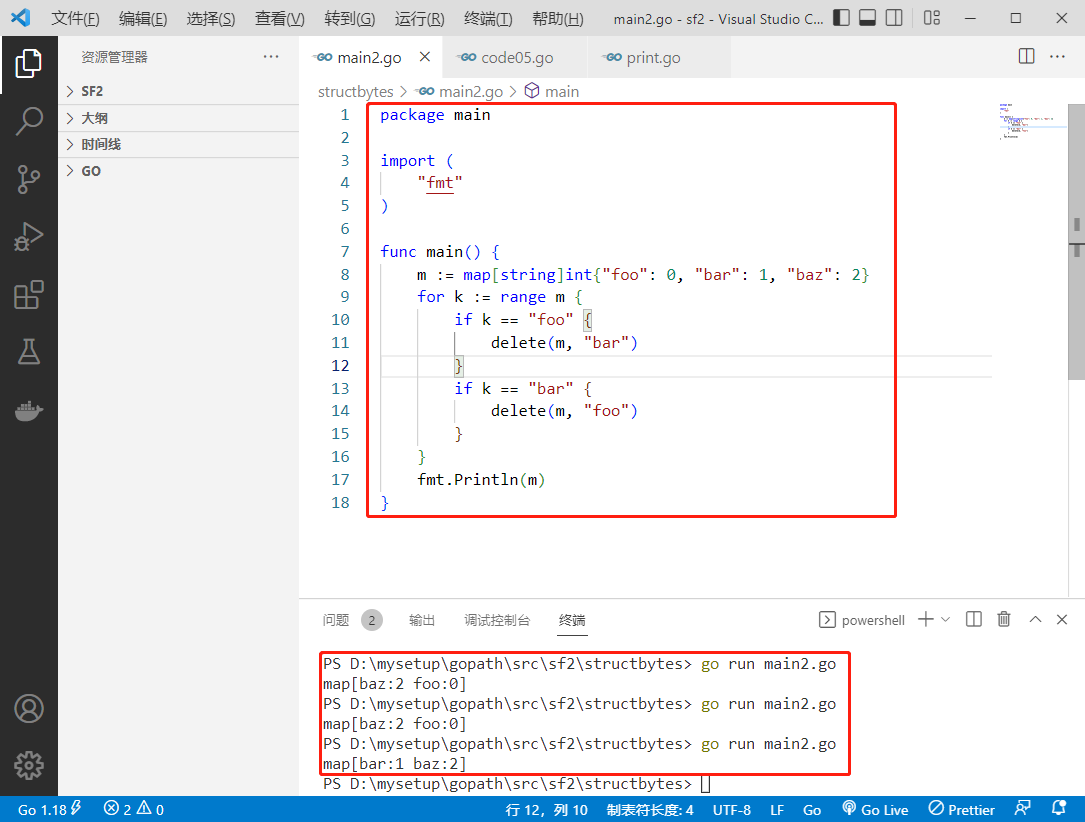
2022-08-23:以下 go 语言代码输出什么?A:map [baz:2 foo:0];B:map [bar:1 baz:2];C:map [baz:2];D:不确定。 package main impo
2022-08-23:以下 go 语言代码输出什么?A:map [baz:2 foo:0];B:map [bar:1 baz:2];C:map [baz:2];D:不确定。
package main
import (
"fmt"
)
func main() {
m := map[string]int{"foo": 0, "bar": 1, "baz": 2}
for k := range m {
if k == "foo" {
delete(m, "bar")
}
if k == "bar" {
delete(m, "foo")
}
}
fmt.Println(m)
}
答案 2022-08-23:
答案选 D。因为 map 中元素顺序是随机的,因此结果不确定,每次运行结果可能不一样。
 得到了一个意外的关键字参数“位置”")
chloropeth() 得到了一个意外的关键字参数“位置”
从 plotly.express.choropleth() 开始,plotly.express.choropleth() 有参数 locations 而不是 location。

Java 8 Lambdas Map 到 Map>
如何解决Java 8 Lambdas Map<String, String> 到 Map<String, Map<String, Long>>
我有一个服务可以返回响应并将其映射到 Map<String,String> object
在此之后,我需要计算新地图的键并插入所有出现的键以及它们出现的次数。
它们的键是通过获取关联字符串的第一个字符来计算的。
Key: A -> August/Air
Key: B -> Boat/Big
示例:
服务响应:
{
{
"august","red"
},{
"air",{
"boat","blue"
},{
"big","red"
}
}
预期输出:
{
"a" : {
"red" : 2
},"b" : {
"blue" : 1,"red": 1
}
}
我已经在 Java 7 中做到了这一点,但我想将 lambdas 应用于此。
Map<String,Map<String,AtomicLong>> map = new HashMap<>();
String key = ...
String value = ...
Response.incrementCount(key,value);
map.put(key,Response.count.get(key));
响应.java
public static Map<String,AtomicLong>> count = new HashMap<>();
public static void incrementCount(String key,String value) {
count.computeIfAbsent(key,k -> new HashMap<>());
AtomicLong actual = count.get(key).get(value);
Map<String,AtomicLong> stringAtomicLongMap = count.get(key);
if (null == actual) {
actual = new AtomicLong();
stringAtomicLongMap.put(value,actual);
count.put(key,stringAtomicLongMap);
}
actual.incrementAndGet();
}
解决方法
现有的 Map<String,String> map 应该这样转换:
- 按key的第一个字符分组
- 对于值,按值和计数频率分组
static Map<String,Map<String,Long>> convert(Map<String,String> map) {
return map.entrySet()
.stream()
.collect(Collectors.groupingBy(
e -> e.getKey().substring(0,1),LinkedHashMap::new,// (optionally) use to keep insertion order
Collectors.groupingBy(
Map.Entry::getValue,Collectors.counting()
)
));
}
测试:
Map<String,String> map = Map.of(
"august","red","air","boat","blue","big","red"
);
Map<String,Long>> result = convert(map);
result.forEach((k,v) -> System.out.printf("''%s'': %s%n",k,v));
输出:
''a'': {red=2}
''b'': {red=1,blue=1}
这是使用 Stream API 的解决方案:
Map<String,Long>> resultMap = map.entrySet().stream()
.map(entry -> {
String firstChar = entry.getKey().substring(0,1);
return new AbstractMap.SimpleEntry<>(firstChar,entry.getValue());
})
.collect(Collectors.groupingBy(
Map.Entry::getKey,Collectors.groupingBy(Map.Entry::getValue,Collectors.counting())
));
实际发生的事情:
- 给定的条目更改为只有第一个字符(但作为字符串)作为条目的键
- 此类条目按键(第一个字符)分组
- 如果此键有多个值 - 它们按条目值分组 - 并对这些值进行计数
我们今天的关于如何在 plotly chloropeth map (python) 代码:和python中plotly的分享已经告一段落,感谢您的关注,如果您想了解更多关于2021-11-21:map [i][j] == 0,代表 (i,j) 是海洋,渡过的话代价是 2, map [i][j] == 1,代表 (i,j) 是陆地,渡过的话代价是 1, map [i][j] == 2,代表、2022-08-23:以下 go 语言代码输出什么?A:map [baz:2 foo:0];B:map [bar:1 baz:2];C:map [baz:2];D:不确定。 package main impo、chloropeth() 得到了一个意外的关键字参数“位置”、Java 8 Lambdas Map
本文标签:




