针对如何使用python将.txt文件转换为xml文件?和python将txt文件转换成excel这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展java实现excel文件转换为xml文件、
针对如何使用python将.txt文件转换为xml文件?和python将txt文件转换成excel这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展java实现excel文件转换为xml文件、python csv文件转换成xml, 构建新xml文件、Python – 将非常大(6.4GB)的XML文件转换为JSON、python 将txt文件转为csv文件等相关知识,希望可以帮助到你。
本文目录一览:- 如何使用python将.txt文件转换为xml文件?(python将txt文件转换成excel)
- java实现excel文件转换为xml文件
- python csv文件转换成xml, 构建新xml文件
- Python – 将非常大(6.4GB)的XML文件转换为JSON
- python 将txt文件转为csv文件
")
如何使用python将.txt文件转换为xml文件?(python将txt文件转换成excel)
Latitude :23.1100348Longitude:72.5364922date&time :30:August:2014 05:04:31 PMgsm cell id: 4993Neighboring List- Lac : Cid : RSSI15000 : 7072 : 25 dBm15000 : 7073 : 23 dBm15000 : 6102 : 24 dBm15000 : 6101 : 24 dBm15000 : 6103 : 17 dBmLatitude :23.1120549Longitude:72.5397988date&time :30:August:2014 05:04:34 PMgsm cell id: 4993Neighboring List- Lac : Cid : RSSI15000 : 7072 : 24 dBm15000 : 7073 : 22 dBm15000 : 6102 : 23 dBm15000 : 6101 : 23 dBm15000 : 2552 : 16 dBm这是my.txt文件,我想将其转换为xml文件,例如
<celldata><time> </time><latitude> </latitude><longitude> </longitude></celldata>我试图列出所有组件,但我没有得到O / P,我想将纬度,经度,gsm单元格ID,时间的所有值存储在列表中,这将在xml文件中添加类似内容。我写下面的代码。
import repa = ''Longitude|Latitude|gsm cell id|Neighboring List- Lac : Cid : RSSI''with open(''cell.txt'',''rw'') as file: for line in file: line.strip() if re.search(pa, line): lineInfo = line.split('':'') title = lineInfo[0] value = lineInfo[1]答案1
小编典典尝试以下代码作为入门:
#!python3import reimport xml.etree.ElementTree as ETrex = re.compile(r''''''(?P<title>Longitude |Latitude |date&time |gsm\s+cell\s+id ) \s*:?\s* (?P<value>.*) '''''', re.VERBOSE)root = ET.Element(''root'')root.text = ''\n'' # newline before the celldata elementwith open(''cell.txt'') as f: celldata = ET.SubElement(root, ''celldata'') celldata.text = ''\n'' # newline before the collected element celldata.tail = ''\n\n'' # empty line after the celldata element for line in f: # Empty line starts new celldata element (hack style, uggly) if line.isspace(): celldata = ET.SubElement(root, ''celldata'') celldata.text = ''\n'' celldata.tail = ''\n\n'' # If the line contains the wanted data, process it. m = rex.search(line) if m: # Fix some problems with the title as it will be used # as the tag name. title = m.group(''title'') title = title.replace(''&'', '''') title = title.replace('' '', '''') e = ET.SubElement(celldata, title.lower()) e.text = m.group(''value'') e.tail = ''\n''# Display for debugging ET.dump(root)# Include the root element to the tree and write the tree# to the file.tree = ET.ElementTree(root)tree.write(''cell.xml'', encoding=''utf-8'', xml_declaration=True)它显示您的示例数据:
<root><celldata><latitude>23.1100348</latitude><longitude>72.5364922</longitude><datetime>30:August:2014 05:04:31 PM</datetime><gsmcellid>4993</gsmcellid></celldata><celldata><latitude>23.1120549</latitude><longitude>72.5397988</longitude><datetime>30:August:2014 05:04:34 PM</datetime><gsmcellid>4993</gsmcellid></celldata></root>所需近邻列表的更新:
#!python3import reimport xml.etree.ElementTree as ETrex = re.compile(r''''''(?P<title>Longitude |Latitude |date&time |gsm\s+cell\s+id |Neighboring\s+List-\s+Lac\s+:\s+Cid\s+:\s+RSSI ) \s*:?\s* (?P<value>.*) '''''', re.VERBOSE)root = ET.Element(''root'')root.text = ''\n'' # newline before the celldata elementwith open(''cell.txt'') as f: celldata = ET.SubElement(root, ''celldata'') celldata.text = ''\n'' # newline before the collected element celldata.tail = ''\n\n'' # empty line after the celldata element for line in f: # Empty line starts new celldata element (hack style, uggly) if line.isspace(): celldata = ET.SubElement(root, ''celldata'') celldata.text = ''\n'' celldata.tail = ''\n\n'' else: # If the line contains the wanted data, process it. m = rex.search(line) if m: # Fix some problems with the title as it will be used # as the tag name. title = m.group(''title'') title = title.replace(''&'', '''') title = title.replace('' '', '''') if line.startswith(''Neighboring''): neighbours = ET.SubElement(celldata, ''neighbours'') neighbours.text = ''\n'' neighbours.tail = ''\n'' else: e = ET.SubElement(celldata, title.lower()) e.text = m.group(''value'') e.tail = ''\n'' else: # This is the neighbour item. Split it by colon, # and set the attributes of the item element. item = ET.SubElement(neighbours, ''item'') item.tail = ''\n'' lac, cid, rssi = (a.strip() for a in line.split('':'')) item.attrib[''lac''] = lac item.attrib[''cid''] = cid item.attrib[''rssi''] = rssi.split()[0] # dBm removed# Include the root element to the tree and write the tree# to the file.tree = ET.ElementTree(root)tree.write(''cell.xml'', encoding=''utf-8'', xml_declaration=True)更新以在邻居之前接受空行 -更好的通用实现:
#!python3import reimport xml.etree.ElementTree as ETrex = re.compile(r''''''(?P<title>Longitude |Latitude |date&time |gsm\s+cell\s+id |Neighboring\s+List-\s+Lac\s+:\s+Cid\s+:\s+RSSI ) \s*:?\s* (?P<value>.*) '''''', re.VERBOSE)root = ET.Element(''root'')root.text = ''\n'' # newline before the celldata elementwith open(''cell.txt'') as f: celldata = ET.SubElement(root, ''celldata'') celldata.text = ''\n'' # newline before the collected element celldata.tail = ''\n\n'' # empty line after the celldata element status = 0 # init status of the finite automaton for line in f: if status == 0: # lines of the heading expected # If the line contains the wanted data, process it. m = rex.search(line) if m: # Fix some problems with the title as it will be used # as the tag name. title = m.group(''title'') title = title.replace(''&'', '''') title = title.replace('' '', '''') if line.startswith(''Neighboring''): neighbours = ET.SubElement(celldata, ''neighbours'') neighbours.text = ''\n'' neighbours.tail = ''\n'' status = 1 # empty line and then list of neighbours expected else: e = ET.SubElement(celldata, title.lower()) e.text = m.group(''value'') e.tail = ''\n'' # keep the same status elif status == 1: # empty line expected if line.isspace(): status = 2 # list of neighbours must follow else: raise RuntimeError(''Empty line expected. (status == {})''.format(status)) status = 999 # error status elif status == 2: # neighbour or the empty line as final separator if line.isspace(): celldata = ET.SubElement(root, ''celldata'') celldata.text = ''\n'' celldata.tail = ''\n\n'' status = 0 # go to the initial status else: # This is the neighbour item. Split it by colon, # and set the attributes of the item element. item = ET.SubElement(neighbours, ''item'') item.tail = ''\n'' lac, cid, rssi = (a.strip() for a in line.split('':'')) item.attrib[''lac''] = lac item.attrib[''cid''] = cid item.attrib[''rssi''] = rssi.split()[0] # dBm removed # keep the same status elif status == 999: # error status -- break the loop break else: raise LogicError(''Unexpected status {}.''.format(status)) break# Display for debuggingET.dump(root)# Include the root element to the tree and write the tree# to the file.tree = ET.ElementTree(root)tree.write(''cell.xml'', encoding=''utf-8'', xml_declaration=True)该代码实现了所谓的 有限自动机 ,其中status变量代表其当前状态。您可以使用铅笔和纸来可视化它-
用内部状态数字绘制一个小圆圈(在图论中称为节点)。处于状态时,您仅允许某种输入(line)。识别输入后,您将箭头(图论中的定向边)绘制到另一种状态(可能是同一状态,就像循环返回到同一节点一样)。箭头标有“条件|
行动’。
一开始的结果可能看起来很复杂;但是,从某种意义上说,您总是可以只专注于属于特定状态的代码部分,这很容易。而且,可以轻松修改代码。但是,有限自动机的功能有限。但是它们只是解决此类问题的理想之选。

java实现excel文件转换为xml文件
一、导包:
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>3.17</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-examples</artifactId>
<version>3.16</version>
</dependency>
<dependency>
<groupId>org.jdom</groupId>
<artifactId>jdom</artifactId>
<version>1.1.3</version>
</dependency>
二、代码部分:
public class AnalysisEtoX {
public static void main(String[] args) {
try {
System.out.println("=============");
// 用输入流从本地拿到对应的Excel文件
InputStream stream = new FileInputStream("C:\\Users\\Administrator\\Desktop\\试题.xlsx");
// 指定要生成的xml的路径,并构建文件对象
File f = new File("test.xml");// 新建个file对象把解析之后得到的xml存入改文件中
writerXML(stream, f);// 将数据以xml形式写入文本
} catch (FileNotFoundException e) {
System.out.println("未找到指定路径的文件!");
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
private static void writerXML(InputStream stream, File f) throws IOException {
System.out.println("into writerXML");
FileOutputStream fo = new FileOutputStream(f);// 得到输入流
Document doc = readExcell(stream);// 读取EXCEL函数
Format format = Format.getCompactFormat().setEncoding("UTF-8").setIndent("");
XMLOutputter XMLOut = new XMLOutputter(format);// 在元素后换行,每一层元素缩排四格
XMLOut.output(doc, fo);
fo.close();
}
private static Document readExcell(InputStream stream) {
System.out.println("into readExcell");
// 设置根<tax_institutions></tax_institutions>元素
Element root = new Element("tax_institutions");
Document doc = new Document(root);
try {
HSSFWorkbook hw = new HSSFWorkbook(stream);
// 获取工作薄的个数,即一个excel文件中包含了多少个Sheet工作簿
int WbLength = hw.getNumberOfSheets();
System.out.println("WbLength=" + WbLength);
for (int i = 0; i < WbLength; i++) {
HSSFSheet shee = hw.getSheetAt(i);
int length = shee.getLastRowNum();
System.out.println("行数:" + length);
for (int j = 1; j <= length; j++) {
HSSFRow row = shee.getRow(j);
if (row == null) {
continue;
}
int cellNum = row.getPhysicalNumberOfCells();// 获取一行中最后一个单元格的位置
System.out.println("列数cellNum:" + cellNum);
Element e = null;
// 设置根元素下的并列元素<tax_institution></tax_institution>
e = new Element("tax_institution");
// Element[] es = new Element[16];
for (int k = 0; k < cellNum; k++) {
HSSFCell cell = row.getCell((short) k);
String temp = get(k);
System.out.print(k + " " + temp + ":");
Element item = new Element(temp);
if (cell == null) {
item.setText("");
e.addContent(item);
cellNum++;// 如果存在空列,那么cellNum增加1,这一步很重要。
continue;
}
else {
String cellvalue = "";
switch (cell.getCellType()) {
// 如果当前Cell的Type为NUMERIC
case HSSFCell.CELL_TYPE_NUMERIC:
case HSSFCell.CELL_TYPE_FORMULA: {
// 判断当前的cell是否为Date
if (HSSFDateUtil.isCellDateFormatted(cell)) {
// 如果是Date类型则,转化为Data格式
// 方法1:这样子的data格式是带时分秒的:2011-10-12 0:00:00
// cellvalue =
cell.getDateCellValue().toLocaleString();
// 方法2:这样子的data格式是不带带时分秒的:2011-10-12
Date date = cell.getDateCellValue();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
cellvalue = sdf.format(date);
item.setText(cellvalue);
}
// 如果是纯数字
else {
// 取得当前Cell的数值
cellvalue = String.valueOf((int) cell.getNumericCellValue());
item.setText(cellvalue);
}
break;
}
// 如果当前Cell的Type为STRIN
case HSSFCell.CELL_TYPE_STRING:
// 取得当前的Cell字符串
cellvalue = cell.getRichStringCellValue().getString();
item.setText(cellvalue);
break;
// 默认的Cell值
default:
cellvalue = " ";
item.setText(cellvalue);
}
e.addContent(item);
System.out.println(cellvalue);
}
}
root.addContent(e);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
stream.close();
} catch (IOException e1) {
e1.printStackTrace();
}
}
return doc;
}
// 设置并列元素里的子元素名
private static String get(int k) {
String test = "";
switch (k) {
case 0:
test = "org_name";
break;
case 1:
test = "legal_mobile_phone";
break;
case 2:
test = "org_address";
break;
case 3:
test = "cert_type";
break;
case 4:
test = "postal_code";
break;
case 5:
test = "reg_sum";
break;
case 6:
test = "business_scope";
break;
case 7:
test = "social_credit_code";
break;
case 8:
test = "reg_type";
break;
case 9:
test = "legal_person_name";
break;
case 10:
test = "cert_number";
break;
case 11:
test = "found_time";
break;
case 12:
test = "service_status";
break;
case 13:
test = "staff_sum";
break;
case 14:
test = "partner_sum";
break;
case 15:
test = "is_branch_org";
break;
default:
}
return test;
}
}转载地址csdn:https://blog.csdn.net/weixin_40420734/article/details/79538772
注意:
excel版本保存文件的后缀名问题,如果是.xls,使用HSSFWorkbook;如果是xlsx,使用XSSFWorkbook。
版本错误会抛出OfficeXmlFileException!!!
原文出处:https://www.cnblogs.com/Pamper-Chen/p/10291004.html

python csv文件转换成xml, 构建新xml文件
csv文件
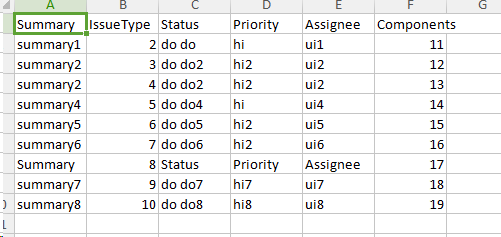
code
from xml.etree.ElementTree import Element,ElementTree,tostring
import json,csv
def csvtoxml(fname):
with open(fname,''r'') as f:
reader=csv.reader(f)
header=next(reader)
root=Element(''Daaa'')
print(''root'',len(root))
for row in reader:
erow=Element(''Row'')
root.append(erow)
for tag,text in zip(header,row):
e=Element(tag)
e.text=text
erow.append(e)
beatau(root)
return ElementTree(root)
def beatau(e,level=0):
if len(e)>0:
e.text=''\n''+''\t''*(level+1)
for child in e:
beatau(child,level+1)
child.tail=child.tail[:-1]
e.tail=''\n'' + ''\t''*level
et=csvtoxml(r''C:\Temp\ff.csv'')
et.write(r''C:\Temp\fff.xml'')
out
<Daaa>
<Row>
<Summary>summary1</Summary>
<IssueType>2</IssueType>
<Status>do do</Status>
<Priority>hi</Priority>
<Assignee>ui1</Assignee>
<Components>11</Components>
</Row>
<Row>
<Summary>summary2</Summary>
<IssueType>3</IssueType>
<Status>do do2</Status>
<Priority>hi2</Priority>
<Assignee>ui2</Assignee>
<Components>12</Components>
</Row>
<Row>
<Summary>summary2</Summary>
<IssueType>4</IssueType>
<Status>do do2</Status>
<Priority>hi2</Priority>
<Assignee>ui2</Assignee>
<Components>13</Components>
</Row>
<Row>
<Summary>summary4</Summary>
<IssueType>5</IssueType>
<Status>do do4</Status>
<Priority>hi</Priority>
<Assignee>ui4</Assignee>
<Components>14</Components>
</Row>
<Row>
<Summary>summary5</Summary>
<IssueType>6</IssueType>
<Status>do do5</Status>
<Priority>hi2</Priority>
<Assignee>ui5</Assignee>
<Components>15</Components>
</Row>
<Row>
<Summary>summary6</Summary>
<IssueType>7</IssueType>
<Status>do do6</Status>
<Priority>hi2</Priority>
<Assignee>ui6</Assignee>
<Components>16</Components>
</Row>
<Row>
<Summary>Summary</Summary>
<IssueType>8</IssueType>
<Status>Status</Status>
<Priority>Priority</Priority>
<Assignee>Assignee</Assignee>
<Components>17</Components>
</Row>
<Row>
<Summary>summary7</Summary>
<IssueType>9</IssueType>
<Status>do do7</Status>
<Priority>hi7</Priority>
<Assignee>ui7</Assignee>
<Components>18</Components>
</Row>
<Row>
<Summary>summary8</Summary>
<IssueType>10</IssueType>
<Status>do do8</Status>
<Priority>hi8</Priority>
<Assignee>ui8</Assignee>
<Components>19</Components>
</Row>
</Daaa>
的XML文件转换为JSON")
Python – 将非常大(6.4GB)的XML文件转换为JSON
print 'opening'
f = open('large.xml','r')
data = f.read()
f.close()
print 'Converting'
newJSON = xmltodict.parse(data)
print 'Json Dumping'
newJSON = json.dumps(newJSON)
print 'Saving'
f = open('newjson.json','w')
f.write(newJSON)
f.close()
错误:
Python(2461) malloc: *** mmap(size=140402048315392) Failed (error code=12)
*** error: can't allocate region
*** set a breakpoint in malloc_error_break to debug
Traceback (most recent call last):
File "/Users/user/Git/Resources/largexml2json.py",line 10,in <module>
data = f.read()
MemoryError
解决方法
您使用的xmltodict库也具有流模式.我认为它可以解决你的问题
https://github.com/martinblech/xmltodict#streaming-mode

python 将txt文件转为csv文件
import csv
a = []
f = open('follow_name_1.txt','r',encoding='utf-8')
line = f.readline()
while line:
a.append(line.split())#保存文件是以空格分离的
line = f.readline()
f.close()
fp = open('follow_name_1.csv','w',encoding='utf_8_sig',newline="")
csvwriter=csv.writer(fp)
csvwriter.writerows(a)
print("finish")
关于如何使用python将.txt文件转换为xml文件?和python将txt文件转换成excel的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于java实现excel文件转换为xml文件、python csv文件转换成xml, 构建新xml文件、Python – 将非常大(6.4GB)的XML文件转换为JSON、python 将txt文件转为csv文件的相关知识,请在本站寻找。
本文标签:




