在本文中,我们将详细介绍Python:如何使用Python访问mp3文件的元数据?的各个方面,并为您提供关于python读取mp3文件的相关解答,同时,我们也将为您带来关于IronPython的任何替
在本文中,我们将详细介绍Python:如何使用Python访问mp3文件的元数据?的各个方面,并为您提供关于python读取mp3文件的相关解答,同时,我们也将为您带来关于IronPython的任何替代品,Python for .NET用于从python访问CLR?、Python 教程:如何使用 Python 分割和合并大文件?、python-3.x – 如何使用Python访问存储桶GCS的子文件夹中的文件?、Python-如何使用Python连接到MySQL数据库?的有用知识。
本文目录一览:- Python:如何使用Python访问mp3文件的元数据?(python读取mp3文件)
- IronPython的任何替代品,Python for .NET用于从python访问CLR?
- Python 教程:如何使用 Python 分割和合并大文件?
- python-3.x – 如何使用Python访问存储桶GCS的子文件夹中的文件?
- Python-如何使用Python连接到MySQL数据库?
")
Python:如何使用Python访问mp3文件的元数据?(python读取mp3文件)
假设我想查看艺术家姓名?或添加BPM信息?我可以使用哪些Python工具执行此操作?

IronPython的任何替代品,Python for .NET用于从python访问CLR?
解决方法
(我对.NET com interop还不太了解,所以希望其他人可以提供进一步的解释.)

Python 教程:如何使用 Python 分割和合并大文件?
有时候,我们需要把一个大文件发送给别人,但是限于传输通道的限制,比如邮箱附件大小的限制,或者网络状况不太好,需要将大文件分割成小文件,分多次发送,接收端再对这些小文件进行合并。今天就来分享一下用 Python 分割合并大文件的方法。
思路及实现
如果是文本文件,可以按行数分割。无论是文本文件还是二进制文件,都可以按指定大小进行分割。
使用 Python 的文件读写功能就可以实现文件的分割与合并,设置每个文件的大小,然后读取指定大小的字节就写入一个新文件,接收端依次读取小文件,把读取到的字节按序写入一个文件,就可以完成合并。
分割
size = 1024 * 1000 * 10# 10MB
with open("bigfile", "rb") as reader:
part = 1
while True:
part_content = reader.read(size)
if not part_content:
print("split done.")
break
with open(f"bigfile_part{part}","wb") as writer:
writer.write(part_content)合并
total_parts = 5
with open("bigfile","wb") as writer:
for i in range(5):
with open(f"bigfile_part{i}", "rb") as reader:
writer.write(reader.read())使用第三方库
虽然可以自己写,但是别人写好了,为什么不节省点时间直接用呢?直接 pip 安装就可以了:
pip install filesplit
分割
from filesplit.split import Split
split = Split("./data.rar", "./output")
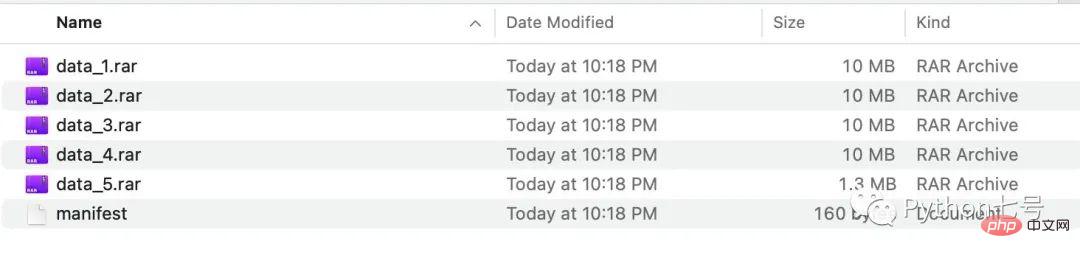
split.bysize(size = 1024*1000*10) # 每个文件最多 10MB执行之后,我们就可以在 output 文件夹里看到分割好的文件:
你也可以按照文件行数进行分割:
split.bylinecount(linecount = 10000) # 每个文件最多 10000 行
合并
合并需要对文件夹里的小文件进行合并,该工具要求文件夹内必须有 manifest 文件,其格式如下:
filename,filesize,header data_1.rar,10000000,False data_2.rar,10000000,False data_3.rar,10000000,False data_4.rar,10000000,False data_5.rar,1304145,False
合并文件的代码只需要指定要合并的目录,目标目录,合并后的文件名,代码如下:
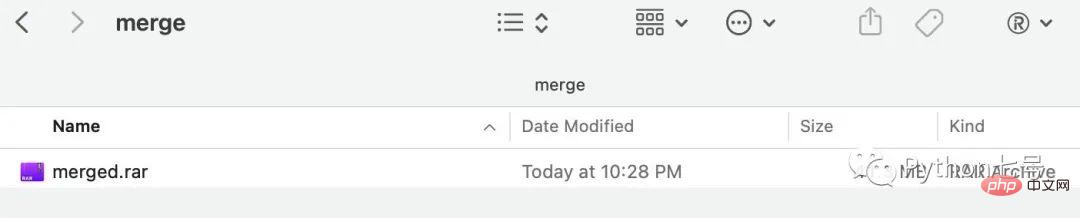
from filesplit.merge import Merge merge = Merge(inputdir = "./output", outputdir="./merge", outputfilename = "merged.rar") merge.merge()
执行之后就可以在 merge 目录内看到合并后的文件:
以上就是Python 教程:如何使用 Python 分割和合并大文件?的详细内容,更多请关注php中文网其它相关文章!

python-3.x – 如何使用Python访问存储桶GCS的子文件夹中的文件?
from google.cloud import storage
import os
bucket = client.get_bucket('path to bucket')
上面的代码将我连接到我的桶,但我很难连接到桶中的特定文件夹.
我正在尝试此代码的变体,但没有运气:
blob = bucket.get_blob("training/bad")
blob = bucket.get_blob("/training/bad")
blob = bucket.get_blob("path to bucket/training/bad")
我希望能够访问坏子文件夹中的图像列表,但我似乎无法这样做.
尽管阅读了文档,我甚至都不完全理解blob是什么,而是基于教程来实现它.
谢谢.
解决方法
list_blobs()函数指定前缀和分隔符参数
请参阅以下来自Google Listing Objects example(也是GitHub snippet)的示例
def list_blobs_with_prefix(bucket_name,prefix,delimiter=None):
"""Lists all the blobs in the bucket that begin with the prefix.
This can be used to list all blobs in a "folder",e.g. "public/".
The delimiter argument can be used to restrict the results to only the
"files" in the given "folder". Without the delimiter,the entire tree under
the prefix is returned. For example,given these blobs:
/a/1.txt
/a/b/2.txt
If you just specify prefix = '/a',you'll get back:
/a/1.txt
/a/b/2.txt
However,if you specify prefix='/a' and delimiter='/',you'll get back:
/a/1.txt
"""
storage_client = storage.Client()
bucket = storage_client.get_bucket(bucket_name)
blobs = bucket.list_blobs(prefix=prefix,delimiter=delimiter)
print('Blobs:')
for blob in blobs:
print(blob.name)
if delimiter:
print('Prefixes:')
for prefix in blobs.prefixes:
print(prefix)

Python-如何使用Python连接到MySQL数据库?
如何使用python程序连接到MySQL数据库?
答案1
小编典典分三步使用Python 2连接到MYSQL
1-设定
在执行任何操作之前,必须安装MySQL驱动程序。与PHP不同,默认情况下,Python仅安装SQLite驱动程序。最常用的软件包是MySQLdb,但很难使用easy_install进行安装。请注意,MySQLdb仅支持Python 2。
对于Windows用户,你可以获取MySQLdb的exe。
对于Linux,这是一个临时包(python-mysqldb)。(你可以在命令行中使用sudo apt-get install python-mysqldb(对于基于debian的发行版),yum install MySQL-python(对于基于rpm的dnf install python-mysql发行版)或(对于现代的fedora发行版)进行下载。)
对于Mac,你可以使用Macport安装MySQLdb。
2-用法
安装后,重新启动。这不是强制性的,但是如果出现问题,它将阻止我回答本文中的3或4个其他问题。因此,请重新启动。
然后就像使用其他任何软件包一样:
#!/usr/bin/pythonimport MySQLdbdb = MySQLdb.connect(host="localhost", # your host, usually localhost user="john", # your username passwd="megajonhy", # your password db="jonhydb") # name of the data base# you must create a Cursor object. It will let# you execute all the queries you needcur = db.cursor()# Use all the SQL you likecur.execute("SELECT * FROM YOUR_TABLE_NAME")# print all the first cell of all the rowsfor row in cur.fetchall(): print row[0]db.close()当然,有成千上万种可能性和选择。这是一个非常基本的例子。你将不得不查看文档。一个良好的起点。
3-更高级的用法
一旦知道了它的工作原理,你可能希望使用ORM来避免手动编写SQL并像处理Python对象一样处理表。Python社区中最著名的ORM是SQLAlchemy。
我强烈建议你使用它:你的生活将变得更加轻松。
我最近在Python世界中发现了另一件珠宝:peewee。这是一个非常精简的ORM,设置起来非常简单快捷。对于小型项目或独立应用程序来说,这让我感到欣慰,而在使用SQLAlchemy或Django等大型工具的情况下,这太过残酷了:
import peeweefrom peewee import *db = MySQLDatabase(''jonhydb'', user=''john'', passwd=''megajonhy'')class Book(peewee.Model): author = peewee.CharField() title = peewee.TextField() class Meta: database = dbBook.create_table()book = Book(author="me", title=''Peewee is cool'')book.save()for book in Book.filter(author="me"): print book.title本示例开箱即用。除了带有peewee(pip install peewee)外,没有其他要求。
关于Python:如何使用Python访问mp3文件的元数据?和python读取mp3文件的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于IronPython的任何替代品,Python for .NET用于从python访问CLR?、Python 教程:如何使用 Python 分割和合并大文件?、python-3.x – 如何使用Python访问存储桶GCS的子文件夹中的文件?、Python-如何使用Python连接到MySQL数据库?等相关知识的信息别忘了在本站进行查找喔。
本文标签:




