本文将带您了解关于如何从Prometheus获得上周的“UP”指标计数=0?的新内容,同时我们还将为您解释prometheus常用指标的相关知识,另外,我们还将为您提供关于k8sprometheus监
本文将带您了解关于如何从 Prometheus 获得上周的“UP”指标计数 = 0?的新内容,同时我们还将为您解释prometheus 常用指标的相关知识,另外,我们还将为您提供关于k8s prometheus监控指标、kube-prometheus和prometheus-operator教程之实战和原理介绍、Prometheus Operator 与 kube-prometheus 之一-简介、Prometheus Operator 教程:根据服务维度对 Prometheus 分片的实用信息。
本文目录一览:- 如何从 Prometheus 获得上周的“UP”指标计数 = 0?(prometheus 常用指标)
- k8s prometheus监控指标
- kube-prometheus和prometheus-operator教程之实战和原理介绍
- Prometheus Operator 与 kube-prometheus 之一-简介
- Prometheus Operator 教程:根据服务维度对 Prometheus 分片
")
如何从 Prometheus 获得上周的“UP”指标计数 = 0?(prometheus 常用指标)
我认为您正在寻找可用性指标。
使用以下查询了解上周 XYZ 作业可用的百分比:
100*avg_over_time(up{job="XYZ"}[1w])
如果您想知道不可用,请执行以下操作:
100-100*avg_over_time(up{job="XYZ"}[1w])

k8s prometheus监控指标
k8s-prometheus监控指标
1. k8s-prometheus监控指标
-
Kubernetes本身监控
- Node资源利用率
- Node数量
- 每个Node运行Pod数量
- 资源对象状态
-
Pod监控
- Pod总数量及每个控制器预期数量
- Pod状态
- 容器资源利用率:cpu、内存、网络
-
监控实现思路
监控指标 具体实现 举例 Pod性能 cAdvisor cpu、内存、网络等 Node性能 node-exporter cpu、内存、网络等 K8S资源对象 kube-state-metrics Pod、Deployment、Service kubelet的节点使用cAdvisor提供的metrics接口获取该节点所有Pod和容器相关的性能指标数据。
指标接口:https://NodeIP:10250/metrics/cadvisor
-
Node
使用node_exporter收集器采集节点资源利用率。
项目地址:https://github.com/prometheus/node_exporter
-
k8s资源对象
kube-state-metrics采集了k8s中各种资源对象的状态信息。
项目地址:https://github.com/kubernetes/kube-state-metrics
-

kube-prometheus和prometheus-operator教程之实战和原理介绍
这一切的一切仅在这里
- kube-prometheus和prometheus-operator史诗级教程
prometheus-guidebook git仓库地址
- guidebook仓库地址
kube-prometheus解决了哪些问题

- 一键化部署k8s-prometheus中的所有组件
- 复杂的k8s采集自动生成
- 内置了很多alert和record rule,专业的promql,不用我们自己写了
- 多级嵌套的record计算如apiserver的slo
- 使用 Prometheus Operator 框架及其自定义资源,使指标的接入可以由业务方自行配置,无需监控管理员介入
kube-prometheus采集难点

kube-prometheus内置的k8s采集任务都采集了什么
- 怎么采集到了
- 为什么要采集这些
- 用了哪些优化手段
kube-prometheus内置的grafana-dashboard看图分析难点

内置的grafana-dashboard看图都包含什么图表
- 为什么要设置这些图表
- 6层slo预聚合到底怎么做的
- 动态dashboard怎么实现的
kube-prometheus内置的告警和预聚合分析,6层预聚合slo原理

- 内置的告警包含哪些规则
- 怎么配置上去的
- apiserver6层slo预聚合到底怎么做的
- 我怎样去自定义规则
kube-rbac 鉴权是干什么的
- 为什么要加着一层
- 和envoy项目什么关系
- 如果代理upstream的流量
怎样把我自定义的指标应用到prometheus-operator中

- 如何用go编写项目部署到k8s的pod中
- prometheus原始的k8s_pod_sd怎么采集自定义指标
- 怎样使用serviceMonitor方式接入
如何利用阿里云构建国外的镜像



- 为何要关闭代码缓存
这一切的一切仅在这里
- kube-prometheus和prometheus-operator史诗级教程

Prometheus Operator 与 kube-prometheus 之一-简介
简介
Prometheus Operator
Prometheus Operator: 在 Kubernetes 上管理 Prometheus 集群。该项目的目的是简化和自动化基于 Prometheus 的 Kubernetes 集群监控堆栈的配置。
kube-prometheus
最简单的方法是将 Prometheus Operator 作为 kube-prometheus 的一部分进行部署。kube-prometheus 部署了 Prometheus Operator,并且已经安排了一个名为 prometheus-k8s 的 prometheus,默认带有警报和规则,并且带有其他 prometheus 需要的组件,如:
- Grafana
- kube-state-metrics
- prometheus adapter
- node exporter
- ...
Prometheus Operator vs. kube-prometheus vs. community helm chart
Prometheus Operator
Prometheus Operator 使用 Kubernetes 自定义资源,简化了 Prometheus、Alertmanager 和相关监控组件的部署和配置。
kube-prometheus
kube-prometheus 提供了一个基于 Prometheus 和 Prometheus Operator 的完整集群监控堆栈的示例配置。这包括部署多个 Prometheus 和 Alertmanager 实例、用于收集节点指标的指标导出器(如 node_exporters)、将 Prometheus 链接到各种指标端点的目标配置,以及用于通知集群中潜在问题的示例警报规则。
helm chart
prometheus-community/kube-prometheus-stack helm chart 提供了与 kube-prometheus 相似的特性集。这张 chart 是由 prometheus 社区维护的。
Prometheus Operator 功能
CRD
Prometheus Operator 的一个核心特性是 watch Kubernetes API 服务器对特定对象的更改,并确保当前 Prometheus 部署与这些对象匹配。Operator 对以下自定义资源定义 (crd) 进行操作:
monitoring.coreos.com/v1:
Prometheus: 它定义了 Prometheus 期望的部署。Alertmanager: 它定义了 AlertManager 期望的部署。ThanosRuler: 它定义了 ThanosRuler 期望的部署;如果有多个 Prometheus 实例,则通过ThanosRuler进行告警规则的统一管理。ServiceMonitor: Prometheus Operator 通过PodMonitor和ServiceMonitor实现对资源的监控,ServiceMonitor用于通过 Service 对 K8S 中的任何资源进行监控,推荐首选ServiceMonitor. 它声明性地指定了 Kubernetes service 应该如何被监控。Operator 根据 API 服务器中对象的当前状态自动生成 Prometheus 刮擦配置。PodMonitor: Prometheus Operator 通过PodMonitor和ServiceMonitor实现对资源的监控,PodMonitor用于对 Pod 进行监控,推荐首选ServiceMonitor.PodMonitor声明性地指定了应该如何监视一组 pod。Operator 根据 API 服务器中对象的当前状态自动生成 Prometheus 刮擦配置。Probe: 它声明性地指定了应该如何监视 ingress 或静态目标组。Operator 根据定义自动生成 Prometheus 刮擦配置。PrometheusRule: 用于管理 Prometheus 告警规则;它定义了一套所需的 Prometheus 警报和/或记录规则。Prometheus 生成一个规则文件,可以被 Prometheus 实例使用。AlertmanagerConfig: 用于管理 AlertManager 配置文件,主要是告警发给谁;它声明性地指定 Alertmanager 配置的子部分,允许将警报路由到自定义接收器,并设置禁止规则。
Prometheus Operator 自动检测 Kubernetes API 服务器对上述任何对象的更改,并确保匹配的部署和配置保持同步。
简化的部署配置
配置 Prometheus 的基础知识,如版本、持久性、保留策略和来自本机 Kubernetes 资源的副本。最简的持久化的 Prometheus 的部署,只需要创建如下 yaml 即可:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: persisted
spec:
storage:
volumeClaimTemplate:
spec:
storageClassName: ssd
resources:
requests:
storage: 40GiPrometheus 目标配置
根据熟悉的 Kubernetes 标签查询自动生成监控目标配置;无需学习普罗米修斯特定的配置语言。
大厂案例
哪些大厂在用 Prometheus Operator 或 kube-prometheus?
RedHat
从 Prometheus Operator 的 API 也能看出来,这个 Operator 最早是由 CoreOS 开发并开源的,而现在 CoreOS 已经被 RedHat 收购,所以 RedHat 的 OpenShift 4 完全是采用 Prometheus Operator 作为它的 Metrics 解决方案的。典型的架构如下图:

可以看到 Prometheus 和 AlertManager 都是通过 Prometheus Operator 来进行管理的。
Rancher
Rancher 2 以后的 rancher-monitoring 也是基于 kube-prometheus 做了进一步的改进而来的,这是通过 rancher-monitoring helm chart 部署后的关系图,可以看到部署的组件还是非常多的:
- Grafana
- Prometheus CRD
- Prometheus Operator
- Prometheus
- AlertManager
- kube-state-metrics
- prometheus adapter
- node exporter
- ...

我为什么推荐你用 Prometheus Operator 或 kube-prometheus 而非原生 prometheus?
理由如下:
- 众多大厂的选择;
- 极大简化了 Prometheus 的配置复杂度;
开箱即用的大量:
- 监控对象,如:K8S 组件 - coredns, kubelet, controller manager, apiserver, etcd, scheduler, kube proxy; 监控组件自监控 - grafana, AlertManager, prometheus 等;
- 仪表板,自带 24 个仪表板,非常实用,涵盖:集群/组件/网络/存储/Node/Pod 等等维度;
- 告警规则,自带了 100 多个告警规则,涵盖 K8S 的方方面面;
- 流行的开源产品,很多也默认会带有对 Prometheus Operator 的支持,如 Loki 就有相关的 ServiceMonitor;
- 通过 ServiceMonitor 等,其实反而相比添加 Prometheus Annotation 有更大的灵活性;如下面的例子
高可用的支持,如:
- 多个 Prometheus 的 shards
- 多个 AlertManager
- ThanosRuler
- RBAC: 如默认可以创建 3 个 monitoring 的角色:admin/edit/viewer, 可以分别对应监控的管理员,维护人员和只读用户;


示例,灵活性:
spec:
endpoints:
- honorLabels: true
params:
_scheme:
- https
port: metrics
proxyUrl: http://pushprox-k3s-server-proxy.cattle-monitoring-system.svc:8080
relabelings:
- sourceLabels:
- __metrics_path__
targetLabel: metrics_path
jobLabel: component
namespaceSelector:
matchNames:
- cattle-monitoring-system
podTargetLabels:
- component
- pushprox-exporter
selector:
matchLabels:
component: k3s-server
k8s-app: pushprox-k3s-server-client
provider: kubernetes
release: rancher-monitoring️ 参考文档
- prometheus-operator/prometheus-operator: Prometheus Operator creates/configures/manages Prometheus clusters atop Kubernetes (github.com)
- Prometheus Operator - Running Prometheus on Kubernetes (prometheus-operator.dev)
- OperatorHub.io | The registry for Kubernetes Operators
以上
EOF

Prometheus Operator 教程:根据服务维度对 Prometheus 分片
原文链接:https://fuckcloudnative.io/posts/aggregate-metrics-user-prometheus-operator/
Promtheus 本身只支持单机部署,没有自带支持集群部署,也不支持高可用以及水平扩容,它的存储空间受限于本地磁盘的容量。同时随着数据采集量的增加,单台 Prometheus 实例能够处理的时间序列数会达到瓶颈,这时 CPU 和内存都会升高,一般内存先达到瓶颈,主要原因有:
- Prometheus 的内存消耗主要是因为每隔 2 小时做一个
Block数据落盘,落盘之前所有数据都在内存里面,因此和采集量有关。 - 加载历史数据时,是从磁盘到内存的,查询范围越大,内存越大。这里面有一定的优化空间。
- 一些不合理的查询条件也会加大内存,如
Group或大范围Rate。
这个时候要么加内存,要么通过集群分片来减少每个实例需要采集的指标。本文就来讨论通过 Prometheus Operator 部署的 Prometheus 如何根据服务维度来拆分实例。
1. 根据服务维度拆分 Prometheus
Prometheus 主张根据功能或服务维度进行拆分,即如果要采集的服务比较多,一个 Prometheus 实例就配置成仅采集和存储某一个或某一部分服务的指标,这样根据要采集的服务将 Prometheus 拆分成多个实例分别去采集,也能一定程度上达到水平扩容的目的。

在 Kubernetes 集群中,我们可以根据 namespace 来拆分 Prometheus 实例,例如将所有 Kubernetes 集群组件相关的监控发送到一个 Prometheus 实例,将其他所有监控发送到另一个 Prometheus 实例。
Prometheus Operator 通过 CRD 资源名 Prometheus 来控制 Prometheus 实例的部署,其中可以通过在配置项 serviceMonitorNamespaceSelector 和 podMonitorNamespaceSelector 中指定标签来限定抓取 target 的 namespace。例如,将 namespace kube-system 打上标签 monitoring-role=system,将其他的 namespace 打上标签 monitoring-role=others。

2. 告警规则拆分
将 Prometheus 拆分成多个实例之后,就不能再使用默认的告警规则了,因为默认的告警规则是针对所有 target 的监控指标的,每一个 Prometheus 实例都无法获取所有 target 的监控指标,势必会一直报警。为了解决这个问题,需要对告警规则进行拆分,使其与每个 Prometheus 实例的服务维度一一对应,按照上文的拆分逻辑,这里只需要拆分成两个告警规则,打上不同的标签,然后在 CRD 资源 Prometheus 中通过配置项 ruleSelector 指定规则标签来选择相应的告警规则。

3. 集中数据存储
解决了告警问题之后,还有一个问题,现在监控数据比较分散,使用 Grafana 查询监控数据时我们也需要添加许多数据源,而且不同数据源之间的数据还不能聚合查询,监控页面也看不到全局的视图,造成查询混乱的局面。
为了解决这个问题,我们可以让 Prometheus 不负责存储数据,只将采集到的样本数据通过 Remote Write 的方式写入远程存储的 Adapter,然后将 Grafana 的数据源设为远程存储的地址,就可以在 Grafana 中查看全局视图了。这里选择 VictoriaMetrics 来作为远程存储。VictoriaMetrics 是一个高性能,低成本,可扩展的时序数据库,可以用来做 Prometheus 的长期存储,分为单机版本和集群版本,均已开源。如果数据写入速率低于每秒一百万个数据点,官方建议使用单节点版本而不是集群版本。本文作为演示,仅使用单机版本,架构如图:

4. 实践
确定好了方案之后,下面来进行动手实践。
部署 VictoriaMetrics
首先部署一个单实例的 VictoriaMetrics,完整的 yaml 如下:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: victoriametrics
namespace: kube-system
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Gi
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: victoriametrics
name: victoriametrics
namespace: kube-system
spec:
serviceName: pvictoriametrics
selector:
matchLabels:
app: victoriametrics
replicas: 1
template:
metadata:
labels:
app: victoriametrics
spec:
nodeSelector:
blog: "true"
containers:
- args:
- --storageDataPath=/storage
- --httpListenAddr=:8428
- --retentionPeriod=1
image: victoriametrics/victoria-metrics
imagePullPolicy: IfNotPresent
name: victoriametrics
ports:
- containerPort: 8428
protocol: TCP
readinessProbe:
httpGet:
path: /health
port: 8428
initialDelaySeconds: 30
timeoutSeconds: 30
livenessProbe:
httpGet:
path: /health
port: 8428
initialDelaySeconds: 120
timeoutSeconds: 30
resources:
limits:
cpu: 2000m
memory: 2000Mi
requests:
cpu: 2000m
memory: 2000Mi
volumeMounts:
- mountPath: /storage
name: storage-volume
restartPolicy: Always
priorityClassName: system-cluster-critical
volumes:
- name: storage-volume
persistentVolumeClaim:
claimName: victoriametrics
---
apiVersion: v1
kind: Service
metadata:
labels:
app: victoriametrics
name: victoriametrics
namespace: kube-system
spec:
ports:
- name: http
port: 8428
protocol: TCP
targetPort: 8428
selector:
app: victoriametrics
type: ClusterIP有几个启动参数需要注意:
- storageDataPath : 数据目录的路径。 VictoriaMetrics 将所有数据存储在此目录中。
- retentionPeriod : 数据的保留期限(以月为单位)。旧数据将自动删除。默认期限为1个月。
- httpListenAddr : 用于监听 HTTP 请求的 TCP 地址。默认情况下,它在所有网络接口上监听端口
8428。
给 namespace 打标签
为了限定抓取 target 的 namespace,我们需要给 namespace 打上标签,使每个 Prometheus 实例只抓取特定 namespace 的指标。根据上文的方案,需要给 kube-system 打上标签 monitoring-role=system:
$ kubectl label ns kube-system monitoring-role=system给其他的 namespace 打上标签 monitoring-role=others。例如:
$ kubectl label ns monitoring monitoring-role=others
$ kubectl label ns default monitoring-role=others拆分 PrometheusRule
告警规则需要根据监控目标拆分成两个 PrometheusRule。具体做法是将 kube-system namespace 相关的规则整合到一个 PrometheusRule 中,并修改名称和标签:
# prometheus-rules-system.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: system
role: alert-rules
name: prometheus-system-rules
namespace: monitoring
spec:
groups:
...
...剩下的放到另外一个 PrometheusRule 中,并修改名称和标签:
# prometheus-rules-others.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: others
role: alert-rules
name: prometheus-others-rules
namespace: monitoring
spec:
groups:
...
...然后删除默认的 PrometheusRule:
$ kubectl -n monitoring delete prometheusrule prometheus-k8s-rules新增两个 PrometheusRule:
$ kubectl apply -f prometheus-rules-system.yaml
$ kubectl apply -f prometheus-rules-others.yaml如果你实在不知道如何拆分规则,或者不想拆分,想做一个伸手党,可以看这里:
- prometheus-rules-system.yaml
- prometheus-rules-others.yaml
拆分 Prometheus
下一步是拆分 Prometheus 实例,根据上面的方案需要拆分成两个实例,一个用来监控 kube-system namespace,另一个用来监控其他 namespace:
# prometheus-prometheus-system.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: system
name: system
namespace: monitoring
spec:
remoteWrite:
- url: http://victoriametrics.kube-system.svc.cluster.local:8428/api/v1/write
queueConfig:
maxSamplesPerSend: 10000
retention: 2h
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
image: quay.io/prometheus/prometheus:v2.17.2
nodeSelector:
beta.kubernetes.io/os: linux
podMonitorNamespaceSelector:
matchLabels:
monitoring-role: system
podMonitorSelector: {}
replicas: 1
resources:
requests:
memory: 400Mi
limits:
memory: 2Gi
ruleSelector:
matchLabels:
prometheus: system
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector:
matchLabels:
monitoring-role: system
serviceMonitorSelector: {}
version: v2.17.2
---
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: others
name: others
namespace: monitoring
spec:
remoteWrite:
- url: http://victoriametrics.kube-system.svc.cluster.local:8428/api/v1/write
queueConfig:
maxSamplesPerSend: 10000
retention: 2h
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
image: quay.io/prometheus/prometheus:v2.17.2
nodeSelector:
beta.kubernetes.io/os: linux
podMonitorNamespaceSelector:
matchLabels:
monitoring-role: others
podMonitorSelector: {}
replicas: 1
resources:
requests:
memory: 400Mi
limits:
memory: 2Gi
ruleSelector:
matchLabels:
prometheus: others
role: alert-rules
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector:
matchLabels:
monitoring-role: others
serviceMonitorSelector: {}
additionalScrapeConfigs:
name: additional-scrape-configs
key: prometheus-additional.yaml
version: v2.17.2需要注意的配置:
- 通过
remoteWrite指定 remote write 写入的远程存储。 - 通过
ruleSelector指定 PrometheusRule。 - 限制内存使用上限为
2Gi,可根据实际情况自行调整。 - 通过
retention指定数据在本地磁盘的保存时间为 2 小时。因为指定了远程存储,本地不需要保存那么长时间,尽量缩短。 - Prometheus 的自定义配置可以通过
additionalScrapeConfigs在 others 实例中指定,当然你也可以继续拆分,放到其他实例中。
删除默认的 Prometheus 实例:
$ kubectl -n monitoring delete prometheus k8s创建新的 Prometheus 实例:
$ kubectl apply -f prometheus-prometheus.yaml查看运行状况:
$ kubectl -n monitoring get prometheus
NAME VERSION REPLICAS AGE
system v2.17.2 1 29h
others v2.17.2 1 29h
$ kubectl -n monitoring get sts
NAME READY AGE
prometheus-system 1/1 29h
prometheus-others 1/1 29h
alertmanager-main 1/1 25d查看每个 Prometheus 实例的内存占用:
$ kubectl -n monitoring top pod -l app=prometheus
NAME CPU(cores) MEMORY(bytes)
prometheus-others-0 12m 110Mi
prometheus-system-0 121m 1182Mi最后还要修改 Prometheus 的 Service,yaml 如下:
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: system
name: prometheus-system
namespace: monitoring
spec:
ports:
- name: web
port: 9090
targetPort: web
selector:
app: prometheus
prometheus: system
sessionAffinity: ClientIP
---
apiVersion: v1
kind: Service
metadata:
labels:
prometheus: others
name: prometheus-others
namespace: monitoring
spec:
ports:
- name: web
port: 9090
targetPort: web
selector:
app: prometheus
prometheus: others
sessionAffinity: ClientIP删除默认的 Service:
$ kubectl -n monitoring delete svc prometheus-k8s创建新的 Service:
$ kubectl apply -f prometheus-service.yaml修改 Grafana 数据源
Prometheus 拆分成功之后,最后还要修改 Grafana 的数据源为 VictoriaMetrics 的地址,这样就可以在 Grafana 中查看全局视图,也能聚合查询。
打开 Grafana 的设置页面,将数据源修改为 http://victoriametrics.kube-system.svc.cluster.local:8428:

点击 Explore 菜单:
在查询框内输入 up,然后按下 Shift+Enter 键查询:
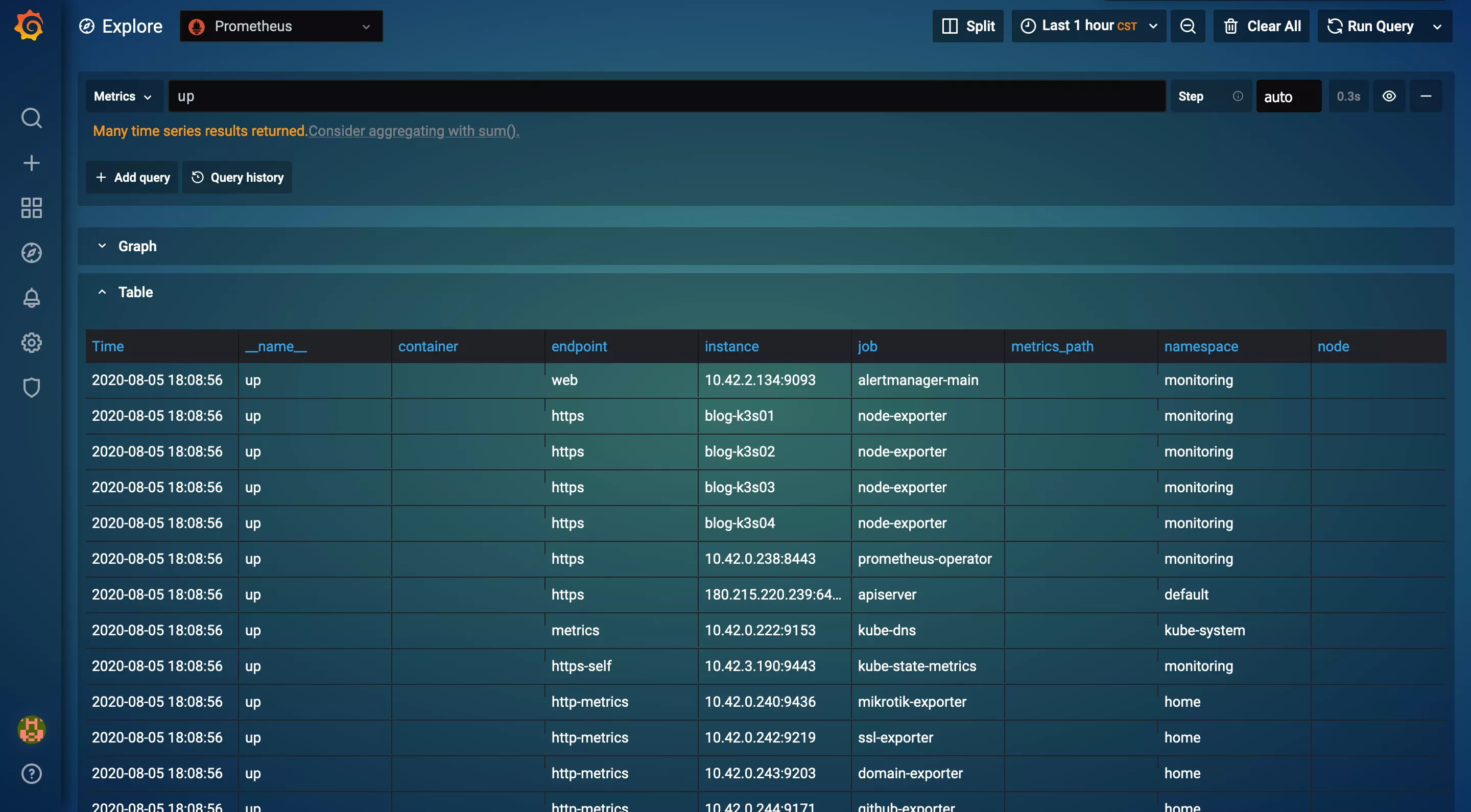
可以看到查询结果中包含了所有的 namespace。
如果你对我的 Grafana 主题配色很感兴趣,可以关注公众号『云原生实验室』,后台回复 grafana 即可获取秘诀。
写这篇文章的起因是我的 k3s 集群每台节点的资源很紧张,而且监控的 target 很多,导致 Prometheus 直接把节点的内存资源消耗完了,不停地 OOM。为了充分利用我的云主机,不得不另谋他路,这才有了这篇文章。
Kubernetes 1.18.2 1.17.5 1.16.9 1.15.12离线安装包发布地址http://store.lameleg.com ,欢迎体验。 使用了最新的sealos v3.3.6版本。 作了主机名解析配置优化,lvscare 挂载/lib/module解决开机启动ipvs加载问题, 修复lvscare社区netlink与3.10内核不兼容问题,sealos生成百年证书等特性。更多特性 https://github.com/fanux/sealos 。欢迎扫描下方的二维码加入钉钉群 ,钉钉群已经集成sealos的机器人实时可以看到sealos的动态。

关于如何从 Prometheus 获得上周的“UP”指标计数 = 0?和prometheus 常用指标的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于k8s prometheus监控指标、kube-prometheus和prometheus-operator教程之实战和原理介绍、Prometheus Operator 与 kube-prometheus 之一-简介、Prometheus Operator 教程:根据服务维度对 Prometheus 分片等相关内容,可以在本站寻找。
本文标签:




