想了解检查PDF文件在Python中是否有效的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于pdf检测的相关问题,此外,我们还将为您介绍关于python–检查pandas中是否有一对值、py
想了解检查PDF文件在Python中是否有效的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于pdf检测的相关问题,此外,我们还将为您介绍关于python – 检查pandas中是否有一对值、python – 检查文件名是否有效、Python中如何用PyPDF2模块拆分PDF文档、使用Python中的PDFMiner从PDF文件提取文本?的新知识。
本文目录一览:- 检查PDF文件在Python中是否有效(pdf检测)
- python – 检查pandas中是否有一对值
- python – 检查文件名是否有效
- Python中如何用PyPDF2模块拆分PDF文档
- 使用Python中的PDFMiner从PDF文件提取文本?
")
检查PDF文件在Python中是否有效(pdf检测)
我通过HTTP上载获得文件,并且需要确保它是pdf文件。 编程语言是Python,但这无关紧要。
我想到了以下解决方案:
-
检查字符串的第一个字节是否为“%PDF”。 这不是一个很好的检查,但是可以防止用户意外上传其他文件。
-
尝试libmagic(bash上的“文件”命令使用它)。 这与(1)中的检查完全相同
-
获取一个lib并尝试从文件中读取页数。 如果该库能够读取一个页面计数,则它应该是有效的pdf。 问题:我不知道python的lib可以做到这一点
那么有人为lib或其他技巧找到了解决方案吗?

python – 检查pandas中是否有一对值
例如,我的数据:
df = pd.DataFrame([[4,8,'wolf','Predator',10],[5,6,'cow','Prey',[8,2,'rabbit',3,[3,[7,5,10]],columns = ['lat','long','name','kingdom','energy']) newcoords1 = [4,4] newcoords2 = [7,5]
是否可以写一个if语句来告诉我是否已经存在具有该纬度和经度的行.在伪代码中:
if newcoords1 in df['lat','long']:
print('yes! ' + str(newcoords1))
(在示例中,newcoords1应为false,newcoords2应为true.
旁注:( df [‘lat’]中的newcoords1 [0])& (df [‘long’]中的newcoords1 [1]不起作用,因为它独立地检查它们,但我需要知道该组合是否出现在一行中.
先感谢您!
解决方法
In [140]: df.query('@newcoords2[0] == lat and @newcoords2[1] == long')
Out[140]:
lat long name kingdom energy
5 7 5 rabbit Prey 10
In [146]: df.query('@newcoords2[0] == lat and @newcoords2[1] == long').empty
Out[146]: False
以下行将返回多个找到的行:
In [147]: df.query('@newcoords2[0] == lat and @newcoords2[1] == long').shape[0]
Out[147]: 1
或使用NumPy方法:
In [103]: df[(df[['lat','long']].values == newcoords2).all(axis=1)] Out[103]: lat long name kingdom energy 5 7 5 rabbit Prey 10
这将显示是否至少找到了一行:
In [113]: (df[['lat','long']].values == newcoords2).all(axis=1).any() Out[113]: True In [114]: (df[['lat','long']].values == newcoords1).all(axis=1).any() Out[114]: False
说明:
In [104]: df[['lat','long']].values == newcoords2 Out[104]: array([[False,False],[False,[ True,True]],dtype=bool) In [105]: (df[['lat','long']].values == newcoords2).all(axis=1) Out[105]: array([False,False,True],dtype=bool)

python – 检查文件名是否有效
防爆.
this_is_valid_name.jpg – >有效
** adad.jpg – >无效
a / ad – >无效
解决方法
valid = myfilename in ['this_is_valid_name.jpg']
在此基础上,您可以定义一组您知道在每个平台上的文件名中允许的字符:
valid = set(valid_char_sequence).issuperset(myfilename)
但这还不够,就像一些操作系统have reserved filenames.
您需要排除保留名称或与OS允许的文件名域匹配的create an expression(regexp),并针对每个目标平台测试您的文件名.
AFAIK,Python不提供这样的帮助器,因为它是Easier to Ask Forgiveness than Permission.操作系统/文件系统有很多不同的可能组合,当os引发异常时,比检查所有它们的安全文件名域更容易做出适当的反应.

Python中如何用PyPDF2模块拆分PDF文档
安装PyPDF2模块
# 这个模块严格区分大小写,y是小写,其余大写
pip3 install pypdf2
安装完成之后呢,在本地硬盘创建一个专门存放本项目的文件夹,我这里在的存放路径是 F:\Python\PyPDF2,在F盘有个Python文件夹,在其中又创建了一个以这个模块命名的文件夹,来单独存放和与别的项目区分。
创建文件,准备PDF文档
找一个练手的比较大的PDF文档,我在Django官网下载了他的文档,这个文档足够大,1900多页,对于练手绝对够了,有需要的去官网下载,或者在我的公众号直接回复‘pdf’ 获取下载链接,然后再创建一个PDFCF.py 的项目文件。
开始写
程序开始两行,写上下边这两句,第一句的意思是指定这个文件的运行程序,第二句是对这个文件的说明,这个的作用现在还看不出来,但如果你知道怎么批量化快速执行程序,你就知道了它的作用,这里不做赘述。
#! python# PDFCF.py - pdf文件拆分程序
文档的拆分思路
不固定拆分成多少份,但固定每一份由多少页组成,然后来动态的计算拆分的份数,拆分思路有了,那么下来就是列出计算公式。
拆分的份数= 文档总页数 / 拆份每个pdf组成的页数
举个例子:
假如我们要拆分一个总页数为35页的pdf文档,按照每10页组成一个新文档,那么能拆分成多少份的计算公式如下:
3.5 = 35 / 10
这时候大家注意了,除不尽有余数0.5,说明什么?用这个例子来说就是拆分成3份还余下5页,那么遇到这种情况不管余数是几都得向前进1,才能完成整个拆分,这个文档拆分的结果就是,前3个文档每个由10页组成,第四个文档则由最后5页组成,能整除则结果直接就是拆分的份数。
if 35 % 10: # 判断是否有余数 35 // 10 + 1 # 取余数整数部分加1else: 0 # 能整除则直接返回0 # 将这个循环写到一行4 = 35 // 10 + 1 if 35 % 10 else 0
立即学习“Python免费学习笔记(深入)”;
具体怎么拆?
还是以这个35页的文档拆分为例:
循环遍历每一页数据 for num in range(35),得到每一页的数据,之后再指定拆分页数范围进行拆分:
第一个文档从0--10,不包含10
第二个文档从10--20 ,不包含20
第三个文档从 20 -30,不包含30
第四个文档从30--35,不包含35
我们发现规律,每次遍历第一个数字的规律是 一个文档的页数,乘以自己属于第几个便可以得到。第二个数我们发现没规律了,其实仔细观察也有规律,假如我们对拆分个数排序,这个例子就是1--4,第二个数字就是当前属于第几个拆分数乘以每个文档组成的页数(页数是固定的10)。
可是我们第一次遍历的时候从0开始,就让num变得不通用,那么我们改造一下从1开始遍历,range(1,35),从一开始遍历,基于range不包含本身最后一个的特性,这样遍历出来就少了一页文档,那么我们给他加1,变成
for num in range(1,35+1)
第一个文档从10*(1-1)--10*1,不包含10
第二个文档从10*(2-1)--10*2 ,不包含20
第三个文档从 10*(3-1) -10*3, 不包含30
第四个文档从10(4-1)--35
具体遍历代码如下:
for num in range(1,35+1): pass for i in range(10 * (num-1), 10 * num if num != 4 else 35): pass
注意:当遍历到 num = 4(最后一个文档排序数时),直接返回 总页数35就可以了,到这里遍历就结束了。这里为什么是总页数35 而不是35+1呢?是因为此次遍历我们是从0开始遍历的,页码从0开始,所以不需要加1了。
完整拆分程序:
import PyPDF2
注意:上边这种拆分思路我个人感觉比较绕,如果你对Python列表的切边以及步长概念理解透彻的话,我觉得不需要这么复杂,只需要把总页码生成一个大列表,再把这个列表利用切片的方法拆分成多个小列表,之后每个拆分的pdf页码范围就是每个小列表第一个数--最后一个数+1,我把我用列表方法实现的代码也贴出来供大家参考。
拆分列表方法实现拆分PDF:
#! python
怎么用?
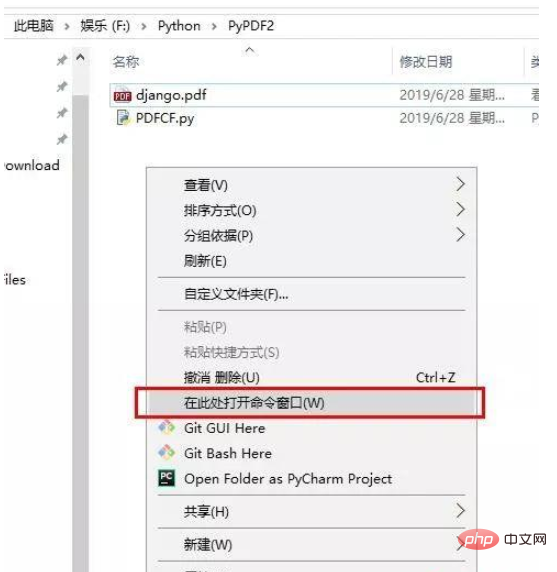
在项目文件夹内部按住Shift键,点击鼠标右键,选择在此处打开命令窗口,输入PDFCF.py,回车即可,根据自己的需求去更改 n 的值。

以上就是Python中如何用PyPDF2模块拆分PDF文档的详细内容,更多请关注php中文网其它相关文章!

使用Python中的PDFMiner从PDF文件提取文本?
我正在寻找有关如何使用带有Python的PDFMiner从PDF文件提取文本的文档 或 示例。
看来PDFMiner更新了他们的API,我发现的所有相关示例都包含过时的代码(类和方法已更改)。我发现的那些使从PDF文件提取文本的任务更加容易的库正在使用旧的PDFMiner语法,因此我不确定如何执行此操作。
照原样,我只是在查看源代码,以查看是否可以解决。
答案1
小编典典这是一个使用当前版本的PDFMiner从PDF文件提取文本的工作示例(2016年9月)
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreterfrom pdfminer.converter import TextConverterfrom pdfminer.layout import LAParamsfrom pdfminer.pdfpage import PDFPagefrom io import StringIOdef convert_pdf_to_txt(path): rsrcmgr = PDFResourceManager() retstr = StringIO() codec = ''utf-8'' laparams = LAParams() device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams) fp = open(path, ''rb'') interpreter = PDFPageInterpreter(rsrcmgr, device) password = "" maxpages = 0 caching = True pagenos=set() for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True): interpreter.process_page(page) text = retstr.getvalue() fp.close() device.close() retstr.close() return textPDFMiner的结构最近发生了变化,因此应该可以从PDF文件中提取文本。
编辑 :截至2018年6月7日仍在工作。在Python Version 3.x中验证
编辑:该解决方案于2019年10月3日与Python 3.7一起使用。我使用了Python库pdfminer.six,该库于2018年11月发布。
我们今天的关于检查PDF文件在Python中是否有效和pdf检测的分享已经告一段落,感谢您的关注,如果您想了解更多关于python – 检查pandas中是否有一对值、python – 检查文件名是否有效、Python中如何用PyPDF2模块拆分PDF文档、使用Python中的PDFMiner从PDF文件提取文本?的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

