以上就是给各位分享什么是SQLselect的Big-O?,同时本文还将给你拓展MySQL-SQL_BIG_SELECTS、SQLServer游标C#DataTable.Select()筛选数据什么是S
以上就是给各位分享什么是SQL select的Big-O?,同时本文还将给你拓展MySQL-SQL_BIG_SELECTS、SQL Server游标 C# DataTable.Select() 筛选数据 什么是SQL游标? SQL Server数据类型转换方法 LinQ是什么? SQL Serve...、SQlite:select into?、SQL为什么是SELECT COUNT(*),MIN(col),MAX(col)快于SELECT MIN(col),MAX(col)等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- 什么是SQL select的Big-O?
- MySQL-SQL_BIG_SELECTS
- SQL Server游标 C# DataTable.Select() 筛选数据 什么是SQL游标? SQL Server数据类型转换方法 LinQ是什么? SQL Serve...
- SQlite:select into?
- SQL为什么是SELECT COUNT(*),MIN(col),MAX(col)快于SELECT MIN(col),MAX(col)

什么是SQL select的Big-O?
对于SQL选择,对于具有n行的表以及要为其返回m结果的Big-O是什么?
Update或delete,或或Create运算的Big-O是什么?
我一般来说是在谈论mysql和sqlite。
答案1
小编典典由于您无法控制所选的算法,因此无法直接知道。但是,没有索引的SELECT应该为O(n)(表扫描必须检查每条记录,这意味着它将根据表的大小进行缩放)。
使用索引时,SELECT可能为O(log(n))(尽管如果适用于任何实表,则SELECT取决于用于索引的算法以及数据本身的属性)。为了确定任何表或查询的结果,您必须求助于对真实世界数据进行概要分析。
不带索引的INSERT应该非常快(接近O(1)),而UPDATE需要首先找到记录,因此,它会比使您到达那里的SELECT慢(略)。
当索引树需要重新平衡时,带有索引的INSERT可能会再次处于O(log(n ^
2))的范围之内,否则将更接近O(log(n))。如果它影响SELECTED成本之外的索引行,则UPDATE也会发生相同的速度下降。
一旦您谈到混合中的JOIN,所有的赌注都关闭了:您将必须分析并使用数据库查询估计工具来进行阅读。还要注意,如果此查询对性能至关重要,则应不时 重新
配置,因为查询优化器使用的算法会随着数据负载的变化而变化。
要记住的另一件事… big-
O不会告诉您每笔交易的固定成本。对于较小的桌子,这些费用可能会高于实际工作成本。举个例子:单行跨网络查询的建立,删除和通信成本肯定会比在小表中查找索引记录更多。
因此,我发现能够将一组相关查询捆绑在一起可以比我对数据库进行的任何优化对性能的影响大得多。

MySQL-SQL_BIG_SELECTS
嘿,我一直在研究SQL_BIG_SELECTS,但是到目前为止,MySQL文档一直没有帮助。我正在寻找某种见解,以防止出现以下错误。
错误1104:SELECT将检查太多的记录,可能需要很长时间。检查您的WHERE,如果SELECT正确,则使用SET OPTION
SQL_BIG_SELECTS = 1
- MySQL决定查询多少行为“ BIG SELECT”?
- 适当的索引编制通常可以解决此问题吗?
- 是将SQL_BIG_SELECTS视为“最后的选择”,还是好的做法?
- 有人将如何在配置中设置“ SQL_BIG_SELECTS = 1”(无需执行查询)?
- 还有其他值得了解的替代方法吗?
提前致谢!
答案1
小编典典MySQL根据“ max_join_size”的值确定查询是否为“大选择”。如果查询可能需要检查的行数超过此数目,则将其视为“大选择”。使用“显示变量”查看最大连接大小的值。
我认为,建立索引以及特别好的where子句可以防止发生此问题。
SQL_BIG_SELECTS用于防止用户意外执行过大的查询。可以在mysql.cnf中将其设置为ON或在启动时使用命令行选项。
您可以在my.cnf或服务器启动时设置SQL_BIG_SELECTS。也可以使用进行会话设置
SET SESSION SQL_BIG_SELECTS=1。不是我能想到的。我只是检查您的查询以确保您确实需要使用它。我们的服务器默认情况下将其打开,并且max_join_size非常大。
 筛选数据 什么是SQL游标? SQL Server数据类型转换方法 LinQ是什么? SQL Serve...")
SQL Server游标 C# DataTable.Select() 筛选数据 什么是SQL游标? SQL Server数据类型转换方法 LinQ是什么? SQL Serve...
SQL Server游标
转载自:http://www.cnblogs.com/knowledgesea/p/3699851.html。
什么是游标
结果集,结果集就是select查询之后返回的所有行数据的集合。
游标则是处理结果集的一种机制吧,它可以定位到结果集中的某一行,多数据进行读写,也可以移动游标定位到你所需要的行中进行操作数据。
一般复杂的存储过程,都会有游标的出现,他的用处主要有:
- 定位到结果集中的某一行。
- 对当前位置的数据进行读写。
- 可以对结果集中的数据单独操作,而不是整行执行相同的操作。
- 是面向集合的数据库管理系统和面向行的程序设计之间的桥梁。
游标的分类
根据游标检测结果集变化的能力和消耗资源的情况不同,SQL Server支持的API服务器游标分为一下4种:
- 静态游标: 静态游标的结果集,在游标打开的时候建立在TempDB中,不论你在操作游标的时候,如何操作数据库,游标中的数据集都不会变。例如你在游标打开的时候,对游标查询的数据表数据进行增删改,操作之后,静态游标中select的数据依旧显示的为没有操作之前的数据。如果想与操作之后的数据一致,则重新关闭打开游标即可。
- 动态游标:这个则与静态游标相对,滚动游标时,动态游标反应结果集中的所有更改。结果集中的行数据值、顺序和成员在每次提取时都会变化。所有用户做的增删改语句通过游标均可见。如果使用API函数或T-SQL Where Current of子句通过游标进行更新,他们将立即可见。在游标外部所做的更新直到提交时才可见。
- 只进游标:只进游标不支持滚动,只支持从头到尾顺序提取数据,数据库执行增删改,在提取时是可见的,但由于该游标只能进不能向后滚动,所以在行提取后对行做增删改是不可见的。
- 键集驱动游标:打开键集驱动游标时,该有表中的各个成员身份和顺序是固定的。打开游标时,结果集这些行数据被一组唯一标识符标识,被标识的列做删改时,用户滚动游标是可见的,如果没被标识的列增该,则不可见,比如insert一条数据,是不可见的,若可见,须关闭重新打开游标。
静态游标在滚动时检测不到表数据变化,但消耗的资源相对很少。动态游标在滚动时能检测到所有表数据变化,但消耗的资源却较多。键集驱动游标则处于他们中间,所以根据需求建立适合自己的游标,避免资源浪费。
游标的生命周期
游标的生命周期包含有五个阶段:声明游标、打开游标、读取游标数据、关闭游标、释放游标。
1.声明游标,语法


DECLARE cursor_name CURSOR [ LOCAL | GLOBAL ]
[ FORWARD_ONLY | SCROLL ]
[ STATIC | KEYSET | DYNAMIC | FAST_FORWARD ]
[ READ_ONLY | SCROLL_LOCKS | OPTIMISTIC ]
[ TYPE_WARNING ]
FOR select_statement
[ FOR UPDATE [ OF column_name [ ,...n ] ] ]

参数说明:
- cursor_name:游标名称。
- Local:作用域为局部,只在定义它的批处理,存储过程或触发器中有效。
- Global:作用域为全局,由连接执行的任何存储过程或批处理中,都可以引用该游标。
- [Local | Global]:默认为local。
- Forward_Only:指定游标智能从第一行滚到最后一行。Fetch Next是唯一支持的提取选项。如果在指定Forward_Only是不指定Static、KeySet、Dynamic关键字,默认为Dynamic游标。如果Forward_Only和Scroll没有指定,Static、KeySet、Dynamic游标默认为Scroll,Fast_Forward默认为Forward_Only
- Static:静态游标
- KeySet:键集游标
- Dynamic:动态游标,不支持Absolute提取选项
- Fast_Forward:指定启用了性能优化的Forward_Only、Read_Only游标。如果指定啦Scroll或For_Update,就不能指定他啦。
- Read_Only:不能通过游标对数据进行删改。
- Scroll_Locks:将行读入游标是,锁定这些行,确保删除或更新一定会成功。如果指定啦Fast_Forward或Static,就不能指定他啦。
- Optimistic:指定如果行自读入游标以来已得到更新,则通过游标进行的定位更新或定位删除不成功。当将行读入游标时,sqlserver不锁定行,它改用timestamp列值的比较结果来确定行读入游标后是否发生了修改,如果表不行timestamp列,它改用校验和值进行确定。如果已修改改行,则尝试进行的定位更新或删除将失败。如果指定啦Fast_Forward,则不能指定他。
- Type_Warning:指定将游标从所请求的类型隐式转换为另一种类型时向客户端发送警告信息。
- For Update[of column_name ,....] :定义游标中可更新的列。
2.声明一个动态游标
declare orderNum_02_cursor cursor scroll
for select OrderId from bigorder where orderNum=''ZEORD003402''3.打开游标
--打开游标语法
open [ Global ] cursor_name | cursor_variable_namecursor_name:游标名,cursor_variable_name:游标变量名称,该变量引用了一个游标。
--打开游标
open orderNum_02_cursor4.提取数据


--提取游标语法
Fetch
[ [Next|prior|Frist|Last|Absoute n|Relative n ]
from ]
[Global] cursor_name
[into @variable_name[,....]]

参数说明:
- Frist:结果集的第一行
- Prior:当前位置的上一行
- Next:当前位置的下一行
- Last:最后一行
- Absoute n:从游标的第一行开始数,第n行。
- Relative n:从当前位置数,第n行。
- Into @variable_name[,...] : 将提取到的数据存放到变量variable_name中。
例子:


--提取数据
fetch first from orderNum_02_cursor
fetch relative 3 from orderNum_02_cursor
fetch next from orderNum_02_cursor
fetch absolute 4 from orderNum_02_cursor
fetch next from orderNum_02_cursor
fetch last from orderNum_02_cursor
fetch prior from orderNum_02_cursor
select * from bigorder where orderNum=''ZEORD003402''

结果(对比一下,就明白啦):

例子:
--提取数据赋值给变量
declare @OrderId int
fetch absolute 3 from orderNum_02_cursor into @OrderId
select @OrderId as id
select * from bigorder where orderNum=''ZEORD003402''结果:
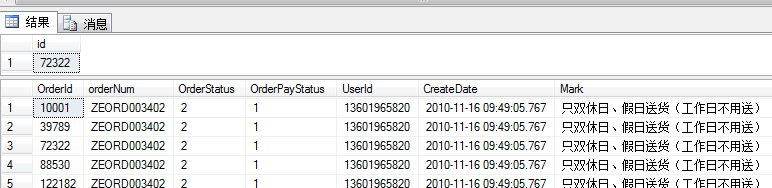
通过检测全局变量@@Fetch_Status的值,获得提取状态信息,该状态用于判断Fetch语句返回数据的有效性。当执行一条Fetch语句之后,@@Fetch_Status可能出现3种值:0,Fetch语句成功。-1:Fetch语句失败或行不在结果集中。-2:提取的行不存在。
这个状态值可以帮你判断提取数据的成功与否。


declare @OrderId int
fetch absolute 3 from orderNum_02_cursor into @OrderId
while @@fetch_status=0 --提取成功,进行下一条数据的提取操作
begin
select @OrderId as id
fetch next from orderNum_02_cursor into @OrderId --移动游标
end

5.利用游标更新删除数据
--游标修改当前数据语法
Update 基表名 Set 列名=值[,...] Where Current of 游标名
--游标删除当前数据语法
Delete 基表名 Where Current of 游标名

---游标更新删除当前数据
---1.声明游标
declare orderNum_03_cursor cursor scroll
for select OrderId ,userId from bigorder where orderNum=''ZEORD003402''
--2.打开游标
open orderNum_03_cursor
--3.声明游标提取数据所要存放的变量
declare @OrderId int ,@userId varchar(15)
--4.定位游标到哪一行
fetch First from orderNum_03_cursor into @OrderId,@userId --into的变量数量必须与游标查询结果集的列数相同
while @@fetch_status=0 --提取成功,进行下一条数据的提取操作
begin
if @OrderId=122182
begin
Update bigorder Set UserId=''123'' Where Current of orderNum_03_cursor --修改当前行
end
if @OrderId=154074
begin
Delete bigorder Where Current of orderNum_03_cursor --删除当前行
end
fetch next from orderNum_03_cursor into @OrderId ,@userId --移动游标
end

6.关闭游标
游标打开后,服务器会专门为游标分配一定的内存空间存放游标操作的数据结果集,同时使用游标也会对某些数据进行封锁。所以游标一旦用过,应及时关闭,避免服务器资源浪费。
--关闭游标语法
close [ Global ] cursor_name | cursor_variable_name
--关闭游标
close orderNum_03_cursor7.删除游标
删除游标,释放资源
--释放游标语法
deallocate [ Global ] cursor_name | cursor_variable_name
--释放游标
deallocate orderNum_03_cursor
C# DataTable.Select() 筛选数据
有时候我们需要对数据表进行筛选,微软为我们封装了一个公共方法, DataTable.Select(),其用法如下:
Select()
Select(string filterExpression)
Select(string filterExpression, string sort)
Select(string filterExpression,string sort, DataViewRowState record States)
1) Select()——获取所有 System.Data.DataRow 对象的数组;
2) Select(string filterExpression)——按照主键顺序(如果没有主键,则按照添加顺序)获取与筛选条件相匹配的所有 System.Data.DataRow 对象的数组;
3) Select(string filterExpression, string sort)——获取按照指定的排序顺序且与筛选条件相匹配的所有System.Data.DataRow 对象的数组;
4) Select(string filterExpression, string sort, DataViewRowState recordStates)——获取与排序顺序中的筛选器以及指定的状态相匹配的所有。
举例说明:
有一个用户表,名称为 dtUsers,有id、姓名name、性别sex、年龄age
1.筛选所有的用户
DataRow[] drs1 =dtUsers.Select();
2.筛选所有性别为男的用户
DataRow[] drs2 =dtUsers.Select("sex = ''男'' ");
3.筛选所有性别为男且年龄在18岁以上的用户
DataRow[] drs3 =dtUsers.Select("sex = ''男'' and age >= 18");
4.筛选所有性别为男或者年龄在18岁以上的用户
DataRow[] drs4 =dtUsers.Select("sex = ''男'' or age >= 18");
5.筛选所有姓“夏”的用户
DataRow[] drs5 =dtUsers.Select("name like ''夏%''");
6.筛选所有18岁以上的用户且按从大到小的顺序排序
DataRow[] drs5 =dtUsers.Select("age >=18","age desc");
7.上面最后一种用法没试过,有机会再列举出来。
注意事项
1.上面的Select操作是不区分大小写的(表字段不敏感,如pl-sql语法),如果需要区分大小写,需要将DataTable的caseSensitive属性设为true,例如上表的
dtUsers.CaseSensitive = true;//区分大小写
2.今天做开发发现一个问题,那边是对空白符的筛选无效,即dt.Select("colnume = '''' ");经过调试后发现是因为我的数据源是从数据库中查询的,如下(表名dtOriginal):
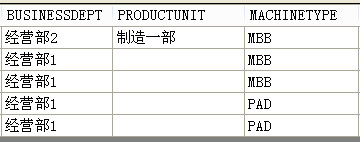
我在对PRODUCTUNIT列进行筛选的时候,第一行的“制作一部”筛选出了结果,而后面4行并没有,因为是数据类型的问题——
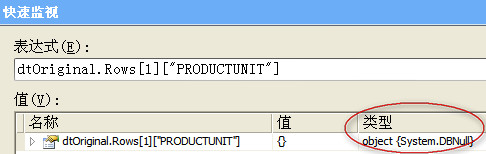
解决办法有两种,一种是把所有的空白单元格替换成空格字符 ‘’,一种是在数据库查询的时候用decode()函数进行替换,例如SELECT DECODE(列名,NULL,'''',''列本身'') FROM 表名(用replace函数在数据库中替换NULL是无效的)。
转载自:https://www.cnblogs.com/programsky/p/4290024.html。
什么是SQL游标?
1.1游标的概念
游标(Cursor)它使用户可逐行访问由SQL Server返回的结果集。使用游标(cursor)的一个主要的原因就是把集合操作转换成单个记录处理方式。用SQL语言从数据库中检索数据后,结果放在内存的一块区域中,且结果往往是一个含有多个记录的集合。游标机制允许用户在SQL server内逐行地访问这些记录,按照用户自己的意愿来显示和处理这些记录。
1.2 游标的优点
从游标定义可以得到游标的如下优点,这些优点使游标在实际应用中发挥了重要作用:
1)允许程序对由查询语句select返回的行集合中的每一行执行相同或不同的操作,而不是对整个行集合执行同一个操作。
2)提供对基于游标位置的表中的行进行删除和更新的能力。
3)游标实际上作为面向集合的数据库管理系统(RDBMS)和面向行的程序设计之间的桥梁,使这两种处理方式通过游标沟通起来。
1.3 游标的使用
讲了这个多游标的优点,现在我们就亲自来揭开游标的神秘的面纱。
使用游标的顺序: 声名游标、打开游标、读取数据、关闭游标、删除游标。
1.3.1声明游标
最简单游标声明:DECLARE <游标名>CURSOR FOR;
其中select语句可以是简单查询,也可以是复杂的接连查询和嵌套查询
例子:[已表2 AddSalary为例子]
Declare mycursor cursor for select * from AddSalary 这样我就对表AddSalary申明了一个游标mycursor
【高级备注】
DECLARE <游标名> [INSENSITIVE] [SCROLL] CURSORFOR 这里我说一下游标中级应用中的[INSENSITIVE]和[SCROLL]
INSENSITIVE
表明MS SQL SERVER 会将游标定义所选取出来的数据记录存放在一临时表内(建立在tempdb 数据库下)。对该游标的读取操作皆由临时表来应答。因此,对基本表的修改并不影响游标提取的数据,即游标不会随着基本表内容的改变而改变,同时也无法通过游标来更新基本表。如果不使用该保留字,那么对基本表的更新、删除都会反映到游标中。
另外应该指出,当遇到以下情况发生时,游标将自动设定INSENSITIVE 选项。
a.在SELECT 语句中使用DISTINCT、 GROUP BY、 HAVING UNION 语句;
b.使用OUTER JOIN;
c.所选取的任意表没有索引;
d.将实数值当作选取的列。
SCROLL
表明所有的提取操作(如FIRST、 LAST、 PRIOR、 NEXT、 RELATIVE、 ABSOLUTE)都可用。如果不使用该保留字,那么只能进行NEXT 提取操作。由此可见,SCROLL 极大地增加了提取数据的灵活性,可以随意读取结果集中的任一行数据记录,而不必关闭再
重开游标。
1.3.2 打开游标
非常简单,我们就打开刚才我们声明的游标mycursor
OPEN mycursor
1.3.3读取数据
参数说明:
NEXT 取下一行的数据,并把下一行作为当前行(递增)。由于打开游标后,行指针是指向该游标第1行之前,所以第一次执行FETCH NEXT操作将取得游标集中的第1行数据。NEXT为默认的游标提取选项。
INTO @变量名[,…] 把提取操作的列数据放到局部变量中。列表中的各个变量从左到右与游标结果集中的相应列相关联。各变量的数据类型必须与相应的结果列的数据类型匹配或是结果列数据类型所支持的隐性转换。变量的数目必须与游标选择列表中的列的数目一致。
现在我们就取出mycursor游标的数据吧!
当游标被打开时,行指针将指向该游标集第1行之前,如果要读取游标集中的第1行数据,必须移动行指针使其指向第1行。就本例而言,可以使用下列操作读取第1行数据:
Eg: Fetch next from mycursor 或则 Fetch first from mycursor
这样我就取出了游标里的数据,但是光光这样可不够,我们还需要将取出的数据赋给变量
CLOSE mycursor
1.3.5删除游标
DEALLOCATE mycursor
转载自:https://blog.csdn.net/shang_111111/article/details/8183737。
SQL Server数据类型转换方法
在SQL Server日常的函数、存储过程和SQL语句中,经常会用到不同数据类型的转换。在SQL Server有两种数据转换类型:一种是显性数据转换;另一种是隐性数据转换。下面分别对这两种数据类型转换进行简要的说明:
1 显式转换
显示转换是将某种数据类型的表达式显式转换为另一种数据类型。常用的是CAST 和 CONVERT 函数。
CAST: CAST ( expression AS data_type )
CONVERT: CONVERT (data_type[(length)], expression [, style])
参数 expression 是任何有效的 Microsoft SQL Server表达式。data_type 目标系统所提供的数据类型,不能使用用户定义的数据类型。
2 隐性转换
隐性转换对于用户是不可见的,由SQL Server 引擎自动处理。 隐性转换自动将数据从一种数据类型转换成另一种数据类型。例如,如果一个 smallint 变量和一个 int 变量相比较,这个 smallint 变量在比较前即被隐性转换成 int 变量。 当从一个 SQL Server 对象的数据类型向另一个转换时,一些隐性和显式数据类型转换是不支持的。例如,nchar 数值根本就不能被转换成 image 数值。nchar 只能显式地转换成 binary,隐性地转换到 binary 是不支持的。nchar 可以显式地或者隐性地转换成 nvarchar。
3 隐性转换的风险
隐性转换有的时候非常方便,可以简化SQL 脚本,但是这里面也孕育着潜在的风险,可能会出现在脚本一开始运行的时候都是正常的,但却某一个时间点之后,程序莫名出现错误。下面举一个现实项目中的例子来说明。在SQL Server 2008中有一个表,需要从两个不同的数据表中拉取数据,由于这两个数据表属于不同的系统,其主键类型是不同的,一个是int类型,一个是GUID,一开始想着这两个都可以转换成字符类型进行存储。所以就在表中建立一个nvarchar(50)的混合ID列作为主键。如下图所示:

一开始拉取的数据并未有GUID的值,都是INT类型转换过来的数据,所以SQL脚本运行的正常,但是突然某一次运行时,出现了“在将 nvarchar 值 ''4C185367-F004-41FE-8A0A-DB4E819B1FF2'' 转换成数据类型 int 时失败。”的错误。如下图所示:

定位到脚本,执行的SQL如下:
select * from dbo.Demo where 混合ID=305
其中主键中的数据有GUID转换的字符型,也有INT转换的字符串,示例数据如下:

但是如果执行下面的SQL,则都是正常执行:
- select * from dbo.Demo where 混合ID=305 and 名称=''INT''
- select * from dbo.Demo where 混合ID=305 and 序号=''2''
- select * from dbo.Demo where 混合ID=305 and 序号=2
- select * from dbo.Demo where 混合ID=''305'' and 名称=''INT''
- select * from dbo.Demo where 混合ID=''305''
结果如下:

出现上述错误的结果应该是这样的:
select * from dbo.Demo where 混合ID=305在执行时,SQL Server会将nvarchar类型的隐性转换成int类型,如果数据中没有GUID类型的字符,则转换正常,如果有,当进行GUID字符到INT的隐性转换时,则转换失败。
转载自:https://blog.csdn.net/qq_37446416/article/details/54861081。
LinQ是什么?
•LINQ(发音:Link)是语言级集成查询(Language INtegrated Query)

var q =
from c in db.Customers
where c.City == "London"
select c;
select * from employee where empno=7376;
SQL Server 分页方法汇总
PageSize = 30
PageNumber = 201
方法一:(最常用的分页代码, top / not in)
select top 30 UserId from UserInfo where UserId not in (select top 6000 UserId from UserInfo order by UserId) order by UserId备注: 注意前后的order by 一致
方法二:(not exists, not in 的另一种写法而已)
select top 30 * from UserLog where not exists (select 1 from (select top 6000 LogId from UserLog order by LogId) a where a.LogId = UserLog.LogId) order by LogId备注:EXISTS用于检查子查询是否至少会返回一行数据,该子查询实际上并不返回任何数据,而是返回值True或False。此处的 select 1 from 也可以是select 2 from,select LogId from, select * from 等等,不影响查询。而且select 1 效率最高,不用查字典表。效率值比较:1 > anycol > *
方法三:(top / max, 局限于使用可比较列排序的时候)
select top 30 * from UserLog where LogId > (select max(LogId) from (select top 6000 LogId from UserLog order by LogId) a ) order by LogId备注:这里max()函数也可以用于文本列,文本列的比较会根据字母顺序排列,数字 < 字母(无视大小写) < 中文字符
方法四:(row_number() over (order by LogId))
select top 30 * from ( select row_number() over (order by LogId) as rownumber,* from UserLog)a
where rownumber > 6000 order by LogIdselect * from (select row_number()over(order by LogId) as rownumber,* from UserLog)a
where rownumber > 6000 and rownumber < 6030 order by LogIdselect * from (select row_number()over(order by LogId) as rownumber,* from UserLog)a
where rownumber between 6000 and 6030 order by LogId


select *
from (
select row_number()over(order by tempColumn)rownumber,*
from (select top 6030 tempColumn=0,* from UserLog where 1=1 order by LogId)a
)b
where rownumber>6000
row_number() 的变体,不基于已有字段产生记录序号,先按条件筛选以及排好序,再在结果集上给一常量列用于产生记录序号
以上几种方法参考http://www.cnblogs.com/songjianpin/articles/3489050.html

备注: 这里rownumber方法属于排名开窗函数(sum, min, avg等属于聚合开窗函数,ORACLE中叫分析函数,参考文章:SQL SERVER 开窗函数简介 )的一种,搭配over关键字使用。
方法五:(offset /fetch next, SQL Server 2012支持)
select * from UserLog Order by LogId offset 6000 rows fetch next 30 rows only备注: 性能参考文章《SQL Server 2012使用OFFSET/FETCH NEXT分页及性能测试》
参考文档:
1、http://blog.csdn.net/qiaqia609/article/details/41445233
2、http://www.cnblogs.com/songjianpin/articles/3489050.html
3、http://database.51cto.com/art/201108/283399.htm
转自:http://www.cnblogs.com/shengxincai/p/6097588.html。

SQlite:select into?
select * into bookmark1 from bookmark;
是真的sqlite不支持这种语法吗?有没有其他替代品?
insert into bookmark1 select * from bookmark
,MIN(col),MAX(col)快于SELECT MIN(col),MAX(col)")
SQL为什么是SELECT COUNT(*),MIN(col),MAX(col)快于SELECT MIN(col),MAX(col)
慢查询
SELECT MIN(col) AS Firstdate,MAX(col) AS Lastdate FROM table WHERE status = 'OK' AND fk = 4193
表’表’.扫描计数2,逻辑读取2458969,物理读取0,预读读取0,lob逻辑读取0,lob物理读取0,lob预读读取0.
sql Server执行时间:cpu时间= 1966 ms,已用时间= 1955 ms.
快速查询
SELECT count(*),MIN(col) AS Firstdate,MAX(col) AS Lastdate FROM table WHERE status = 'OK' AND fk = 4193
表’表’.扫描计数1,逻辑读取5803,lob预读读取0.
sql Server执行时间:cpu时间= 0 ms,已用时间= 9 ms.
题
查询之间巨大的性能差异之间的原因是什么?
更新
基于作为评论的问题的一点更新:
执行顺序或重复执行不会改变性能.
没有使用额外的参数,(测试)数据库在执行过程中没有做任何其他的事情.
慢查询
|--nested Loops(Inner Join)
|--Stream Aggregate(DEFINE:([Expr1003]=MIN([DBTest].[dbo].[table].[startdate])))
| |--Top(TOP EXPRESSION:((1)))
| |--nested Loops(Inner Join,OUTER REFERENCES:([DBTest].[dbo].[table].[id],[Expr1008]) WITH ORDERED PREFETCH)
| |--Index Scan(OBJECT:([DBTest].[dbo].[table].[startdate]),ORDERED FORWARD)
| |--Clustered Index Seek(OBJECT:([DBTest].[dbo].[table].[PK_table]),SEEK:([DBTest].[dbo].[table].[id]=[DBTest].[dbo].[table].[id]),WHERE:([DBTest].[dbo].[table].[FK]=(5806) AND [DBTest].[dbo].[table].[status]<>'A') LOOKUP ORDERED FORWARD)
|--Stream Aggregate(DEFINE:([Expr1004]=MAX([DBTest].[dbo].[table].[startdate])))
|--Top(TOP EXPRESSION:((1)))
|--nested Loops(Inner Join,[Expr1009]) WITH ORDERED PREFETCH)
|--Index Scan(OBJECT:([DBTest].[dbo].[table].[startdate]),ORDERED BACKWARD)
|--Clustered Index Seek(OBJECT:([DBTest].[dbo].[table].[PK_table]),WHERE:([DBTest].[dbo].[table].[FK]=(5806) AND [DBTest].[dbo].[table].[status]<>'A') LOOKUP ORDERED FORWARD)
快速查询
|--Compute Scalar(DEFINE:([Expr1003]=CONVERT_IMPLICIT(int,[Expr1012],0)))
|--Stream Aggregate(DEFINE:([Expr1012]=Count(*),[Expr1004]=MIN([DBTest].[dbo].[table].[startdate]),[Expr1005]=MAX([DBTest].[dbo].[table].[startdate])))
|--nested Loops(Inner Join,[Expr1011]) WITH UnorDERED PREFETCH)
|--Index Seek(OBJECT:([DBTest].[dbo].[table].[FK]),SEEK:([DBTest].[dbo].[table].[FK]=(5806)) ORDERED FORWARD)
|--Clustered Index Seek(OBJECT:([DBTest].[dbo].[table].[PK_table]),WHERE:([DBTest].[dbo].[table].[status]<'A' OR [DBTest].[dbo].[table].[status]>'A') LOOKUP ORDERED FORWARD)
回答
马丁史密斯下面给出的答案似乎解释了这个问题.超简短版本是MS-SQL查询分析器在慢查询中错误地使用查询计划,从而导致完整的表扫描.
添加一个Count(*),使用(FORCESCAN)的查询提示或startdate,FK和status列上的组合索引修复了性能问题.
解决方法
- Independence: Data distributions on different columns are independent unless correlation information is available.
- Uniformity: Within each statistics object histogram step,distinct values are evenly spread and each value has the same frequency.
07000
表中有810,064行.
你有查询
SELECT COUNT(*),MIN(startdate) AS Firstdate,MAX(startdate) AS Lastdate
FROM table
WHERE status <> 'A'
AND fk = 4193
1,893(0.23%)行满足fk = 4193谓词,并且那些行失败状态为<> “A”部分总共1,891匹配,需要聚合.
您也有两个索引,两个索引都不包括整个查询.
对于您的快速查询,它使用fk上的索引直接查找fk = 4193的行,然后需要执行1,893 key lookups查找聚簇索引中的每一行以检查状态谓词并检索用于聚合的startdate.
从SELECT列表中删除COUNT(*)时,sql Server不再需要处理每个合格的行.因此,它考虑了另一个选择.
您在startdate上有一个索引,所以它可以从一开始就开始扫描,执行关键查找回到基表,一旦找到第一个匹配的行停止,就像找到MIN(startdate)一样,MAX也可以发现另一个扫描开始索引的另一端并向后工作.
sql Server估计,这些扫描中的每一个都会在匹配谓词之前结束处理590行.提供1,180总查询与1,893,所以选择这个计划.
590的数字只是table_size / estimated_number_of_rows_that_match.即基数估计器假设匹配行将在整个表格中均匀分布.
不幸的是,符合谓词的1,891行不是随机分配的,与startdate相关.事实上,它们都被缩小为单个8,205行分段,指向索引的末尾,意味着进入MIN(startdate)的扫描最终可以执行801,859次查询,然后才能停止.
这可以在下面再现.
CREATE TABLE T ( id int identity(1,1) primary key,startdate datetime,fk int,[status] char(1),Filler char(2000) ) CREATE NONCLUSTERED INDEX ix ON T(startdate) INSERT INTO T SELECT TOP 810064 Getdate() - 1,4192,'B','' FROM sys.all_columns c1,sys.all_columns c2 UPDATE T SET fk = 4193,startdate = GETDATE() WHERE id BETWEEN 801859 and 803748 or id = 810064 UPDATE T SET startdate = GETDATE() + 1 WHERE id > 810064 /*Both queries give the same plan. UPDATE STATISTICS T WITH FULLSCAN makes no difference*/ SELECT MIN(startdate) AS Firstdate,MAX(startdate) AS Lastdate FROM T WHERE status <> 'A' AND fk = 4192 SELECT MIN(startdate) AS Firstdate,MAX(startdate) AS Lastdate FROM T WHERE status <> 'A' AND fk = 4193
您可以考虑使用查询提示强制计划使用fk而不是startdate上的索引,或者在(fk,status)INCLUDE(startdate)上执行计划中突出显示的建议的缺失索引,以避免此问题.
今天关于什么是SQL select的Big-O?的讲解已经结束,谢谢您的阅读,如果想了解更多关于MySQL-SQL_BIG_SELECTS、SQL Server游标 C# DataTable.Select() 筛选数据 什么是SQL游标? SQL Server数据类型转换方法 LinQ是什么? SQL Serve...、SQlite:select into?、SQL为什么是SELECT COUNT(*),MIN(col),MAX(col)快于SELECT MIN(col),MAX(col)的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

