本文的目的是介绍WebDriver的Python绑定中的selenium.wait_for_condition等效的详细情况,特别关注pythonseleniumwebdriver的相关信息。我们将通
本文的目的是介绍WebDriver的Python绑定中的selenium.wait_for_condition等效的详细情况,特别关注python selenium webdriver的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解WebDriver的Python绑定中的selenium.wait_for_condition等效的机会,同时也不会遗漏关于java – Selenium WebDriver中selenium.waitForPageToLoad(“30000”)的等效代码是什么?、python + selenium WebDriver的环境配置、Python selenium webdriver 基本使用、Python Selenium Webdriver安装手册的知识。
本文目录一览:- WebDriver的Python绑定中的selenium.wait_for_condition等效(python selenium webdriver)
- java – Selenium WebDriver中selenium.waitForPageToLoad(“30000”)的等效代码是什么?
- python + selenium WebDriver的环境配置
- Python selenium webdriver 基本使用
- Python Selenium Webdriver安装手册
")
WebDriver的Python绑定中的selenium.wait_for_condition等效(python selenium webdriver)
我正在将一些测试从Selenium移到WebDriver。我的问题是我找不到selenium.wait_for_condition的等效项。Python绑定现在有此功能还是仍在计划中?
答案1
小编典典当前,无法在WebDriver中使用wait_for_condition。python
selenium代码确实提供了DrivenSelenium类来访问旧的selenium方法,但是它不能执行wait_for_condition。
硒Wiki上有一些信息。
最好的选择是使用WebDriverWait类。这是一个帮助程序类,该类定期执行一个函数,等待其返回True。我的一般用法是
driver = webdriver.Firefox()driver.get(''http://example.com'')add = driver.find_element_by_id("ajax_button")add.click()source = driver.page_sourcedef compare_source(driver): try: return source != driver.page_source except WebDriverException: passWebDriverWait(driver, 5).until(compare_source)# and now do some assertions此解决方案绝不是理想的选择。对于页面请求/响应周期被延迟以等待某些ajax活动完成的情况,try /
except是必需的。如果在请求/响应周期中调用compare_source get,则会抛出WebDriverException。
WebDriverWait的测试范围也很有帮助。
的等效代码是什么?")
java – Selenium WebDriver中selenium.waitForPageToLoad(“30000”)的等效代码是什么?
selenium.waitForPagetoLoad("30000");
Selenium WebDriver中的等效java代码是什么?
解决方法
>如果你需要等待60秒,你可以使用Thread.sleep(60000)
>如果您想确保页面已加载(可能小于或大于60秒),我建议使用以下方法:
确定目标网页中的元素&等待它可以点击.然后您确定该页面已加载.
webdriverwait wait = new webdriverwait(driver,120); wait.until(ExpectedConditions.elementToBeClickable(By.id(id)));
WebDriver等待最多120秒.对于可点击的元素.如果元素在此之前可单击,则测试将进行.

python + selenium WebDriver的环境配置
想试用python语言来学习selenium WebDriver,首先需要搭建一个测试环境,从python安装到浏览器插件配置的详细步骤,总结如下:
一、python环境配置
1、从官网下载最新的一个python包https://www.python.org/downloads
2、python安装选择自定义安装,方便配置环境变量,其他安装步骤和其他软件安装一致
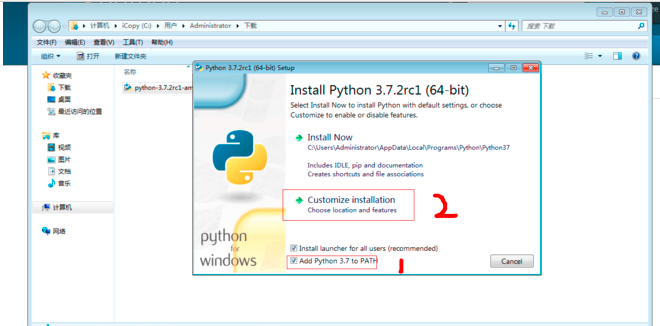
3、安装成功后去配置环境变量
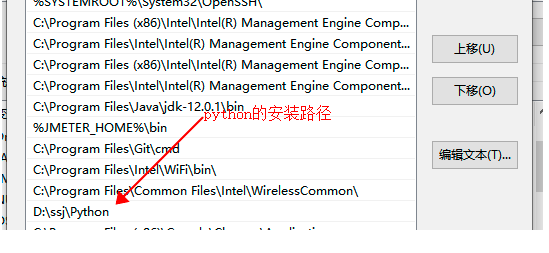
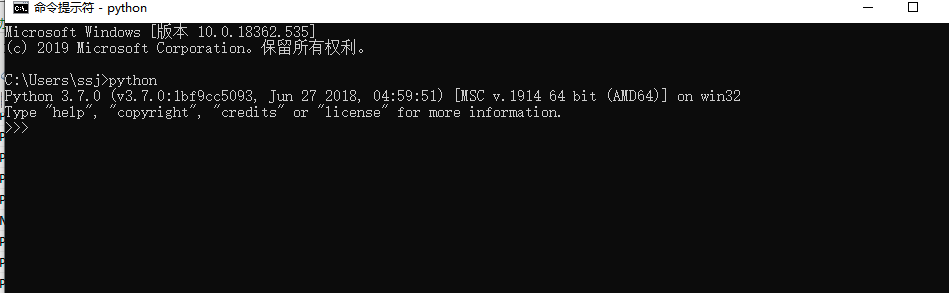
4、去验证python的环境配置是否成功,打开cmd窗口,输入python,如果环境配置成功会出现安装的python版本信息
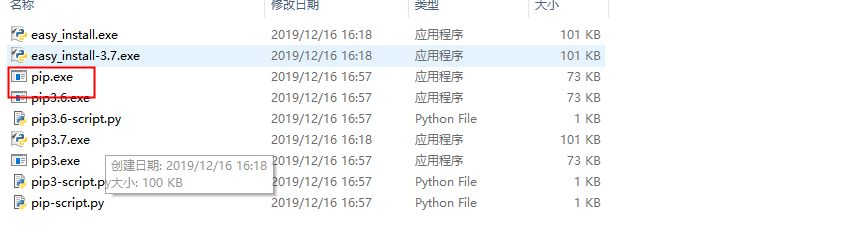
5、在python的安装目录下找到Scripts文件下的pip.exe,然后把该路径配置到环境变量中,如果没有该文件,需要单独去下载安装
配置成功后,在cmd窗口,输入pip,会出现如下信息
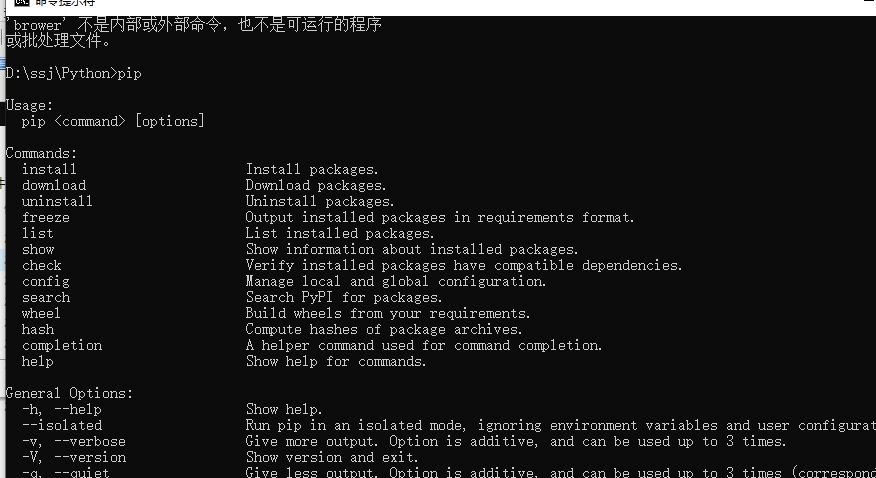
二、使用pip工具安装Selenium
1、进入pip所在安装目录执行下面命令可以在线安装
D:\Python\Scripts>pip install -U selenium
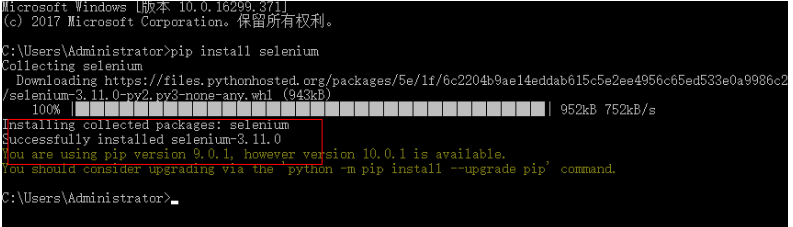
三、下载webdriver插件
1、chrome浏览器的webdriver下载地址 http://chromedriver.storage.googleapis.com/index.html ,需要找到浏览器版本对应的插件
2、把解压后的文件放在python文件下,和python.exe同一目录下
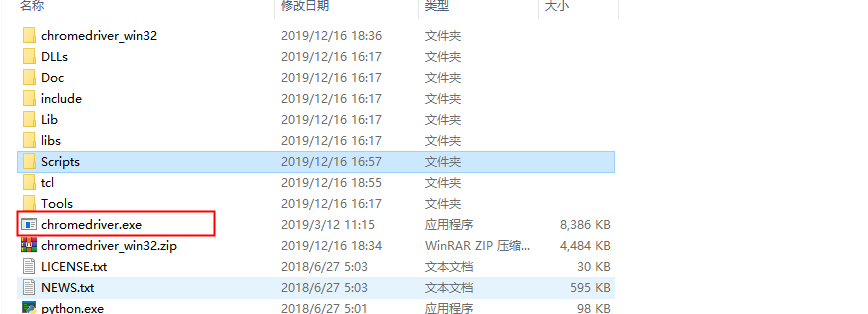
3、浏览器的安装路径也需要加入环境变量
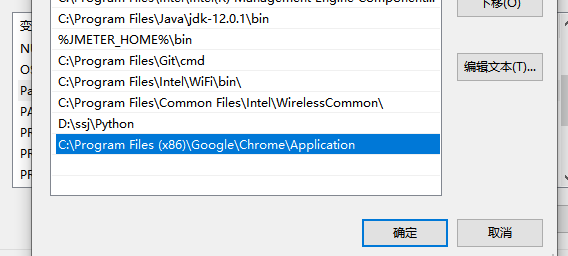
四、验证webdriver插件环境是否配置成功
1、运行python.exe
from selenium import webdriver
brower=webdriver.Chrome() //能打开浏览器说明配置成功了

Python selenium webdriver 基本使用
系列文章目录
selenium webdriver 的常用示例
文章目录
- 系列文章目录
- selenium webdriver 的常用示例
- 前言
- 一、Pip安装&创建Bowser对象
- 1.Pip install selenium
- 2.创建Bowser对象
- 二、webdriver.ChromeOptions配置
- 配置浏览器的常用模式
- 三、常用代码
- 四、selenium的异常处理
- 总结
前言
本文就介绍了Selenium的常用内容:了解Selenium Webdriver 是干什么的
以下是本篇文章正文内容,下面案例可供参考
一、Pip安装&创建Bowser对象
1.Pip install selenium
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
2.创建Bowser对象
# 导入webdriver模块
from selenium import webdriver
# 指定使用Chrome浏览器
driver = webdriver.Chrome() # chrome_options,executable_path常用这两个参数
二、webdriver.ChromeOptions配置
配置浏览器的常用模式
chromeoptions 的常用功能
(1)添加启动参数 (add_argument)
(2)添加扩展应用参数 (add_extension,add_encoded_extension),常用在代理身份验证
(3)添加实验性质参数 (add_experimental_option)
代码如下(示例):
options= webdriver.ChromeOptions() # 创建配置对象
options.add_argument('lang=zh_CN.UTF-8') # 设置中文
options.add_argument('--headless') # 无头参数,浏览器隐藏在后台运行
options.add_argument('--disable-gpu') # 禁用GPU加速
options.add_argument('--start-maximized')#浏览器最大化
options.add_argument('--window-size=1280x1024') # 设置浏览器分辨率(窗口大小)
options.add_argument('--user-agent=""') # 设置请求头的User-Agent
options.add_argument('--incognito') # 隐身模式(无痕模式)
options.add_argument(f'--proxy-server={proxy}') # 添加IP代理 proxy=f"http://{ip}:{port}"
# 关闭'Chrome目前受到自動測試軟體控制'的提示
options.add_experimental_option('useAutomationExtension', False)
options.add_experimental_option('excludeSwitches', ['enable-automation'])
prefs = {
"download.default_directory":"D:\download", # 设置浏览器下载地址(绝对路径)
"profile.managed_default_content_settings.images": 2, # 不加载图片
}
chrome_options.add_experimental_option('prefs', prefs) # 添加prefs
# chrome_options="浏览器配置参数", executable_path="浏览器驱动绝对路径"
driver = webdriver.Chrome(chrome_options=options") # 创建浏览器对象
driver.maximize_window() # 浏览器窗口最大化
driver.set_page_load_timeout(30) # 设置连接超时30秒
三、常用代码
# 导入webdriver模块
from selenium import webdriver
driver = webdriver.Chrome() # chrome_options,executable_path常用这两个参数
# get 会一直等到页面被完全加载,然后才会执行下一步代码,如果超出了set_page_load_timeout()的设置,则会抛出异常。
driver.get("https://baidu.com/")
new_window = driver.window_handles[-1] # 新窗口'-1'代表打开的最后一个窗口,导航栏有多少个窗口根据下标来锁定
driver.switch_to.window(new_window) # 切换到新窗口:
driver.switch_to.frame('passport_iframe') # 根据name或id 定位至 iframe
driver.switch_to.default_content() # 切换出(iframe)至默认,有好多种切换方式找BaiDu
driver.find_element_by_xpath('//input[@xx="xxxx"]').send_keys(content) # 根据xpath语法定位元素输入内容
driver.find_element_by_xpath('//div[@xx="xxxx"]').click() # 根据xpath语法定位元素后并点击
driver.find_element_by_xpath('//div[@xx="xxxx"]').text # 根据xpath语法定位后获取元素的文本信息
driver.get_cookie('name') #根据name取出对应字典类型的对象
driver.get_cookies() # 返回一个列表,包含多个字典类型的对象
# 添加Cookie部分参数介绍:name=cookie的名称,value=cookie对应的值,domain=服务器域名,expiry=Cookie有效终止日期
driver.add_cookie({'name' : 'xxx', 'value' : 'xxx'}) # 添加cookie
driver.delete_cookie('name') # 删除指定部分的Cookie
driver.delete_all_cookies() # 删除所有Cookie
js="var q=document.documentElement.scrollTop=10000" # 滚动到最下面
js="var q=document.documentElement.scrollTop=0" # 滚动到最上面
driver.execute_script(js) # 执行JS代码,更多自行BaiDu
driver.quit() # 退出浏览器
四、selenium的异常处理
# 导入exceptions模块
from selenium.common import exceptions
try:
# 执行代码
except exceptions.TimeoutException:
print("xxxx - 请求加载超时异常!\n", end='')
except exceptions.NoSuchElementException:
print("xxxx - 网页元素定位异常!\n", end='')
except exceptions.NoSuchWindowException:
print("xxxx - 目标窗口切换异常!\n", end='')
except exceptions.WebDriverException:
print("xxxx - 浏览器对象各种异常!\n", end='')
except Exception:
print("xxxx - 以上未捕捉到的异常!\n", end='')
selenium 更多异常参考:https://blog.csdn.net/cunhui1209/article/details/112544287
总结
例如:以上就是今天要记录的内容,本文仅仅简单介绍了selenium的使用,selenium 提供了大量能使我们捷地实现自动化测试的函数和方法,后续会在本文的基础上记录新的常用操作。
Google官方下载地址:https://www.google.cn/chrome/
Google驱动下载地址:https://npm.taobao.org/mirrors/chromedriver/
驱动配置请参考:https://blog.csdn.net/flyskymood/article/details/123203105

Python Selenium Webdriver安装手册
本次就python webdriver的安装和驱动不同浏览器的配置进行分享,以解决大家在入门过程中的一些基本的环境问题。
python安装
目前python有2.x和3.x版本,笔者在这里推荐2.x版本。
从下述地址,根据自己操作系统的版本下载32位或64位的python 2.x最新版本:https://www.python.org/downloads/
双击下载的python安装包,默认或自定义安装路径,一步步的完成安装。
在命令行中,输入python,回车,确保python已加入环境变量。如图:
升级最新的pip
在命令中输入以下命令,升级最新版的pip
python -mpip install -Upip
为什么要升级pip: 确保后续大家在使用pip安装python包时,能获取最新最稳定的包。
安装webdriver
在命令行中输入以下命令,安装最新版的webdriver
pipinstallselenium-U
注:webdriver是selenium 2的一部分。
配置各种浏览器的驱动
firefox 下载地址:https://github.com/
mozilla/geckodriver/releases下载后,将解压的geckodriver.exe放至在python安装的根目录,笔者放在C:/Python27下。
注:要使用geckodriver,须把selenium升级至3.3及以上版本
ie 下载地址:http://selenium-release.storage.googleapis.com/index.html请从中选择最新版,注意是32位还是64位。 下载后,将解压的iedriver.exe放至在python安装的根目录,笔者放在C:/Python27下。
chrome 下载地址:http://chromedriver.storage.googleapis.com/index.html请从中选择最新版,注意是32位还是64位。 下载后,将解压的chromedriver.exe放至在python安装的根目录,笔者放在C:/Python27下。
phantomjs 下载地址:http://phantomjs.org/download.html请从中选择最新版,注意是32位还是64位。 下载后,将解压的phantomjs.exe放至在python安装的根目录,笔者放在C:/Python27下。
注: 请注意各驱动所支持的对应的浏览器版本(webdriver、驱动、浏览器三者需匹配),不然会出现启动浏览器失败或connect timeout等异常
关于WebDriver的Python绑定中的selenium.wait_for_condition等效和python selenium webdriver的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于java – Selenium WebDriver中selenium.waitForPageToLoad(“30000”)的等效代码是什么?、python + selenium WebDriver的环境配置、Python selenium webdriver 基本使用、Python Selenium Webdriver安装手册等相关知识的信息别忘了在本站进行查找喔。
本文标签:




