对于SQLServer:将几行数据合并为一行感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍sqlserver多行数据合并一行,并为您提供关于linux中将指定行数据合并为一行数据、mysql中
对于SQL Server:将几行数据合并为一行感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍sql server 多行数据合并一行,并为您提供关于linux中将指定行数据合并为一行数据、mysql中将多行数据合并成一行数据、SQL 2008将具有相同ID的多行数据合并为一行、SQL Server Sql function 多行中的列合并为一行一列的方法的有用信息。
本文目录一览:- SQL Server:将几行数据合并为一行(sql server 多行数据合并一行)
- linux中将指定行数据合并为一行数据
- mysql中将多行数据合并成一行数据
- SQL 2008将具有相同ID的多行数据合并为一行
- SQL Server Sql function 多行中的列合并为一行一列的方法
")
SQL Server:将几行数据合并为一行(sql server 多行数据合并一行)
我想要做的是合并几行数据,以便在Transact-SQL或SSIS中将其显示为单行。因此,例如:
制作:
REF ID Title Surname Forename DOB Add1 Postcode------------------------------------------------------------------------------------------ D 10 MR KINGSTON NULL 15/07/1975 3 WATER SQUARE NULLT 10 NULL NULL BOB NULL NULL NULLT 10 MRS NULL NULL NULL NULL TW13 7DT到这个:
REF ID Title Surname Forename DOB Add1 Postcode---------------------------------------------------------------------------------- D 10 MRS KINGSTON BOB 15/07/1975 3 WATER SQUARE TW13 7DT因此,我所做的就是将值合并在一起,而忽略了null值。(D =数据; T =更新)
任何建议将是最欢迎的。
谢谢。
答案1
小编典典这将起作用,但是由于没有标识或日期时间列-无法找到哪个更新行是较新的。因此,如果同一列上有更多更新,那么我只需按字母/数字(MIN)来选择第一个。
WITH CTE AS ( SELECT ID, REF, MIN(Title) Title, MIN(Surname) Surname, MIN(Forename) Forename, MIN(DOB) DOB, MIN(Add1) Add1, MIN(Postcode) Postcode FROM Table1 GROUP BY id, REF)SELECT d.REF , d.ID , COALESCE(T.Title, d.TItle) AS Title , COALESCE(T.Surname, d.Surname) AS Surname , COALESCE(T.Forename, d.Forename) AS Forename , COALESCE(T.DOB, d.DOB) AS DOB , COALESCE(T.Add1, d.Add1) AS Add1 , COALESCE(T.Postcode, d.Postcode) AS PostcodeFROM CTE d INNER JOIN CTE t ON d.ID = t.ID AND d.REF = ''D'' AND t.REF = ''t''SQLFiddle演示
如果可以添加标识列,我们可以重写CTE部分以使其更准确。
编辑:
如果我们有标识列,并且将CTE重写为递归,则实际上可以删除整个查询的其他部分。
WITH CTE_RN AS ( --Assigning row_Numbers based on identity - it has to be done since identity can always have gaps which would break the recursion SELECT *, ROW_NUMBER() OVER (PARTITION BY ID ORDER BY IDNT DESC) RN FROM dbo.Table2),RCTE AS ( SELECT ID , Title , Surname , Forename , DOB , Add1 , Postcode , RN FROM CTE_RN WHERE RN = 1 -- taking the last row for each ID UNION ALL SELECT r.ID, COALESCE(r.TItle,p.TItle), --Coalesce will hold prev value if exist or use next one COALESCE(r.Surname,p.Surname), COALESCE(r.Forename,p.Forename), COALESCE(r.DOB,p.DOB), COALESCE(r.Add1,p.Add1), COALESCE(r.Postcode,p.Postcode), p.RN FROM RCTE r INNER JOIN CTE_RN p ON r.ID = p.ID AND r.RN + 1 = p.RN --joining the previous row for each id),CTE_Group AS ( --rcte now holds both merged and unmerged rows, merged is max(rn) SELECT ID, MAX(RN) RN FROM RCTE GROUP BY ID )SELECT r.* FROM RCTE rINNER JOIN CTE_Group g ON r.ID = g.ID AND r.RN = g.RNSQLFiddle演示

linux中将指定行数据合并为一行数据
1、测试数据
root@DESKTOP-1N42TVH:/home/test# ls a.txt root@DESKTOP-1N42TVH:/home/test# cat a.txt 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20
2、将每两行数据合并为一行数据
a、sed实现
root@DESKTOP-1N42TVH:/home/test# ls a.txt root@DESKTOP-1N42TVH:/home/test# cat a.txt 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20 root@DESKTOP-1N42TVH:/home/test# sed 'N; s/\n/ /' a.txt ## 将每两行中间的换行符替换为空格 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20
b、awk实现
root@DESKTOP-1N42TVH:/home/test# ls a.txt root@DESKTOP-1N42TVH:/home/test# cat a.txt 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20 root@DESKTOP-1N42TVH:/home/test# awk '{if(NR % 2 == 0) {print $0} else {printf("%s ", $0)}}' a.txt 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20
c、paste实现
root@DESKTOP-1N42TVH:/home/test# ls a.txt root@DESKTOP-1N42TVH:/home/test# cat a.txt 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 root@DESKTOP-1N42TVH:/home/test# cat a.txt | paste - - 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 root@DESKTOP-1N42TVH:/home/test# cat a.txt | paste - - -d " " 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20
3、将每三行数据合并为一行数据
a、awk实现
root@DESKTOP-1N42TVH:/home/test# ls a.txt root@DESKTOP-1N42TVH:/home/test# cat a.txt 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20 root@DESKTOP-1N42TVH:/home/test# awk '{if(NR % 3 == 0) {print $0} else {printf("%s ", $0)}}' a.txt ## 不完整行最后缺少空格 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20 root@DESKTOP-1N42TVH:/home/test# awk '{if(NR % 3 == 0) {print $0} else {printf("%s ", $0)}}' a.txt | sed '$ s/$/\n/' ## sed添加空格 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20 root@DESKTOP-1N42TVH:/home/test# awk '{if(NR % 3 == 0) {print $0} else {printf("%s ", $0)}}' a.txt | sed '$ s/$/\n/' 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20
b、paste实现
root@DESKTOP-1N42TVH:/home/test# ls a.txt root@DESKTOP-1N42TVH:/home/test# cat a.txt 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 root@DESKTOP-1N42TVH:/home/test# cat a.txt | paste - - - ## 每三行合并为一行 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 root@DESKTOP-1N42TVH:/home/test# cat a.txt | paste - - - -d " " ## 指定输出分割符 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20
4、每四行数据合并为一行数据
a、awk实现
root@DESKTOP-1N42TVH:/home/test# ls a.txt root@DESKTOP-1N42TVH:/home/test# cat a.txt 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20 root@DESKTOP-1N42TVH:/home/test# awk '{if(NR % 4 == 0) {print $0} else {printf("%s ", $0)}}' a.txt 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20 root@DESKTOP-1N42TVH:/home/test# awk '{if(NR % 4 == 0) {print $0} else {printf("%s ", $0)}}' a.txt | sed '$ s/$/\n/' 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20 root@DESKTOP-1N42TVH:/home/test# awk '{if(NR % 4 == 0) {print $0} else {printf("%s ", $0)}}' a.txt | sed '$ s/$/\n/' 01 11 02 12 03 13 04 14 05 15 06 16 07 17 08 18 09 19 10 20
b、paste 实现
root@DESKTOP-1N42TVH:/home/test# ls a.txt root@DESKTOP-1N42TVH:/home/test# cat a.txt 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 root@DESKTOP-1N42TVH:/home/test# cat a.txt | paste - - - - 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 root@DESKTOP-1N42TVH:/home/test# cat a.txt | paste - - - - -d " " ## 将四行合并为一行 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20

mysql中将多行数据合并成一行数据
地址:https://www.cnblogs.com/shoshana-kong/p/11147690.html
mysql中将多行数据合并成一行数据
一个字段可能对应多条数据,用mysql实现将多行数据合并成一行数据
例如:一个活动id(activeId)对应多个模块名(modelName),按照一般的sql语句:
1 SELECT am.activeId,m.modelName
2 FROM activemodel am
3 JOIN model m
4 ON am.modelId = m.modelId
5 ORDER BY am.activeId查询出的列表为图1所示:
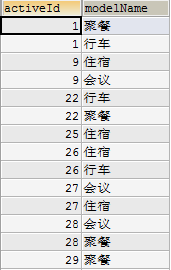
图1
修改过后的sql语句,查询后如图2所示:
1 SELECT am.activeId,GROUP_CONCAT(m.modelName SEPARATOR '','') modelName
2 FROM activemodel am
3 JOIN model m
4 ON am.modelId=m.modelId
5 WHERE m.valid=1
6 GROUP BY am.activeId需注意:
1.GROUP_CONCAT()中的值为你要合并的数据的字段名;
SEPARATOR 函数是用来分隔这些要合并的数据的;
'' ''中是你要用哪个符号来分隔;
2.必须要用GROUP BY 语句来进行分组管理,不然所有的数据都会被合并成一条记录,如图3

图2

图3

SQL 2008将具有相同ID的多行数据合并为一行
我在一个表中包含数据,该表包含同一CardNum的几行数据。我想创建一个表,其中同一CardNum的所有数据都显示在同一行上。
我的数据目前是这样的:
PartID | CardNumber | RdrGrpID | TZID0 412 31 10 412 34 10 567 38 10 567 33 50 567 71 3这就是我想要的数据:
PartID | CardNumber | RdrGrpID_1 | TZID_1 | RdrGrpID_2 | TZID_2 | RdrGrpID_3 | TZID_30 412 31 1 34 10 567 38 1 33 5 71 3先感谢您。
答案1
小编典典要获得此结果,可以采用几种方式来制定查询。
如果每个partId和的值数量有限cardNumber,则可以row_number()与聚合函数/ CASE组合一起使用:
select partid, cardnumber, max(case when rn = 1 then rdrgrpid end) rdrgrpid_1, max(case when rn = 1 then TZID end) TZID_1, max(case when rn = 2 then rdrgrpid end) rdrgrpid_2, max(case when rn = 2 then TZID end) TZID_2, max(case when rn = 3 then rdrgrpid end) rdrgrpid_3, max(case when rn = 3 then TZID end) TZID_3from( select partId, cardNumber, RdrGrpID, TZID , row_number() over(partition by partiD, cardnumber order by rdrgrpid) rn from yt) dgroup by partid, cardnumber;参见带有演示的SQL Fiddle
您还可以使用PIVOT / UNPIVOT函数获取结果:
select *from( select partid, cardnumber, col+''_''+cast(rn as varchar(10)) col, val from ( select partId, cardNumber, RdrGrpID, TZID , row_number() over(partition by partiD, cardnumber order by rdrgrpid) rn from yt ) d unpivot ( val for col in (rdrgrpid, tzid) ) un) spivot( max(val) for col in (RdrGrpID_1, TZID_1, RdrGrpID_2, TZID_2, RdrGrpID_3, TZID_3)) piv请参阅带有演示的SQL Fiddle。
现在,如果您有未知数量的值,那么您将需要使用动态sql:
DECLARE @colsPivot AS NVARCHAR(MAX), @query AS NVARCHAR(MAX)select @colsPivot = STUFF((SELECT '','' + QUOTENAME(c.col + ''_''+cast(rn as varchar(10))) from ( select row_number() over(partition by partiD, cardnumber order by rdrgrpid) rn from yt ) t cross apply ( select ''RdrGrpID'' col, 1 so union all select ''TZID'', 2 ) c group by col, rn, so order by rn, so FOR XML PATH(''''), TYPE ).value(''.'', ''NVARCHAR(MAX)'') ,1,1,'''')set @query = ''select partid, cardnumber, ''+@colsPivot+'' from ( select partid, cardnumber, col+''''_''''+cast(rn as varchar(10)) col, val from ( select partId, cardNumber, RdrGrpID, TZID , row_number() over(partition by partiD, cardnumber order by rdrgrpid) rn from yt ) d unpivot ( val for col in (rdrgrpid, tzid) ) un ) s pivot ( max(val) for col in (''+ @colspivot +'') ) p''exec(@query);请参阅带有演示的SQL Fiddle。所有版本均提供结果:
| PARTID | CARDNUMBER | RDRGRPID_1 | TZID_1 | RDRGRPID_2 | TZID_2 | RDRGRPID_3 | TZID_3 |-----------------------------------------------------------------------------------------| 0 | 412 | 31 | 1 | 34 | 1 | (null) | (null) || 0 | 567 | 33 | 5 | 38 | 1 | 71 | 3 |
SQL Server Sql function 多行中的列合并为一行一列的方法
感兴趣的小伙伴,下面一起跟随小编 jb51.cc的小编两巴掌来看看吧!
代码如下:
CREATE TABLE tb(standards varchar(50),amount varchar(50),variation varchar(50),statuss varchar(50),Reason varchar(50))
insert into tb values('55','279','4','物量积压','加工人员设备不足;T排制作进度较慢;')
insert into tb values('55','部件人员不足;')
insert into tb values('55','跨间场地积压;图纸问题较多;')
insert into tb values('56','300','AAAA;')
insert into tb values('56','BBBB;')
insert into tb values('56','CCCC;')
create function test(@standards varchar(100))
returns varchar(8000)
as
begin
declare @re varchar(500)
set @re = ''
select @re = @re+','+Reason
from tb
where @standards=standards
return (stuff(@re,1,''))
end
调用
代码如下:
select distinct standards,amount,variation,statuss,Reason = dbo.test('55') from tb where standards=55
select distinct standards,Reason = dbo.test('56') from tb where standards=56
今天的关于SQL Server:将几行数据合并为一行和sql server 多行数据合并一行的分享已经结束,谢谢您的关注,如果想了解更多关于linux中将指定行数据合并为一行数据、mysql中将多行数据合并成一行数据、SQL 2008将具有相同ID的多行数据合并为一行、SQL Server Sql function 多行中的列合并为一行一列的方法的相关知识,请在本站进行查询。
本文标签:




