这篇文章主要围绕在WHERE子句中使用多个变量的JavaSQLSelect语句展开,旨在为您提供一份详细的参考资料。我们将全面介绍在WHERE子句中使用多个变量的JavaSQLSelect语句,同时也
这篇文章主要围绕在WHERE子句中使用多个变量的Java SQL Select语句展开,旨在为您提供一份详细的参考资料。我们将全面介绍在WHERE子句中使用多个变量的Java SQL Select语句,同时也会为您带来INSERT语句中的WHERE子句使用mysql / php、java – 带有where子句的SQL select语句、mysql在where子句中使用用户定义的变量、Mysql应用msql select语句的WHERE子句详解的实用方法。
本文目录一览:- 在WHERE子句中使用多个变量的Java SQL Select语句
- INSERT语句中的WHERE子句使用mysql / php
- java – 带有where子句的SQL select语句
- mysql在where子句中使用用户定义的变量
- Mysql应用msql select语句的WHERE子句详解

在WHERE子句中使用多个变量的Java SQL Select语句
我正在使用UDP套接字编写一个简单的程序。我需要输入患者的姓名并从数据库中检索其详细信息。患者的姓名输入在Doctor类中,然后发送到Server类。然后,Server类执行查询以检索患者的详细信息。问题出在SQL语句中。当我仅使用变量名字时,它工作正常,但是当我放置第二个变量名字时,PatientRecord变量为NULL。
服务器类:
public class Server { public static Connection con; public static String PatientRecords; public static String QueryPatientInfo(String PatientDetails) throws SQLException { System.out.print("\nNew Patient query received:\n"); String [] PatientDetArray = PatientDetails.split(","); String firstname,lastname; firstname = PatientDetArray[1]; lastname = PatientDetArray[2]; System.out.println("First Name: "+ firstname); System.out.println("Last Name: "+ lastname); Statement query = con.createStatement(); query.execute("SELECT * FROM patient WHERE FirstName = ''"+firstname+"'' AND LastName = ''"+lastname+"'' "); ResultSet rs = query.getResultSet(); String sex; String dob ; String address ; String occupation; String phoneno ; if(rs != null){ while (rs.next()){ sex = rs.getString("Sex"); dob = rs.getString("DOB"); address = rs.getString("Address"); occupation = rs.getString("Occupation"); phoneno = rs.getString("PhoneNo"); PatientRecords = sex + "," + dob + "," + address + "," + occupation + "," + phoneno; } System.out.print("Patient records successfully retrieved from database !\n\n"); return PatientRecords; } else { System.out.print("Error occurred patient records not found !\n\n"); return "Error occurred patient records not found !"; } } public static void main(String[] args) throws IOException, SQLException { // Connecting to database - using xampp try { Class.forName("com.mysql.jdbc.Driver"); con = DriverManager.getConnection("jdbc:mysql://localhost/patientrecord", "root", ""); System.out.println("Database is connected !"); } catch(Exception e) { System.out.println("Database connection error: " + e); } DatagramSocket serverSocket = new DatagramSocket(8008); byte[] receiveData = new byte[1024]; byte[] sendData; System.out.println("Server ready and waiting for clients to connect..."); while (true) { DatagramPacket receivePacket = new DatagramPacket(receiveData, receiveData.length); serverSocket.receive(receivePacket); String PatientDetails = new String(receivePacket.getData()); String message; message = QueryPatientInfo(PatientDetails); System.out.print(message); InetAddress IPAddress = receivePacket.getAddress(); int port = receivePacket.getPort(); sendData = message.getBytes(); DatagramPacket sendPacket = new DatagramPacket(sendData, sendData.length, IPAddress, port); serverSocket.send(sendPacket); } }}医生班:
public class Doctor { public static void main(String[] args) throws IOException { BufferedReader inFromUser = new BufferedReader(new InputStreamReader(System.in)); DatagramSocket clientSocket = new DatagramSocket(); InetAddress IPAddress = InetAddress.getByName("localhost"); // Creating array of bytes to send and receive packet byte[] sendData; byte[] receiveData = new byte[1024]; String request,firstName,lastName; request = "query"; System.out.print("Patient Registration"); System.out.print("\n\nEnter Patient Details:\n"); // User input System.out.print("First name: \n"); firstName= inFromUser.readLine(); System.out.print("Last name: \n"); lastName = inFromUser.readLine(); String PatientDetails = request + ","+ firstName + "," +lastName; sendData = PatientDetails.getBytes(); DatagramPacket sendPacket = new DatagramPacket(sendData, sendData.length,IPAddress, 8008); // Send data packet to server clientSocket.send(sendPacket); DatagramPacket receivePacket = new DatagramPacket(receiveData, receiveData.length); //Receive data packet from server clientSocket.receive(receivePacket); String PatientRecords = new String(receivePacket.getData()); //System.out.print(PatientRecords); String [] PatientDetArray = PatientRecords.split(","); String sex,dob,address,occupation,phoneno; sex = PatientDetArray[0]; dob = PatientDetArray[1]; address = PatientDetArray[2]; occupation = PatientDetArray[3]; phoneno = PatientDetArray[4]; System.out.println("FROM SERVER: "); System.out.println("Details for patient : " + firstName + " " + lastName); System.out.println("Sex: " + sex); System.out.println("Date of birth: " +dob ); System.out.println("Address: " + address ); System.out.println("Occupation: " + occupation); System.out.println("Phone number: " + phoneno); clientSocket.close(); }}答案1
当您的字符串具有空格时,可能会发生这种情况,因此可以使用以下方法来避免这种情况trim():
query.execute("SELECT * FROM patient WHERE FirstName = ''" + firstname.trim() + "'' AND LastName = ''" + lastname.trim() + "'' ");您设置变量的方式不安全,它可能导致语法错误或导致SQL注入,因此建议您使用Prepapred语句,这种方式更安全,因此可以使用以下查询代替:
PreparedStatement preparedStatement = connection.prepareCall("SELECT * FROM patient WHERE FirstName = ? AND LastName = ? ");preparedStatement.setString(1, firstname.trim());preparedStatement.setString(2, lastname.trim());ResultSet result = preparedStatement.executeQuery();希望这可以与您合作。

INSERT语句中的WHERE子句使用mysql / php
在Google上搜索后,我才知道,
我不能在我的INSERT查询中使用WHERE子句.
但我想在列“Book_4”上插入一个值,其中“Student_ID = 1”
我怎样才能做到这一点 ??
有没有替代方法呢?
会感激你的!
$Query = "INSERT INTO issued_books (Book_4) VALUES ('$IssuedBookNumber')" ;
编辑:
更多细节
使用插入查询,当我在我的表中的“Student_ID”列中插入一个值. Student_ID行(Student_ID除外)中的所有列在我的数据库中显示为0.
根据DB,我知道这意味着什么.
它可能是Null或数字0.
如果它是数字0,则应使用UPDATE语句更新它.
但每当我试图更新它时,它永远不会使用UPDATE语句更新.这就是我要问的原因!
P.S:所有列都具有数据类型INT.
希望你明白我想说的话:)
这是完整的代码.
假设:已创建具有值2的Student_ID.
IssuedBookNumber = 51
使用以上值:
Result =创建一个新行,除了列为“IssuedBookNumber”且值为51的列之外,所有列都为0.
虽然我想,结果应该是:
在行Student_ID = 2时,Book_4应为51.
关键是,当我在Student_ID上插入一个值时,所有其他列在同一行上变为0.但是当同一行中的任何列具有除0之外的任何数字时(当我在Student_ID中插入值时,该列自动出现在所有列上).更新查询将工作..!
$IssuedBookNumber = $_POST['IssuedBookNumber'];
$Student_ID = $_POST['StudentId'];
$FetchingQuery = "SELECT * FROM issued_books WHERE Student_ID='" . $Student_ID . "'";
$RunFetchingQuery = MysqL_query($FetchingQuery);
while ( $row = MysqL_fetch_array( $RunFetchingQuery ) ) {
$Book_1 = $row[ 'Book_1' ];
$Book_2 = $row[ 'Book_2' ];
$Book_3 = $row[ 'Book_3' ];
$Book_4 = $row[ 'Book_4' ];
$Book_5 = $row[ 'Book_5' ];
}
if(!empty($Book_4))
{
$Update = "UPDATE issued_books SET Book_4='$IssuedBookNumber' WHERE Student_ID= '$Student_ID'";
MysqL_query ($Update);
}
else
{
$AddQuery = "INSERT INTO issued_books (Book_4) VALUES ('$IssuedBookNumber')";
MysqL_query ($AddQuery);
}
解决方法:
那不是INSERT.那是一个更新. INSERT语句插入一个新行. UPDATE语句更新现有行.
UPDATE issued_books
SET Book_4 = '$IssuedBookNumber'
WHERE Student_ID = '$Student_ID'
(我假设您已正确转义$IssuedBookNumber和$Student_ID)

java – 带有where子句的SQL select语句
resultSet = statement
.executeQuery("select * from myDatabase.myTable where name = 'john'");
// this works
而是有类似的东西:
String name = "john";
resultSet = statement
.executeQuery("select * from myDatabase.myTable where name =" + name);
// UnkNown column 'john' in 'where clause' at
// sun.reflect.NativeConstructorAccessorImpl.newInstance0...etc...
提前致谢..
解决方法
PreparedStatement statement = connection.prepareStatement("select * from myDatabase.myTable where name = ?");
statement.setString(1,name);
ResultSet resultSet = statement.executeQuery();
请注意,prepareStatement()是一个昂贵的调用(除非您的应用程序服务器使用语句缓存和其他类似的工具).从理论上讲,最好是准备一次语句,然后多次重复使用它(尽管不是同时使用):
String[] names = new String[] {"Isaac","Hello"};
PreparedStatement statement = connection.prepareStatement("select * from myDatabase.myTable where name = ?");
for (String name: names) {
statement.setString(1,name);
ResultSet resultSet = statement.executeQuery();
...
...
statement.clearParameters();
}

mysql在where子句中使用用户定义的变量
sql查询:
select u.username, @total_subscribers:=( select count(s.id) from subscribers as s where s.suid = u.uid ) as total_subscribersfrom users as uwhere @total_subscribers > 0如果我删除where @total_subscribers > 0查询,将显示所有用户及其总订阅者
但是我只想显示那些至少拥有1个订阅者的用户…在我添加where子句并使用定义的变量后,我得到一个空结果集。
答案1
您可以使用group by和进行操作having:
select u.username, count(s.id) as total_subscribersfrom users as uinner join subscribers as s on s.suid = u.uidgroup by u.idhaving count(s.id) > 0
Mysql应用msql select语句的WHERE子句详解
《MysqL应用msql select语句的WHERE子句详解》要点:
本文介绍了MysqL应用msql select语句的WHERE子句详解,希望对您有用。如果有疑问,可以联系我们。
1,WHERE子句
在SELECT语句中,然后就开始执行WHERE子句.
WHERE子句是对FROM子句生成的成果集进行过滤,对中间成果集的每一行记录,WHERE子句会返回一个布尔值,(TRUE/FALSE),如果TURE,这行记录继续留在成果集中,如果FALSE,则这行记录从成果集中移除.
例如:
MysqL必读
FROM子句返回的中间成果集:
MysqL必读
--------- ----
1 张三
2 李四
3 王五
4 赵六
总共4行记录,对每一行记录执行WHERE子句.第一行中studentNO是1,所以studentNO=2表达式返回值为FALSE,这行记录移除.第二行中studentNO是2,所以studentNO=2返回TRUE,这行记录继续保存;同理第三行和第四行记录也移除,执行完WHERE语句后的中间结果集为:
MysqL必读
--------- ----
2 李四
然后执行SELECT语句,最终的成果集为:
MysqL必读
----
李四
2,比拟运算符
WHERE子句返回布尔值,所以WHERE子句经常会用到比拟运算符.MysqL必读
比拟运算符有:
MysqL必读
<=> 相等或者都等于空
< 小于
> 大于
<= 小于或等于
>= 大于或等于
<> 不等于
!= 不等于
2=2的结果为true,15<9的结果为false,3>2的结果为true,5!=4的结果为true.
字符串也可以进行比拟,'b'<'g'的结果为true,'h'>'k'的结果为false.
时间值可以比拟,较早的时间小于较晚的时间.'1980-5-4'<'1990-02-15'的结果为true,'1991-2-18'>'1991-2-19'的结果为false.
=比拟符与<=>比拟符的差别在于,当比拟两个空值的时候,=返回unkNown,<=>返回为true.
3,子查询中的比拟运算符
例句:
MysqL必读
一个子查询可以用于WHERE子句中.上例中是一个标量子查询,子查询只能返回一个标量值.MysqL必读
同样一个行子查询也可以用于WHERE子句中:
MysqL必读
4,不带比拟运算符的WHERE子句
WHERE子句并不一定带比拟运算符,当不带运算符时,会执行一个隐式转换.当0时转化为false,当其他值是转化为true.MysqL必读
例句:
MysqL必读
则会返回一个空集,因为每一行记载WHERE都返回false.MysqL必读
例句:
MysqL必读
或者
SELECT studentNO FROM student WHERE 'abc'
都将返回student表所有行记载的studentNO列.因为每一行记载WHERE都返回true.MysqL必读
《MysqL应用msql select语句的WHERE子句详解》是否对您有启发,欢迎查看更多与《MysqL应用msql select语句的WHERE子句详解》相关教程,学精学透。小编PHP学院为您提供精彩教程。
关于在WHERE子句中使用多个变量的Java SQL Select语句的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于INSERT语句中的WHERE子句使用mysql / php、java – 带有where子句的SQL select语句、mysql在where子句中使用用户定义的变量、Mysql应用msql select语句的WHERE子句详解等相关知识的信息别忘了在本站进行查找喔。
想了解Oracle SQL-使用select为某些行生成聚合行的新动态吗?本文将为您提供详细的信息,此外,我们还将为您介绍关于ibatis 自动生成键 selectkey(Oracle、MYSQL、MSSQL、SQLITE)、Mybatis「MySQL-Oracle」 中主键自动生成
- Oracle SQL-使用select为某些行生成聚合行
- ibatis 自动生成键 selectkey(Oracle、MYSQL、MSSQL、SQLITE)
- Mybatis「MySQL-Oracle」 中主键自动生成
序列化 - ORA-01840:输入值不足以使用Select在Oracle Insert中显示日期格式
- Oracle 11g Release 1 (11.1) PL/SQL Collection 方法

Oracle SQL-使用select为某些行生成聚合行
我有一个像下面的表。
|FILE| ID |PARENTID|SHOWCHILD|CAT1|CAT2|CAT3|TOTAL||F1 | A1 | P1 | N | 3 | 2 | 6 | 11 ||F2 | A2 | P2 | N | 4 | 7 | 3 | 14 ||F3 | A3 | P1 | N | 3 | 1 | 1 | 5 ||F4 | LG1| | Y | 6 | 3 | 7 | 16 ||F5 | LG2| | Y | 4 | 7 | 3 | 14 |现在,是否有可能,我只想为showChild为’Y’的行找到cat1,cat2,cat3和total的总计(即)汇总,并将其添加到结果集中。
|小孩| RES | RES | N | 10 | 10 | 10 | 30 |
预期最终产量:
|FILE| ID |PARENTID|SHOWCHILD|CAT1|CAT2|CAT3|TOTAL||F1 | A1 | P1 | N | 3 | 2 | 6 | 11 ||F2 | A2 | P2 | N | 4 | 7 | 3 | 14 ||F3 | A3 | P1 | N | 3 | 1 | 1 | 5 ||F4 | LG1| | Y | 6 | 3 | 7 | 16 ||F5 | LG2| | Y | 4 | 7 | 3 | 14 ||Tot | Res| Res | N | 10 | 10 | 10 | 30 |在这里,我仅在考虑将showchild为’Y’的行之后添加了Tot行(最后一行),并将其添加到了结果集中。
我正在尝试不使用UNION的解决方案
在实现上述结果方面的任何帮助均受到高度赞赏。
谢谢你。
答案1
一种方法是使用联合:
WITH cte AS ( SELECT "FILE", ID, PARENTID, SHOWCHILD, CAT1, CAT2, CAT3, TOTAL, 1 AS position FROM yourTable UNION ALL SELECT ''Tot'', ''Res'', ''Res'', ''N'', SUM(CAT1), SUM(CAT2), SUM(CAT3), SUM(TOTAL), 2 FROM yourTable WHERE SHOWCHILD = ''Y'')SELECT "FILE", ID, PARENTID, SHOWCHILD, CAT1, CAT2, CAT3, TOTALFROM cteORDER BY position, "FILE";")
ibatis 自动生成键 selectkey(Oracle、MYSQL、MSSQL、SQLITE)
我们在数据库插入一条数据的时候,经常是需要返回插入这条数据的主键。但是数据库供应商之间生成主键的方式都不一样。有些是预先生成 (pre-generate) 主键的,如 Oracle 和 PostgreSQL;有些是事后生成 (post-generate) 主键的,如 MySQL 和 SQL Server。但不管是哪种方式,我们都可以用 ibatis 的节点来获取语句所产生的主键。
oracle 例子:
<insert id="insertProduct-ORACLE" parameterClass="product">
<selectKey resultClass="int" type="pre" keyProperty="id" >
SELECT STOCKIDSEQUENCE.NEXTVAL AS VALUE FROM DUAL
</selectKey>
insert into PRODUCT (PRD_ID,PRD_DESCRIPTION) values (#id#,#description#)
</insert>sql-server 例子:
<insert id="insertProduct-MS-SQL" parameterClass="product">
insert into PRODUCT (PRD_DESCRIPTION) values (#description#)
<selectKey resultClass="int" type="post" keyProperty="id" >
select @@IDENTITY as value
</selectKey>
</insert>mysql 例子:
<insert id="insertProduct-MYSQL" parameterClass="product">
insert into PRODUCT (PRD_DESCRIPTION) values (#description#)
<selectKey resultClass="int" type="post" keyProperty="id" >
select LAST_INSERT_ID() as value
</selectKey>
</insert>SQLite 例子:
<insert id="Create" parameterClass="Subject">
INSERT INTO SUBJECT
(SubjectName,QuestionCount,IsNowPaper)
VALUES(#SubjectName#,#QuestionCount#,#IsNowPaper#)
<selectKey resultClass="int" type="post" property="SubjectId">
SELECT seq
FROM sqlite_sequence
WHERE (name = ''SUBJECT'')
</selectKey>
</insert>
注意:name = ''SUBJECT''中SUBJECT为表名称

Mybatis「MySQL-Oracle」 中主键自动生成 序列化
有时候我们不仅仅是通过返回 int 影响行数来确定数据是否插入成功就行了,因为我们总是会用到这个刚刚插入的自增主键,比如主子表入库,子表需要主表的 id,那这个时候我们再去数据库查就显得有点 low 了~
关于数据库中主键的生成无非就两种,一种是 int 类型的自增,一种是 varchar 类型的非自增 (例如:UUID)。
在 Mybatis 中,提供了 selectKey 来帮我们获取新增的主键,同时通过 selectKey 可以很容易的实现自增还是非自增规则的需求。
首先看一下 Mybatis 中 selectKey 的属性说明:
| 属性 | 描述 |
|---|---|
| keyProperty | selectKey 语句结果应该被设置的目标属性 (也就是自增的主键字段,比如 id)。 |
| resultType | 结果的类型,比如 java.lang.Integer,java.lang.String 等。MyBatis 通常可以算出来,但是写上也没有问题。MyBatis 允许任何简单类型用作主键的类型,包括字符串。 |
| order | 这可以被设置为 BEFORE 或 AFTER。如果设置为 BEFORE,那么它会首先选择主键,设置 keyProperty 然后执行插入语句。如果设置为 AFTER, 那么先执行插入语句,然后是 selectKey 元素 - 这和如 Oracle 数据库相似,可以在插入语句中嵌入序列调用。 |
| statementType | 和前面的相同,MyBatis 支持 STATEMENT,PREPARED 和 CALLABLE 语句的映射类型,分别代表 PreparedStatement 和 CallableStatement 类型。 |
下面从 Oracle 跟 MySQL 分别举例说明。
1. Oracle
<insert id="insertUserInfo" parameterType="club.sscai.entity.UserInfo">
<selectKey keyProperty="id" resultType="java.lang.Integer" order="BEFORE">
select SEQ_T_USER_INFO.NEXTVAL from dual
</selectKey>
insert into "T_USER_INFO"
<trim prefix="(" suffix=")" suffixOverrides=",">
ID,USER_NAME,PASSWORD,PHONE,STATUS,
<if test="remark != null">
REMARK,
</if>
CREATE_TIME,UPDATE_TIME,UPDATE_BY
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
#{id,jdbcType=DECIMAL}, #{userName,jdbcType=VARCHAR},
#{PASSWORD,jdbcType=VARCHAR},#{PHONE,jdbcType=VARCHAR},#{status,jdbcType=CHAR},
<if test="remark != null">
#{remark,jdbcType=VARCHAR},
</if>
#{createTime,jdbcType=TIMESTAMP},#{updateTime,jdbcType=TIMESTAMP}, #{updateBy,jdbcType=VARCHAR}
</trim>
</insert>
如上代码主要是向 T_USER_INFO 表插入用户数据,parameterType 值传入的是实体对象,这里也可以是 map 或者是其他对象。
其中 的 keyProperty 值对应生成主键的字段,resultType 表示要返回的主键的类型,在这里我用的 Integer 类型,你也可以用 String,只要跟实体的字段对应即可。order 属性需要注意一下,不同于支持自增类型的 MySQL 等数据库,Oracle 需要设置设置为 after 才能取到正确的值,但是如果要从序列化中取值,则需要设置为 befor,否则会报错,我上边的代码是从序列中取值所以设置为 befor。
标签内的 SEQ_T_USER_INFO 表示该表的序列化,关于创建表序列化代码如下(SEQ_T_USER_INFO 名称随便起,尽量规范即可):
create sequence SEQ_T_USER_INFO
minvalue 1
maxvalue 9999999999999999999999999999
start with 1
increment by 1
cache 20;
字符串 uuid 类型非自增主键, selectKey 如下:
<selectKey keyProperty="id" resultType="java.lang.String" order="BEFORE">
select sys_guid() from dual
</selectKey>
2. MySQL
<insert id="insertUserInfo" parameterType="club.sscai.entity.UserInfo" >
<selectKey keyProperty="id" order="BEFORE" resultType="java.lang.string">
select uuid()
</selectKey>
insert into T_USER_INFO
(id, user_name, PASSWORD,PHONE,STATUS,REMARK,CREATE_TIME,UPDATE_TIME,UPDATE_BY)
values
(#{id},#{userName},#{password},#{phone},#{status},省略...)
</insert>
上方是 MySQL 通过 select uuid() 就能得到 uuid 字符串,实现 UUID 字符串形式的主键生成。如果需要 int 类型则如下所示:
<selectKey keyProperty="id" order="AFTER" resultType="java.lang.Long">
select LAST_INSERT_ID()
</selectKey>
至此,关于主键生成基本已经完事了,再额外补充关于 order = befor、after 的应用。
如果你使用的是 UUID() 这种形式的,建议选择 order = befor,而 order = after 更适合返回自增(int)类型的主键。
我创建了一个用来记录自己学习之路的公众号,感兴趣的小伙伴可以关注一下微信公众号:niceyoo


ORA-01840:输入值不足以使用Select在Oracle Insert中显示日期格式
我在下面的查询中,我得到了错误ORA-01840: input value not long enough for dateformat。该C_DATE列是“日期”数据类型。
INSERT INTO CS_LOG(NAME, ID, C_DATE)Select MAX(ML.NAME), ML.ID, TO_CHAR(CHK_DATE,''YYYYMM'')from D_ID ML, CS_LOG MDWHERE ML.NAME != MD.NAME and ML.ID != MD.ID and MD.C_DATE = LAST_DAY(to_date(sysdate,''YYYYMMDD''))GROUP BY ML.ID, C_DATE;答案1
小编典典您可以“以格式插入日期”。日期具有内部表示形式,它们始终具有所有日期/时间组成部分,然后可以根据需要进行格式化以进行显示。
您作为YYYYMM生成的字符串已通过插入隐式转换为日期,因为这是目标列的数据类型。该隐式转换正在使用您的NLS设置,并且因此期望使用更长的值来匹配NLS日期格式。您的字符串与该隐式格式不匹配,这会导致您看到错误。
如果您只对年份和月份感兴趣,那么可以得到的最接近的结果是在当月的第一天午夜存储trunc:
INSERT INTO CS_LOG(NAME, ID, C_DATE)Select MAX(ML.NAME), ML.ID, TRUNC(CHK_DATE,''MM'')from D_ID ML,CS_LOG MDWHERE ML.NAME != MD.NAME and ML.ID != MD.IDand MD.C_DATE = LAST_DAY(sysdate)GROUP BY ML.ID,C_DATE;我也删除了多余的to_date电话。您也应该考虑切换到ANSI连接语法。
然后,您可以通过c_date查询将其格式化为YYYYMM以便在查询时显示to_char。
 PL/SQL Collection 方法")
Oracle 11g Release 1 (11.1) PL/SQL Collection 方法
collection 方法是一个内置的 PL/SQL 子程序,可以返回 collection 信息,或是在 collection 上执行操作,很方便。你可以通过点记
本文内容
collection 方法是一个内置的 PL/SQL 子程序,可以返回 collection 信息,或是在 collection 上执行操作,很方便。
你可以通过点记号来调用 collection 方法。语法如下图所示:

图1 Collection Method 调用
不能在 SQL 语句调用 collection 方法。
当 collection 为空时,你只能使用 EXISTS 方法,使用其他方法都会抛出 COLLECTION_IS_NULL 异常。
EXISTS 方法
若 collection 中第 n 个元素存在,则 EXISTS(n) 返回 TRUE;否则,返回 FALSE。EXISTS 方法结合 DELETE 方法,会把 collection 变成稀疏 nested tables(sparse nested tables)。通过 EXISTS 方法,避免引用一个不存在的元素,从而产生异常。当传递一个超出范围的标值时,EXISTS 方法返回 FALSE,而不是产生 SUBSCRIPT_OUTSIDE_LIMIT 异常。
示例1:演示检查元素是否存在
; n NumList := NumList(1,3,5,7); DBMS_OUTPUT.PUT_LINE( DBMS_OUTPUT.PUT_LINE(''OK, element #99 does not exist at all.''); END IF;END;/
COUNT 方法
COUNT 返回 collection 中元素的当前数量。当你不知道 collection 中有多少元素时,很有用。例如,当你把获取的表的一列,放到一个 nested table 时,元素的数量取决于结果集的大小。
对于 varray,COUNT 总是等于 LAST。通过 EXTEND 和 TRIM 方法,你可以增加或减少 varray 的大小,,因此,COUNT 值是变化的,取决于 LIMIT 方法的值。
对于 nested tables,COUNT 方法通常等于 LAST 方法。然而,若你从 nested table 删除元素,则 COUNT 小于 LAST。当你整理元素时,COUNT 会忽略已删除的元素。使用不带参数的 DELETE 方法会设置 COUNT 为 0。
备注:FIRST 方法和 LAST 方法返回最大和最小的索引数。后面说明。
![]()
我们今天的关于Oracle SQL-使用select为某些行生成聚合行的分享就到这里,谢谢您的阅读,如果想了解更多关于ibatis 自动生成键 selectkey(Oracle、MYSQL、MSSQL、SQLITE)、Mybatis「MySQL-Oracle」 中主键自动生成
关于SQL Server-删除组中带有NULL的结果和sql删除为null的数据的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于IS NULL vs = NULL在where子句中+ SQL Server、postgresql – 为什么带有NULL的集合的NOT IN总是返回FALSE / NULL?、SQL Server 2005:末尾带有NULL值的订单、SQL Server 2008:将存储过程(动态列)的结果与SELECT语句的结果联接等相关知识的信息别忘了在本站进行查找喔。
本文目录一览:- SQL Server-删除组中带有NULL的结果(sql删除为null的数据)
- IS NULL vs = NULL在where子句中+ SQL Server
- postgresql – 为什么带有NULL的集合的NOT IN总是返回FALSE / NULL?
- SQL Server 2005:末尾带有NULL值的订单
- SQL Server 2008:将存储过程(动态列)的结果与SELECT语句的结果联接
")
SQL Server-删除组中带有NULL的结果(sql删除为null的数据)
不确定标题是否正确,但是我不太确定该如何写。我有一张表格,circumstances我需要根据circumstances给定的传入数据组显示某些问题。
我传入的数据如下所示:
----------------------------------------------------| CircumstanceTypeGiven | CircumstanceValueGiven |----------------------------------------------------| Equipment | X |----------------------------------------------------| Customer | BEEFORE |----------------------------------------------------我的CircumstanceMaster桌子看起来像这样:
--------------------------------------------------| ID | CircumstanceType | GroupID | Value |--------------------------------------------------| 1 | Equipment | 1 | Reefer |--------------------------------------------------| 2 | Customer | 1 | BEEFOR |--------------------------------------------------然后,我得到了一个表格,其中包含这样的组的问题ID:
--------------------------------------------------| ID | CircumstanceGroupID | QuestionID |--------------------------------------------------| 1 | 1 | 1 |--------------------------------------------------我的问题表:
--------------------------------------------------| ID | Question |--------------------------------------------------| 1 | This is my question for Reefer & BEEFOR |--------------------------------------------------因此,我获得了 X 的设备类型和 BEEFOR 的客户价值。我的情况表说,如果我通过了 reefer 和 BEEFORE
,那么我需要得到1的问题groupID。但是,如果只传入1(我给出的情况),我不希望这些问题。
这是SQL:
CREATE TABLE CircumstanceMaster( CircumstanceID INT NOT NULL PRIMARY KEY IDENTITY(1,1), CircumstanceGroupID INT NOT NULL, CircumstanceType INT NOT NULL, CircumstanceValue VARCHAR(MAX) NOT NULL)INSERT INTO CircumstanceMaster ( CircumstanceType, CircumstanceGroupID, CircumstanceValue ) VALUES ( 1, 1, ''R'' )INSERT INTO CircumstanceMaster ( CircumstanceType, CircumstanceGroupID, CircumstanceValue ) VALUES ( 2, 1, ''DEEFOR'' )CREATE TABLE QuestionMaster( QuestionID INT NOT NULL PRIMARY KEY IDENTITY(1,1), Question VARCHAR(MAX) NOT NULL)INSERT INTO QuestionMaster ( Question ) VALUES ( ''Reefer & DEEFOR question'' )CREATE TABLE CircumstanceQuestion( ID INT NOT NULL PRIMARY KEY IDENTITY(1,1), CircumstanceGroupID INT NOT NULL, QuestionID INT NOT NULL)INSERT INTO CircumstanceQuestion ( CircumstanceGroupID, QuestionID ) VALUES ( 1, 1 )declare @given Table(CircumstanceTypeGivenID INT, CircumstanceValueGiven varchar(50))insert into @given(CircumstanceTypeGivenID,CircumstanceValueGiven) VALUES ( 1, ''X'')insert into @given(CircumstanceTypeGivenID,CircumstanceValueGiven) VALUES ( 2, ''DEEFOR'')select *from CircumstanceMaster cm left outer join @given g on cm.CircumstanceType=g.CircumstanceTypeGivenID and cm.CircumstanceValue=g.CircumstanceValueGiven当我加入circumstancemaster餐桌时,我得到了这个结果。我希望得到结果,但是我需要一种方式说“如果SAME组中的任何行具有空值,请不要返回任何内容”:
----------------------------------------------------------------| CircumstanceID | CircumstanceGroupID | CircumstanceValueGiven|----------------------------------------------------------------| 1 | 1 | NULL |----------------------------------------------------------------| 2 | 1 | BEEFOR | ----------------------------------------------------------------答案1
试试这个:
select CircumstanceGroupID from CircumstanceMaster cm left join @given g on cm.CircumstanceType=g.CircumstanceTypeGivenID and cm.CircumstanceValue=g.CircumstanceValueGivengroup by CircumstanceGroupIDhaving sum(case when CircumstanceValueGiven is null then 0 else 1 end) = count(*)
IS NULL vs = NULL在where子句中+ SQL Server
如何检查值IS NULL [or] = @param(@param为空)
前任:
Select column1 from Table1
where column2 IS NULL => works fine
如果我想将比较值(IS NULL)替换为@param。如何才能做到这一点
Select column1 from Table1
where column2 = @param => this works fine until @param got some value in it and if is null never finds a record.
如何实现?

postgresql – 为什么带有NULL的集合的NOT IN总是返回FALSE / NULL?
理解这个的最好方法是什么?我认为NULL是没有值的东西,因此不期望查询失败,但显然这不是想到NULL的正确方法.
> IN是一系列OR条件的简写
> x NOT IN(1,2,NULL)与NOT相同(x = 1 OR x = 2 OR x = NULL)
> …与x<>相同1和x<> 2和x<>空值
> …与真实相同且真实且未知**
> … =未知**
> …在这种情况下几乎与false相同,因为它不会通过WHERE条件**
现在,这就是民间使用EXISTS NOT EXISTS而不是IN NOT IN的原因.另请参阅The use of NOT logic in relation to indexes了解更多信息
**注意:在WHERE条件中表达式结尾处的unkNown与false相同.在评估表达式时,它是未知的请参阅下面的@ kgrittn的评论

SQL Server 2005:末尾带有NULL值的订单
我正在寻找按“ordernum”字段排序的记录列表。ordernum字段是一个int字段。该字段以NULL开头,直到由用户设置为止。我希望NULL条目显示在列表的末尾。
我正在建立一个查询,如下所示:
select *, case when (ordernum is null) then [largestInt] else ordernum end as newordernumfrom tableNameorder by newordernum我知道我可以为[largestInt]输入最大的整数值,但是我想用一个变量替换[largestInt]。这可能吗?
答案1
小编典典我找到了一种在底部排序NULL值的方法。
它很好地满足了我的需求。我的查询现在是:
select *from tableNameorder by case when ordernum is null then 1 else 0 end, ordernum的结果与SELECT语句的结果联接")
SQL Server 2008:将存储过程(动态列)的结果与SELECT语句的结果联接
我想将这些结果与另一个表中的数据结合起来。我已经看到了执行此操作的各种示例,这些示例是创建一个 临时表
并将其插入其中,但是,这并不理想,因为存储过程会返回许多 动态列 ,这些 列 可能会发生变化。有没有办法动态地加入他们?
示例方案:
存储过程返回以下内容:
EXEC uspGetProductCategories
products_id | products_model | Leather Seats | Heated Seats | Tapedeck | Heater | Hybrid | Sunroof | Cruise Control
===================================================================================================================
100 | Saturn Vue | N | N | Y | N | N | N | N
200 | Toyota Pruis | Y | N | N | Y | Y | N | N
300 | Ford Focus | N | N | N | Y | N | N | Y
我想用生成如下内容的SQL查询来加入它:
SELECT * FROM Products_Detail
products_id | manufacturer | purchaser | pay_type
=================================================
100 | GM | GREG | P
200 | TOYT | SAM | P
300 | FORD | GREG | L
换一种说法…
有没有一种轻松的方式来实现这一目标?这是我想要实现的一些psedo代码(尽管我知道这是行不通的):
SELECT pd.*,sp.* FROM Products_Detail pd
LEFT JOIN uspGetProductCategories sp ON pd.product_id = sp.product_id
同样,我知道您无法执行此操作,但希望它能够描述我正在寻找的逻辑。
所需输出示例
products_id | manufacturer | purchaser | pay_type | products_model | Leather Seats | Heated Seats | Tapedeck | Heater | Hybrid | Sunroof | Cruise Control
=========================================================================================================================================================
100 | GM | GREG | P | Saturn Vue | N | N | Y | N | N | N | N
200 | TOYT | SAM | P | Toyota Pruis | Y | N | N | Y | Y | N | N
300 | FORD | GREG | L | Ford Focus | N | N | N | Y | N | N | Y
今天关于SQL Server-删除组中带有NULL的结果和sql删除为null的数据的介绍到此结束,谢谢您的阅读,有关IS NULL vs = NULL在where子句中+ SQL Server、postgresql – 为什么带有NULL的集合的NOT IN总是返回FALSE / NULL?、SQL Server 2005:末尾带有NULL值的订单、SQL Server 2008:将存储过程(动态列)的结果与SELECT语句的结果联接等更多相关知识的信息可以在本站进行查询。
在这篇文章中,我们将带领您了解SQL-使用WITH在INSERT INTO上声明变量的全貌,同时,我们还将为您介绍有关.net – 可以使用SqlCommandBuilder(不使用Stored Proc)在insert上检索IDENTITY列值?、Auth在Windows XP上使用git和tortoisegit失败、iOS OC声明变量@interface{}和@property的区别、Kotlin SQLite“(代码1 SQLITE_ERROR):,同时编译:INSERT INTO”的知识,以帮助您更好地理解这个主题。
本文目录一览:- SQL-使用WITH在INSERT INTO上声明变量
- .net – 可以使用SqlCommandBuilder(不使用Stored Proc)在insert上检索IDENTITY列值?
- Auth在Windows XP上使用git和tortoisegit失败
- iOS OC声明变量@interface{}和@property的区别
- Kotlin SQLite“(代码1 SQLITE_ERROR):,同时编译:INSERT INTO”

SQL-使用WITH在INSERT INTO上声明变量
我正在尝试使用WITH时为查询声明一个变量INSERTINTO。我正在关注https://stackoverflow.com/a/16552441/2923526,该示例提供了以下SELECT查询示例:
WITH myconstants (var1, var2) as ( values (5, ''foo''))SELECT *FROM somewhere, myconstantsWHERE something = var1 OR something_else = var2;我没有运气就尝试了以下方法:
playground> CREATE TABLE foo (id numeric)CREATE TABLEplayground> WITH consts (x) AS (VALUES (2)) INSERT INTO foo VALUES (x)column "x" does not existLINE 1: WITH consts (x) AS (VALUES (2)) INSERT INTO foo VALUES (x) ^playground> WITH consts (x) AS (VALUES (2)) INSERT INTO foo VALUES (consts.x)missing FROM-clause entry for table "consts"LINE 1: ...consts (x) AS (VALUES (2)) INSERT INTO foo VALUES (consts.x) ^playground> WITH consts (x) AS (VALUES (2)) INSERT INTO foo VALUES (consts.x) FROM constssyntax error at or near "FROM"LINE 1: ...AS (VALUES (2)) INSERT INTO foo VALUES (consts.x) FROM const... ^playground> WITH consts (x) AS (VALUES (2)) INSERT INTO foo FROM consts VALUES (consts.x)syntax error at or near "FROM"LINE 1: WITH consts (x) AS (VALUES (2)) INSERT INTO foo FROM consts ... ^注意:我是SQL的初学者,因此我在寻找避免暗示使用PLPGSQL的解决方案的方法。
答案1
我认为您想要:
WITH consts (x) AS (VALUES (2)) INSERT INTO foo SELECT x FROM consts也就是说:该WITH子句创建一个 派生表 ,然后可以在主查询中使用它;因此您实际上需要SELECT ... FROM公用表表达式。
在insert上检索IDENTITY列值?")
.net – 可以使用SqlCommandBuilder(不使用Stored Proc)在insert上检索IDENTITY列值?
我正在尝试在执行更新(使用sqlDataAdapter和sqlCommandBuilder)之后检索一个标识列的值到我的数据集中.
执行sqlDataAdapter.Update(myDataset)后,我想能够读取myDataset.tables(0).Rows(0)(“ID”)的自动分配的值,但它是System.dbnull(尽管事实上该行已插入).
(注意:我不想明确地写一个新的存储过程来做到这一点!)
经常发布的一种方法是:http://forums.asp.net/t/951025.aspx修改sqlDataAdapter.InsertCommand和UpdatedRowSource,如下所示:
sqlDataAdapter.InsertCommand.CommandText += "; SELECT MyTableID = ScopE_IDENTITY()" InsertCommand.UpdatedRowSource = UpdateRowSource.FirstReturnedRecord
显然,这对过去的许多人来说似乎是有效的,但对我来说并不奏效.
另一种技术:http://forums.microsoft.com/MSDN/ShowPost.aspx?PostID=619031&SiteID=1对我来说不起作用,因为在执行sqlDataAdapter.Update之后,sqlDataAdapter.InsertCommand.Parameters集合将重置为原始(丢失附加的附加参数).
有人知道这个答案吗?
解决方法
da.Update(DS);
insert命令的参数数组将重置为从命令构建器创建的初始列表,它将删除您添加的身份的输出参数.
解决方案是创建一个新的dataAdapter并复制命令,然后使用这个新的da.update(ds);
喜欢
sqlDataAdapter da = new sqlDataAdapter("select Top 0 " + GetTableSelectList(dt) +
"FROM " + tableName,_sqlConnectString);
sqlCommandBuilder custCB = new sqlCommandBuilder(da);
custCB.QuotePrefix = "[";
custCB.QuoteSuffix = "]";
da.TableMappings.Add("Table",dt.TableName);
da.UpdateCommand = custCB.GetUpdateCommand();
da.InsertCommand = custCB.GetInsertCommand();
da.DeleteCommand = custCB.GetDeleteCommand();
da.InsertCommand.CommandText = String.Concat(da.InsertCommand.CommandText,"; SELECT ",GetTableSelectList(dt)," From ",tableName," where ",pKeyName,"=ScopE_IDENTITY()");
sqlParameter identParam = new sqlParameter("@Identity",sqlDbType.BigInt,pKeyName);
identParam.Direction = ParameterDirection.Output;
da.InsertCommand.Parameters.Add(identParam);
da.InsertCommand.UpdatedRowSource = UpdateRowSource.FirstReturnedRecord;
//new adaptor for performing the update
sqlDataAdapter daAutoNum = new sqlDataAdapter();
daAutoNum.DeleteCommand = da.DeleteCommand;
daAutoNum.InsertCommand = da.InsertCommand;
daAutoNum.UpdateCommand = da.UpdateCommand;
daAutoNum.Update(dt);

Auth在Windows XP上使用git和tortoisegit失败
我的身份validation保持失败。 我已经创build了我的SSH密钥,公钥已经被本地的git admin导入,但是我仍然被提示input密码:
git.exe clone --progress -v "git@repo:project.git" "C:webproject" cloning into C:webproject... git@repo's password: fatal: The remote end hung up unexpectedly
我的SSH密钥是无密码的,并在“ C:Documents and Settingsusername.ssh ”下C:Documents and Settingsusername.ssh ,我也将它们复制到“ C:Documents and Settingsusernamessh ”(没有前面的点)。
在Windows环境variables屏幕中, HOME系统var被设置为我的用户正确的目录。
如何分离/解耦Git仓库到不同的位置
在窗口中添加目录到gitignore
移动gitolite服务器
Git SSH客户端的Windows和错误的path为.ssh /configuration文件
有没有一个可以接受的git-svn的Linux目标客户端?
什么ssh -vvv git@repo返回?
只要这个ssh请求不起作用,git操作将不会与git@repo服务器一起工作。
如果ssh报告它是否尝试提供公钥,那么您必须仔细检查它是否已正确添加到repo服务器上的〜git ~git/.ssh/authorized_keys文件中。
下面是一个ssh会话例子的摘录,
debug1: Authentications that can continue: publickey,password,keyboard-interactive debug3: start over,passed a different list publickey,keyboard-interactive debug3: preferred publickey,keyboard-interactive,password debug3: authmethod_lookup publickey debug3: remaining preferred: keyboard-interactive,password debug3: authmethod_is_enabled publickey debug1: Next authentication method: publickey debug1: Offering public key: /p/.ssh/mypubkey debug3: send_pubkey_test debug2: we sent a publickey packet,wait for reply debug1: server accepts key: pkalg ssh-rsa blen 277 debug2: input_userauth_pk_ok: fp f8:d9:7...:cf debug3: sign_and_send_pubkey debug1: read PEM private key done: type RSA debug1: Authentication succeeded (publickey). debug1: channel 0: new [client-session] debug3: ssh_session2_open: channel_new: 0 debug2: channel 0: send open debug1: Entering interactive session.
两点评论:
我的%HOME%引用不是%HOMEDIR%而是一个自定义驱动器( p: ),这是一个在工作中的本地约定,可能不适用于您。
我公钥/私钥的名称不符合默认标准( id_rsa.pub / id_rsa )
我在%HOME%.ssh目录中添加了一个config文件,以便明确指定公钥文件:
host gitrepo user git hostname repo identityfile ~/.ssh/mypubkey
这样,我可以简单地键入: ssh gitrepo ,而ssh将知道哪个用户,主机名和确切完整路径的公钥使用。

iOS OC声明变量@interface{}和@property的区别
iOS开发中声明属性时的三种方式:
方式一:直接在@interface中的大括号中声明。
@interface MyTest : NSObject{
NSString *mystr;
}
方式二:在@interface中声明,然后再在@property中声明。
@interface MyTest : NSObject{
NSString *_mystr;
}
@property (strong, nonatomic) NSString *mystr;
随后在.m文件中加入
@synthesize mystr = _myStr;
方式三:直接用@property声明
@interface MyTest : NSObject{
}
@property (strong, nonatomic) NSString *mystr;
随后在.m文件中加入@synthesize mystr = _myStr;
==============================我是分割线===========================
首先来说一下方式一根方式三的区别,使用方式一声明的成员变量是只能在自己类内部使用的,而不能在类的外部使用,(就是通过 类名. 点的方式是显示不出来的),方式三则相反,它可以在类的外部访问,在类的内部可以通过下划线+变量名或者self.变量名的方式来访问。
方式二的写法是一种过时的声明变量的方式,xcode在早期@systhesize没有自动合成属性器之前,需要手写
getter与setter方法,下划线从风格上表明这是类的内部变量,要是需要直接使用变量则需要使用get或者set的方式。
在XCode目前有了自动合成属性器后,编译器会自动帮我们生成一个以下划线开头的的实例变量,所以我们不必去同时声明属性与变量。 我们可以直接用@property的方式来声明一个成员属性,在.m文件中使不使用@systhesize都无所谓,xcode会自动帮你生成getter与setter.
个人比较喜欢使用方式三的方式,这是是苹果开发模板所推荐的,也可以在.m文件中不加@systhesize看个人喜好吧。
:,同时编译:INSERT INTO”")
Kotlin SQLite“(代码1 SQLITE_ERROR):,同时编译:INSERT INTO”
我通过添加查询字符串解决了该问题。感谢您对g_bor的帮助。
sqlite_database = this.requireContext().openOrCreateDatabase("main_database",MODE_PRIVATE,null)
val create_table_if_not_exist_query = "CREATE TABLE IF NOT EXISTS schedules " +
"('schedule_id' INTEGER PRIMARY KEY," +
"'schedule_name' VARCHAR," +
"'schedule_info' VARCHAR," +
"'schedule_day' INTEGER," +
"'schedule_start_time' VARCHAR," +
"'schedule_end_time' VARCHAR," +
"'schedule_color' VARCHAR)"
sqlite_database.execSQL(create_table_if_not_exist_query)
val insert_into_query = "INSERT INTO schedules " +
"( 'schedule_name','schedule_info','schedule_day','schedule_start_time','schedule_end_time','schedule_color')" +
" VALUES " +
"( '$schedule_title','$schedule_info','$schedule_save_day','$start_time','$end_time','$schedule_color')"
sqlite_database.execSQL(insert_into_query)
关于SQL-使用WITH在INSERT INTO上声明变量的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于.net – 可以使用SqlCommandBuilder(不使用Stored Proc)在insert上检索IDENTITY列值?、Auth在Windows XP上使用git和tortoisegit失败、iOS OC声明变量@interface{}和@property的区别、Kotlin SQLite“(代码1 SQLITE_ERROR):,同时编译:INSERT INTO”等相关知识的信息别忘了在本站进行查找喔。
如果您对SQL Server带有不可打印字符的排序顺序感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于SQL Server带有不可打印字符的排序顺序的详细内容,我们还将为您解答sql语句不支持数据排序的相关问题,并且为您提供关于04-SQLServer的排序规则(字符集编码)、C语言判断字符是否为可打印字符的方法、MS SQL Server 中的排序依据、oracle – 消除SQL Developer表视图的Data选项卡上的排序顺序的有价值信息。
本文目录一览:- SQL Server带有不可打印字符的排序顺序(sql语句不支持数据排序)
- 04-SQLServer的排序规则(字符集编码)
- C语言判断字符是否为可打印字符的方法
- MS SQL Server 中的排序依据
- oracle – 消除SQL Developer表视图的Data选项卡上的排序顺序
")
SQL Server带有不可打印字符的排序顺序(sql语句不支持数据排序)
我有一个标量值函数,该函数返回包含ASCII单位分隔符Char(31)的数据的varchar。我将此结果用作Order By子句的一部分,并尝试按升序排序。
我的标量值函数返回如下结果(拼写供参考的不可打印字符)
- ABC
- ABC (CHAR(31)) DEF
- ABC (CHAR(31)) DEF (CHAR(31)) HIJ
我希望当我通过升序订购时,结果如下:
- ABC
- ABCDEF
- ABCDEFHIJ
相反,我看到的是完全相反的结果:
- ABCDEFHIJ
- ABCDEF
- ABC
现在,我相当确定这与不可打印字符有关,但是我不确定为什么。知道为什么会这样吗?
谢谢
答案1
排序顺序可能会受到COLLATION设置的影响。在脚本之后,显式使用Latin1_General_CI_AS排序规则来按期望的顺序对项目进行排序。
;WITH q (Col) AS ( SELECT ''ABC'' UNION ALL SELECT ''ABC'' + CHAR(31) + ''DEF'' UNION ALL SELECT ''ABC'' + CHAR(31) + ''DEF'' + CHAR(31) + ''HIJ'')SELECT *FROM q ORDER BY Col COLLATE Latin1_General_CI_AS您正在使用什么排序规则?您可以使用以下命令验证当前的数据库排序规则设置
SELECT DATABASEPROPERTYEX(''master'', ''Collation'') SQLCollation;")
04-SQLServer的排序规则(字符集编码)
一、总结
1.SQLServer中的排序规则就是其他关系型数据库里所说的字符集编码;
2.SQLServer中的排序规则可以在3处设置,如下:
服务器级别(实例):instances ----->安装数据库的时候设置
数据库级别:database
表列级别:columns
所以在使用SQLServer的排序规则的时候,只需要保证这三处一致,就是正确的使用方式;
3.SQLServer的排序规则不仅影响记录行的sort顺序,还影响中文显示是否乱码;
4.创建数据库时,若我们未指定排序规则,数据库就会使用实例默认的排序规则;
5.SQLServer的排序规则只影响字符型的列,例如:char,varchar,text,nchar,nvarchar,ntext,因此在查询视图sys.columns中非字符型的字段的排序规则显示是NULL;
6.需要注意的是,虽然数据库的排序规则可以改,但是是有问题的,因为即使把数据库的排序规则改了,库里的表的字段的排序规则可能还是原来的,没有改,这在使用的时候,就可能会存在问题,所以数据库的排序规则尽力不要随意改动。
7.排序规则中,二进制排序的速度是最快的,因为SQLServer不用做任何调整即可使用快速、简单的排序算法。
二、查询语句
1.查询字符集编码
命令:SELECT COLLATIONPROPERTY(''Chinese_PRC_Stroke_CI_AI_KS_WS'', ''CodePage'')
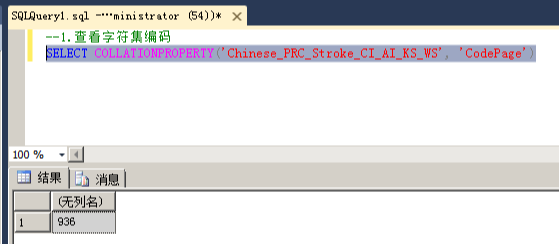
注:
(1).该数据库实例的排序规则是Chinese_PRC_CI_AS
(2).查出结果对应的字符集编码
936 :简体中文GBK
950 :繁体中文BIG5
437 :美国/加拿大英语
932 :日文
949 :韩文
866 :俄文
65001 :unicode UTF-8
2.查看实例的排序规则
命令:select serverproperty(N''Collation'')

3.查看实例下所有数据库的排序规则
命令:select name,collation_name from sys.databases
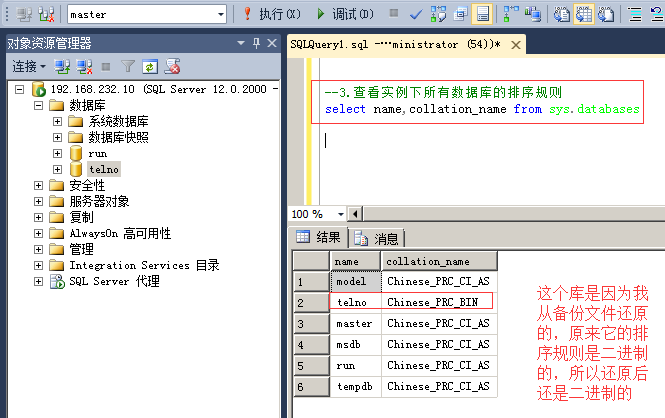
4.修改现有数据库的排序规则
命令:alter database telno collate Chinese_PRC_BIN
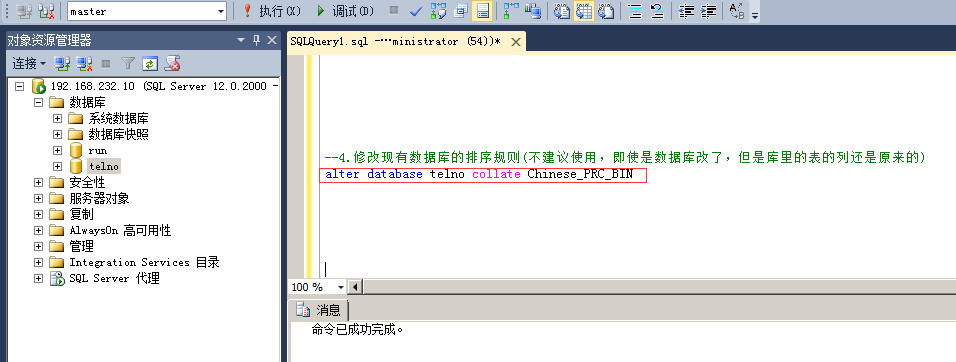
注:不建议使用,即使是数据库改了,但是库里的表的列还是原来的。
5.查询列的排序规则
命令:select name,collation_name from telno.sys.columns where collation_name is not null
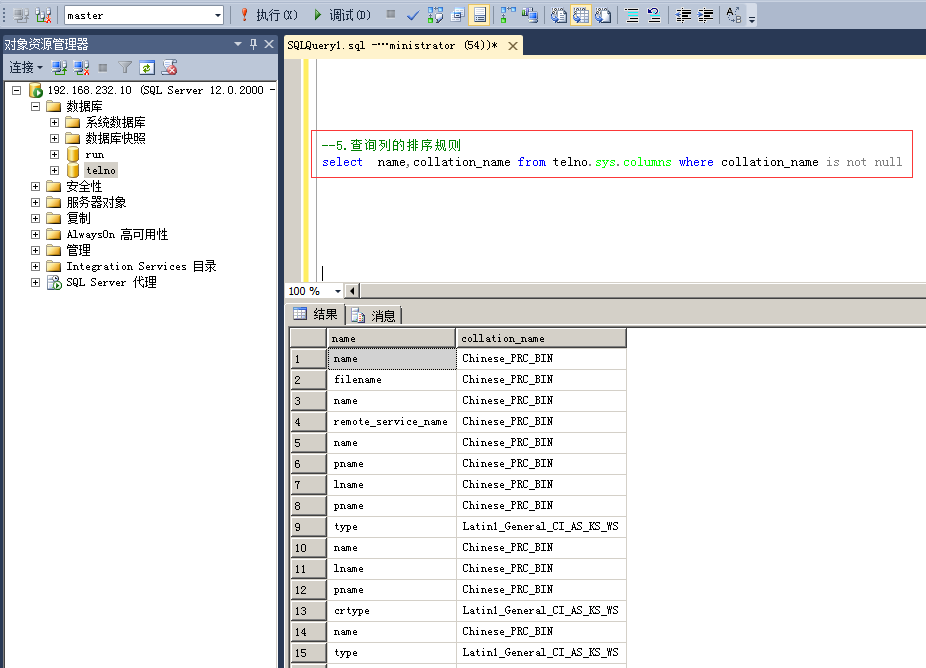
注:非字符型的字段的排序规则显示为NULL,所以要把NULL的结果过滤掉。
6.查看当前SQLServer版本支持的排序规则
命令:
select * from ::fn_helpcollations()
select * from fn_helpcollations()
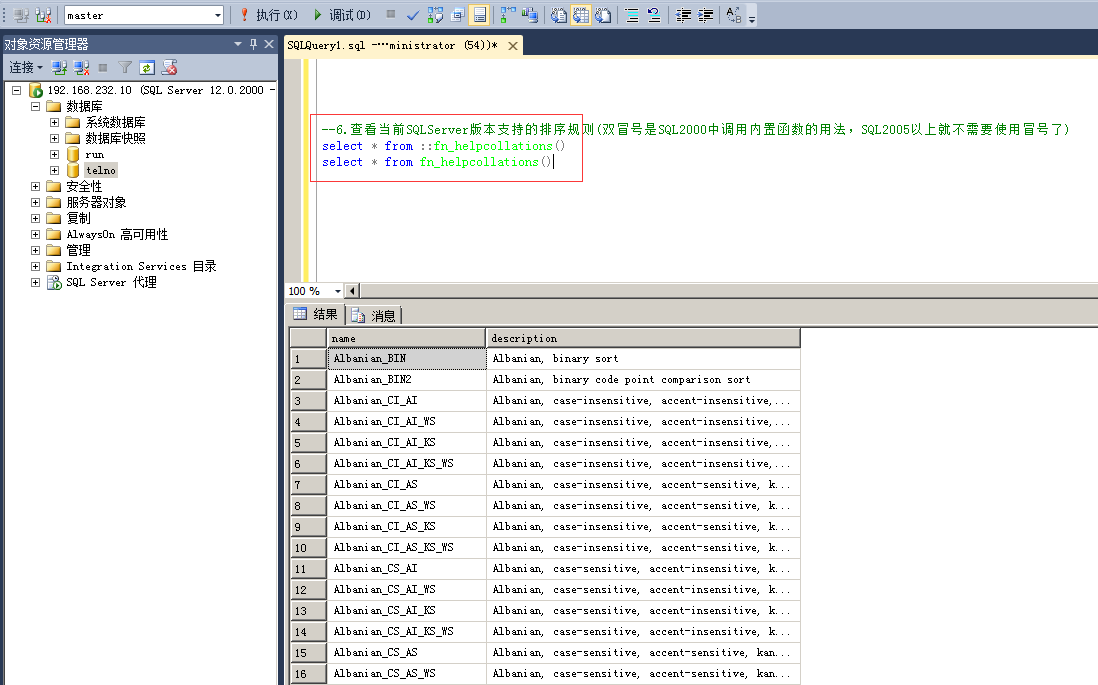
注:
(1)双冒号是SQL2000中调用内置函数的用法,SQL2005以上不需要使用冒号也能使用内置函数了;
(2)排序规则代表的意思详解
Chinese_PRC_ :指针对大陆简体字Unicode字符集的排序规则
后半部分的含义:
_BIN :二进制排序
C : case,大小写;
A :accent,重音;
I :Insensitive,不敏感,不区分;
S :sensitive,敏感,区分;
W :width,宽度
K :kanatype,假名
eg:
_CI :不区分大小写
_AS :区分重音
原文出处:https://www.cnblogs.com/jialanyu/p/11550367.html

C语言判断字符是否为可打印字符的方法
C语言isprint()函数:判断字符是否为可打印字符
头文件:
#include <ctype.h>
isprint() 函数用来判断一个字符是否为打印字符,其原型为:
int isprint(int c);
【参数】c 为需要被检测的字符。
【返回值】如果 c 为可打印字符,将返回非 0 值,否则返回 0。
可打印字符的ASCII码值大于 0x1f(除了0x7f(DEL)),这些字符可以显示到屏幕上,让我们看到;不能显示在屏幕上,我们看不到的,叫控制字符,ASCII码值为 0x00 ~ 0x1f,再加上 0x7f(DEL)。检测控制字符请使用 isiscntrl() 函数。
注意,此函数为宏定义,非真正函数。
【实例】判断str 字符串中哪些为可打印字符包含空格字符。
#include <ctype.h>
main(){
char str[] = "a5 @;";
int i;
for(i = 0; str[i] != 0; i++)
if(isprint(str[i]))
printf("str[%d] is printable character:%d\n",i,str[i]);
}
输出结果:
str[0] is printable character:a str[1] is printable character:5 str[2] is printable character: str[3] is printable character:@ str[4] is printable character:;
C语言isgraph()函数:判断字符是否为除空格以外的可打印字符
头文件:
#include <ctype.h>
isgraph() 用来判断一个字符是否为除空格以外的可打印字符,其原型为:
int isgraph (int c);
【参数】c 为需要检测的字符。
【返回值】如果 c 所对应的 ASCII 码可打印,且为非空格字符,则返回非 0 值,否则返回 0。
注意,isgraph() 为宏定义,非真正函数。
【范例】判断str 字符串中哪些为可打印字符。
#include <ctype.h>
main(){
char str[] = "a5 @;";
int i;
for(i = 0; str[i] != 0; i++)
if(isgraph(str[i]))
printf("str[%d] is printable character:%d\n",str[i]);
}
输出结果:
str[0] is printable character:a str[1] is printable character:5 str[3] is printable character:@ str[4] is printable character:;

MS SQL Server 中的排序依据

Order by 是 SQL 中的一个子句。它用于按升序或降序对查询的结果集进行排序。它可以使用一列或多列进行排序。在本文中,我们将讨论 MS SQL Server 中的 Order by 子句。
语法
在 MS SQL Server 中使用 Order by 子句的语法如下 -
SELECT column1, column2, ... FROM table_name ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...;
语法解释
SELECT column1, column2, ...:指定我们要从表中检索的列。
FROM table_name:指定我们要从中检索数据的表的名称。
ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...:根据指定列对结果集进行升序或降序排序。
升序排序
默认情况下,Order by 子句按升序对结果集进行排序。要按升序对结果集进行排序,我们不需要显式指定 ASC 关键字。
示例 1
SELECT * FROM customers ORDER BY customer_name;
在此示例中,结果集将根据 customer_name 列按升序排序。
示例 2
假设我们有一个名为“Employees”的表,其中包含以下列和数据 -
员工ID |
员工姓名 |
部门 |
薪资 |
|---|---|---|---|
1 |
约翰 |
IT |
50000 |
2 |
简 |
销售 |
45000 |
3 |
鲍勃 |
IT |
55000 |
4 |
爱丽丝 |
人力资源 |
40000 |
5 |
汤姆 |
人力资源 |
42000 |
如果我们想从Employees表中检索所有数据并按Salary列升序排序,SQL查询将是 -
SELECT * FROM Employees ORDER BY Salary;
上述查询的输出为 -
员工ID |
员工姓名 |
部门 |
薪资 |
|---|---|---|---|
4 |
爱丽丝 |
人力资源 |
40000 |
5 |
汤姆 |
人力资源 |
42000 |
2 |
简 |
销售 |
45000 |
1 |
约翰 |
IT |
50000 |
3 |
鲍勃 |
IT |
55000 |
按降序排序
要将结果集按降序排序,我们需要在列名后指定 DESC 关键字。
示例 1
SELECT * FROM customers ORDER BY customer_name DESC;
在此示例中,结果集将根据 customer_name 列按降序排序。
示例 2
如果我们想要从员工表中检索所有数据并按部门列降序排序,SQL 查询将是 -
SELECT * FROM Employees ORDER BY Department DESC;
上述查询的输出为
员工ID |
员工姓名 |
部门 |
薪资 |
|---|---|---|---|
2 |
简 |
销售 |
45000 |
1 |
约翰 |
IT |
50000 |
3 |
鲍勃 |
IT |
55000 |
5 |
汤姆 |
人力资源 |
42000 |
4 |
爱丽丝 |
人力资源 |
40000 |
按多列排序
我们还可以按多列对结果集进行排序。在本例中,Order by 子句首先根据第一列对结果集进行排序,然后根据第二列对结果集进行排序。
示例 1
SELECT * FROM customers ORDER BY country, customer_name;
在此示例中,结果集将根据国家/地区列按升序排序。如果两行或多行具有相同的国家/地区,则这些行将根据 customer_name 列按升序排序。
示例 2
如果我们想从Employees表中检索所有数据,并首先按Department列升序排序,然后按Salary列升序排序,SQL查询将是 -
SELECT * FROM Employees ORDER BY Department DESC;
上述查询的输出为
员工ID |
员工姓名 |
部门 |
薪资 |
|---|---|---|---|
2 |
简 |
销售 |
45000 |
| 1 | 约翰 |
IT |
50000 |
3 |
鲍勃 |
IT |
55000 |
5 |
汤姆 |
人力资源 |
42000 |
4 |
爱丽丝 |
人力资源 |
40000 |
按多列排序
我们还可以按多列对结果集进行排序。在本例中,Order by 子句首先根据第一列对结果集进行排序,然后根据第二列对结果集进行排序。
示例 1
SELECT * FROM customers ORDER BY country, customer_name;
在此示例中,结果集将根据国家/地区列按升序排序。如果两行或多行具有相同的国家/地区,则这些行将根据 customer_name 列按升序排序。
示例 2
如果我们想要从Employees表中检索所有数据,并首先按Department列升序排序,然后按Salary列升序排序,那么SQL查询将是
SELECT * FROM Employees ORDER BY Department ASC, Salary ASC;
上述查询的输出为
员工ID |
员工姓名 |
部门 |
薪资 |
|---|---|---|---|
4 |
爱丽丝 |
人力资源 |
40000 |
5 |
汤姆 |
人力资源 |
42000 |
1 |
约翰 |
IT |
50000 |
3 |
鲍勃 |
IT |
55000 |
2 |
简 |
销售 |
45000 |
这些示例演示了如何使用 Order by 子句对 MS SQL Server 中的查询结果集进行排序。
使用 NULL 值排序
当我们使用 Order by 子句时,NULL 值的排序方式有所不同,具体取决于我们是按升序还是降序排序。按升序排列,首先显示 NULL 值,按降序排列,最后显示 NULL 值。
例如
SELECT * FROM customers ORDER BY city DESC;
在此示例中,结果集将根据城市列按降序排序。 NULL 值将显示在最后。
结论
MS SQL Server 中的 Order by 子句是一个功能强大的工具,它允许我们根据一个或多个列以升序或降序对查询结果集进行排序。通过了解 Order by 子句的语法和用法,我们可以创建更复杂且更有意义的查询来从数据库中检索数据。
以上就是MS SQL Server 中的排序依据的详细内容,更多请关注php中文网其它相关文章!

oracle – 消除SQL Developer表视图的Data选项卡上的排序顺序
问题:我设置了一个排序顺序,用于查看该表上索引不支持的特定表.当你去查看那些数据时,似乎sql Developer会动态进行排序.起初延迟并不算太糟糕.但桌子已经成长,现在需要永远.没有办法阻止它,除非强制退出sql Developer,丢失任何未保存的东西. (如果您知道另一种方法可以停止此类操作,请告诉我们!)因此,我应该将查看排序顺序更改为其他内容,但您只能在查看数据时访问“排序…”按钮.
除了查看数据之外,还有其他方法可以删除查看排序顺序吗?
sql Developer在哪里存储此信息?
在等待数据选项卡出现时单击数据选项卡后是否有任何方法可以停止对数据进行排序?
解决方法
>进入sqldeveloper设置文件夹.在M $Windows上位于%HOME_USER%/ Application Data / sql Developer中
>执行全文搜索,指定已排序列的名称.如果列的名称太常见(例如:data),请在同一个表中指定另一个具有不同名称的列.您将找到一个或多个符合搜索条件的xml文件.那些文件是表描述符.
>在xml描述符的末尾搜索名为’orderByClause’的taf元素.如果它包含要从排序中消除的列的名称,则用空元素替换该行()
>重新启动sqldeveloper并且…不再存在了!
希望这可以帮助
干杯,法布里奇奥·福蒂诺
关于SQL Server带有不可打印字符的排序顺序和sql语句不支持数据排序的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于04-SQLServer的排序规则(字符集编码)、C语言判断字符是否为可打印字符的方法、MS SQL Server 中的排序依据、oracle – 消除SQL Developer表视图的Data选项卡上的排序顺序的相关知识,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

