对于想了解更改具有外键的表的读者,本文将提供新的信息,我们将详细介绍SQLServer中的记录?,并且为您提供关于copy一张老数据表(sqlserver)、mysql-如何关联两个没有外键的表?、p
对于想了解更改具有外键的表的读者,本文将提供新的信息,我们将详细介绍SQL Server中的记录?,并且为您提供关于copy一张老数据表(sqlserver)、mysql-如何关联两个没有外键的表?、postgresql – 具有复合主键的表中的记录顺序是什么、SQL Server 2016 中有外键的表无法被Truncate,只能被Delete的有价值信息。
本文目录一览:- 更改具有外键的表(SQL Server)中的记录?(sql修改外键)
- copy一张老数据表(sqlserver)
- mysql-如何关联两个没有外键的表?
- postgresql – 具有复合主键的表中的记录顺序是什么
- SQL Server 2016 中有外键的表无法被Truncate,只能被Delete
中的记录?(sql修改外键)")
更改具有外键的表(SQL Server)中的记录?(sql修改外键)
有谁知道是否有一种更快的方法来编辑表(在sql server中)中具有外键的记录..我会解释..我大约有5个表具有自己的ID,但使用外键链接在一起…
因此,我需要更改外键(在我的情况下为合同编号),但是我必须将每个记录复制到新记录并以这种方式进行编辑…
就像我尝试编辑合同编号一样,它给了我与之相关的标准错误,并且违反了外键等
真的有更好的办法吗?
有任何想法吗?
答案1
您是在谈论更改PK,然后更新所有Fks吗?在这种情况下,请启用级联更新,并且删除操作将自动完成,您可以启用级联删除
删除级联
指定如果尝试删除其他表中现有行中外键引用的键的行,则包含这些外键的所有行也将被删除。如果还在目标表上定义了级联引用动作,则将从这些表中删除的行也采用指定的级联动作。
关于更新级联
指定如果尝试更新一行中的键值(其中键值由其他表中现有行中的外键引用),则所有外键值也将更新为该键指定的新值。如果级联引用动作
")
copy一张老数据表(sqlserver)
测试需要,但是不能动原有数据库表内容;
现在希望创建一张新表NEWTABLE,它必须有老表OLDTABLE的表结构和数据
select * into NEWTABLE from OLDTABLE;
如果只需要表结构,那么,后面加一句限制条件,如where 1=2;
select * into NEWTABLE from OLDTABLE where 1=2;

mysql-如何关联两个没有外键的表?
有人可以演示吗?
我正在使用MySQL,但是想法应该是一样的!
编辑
实际上,我想问的是Doctrine_Relation和Doctrine_Relation_ForeignKey在教义上有什么区别?
例如,如果db1.tableA具有L_Name列,而db2.tableB具有LastName列,则字符串距离匹配将为您获取一个度量.您可以通过比较行中的值来检查是否存在一致性,例如两个表中的值是否包含“ Smith”,“ Johnson”等,从而扩展双赢.
最近,我做了类似的事情,集成了多个大型数据库(其中一个使用另一种语言-法语!),事实证明这是非常不错的体验.
高温超导

postgresql – 具有复合主键的表中的记录顺序是什么
这是假设Postgresql按主键的顺序排列记录.可以?
此外,Postgresql的主键是否自动编入索引?
您可能会认为Postgresql表存储为按主键顺序存储在磁盘上的索引导向表,但这不是Pg的工作原理.我认为InnoDB存储由主键组织的表(但尚未检查),并且在某些其他供应商的数据库中使用通常称为“聚簇索引”或“索引组织表”的功能是可选的. Postgresql当前不支持此功能(至少9.3).
也就是说,PRIMARY KEY使用UNIQUE索引来实现,并且该索引有一个顺序.它从索引的左侧列(从而是主键)向上排序,就好像是ORDER BY col1 ASC,col2 ASC,col3 ASC ;. Postgresql中的任何其他b-tree(与GiST或GIN不同)索引也是如此,因为它们使用b+trees实现.
所以在表中:
CREATE TABLE demo ( a integer,b text,PRIMARY KEY(a,b) );
系统会自动创建相当于:
CREATE UNIQUE INDEX demo_pkey ON demo(a ASC,b ASC);
创建表时会向您报告,例如:
regress=> CREATE TABLE demo ( regress(> a integer,regress(> b text,regress(> PRIMARY KEY(a,b) regress(> ); NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "demo_pkey" for table "demo" CREATE TABLE
检查表格时可以看到这个索引:
regress=> \d demo
Table "public.demo"
Column | Type | Modifiers
--------+---------+-----------
a | integer | not null
b | text | not null
Indexes:
"demo_pkey" PRIMARY KEY,btree (a,b)
您可以在此索引上的CLUSTER根据主键重新排列表,但它是一次性操作.系统不会维护这个顺序 – 尽管由于非默认的FILLFACTOR,如果页面空间有限,我认为它会尝试.
索引(而不是堆)的固有顺序的一个后果是,搜索速度要快得多:
SELECT * FROM demo ORDER BY a,b; SELECT * FROM demo ORDER BY a;
比:
SELECT * FROM demo ORDER BY a DESC,b;
并且这些都不能使用主键索引,除非您在b上有索引,否则它们将执行seqscan:
SELECT * FROM demo ORDER BY b,a; SELECT * FROM demo ORDER BY b;
这是因为Postgresql可以使用(a,b)上的索引与(a)上的索引几乎一样快.它不能使用(a,b)上的索引,就像它是(b)上的索引一样 – 甚至不是缓慢的,它只是不能.
对于DESC条目,对于那个Pg,必须进行反向索引扫描,这比普通的前向索引扫描慢.如果您在EXPLAIN ANALYZE中看到大量反向索引扫描,并且您可以承担额外索引的性能成本,您可以在DESC顺序的字段上创建一个索引.
对于WHERE子句而言,这并不只是ORDER BY.您可以使用(a,b)上的索引来搜索WHERE a = 4或WHERE a = 4 AND b = 3,但不能单独搜索WHERE b = 3.

SQL Server 2016 中有外键的表无法被Truncate,只能被Delete
问:
I get the following message even when the table that references it is empty: "Cannot truncate table ''dbo.Link'' because it is being referenced by a FOREIGN KEY constraint" Doesn''t seem to make much sense why this is occurring. Any suggestions?
答
In SQL Server a table referenced by a FK cannot currently be truncated even if all referencing tables are empty or the foreign keys are disabled.
You need to use DELETE (may require much more logging) or drop the relationship(s) prior to using TRUNCATE and recreate them afterwards or see the workarounds on this connect item for a way of achieving this using ALTER TABLE ... SWITCH
原文链接
今天的关于更改具有外键的表和SQL Server中的记录?的分享已经结束,谢谢您的关注,如果想了解更多关于copy一张老数据表(sqlserver)、mysql-如何关联两个没有外键的表?、postgresql – 具有复合主键的表中的记录顺序是什么、SQL Server 2016 中有外键的表无法被Truncate,只能被Delete的相关知识,请在本站进行查询。
本篇文章给大家谈谈我可以在SQL UPDATE内使用内部SELECT吗?,同时本文还将给你拓展mysql --- select ...for update、MySQL SELECT ... FOR UPDATE、mysql select for update 的问题、mysql SELECT FOR UPDATE语句使用示例等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- 我可以在SQL UPDATE内使用内部SELECT吗?
- mysql --- select ...for update
- MySQL SELECT ... FOR UPDATE
- mysql select for update 的问题
- mysql SELECT FOR UPDATE语句使用示例

我可以在SQL UPDATE内使用内部SELECT吗?
我有一个像这样的数据库:
表foo有列id,name 表bar有列id和foo_id
我有一个带有的传入HTTP查询foo.name,我想bar在bar.foo_idset中适当插入一行。因此,例如:
> SELECT * FROM foo;id name------ -------1 "Andrey"(1 row)> SELECT * FROM bar;(0 rows)给定"Andrey",是否有一个我可以执行以下查询的查询:
> SELECT * FROM bar;id foo_id------ -------1 1(1 row)我在考虑以下方面:
> UPDATE bar SET foo_id=(SELECT id FROM foo WHERE foo.name=?)但这似乎是错误的,因为SELECT的返回集是值,而不是值…
答案1
你将不得不做
SELECT TOP 1 ID FROM foo where foo.name=?但是除此之外,在更新中进行选择没有任何问题。

mysql --- select ...for update
——————————— Oracle —————————————————–
Oracle 的for update行锁
键字: oracle 的for update行锁
SELECT…FOR UPDATE 语句的语法如下:
SELECT … FOR UPDATE [OF column_list][WAIT n|NOWAIT][SKIP LOCKED];
其中:
OF 子句用于指定即将更新的列,即锁定行上的特定列。
WAIT 子句指定等待其他用户释放锁的秒数,防止无限期的等待。
“使用FOR UPDATE WAIT”子句的优点如下:
1防止无限期地等待被锁定的行;
2允许应用程序中对锁的等待时间进行更多的控制。
3对于交互式应用程序非常有用,因为这些用户不能等待不确定
4 若使用了skip locked,则可以越过锁定的行,不会报告由wait n 引发的‘资源忙’异常报告
示例1:
create table t(a varchar2(20),b varchar2(20));
insert into t values(‘1’,’1’);
insert into t values(‘2’,’2’);
insert into t values(‘3’,’3’);
insert into t values(‘4’,’4’);
现在执行如下操作:
在plsql develope中打开两个sql窗口,
在1窗口中运行sql
select * from t where a=’1’ for update;
在2窗口中运行sql1
1. select * from t where a=’1’; 这一点问题也没有,因为行级锁不会影响纯粹的select语句
再运行sql2
2. select * from t where a=’1’ for update; 则这一句sql在执行时,永远处于等待状态,除非窗口1中sql被提交或回滚。
如何才能让sql2不等待或等待指定的时间呢? 我们再运行sql3
3. select * from t where a=’1’ for update nowait; 则在执行此sql时,直接报资源忙的异常。
若执行 select * from t where a=’1’ for update wait 6; 则在等待6秒后,报 资源忙的异常。
如果我们执行sql4
4. select * from t where a=’1’ for update nowait skip Locked; 则执行sql时,即不等待,也不报资源忙异常。
现在我们看看执行如下操作将会发生什么呢?
在窗口1中执行:
select * from t where rownum<=3 nowait skip Locked;
在窗口2中执行:
select * from t where rownum<=6 nowait skip Locked;
select for update 也就如此了吧,insert、update、delete操作默认加行级锁,其原理和操作与select for update并无两样。
select for update of,这个of子句在牵连到多个表时,具有较大作用,如不使用of指定锁定的表的列,则所有表的相关行均被锁定,若在of中指定了需修改的列,则只有与这些列相关的表的行才会被锁定。
实例2
elect * from t for update 会等待行锁释放之后,返回查询结果。
select * from t for update nowait 不等待行锁释放,提示锁冲突,不返回结果
select * from t for update wait 5 等待5秒,若行锁仍未释放,则提示锁冲突,不返回结果
select * from t for update skip locked 查询返回查询结果,但忽略有行锁的记录
——————————— MySQL —————————————————–
MySQL中select * for update锁表的问题
页级:引擎 BDB。
表级:引擎 MyISAM , 理解为锁住整个表,可以同时读,写不行
行级:引擎 INNODB , 单独的一行记录加锁
表级,直接锁定整张表,在你锁定期间,其它进程无法对该表进行写操作。如果你是写锁,则其它进程则读也不允许
行级,,仅对指定的记录进行加锁,这样其它进程还是可以对同一个表中的其它记录进行操作。
页级,表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。
MySQL 5.1支持对MyISAM和MEMORY表进行表级锁定,对BDB表进行页级锁定,对InnoDB表进行行级锁定。
对WRITE,MySQL使用的表锁定方法原理如下:
如果在表上没有锁,在它上面放一个写锁。
否则,把锁定请求放在写锁定队列中。
对READ,MySQL使用的锁定方法原理如下:
如果在表上没有写锁定,把一个读锁定放在它上面
否则,把锁请求放在读锁定队列中。
InnoDB使用行锁定,BDB使用页锁定。对于这两种存储引擎,都可能存在死锁。这是因为,在SQL语句处理期间,InnoDB自动获得行锁定和BDB获得页锁定,而不是在事务启动时获得。
MySQL中select * for update锁表的问题
由于InnoDB预设是Row-Level Lock,所以只有「明确」的指定主键,MySQL才会执行Row lock (只锁住被选取的资料例) ,否则MySQL将会执行Table Lock (将整个资料表单给锁住)。
举个例子:
假设有个表单products ,里面有id跟name二个栏位,id是主键。
例1: (明确指定主键,并且有此笔资料,row lock)
SELECT * FROM products WHERE id=’3’ FOR UPDATE;
SELECT * FROM products WHERE id=’3’ and type=1 FOR UPDATE;
例2: (明确指定主键,若查无此笔资料,无lock)
SELECT * FROM products WHERE id=’-1’ FOR UPDATE;
例2: (无主键,table lock)
SELECT * FROM products WHERE name=’Mouse’ FOR UPDATE;
例3: (主键不明确,table lock)
SELECT * FROM products WHERE id<>’3’ FOR UPDATE;
例4: (主键不明确,table lock)
SELECT * FROM products WHERE id LIKE ‘3’ FOR UPDATE;
注1: FOR UPDATE仅适用于InnoDB,且必须在交易区块(BEGIN/COMMIT)中才能生效。
注2: 要测试锁定的状况,可以利用MySQL的Command Mode ,开二个视窗来做测试。
在MySql 5.0中测试确实是这样的
另外:MyAsim 只支持表级锁,InnerDB支持行级锁
添加了(行级锁/表级锁)锁的数据不能被其它事务再锁定,也不被其它事务修改(修改、删除)
是表级锁时,不管是否查询到记录,都会锁定表
关于Oracle中for update的补充说明:
分成两类:加锁范围子句和加锁行为子句
加锁范围子句:
在select…for update之后,可以使用of子句选择对select的特定数据表进行加锁操作。默认情况下,不使用of子句表示在select所有的数据表中加锁
加锁行为子句:
当我们进行for update的操作时,与普通select存在很大不同。一般select是不需要考虑数据是否被锁定,最多根据多版本一致读的特性读取之前的版本。加入for update之后,Oracle就要求启动一个新事务,尝试对数据进行加锁。如果当前已经被加锁,默认的行为必然是block等待。使用nowait子句的作用就是避免进行等待,当发现请求加锁资源被锁定未释放的时候,直接报错返回。
在日常中,我们对for update的使用还是比较普遍的,特别是在如pl/sql developer中手工修改数据。此时只是觉得方便,而对for update真正的含义缺乏理解。
For update是Oracle提供的手工提高锁级别和范围的特例语句。Oracle的锁机制是目前各类型数据库锁机制中比较优秀的。所以,Oracle认为一般不需要用户和应用直接进行锁的控制和提升。甚至认为死锁这类锁相关问题的出现场景,大都与手工提升锁有关。所以,Oracle并不推荐使用for update作为日常开发使用。而且,在平时开发和运维中,使用了for update却忘记提交,会引起很多锁表故障。
那么,什么时候需要使用for update?就是那些需要业务层面数据独占时,可以考虑使用for update。场景上,比如火车票订票,在屏幕上显示邮票,而真正进行出票时,需要重新确定一下这个数据没有被其他客户端修改。所以,在这个确认过程中,可以使用for update。这是统一的解决方案方案问题,需要前期有所准备。

MySQL SELECT ... FOR UPDATE
MySQL 使用 SELECT ... FOR UPDATE 做事务写入前的确认
以 MySQL 的 InnoDB 为例,预设的 Tansaction isolation level 为 REPEATABLE READ,在 SELECT 的读取锁定主要分为两种方式:
SELECT ... LOCK IN SHARE MODE SELECT ... FOR UPDATE
这两种方式在事务 (Transaction) 进行当中 SELECT 到同一个数据表时,都必须等待其它事务数据被提交 (Commit) 后才会执行。而主要的不同在于 LOCK IN SHARE MODE 在有一方事务要 Update 同一个表单时很容易造成死锁 。
简单的说,如果 SELECT 后面若要 UPDATE 同一个表单,最好使用 SELECT ... UPDATE。
举个例子:假设商品表单 products 内有一个存放商品数量的 quantity ,在订单成立之前必须先确定 quantity 商品数量是否足够 (quantity>0) ,然后才把数量更新为 1。
不安全的做法:
SELECT quantity FROM products WHERE id=3; UPDATE products SET quantity = 1 WHERE id=3;
为什么不安全呢?
少量的状况下或许不会有问题,但是大量的数据存取「铁定」会出问题。
如果我们需要在 quantity>0 的情况下才能扣库存,假设程序在第一行 SELECT 读到的 quantity 是 2 ,看起来数字没有错,但是当 MySQL 正准备要 UPDATE 的时候,可能已经有人把库存扣成 0 了,但是程序却浑然不知,将错就错的 UPDATE 下去了。
因此必须透过的事务机制来确保读取及提交的数据都是正确的。
于是我们在 MySQL 就可以这样测试: (注 1)
SET AUTOCOMMIT=0; BEGIN WORK; SELECT quantity FROM products WHERE id=3 FOR UPDATE; ===========================================
此时 products 数据中 id=3 的数据被锁住 (注 3),其它事务必须等待此次事务 提交后才能执行
SELECT * FROM products WHERE id=3 FOR UPDATE (注 2) 如此可以确保 quantity 在别的事务读到的数字是正确的。 ===========================================
UPDATE products SET quantity = ''1'' WHERE id=3 ; COMMIT WORK;
===========================================
提交 (Commit) 写入数据库,products 解锁。
注 1: BEGIN/COMMIT 为事务的起始及结束点,可使用二个以上的 MySQL Command 视窗来交互观察锁定的状况。
注 2: 在事务进行当中,只有 SELECT ... FOR UPDATE 或 LOCK IN SHARE MODE 同一笔数据时会等待其它事务结束后才执行,一般 SELECT ... 则不受此影响。
注 3: 由于 InnoDB 预设为 Row-level Lock,数据列的锁定可参考这篇。
注 4: InnoDB 表单尽量不要使用 LOCK TABLES 指令,若情非得已要使用,请先看官方对于 InnoDB 使用 LOCK TABLES 的说明,以免造成系统经常发生死锁。
MySQL SELECT ... FOR UPDATE 的 Row Lock 与 Table Lock
上面介绍过 SELECT ... FOR UPDATE 的用法,不过锁定 (Lock) 的数据是判别就得要注意一下了。由于 InnoDB 预设是 Row-Level Lock,所以只有「明确」的指定主键,MySQL 才会执行 Row lock (只锁住被选取的数据) ,否则 MySQL 将会执行 Table Lock (将整个数据表单给锁住)。
举个例子:
假设有个表单 products ,里面有 id 跟 name 二个栏位,id 是主键。
例 1: (明确指定主键,并且有此数据,row lock)
SELECT * FROM products WHERE id=''3'' FOR UPDATE;
例 2: (明确指定主键,若查无此数据,无 lock)
SELECT * FROM products WHERE id=''-1'' FOR UPDATE;
例 2: (无主键,table lock)
SELECT * FROM products WHERE name=''Mouse'' FOR UPDATE;
例 3: (主键不明确,table lock)
SELECT * FROM products WHERE id<>''3'' FOR UPDATE;
例 4: (主键不明确,table lock)
SELECT * FROM products WHERE id LIKE ''3'' FOR UPDATE;
注 1: FOR UPDATE 仅适用于 InnoDB,且必须在事务区块 (BEGIN/COMMIT) 中才能生效。
注 2: 要测试锁定的状况,可以利用 MySQL 的 Command Mode ,开二个视窗来做测试。

mysql select for update 的问题
打开 2 个 cmd 窗口连接 mysql,都设置 autocommit=0,然后在窗口 1 执行查询语句并加锁:

然后,在窗口 2 执行 update user set score=100 where id=1; 因为前面加了锁这里是 wait:
![]()
再回到窗口 1 执行 commit,以便窗口 2 的 update 能执行成功:
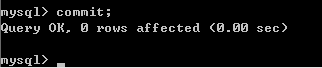
窗口 2update 就会成功:

在窗口 2commit:

在窗口 1 执行查询语句发现分数字段并未更新成功,但数据库实际已经更新了。
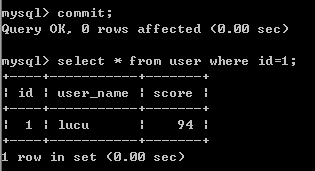
而且,在窗口 1 再次执行加锁的语句显示等待:

不明白这里怎么还是锁定状态,我上一步已经 commit 了而且窗口 2 也是 update 成功的。在窗口 1 再次执行 commit 发现分数更新了:不明白这里怎么要 commit2 次。
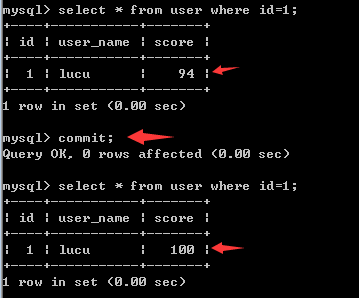

mysql SELECT FOR UPDATE语句使用示例
以MysqL 的InnoDB 为例,预设的Tansaction isolation level 为REPEATABLE READ,在SELECT 的读取锁定主要分为两种方式:
SELECT ... LOCK IN SHARE MODE SELECT ... FOR UPDATE
这两种方式在事务(Transaction) 进行当中SELECT 到同一个数据表时,都必须等待其它事务数据被提交(Commit)后才会执行。而主要的不同在于LOCK IN SHARE MODE 在有一方事务要Update 同一个表单时很容易造成死锁 。
简单的说,如果SELECT 后面若要UPDATE 同一个表单,最好使用SELECT ... UPDATE。
举个例子: 假设商品表单products 内有一个存放商品数量的quantity ,在订单成立之前必须先确定quantity 商品数量是否足够(quantity>0) ,然后才把数量更新为1。
不安全的做法:
SELECT quantity FROM products WHERE id=3; UPDATE products SET quantity = 1 WHERE id=3;
为什么不安全呢?
少量的状况下或许不会有问题,但是大量的数据存取「铁定」会出问题。
如果我们需要在quantity>0 的情况下才能扣库存,假设程序在第一行SELECT 读到的quantity 是2 ,看起来数字没有错,但是当MysqL 正准备要UPDATE 的时候,可能已经有人把库存扣成0 了,但是程序却浑然不知,将错就错的UPDATE 下去了。
因此必须透过的事务机制来确保读取及提交的数据都是正确的。
于是我们在MysqL 就可以这样测试:
SET AUTOCOMMIT=0; BEGIN WORK; SELECT quantity FROM products WHERE id=3 FOR UPDATE;





 工具按钮,将显示窗口分为上下两部分,上部分是sql语句,下部分是结果,修改上部分的语句,点(!)运行,【不能按F5执行】,然后下边的显示结果是可以修改的,非只读状态!
工具按钮,将显示窗口分为上下两部分,上部分是sql语句,下部分是结果,修改上部分的语句,点(!)运行,【不能按F5执行】,然后下边的显示结果是可以修改的,非只读状态!")




方法(筛选器代码aiag)")









")

")




