对于想了解如何使用MERGE或UpsertSql语句的读者,本文将是一篇不可错过的文章,并且为您提供关于flinksql1.15以后不支持upsert了,之前写了upsert的语句如何升级呢?、pos
对于想了解如何使用MERGE或Upsert Sql语句的读者,本文将是一篇不可错过的文章,并且为您提供关于flink sql 1.15 以后 不支持 upsert了 ,之前写了upsert的语句如何升级呢?、postgresql – 用于在重复UPDATE上进行UPSERT或INSERT的MERGE语法、ruby-on-rails – 在默认方法参数中使用.reverse_merge或.merge、SQL Server MERGE(合并)语句的有价值信息。
本文目录一览:- 如何使用MERGE或Upsert Sql语句
- flink sql 1.15 以后 不支持 upsert了 ,之前写了upsert的语句如何升级呢?
- postgresql – 用于在重复UPDATE上进行UPSERT或INSERT的MERGE语法
- ruby-on-rails – 在默认方法参数中使用.reverse_merge或.merge
- SQL Server MERGE(合并)语句

如何使用MERGE或Upsert Sql语句
我如何在下面的代码中使用MERGESql语句或UPDATE语句。我有一个称为columnName的MachineName列,其他列值更改了,但是MachineName却没有更改。如果列MachineName更改,则需要在第二行中插入新值。如果不是,我需要更新同一行。我怎样才能做到这一点。这是正确的方法吗?请帮忙
MERGE INTO [devLaserViso].[dbo].[Machine] WITH (HOLDLOCK) USING [devLaserViso].[dbo].[Machine] ON (MachineName = MachineName) WHEN MATCHED THEN UPDATE SET MachineName = L1,ProgramName= ancdh.pgm, TotalCount= 10, RightCount=4, LeftCount= 3,ErrorCode=0,FinishingTime=fsefsefef WHEN NOT MATCHED THEN INSERT (MachineName, ProgramName, TotalCount, RightCount, LeftCount, ErrorCode, FinishingTime) VALUES (L02, djiwdn.pgm, 11, 5, 4, 0, dnwdnwoin);答案1
您可以将新的Machine数据加载到Temporary表中,然后可以使用Merge语句来更新Machine表中已经存在记录的记录,如果Machine表中不存在新记录,则将插入新记录。
MERGE [devLaserViso].[dbo].[Machine] t WITH (HOLDLOCK) USING [devLaserViso].[dbo].[TempMachine] sON (s.MachineName = t.MachineName)WHEN MATCHED THEN UPDATE SET t.MachineName = s.MachineName,t.ProgramName =s.ProgramNameWHEN NOT MATCHED BY TARGET THEN INSERT (MachineName,ProgramName) VALUES (s.MachineName, s.ProgramName);
flink sql 1.15 以后 不支持 upsert了 ,之前写了upsert的语句如何升级呢?
flink sql 1.15 以后 不支持 upsert了 ,之前写了upsert的语句如何升级呢?

postgresql – 用于在重复UPDATE上进行UPSERT或INSERT的MERGE语法
INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1;
但是现在我正在使用Postgresql,并且努力添加UPSERT功能,看起来MERGE可能适用于我想要的但想看看这是否是最优化的语法. Example Syntax 1,I’ve also seen this but don’t understand how to implement.我还没有尝试过这个,因为我认为MERGE用于合并从table1到Table2的数据或类似的工作?
MERGE INTO table USING table ON c = 1 WHEN MATCHED THEN UPDATE SET c=c+1 WHEN NOT MATCHED THEN INSERT (a,c) VALUES (1,3)
还有其他建议吗?

ruby-on-rails – 在默认方法参数中使用.reverse_merge或.merge
def setup(options = {})
options.reverse_merge :size => 25,:veLocity => 10
end
和
def setup(options = {})
{ :size => 25,:veLocity => 10 }.merge(options)
end
在方法的参数中指定默认值.
问题是:哪一个更好?你更愿意使用哪一个?性能,代码可读性或其他方面有什么不同吗?
编辑:我偶然添加了爆炸(!)…并不是要问无爆炸方法与爆炸方法之间的区别
解决方法
options.reverse_merge(size: 25,veLocity: 10)
原因是:
>当哈希用作方法参数时,您不必为哈希编写大括号.
>从左到右阅读你知道这行代码正在处理传入的选项哈希,首先要了解一个新哈希,然后实现选项合并到它.
>如果您确实想要更新原始选项哈希,那就像添加一样简单!到reverse_merge!方法.而使用其他方法,您现在必须添加变量(重新)赋值.
最终,我认为这只是一种风格选择,而且取决于你和大脑的感觉.
语句")
SQL Server MERGE(合并)语句
如何使用SQL Server MERGE语句基于与另一个表匹配的值来更新表中的数据。
SQL Server MERGE语句
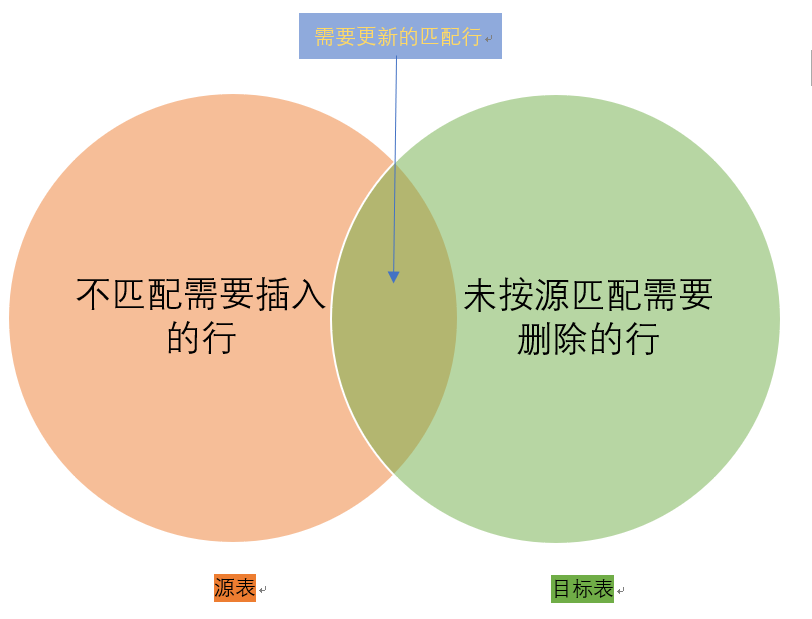
假设有两个表,分别称为源表和目标表,并且需要根据与源表匹配的值来更新目标表。有以下三种情况:
- 源表中有一些目标表中不存在的行。在这种情况下,需要将源表中的行插入目标表中。
- 目标表中的某些行在源表中不存在。在这种情况下,需要从目标表中删除行。
- 源表中的某些行与目标表中的行具有相同的键。但是,这些行在非键列中具有不同的值。在这种情况下,需要使用源表中的值更新目标表中的行。
下图说明了源表和目标表以及相应的操作:插入,更新和删除:
如果使用INSERT,UPDATE以及DELETE单独的语句,你必须建立三个单独的语句从源表匹配的行更新数据到目标表。
但是,SQL Server提供了MERGE允许同时执行三个操作的语句。下面显示了该MERGE语句的语法:
MERGE target_table USING source_table
ON merge_condition
WHEN MATCHED
THEN update_statement
WHEN NOT MATCHED
THEN insert_statement
WHEN NOT MATCHED BY SOURCE
THEN DELETE;
首先,在MERGE子句中指定目标表和源表。
其次,merge_condition确定源表中的行与目标表中的行如何匹配。它类似于join子句中的join条件。通常,使用主键或唯一键的键列进行匹配。
三,merge_condition结果有三种状态:MATCHED,NOT MATCHED,和NOT MATCHED BY SOURCE。
MATCHED:这些是符合合并条件的行。对于匹配的行,需要使用源表中的值更新目标表中的行列。
NOT MATCHED:这些是源表中的行,目标表中没有任何匹配的行。在这种情况下,需要将源表中的行添加到目标表中。请注意,NOT MATCHED也称为NOT MATCHED BY TARGET。
NO MATCHED BY SOURCE:这些是目标表中的行,与源表中的任何行都不匹配。如果要使目标表与源表中的数据同步,则需要使用此匹配条件从目标表中删除行。
SQL Server MERGE语句示例
假设我们有两个表,sales.category并且sales.category_staging按产品类别存储销售额。
CREATE TABLE sales.category (
category_id INT PRIMARY KEY,
category_name VARCHAR(255) NOT NULL,
amount DECIMAL(10 , 2 )
);
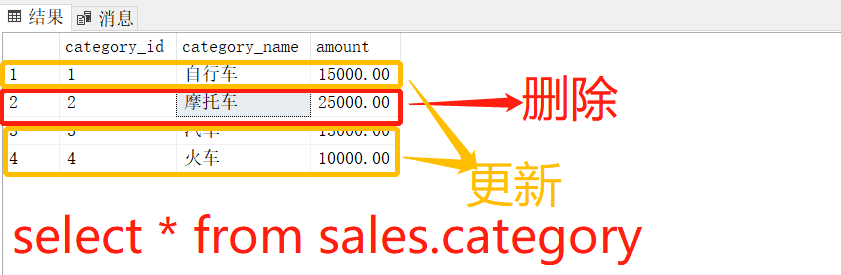
INSERT INTO sales.category(category_id, category_name, amount)
VALUES(1,''自行车'',15000),
(2,''摩托车'',25000),
(3,''汽车'',13000),
(4,''火车'',10000);
CREATE TABLE sales.category_staging (
category_id INT PRIMARY KEY,
category_name VARCHAR(255) NOT NULL,
amount DECIMAL(10 , 2 )
);
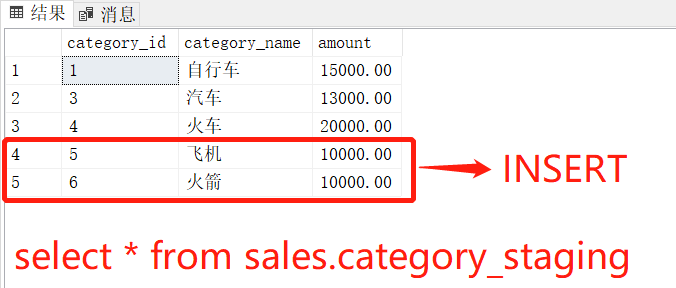
INSERT INTO sales.category_staging(category_id, category_name, amount)
VALUES(1,''自行车'',15000),
(3,''汽车'',13000),
(4,''火车'',20000),
(5,''飞机'',10000),
(6,''火箭'',10000);要使用(源表)中sales.category的值将数据更新到(目标sales.category_staging表),使用以下MERGE语句:
MERGE sales.category t
USING sales.category_staging s
ON (s.category_id = t.category_id)
WHEN MATCHED
THEN UPDATE SET
t.category_name = s.category_name,
t.amount = s.amount
WHEN NOT MATCHED BY TARGET
THEN INSERT (category_id, category_name, amount)
VALUES (s.category_id, s.category_name, s.amount)
WHEN NOT MATCHED BY SOURCE
THEN DELETE;
SQL Server合并示例
在此示例中,我们将category_id两个表中的列中的值用作合并条件。
- 首先,sales.category_staging表中ID为1、3、4的行与目标表中的行匹配,因此,该MERGE语句更新了表中类别名称和数量列中的值sales.category。
- 其次,sales.category_staging表中ID为5和6的行在表中不存在sales.category,因此该MERGE语句将这些行插入到目标表中。
- 第三,sales.category表中ID为2的行在表中不存在sales.sales_staging,因此,该MERGE语句删除了该行。
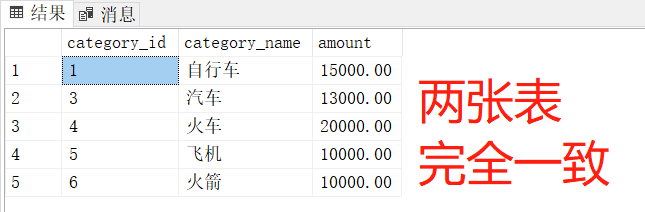
合并的结果是,sales.category表中的数据与sales.category_staging表中的数据完全同步 。
今天关于如何使用MERGE或Upsert Sql语句的讲解已经结束,谢谢您的阅读,如果想了解更多关于flink sql 1.15 以后 不支持 upsert了 ,之前写了upsert的语句如何升级呢?、postgresql – 用于在重复UPDATE上进行UPSERT或INSERT的MERGE语法、ruby-on-rails – 在默认方法参数中使用.reverse_merge或.merge、SQL Server MERGE(合并)语句的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

