本文将为您提供关于在Windows中设置HADOOP_HOMEvariables的详细介绍,我们还将为您解释在WINDOWS中设置屏幕保护程序操作正确的是的相关知识,同时,我们还将为您提供关于CDH的
本文将为您提供关于在Windows中设置HADOOP_HOMEvariables的详细介绍,我们还将为您解释在WINDOWS中设置屏幕保护程序操作正确的是的相关知识,同时,我们还将为您提供关于CDH的 $HADOOP_HOME or $HADOOP_PREFIX must be set、Hadoop on Windows - “Error JAVA_HOME is incorrectly set.”、HADOOP_HOME and hadoop.home.dir are unset.、Hadoop在window上运行 user=Administrator, access=WRITE, inode="hadoop"的实用信息。
本文目录一览:- 在Windows中设置HADOOP_HOMEvariables(在WINDOWS中设置屏幕保护程序操作正确的是)
- CDH的 $HADOOP_HOME or $HADOOP_PREFIX must be set
- Hadoop on Windows - “Error JAVA_HOME is incorrectly set.”
- HADOOP_HOME and hadoop.home.dir are unset.
- Hadoop在window上运行 user=Administrator, access=WRITE, inode="hadoop"
")
在Windows中设置HADOOP_HOMEvariables(在WINDOWS中设置屏幕保护程序操作正确的是)
我试图在Windows 8中使用Spark和Hadoop。但是不pipe我的代码是什么,我收到这个错误:
15/08/25 19:29:58 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable nullbinwinutils.exe in the Hadoop binaries. at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:355) at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:370) at org.apache.hadoop.util.Shell.<clinit>(Shell.java:363) at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79) at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:104) at org.apache.hadoop.security.Groups.<init>(Groups.java:86) at org.apache.hadoop.security.Groups.<init>(Groups.java:66) at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:280) at org.apache.hadoop.security.UserGroupinformation.initialize(UserGroupinformation.java:271) at org.apache.hadoop.security.UserGroupinformation.ensureInitialized(UserGroupinformation.java:248) at org.apache.hadoop.security.UserGroupinformation.loginUserFromSubject(UserGroupinformation.java:763) at org.apache.hadoop.security.UserGroupinformation.getLoginUser(UserGroupinformation.java:748) at org.apache.hadoop.security.UserGroupinformation.getCurrentUser(UserGroupinformation.java:621) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2162) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2162) at scala.Option.getorElse(Option.scala:120) at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2162) at org.apache.spark.SparkContext.<init>(SparkContext.scala:301) at org.apache.spark.api.java.JavaSparkContext.<init>(JavaSparkContext.scala:61) at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(UnkNown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(UnkNown Source) at java.lang.reflect.Constructor.newInstance(UnkNown Source) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:234) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:379) at py4j.Gateway.invoke(Gateway.java:214) at py4j.commands.ConstructorCommand.invokeConstructor(ConstructorCommand.java:79) at py4j.commands.ConstructorCommand.execute(ConstructorCommand.java:68) at py4j.GatewayConnectionun(GatewayConnection.java:207) at java.lang.Thread.run(UnkNown Source)
如你看到的:
nullbinwinutils.exe
hadoop主path为null。 我试图设置HADOOP_HOME作为一个环境variables,但没有解决这个问题。 任何帮助或评论关于这将不胜感激。
谢谢
为什么DwmRegisterThumbnail可能会失败?
Windows 8:对通过WOW64运行的32位应用程序进行堆分析
我如何使JDK成为默认的JRE?
couchDB完整的包与Windows的所有依赖项
Windows 8手机应用程序与Windows 8的选项卡应用程序
在TideSDK中安装python模块
如何利用Windows中的RDMA
我如何使用和访问使用PHP和Wamp服务器的sqlite数据库?
如何在Windows上安装厨师服务器
应用程序不会从创build者启动
我设法解决这个问题在开始时使用下面的代码部分:
import sys import os os.environ['HADOOP_HOME'] = "C:/mine/Spark/hadoop-2.6.0" sys.path.append("C:/mine/Spark/hadoop-2.6.0/bin")
希望这可以帮助别人,如果有人有更好的主意,我一定会明白的。

CDH的 $HADOOP_HOME or $HADOOP_PREFIX must be set
cdh跟apache集群存在差异,找配置文件找了半天。现在贴出来供大家参考
方法一:
hadoop的安装目录为:/opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop
hive在cdh的安装目录为 :
/opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hive/conf
修改hive-env.sh 插入一行:
export HADOOP_HOME=
然后 : source hive-env.sh
问题解决!
方法二:
用原始的方法
vim /etc/profile
加入一行:
export HADOOP_HOME=/opt/cloudera/parcels/CDH-5.15.1-1.cdh5.15.1.p0.4/lib/hadoop
不要忘了刷新!问题解决!

Hadoop on Windows - “Error JAVA_HOME is incorrectly set.”

Hadoop on Windows - “Error JAVA_HOME is incorrectly set.”
java 环境目录不能有空格
https://stackoverflow.com/questions/31621032/hadoop-on-windows-error-java-home-is-incorrectly-set
---------------------------------------------------------
java.io.filenotfoundexception: hadoop_home and hadoop.home.dir are unset.
配置 hadoop 本地环境,且重启机器,保证 System.out.println (System.getenv ("HADOOP_HOME")); 能获取到

HADOOP_HOME and hadoop.home.dir are unset.
具体异常如下:
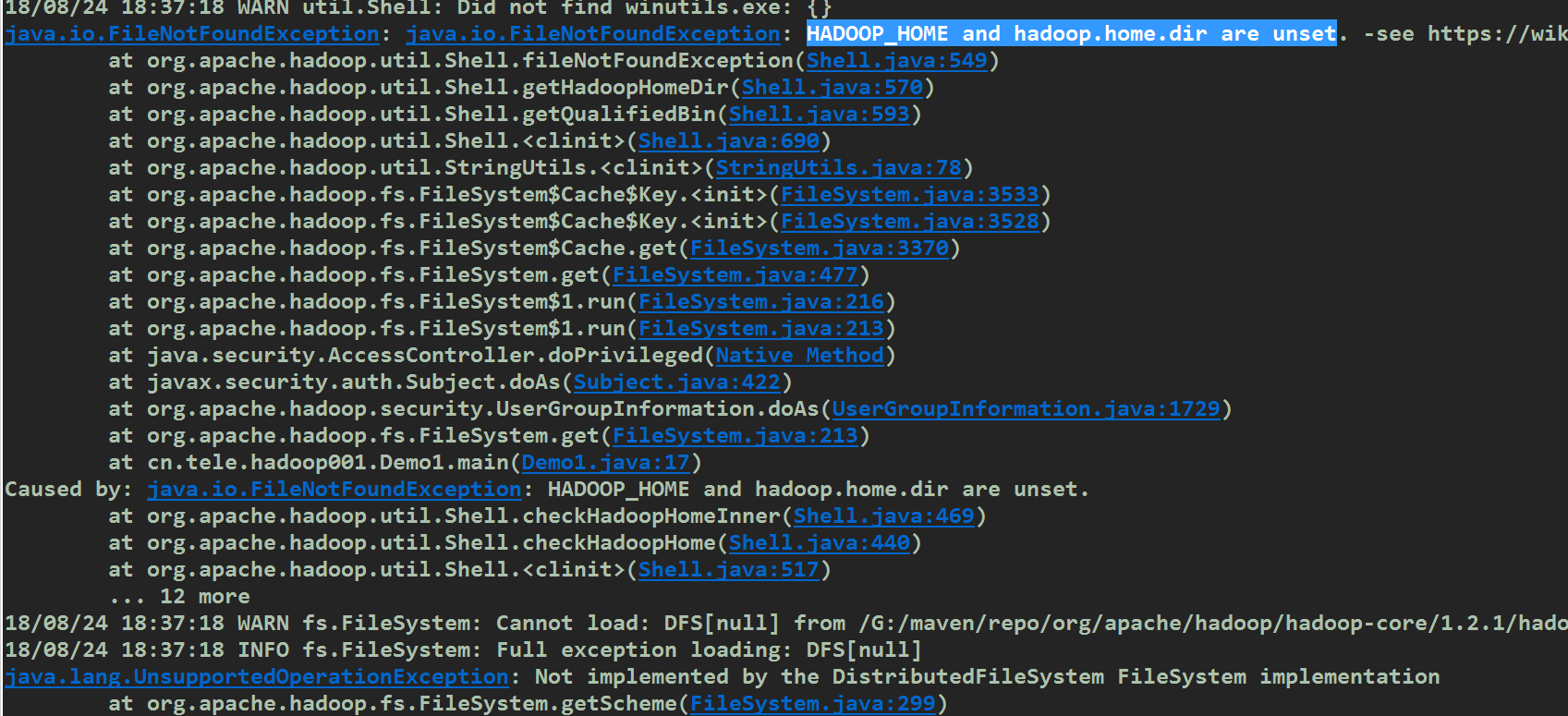
解决方案:
删除pom文件中的hadoop-core的依赖,原因:hadoop-core是1.x的产物,在2.x之后已经被hadoop-common取代,我配置的时候同时使用了这两个依赖导致jar包冲突.
附上我测试上传用的代码

1 /**
2 * 上传文件到hdfs
3 * @author tele
4 *
5 */
6 public class Demo1 {
7 public static void main(String[] args) throws Exception {
8 Configuration conf = new Configuration();
9 FileSystem fs = FileSystem.get(new URI("hdfs://hadoop002:9000"), conf,"tele");
10 fs.copyFromLocalFile(new Path("f:/test.sql"),new Path("/111.sql"));
11 fs.close();
12 System.out.println("上传完毕");
13 }
14 }
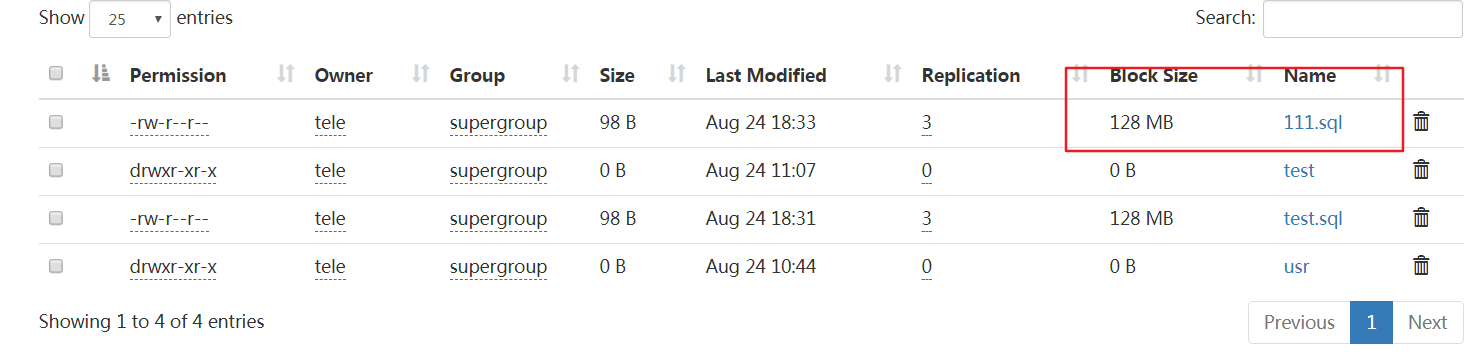
如果下载的过程中出现了 HADOOP_HOME and hadoop.home.dir are unset,那么就说明你没有配置windows本地的hadoop环境变量.你可能会想我是远程调用linux下的hadoop,与我本地的hadoop有什么关系?如果你的操作只对远程的hadoop生效,如上传,创建目录,文件改名(写)等那么你是不需要在windows本地配置hadoop的,可一旦涉及到下载(读),hadoop内部的缓存机制要求本地也必须有hadoop,于是也会出现HADOOP_HOME and hadoop.home.dir are unset,解决办法配置HADOOP_HOME并加入%HADOOP_HOME%\bin到PATH中,之后测试下hadoop version命令,有效的话重启你的eclipse/myeclipse,但这还不够,windows下的hadoop还需要winutils.exe,否则会报Could not locate Hadoop executable: xxxx\winutils.exe
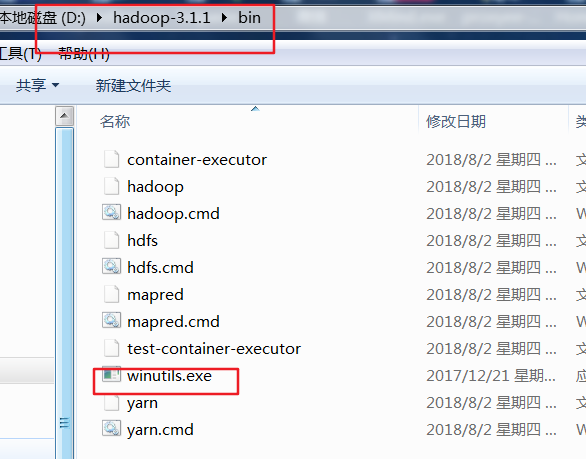
测试下载的代码如下
1 static FileSystem fs;
2 static {
3 Configuration conf = new Configuration();
4 try {
5 fs = FileSystem.get(new URI("hdfs://hadoop002:9000"), conf,"tele");
6 } catch (IOException e) {
7 // TODO Auto-generated catch block
8 e.printStackTrace();
9 } catch (InterruptedException e) {
10 // TODO Auto-generated catch block
11 e.printStackTrace();
12 } catch (URISyntaxException e) {
13 // TODO Auto-generated catch block
14 e.printStackTrace();
15 }
16 }
17
18 //下载文件
19 @Test
20 public void downLoadFile() throws Exception{
21 //如果为null,重启myeclipse/eclipse即可
22 System.out.println(System.getenv("HADOOP_HOME"));
23 fs.copyToLocalFile(new Path("/hello2.sql"),new Path("C:/a.sql"));
24 fs.close();
25 System.out.println("下载完毕");
26 }

Hadoop在window上运行 user=Administrator, access=WRITE, inode="hadoop"
win7下eclipse中错误的详细描述如下:
org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied: user=Administrator, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x
其实这个错误的原因很容易看出来,用户Administator在hadoop上执行写操作时被权限系统拒绝.
解决问题的过程
看到这个错误的,第一步就是将这个错误直接入放到百度google里面进行搜索。找到了N多篇文章,但是主要的思路就如此篇文章所写的两个解决办法:http://www.cnblogs.com/acmy/archive/2011/10/28/2227901.html
1、在hdfs的配置文件中,将dfs.permissions修改为False
2、执行这样的操作 hadoop fs -chmod 777 /user/hadoop
对于上面的第一个方法,我试了行不通,不知道是自己设置错误还是其他原因,对我此法不可行,第二个方法可行。第二个方法是让我们来修改HDFS中相应文件夹的权限,后面的/user/hadoop这个路径为HDFS中的文件路径,这样修改之后就让我们的administrator有在HDFS的相应目录下有写文件的权限(所有的用户都是写权限)。
虽然上面的第二步可以解决问题了,上传之后的文件所有者为Administrator,但是总感觉这样的方法不够优雅,而且这样修改权限会有一定的安全问题,总之就是看着不爽,就在想有没有其他的办法?
问题分析
开始仔细的观察了这个错误的详细信息,看到user=Administrator, access=WRITE。这里的user其实是我当前系统(运行客户端的计算机的操作系统)的用户名,实际期望这里的user=hadoop(hadoop是我的HADOOP上面的用户名),但是它取的是当前的系统的用户名,很明显,如果我将当前系统的用户名改为hadoop,这个肯定也是可以行得通的,但是如果后期将开发的代码部署到服务器上之后,就不能方便的修改用户,此方法明显也不够方便。
现在就想着Configuration这个是一个配置类,有没有一个参数是可以在某个地方设置以哪个用户运行呢?搜索了半天,无果。没有找到相关的配置参数。
最终只有继续分析代码, FileSystem fs = FileSystem.get(URI.create(dest), conf);代码是在此处开始对HDFS进行调用,所以就想着将HADOOP的源码下下来,debug整个调用过程,这个user=Administator是在什么时间赋予的值。理解了调用过程,还怕找不到解决问题的办法么?
跟踪代码进入 FileSystem.get-->CACHE.get()-->Key key = new Key(uri, conf);到这里的时候发现key值里面已经有Administrator了,所以关键肯定是在new key的过程。继续跟踪UserGroupInformation.getCurrentUser()-->getLoginUser()-->login.login()到这一步的时候发现用户名已经确定了,但是这个方法是Java的核心源码,是一个通用的安全认证,但对这一块不熟悉,但是debug时看到subject里面有NTUserPrincipal:Administator,所以就想着搜索一下这个东西是啥,结果就找到了下面这一篇关键的文章:
http://www.udpwork.com/item/7047.html
在此篇文章里面作者分析了hadoop的整个登录过程,对于我有用的是其中的这一段:
2.login.login();
这个会调用HadoopLoginModule的login()和commit()方法。
HadoopLoginModule的login()方法是一个空函数,只打印了一行调试日志 LOG.debug("hadoop login");
commit()方法负责把Principal添加到Subject中。
此时一个首要问题是username是什么?
在使用了kerberos的情况下,从javax.security.auth.kerberos.KerberosPrincipal的实例获取username。
在未使用kerberos的情况下,优先读取HADOOP_USER_NAME这个系统环境变量,如果不为空,那么拿它作username。否则,读取HADOOP_USER_NAME这个java环境变量。否则,从com.sun.security.auth.NTUserPrincipal或者com.sun.security.auth.UnixPrincipal的实例获取username。
如果以上尝试都失败,那么抛出异常LoginException("Can’t find user name")。
最终拿username构造org.apache.hadoop.security.User的实例添加到Subject中。
看完这一段,我明白了执行login.login的时候调用了hadoop里面的HadoopLoginModule方法,而关键是在commit方法里面,在这里优先读取HADOOP_USER_NAME系统环境变量,然后是java环境变量,如果再没有就从NTUserPrincipal等里面取。关键代码为:
if (!isSecurityEnabled() && (user == null)) {
String envUser = System.getenv(HADOOP_USER_NAME);
if (envUser == null) {
envUser = System.getProperty(HADOOP_USER_NAME);
}
user = envUser == null ? null : new User(envUser);
}
OK,看到这里我的需求也就解决了,只要在系统的环境变量里面添加HADOOP_USER_NAME=hadoop(HDFS上的有权限的用户,具体看自己的情况),或者在当前JDK的变量参数里面添加HADOOP_USER_NAME这个Java变量即可。我的情况添加系统环境变量更方法。
如果是在Eclipse里面运行,修改完环境变量后,记得重启一下eclipse,不然可能不会生效。
解决办法
最终,总结下来解决办法大概有三种:
1、在系统的环境变量或java JVM变量里面添加HADOOP_USER_NAME,这个值具体等于多少看自己的情况,以后会运行HADOOP上的Linux的用户名。(修改完重启eclipse,不然可能不生效)
2、将当前系统的帐号修改为hadoop
3、使用HDFS的命令行接口修改相应目录的权限,hadoop fs -chmod 777 /user,后面的/user是要上传文件的路径,不同的情况可能不一样,比如要上传的文件路径为hdfs://namenode/user/xxx.doc,则这样的修改可以,如果要上传的文件路径为hdfs://namenode/java/xxx.doc,则要修改的为hadoop fs -chmod 777 /java或者hadoop fs -chmod 777 /,java的那个需要先在HDFS里面建立Java目录,后面的这个是为根目录调整权限。
4、右击计算机-->管理--->用户和组-->admin。。。改为与Linux下集群主机名相同
本人验证过第四种方式
---------------------
作者:顺顺顺子
来源:CSDN
原文:https://blog.csdn.net/xiaoshunzi111/article/details/52062640
版权声明:本文为博主原创文章,转载请附上博文链接!
今天关于在Windows中设置HADOOP_HOMEvariables和在WINDOWS中设置屏幕保护程序操作正确的是的介绍到此结束,谢谢您的阅读,有关CDH的 $HADOOP_HOME or $HADOOP_PREFIX must be set、Hadoop on Windows - “Error JAVA_HOME is incorrectly set.”、HADOOP_HOME and hadoop.home.dir are unset.、Hadoop在window上运行 user=Administrator, access=WRITE, inode="hadoop"等更多相关知识的信息可以在本站进行查询。
本文标签:




