本文将介绍docker1-->dockerswarm转载的详细情况,特别是关于docker转移的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于35.
本文将介绍docker 1-->docker swarm 转载的详细情况,特别是关于docker 转移的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于35. docker swarm dockerStack 部署 投票应用、37. docker swarm docker service 的更新、Docker (二十一)-Docker Swarm 集群部署、Docker 1.12 以前的: swarm 搭建 docker 集群的知识。
本文目录一览:- docker 1-->docker swarm 转载(docker 转移)
- 35. docker swarm dockerStack 部署 投票应用
- 37. docker swarm docker service 的更新
- Docker (二十一)-Docker Swarm 集群部署
- Docker 1.12 以前的: swarm 搭建 docker 集群
")
docker 1-->docker swarm 转载(docker 转移)
实践中会发现,生产环境中使用单个 Docker 节点是远远不够的,搭建 Docker 集群势在必行。然而,面对 Kubernetes, Mesos 以及 Swarm 等众多容器集群系统,我们该如何选择呢?它们之中,Swarm 是 Docker 原生的,同时也是最简单,最易学,最节省资源的,比较适合中小型公司使用。
Docker Swarm 介绍
Swarm 在 Docker 1.12 版本之前属于一个独立的项目,在 Docker 1.12 版本发布之后,该项目合并到了 Docker 中,成为 Docker 的一个子命令。目前,Swarm 是 Docker 社区提供的唯一一个原生支持 Docker 集群管理的工具。它可以把多个 Docker 主机组成的系统转换为单一的虚拟 Docker 主机,使得容器可以组成跨主机的子网网络。
Docker Swarm 是一个为 IT 运维团队提供集群和调度能力的编排工具。用户可以把集群中所有 Docker Engine 整合进一个「虚拟 Engine」的资源池,通过执行命令与单一的主 Swarm 进行沟通,而不必分别和每个 Docker Engine 沟通。在灵活的调度策略下,IT 团队可以更好地管理可用的主机资源,保证应用容器的高效运行。
Docker Swarm 优点
任何规模都有高性能表现
对于企业级的 Docker Engine 集群和容器调度而言,可拓展性是关键。任何规模的公司 —— 不论是拥有五个还是上千个服务器 —— 都能在其环境下有效使用 Swarm。
经过测试,Swarm 可拓展性的极限是在 1000 个节点上运行 50000 个部署容器,每个容器的启动时间为亚秒级,同时性能无减损。
灵活的容器调度
Swarm 帮助 IT 运维团队在有限条件下将性能表现和资源利用最优化。Swarm 的内置调度器(scheduler)支持多种过滤器,包括:节点标签,亲和性和多种容器部策略如 binpack、spread、random 等等。
服务的持续可用性
Docker Swarm 由 Swarm Manager 提供高可用性,通过创建多个 Swarm master 节点和制定主 master 节点宕机时的备选策略。如果一个 master 节点宕机,那么一个 slave 节点就会被升格为 master 节点,直到原来的 master 节点恢复正常。
此外,如果某个节点无法加入集群,Swarm 会继续尝试加入,并提供错误警报和日志。在节点出错时,Swarm 现在可以尝试把容器重新调度到正常的节点上去。
和 Docker API 及整合支持的兼容性
Swarm 对 Docker API 完全支持,这意味着它能为使用不同 Docker 工具(如 Docker CLI,Compose,Trusted Registry,Hub 和 UCP)的用户提供无缝衔接的使用体验。
Docker Swarm 为 Docker 化应用的核心功能(诸如多主机网络和存储卷管理)提供原生支持。开发的 Compose 文件能(通过 docker-compose up )轻易地部署到测试服务器或 Swarm 集群上。Docker Swarm 还可以从 Docker Trusted Registry 或 Hub 里 pull 并 run 镜像。
综上所述,Docker Swarm 提供了一套高可用 Docker 集群管理的解决方案,完全支持标准的 Docker API,方便管理调度集群 Docker 容器,合理充分利用集群主机资源。
** 并非所有服务都应该部署在 Swarm 集群内。数据库以及其它有状态服务就不适合部署在 Swarm 集群内。**
相关概念
节点
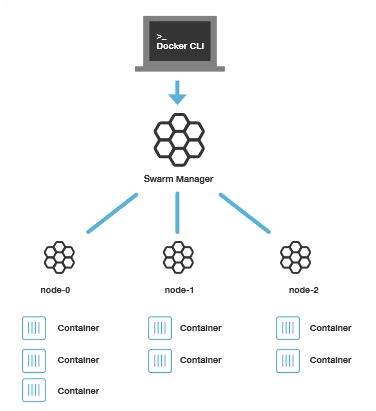
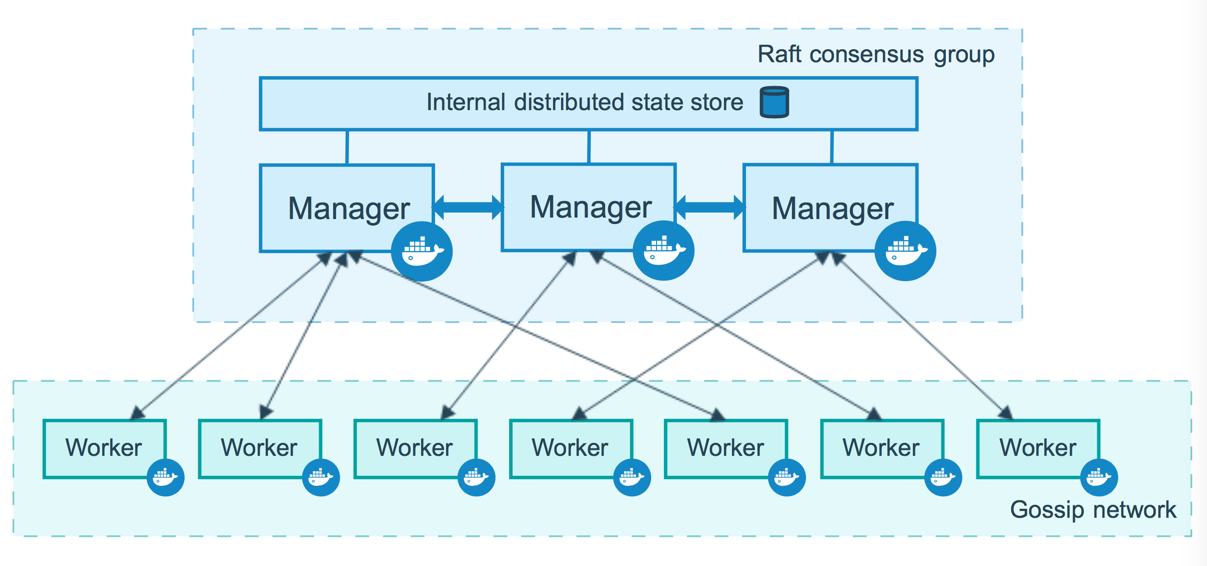
运行 Docker 的主机可以主动初始化一个 Swarm 集群或者加入一个已存在的 Swarm 集群,这样这个运行 Docker 的主机就成为一个 Swarm 集群的节点 (node) 。节点分为管理 (manager) 节点和工作 (worker) 节点。
管理节点用于 Swarm 集群的管理,docker swarm 命令基本只能在管理节点执行(节点退出集群命令 docker swarm leave 可以在工作节点执行)。一个 Swarm 集群可以有多个管理节点,但只有一个管理节点可以成为 leader,leader 通过 raft 协议实现。
工作节点是任务执行节点,管理节点将服务 (service) 下发至工作节点执行。管理节点默认也作为工作节点。你也可以通过配置让服务只运行在管理节点。下图展示了集群中管理节点与工作节点的关系。
服务和任务
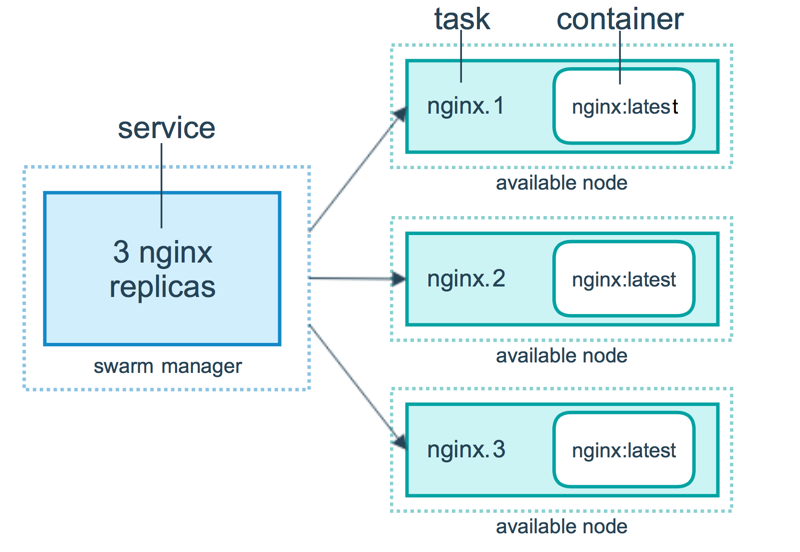
任务 (Task)是 Swarm 中的最小的调度单位,目前来说就是一个单一的容器。
服务 (Services) 是指一组任务的集合,服务定义了任务的属性。服务有两种模式:
- replicated services 按照一定规则在各个工作节点上运行指定个数的任务。
- global services 每个工作节点上运行一个任务
两种模式通过 docker service create 的 --mode 参数指定。下图展示了容器、任务、服务的关系。
创建 Swarm 集群
我们知道 Swarm 集群由管理节点和工作节点组成。我们来创建一个包含一个管理节点和两个工作节点的最小 Swarm 集群。
初始化集群
查看虚拟主机,现在没有
docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS使用 virtualbox 创建管理节点
docker-machine create --driver virtualbox manager1
#进入管理节点
docker-machine ssh manager1执行 sudo -i 可以进入 Root 权限
我们使用 docker swarm init 在 manager1 初始化一个 Swarm 集群。
docker@manager1:~$ docker swarm init --advertise-addr 192.168.99.100
Swarm initialized: current node (j0o7sykkvi86xpc00w71ew5b6) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-47z6jld2o465z30dl7pie2kqe4oyug4fxdtbgkfjqgybsy4esl-8r55lxhxs7ozfil45gedd5b8a 192.168.99.100:2377
To add a manager to this swarm, run ''docker swarm join-token manager'' and follow the instructions.如果你的 Docker 主机有多个网卡,拥有多个 IP,必须使用 --advertise-addr 指定 IP。
执行 docker swarm init 命令的节点自动成为管理节点。
命令 docker info 可以查看 swarm 集群状态:
Containers: 0
Running: 0
Paused: 0
Stopped: 0
...snip...
Swarm: active
NodeID: dxn1zf6l61qsb1josjja83ngz
Is Manager: true
Managers: 1
Nodes: 1
...snip...命令 docker node ls 可以查看集群节点信息:
docker@manager1:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
1ipck4z2uuwf11f4b9mnon2ul * manager1 Ready Active Leader退出虚拟主机
docker@manager1:~$ exit 增加工作节点
上一步初始化了一个 Swarm 集群,拥有了一个管理节点,在 Docker Machine 一节中我们了解到 Docker Machine 可以在数秒内创建一个虚拟的 Docker 主机,下面我们使用它来创建两个 Docker 主机,并加入到集群中。
创建虚拟主机 worker1
创建主机
$ docker-machine create -d virtualbox worker1进入虚拟主机 worker1
$ docker-machine ssh worker1加入 swarm 集群
docker@worker1:~$ docker swarm join \
--token SWMTKN-1-47z6jld2o465z30dl7pie2kqe4oyug4fxdtbgkfjqgybsy4esl-8r55lxhxs7ozfil45gedd5b8a \
192.168.99.100:2377
This node joined a swarm as a worker. 退出虚拟主机
docker@worker1:~$ exit 创建虚拟主机 worker2
创建
$ docker-machine create -d virtualbox worker2入虚拟主机 worker2
$ docker-machine ssh worker2加入 swarm 集群
docker@worker2:~$ docker swarm join \
--token SWMTKN-1-47z6jld2o465z30dl7pie2kqe4oyug4fxdtbgkfjqgybsy4esl-8r55lxhxs7ozfil45gedd5b8a \
192.168.99.100:2377
This node joined a swarm as a worker. 退出虚拟主机
docker@worker2:~$ exit 两个工作节点添加完成
查看集群
进入管理节点:
docker-machine ssh manager1宿主机子上查看虚拟主机
docker@manager1:~$ docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
manager1 * virtualbox Running tcp://192.168.99.100:2376 v17.12.1-ce
worker1 - virtualbox Running tcp://192.168.99.101:2376 v17.12.1-ce
worker2 - virtualbox Running tcp://192.168.99.102:2376 v17.12.1-ce在主节点上面执行 docker node ls 查询集群主机信息
docker@manager1:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
1ipck4z2uuwf11f4b9mnon2ul * manager1 Ready Active Leader
rtcpqgcn2gytnvufwfveukgrv worker1 Ready Active
te2e9tr0qzbetjju5gyahg6f7 worker2 Ready Active这样我们就创建了一个最小的 Swarm 集群,包含一个管理节点和两个工作节点。
部署服务
我们使用 docker service 命令来管理 Swarm 集群中的服务,该命令只能在管理节点运行。
新建服务
进入集群管理节点:
docker-machine ssh manager1使用 docker 中国镜像
docker search alpine
docker pull registry.docker-cn.com/library/alpine现在我们在上一节创建的 Swarm 集群中运行一个名为 helloworld 服务。
docker@manager1:~$ docker service create --replicas 1 --name helloworld alpine ping ityouknow.com
rwpw7eij4v6h6716jvqvpxbyv
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged命令解释:
docker service create命令创建一个服务--name服务名称命名为helloworld--replicas设置启动的示例数alpine指的是使用的镜像名称,ping ityouknow.com指的是容器运行的 bash
使用命令 docker service ps rwpw7eij4v6h6716jvqvpxbyv 可以查看服务进展
docker@manager1:~$ docker service ps rwpw7eij4v6h6716jvqvpxbyv
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
rgroe3s9qa53 helloworld.1 alpine:latest worker1 Running Running about a minute ago使用 docker service ls 来查看当前 Swarm 集群运行的服务。
docker@manager1:~$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
yzfmyggfky8c helloworld replicated 0/1 alpine:latest监控集群状态
登录管理节点 manager1
docker-machine ssh manager1运行 docker service inspect --pretty <SERVICE-ID> 查询服务概要状态,以 helloworld 服务为例:
docker@manager1:~$ docker service inspect --pretty helloworld
ID: rwpw7eij4v6h6716jvqvpxbyv
Name: helloworld
Service Mode: Replicated
Replicas: 1
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
...
Rollback order: stop-first
ContainerSpec:
Image: alpine:latest@sha256:7b848083f93822dd21b0a2f14a110bd99f6efb4b838d499df6d04a49d0debf8b
Args: ping ityouknow.com
Resources:
Endpoint Mode: vip运行
docker service inspect helloworld查询服务详细信息。
运行 docker service ps <SERVICE-ID> 查看那个节点正在运行服务:
docker@manager1:~$ docker service ps helloworld
NAME IMAGE NODE DESIRED STATE LAST STATE
helloworld.1.8p1vev3fq5zm0mi8g0as41w35 alpine worker1 Running Running 3 minutes在工作节点查看任务的执行情况
docker-machine ssh worker1在节点执行 docker ps 查看容器的运行状态。
docker@worker1:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
96bf5b1d8010 alpine:latest "ping ityouknow.com" 4 minutes ago Up 4 minutes helloworld.1.rgroe3s9qa53lf4u4ky0tzcb8这样的话,我们在 Swarm 集群中成功的运行了一个 helloworld 服务,根据命令可以看出在 worker1 节点上运行。
弹性伸缩实验
我们来做一组实验来感受 Swarm 强大的动态水平扩展特性,首先动态调整服务实例个数。
调整实例个数
增加或者减少服务的节点数
调整 helloworld 的服务实例数为 2 个
docker service update --replicas 2 helloworld查看那个节点正在运行服务:
docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
rgroe3s9qa53 helloworld.1 alpine:latest manager1 Running Running 8 minutes ago
a61nqrmfhyrl helloworld.2 alpine:latest worker2 Running Running 9 seconds ago调整 helloworld 的服务实例数为 1 个
docker service update --replicas 1 helloworld再次查看节点运行情况:
docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
a61nqrmfhyrl helloworld.2 alpine:latest worker2 Running Running about a minute ago再次调整 helloworld 的服务实例数为 3 个
docker service update --replicas 3 helloworld
helloworld
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged查看节点运行情况:
docker@manager1:~$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
mh7ipjn74o0d helloworld.1 alpine:latest worker2 Running Running 40 seconds ago
1w4p9okvz0xw helloworld.2 alpine:latest manager1 Running Running 2 minutes ago
snqrbnh4k94y helloworld.3 alpine:latest worker1 Running Running 32 seconds ago删除集群服务
docker service rm helloworld调整集群大小
动态调整 Swarm 集群的工作节点。
添加集群
创建虚拟主机 worker3
$ docker-machine create -d virtualbox worker3入虚拟主机 worker3
$ docker-machine ssh worker3加入 swarm 集群
docker@worker3:~$ docker swarm join \
--token SWMTKN-1-47z6jld2o465z30dl7pie2kqe4oyug4fxdtbgkfjqgybsy4esl-8r55lxhxs7ozfil45gedd5b8a \
192.168.99.100:2377
This node joined a swarm as a worker. 退出虚拟主机
docker@worker3:~$exit 在主节点上面执行 docker node ls 查询集群主机信息
登录主节点
docker-machine ssh manager1查看集群节点
docker@manager1:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
j0o7sykkvi86xpc00w71ew5b6 * manager1 Ready Active Leader
xwv8aixasqraxwwpox0d0bp2i worker1 Ready Active
ij3z1edgj7nsqvl8jgqelrfvy worker2 Ready Active
i31yuluyqdboyl6aq8h9nk2t5 worker3 Ready Active可以看出集群节点多了 worker3
退出 Swarm 集群
如果 Manager 想要退出 Swarm 集群, 在 Manager Node 上执行如下命令:
docker swarm leave 就可以退出集群,如果集群中还存在其它的 Worker Node,还希望 Manager 退出集群,则加上一个强制选项,命令行如下所示:
docker swarm leave --force在 Worker2 上进行退出测试,登录 worker2 节点
docker-machine ssh worker2执行退出命令
docker swarm leave 查看集群节点情况:
docker@manager1:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
j0o7sykkvi86xpc00w71ew5b6 * manager1 Ready Active Leader
xwv8aixasqraxwwpox0d0bp2i worker1 Ready Active
ij3z1edgj7nsqvl8jgqelrfvy worker2 Down Active
i31yuluyqdboyl6aq8h9nk2t5 worker3 Ready Active可以看出集群节点 worker2 状态已经下线
也可以再次加入
docker@worker2:~$ docker swarm join \
> --token SWMTKN-1-47z6jld2o465z30dl7pie2kqe4oyug4fxdtbgkfjqgybsy4esl-8r55lxhxs7ozfil45gedd5b8a \
> 192.168.99.100:2377
This node joined a swarm as a worker.再次查看
docker@manager1:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
j0o7sykkvi86xpc00w71ew5b6 * manager1 Ready Active Leader
xwv8aixasqraxwwpox0d0bp2i worker1 Ready Active
0agpph1vtylm421rhnx555kkc worker2 Ready Active
ij3z1edgj7nsqvl8jgqelrfvy worker2 Down Active
i31yuluyqdboyl6aq8h9nk2t5 worker3 Ready Active可以看出集群节点 worker2 又重新加入到了集群中
重新搭建命令
使用 VirtualBox 做测试的时候,如果想重复实验可以将实验节点删掉再重来。
//停止虚拟机
docker-machine stop [arg...] //一个或多个虚拟机名称
docker-machine stop manager1 worker1 worker2//移除虚拟机
docker-machine rm [OPTIONS] [arg...]
docker-machine rm manager1 worker1 worker2停止、删除虚拟主机后,再重新创建即可。
总结
通过对 Swarm 的学习,强烈感觉到自动化水平扩展的魅力,这样在公司流量爆发的时候,只需要执行一个命令就可以完成实例上线。如果再根据公司的业务流量做自动化控制,那就真正实现了完全自动的动态伸缩。
举个例子,我们可以利用脚本监控公司的业务流量,当流量是某个级别的时候我们启动对应的 N 个节点数,当流量减少的时候我们也动态的减少服务实例个数,既可以节省公司资源,也不用操心业务爆发被流量击垮。Docker 能发展的这么好还是有原因的,容器化是 DevOps 最重要的一个环节,未来容器化的技术会越来越丰富和完善,智能化运维可期待。

35. docker swarm dockerStack 部署 投票应用
1. 编写 docker-compose.yml
# docker-compose.yml
version: "3"
services:
redis:
image: redis:alpine
ports:
- "6379"
networks:
- frontend
deploy:
replicas: 2
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
db:
image: postgres:9.4
volumes:
- db-data:/var/lib/postgresql/data
networks:
- backend
deploy:
placement:
constraints: [node.role == manager]
vote:
image: dockersamples/examplevotingapp_vote:before
ports:
- 5000:80
networks:
- frontend
depends_on:
- redis
deploy:
replicas: 2
update_config:
parallelism: 2
restart_policy:
condition: on-failure
result:
image: dockersamples/examplevotingapp_result:before
ports:
- 5001:80
networks:
- backend
depends_on:
- db
deploy:
replicas: 1
update_config:
parallelism: 2
delay: 10s
restart_policy:
condition: on-failure
worker:
image: dockersamples/examplevotingapp_worker
networks:
- frontend
- backend
deploy:
mode: replicated
replicas: 1
labels: [APP=VOTING]
restart_policy:
condition: on-failure
delay: 10s
max_attempts: 3
window: 120s
placement:
constraints: [node.role == manager]
visualizer:
image: dockersamples/visualizer:stable
ports:
- "8080:8080"
stop_grace_period: 1m30s
volumes:
- "/var/run/docker.sock:/var/run/docker.sock"
deploy:
placement:
constraints: [node.role == manager]
networks:
frontend:
backend:
volumes:
db-data:
2. 启动 service 并 查看 service 的状态
docker stack deploy vote -c=docker-compose.yml
docker stack ls
docker stack services vote

docker stack ps vote
3. 对 vote_vote service 进行拓展
docker service stack scale vote_vote=3
4. 访问
访问 192.168.205.10:5000 进行投票
访问 192.168.205.10:5001 查看投票情况
访问 192.168.205.10:8080 查看容器 部署情况

37. docker swarm docker service 的更新
在 service 运行的情况下 进行更新
1. 创建 名为 demo 的 overlay 网络
docker network create -d overlay demo
2. 创建 python-flask-demo:1.0 服务
映射 本地的 8080 端口 到 容器的 5000 端口
docker service create --name web --publish 8080:5000 --network demo xiaopeng163/python-flask-demo:1.0
3. 查看运行的服务器
docker service ps web
4. 横向拓展 web 应用
docker service scale web=2
5. shell 循环请求 web
sh -c "while true;do curl 127.0.0.1:8080 && sleep 1; done"
6. 更新 service image
docker service update --image xiaopeng163/python-flask-demo:2.0 web
7. 查看容器详情
docker service ps web
8. 更新 service 端口映射 将 外部访问端口 8080 变换 8888
docker service update --publish-rm 8080:5000 --publish-add 8888:5000 web
9. docker-compose 文件更新
docker stack deploy wordpress -c=docker-compose.yml
-Docker Swarm 集群部署")
Docker (二十一)-Docker Swarm 集群部署
介绍
Swarm 在 Docker 1.12 版本之前属于一个独立的项目,在 Docker 1.12 版本发布之后,该项目合并到了 Docker 中,成为 Docker 的一个子命令。目前,Swarm 是 Docker 社区提供的唯一一个原生支持 Docker 集群管理的工具。它可以把多个 Docker 主机组成的系统转换为单一的虚拟 Docker 主机,使得容器可以组成跨主机的子网网络。
Swarm 是目前 Docker 官方唯一指定(绑定)的集群管理工具。Docker 1.12 内嵌了 swarm mode 集群管理模式。
Swarm 关键概念
1)Swarm
集群的管理和编排是使用嵌入到 docker 引擎的 SwarmKit,可以在 docker 初始化时启动 swarm 模式或者加入已存在的 swarm
2)Node
一个节点 (node) 是已加入到 swarm 的 Docker 引擎的实例 当部署应用到集群,你将会提交服务定义到管理节点,接着 Manager
管理节点调度任务到 worker 节点,manager 节点还执行维护集群的状态的编排和群集管理功能,worker 节点接收并执行来自
manager 节点的任务。通常,manager 节点也可以是 worker 节点,worker 节点会报告当前状态给 manager 节点
3)服务(Service)
服务是要在 worker 节点上要执行任务的定义,它在工作者节点上执行,当你创建服务的时,你需要指定容器镜像
4)任务(Task)
任务是在 docekr 容器中执行的命令,Manager 节点根据指定数量的任务副本分配任务给 worker 节点
docker swarm:集群管理,子命令有 init, join, leave, update。(docker swarm –help 查看帮助)
docker service:服务创建,子命令有 create, inspect, update, remove, tasks。(docker service–help 查看帮助)
docker node:节点管理,子命令有 accept, promote, demote, inspect, update, tasks, ls, rm。(docker node –help 查看帮助)
node 是加入到 swarm 集群中的一个 docker 引擎实体,可以在一台物理机上运行多个 node,node 分为:manager nodes 管理节点,worker nodes 工作节点。
一、系统环境
1)服务器环境
| 节点名称 | IP | 操作系统 | 内核版本 |
| manager | 172.16.60.95 | CentOs7 | 4.16.1-1.el7.elrepo.x86_64 |
| node-01 | 172.16.60.96 | CentOs7 | 4.16.1-1.el7.elrepo.x86_64 |
| node-02 | 172.16.60.97 | CentOs7 | 4.16.1-1.el7.elrepo.x86_64 |
| node-03 | 172.16.60.98 | CentOs7 | 4.16.1-1.el7.elrepo.x86_64 |
2)前提条件
- Docker 版本 1.12+
- 集群节点之间保证 TCP 2377、TCP/UDP 7946 和 UDP 4789 端口通信
TCP 端口 2377 集群管理端口
TCP 与 UDP 端口 7946 节点之间通讯端口
TCP 与 UDP 端口 4789 overlay 网络通讯端口
二、集群部署
1)master 创建 Swarm(要保存初始化后 token,因为在节点加入时要使用 token 作为通讯的密钥)
|
1
2
3
4
5
6
7
8
|
[root@master ~]
# docker swarm init --advertise-addr 172.16.60.95
Swarm initialized: current node (kfi2r4dw6895z5yvhlbyzfck6)
is
now a manager.
To add a worker to this swarm, run the following command:
docker swarm join
-
-
token SWMTKN
-
1
-
3fzyz5knfbhw9iqlzxhb6dmzdtr0izno9nr7iqc5wid09uglh8
-
0mocmawzvm3xge6s37n5a48fw
172.16
.
60.95
:
2377
To add a manager to this swarm, run
''docker swarm join-token manager''
and
follow the instructions.
|
注:上面命令执行后,该机器自动加入到 swarm 集群。这个会创建一个集群 token,获取全球唯一的 token,作为集群唯一标识。后续将其他节点加入集群都会用到这个 token 值。 其中,--advertise-addr 参数表示其它 swarm 中的 worker 节点使用此 ip 地址与 manager 联系。命令的输出包含了其它节点如何加入集群的命令。
使用 docker info 或者 docker node ls 查看集群中的相关信息
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
docker info
.......
Swarm: active
NodeID: kfi2r4dw6895z5yvhlbyzfck6
Is Manager: true
ClusterID: y2zgs373cg0y6559t675yexcj
Managers:
1
Nodes:
1
Orchestration:
Task History Retention Limit:
5
.......
|
2)添加节点到 swarm 集群中
所有节点执行
|
1
|
docker swarm join
-
-
token SWMTKN
-
1
-
3fzyz5knfbhw9iqlzxhb6dmzdtr0izno9nr7iqc5wid09uglh8
-
0mocmawzvm3xge6s37n5a48fw
172.16
.
60.95
:
2377
|
在 master 上查看集群节点的状态

到此 Swarm 集群就创建好了
3)docker node 命令
[root@master ~]# docker node --help
Usage: docker node COMMAND
Manage Swarm nodes
Options:
Commands:
demote Demote one or more nodes from manager in the swarm
inspect Display detailed information on one or more nodes
ls List nodes in the swarm
promote Promote one or more nodes to manager in the swarm
ps List tasks running on one or more nodes, defaults to current node
rm Remove one or more nodes from the swarm
update Update a node
# demote
将管理节点降级为普通节点
# inspect
查看节点的详细信息
# ls
列出节点
# promote
将普通节点升级为管理节点
# ps
查看运行的任务
# rm
从swarm集群中删除节点
# update
改变集群节点状态[root@master ~]# docker node update --help
Usage: docker node update [OPTIONS] NODE
Update a node
Options:
--availability string Availability of the node ("active"|"pause"|"drain")
--label-add list Add or update a node label (key=value)
--label-rm list Remove a node label if exists
--role string Role of the node ("worker"|"manager")
# 主要使用availability string
# active
节点状态正常
# pause
节点挂起、暂停
# drain
排除节点,比如将master节点排除,不分配任务,只作为管理节点三、在 Swarm 中部署服务
1) 创建服务
[root@master ~]# docker service --help
Usage: docker service COMMAND
Manage services
Options:
Commands:
create Create a new service
inspect Display detailed information on one or more services
logs Fetch the logs of a service or task
ls List services
ps List the tasks of one or more services
rm Remove one or more services
rollback Revert changes to a service''s configuration
scale Scale one or multiple replicated service |
1
2
3
4
5
|
[root@master ~]
# docker service create --replicas 1 --name hello busybox
# --replicas : 副本集个数
# --name:服务名称
|
2)查看服务信息
|
1
2
3
|
[root@master ~]
# docker service ls
ID
NAME MODE REPLICAS IMAGE PORTS
kosznwn4ombx hello replicated
0
/
1
busybox:latest
|
从 REPLICAS 中能看出这个 hello 服务并没有启动起来,0/1 表示 1 计划启动的副本数,0 实际启动的数量。所以启动失败

3)添加参数
在 hello 服务中 busybox 只是一个基础镜像,并没有一个持续运行的任务,所以 manager 会不断重启 hello 这个服务,所以有好多 shutdown 的记录。但是可以为其添加一个任务。
|
1
2
3
4
5
6
7
8
9
10
|
[root@master ~]
# docker service update --args "ping www.baidu.com" hello
hello
overall progress:
1
out of
1
tasks
1
/
1
: running [
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
>]
verify: Service converged
# update:更新状态
# --args:增加参数
|
再次查看状态:
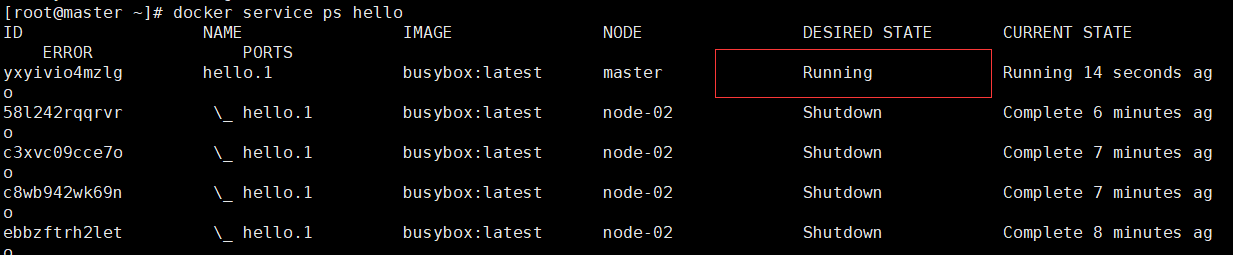
过滤不正常的状态:
|
1
2
3
4
5
6
|
[root@master ~]
# docker service ps -f "desired-state=running" hello
ID
NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
yxyivio4mzlg hello.
1
busybox:latest master Running Running
4
minutes ago
# -f "desired-state=running" : 状态为runngin的服务
|
4)为服务扩容(缩融)scale
刚才设置的 replicas=1,可以增加副本数量
|
1
2
3
4
5
6
7
8
9
10
11
12
|
[root@master ~]
# docker service scale hello=4
hello scaled to
4
overall progress:
4
out of
4
tasks
1
/
4
: running
2
/
4
: running
3
/
4
: running
4
/
4
: running
verify: Service converged
# scale : 指定服务的数量
|

5)工作节点排除 manager,manager 只作为管理节点
上图中 manager 也运行了一个服务,将 manager 排除在外
|
1
2
3
4
5
6
7
8
9
|
[root@manager ~]
# docker node update --availability drain manager
# node update : 更改节点状态
# --availability : 三种状态
active: 正常
pause:挂起
drain:排除
|
排除 manager 后,其上面运行的服务会转移到其他节点

四、滚动更新服务
例如升级服务的镜像版本
|
1
2
3
4
5
6
7
8
9
10
|
[root@manager ~]
# docker service create \
>
-
-
replicas
3
\
>
-
-
name redis \
>
-
-
update
-
delay
10s
\
> redis:
3.0
.
6
# 启动3个副本集的redis
# update-delay 10s :每个容器依次更新,间隔10s
|
滚动更新:
|
1
2
3
|
docker service update
-
-
image redis:
3.0
.
7
redis
# --image : 指定版本
|
更新完成后新版本和历史记录都能查看
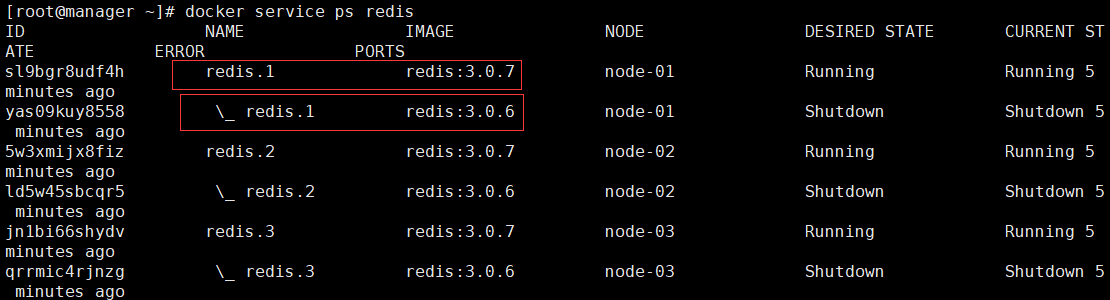
查看配置信息:
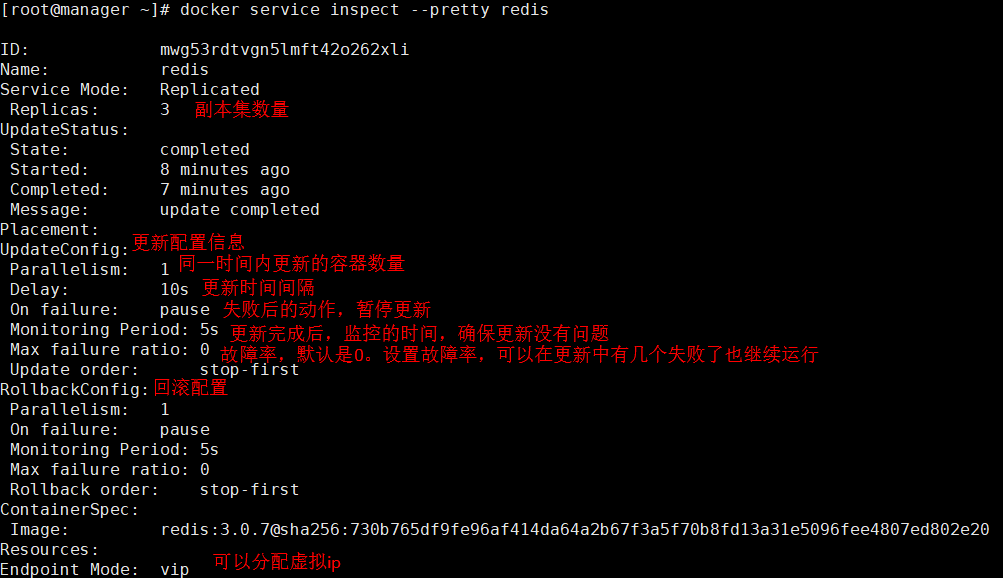
五、服务更新和回滚策略
1)设置策略
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
[root@manager ~]
# docker service create \
-
-
name my
-
web \
-
-
replicas
10
\
-
-
update
-
delay
10s
\
-
-
update
-
parallelism
2
\
-
-
update
-
failure
-
action
continue
\
-
-
rollback
-
parallelism
2
\
-
-
rollback
-
monitor
20s
\
-
-
rollback
-
max
-
failure
-
ratio
0.2
\
nginx:
1.12
.
1
# --update-parallelism 2 : 每次允许两个服务一起更新
#--update-failure-action continue : 更新失败后的动作是继续
# --rollback-parallelism 2 : 回滚时允许两个一起
# --rollback-monitor 20s :回滚监控时间20s
# --rollback-max-failure-ratio 0.2 : 回滚失败率20%
|
如果执行后查看状态不是设置的,可以在 update 一下,将服务状态设置为自己想要的
|
1
2
3
4
5
|
docker service update
-
-
rollback
-
monitor
20s
my
-
web
docker service update
-
-
rollback
-
max
-
failure
-
ratio
0.2
my
-
web
# 有两个地方设置数值没有成功,手动设置
|
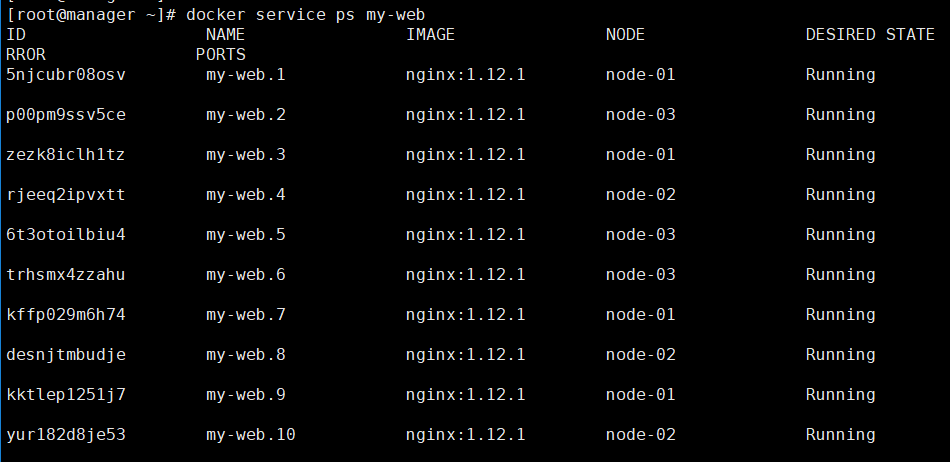
查看状态:

2)服务更新
|
1
|
[root@manager ~]
# docker service update --image nginx:1.13.5 my-web
|
和上述策略一致,两两更新
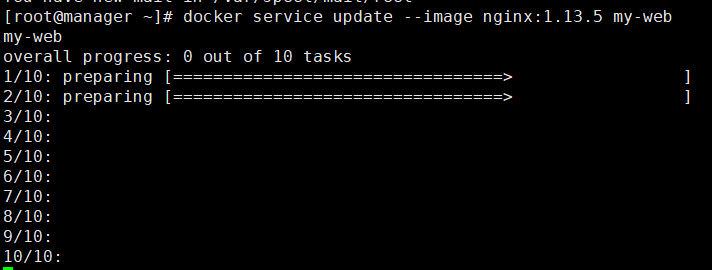
更新完成:
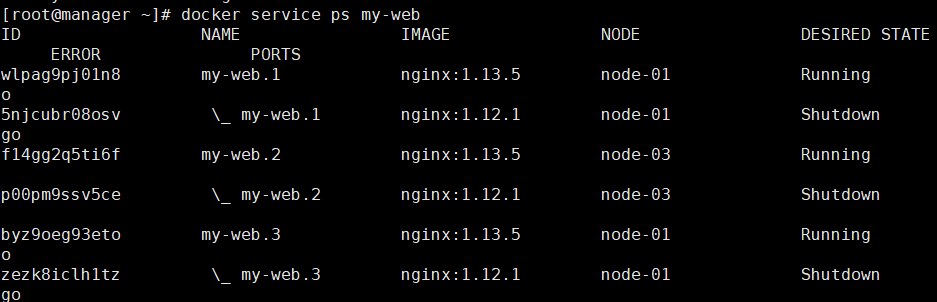
3)手动回滚(策略是失败会回滚,现在没有失败)
刚才 nginx 版本已经是 1.13.5 了,现在将其还原到 1.12.1
|
1
|
[root@manager ~]
# docker service update --rollback my-web
|
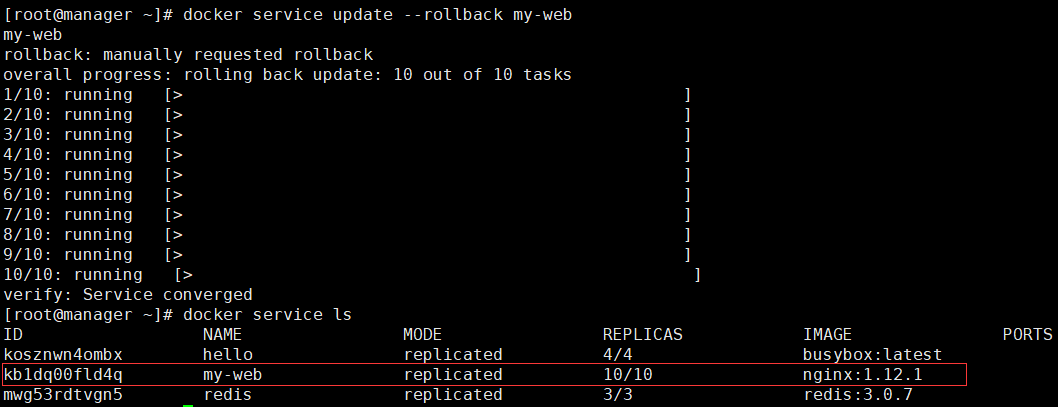
手动回滚成功

Docker 1.12 以前的: swarm 搭建 docker 集群
什么是 Swarm
Swarm 是 Docker 公司在 2014 年 12 月初发布的一套较为简单的工具,用来管理 Docker 集群,它将一群 Docker 宿主机变成一个单一的,虚拟的主机。Swarm 使用标准的 Docker API 接口作为其前端访问入口,换言之,各种形式的 Docker Client (docker client in go, docker_py, docker 等) 均可以直接与 Swarm 通信。Swarm 几乎全部用 Go 语言来完成开发,上周五,4 月 17 号,Swarm0.2 发布,相比 0.1 版本,0.2 版本增加了一个新的策略来调度集群中的容器,使得在可用的节点上传播它们,以及支持更多的 Docker 命令以及集群驱动。
Swarm deamon 只是一个调度器(Scheduler)加路由器 (router),Swarm 自己不运行容器,它只是接受 docker 客户端发送过来的请求,调度适合的节点来运行容器,这意味着,即使 Swarm 由于某些原因挂掉了,集群中的节点也会照常运行,当 Swarm 重新恢复运行之后,它会收集重建集群信息。下面是 Swarm 的结构图: 
能干什么
- 搭建一个 dockers 集群
怎么玩
- 安装 env :A,B,C 三台机 ,A 将作管理机,centos 系统 ,root 用户 每一台机执行:
sudo docker pull swarm - 修改 docker 配置文件 sudo vi /etc/sysconfig/docker 在文件的最后面添加下面这句 DOCKER_OPTS="-H 0.0.0.0:2375 –H unix:///var/run/docker.sock"
- 重启 dockers sudo service docker restart
- 使用令牌来发现
- 使用 DOCKHUB 来建立 任意一台,执行下面的命令 sudo docker run --rm swarm create 这里会产生一个令牌 ,假设为 1111
- swarm join 命令,把机器加入集群。 A,B,C: sudo docker run -d swarm join –addr=A:2375 token://1111
- swarm manager
A: sudo docker run –d –p 2376:2375 swarm manage token://1111- 首先要以 daemon 的形式运行 swarm;
- 其次端口映射:2376 可以更换成任何一个本机没有占用的端口,一定不能是 2375,否则就会出问题
- swarm list
A,b,c:docker run --rm swarm list token://1111
引用:Docker 学习教程
关于docker 1-->docker swarm 转载和docker 转移的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于35. docker swarm dockerStack 部署 投票应用、37. docker swarm docker service 的更新、Docker (二十一)-Docker Swarm 集群部署、Docker 1.12 以前的: swarm 搭建 docker 集群等相关知识的信息别忘了在本站进行查找喔。
本文标签:




