在这篇文章中,我们将带领您了解Wildcard与RegularExpression的区别的全貌,包括wilderness和wild的相关情况。同时,我们还将为您介绍有关10.RegularExpres
在这篇文章中,我们将带领您了解Wildcard与Regular Expression的区别的全貌,包括wilderness和wild的相关情况。同时,我们还将为您介绍有关10. Regular Expression Matching(hard)、About Regular Expression、Expresso - A Tool for Building and Testing Regular Expressions、IOS中NSPredicate和NSRegularExpression校验正则表达式区别的知识,以帮助您更好地理解这个主题。
本文目录一览:- Wildcard与Regular Expression的区别(wilderness和wild)
- 10. Regular Expression Matching(hard)
- About Regular Expression
- Expresso - A Tool for Building and Testing Regular Expressions
- IOS中NSPredicate和NSRegularExpression校验正则表达式区别
")
Wildcard与Regular Expression的区别(wilderness和wild)
转载自 Shell十三问:http://wiki.jikexueyuan.com/project/13-questions-of-shell/wildcard.html
题目:[^ ] 跟[! ]差在哪? (wildcard)
这个题目说穿了, 就是要探讨Wildcard与Regular Expression的差别的。 这也是很多初学shell的朋友很容易混淆的地方。
首先,让我们回到十三问之第2问, 再一次将我们提到的command line format 温习一次:
command_nameoptionsarguments
同时,也再来理解一下,我在第5章所提到的变量替换的特性:
先替换,再重组commandline!
有了这个两个基础后,再让我们来看Wildcard是什么回事吧。
Part-I Wildcard (通配符)
首先,
`Wildcard`也是属于`commandline`的处理工序,作用于`arguments`里的`path`之上。
没错,它不用在command_name,也不用在options上。 而且,若argument不是path的话,那也与wildcard无关。
换句更为精确的定义来讲,
`wildcard`是一种命令行的路径扩展(pathexpansion)功能。
提到这个扩展,那就不要忘了 command line的“重组”特性了!
是的,这与变量替换(variable subtitution)及命令替换(command substitution)的重组特性是一样的。
也就是在wildcard进行扩展后, 命令行会先完成重组,才会交给shell来处理。
了解了wildcard的扩展与重组特性后, 接下来,让我们了解一些常见的wildcard吧。
| wildcard | 功能 |
|---|---|
| * | 匹配0个或多个字符 |
| ? | 匹配任意单一字符 |
| [list] | 匹配list中任意单一字符 |
| [!list] | 匹配不在list中任意单一字符 |
| {string1,string2,...} | 匹配string1或者stsring2或者(...)中其一字符串 |
Note: list 中可以指定单个字符,如abcd,也可以指定ASCII字符的起止范围,如 a-d。 即[abcd] 与 [a-d] 是等价的,称为一个自定义的字符类。
例如:
a*b#a与b之间可以有任意个字符(0个或多个),如aabcb,axyzb,a012b,ab等。
a?b#a与b之间只能有一个字符,但该字符可以任意字符,如aab,abb,acb,azb等。
a[xyz]b#a与b之间只能有一个字符,但这个字符只能是x或者y或者z,如:axb,ayb,azb这三个。
a[!0-9]b#a与b之间只能有一个字符,但这个字符不能是阿拉伯数字,如aab,ayb,a-b等。
a{abc,xyz,123}b#a与b之间只能是abc或者xyz或者123这三个字串之一,扩展后是aabcb,axyzb,a123b。
[! ]中的!只有放在第一位时,才有取反的功效。 eg:[!a]*表示当前目录下不以a开头的路径名称;/tmp/[a\!]*表示/tmp目录下所有以a 或者 ! 开头的路径名称;思考:为何!前面要加\呢?提示是十三问之4.
[ - ]中
-左右两边均有字符时,才表示一个范围,否则,仅作-(减号)字符来处理。 举例:/tmp/*[-z]/[a-zA-Z]*表示/tmp 目录下所有以z或者-结尾的子目录中, 以英文字母(不分大小写)开头的目录名称。以*或?开头的wildcard不能匹配隐藏文件(即以.开头的文件名)。 eg:
*.txt并不能匹配.txt但能匹配1.txt这样的路径名。 但1*txt及1?txt均可匹配1.txt这样的路径名。
基本上,要掌握wildcard并不难, 只要多加练习,再勤于思考,就能灵活运用了。
再次提醒:
别忘了wildcard的"扩展"+"重组"这个重要特性,而且只作用在argument的path上。
比方说, 假如当前目录下有: a.txt b.txt c.txt 1.txt 2.txt 3.txt 这几个文件。
当我们在命令行中执行ls -l [0-9].txt的命令行时, 因为wildcard处于argument的位置上,
于是根据匹配的路径,扩展为: 1.txt 2.txt 3.txt, 在重组出ls -l 1.txt 2.txt 3.txt这样的命令行。
因此,你在命令行上敲ls -l [0-9].txt与ls -l 1.txt 2.txt 3.txt输出的结果是一样, 原因就是在于此。
Part-II Regular Expression (正则表达式)
接下来的Regular Expression(RE) 可是个大题目,要讲的很多。 我这里当然不可能讲得很全。 只希望能带给大家一个基本的入门概念,就很足够了...
先来考一下英文好了:What is expression? 简单来说,就是"表达",也就是人们在沟通的时候所要陈述的内容。
然而,生活中,表达方要清楚的将意思描述清楚, 而让接收方完整无误地领会,可不是件容易的事情。
因而才会出现那么多的"误会",真可叹句"表达不易"啊......
同样的情形也发生在计算机的数据处理过程中, 尤其是当我们在描述一段"文字内容"的时候.... 那么,我们不禁要问: 有何方法可以让大家的误会降至最低程度, 而让表达的精确度达到最高程度呢? 答案就是"标准化"了, 也就是我们这里要谈的Regular Expression啦...^_^
然而,在进入RE介绍之前,不妨先让我们温习一下shell十三问之第4问, 那就是关于quoting的部分。
关键是要能够区分 shell command line上的Meta与literal的这两种不同的字符类型。
然后,我这里也跟你讲:RE 表达式里字符也分Meta与literal这两种。
呵,不知亲爱的读者是否被我搞混乱了呢?... ^_^
这也难怪啦,因为这的确是最容易混淆的地方, 刚学RE的朋友很多时候,都死在这里! 因此,请特别小心理解哦...
简单而言,除非你将RE写在特定程序使用的脚本里, 否则,我们的RE也是通过 command line输入的。 然而,不少RE所使用的Meta字符,跟shell 的Meta字符是冲突的。
比方说, *``这个字符,在RE里是一个modifier(修饰符);而在command line上,确是wildcard(通配符)**。
那么,我们该如何解决这样的冲突呢? 关键就是看你对shell十三问的第4问中所提的quoting是否足够理解了!
若你明白到shell quoting 就是用来在command line上关闭shell Meta这一基本原理, 那你就能很轻松的解决 RE Meta与shell Meta的冲突问题了:用shell quoting 关闭掉shell Meta就是了。 就这么简单... ^_^
再以刚提到*字符为例, 若在command line的path中没有quoting处理的话, 如abc* 就会被作为wildcard expression来扩充及重组了。 若将其置于quoting中,即"abc*",则可以避免wildcard expand的处理。
好了,说了大半天,还没有进入正式的RE介绍呢.... 大家别急,因为我的教学风格就是要先建立基础,循序渐进的... ^_^ 因此,我这里还要再��嗦一个观念,才会到RE的说明啦...(哈...别打我...)
当我们在谈到RE时,千万别跟wildcard搞混在一起! 尤其是
在commandline的位置里,wildcard只作用于argument的path上; 而RE却只用于"字符串处理"的程序中,这与路径名一点关系也没有。
Tips:RE 所处理的字符串,通常是指纯文本或通过stdin读进的内容。
okay,够了够了,我已看到一堆人开始出现不耐烦的样子了... ^_^ 现在,就让我们登堂入室,揭开RE的神秘面纱吧, 这样可以放过我了吧? 哈哈...
在RE的表达式里,主要分为两种字符:literal与Meta。 所谓literal就是在RE里不具有特殊功能的字符,如abc,123等; 而Meta,在RE里具有特殊的功能。 要关闭之,需要在Meta之前使用escape()转义字符。
然而,在介绍Meta之前,先让我们来认识一下字符组合(character set)会更好些。
一、所谓的char set就是将多个连续的字符作为一个集合。 例如:
char set| 意义 | |
|---|---|
| abc | 表示abc三个连续的字符,但彼此独立而非集合。(可简单视为三个char set) |
| (abc) | 表示abc这三个连续字符的集合。(可简单视为一个char set) |
| abc|xyz | 表示abc或xyz这两个char set之一 |
| [abc] | 表示单一字符,可为a或b或c;与wildcard的[abc]原理相同,称之为字符类。 |
| [^abc] | 表示单一字符,不为a或b或c即可。(与wildcard [!abc]原理相同) |
| . | 表示任意单个字符,(与wildcard的?原理相同) |
note: abc|xyz 表示abc或xyz这两个char set之一
在认识了RE的char set这个概念之后,然后,在让我们多认识几个RE中常见的Meta字符:
二、 锚点(anchor): 用以标识RE在句子中的位置所在。 常见的有:
锚点| 说明 | |
|---|---|
| ^ | 表示句首。如,^abc表示以abc开头的句子。 |
| $ | 表示句尾。如,abc$表示以abc结尾的句子。 |
| \< | 表示词首。如,\<abc表示以abc开头的词。 |
| \> | 表示词尾。如,abc\>表示以abc结尾的词。 |
三、 修饰符(modifier):独立表示时本身不具意义,专门用以修饰前一个char set出现的次数。 常见的有:
modifier表示前一个char set至少出现n次,至多出现m次。如ab{n,m}c 表示a与c之间至少有n个b,至多有m个b。| * | 表示前一个char set出现0次或多次,即任意次。如ab*c表示a与c之间可以有0个或多个b。 | |
| ? | 表示前一个char set出现0次或1次,即至多出现1次。如ab?c 表示a与c之间可以有0个或1个b。 | |
| + | 表示前一个char set出现1次或多次,即至少出现1次。如ab+c 表示a与c之间可以有1个或多个b。 | |
| {n} | 表示前一个char set出现n次。如ab{n}c 表示a与c之间可以有n个b。 | |
| {n,} | 表示前一个char set至少出现n次。如ab{n}c 表示a与c之间至少有n个b。 |
然而,当我们在识别modifier时,却很容易忽略"边界(boundary)字符"的重要性。
以ab{3,5}c为例,这里的a与c就是边界字符了。 若没有边界字符的帮忙,我们很容易做出错误的解读。 比方说: 我们用
同样,我们用b{3,5}c也同样可以抓到"abbbbbbbbbbc" 这样的字符串。
但当我们用
x* ax*,abx*,ax*b abcx*,abx*c,ax*bc bx*c,bcx*,x*bc
但,若我们在这些RE前后分别加^与$这样的anchor,那又如何呢?
刚学RE时,只要能掌握上面这些基本的Meta的大概就可以入门了。 一如前述,RE是一种规范化的文字表达式, 主要用于某些文字处理工具之间,如: grep, perl, vi,awk,sed,等等, 常用于表示一段连续的字符串,查找和替换。
然而每种工具对RE表达式的具体解读或有一些细微差别, 不过节本原理还是一致的。 只要掌握RE的基本原理,那就一理通百理了, 只是在实践时,稍加变通即可。
比方以grep来说, 在Linux上,你可以找到grep,egrep,fgrep这些程序, 其差异大致如下:
grep: 传统的grep程序,在没有任何选项(options)的情况下,只输出符合RE字串的句子, 其常见的选项如下:
选项 (option)| 用途 | |
|---|---|
| -v | 反模式, 只输出“不含”RE的字符串的行。 |
| -r | 递归模式,可同时处理所有层级的子目录里的文件 |
| -q | 静默模式,不输出任何结果(stderr 除外,常用于获取return value,符合为true,否则,为false. |
| -i | 忽略大小写 |
| -w | 整词匹配,类似 \<RE> |
| -n | 同时输出行号 |
| -l | 输出匹配RE的文件名 |
| -o | 只输出匹配RE的字符串。(gnu新版独有,不见得所有版本支持) |
| -E | 切换为egrep |
egrep:为grep的扩充版本,改良了许多传统grep不能或者不便的操作,
grep下不支持
?与+这两种Meta,但egrep支持;grep 不支持
a|b或(abc|xyz)这类“或一”的匹配,但egrep支持;grep 在处理
{n,m}时,需要\{ 与 \}处理,但egrep不需。
等诸如此类的。我个人建议能用egrep就不用grep啦...^_^
fgrep: 不作RE处理,表达式仅作一般的字符串处理,所有的Meta均市区功能。
好了,关于RE的入门,我们暂时就介绍到这里。 虽然有点乱,且有些观念也不恨精确, 不过,姑且算是对大家的一个交差吧...^_^ 若这两天有时间的话,我在举些范例来分析一下,以帮助大家更好的理解。 假如更有可能的话,也顺道为大家介绍一下sed这个工具。
Part-III eval
讲到command line的重组特性, 真的需要我们好好的加以解释的。
如此便能抽丝剥茧的一层层的将整个command line分析的 一清二楚,而不至于含糊。
假如这个重组的特性理解了,那我们介绍一个好玩的命令:eval.
我们在变量替换的过程中,常会碰到所谓的复式变量的问题: 如:
a=1 A1=abc
我们都知道echo $A1就可以得到abc的结果。 然而,我们能否用$A$a来取代$A1,而同一样替换为abc呢?
这个问题我们可用很轻松的用eval来解决:
evalecho\$A$a
说穿了,eval只不过是在命令行完成替换重组后, 在来一次替换重组罢了... 就是这么简单啦~~~ ^_^
")
10. Regular Expression Matching(hard)
10. Regular Expression Matching
题目
Implement regular expression matching with support for ''.'' and ''*''.
''.'' Matches any single character.
''*'' Matches zero or more of the preceding element.
The matching should cover the entire input string (not partial).
The function prototype should be:
bool isMatch(const char *s, const char *p)
Some examples:
isMatch("aa","a") → false
isMatch("aa","aa") → true
isMatch("aaa","aa") → false
isMatch("aa", "a*") → true
isMatch("aa", ".*") → true
isMatch("ab", ".*") → true
isMatch("aab", "c*a*b") → true
解析
- 动态规划的问题一直都是难点,需要找出状态转移方程!!!
如果“*”不好判断,那我大不了就来个暴力的算法,把“*”的所有可能性都测试一遍看是否有满足的,用两个指针i,j来表明当前s和p的字符。
我们采用从后往前匹配,为什么这么匹配,因为如果我们从前往后匹配,每个字符我们都得判断是否后面跟着“*”,而且还要考虑越界的问题。但是从后往前没这个问题,一旦遇到“*”,前面必然有个字符。
如果j遇到”*”,我们判断s[i] 和 p[j-1]是否相同,
如果相同我们可以先尝试匹配掉s的这个字符,i–,然后看之后能不能满足条件,满足条件,太棒了!我们就结束了,如果中间出现了一个不满足的情况,马上回溯到不匹配这个字符的状态。
不管相同不相同,都不匹配s的这个字符,j-=2 (跳过“*”前面的字符)
if(p[j-1] == ''.'' || p[j-1] == s[i])
if(myMatch(s,i-1,p,j))
return true;
return myMatch(s,i,p,j-2);
如果j遇到的不是“*”,那么我们就直接看s[i]和p[j]是否相等,不相等就说明错了,返回。
if(p[j] == ''.'' || p[j] == s[i])
return myMatch(s,i-1,p,j-1);
else return false;
再考虑退出的情况
如果j已经<0了说明p已经匹配完了,这时候,如果s匹配完了,说明正确,如果s没匹配完,说明错误。
如果i已经<0了说明s已经匹配完,这时候,s可以没匹配完,只要它还有”*”存在,我们继续执行代码。
// 10. Regular Expression Matching
class Solution_10 {
public:
/*
动态规划
如果 p[j] == str[i] || pattern[j] == ''.'', 此时dp[i][j] = dp[i-1][j-1];
如果 p[j] == ''*''
分两种情况:
1: 如果p[j-1] != str[i] && p[j-1] != ''.'', 此时dp[i][j] = dp[i][j-2] //*前面字符匹配0次
2: 如果p[j-1] == str[i] || p[j-1] == ''.''
此时dp[i][j] = dp[i][j-2] // *前面字符匹配0次
或者 dp[i][j] = dp[i][j-1] // *前面字符匹配1次
或者 dp[i][j] = dp[i-1][j] // *前面字符匹配多次
*/
bool isMatch(string s, string p) { //p去匹配s
vector<vector<bool> > dp(s.size() + 1, vector<bool>(p.size() + 1, false));
dp[0][0] = true; // 空串匹配空串
//第一列空串p去匹配,为false
//第一行非空串p去匹配空串s;只要p中有*,就可以匹配
for (int i = 1; i < dp[0].size(); i++)
{
if (p[i - 1] == ''*'')
{
dp[0][i] = i>1 && dp[0][i - 2];
}
}
for (int i = 1; i <= s.size();i++)
{
for (int j = 1; j <= p.size();j++)
{
if (s[i-1]==p[j-1]||p[j-1]==''.'') //直接匹配成功
{
dp[i][j] = dp[i - 1][j - 1];
}
else if (p[j-1]==''*'')
{
if (s[i-1]!=p[j-2]&&p[j-2]!=''.'') //匹配*前面的字符0次,跳过当前p
{
dp[i][j] = dp[i][j-2];
}
else
{
//*前面字符匹配1次 || *前面字符匹配0次 || *前面字符匹配多次
dp[i][j] = dp[i][j - 1] || dp[i][j - 2] || dp[i - 1][j];
}
}
}
}
return dp[s.size()][p.size()];
}
};
题目来源
- 《LeetBook》leetcode 题解 (10): Regular Expression Matching——DP 解决正则匹配
- 10. Regular Expression Matching

About Regular Expression
Regular Expression 使用规则
1、正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
2、给定一个正则表达式和另一个字符串,可以达到如下目的:
(1)给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”);
(2)可以通过正则表达式,从字符串中获取我们想要的特定部分。
3、正则表达式"testing"中没有包含任何元字符,它可以匹配"testing"和"testing123"等字符串,但是不能匹配"Testing"。
4、正则表达式是区分大小写的,如果要忽略大小写可使用方括号表达式“[]”。只要匹配的字符出现在方括号内,即可表示匹配成功。但要注意:一个方括号只能匹配一个字符。例如,要匹配的字串tm不区分大小写,那么该表达式应该写作如下格式:[Tt][Mm].
用正则表达式写出查找姓名,电话,邮件的表达式
name: var str = "My name is Linda";
var n = str.search(/Linda/i);
phone: var str= "My phone is 15152180476";
var n =str .search(/15152180476/i);
email: var str= "My email is [email protected]";
var n =str .search(/[email protected]/i);
引用自https://www.cnblogs.com/l69-l54/p/9846595.html

Expresso - A Tool for Building and Testing Regular Expressions
- Download Installation File - 88 Kb
- Download Source Code - 91 Kb
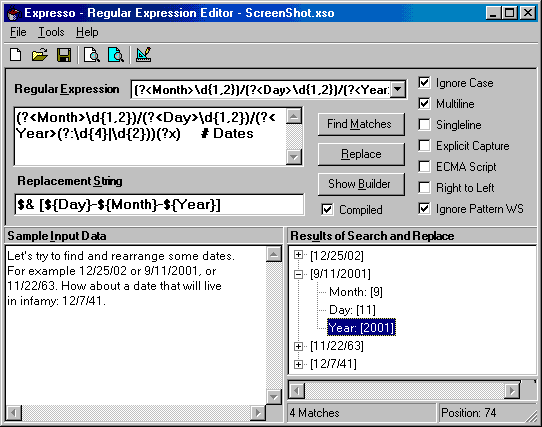
Introduction
The .NET framework provides a powerful class Regex for creating and using Regular Expressions. While regular expressions are a powerful way to parse, edit, and replace text, the complex syntax makes them hard to understand and prone to errors, even for the experienced user. When developing code that uses regular expressions, I have found it very helpful to create and debug my expressions in a separate tool to avoid time consuming compile/debug cycles. Expresso enables me to do the following:
-
Build complex regular expressions by selecting components from a palette
-
Test expressions against real or sample input data
-
Display all matches in a tree structure showing captured groups, and all captures within a group
-
Build replacement strings and test the match and replace functionality
-
Highlight matched text in the input data
-
Automatically test for syntax errors
-
Generate Visual Basic or C# code that can be incorporated directly into programs
-
Read or save regular expressions and input data
Background
Regular expressions are a sophisticated generalization of the "wildcard" syntax that users of Unix, MSDOS, Perl, AWK, and other systems are already familiar with. For example, in MSDOS, one can say:
dir *.exeto list all of the files with the exe extension. Here the asterisk is a wildcard that matches any character string and the period is a literal that matches only a period. For decades, much more complex systems have been used to great advantage whenever it is necessary to search text for complex patterns in order to extract or edit parts of that text. The .NET framework provides a class called Regex that can be used to do search and replace operations using regular expressions. In .NET, for example, suppose we want to find all the words in a text string. The expression \wwill match any alphanumeric character (and also the underscore). The asterisk character can be appended to \w to match an arbitrary number of repetitions of \w, thus \w* matches all words of arbitrary length that include only alphanumeric characters (and underscores).
Expresso provides a toolbox with which one can build regular expressions using a set of tab pages from which any of the syntactical elements can be selected. After building an expression, sample data can be read or entered manually, and the regular expression can be run against that data. The results of the search are then displayed, showing the hierarchy of named groups that Regex supports. The tool also allows testing of replacement strings and generation of code to be inserted directly into a C# or Visual Basic .NET program.
The purpose of this article is not to give a tutorial on the use of regular expressions, but rather to provide a tool for both experienced and novice users of regular expressions. Much of the complex behavior of regular expressions can be learned by experimenting with Expresso.
The reader may also find it helpful to explore some of the code within Expresso to see examples of the use of regular expressions and the Regexclass.
Using Expresso to Build and Test Regular Expressions on Sample Input Data
To use Expresso, download and run the executable file, which requires the .NET Framework. If you want to explore the code, download and extract the source files, open the solution within Visual Studio .NET, then compile and run the program. Expresso will start with sample data preloaded into the "Input Data" box (refer to the figure above). Create your own regular expression or select one of the examples from the list box. Click "Find Matches" to test the regular expression. The matches are shown in a tree structure in the "Results" box. Multiple groups and captures can be displayed by expanding the plus sign as shown above.
To begin experimenting with your own regular expressions, click the "Show Builder" button. It will display a set of tab pages as shown here:

In this example, the expression \P{IsGreek}{4,7}? has been generated by setting options that specify: match strings of four to seven characters, but with as few repetitions as possible, of any characters other than Greek letters. By clicking the "Insert" button, this expression will be inserted into the regular expression that is being constructed in the text box that contains the regular expression that will be used by the "FindMatch" or "Replace" buttons. Using the other tab pages, all of the syntactical elements of .NET regular expressions can be tested.
The Regex class supports a number of options such as ignoring the case of characters. These options can be specified using check boxes on the main form of the application.
Replacement strings may be built using the various expressions found on the "Substitutions" tab. To test a replacement pattern, enter a regular expression, a replacement string, some input data, and then click the "Replace" button. The output will be shown in the "Results" box.
Using Expresso to Generate Code
Once a regular expression has been thoroughly debugged, code can be generated by selecting the appropriate option in the "Code" menu. For example, to generate code for a regular expression to find dates, create the following regular expression (or select this example from the drop down list):
(?<Month>\d{1,2})/(?<Day>\d{1,2})/(?<Year>(?:\d{4}|\d{2}))By selecting the "Make C# Code" from the "Code" menu, the following code is generated. It can be saved to a file or cut and pasted into a C# program to create a Regex object that encapsulates this particular regular expression. Note that the regular expression itself and all the selected options are built into the constructor for the new object:
using System.Text.RegularExpressions;
Regex regex = new Regex(
@"(?<Month>\d{1,2})/(?<Day>\d{1,2})/(?<Yea"
+ @"r>(?:\d{4}|\d{2}))",
RegexOptions.IgnoreCase
| RegexOptions.Multiline
| RegexOptions.IgnorePatternWhitespace
| RegexOptions.Compiled
);Points of Interest
After creating this tool, I discovered the Regex Workbench by Eric Gunnerson, which was designed for the same purpose. Expresso provides more help in building expressions and gives a more readable display of matches (in my humble opinion), but Eric''s tool has a nice feature that shows Tooltips that decode the meaning of subexpressions within an expression. If you are serious about regular expressions, try both of these tools!
History
Original Version: 2/17/03
Version 1.0.1148: 2/22/03 - Added a few additional features including the ability to create an assembly file and registration of a new file type (*.xso) to support Expresso Project Files.
Version 1.0.1149: 2/23/03 - Added a toolbar.
My brother John doesn''t like the name Expresso, since he says too many people are already confused about the proper spelling and pronunciation of Espresso. Somehow, I doubt this program will have any impact on the declining literacy of America, but who knows. John prefers my earlier name "Mr. Mxyzptlk", after the Superman character with the unpronounceable name.
For the latest information on Expresso (if any), see http://www.ultrapico.com/ .
License
This article has no explicit license attached to it but may contain usage terms in the article text or the download files themselves. If in doubt please contact the author via the discussion board below.
A list of licenses authors might use can be found here
About the Author
| Jim Hollenhorst
Researcher
 United States United States
Member |
Ultrapico Website: http://www.ultrapico.com Download Expresso 3.0, the latest version of the award-winning regular expression development tool. |

IOS中NSPredicate和NSRegularExpression校验正则表达式区别
在代码开发过程中,我们经常需要用来校验邮箱、手机号等等,这个时候就需要用到正则表达式。在iOS开发中,能用来做正则校验的有两个 NSPredicate 和 NSRegularExpression 。
NSPredicate
NSPredicate 能用来简单做正则校验,但是它的问题是存在校验不出来的情况。
//NSString+RegEx.h
#import <Foundation/Foundation.h>
@interface NSString (RegEx)
#pragma mark - NSPredicate
- (BOOL)mars_matchedByPrdicateToRegEx:(NSString *)regEx;
@end
//NSString+RegEx.m
#import "NSString+RegEx.h"
@implementation NSString (RegEx)
#pragma mark - NSPredicate
- (BOOL)mars_matchedByPrdicateToRegEx:(NSString *)regEx{
NSPredicate *predicate = [NSPredicate predicateWithFormat:@"SELF MATCHES %@", regEx];
return [predicate evaluateWithObject:self];
}
@end
NSRegularExpression (推荐)
NSRegularExpression 相对于 NSPredicate 功能就强大的多了,这也是iOS正则校验的正统路子。
//NSString+RegEx.h
#import <Foundation/Foundation.h>
@interface NSString (RegEx)
#pragma mark - NSRegularExpression
//校验是否匹配
- (BOOL)mars_matchedToRegEx:(NSString *)regEx;
//匹配到的第一个字符串
- (NSString *)mars_firstMatchToRegEx:(NSString *)regEx;
//所有匹配的字符串
- (NSArray *)mars_matchesToRegEx:(NSString *)regEx;
//替换匹配到的字符串
- (NSString *)mars_stringByReplaceMatchesToRegEx:(NSString *)regEx replaceString:(NSString *)replaceString;
@end
//NSString+RegEx.m
#import "NSString+RegEx.h"
@implementation NSString (RegEx)
#pragma mark - NSRegualrExpression
//校验是否匹配
- (BOOL)mars_matchedToRegEx:(NSString *)regEx{
NSError *error;
NSRegularExpression *regularExpression = [NSRegularExpression regularExpressionWithPattern:regEx options:NSRegularExpressionCaseInsensitive error:&error];
NSUInteger number = [regularExpression numberOfMatchesInString:self options:0 range:NSMakeRange(0, self.length)];
return number != 0;
}
//匹配到的第一个字符串
- (NSString *)mars_firstMatchToRegEx:(NSString *)regEx{
NSError *error;
NSRegularExpression *regularExpression = [NSRegularExpression regularExpressionWithPattern:regEx options:NSRegularExpressionCaseInsensitive error:&error];
NSTextCheckingResult *firstMatch = [regularExpression firstMatchInString:self options:0 range:NSMakeRange(0, self.length)];
if (firstMatch) {
NSString *result = [self substringWithRange:firstMatch.range];
return result;
}
return nil;
}
//所有匹配的字符串
- (NSArray *)mars_matchesToRegEx:(NSString *)regEx{
NSError *error;
NSRegularExpression *regularExpression = [NSRegularExpression regularExpressionWithPattern:regEx options:NSRegularExpressionCaseInsensitive error:&error];
NSArray *matchArray = [regularExpression matchesInString:self options:0 range:NSMakeRange(0, self.length)];
NSMutableArray *array = [NSMutableArray array];
if (matchArray.count != 0) {
for (NSTextCheckingResult *match in matchArray) {
NSString *result = [self substringWithRange:match.range];
[array addObject:result];
}
}
return array;
}
//替换匹配到的字符串
- (NSString *)mars_stringByReplaceMatchesToRegEx:(NSString *)regEx replaceString:(NSString *)replaceString{
NSError *error;
NSRegularExpression *regularExpression = [NSRegularExpression regularExpressionWithPattern:regEx options:NSRegularExpressionCaseInsensitive error:&error];
return [regularExpression stringByReplacingMatchesInString:self options:0 range:NSMakeRange(0, self.length) withTemplate:replaceString];
}
@end
最后我们看到,还是推荐大家使用NSRegularExpression来做正则的校验,如果大家在学习中有更好的解决方法或者心得,可以在下方的留言区讨论。
- Java Predicate及Consumer接口函数代码实现解析
- SpringCloud Gateway加载断言predicates与过滤器filters的源码分析
- C#中的Action、Func和Predicate如何使用
- iOS中谓词(NSPredicate)的基本入门使用教程
- iOS中NSPredicate谓词的使用
- 30分钟快速带你理解iOS中的谓词NSPredicate
- 与Func
- 浅谈Java8新特性Predicate接口
关于Wildcard与Regular Expression的区别和wilderness和wild的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于10. Regular Expression Matching(hard)、About Regular Expression、Expresso - A Tool for Building and Testing Regular Expressions、IOS中NSPredicate和NSRegularExpression校验正则表达式区别等相关知识的信息别忘了在本站进行查找喔。
本文标签:




