如果您对使用Swift3.0操作MySQL数据库感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于使用Swift3.0操作MySQL数据库的详细内容,并且为您提供关于41-数据
如果您对使用 Swift 3.0 操作 MySQL 数据库感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于使用 Swift 3.0 操作 MySQL 数据库的详细内容,并且为您提供关于41 - 数据库-pymysql41 - 数据库-pymysql-DBUtils、Access MySQL from C (用 C 访问 MySQL 数据库)、bat脚本备份SQL Server 数据库 - cmd命令备份SQL Server 数据库、canDB.swift iOS 数据库的有价值信息。
本文目录一览:- 使用 Swift 3.0 操作 MySQL 数据库
- 41 - 数据库-pymysql41 - 数据库-pymysql-DBUtils
- Access MySQL from C (用 C 访问 MySQL 数据库)
- bat脚本备份SQL Server 数据库 - cmd命令备份SQL Server 数据库
- canDB.swift iOS 数据库

使用 Swift 3.0 操作 MySQL 数据库
如果你阅读过本主其他的 Swift 文章,你会发现我们是 Swift 服务器端开发的忠实拥护者。
今天我们将继续研究这个主题,使用 Vapor 封装的 MySQL wrapper 来操作 MySQL 数据库。
说明:这并不是一篇介绍 MySQL 或 SQL 的文章,如果你对数据库还不熟悉,网上有大量的教程可供学习。本篇我们将焦聚在 Linux 上使用 Swift 3.0 来操作 MySQL 数据库。
开始
在这篇教程中,我们采用 Ubuntu 16.04 系统和 MySQL 5.7。MySQL 5.7 引入了一系列的新特性。其中一个就是提供了更加高效的存储 JSON 数据的能力,同时提供了查询 JSON 数据内部的能力。稍后如果 MySQL 5.7 成为了 Ubuntu 16.04 上默认的 MySQL 版本以后,我们将使用 Ubuntu 16.04 作为我们的操作系统。
如果你还没有安装 Swift, 你可以使用 apt-get 方式来安装。参见这篇文章的说明安装。2016 年 9 月底,苹果也开始在 Ubuntu16.04 上编译 Swift 的镜像。请查看 Swift.org 获取更多的信息。
创建数据库
我们把数据库命名为 swift_test, 分配的用户是 swift, 密码是 swiftpass,如果你熟悉 MySQL,你应该知道需要执行 GRANT ALL ON swift_test.* 进行授权。
下面是这部分的命令:
# sudo mysql
...
mysql> create user swift;
Query OK, 0 rows affected (0.00 sec)
mysql> create database swift_test;
Query OK, 1 row affected (0.00 sec)
mysql> grant all on swift_test.* to ''swift''@''localhost'' identified by ''swiftpass'';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> quit
Bye
创建 Swift 包
现在开始正式进行编码,首先创建一个包:
# mkdir swift_mysql
# swift package init --type executable编写 Package.swift 文件:
import PackageDescription
let package = Package(
name: "swift_mysql",
dependencies:[
.Package(url:"https://github.com/vapor/mysql", majorVersion:1)
]
)第二步,我们使用一些辅助的工具代码来生成一些随机的数据,填充到数据库中。
在 Sources 目录下添加 utils.swift 文件并在里面添加以下内容:
import Glibc
class Random {
static let initialize:Void = {
srandom(UInt32(time(nil)))
return ()
}()
}
func randomString(ofLength length:Int) -> String {
Random.initialize
let charactersString = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
let charactersArray:[Character] = Array(charactersString.characters)
var string = ""
for _ in 0..<length {
string.append(charactersArray[Int(random()) % charactersArray.count])
}
return string
}
func randomInt() -> Int {
Random.initialize
return Int(random() % 10000)
}
Vapor MySQL
接下来是真正的代码,我们的 main.swift 文件使用了 Vapor MySQL 模块。
连接数据库
添加以下代码到 Sources/main.swift 中:
import Glibc
import MySQL
var mysql:Database
do {
mysql = try Database(host:"localhost",
user:"swift",
password:"swiftpass",
database:"swift_test")
try mysql.execute("SELECT @@version")
} catch {
print("Unable to connect to MySQL: \(error)")
exit(-1)
}
以上代码设置数据库并且处理 mysql。构造器 Database(host:String, user:String, password:String, database:String) 一目了然。
语句 try mysql.execute("SELECT @@version”) 是用来测试保证我们连接正确,并成功连接到了数据库。如果 do 代码块运行无错误,接下来就可以开始操作数据库了!
整型和字符串
所有对 MySQL 的调用都将通过 execute(_:String) 方法。需要注意的是该方法和一些抽象 API 的方法不同,比如 .create(table:String, ...) 或者 .insert(table:String, …。execute 获取原始的 SQL 语句并传给 MySQL 连接器。
do {
try mysql.execute("DROP TABLE IF EXISTS foo")
try mysql.execute("CREATE TABLE foo (bar INT(4), baz VARCHAR(16))")
for i in 1...10 {
let int = randomInt()
let string = randomString(ofLength:16)
try mysql.execute("INSERT INTO foo VALUES (\(int), ''\(string)'')")
}
// Query
let results = try mysql.execute("SELECT * FROM foo")
for result in results {
if let bar = result["bar"]?.int,
let baz = result["baz"]?.string {
print("\(bar)\t\(baz)")
}
}
} catch {
print("Error: \(error)")
exit(-1)
}
查询结果也是使用的 execute(_:String) 方法。但是返回的结果是一个 [String:Node] 字典。字典的 key 对应着数据库的列名。
Node 类型是 Vapor 中的数据结构,用于转化为不同的类型。你可以从这里获取更多的信息。使用 Node 类型来表达 MySQL 可以方便的转换成对应的 Swift 类型。比如:let bar = result["bar"]?.int 给我们一个整型。
继续
接着我们来看一些更复杂的例子,比如创建一个表,包含了 MySQL 的 DATE, POINT 和 JSON 数据类型。我们的表名叫 samples。
do {
try mysql.execute("DROP TABLE IF EXISTS samples")
try mysql.execute("CREATE TABLE samples (id INT PRIMARY KEY AUTO_INCREMENT, created_at DATETIME, location POINT, reading JSON)")
// ... Date
// ... Point
// ... Sample
// ... Insert
// ... Query
} catch {
print("Error: \(error)")
exit(-1)
}
要插入一个日期到数据库中,需要正确的 SQL 语句:
// ... Date
let now = Date()
let formatter = DateFormatter()
formatter.dateFormat = "yyyy-MM-dd HH:mm:ss" // MySQL will accept this format
let created_at = formatter.string(from:date)
接下来使用 Swift 元组来创建一个 POINT:
// ... Point
let location = (37.20262, -112.98785) // latitude, longitude
最后,我们来处理 MySQL 5.7 中新的 JSON 数据类型,此外我们使用了 Jay 包来快速将一个 Swift 字典 [String:Any] 转换为 JSON 格式的字符串。
// ... Sample
let sample:[String:Any] = [
"heading":90,
"gps":[
"latitude":37.20262,
"longitude":-112.98785
],
"speed":82,
"temperature":200
]
提示:你不需要显式在 Package.swift 中声明对 Jay 的依赖,因为在 MySQL 的包中已经包含了这个依赖。
接下来我们把 JSON 数据转换为 String,用来拼凑 MySQL 语句。
let sampleData = try Jay(formatting:.minified).dataFromJson(any:sample) // [UInt8]
let sampleJSON = String(data:Data(sampleData), encoding:.utf8)
这样我们就有了 date, point 和 JSON 字符串(sample) 了, 现在添加数据到 sample 表中:
// ... Insert
let stmt = "INSERT INTO samples (created_at, location, sample) VALUES (''\(created_at)'', POINT\(point), ''\(sampleJSON)'')"
try mysql.execute(stmt)
请注意我们在处理 POINT 时候,使用了一些技巧。在对 (point) 展开为字符串 (37.20262, -112.98785) 后,完整的字符串是 POINT(37.20262, -112.98785),这是 MySQL 所需要的数据,整个语句的字符串如下:
INSERT INTO samples (created_at, location, sample) VALUES (''2016-09-21 22:28:44'', POINT(37.202620000000003, -112.98784999999999), ''{"gps":{"latitude":37.20262,"longitude":-112.98785},"heading":90,"speed":82,"temperature":200}'')
获取结果
警告:在写这篇文章的时候(2016-09-22), Vapor MySQL 1.0.0 有一个 bug:在读取 POINT 数据类型时会 crash 掉,所以不得不在下面代码中加入 do 代码块,然后不使用 select 语句。
我们在 Vapor MySQL 中记录了这个 issue,等这个 issue 修复以后,我们将更新文章。
在下面的例子中,我们将使用 MySQL 5.7 中引入对 JSON 数据内部的查询特性,使用 SELECT … WHERE 查询 JSON 数据。在这里查询的是 samples 表中 JSON 数据类型 sample
中、speed 字段大于 80 的数据。
// ... 查询
let results = try mysql.execute("SELECT created_at,sample FROM samples where JSON_EXTRACT(sample, ''$.speed'') > 80")
for result in results {
if let sample = result["sample"]?.object,
let speed = sample["speed"]?.int,
let temperature = sample["temperature"]?.int,
let created_at = result["created_at"]?.string {
print("Time:\(created_at)\tSpeed:\(speed)\tTemperature:\(temperature)")
}
}
这里做一些说明。JSON_EXTRACT 函数是用来 返回从 JSON 文档中的数据,根据传入的路径参数选择文档中满足条件的数据。在本例中,我们解包了列 sample 中的 speed 值。
为了循环处理结果,我们使用了 for result in results 语句,接着使用 if let 语句验证结果数据。首先使用 let sample = result["sample"]?.object 获取一个字典,对应 MySQL 中的 JSON 文档,这是一句关键的代码!Vapor MySQL 库并没有返回一个 String,而 String 还需进行 JSON 的解析。这个解析工作库已经帮你做了,所以你可以直接使用 sample 字典啦。
剩下的 let 语句给了我们 speed,temperature 和 created_at。注意 created_at 在 MySQL 中是 DATETIME 类型,我们读取它为字符串。为了在 Swift 中转换成 Date 类型,需要使用 .date(from:String) 方法加一个 DateFormatter 来做类型转换。
获取代码
如果你想直接运行代码,请到 github 上下载我们的代码。
在任何地方使用 swift build 进行编译,运行可执行代码,不要忘了你还需要拥有一个数据库,用户名并且授权通过。
本文由 SwiftGG 翻译组翻译,已经获得作者翻译授权,最新文章请访问 http://swift.gg。

41 - 数据库-pymysql41 - 数据库-pymysql-DBUtils
[toc]
1 Python操作数据库
Python 提供了程序的DB-API,支持众多数据库的操作。由于目前使用最多的数据库为MySQL,所以我们这里以Python操作MySQL为例子,同时也因为有成熟的API,所以我们不必去关注使用什么数据,因为操作逻辑和方法是相同的。
2 安装模块
Python 程序想要操作数据库,首先需要安装 模块 来进行操作,Python 2 中流行的模块为 MySQLdb,而该模块在Python 3 中将被废弃,而使用PyMySQL,这里以PyMySQL模块为例。下面使用pip命令安装PyMSQL模块
pip3 install pymysql
如果没有pip3命令那么需要确认环境变量是否有添加,安装完毕后测试是否安装完毕。
lidaxindeMacBook-Pro:~ DahlHin$ python3
Python 3.6.1 (v3.6.1:69c0db5050, Mar 21 2017, 01:21:04)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pymysql
>>>
# 如果没有报错,则表示安装成功
3 基本使用
首先我们需要手动安装一个MySQL数据库,这里不再赘述,参考博文:http://www.cnblogs.com/dachenzi/articles/7159510.html
连接数据库并执行sql语句的一般流程是:
- 建立连接
- 获取游标(创建)
- 执行SQL语句
- 提交事务
- 释放资源
对应到代码上的逻辑为:
- 导入相应的Python模块
- 使用connect函数连接数据库,并返回一个Connection对象
- 通过Connection对象的cursor方法,返回一个Cursor对象
- 通过Cursor对象的execute方法执行SQL语句
- 如果执行的是查询语句,通过Cursor对象的fetchall语句获取返回结果
- 调用Cursor对象的close关闭Cursor
- 调用Connection对象的close方法关闭数据库连接
3.1 创建一个连接
使用pymysql.connect方法来连接数据库
import pymysql
pymysql.connect(host=None, user=None, password="",
database=None, port=0, unix_socket=None,
charset=''''......)
主要的参数有:
- host:表示连接的数据库的地址
- user:表示连接使用的用户
- password:表示用户对应的密码
- database:表示连接哪个库
- port:表示数据库的端口
- unix_socket:表示使用socket连接时,socket文件的路径
- charset:表示连接使用的字符集
- read_default_file:读取mysql的配置文件中的配置进行连接
3.2 连接数据库
调用connect函数,将创建一个数据库连接并得到一个Connection对象,Connection对象定义了很多的方法和异常。
host = ''10.0.0.13''
port = 3306
user = ''dahl''
password = ''123456''
database = ''test''
conn = pymysql.connect(host, user, password, database, port)
print(conn) # <pymysql.connections.Connection object at 0x000001ABD3063550>
conn.ping() # 没有返回值,无法连接会提示异常
这里conn就是一个Connection对象,它具有一下属性和方法:
begin:开始事务commit:提交事务rollback:回滚事务cursor:返回一个Cursor对象autocommit:设置事务是否自动提交set_character_set:设置字符集编码get_server_info:获取数据库版本信息ping(reconnect=True): 测试数据库是否活着,reconnect表示断开与服务器连接后是否重连,连接关闭时抛出异常(一般用来测通断)
在实际的编程过程中,一般不会直接调用begin、commit和rollback函数,而是通过上下文管理器实现事务的提交与回滚操作。
3.3 游标
游标是系统为用户开设的一个数据缓存区,存放SQL语句执行的结果,用户可以用SQL语句逐一从游标中获取记录,并赋值给变量,交由Python进一步处理。
在数据库中,游标是一个十分重要的概念。游标提供了一种对从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条SQL 选择语句相关联因为游标由结果集(可以是零条、一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。当决定对结果集进行处理时,必须声明一个指向该结果集的游标。
正如前面我们使用Python对文件进行处理,那么游标就像我们打开文件所得到的文件句柄一样,只要文件打开成功,该文件句柄就可代表该文件。对于游标而言,其道理是相同的。
3.3.1 利用游标操作数据库
在进行数据库的操作之前需要创建一个游标对象,来执行sql语句。
cursor = conn.cursor()
下面利用游标来执行sql语句:
import pymysql
def connect_mysql():
db_config = {
''host'':''127.0.0.1'',
''port'':3306,
''user'':''root'',
''password'':''abc.123'',
''charset'':''utf8''
}
return pymysql.connect(**db_config)
if __name__ == ''__main__'':
conn = connect_mysql()
cursor = conn.cursor() # 创建游标
sql = r" select user,host from mysql.user " # 要执行的sql语句
cursor.execute(sql) # 交给 游标执行
result = cursor.fetchall() # 获取游标执行结果
print(result)
3.3.2 事务管理
Connection对象包含如下三个方法用于事务管理:
- begin:开始事务
- commit:提交事务
- rollback:回滚事务
import pymysql
def connect_mysql():
db_config = {
''host'': ''10.0.0.13'',
''port'': 3306,
''user'': ''dahl'',
''password'': ''123456'',
''charset'': ''utf8''
}
return pymysql.connect(**db_config)
if __name__ == ''__main__'':
conn = connect_mysql()
cursor = conn.cursor() # 创建游标
conn.begin()
sql = r"insert into test.student (id,name,age) VALUES (5,''dahl'',23)" # 要执行的sql语句
res = cursor.execute(sql) # 交给 游标执行
print(res)
conn.commit()
这样使用是极其不安全的,因为sql语句有可能执行失败,当失败时,我们应该进行回滚
if __name__ == ''__main__'':
conn = None
cursor = None
try:
conn = connect_mysql()
cursor = conn.cursor() # 创建游标
sql = r"insert into test.student (id,name,age) VALUES (6,''dahl'',23)" # 要执行的sql语句
cursor.execute(sql) # 交给 游标执行
conn.commit() # 提交事务
except:
conn.rollback() # 当SQL语句执行失败时,回滚
finally:
if cursor:
cursor.close() # 关闭游标
if conn:
conn.close() # 关闭连接
3.3.3 执行SQL语句
用于执行SQL语句的两个方法为:
- cursor.execute(sql):执行一条sql语句
- executemany(sql,parser):执行多条语句
sql = r"select * from test.student"
res = cursor.execute(sql)
3.3.3.1 批量执行
executemany用于批量执行sql语句,
- sql 为模板,c风格的占位符。
- parser:为模板填充的数据(可迭代对象)
sql = r"insert into test.student (id,name,age) values (%s,''daxin'',20)"
cursor.executemany(sql,(7,8,9,))
3.3.3.2 SQL注入攻击
我们一般在程序中使用sql,可能会有如下代码:
# 接受用户id,然后拼接查询用户信息的SQL语句,然后查询数据库。
userid = 10 # 来源于程序
sql = ''select * from user where user_id = {}''.format(userid)
userid是可变的,比如通过客户端发来的request请求,直接拼接到查询字符串中。如果客户端传递的userid是 ''5 or 1=''呢
sql = ''select * from test.student where id = {}''.format(''5 or 1=1'')
此时真正在数据库中查询的sql语句就变成了
select * from test.student where id = 5 or 1=1
这条语句的where条件的函数含义是:当id等于5,或者1等于1时,列出所有匹配的字段,这样就轻松的查到了标准所有的数据!!!
永远不要相信客户端传来的数据是规范及安全的。
3.3.3.3 参数化查询
cursor.execute(sql)方法还额外提供了一个args参数,用于进行参数化查询,它的类型可以为元组、列表、字典。如果查询字符串使用命名关键字(%(name)s),那么就必须使用字典进行传参。
sql = ''select * from test.student where id = %s''
cursor.execute(sql,args=(2,))
sql = ''select * from test.student where id = %(id)s''
cursor.execute(sql,args={''id'':2})
我们说使用参数化查询,效率会高一点,为什么呢?因为SQL语句缓存。数据库一般会对SQL语句编译和缓存,编译只对SQL语句部分,所以参数中就算有SQL指令也不会被执行。编译过程,需要此法分析、语法分析、生成AST、优化、生成执行计划等过程,比较耗费资源。服务端会先查找是否是同一条语句进行了缓存,如果缓存未失效,则不需要再次编译,从而降低了编译的成本,降低了内存消耗。
可以认为SQL语句字符串就是一个key,如果使用拼接方案,每次发过去的SQL语句都不一样,都需要编译并缓存。大量查询的时候,首选使用参数化查询,以节省资源。
3.4 获取查询结果
Cursor类提供了三种查询结果集的方法:(返回值为元组,多个值为嵌套元组)
fetchone():获取一条fetchmany(size=None):获取多条,当size为None时,返回一个包含一个元素的嵌套元组fetchall():获取所有
sql = ''select * from test.student''
cursor.execute(sql)
print(cursor.fetchall())
print(cursor.fetchone()) # None
print(cursor.fetchmany(2)) # None
fetch存在一个指针,fetchone一次,就读取结果集中的一个结果,如果fetchall,那么一次就会读取完所有的结果。可以通过调整这个指针来重复读取
- cursor.rownumber: 返回当前行号,可以修改,支持 负数
- cursor.rowcount: 返回总行数
sql = ''select * from test.student''
cursor.execute(sql)
print(cursor.fetchall()) # ((2, ''dahl'', 20), (3, ''dahl'', 21), (4, ''daxin'', 22), (5, ''dahl'', 23), (6, ''dahl'', 23), (7, ''daxin'', 20), (8, ''daxin'', 20), (9, ''daxin'', 20))
cursor.rownumber = 0
print(cursor.fetchone()) # (2, ''dahl'', 20)
print(cursor.fetchmany()) # ((3, ''dahl'', 21),)
fetch操作的是结果集,结果集是保存在客户端的,也就是说fetch的时候,查询已经结束了。
3.4.1 带列明的查询
结果中不包含字段名,除非我们记住字段的顺序,不然很麻烦,那么下面来解决这个问题。
观察cursor原码,我们发现,它接受一个参数cursor,有一个参数是:DictCursor,查看源码得知,它是Cursor的Mixin子类。
def cursor(self, cursor=None):
"""
Create a new cursor to execute queries with.
:param cursor: The type of cursor to create; one of :py:class:`Cursor`,
:py:class:`SSCursor`, :py:class:`DictCursor`, or :py:class:`SSDictCursor`.
None means use Cursor.
"""
if cursor:
return cursor(self)
return self.cursorclass(self)
观察DictCursor的原码,得知结果集会返回一个字典,一个字段名:值的结果,所以,只需要传入cursor参数即可
from pymysql import cursors # DictCursor存在与cursors模块中
... ...
cursor = conn.cursor(cursors.DictCursor)
sql = ''select * from test.student''
cursor.execute(sql)
print(cursor.fetchone()) # {''id'': 2, ''name'': ''dahl'', ''age'': 20}
3.5 上下文支持
Connection和Cursor类实现了__enter__和__exit__方法,所以它支持上下文管理。
- Connection:进入时返回一个cursor,退出时如果有异常,则回滚,否则提交
- Cursor: 进入时返回cursor本身,退出时,关闭cursor连接
所以利用上下文的特性,我们可以这样使用
import pymysql
def connect_mysql():
db_config = {
''host'': ''10.0.0.13'',
''port'': 3306,
''user'': ''dahl'',
''password'': ''123456'',
''charset'': ''utf8''
}
return pymysql.connect(**db_config)
if __name__ == ''__main__'':
conn = connect_mysql()
with conn as cursor:
sql = ''select * from student''
cursor.execute(sql)
print(cursor.fetchmany(2))
# conn的exit只是提交了,并没有关闭curosr
cursor.close()
conn.close()
如果要自动关闭cursor,可以进行如下改写
if __name__ == ''__main__'':
conn = connect_mysql()
with conn as cursor:
with cursor # curosr的exit会关闭cursor
sql = ''select * from student''
cursor.execute(sql)
print(cursor.fetchmany(2))
conn.close()
多个 cursor共享一个 conn
4 DBUtils连接池
在python编程中可以使用MySQLdb/pymysql等模块对数据库的连接及诸如查询/插入/更新等操作,但是每次连接mysql数据库请求时,都是独立的去请求访问,相当浪费资源,而且访问数量达到一定数量时,对mysql的性能会产生较大的影响。因此,实际使用中,通常会使用数据库的连接池技术,来访问数据库达到资源复用的目的。
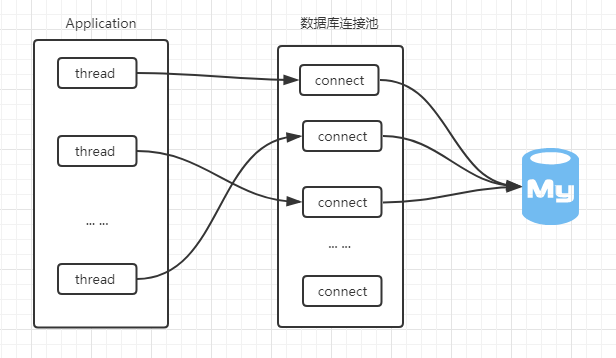
连接池对性能的提升表现在:
- 在程序创建连接的时候,可以从一个空闲的连接中获取,不需要重新初始化连接,提升获取连接的速度
- 关闭连接的时候,把连接放回连接池,而不是真正的关闭,所以可以减少频繁地打开和关闭连接
DBUtils是一套Python数据库连接池包,并允许对非线程安全的数据库接口进行线程安全包装。DBUtils来自Webware for Python。
DBUtils提供两种外部接口:
- PersistentDB:提供线程专用的数据库连接,并自动管理连接。(为每一个线程创建一个)
PooledDB:提供线程间可共享的数据库连接,并自动管理连接。
为每个线程创建一个,资源消耗太大,所以我们常用的是PooledDB.
PooledDB常用的参数为:
creator=pymysql: 使用链接数据库的模块maxconnections=6: 连接池允许的最大连接数,0和None表示不限制连接数mincached=2: 初始化时,链接池中至少创建的空闲的链接,0表示不创建,如果空闲连接数小于这个数,pool会创建一个新的连接maxcached=5: 链接池中最多闲置的链接,0和None不限制,如果空闲连接数大于这个数,pool会关闭空闲连接- maxshared=3: 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True: 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错- maxusage=None: 一个链接最多被重复使用的次数,None表示无限制
- setsession=[]: 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
- ping=0: ping MySQL服务端,检查是否服务可用。
0= None = never- 1 = default = whenever it is requested
- 2 = when a cursor is created
4= when a query is executed- 7 = always
- host=''127.0.0.1'',
- port=3306,
- user=''root'',
- password=''123'',
- database=''pooldb'',
- charset=''utf8''
安装DBUtils
pip install DBUtils
示例代码:
import threading
import time
from DBUtils.PooledDB import PooledDB
import pymysql
POOL = PooledDB(
creator=pymysql,
maxconnections=6,
mincached=2,
maxcached=5,
# maxshared=3,
blocking=True,
maxusage=None,
setsession=[],
ping=0,
host=''10.0.0.13'',
port=3306,
user=''dahl'',
password=''123456'',
database=''test'',
charset=''utf8''
)
def func():
conn = POOL.connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
time.sleep(2)
cursor.execute(''select * from employees'')
res = cursor.fetchall()
conn.close()
print(threading.get_ident(), res)
if __name__ == ''__main__'':
for i in range(10):
threading.Thread(target=func).start()
")
Access MySQL from C (用 C 访问 MySQL 数据库)
This blog is mainly a collection of study notes and some simple tryout examples. For more details, refer to "Beginning Linux Programming", Chapter 8.
Most Commonly Used APIs for Accessing MySQL:
MYSQL *mysql_init(MYSQL *);
MYSQL *mysql_real_connect(MYSQL *connection,
const char *server_host,
const char *sql_user_name,
const char *sql_password,
const char *db_name,
unsigned int port_number,
const char *unix_socket_name,
unsigned int flags);
void mysql_close(MYSQL *connection);
int mysql_options(MYSQL *connection, enum option_to_set,
const char *argument);
int mysql_query(MYSQL *connection, const char *query);
my_ulonglong mysql_affected_rows(MYSQL *connection);
unsigned int mysql_errno(MYSQL *connection);
char *mysql_error(MYSQL *connection);
MYSQL_RES *mysql_store_result(MYSQL *connection);
my_ulonglong mysql_num_rows(MYSQL_RES *result);
MYSQL_ROW mysql_fetch_row(MYSQL_RES *result);
void mysql_data_seek(MYSQL_RES *result, my_ulonglong offset);
MYSQL_ROW_OFFSET mysql_row_tell(MYSQL_RES *result);
MYSQL_ROW_OFFSET mysql_row_seek(MYSQL_RES *result, MYSQL_ROW_OFFSET offset);
void mysql_free_result(MYSQL_RES *result);
unsigned int mysql_field_count(MYSQL *connection);
MYSQL_FIELD *mysql_fetch_field(MYSQL_RES *result);
char *mysql_get_client_info(void);
char *mysql_get_host_info(MYSQL *connection);
char *mysql_get_server_info(MYSQL *connection);
char *mysql_info(MYSQL *connection);
int mysql_select_db(MYSQL *connection, const char *dbname);
int mysql_shutdown(MYSQL *connection, enum mysql_enum_shutdown_level);
Example1: how to connect to a mysql server
#include <stdlib.h>
#include <stdio.h>
#include "mysql.h"
int main(int argc, char *argv[])
{
MYSQL *conn_ptr;
conn_ptr = mysql_init(NULL);
if (!conn_ptr)
{
fprintf(stderr, "mysql_init failed\n");
exit(EXIT_FAILURE);
}
conn_ptr = mysql_real_connect(conn_ptr, "localhost", "chenqi", "helloworld",
"test", 0, NULL, 0);
if (conn_ptr)
{
printf("Connection Success \n");
}
else
{
printf("Connection failed \n");
}
mysql_close(conn_ptr);
exit(EXIT_SUCCESS);
}
gcc -I/usr/include/mysql connect1.c -L/usr/lib/mysql -lmysqlclient -o connect1
Example2: how to handle errors
#include <stdlib.h>
#include <stdio.h>
#include "mysql.h"
int main(int argc, char *argv[])
{
MYSQL conn;
mysql_init(&conn);
if (mysql_real_connect(&conn, "localhost", "chenqi",
"i do not know", "test", 0, NULL, 0))
{
printf("Connection Success \n");
mysql_close(&conn);
}
else
{
fprintf(stderr, "Connection Failed \n");
if (mysql_errno(&conn))
{
fprintf(stderr, "Connection error %d: %s \n",
mysql_errno(&conn), mysql_error(&conn));
}
}
exit(EXIT_SUCCESS);
}
result:
chenqi@chenqi-laptop ~/MyPro/Database/access_with_c $ ./connect2
Connection Failed
Connection error 1045: Access denied for user ''chenqi''@''localhost'' (using password: YES)
Example3: how to insert and update
/* insert a row into the table children */
ret = mysql_query(&conn, "insert into children(fname, age) values(''James'', 23)");
if (!ret)
{
printf("Inserted %lu rows \n",
(unsigned long)mysql_affected_rows(&conn));
}
else
{
fprintf(stderr, "Insert error %d: %s \n",
mysql_errno(&conn), mysql_error(&conn));
}
/* update a row in the table children */
ret = mysql_query(&conn, "update children set age = 24 where fname = ''James''");
if (!ret)
{
printf("Update %lu rows \n",
(unsigned long)mysql_affected_rows(&conn));
}
else
{
fprintf(stderr, "Update error %d: %s \n",
mysql_errno(&conn), mysql_error(&conn));
}
result:
chenqi@chenqi-laptop ~/MyPro/Database/access_with_c $ ./insert-update
Connection Success
Inserted 1 rows
Update 2 rows
Example4: how to retrieve data into C application
Step1: Issue the query (mysql_query)
Step2: Retrieve the data (mysql_store_result, mysql_use_result)
Step3: Process the data (mysql_fetch_row)
Step4: Tidy up if necessary (mysql_free_result)
For a large data set, mysql_use_result should be considered, because it uses less storage.
MySQL, like other SQL databases, gives back two sorts of data:
1. The retrieved information from the table, namely the column data
2. Data about the data, so-called metadata, such as column types and names
#include <stdlib.h>
#include <stdio.h>
#include "mysql.h"
MYSQL my_connection;
MYSQL_RES *res_ptr;
MYSQL_ROW sqlrow;
void display_row()
{
unsigned int field_count = 0;
while(field_count < mysql_field_count(&my_connection))
{
if (sqlrow[field_count])
printf("%12s", sqlrow[field_count]);
else
printf("%12s", "NULL");
field_count++;
}
printf("\n");
}
/* show metadata of each column */
void display_header()
{
MYSQL_FIELD *field_ptr;
printf("Column Details:\n");
while((field_ptr = mysql_fetch_field(res_ptr)) != NULL)
{
printf("\t Name: %s\n", field_ptr->name);
printf("\t Type: ");
if (IS_NUM(field_ptr->type))
{
printf("Numeric Field\n");
}
else
{
switch(field_ptr->type)
{
case FIELD_TYPE_VAR_STRING:
printf("VARCHAR\n");
break;
case FIELD_TYPE_LONG:
printf("LONG\n");
break;
default:
printf("Type is %d, check in mysql_com.h\n", field_ptr->type);
}
} /* else */
printf("\t Max_width %ld\n", field_ptr->max_length);
if (field_ptr->flags & AUTO_INCREMENT_FLAG)
{
printf("\t Auto increments\n");
}
printf("\n");
} /* while */
}
int main(int argc, char *argv[])
{
int ret;
mysql_init(&my_connection);
if (mysql_real_connect(&my_connection, "localhost", "chenqi",
"helloworld", "test", 0, NULL, 0))
{
printf("Conncetion Success\n");
ret = mysql_query(&my_connection, "select * from children");
if (ret) /* error */
{
printf("select error: %s\n", mysql_error(&my_connection));
}
else /* ok */
{
res_ptr = mysql_store_result(&my_connection); /* mysql_use_result for an alternative */
if (res_ptr)
{
printf("Retrieved %lu rows \n", (unsigned long)mysql_num_rows(res_ptr));
display_header();
while (sqlrow = mysql_fetch_row(res_ptr))
{
/// printf("Fetching data ... \n");
display_row();
}
if (mysql_errno(&my_connection))
{
fprintf(stderr, "Retrieve error: %s\n", mysql_error(&my_connection));
}
mysql_free_result(res_ptr); /* res_ptr != NULL */
}
}
mysql_close(&my_connection);
}
else
{
fprintf(stderr, "Connection Failed\n");
if (mysql_errno(&my_connection))
{
fprintf(stderr, "Connection error %d: %s\n",
mysql_errno(&my_connection), mysql_error(&my_connection));
}
exit(EXIT_FAILURE);
}
exit(EXIT_SUCCESS);
}
Result:
chenqi@chenqi-laptop ~/MyPro/Database/access_with_c $ ./select1
Conncetion Success
Retrieved 12 rows
Column Details:
Name: childno
Type: Numeric Field
Max_width 2
Auto increments
Name: fname
Type: VARCHAR
Max_width 8
Name: age
Type: Numeric Field
Max_width 2
1 Jenny 21
2 Feby 25
3 Chandler 12
4 Monica 23
5 Rachel 21
6 Ross 2
7 Joy 11
8 Emma 11
9 Gavin 14
10 Andrew 21
12 James 24
13 Tom 13

bat脚本备份SQL Server 数据库 - cmd命令备份SQL Server 数据库
bat脚本备份SQL Server 数据库 - cmd命令备份SQL Server 数据库
如何用命令或者脚本来备份 SQL Server 备份数据库。
实现方法
通过bat脚本或者cmd命令来执行sql脚本实现备份;
开始
mybackup.sql 脚本内容如下
BACKUP DATABASE [database_name]
TO DISK=''E:\DataBaseBAK\database_name.bak''
解释
database_name 需要备份的数据库名称;
E:\DataBaseBAK\database_name.bak 数据库备份位置;
编辑打开,填入如下命令
sqlcmd -S 127.0.0.1 -U sa -P 123 -i E:\DataBaseBAK\mybackup.sql
解释
127.0.0.1 数据库服务器IP;
sa 数据库用户名
123 sa用户密码;
E:\DataBaseBAK\mybackup.sql mybackup.sql 脚本位置;
以上。

canDB.swift iOS 数据库
canDB.swift 介绍
canDB.swift 是一个框架,作用类似 nonsql 的数据库,但运作在 sqlite(FMDB) 。
// loading the json
let filePath = NSBundle.mainBundle().pathForResource("data", ofType:"json") let data = NSData(contentsOfFile:filePath!, options:NSDataReadingOptions.DataReadingUncached, error:nil) let dataArray:Array = NSJSONSerialization.JSONObjectWithData(data!, options: NSJSONReadingOptions.allZeros, error: nil) as! Array<Dictionary<String, String>>
// singleton instance
let storeInstance = canDB.sharedInstance // saving the data, the can is automatically created if not exists
storeInstance.saveData("Person", data: dataArray, idString: kCanDBDefaultIdString, error: nil) // adding the index for future queries and reindexing the table
storeInstance.addindex("Person", indexes: ["Name"], error: nil)
storeInstance.reIndex("Person", idString: kCanDBDefaultIdString) let result = storeInstance.loadData("Person") for item in result { for (key, value) in (item as! NSDictionary) {
println("\(key): \(value)")
}
} // custom query using the prevIoUs created index "Name"
let resultWithQuery = storeInstance.loadDataWithQuery("SELECT * FROM Person WHERE Name=''John''") for item in resultWithQuery { for (key, value) in (item as! NSDictionary) {
println("\(key): \(value)")
}
}
storeInstance.removeDataForId("Person", idString: kCanDBDefaultIdString, idsToDelete: ["17", "19"], error: nil)
canDB.swift 官网
https://github.com/colatusso/canDB.swift
我们今天的关于使用 Swift 3.0 操作 MySQL 数据库的分享就到这里,谢谢您的阅读,如果想了解更多关于41 - 数据库-pymysql41 - 数据库-pymysql-DBUtils、Access MySQL from C (用 C 访问 MySQL 数据库)、bat脚本备份SQL Server 数据库 - cmd命令备份SQL Server 数据库、canDB.swift iOS 数据库的相关信息,可以在本站进行搜索。
本文标签:




