如果您想了解MIT6.8242018MapReducePartIII:DistributingMapReducetasksandPartIV:Handlingworkerfailures的知识,那么本
如果您想了解MIT6.824 2018 MapReduce Part III: Distributing MapReduce tasks and Part IV: Handling worker failures的知识,那么本篇文章将是您的不二之选。同时我们将深入剖析druid.io 集成 hadoop 问题解决 /hdp/apps/${hdp.version}/mapreduce/mapreduce.tar.gz#mr-framework、Hadoop Outline Part 6 (MapReduce v1 vs v2 (@YARN))、Hadoop Outline Part 8 (MapReduce Features)、Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区的各个方面,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- MIT6.824 2018 MapReduce Part III: Distributing MapReduce tasks and Part IV: Handling worker failures
- druid.io 集成 hadoop 问题解决 /hdp/apps/${hdp.version}/mapreduce/mapreduce.tar.gz#mr-framework
- Hadoop Outline Part 6 (MapReduce v1 vs v2 (@YARN))
- Hadoop Outline Part 8 (MapReduce Features)
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区

MIT6.824 2018 MapReduce Part III: Distributing MapReduce tasks and Part IV: Handling worker failures
Your current implementation runs the map and reduce tasks one at a time. One of Map/Reduce''s biggest selling points is that it can automatically parallelize ordinary sequential code without any extra work by the developer. In this part of the lab, you will complete a version of MapReduce that splits the work over a set of worker threads that run in parallel on multiple cores. While not distributed across multiple machines as in real Map/Reduce deployments, your implementation will use RPC to simulate distributed computation.
The code in mapreduce/master.go does most of the work of managing a MapReduce job. We also supply you with the complete code for a worker thread, in mapreduce/worker.go, as well as some code to deal with RPC in mapreduce/common_rpc.go.
Your job is to implement schedule() in mapreduce/schedule.go. The master calls schedule() twice during a MapReduce job, once for the Map phase, and once for the Reduce phase. schedule()''s job is to hand out tasks to the available workers. There will usually be more tasks than worker threads, so schedule() must give each worker a sequence of tasks, one at a time. schedule() should wait until all tasks have completed, and then return.
schedule() learns about the set of workers by reading its registerChan argument. That channel yields a string for each worker, containing the worker''s RPC address. Some workers may exist before schedule() is called, and some may start while schedule() is running; all will appear on registerChan. schedule() should use all the workers, including ones that appear after it starts.
schedule() tells a worker to execute a task by sending a Worker.DoTask RPC to the worker. This RPC''s arguments are defined by DoTaskArgs in mapreduce/common_rpc.go. The File element is only used by Map tasks, and is the name of the file to read; schedule() can find these file names in mapFiles.
Use the call() function in mapreduce/common_rpc.go to send an RPC to a worker. The first argument is the the worker''s address, as read from registerChan. The second argument should be "Worker.DoTask". The third argument should be the DoTaskArgs structure, and the last argument should be nil.
Your solution to Part III should only involve modifications to schedule.go. If you modify other files as part of debugging, please restore their original contents and then test before submitting.
Use go test -run TestParallel to test your solution. This will execute two tests, TestParallelBasic and TestParallelCheck; the latter verifies that your scheduler causes workers to execute tasks in parallel.
这里是实现 Master 的调度算法:
Master 把 N 个任务分配给 worker 来做,最自然的想法是使用任务队列,这里是典型的生产者消费者模型,可以并发的来做。在 Golang 中,这里使用管道来做这个并发。这里是比较难的地方。
//
// schedule() starts and waits for all tasks in the given phase (mapPhase
// or reducePhase). the mapFiles argument holds the names of the files that
// are the inputs to the map phase, one per map task. nReduce is the
// number of reduce tasks. the registerChan argument yields a stream
// of registered workers; each item is the worker''s RPC address,
// suitable for passing to call(). registerChan will yield all
// existing registered workers (if any) and new ones as they register.
//
func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) {
var ntasks int
var n_other int // number of inputs (for reduce) or outputs (for map)
switch phase {
case mapPhase:
ntasks = len(mapFiles)
n_other = nReduce
case reducePhase:
ntasks = nReduce
n_other = len(mapFiles)
}
fmt.Printf("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, n_other)
// All ntasks tasks have to be scheduled on workers. Once all tasks
// have completed successfully, schedule() should return.
//
// Your code here (Part III, Part IV).
//
taskChan := make(chan int)
var wg sync.WaitGroup
go func() {
for taskNumber := 0; taskNumber < ntasks; taskNumber++ {
taskChan <- taskNumber
fmt.Printf("taskChan <- %d in %s\n", taskNumber, phase)
wg.Add(1)
}
wg.Wait() //ntasks个任务执行完毕后才能通过
close(taskChan)
}()
for task := range taskChan { //所有任务都处理完后跳出循环
worker := <- registerChan //消费worker
fmt.Printf("given task %d to %s in %s\n", task, worker, phase)
arg := DoTaskArgs{
JobName: jobName,
Phase: phase,
TaskNumber: task,
NumOtherPhase: n_other,
}
if phase == mapPhase {
arg.File = mapFiles[task]
}
go func(worker string, arg DoTaskArgs) {
if call(worker, "Worker.DoTask", arg, nil) {
//执行成功后,worker需要执行其它任务
//注意:需要先掉wg.Done(),然后调register<-worker,否则会出现死锁
//fmt.Printf("worker %s run task %d success in phase %s\n", worker, task, phase)
wg.Done()
registerChan <- worker //回收worker
} else {
//如果失败了,该任务需要被重新执行
//注意:这里不能用taskChan <- task,因为task这个变量在别的地方可能会被修改。比如task 0执行失败了,我们这里希望
//将task 0重新加入到taskChan中,但是因为执行for循环的那个goroutine,可能已经修改task这个变量为1了,我们错误地
//把task 1重新执行了一遍,并且task 0没有得到执行。
taskChan <- arg.TaskNumber
}
}(worker, arg)
}
fmt.Printf("Schedule: %v done\n", phase)
fmt.Printf("Schedule: %v done\n", phase)
}
Part IV: Handling worker failures
In this part you will make the master handle failed workers. MapReduce makes this relatively easy because workers don''t have persistent state. If a worker fails while handling an RPC from the master, the master''s call() will eventually return false due to a timeout. In that situation, the master should re-assign the task given to the failed worker to another worker.
An RPC failure doesn''t necessarily mean that the worker didn''t execute the task; the worker may have executed it but the reply was lost, or the worker may still be executing but the master''s RPC timed out. Thus, it may happen that two workers receive the same task, compute it, and generate output. Two invocations of a map or reduce function are required to generate the same output for a given input (i.e. the map and reduce functions are "functional"), so there won''t be inconsistencies if subsequent processing sometimes reads one output and sometimes the other. In addition, the MapReduce framework ensures that map and reduce function output appears atomically: the output file will either not exist, or will contain the entire output of a single execution of the map or reduce function (the lab code doesn''t actually implement this, but instead only fails workers at the end of a task, so there aren''t concurrent executions of a task).
You don''t have to handle failures of the master. Making the master fault-tolerant is more difficult because it keeps state that would have to be recovered in order to resume operations after a master failure. Much of the later labs are devoted to this challenge.
Your implementation must pass the two remaining test cases in test_test.go. The first case tests the failure of one worker, while the second test case tests handling of many failures of workers. Periodically, the test cases start new workers that the master can use to make forward progress, but these workers fail after handling a few tasks. To run these tests:
$ go test -run FailureYou receive full credit for this part if your software passes the tests with worker failures (those run by the command above) when we run your software on our machines.
Your solution to Part IV should only involve modifications to schedule.go. If you modify other files as part of debugging, please restore their original contents and then test before submitting.

druid.io 集成 hadoop 问题解决 /hdp/apps/${hdp.version}/mapreduce/mapreduce.tar.gz#mr-framework
系统环境:
CentOS release 6.5 (Final) druid.io 0.10.0
问题出现
在执行从 hadoop 导入数据到 druid 的时候失败,观察 middle 节点日志,发现报如下错误
2017-07-06T01:58:01,637 ERROR [task-runner-0-priority-0] io.druid.indexing.overlord.ThreadPoolTaskRunner - Exception while running task[HadoopIndexTask{id=index_hadoop_demo_2017-07-06T01:57:43.791Z
, type=index_hadoop, dataSource=demo}]
java.lang.RuntimeException: java.lang.reflect.InvocationTargetException
at com.google.common.base.Throwables.propagate(Throwables.java:160) ~[guava-16.0.1.jar:?]
at io.druid.indexing.common.task.HadoopTask.invokeForeignLoader(HadoopTask.java:211) ~[druid-indexing-service-0.10.0.jar:0.10.0]
at io.druid.indexing.common.task.HadoopIndexTask.run(HadoopIndexTask.java:176) ~[druid-indexing-service-0.10.0.jar:0.10.0]
at io.druid.indexing.overlord.ThreadPoolTaskRunner$ThreadPoolTaskRunnerCallable.call(ThreadPoolTaskRunner.java:436) [druid-indexing-service-0.10.0.jar:0.10.0]
at io.druid.indexing.overlord.ThreadPoolTaskRunner$ThreadPoolTaskRunnerCallable.call(ThreadPoolTaskRunner.java:408) [druid-indexing-service-0.10.0.jar:0.10.0]
at java.util.concurrent.FutureTask.run(FutureTask.java:266) [?:1.8.0_77]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) [?:1.8.0_77]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) [?:1.8.0_77]
at java.lang.Thread.run(Thread.java:745) [?:1.8.0_77]
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_77]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_77]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_77]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_77]
at io.druid.indexing.common.task.HadoopTask.invokeForeignLoader(HadoopTask.java:208) ~[druid-indexing-service-0.10.0.jar:0.10.0]
... 7 more
Caused by: java.lang.IllegalArgumentException: Unable to parse ''/hdp/apps/${hdp.version}/mapreduce/mapreduce.tar.gz#mr-framework'' as a URI, check the setting for mapreduce.application.framework.pat
h
at org.apache.hadoop.mapreduce.JobSubmitter.addMRFrameworkToDistributedCache(JobSubmitter.java:443) ~[?:?]
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:142) ~[?:?]
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290) ~[?:?]
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287) ~[?:?]
at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_77]
at javax.security.auth.Subject.doAs(Subject.java:422) ~[?:1.8.0_77]
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698) ~[?:?]
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287) ~[?:?]
at io.druid.indexer.DetermineHashedPartitionsJob.run(DetermineHashedPartitionsJob.java:116) ~[druid-indexing-hadoop-0.10.0.jar:0.10.0]
at io.druid.indexer.JobHelper.runJobs(JobHelper.java:349) ~[druid-indexing-hadoop-0.10.0.jar:0.10.0]
at io.druid.indexer.HadoopDruidDetermineConfigurationJob.run(HadoopDruidDetermineConfigurationJob.java:91) ~[druid-indexing-hadoop-0.10.0.jar:0.10.0]
at io.druid.indexing.common.task.HadoopIndexTask$HadoopDetermineConfigInnerProcessing.runTask(HadoopIndexTask.java:306) ~[druid-indexing-service-0.10.0.jar:0.10.0]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_77]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_77]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_77]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_77]
at io.druid.indexing.common.task.HadoopTask.invokeForeignLoader(HadoopTask.java:208) ~[druid-indexing-service-0.10.0.jar:0.10.0]
... 7 more
Caused by: java.net.URISyntaxException: Illegal character in path at index 11: /hdp/apps/${hdp.version}/mapreduce/mapreduce.tar.gz#mr-framework
at java.net.URI$Parser.fail(URI.java:2848) ~[?:1.8.0_77]
at java.net.URI$Parser.checkChars(URI.java:3021) ~[?:1.8.0_77]
at java.net.URI$Parser.parseHierarchical(URI.java:3105) ~[?:1.8.0_77]
at java.net.URI$Parser.parse(URI.java:3063) ~[?:1.8.0_77]
at java.net.URI.<init>(URI.java:588) ~[?:1.8.0_77]
at org.apache.hadoop.mapreduce.JobSubmitter.addMRFrameworkToDistributedCache(JobSubmitter.java:441) ~[?:?]
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:142) ~[?:?]
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290) ~[?:?]
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287) ~[?:?]
at java.security.AccessController.doPrivileged(Native Method) ~[?:1.8.0_77]
at javax.security.auth.Subject.doAs(Subject.java:422) ~[?:1.8.0_77]
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698) ~[?:?]
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287) ~[?:?]
at io.druid.indexer.DetermineHashedPartitionsJob.run(DetermineHashedPartitionsJob.java:116) ~[druid-indexing-hadoop-0.10.0.jar:0.10.0]
at io.druid.indexer.JobHelper.runJobs(JobHelper.java:349) ~[druid-indexing-hadoop-0.10.0.jar:0.10.0]
at io.druid.indexer.HadoopDruidDetermineConfigurationJob.run(HadoopDruidDetermineConfigurationJob.java:91) ~[druid-indexing-hadoop-0.10.0.jar:0.10.0]
at io.druid.indexing.common.task.HadoopIndexTask$HadoopDetermineConfigInnerProcessing.runTask(HadoopIndexTask.java:306) ~[druid-indexing-service-0.10.0.jar:0.10.0]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_77]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_77]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_77]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_77]
at io.druid.indexing.common.task.HadoopTask.invokeForeignLoader(HadoopTask.java:208) ~[druid-indexing-service-0.10.0.jar:0.10.0]
... 7 more
2017-07-06T01:58:01,653 INFO [task-runner-0-priority-0] io.druid.indexing.overlord.TaskRunnerUtils - Task [index_hadoop_demo_2017-07-06T01:57:43.791Z] status changed to [FAILED].
2017-07-06T01:58:01,656 INFO [task-runner-0-priority-0] io.druid.indexing.worker.executor.ExecutorLifecycle - Task completed with status: {
"id" : "index_hadoop_demo_2017-07-06T01:57:43.791Z",
"status" : "FAILED",
"duration" : 13783
}
问题原因很明确
java.net.URISyntaxException: Illegal character in path at index 11: /hdp/apps/${hdp.version}/mapreduce/mapreduce.tar.gz#mr-framework
变量 ${hdp.version} 在 druid 集群服务器上是不存在的
解决方案
修改 middle 配置文件 conf/druid/middleManager/runtime.properties 在参数 druid.indexer.runner.javaOpts 上增加 hpd hadoop 的版本号变量 -Dhdp.version=2.5.3.0-37 例如:
druid.indexer.runner.javaOpts=-server -Xms1g -Xmx1g -XX:+UseG1GC -Duser.timezone=UTC -Dfile.encoding=UTF-8 -Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager -Dhdp.version=2.5.3.0-37
)")
Hadoop Outline Part 6 (MapReduce v1 vs v2 (@YARN))

MapReduce v1


MRv1 Question?
How to decide how many splits in total?
What''s the split information format?
MapReduce v2 (YARN)
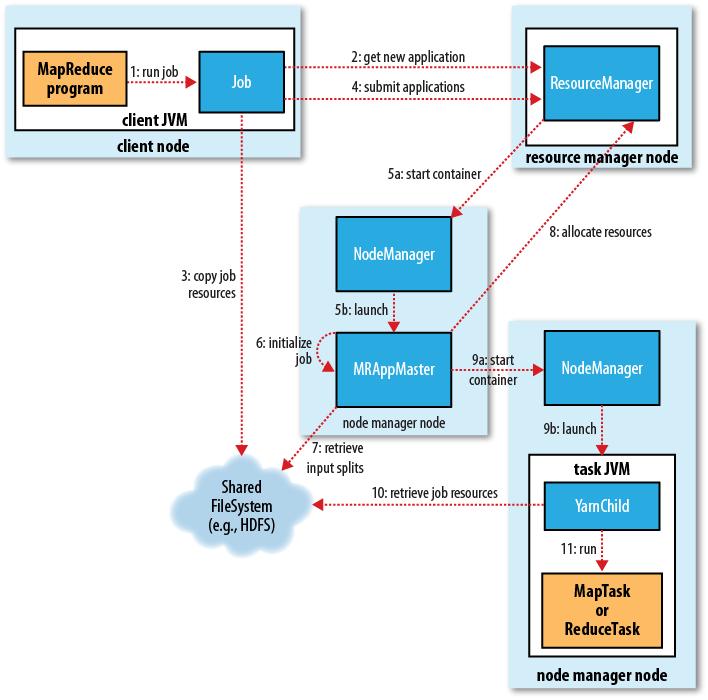
MapReduce on YARN
The client, which submits the MapReduce job.
The YARN resource manager, which coordinates the allocation of compute resources on the cluster.
The MapReduce application master, which coordinates the tasks running the MapReduce job. The application master and the MapReduce tasks run in containers that are scheduled by the resource manager and managed by the node managers.
The distributed filesystem (normally HDFS, covered in Chapter 3), which is used for sharing job files between the other entities.
Job submission
MapReduce 2 has an implementation of ClientProtocol that is activated when mapre duce.framework.name is set to yarn.
if the Job is small (<10 mappers,only 1 reducer, and an input size that is less than the size of one HDFS block), the application master may choose to run the tasks in the same JVM as itself. This happens when it judges the overhead of allocating and running tasks in new containers outweighs the gain to be had in running them in parallel, compared to running them sequentially on one node. (This is different from MapReduce 1, where small jobs are never run on a single tasktracker.) Such a job is said to be uberized, or run as an uber task.
That must be a multiple of the minimum allocation.Default memory allocations are scheduler-specific, and for the capacity scheduler, the default minimum is 1024 MB. The task is executed by a Java application whose main class is YarnChild.however, YARN does not support JVM reuse, so each task runs in a new JVM.
Every five seconds the client checks whether the job has completed by calling the waitForCompletion()
Failure
ZooKeeper-based store in the works that will support reliable recovery from resource manager failures.
Scheduler
MapReduce in Hadoop comes with a choice of schedulers. The default in MapReduce 1 is the original FIFO queue-based scheduler, and there are also multiuser schedulers called the Fair Scheduler (Jobs are placed in pools, and by default, each user gets her own pool) and the Capacity Scheduler (within each queue, jobs are scheduled using FIFO scheduling (with priorities).
Shuffle and Sort
->The Map Side:
Map->Buffer->Partitions->Sort>Compress->Spill toDisk->Combine->copy to reducers
Each map task has a circular memory buffer that it writes the output to. The buffer is 100 MB by default.Whenthe contents of the buffer reaches a certain threshold size (io.sort.spill.percent,which has the default 0.80, or 80%), a background thread will start to spill the contents to disk. Map outputs will continue to be written to the buffer while the spill takes place,but if the buffer fills up during this time, the map will block until the spill is complete.
Combinner
Before it writes to disk, the thread first divides the data into partitions corresponding to the reducers that they will ultimately be sent to. Within each partition, the background thread performs an in-memory sort by key, and if there is a combiner function, it is run on the output of the sort. Running the combiner function makes for a more compact map output, so there is less data to write to local disk and to transfer to the reducer.
Map Sort Phase
Each time the memory buffer reaches the spill threshold, a new spill file is created, so after the map task has written its last output record, there could be several spill files. Before the task is finished, the spill files are merged into a single partitioned and sorted output file. The configuration property io.sort.factor controls the maximum number of streams to merge at once; the default is 10.
It is often a good idea to compress the map output,By default, the output is not compressed, but it is easy to enable this by setting mapred.compress.map.output to true.
The output file’s partitions are made available to the reducers over HTTP. The maximum number of worker threads used to serve the file partitions is controlled by the tasktracker.http.threads property; this setting is per tasktracker, not per map task slot. The default of 40 may need to be increased for large clusters running large jobs. In MapReduce 2, this property is not applicable because the maximum number of threads used is set automatically based on the number of processors on the machine. (MapReduce 2 uses Netty, which by default allows up to twice as many threads as there are processors.)
->The Reduce Side:
Uncompress ->Merge->Memory/Spill to disk->Reduce Phase
Reduce Copy Phase
The reduce task has a small number of copier threads so that it can fetch map outputs in parallel. The default is five threads, but this number can be changed by setting the mapred.reduce.parallel.copies property.
If a combiner is specified,it will be run during the merge to reduce the amount of data written to disk.
Reduce Merge Phase
if there were 50 map outputs and the merge factor was 10 (the default, controlled by the io.sort.factor property, just like in the map’s merge), 210 | Chapter 6: How MapReduce Works there would be five rounds. Each round would merge 10 files into one, so at the end there would be five intermediate files.
Configuration Tuning
Map-side tuning properties
Reduce-side tuning properties
Task Execution
Speculative Execution
a speculative task is launched only after all the tasks for a job have been launched, and then only for tasks that have been running for some time (at least a minute) and have failed to make as much progress, on average, as the other tasks from the job. Speculative execution is an optimization, and not a feature to make jobs run more reliably.
Speculative execution is turned on by default.
mapred.map.tasks.speculative.execution
mapred.reduce.tasks.speculative.execution
yarn.app.mapreduce.am.job.speculator.class
yarn.app.mapreduce.am.job.task.estimator.class.
Output Committers
The default is FileOutputCommitter, which is appropriate for file-based MapReduce.You can customize an existing OutputCommitter or even write a new implementation if you need to do special setup or cleanup for jobs or tasks.
The OutputCommitter API is as follows (in both old and new MapReduce APIs):
public abstract class OutputCommitter {
public abstract void setupJob(JobContext jobContext) throws IOException;
public void commitJob(JobContext jobContext) throws IOException { }
public void abortJob(JobContext jobContext, JobStatus.State state) throws IOException { }
public abstract void setupTask(TaskAttemptContext taskContext) throws IOException;
public abstract boolean needsTaskCommit(TaskAttemptContext taskContext) throws IOException;
public abstract void commitTask(TaskAttemptContext taskContext) throws IOException;
public abstract void abortTask(TaskAttemptContext taskContext) throws IOException;
}Task side-effect files
One way to do this is to have a map-only job, where each map is given a set of images to convert (perhaps using NLineInputFormat}
job.setNumReduceTasks(0);
Task JVM Reuse
JVM reuse is not currently supported in MapReduce 2. There is however, the concept of an "über" task which is similar in nature but the config has gotten only more complex/fine-grained.
Skipping Bad Records
If you are using TextInputFormat (“TextInputFormat” on page 246), you can set a maximum expected line length to safeguard against corrupted files. Corruption in a file can manifest itself as a very long line, which can cause out-of-memory errors and then task failure. By setting mapred.linerecordreader.maxlength to a value in bytes that fits in memory (and is comfortably greater than the length of lines in your input data), the record reader will skip the (long) corrupt lines without the task failing.
skipping mode is turned on for a task only after it has failed twice.
1. Task fails.
2. Task fails.
3. Skipping mode is enabled. Task fails, but the failed record is stored by the tasktracker.
4. Skipping mode is still enabled. Task succeeds by skipping the bad record that failed
in the previous attempt.
Skipping mode is off by default;
Bad records that have been detected by Hadoop are saved as sequence files in the job’s output directory under the _logs/skip subdirectory. These can be inspected for diagnostic purposes after the job has completed (using hadoop fs -text, for example).
Skipping mode is not supported in the new MapReduce API.
")
Hadoop Outline Part 8 (MapReduce Features)
1. Counter
1.1 内建计数器 (Built-in Counters)
1.11 Task counters
每一个 Built-in 计数器组要么包含一个 task counters (for task progresses) 或者是 job counters (for progresses).
Task Counter 在每一个 map 或 reduce 中收集,定期的发给 task Tracker, 然后发到 job tracker.
MapReduce task counters
Filesystem counters
FileInputFormat counters
FileOutputFormat counters
Job counters
1.2. 自定义计数器 (User-Defined Counters)
context.getCounter(Temperature.MISSING).increment(1);
1.2.1 动态计数器 (Dynamic counters)
public void incrCounter(String group, String counter, long amount)
1.2.2 Readable counter names
配置一个 property 文件,放在 counter 所在类的同级目录.
命名方法:使用下划线分隔不同的类,比如 MyWordCount_BadRecords.properties
本地化居然也可以:MyWordCount_BadRecords_zh_CN.properties
CounterGroupName=Air Temperature Records
MISSING.name=Missing
MALFORMED.name=Malformed
1.2.3 Retrieving counters
job 激活数,mapred.jobtracker.completeuserjobs.maximum, 默认 100, 超过的会被清除掉,所以 job 有可能空
Cluster cluster = new Cluster(getConf());
Job job = cluster.getJob(JobID.forName(jobID));
Counters counters = job.getCounters();
long missing = counters.findCounter(MaxTemperatureWithCounters.Temperature.MISSING).getValue();
long total = counters.findCounter(TaskCounter.MAP_INPUT_RECORDS).getValue();1.3 User-Defined Streaming Counters
ignore for Streaming topic.
2. Sorting
2.1 Partial Sort
我们知道 shuffle 会对 key 进行排序,然后在产生的每个 partitionzhong,key 都是排序的,只不过这个排序不是全局的,所以叫 Partial Sort. 如果数据集比较小,可以使用 merge 和 sort 命令,如果大的结果集,请看下面 Total Sort.
当然了,如果结果写入 SequenceFile 或 MapFile,MR 提供了 Sort 方法进行排序和索引。
对于一个 job, 对 sort 的控制有如下步骤:
1.job.setSortComparatorClass (), 这个可以提供一个类来特化 Key 的排序规则。
2. 如果上面 1 没设置,key 必须是 WritableComparable 的子类,因为必须实现 compareTo 方法。
3. 如果 2 种的类,没有注册 RawComparator,那么 RawComparator 将使用 Ser/De 来构造对象,然后调用 WritableComparable 的 compareTo 方法。这当然是效率低的,所以实现自己的 RawComparator
对效率提升很有必要,尤其是大对象。
2.2 Total Sort
对于一个 Total Sort 的需求,一个 Naive 的方法是只指定一个 Reduce, 这样自然是全局排序的。但是如果结果集比较大,则 applicationMaster 将负担过重,失去了分布式的优势。
既然 Partitioner 会造成 Partial sort, 那么如果,我们能够让 Partitioner 告诉 MapReduce, 什么样的值必须去某个 Reduce,那不就是 Total Sort 了吗?
的确,它是可行的。我给这种方法取了名字,叫 Ranged Partitioning。
实践中,带来一个问题,就是这个 Range 的 boundary 不好取,你没法保证 range 的均匀性。不均匀带来一个比较不好的性能。
当然全部浏览数据也是不现实的,可行的办法是做 Sampling, 来预测一个较好的数值分布。好消息是,Hadoop 已经提供 InputSampler.Sampler 接口,和一些有用的实现。这里我隆重介绍 InputSampler 和 TotalSortPartitioner.
2.2.1 InputSampler
InputSampler 类的结构如下,通过集成 Sampler Interface 的三种实现 (SplitSampler,RandomSampler 和 IntervalSampler), 当然你也可以自己写自己的 Sampler.
/**
* Utility for collecting samples and writing a partition file for
* {@link org.apache.hadoop.mapred.lib.TotalOrderPartitioner}.
*/
public class InputSampler<K,V> implements Tool {
/**
*采样器接口
*/
public interface Sampler<K,V> {
/**
* 从输入数据几种获得一个数据采样的子集,然后通过这些采样数据在Map端由
* TotalOrderPartitioner对处理数据做hash分组,以保证不同Reduce处理数据的有序性。
* 该方法的具体采样逻辑由继承类实现。
* For a given job, collect and return a subset of the keys from the
* input data.
*/
K[] getSample(InputFormat<K,V> inf, JobConf job) throws IOException;
}
/**
* 分片数据采样器,即从N个分片中采样,效率最高
* Samples the first n records from s splits.
* Inexpensive way to sample random data.
*/
public static class SplitSampler<K,V> implements Sampler<K,V> {
...
}
/**
* 通用的随机数据采样器,按一定的频率对所有数据做随机采样,效率很低,
* 但是对于分布不可预测的数据可能效果比较好.
* Sample from random points in the input.
* General-purpose sampler. Takes numSamples / maxSplitsSampled inputs from
* each split.
*/
public static class RandomSampler<K,V> implements Sampler<K,V> {
...
}
/**
* 有固定采样间隔的数据采样器,适合有序的数据集,效率较随机数据采样器要好一些
* Sample from s splits at regular intervals.Useful for sorted data.
*/
public static class IntervalSampler<K,V> implements Sampler<K,V> {
}
}
我们先不管 Sampler 的具体抽样细节,从外围看都是产生一个系列的 K [] = getSample (), 这个 key 数组提供给 TotalSortPartitioner 来做 Boundary。Sampler 一般都是获取所需要的 splits 进行 split 级别的 sampling, 然后在 record 级别进行 sampling. 当然不同的 sampling 策略,会影响 sampling 的效果和数据分布。这也是上面三个不同实现的重点部分.
题记: 这里发点负能量的评论。看 hadoop 看到这个 sampler, 我真心觉得有点蛋疼:
1. 这个 sampler 是基于 mapper 输入的,而不是基于输出,这也是为什么很多人抱怨的原因,这尼玛怎么这么 stupid 呢,难道不是输出才需要作 partitioning 吗?
2. 这个 sampler 是基于本地的,也就是有网络 io + 磁盘 io 的,居然没有 map-reduce 版本的 sampling 吗,开始写的时候,没有灵活设计吗?
3. 我用 cdh5.1 测试,发现_partition.lst 不能产生,产生也不能产生预想的结果。在这里浪费了几天时间,无奈暂时撤兵,后来再看。
对这个部分的实现不敢恭维,以后没人改,我写一个看看。。
2.2.2 TotalSortPartitioner
TotalOrderPartitioner 依赖于一个 partition file 来 distribute keys,partition file 是一个实现计算好的 sequence file,如果我们设置的 reducer number 是 N,那么这个文件包含(N-1)个 key 分割点,并且是基于 key comparator 排好序的。TotalOrderPartitioner 会检查每一个 key 属于哪一个 reducer 的范围内,然后决定分发给哪一个 reducer。
2.3 Secondary Sort
所谓 Secondary Sort, 就是对于 k-v 有多个排序纬度,比如 wordcount 中,第一排序字段是 count 倒序,第二排序字段是 word 字母顺序,这样的需求无法以来单一 key 的 shuffle 自然排序来完成,所以必须建立自定义的 WritableComparable, 并依次提供 Partitioner,GroupingSortComparator,Sort:
- Partitioner, 可以使需要 grouping 的 kv 输出到同一个 Reducer
- Grouping, setGroupingComparatorClass
- Sort, setSortComparatorClass
3. Joins
3.1 Map Side Join
所谓 MapSide Join 简单而言就是 Join 数据连接操作发生在 Map 阶段,一般没有 Reducer,也就是说没有 Shuffle 过程,其自然是非常高效的。这里有一个概念 Side Data, 是说这种类型的 Join, 适合一个大数据集和一个小数据集的连接,其中小数据集小道比较容易存放在一个机器的内存中。那么这个小数据集称为 SideData.
实践中,有这么几种方法来存储 SideData:
- Configuration 参数存储 , 如果 SideData 是非常小的,可以使用序列化 + 压缩的办法,把数据存储在 Job 配置中。缺点是:这种办法会显著增加 jobtraker 和 tasktracker 进程的内存,浪费读取时间。
- Distribute Cache 存储,简单说就是把数据存储在某固定存储上,一般用 HDFS 文件存储,HBase,MongoDB 等。特点是在 Mapper 的 setup 节点,读取这些文件。Hadoop 特别提供了 - file,可以以逗号添加多个文件,可以来自于本地,hdfs,S3 等。
问题: 如果是大文件,无法在单机内存加载怎么办呢?书上推荐 MapFile 格式存储,可以基于 Map 特征进行 FileAPI 级别的检索数据,只加载命中数据。HBase 等也是一个选择,如果有的话。
3.2 Reduce Side Join
所谓 ReduceSide Join 是 Join 发生在 Reduce 阶段,其模型是比较简单的,过程如下:
a. Map 输入,这里一般多个 Input,无论是否使用 MutlipleInput 或 CompositeInputFormat,总之,Join 的 On 字段,将作为 key 输出。
如:k1->v1, k1->v2
b. Reduce 合并,把同一个 key 的 Values,Join 在一起:
如:k1,v1,v2
c. 笛卡尔乘积 , 上面的如果是 1-1,那么 OK。如果是 1-n 或者 m-n 怎么处理呢?答案是进行 Value 和文件名的关联,这样在 Reduce 的时候,可以进行 m*n 的笛卡尔乘积。为了避免长文件名编入 PairValue,可以对文件名做 Hash 值,或者做自然数全局索引。
原理如下:file1 join file2, map 产出: k1->Pair<f1,v1>, k1->Pair<f2,v2> and k1->Pair<f2,v3>, 那么 Reduce 时,比较简单做出 v1-v2,v1-v3 的 join 处理。
3.3. Side Data Distribution
见 MapSide Join
3.4. MapReduce Library Classes
- ChainMapper+ChainReducer,M(Ms)+R(Ms)
- FieldSelectionMapper and FieldSelectionReducer (new API)
- IntSumReducer,LongSumReducer
- MultithreadedMapper (new API)
- TokenCounterMapper
- RegexMapper
-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区")
Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程
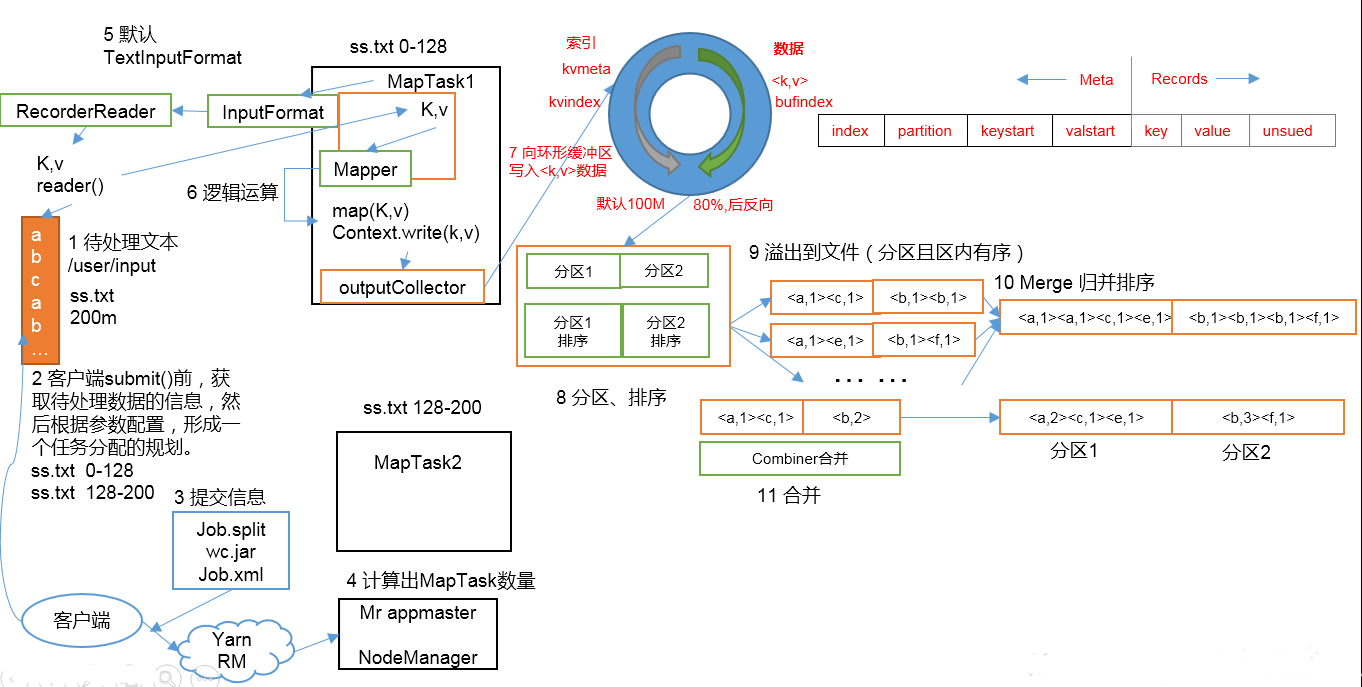
1.准备待处理文件
2.job提交前生成一个处理规划
3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn
4.yarn根据切片规划计算出MapTask的数量
(以一个MapTask为例)
5.Maptask调用inputFormat生成RecordReader,将自己处理的切片文件内容打散成K,V值
6.MapTask将打散好的K,V值交给Mapper,Mapper经过一系列的处理将KV值写出
7.写出的KV值被outputCollector收集起来,写入一个在内存的环形缓冲区
8,9.当环形缓冲区被写入的空间等于80%时,会触发溢写.此时数据是在内存中,所以在溢写之前,会对数据进行排序,是一个二次排序的快排(先根据分区排序再根据key排序).然后将数据有序的写入到磁盘上.
缓冲区为什么是环形的?这样做是为了可以在缓冲区的任何地方进行数据的写入.

当第一次溢写时,数据会从余下的20%空间中的中间位置,再分左右继续写入,也就是从第一次是从上往下写数据变成了从下往上写数据
10,11.当多次溢写产生多个有序的文件后,会触发归并排序,将多个有序的文件合并成一个有序的大文件.当文件数>=10个时,会触发归并排序,取文件的一小部分放入内存的缓冲区,再生成一个小文件部分大小x文件数的缓冲区,逐个比较放入大文件缓冲区,依次比较下去,再将大文件缓冲写入到磁盘,归并结束后将大文件放在文件列表的末尾,继续重复此动作,直到合并成一个大文件.此次归并排序的时间复杂度要求较低.
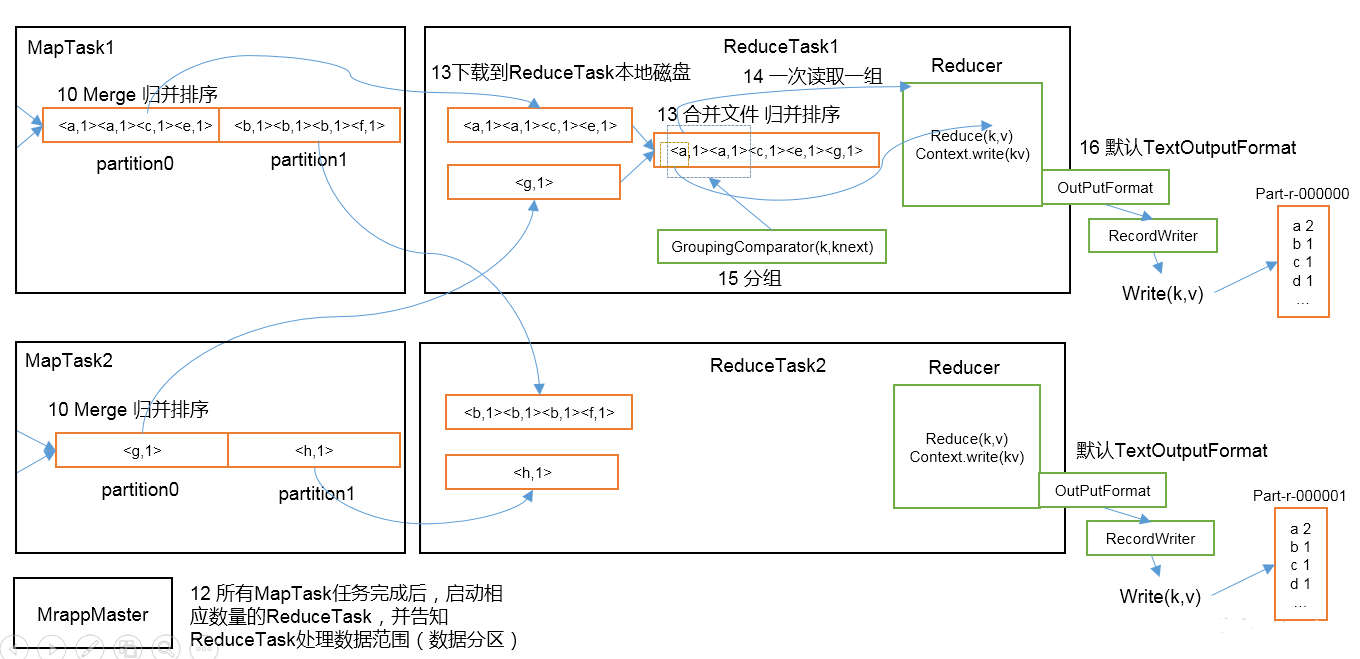
12.当所有的MapTask执行完任务后,启动相应数量的ReduceTask,并告知每一个ReduceTask应该处理的数据分区
13.ReduceTask将指定分区的文件下载到本地,如有多个分区文件的话,ReduceTask上将会有多个大文件,再一次归并排序,形成一个大文件.
14.15,如果有分组要求的话,ReduceTask会将数据一组一组的交给Reduce,处理完后准备将数据写出
16.Reduce调用output生成RecordWrite将数据写入到指定路径中
Shuffle机制
上图中,数据从Mapper写出来之后到数据进入到Reduce之前,这一阶段就叫做Shuffle
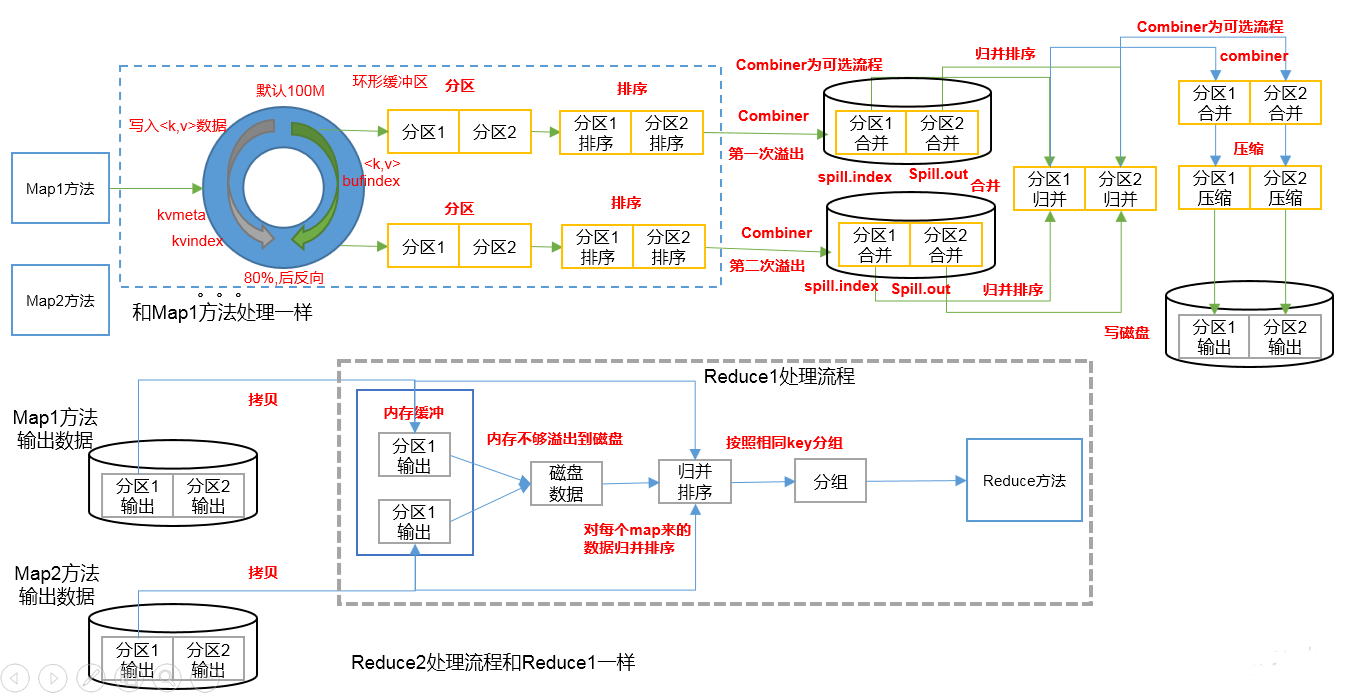
Shuffle时,会有三次排序,第一次是数据从环形缓冲区写入到磁盘时,会有一次快排,第二次是在MapTask中,将多个分区且内部有序的小文件归并成一个分区且内部有序的大文件,第三次是在ReduceTask中,从多个MapTask中获取指定分区的大文件,再进行一个归并排序,合并成一个大文件.
以WordCount为例,试想一下,在第一次从环形缓冲区写入到磁盘时,排好序的数据为(w1,1),(w1,1),(w1,1),(w2,1),(w2,1),(w3,1),这样的数据会增加网络传输量,所以在这里可以使用Combiner进行数据合并.最后形成的数据是(w1,3),(w2,2),(w3,1),后续会详细讲解~
Partition分区
将Mapper想象成一个水池,数据是池里的水.默认分一个区,只有一根水管.如果只有一个ReduceTask,则水会全部顺着唯一的水管流入到ReduceTask中.如果此时有3根水管,则水会被分成三股水流流入到3个ReduceTask中,而且哪些水进哪个水管,并不受我们主观控制,也就是数据处理速度加快了~~Partition分区就决定了分几根水管.试想一下,如果有4根水管,末端只有3个ReduceTask,那么有一股水流会丢失.也就是造成数据丢失,程序会报错.如果只有2根水管,那么则有一个ReduceTask无事可做,最后生成的是一个空文件,浪费资源
所以,一般来说,有几个ReduceTask就要分几个区,至于partition和ReduceTask设置为几,要看集群性能,数据集,业务,经验等等~
对应流程图上,也就是从环形缓冲区写入到磁盘时,会分区



collector出现了,除了将key,value收集到缓冲区中之外,还收集了partition分区


key.hashCode() & Integer.MAX_VALUE,保证取余前的数为正数
比如,numReduceTasks = 3, 一个数n对3取余,结果会有0,1,2三种可能,也就是分三个区,再一次印证了要 reduceTask number = partition number
默认分区是根据key的hashcode和reduceTasks的个数取模得到的,用户无法控制哪个key存储到哪个分区上
案例演练
以12小章的统计流量案例为例,大数据-Hadoop生态(12)-Hadoop序列化和源码追踪
将手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中
自定义Partition类
package com.atguigu.partitioner;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<Text, FlowBean> {
public int getPartition(Text text, FlowBean flowBean, int numPartitions) {
//1. 截取手机前三位
String start = text.toString().substring(0, 3);
//2. 按照手机号前三位返回分区号
switch (start) {
case "136":
return 0;
case "137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return 4;
}
}
}Driver类的main()中增加以下代码
job.setPartitionerClass(MyPartitioner.class);
job.setNumReduceTasks(5);输出结果,5个文件

如果job.setNumReduceTasks(10),会生成10个文件,其中5个是空文件
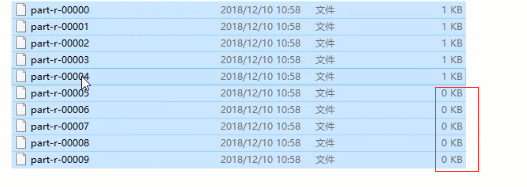
如果job.setNumReduceTasks(2),程序会直接执行失败报异常

如果job.setNumReduceTasks(1),程序会运行成功,因为如果numReduceTasks=1时,根本就不会执行分区的过程
如果是以下情况,也会执行失败.MapReduce会认为你分了41个区,所以分区号必须从0开始,逐一累加.
job.setNumReduceTasks(5)
switch (start) {
case "136":
return 0;
case "137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return 40;
}
我们今天的关于MIT6.824 2018 MapReduce Part III: Distributing MapReduce tasks and Part IV: Handling worker failures的分享已经告一段落,感谢您的关注,如果您想了解更多关于druid.io 集成 hadoop 问题解决 /hdp/apps/${hdp.version}/mapreduce/mapreduce.tar.gz#mr-framework、Hadoop Outline Part 6 (MapReduce v1 vs v2 (@YARN))、Hadoop Outline Part 8 (MapReduce Features)、Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区的相关信息,请在本站查询。
本文标签:




