在本文中,我们将详细介绍Node对象和Element对象的区别?的各个方面,并为您提供关于xmlnodeelement区别的相关解答,同时,我们也将为您带来关于.net–比较XElement对象的最佳
在本文中,我们将详细介绍Node对象和Element对象的区别?的各个方面,并为您提供关于xml node element区别的相关解答,同时,我们也将为您带来关于.net – 比较XElement对象的最佳方法、angularjs – element.bind和element.on之间有什么区别?、c# – XElement Nodes()与Elements()有什么区别?、C++中函数返回临时对象和本地对象的区别的有用知识。
本文目录一览:- Node对象和Element对象的区别?(xml node element区别)
- .net – 比较XElement对象的最佳方法
- angularjs – element.bind和element.on之间有什么区别?
- c# – XElement Nodes()与Elements()有什么区别?
- C++中函数返回临时对象和本地对象的区别
")
Node对象和Element对象的区别?(xml node element区别)
我完全混淆了 Node 对象和 Element 对象。 document.getElementById()返回 Element
对象,同时document.getElementsByClassName() 返回 NodeList 对象(元素或节点的集合?)
如果一个 div 是一个元素对象,那么 div 节点对象呢?
什么是节点对象?
文档对象、元素对象和文本对象也是节点对象吗?
根据大卫弗拉纳根的书“文档对象,其元素对象和文本对象都是节点对象”。
那么一个对象怎么能继承 Element 对象和 Node 对象的属性/方法呢?
如果是,我猜节点类和元素类在继承的原型树中是相关的。
<div id="test"> <p> 123 </p> <p> abc </p> </div> <p id="id_para"> next </p>document.documentElement.toString(); // [object HTMLHtmlElement]var div = document.getElementById("test");div.toString(); // [object HTMLDivElement]var p1 = document.getElementById("id_para");p1.toString(); // [object HTMLParagraphElement]var p2 = document.getElementsByClassName("para");p2.toString(); //[object HTMLCollection]答案1
小编典典Anode是 DOM 层次结构中任何类型对象的通用名称。Anode可以是内置 DOM 元素之一,例如documentordocument.body,它可以是 HTML 中指定的 HTML 标记,例如<input>or
,<p>或者它可以是由系统创建的文本节点,用于在另一个元素中保存文本块. 因此,简而言之,anode是任何 DOM 对象。
Anelement是一种特定类型,node因为有许多其他类型的节点(文本节点、评论节点、文档节点等)。
DOM 由节点层次结构组成,其中每个节点可以有一个父节点、一个子节点列表以及一个 nextSibling 和
previousSibling。该结构形成树状层次结构。该document节点将该html节点作为其子节点。节点有它的html子节点列表(head节点和body节点)。该body节点将具有其子节点列表(HTML
页面中的顶级元素)等等。
所以,anodeList只是一个类似数组的列表nodes。
元素是一种特定类型的节点,可以在 HTML 中使用 HTML 标记直接指定,并且可以具有类似 anid或 a
的属性class。可以有子节点等等……还有其他类型的节点比如评论节点、文本节点等等……各有特点。每个节点都有一个属性.nodeType,它报告它是什么类型的节点。您可以在此处查看各种类型的节点(来自MDN的图表):

您可以看到 anELEMENT_NODE是一种特定类型的节点,其中nodeType属性的值为1。
所以document.getElementById("test")只能返回一个节点,并且保证是一个元素(一种特定类型的节点)。因此,它只返回元素而不是列表。
由于document.getElementsByClassName("para")可以返回多个对象,因此设计人员选择返回 a
是nodeList因为这是他们为包含多个节点的列表创建的数据类型。由于这些只能是元素(通常只有元素具有类名),因此从技术上讲,它是 anodeList,其中只有元素类型的节点,设计者可以制作一个不同命名的集合,它是 aelementList,但他们选择只使用一种类型集合是否只有元素。
编辑: HTML5 定义了一个HTMLCollectionHTML 元素列表(不是任何节点,只有元素)。HTML5
中的许多属性或方法现在返回一个HTMLCollection. 虽然它在接口上与 a
非常相似,nodeList但现在的区别在于它只包含元素,而不包含任何类型的节点。
nodeLista和 an之间的区别HTMLCollection对你如何使用它几乎没有影响(据我所知),但 HTML5
的设计者现在已经做出了这种区分。
例如,该element.children属性返回一个实时 HTMLCollection。

.net – 比较XElement对象的最佳方法
我检查了XElement.deepequals()方法,但由于任何原因,它没有帮助.
有人有想法我应该使用什么最好的方法?
为了说明,对于这些语义上等效的文档,XNode.deepequals的实现返回false:
XElement root1 = XElement.Parse("<Root a='1' b='2'><Child>1</Child></Root>");
XElement root2 = XElement.Parse("<Root b='2' a='1'><Child>1</Child></Root>");
然而,从文章中使用deepequalsWithnormalization的实现,您将得到值为true,因为属性的顺序不被认为是重要的.这个实现包括在下面.
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
using System.Xml;
using System.Xml.Linq;
using System.Xml.Schema;
public static class MyExtensions
{
public static string ToStringalignAttributes(this XDocument document)
{
XmlWriterSettings settings = new XmlWriterSettings();
settings.Indent = true;
settings.OmitXmlDeclaration = true;
settings.NewLineOnAttributes = true;
StringBuilder stringBuilder = new StringBuilder();
using (XmlWriter xmlWriter = XmlWriter.Create(stringBuilder,settings))
document.Writeto(xmlWriter);
return stringBuilder.ToString();
}
}
class Program
{
private static class Xsi
{
public static XNamespace xsi = “http://www.w3.org/2001/XMLSchema-instance”;
public static XName schemaLocation = xsi + “schemaLocation”;
public static XName noNamespaceSchemaLocation = xsi + “noNamespaceSchemaLocation”;
}
public static XDocument normalize(XDocument source,XmlSchemaSet schema)
{
bool havePSVI = false;
// validate,throw errors,add PSVI information
if (schema != null)
{
source.Validate(schema,null,true);
havePSVI = true;
}
return new XDocument(
source.Declaration,source.Nodes().Select(n =>
{
// Remove comments,processing instructions,and text nodes that are
// children of XDocument. Only white space text nodes are allowed as
// children of a document,so we can remove all text nodes.
if (n is XComment || n is XProcessingInstruction || n is XText)
return null;
XElement e = n as XElement;
if (e != null)
return normalizeElement(e,havePSVI);
return n;
}
)
);
}
public static bool deepequalsWithnormalization(XDocument doc1,XDocument doc2,XmlSchemaSet schemaSet)
{
XDocument d1 = normalize(doc1,schemaSet);
XDocument d2 = normalize(doc2,schemaSet);
return XNode.deepequals(d1,d2);
}
private static IEnumerable<XAttribute> normalizeAttributes(XElement element,bool havePSVI)
{
return element.Attributes()
.Where(a => !a.IsNamespaceDeclaration &&
a.Name != Xsi.schemaLocation &&
a.Name != Xsi.noNamespaceSchemaLocation)
.OrderBy(a => a.Name.NamespaceName)
.ThenBy(a => a.Name.LocalName)
.Select(
a =>
{
if (havePSVI)
{
var dt = a.GetSchemaInfo().SchemaType.TypeCode;
switch (dt)
{
case XmlTypeCode.Boolean:
return new XAttribute(a.Name,(bool)a);
case XmlTypeCode.DateTime:
return new XAttribute(a.Name,(DateTime)a);
case XmlTypeCode.Decimal:
return new XAttribute(a.Name,(decimal)a);
case XmlTypeCode.Double:
return new XAttribute(a.Name,(double)a);
case XmlTypeCode.Float:
return new XAttribute(a.Name,(float)a);
case XmlTypeCode.HexBinary:
case XmlTypeCode.Language:
return new XAttribute(a.Name,((string)a).ToLower());
}
}
return a;
}
);
}
private static XNode normalizeNode(XNode node,bool havePSVI)
{
// trim comments and processing instructions from normalized tree
if (node is XComment || node is XProcessingInstruction)
return null;
XElement e = node as XElement;
if (e != null)
return normalizeElement(e,havePSVI);
// Only thing left is XCData and XText,so clone them
return node;
}
private static XElement normalizeElement(XElement element,bool havePSVI)
{
if (havePSVI)
{
var dt = element.GetSchemaInfo();
switch (dt.SchemaType.TypeCode)
{
case XmlTypeCode.Boolean:
return new XElement(element.Name,normalizeAttributes(element,havePSVI),(bool)element);
case XmlTypeCode.DateTime:
return new XElement(element.Name,(DateTime)element);
case XmlTypeCode.Decimal:
return new XElement(element.Name,(decimal)element);
case XmlTypeCode.Double:
return new XElement(element.Name,(double)element);
case XmlTypeCode.Float:
return new XElement(element.Name,(float)element);
case XmlTypeCode.HexBinary:
case XmlTypeCode.Language:
return new XElement(element.Name,((string)element).ToLower());
default:
return new XElement(element.Name,element.Nodes().Select(n => normalizeNode(n,havePSVI))
);
}
}
else
{
return new XElement(element.Name,havePSVI))
);
}
}
}

angularjs – element.bind和element.on之间有什么区别?
我一直在追踪angularjs指令的例子。我看到有人使用:
element.bind('click',callback)
而其他则使用:
element.on('click',callback)
任何关于两者之间有什么区别的线索呢?
您可以在这里了解更多有关差异的信息:jquery .bind() vs. .on()
与Elements()有什么区别?")
c# – XElement Nodes()与Elements()有什么区别?
XContainer.Nodes方法()
按文档顺序返回此元素或文档的子节点的集合.
备注
请注意,内容不包含属性.在LINQ to XML中,属性不被视为树的节点.它们是与元素关联的名称/值对.
XContainer.Elements方法()
按文档顺序返回此元素或文档的子元素的集合.
所以它看起来像Nodes()有一个限制,但那为什么它存在?使用节点()有任何可能的原因或优点吗?
解决方法
XDocument doc = XDocument.Parse("<root><el1 />some text<!-- comment --></root>");
foreach (var node in doc.Root.Nodes()) {
Console.WriteLine(node);
}
foreach (var element in doc.Root.Elements()) {
Console.WriteLine(element);
}
第二个循环(通过Elements())将只返回一个项目:< el />
然而,第一个循环还将返回文本节点(一些文本)和注释节点(<! - comment - >),因此您可以看到差异.
您可以在XNode类的documentaiton中看到XNode的其他后代.

C++中函数返回临时对象和本地对象的区别
C++中函数返回临时对象和本地对象的区别
在C++中如果函数返回值是对象的时候,那么该直接返回临时对象呢,还是先在函数体内构造好一个本地
对象,然后返回。如果可以直接返回临时对象,那么我们就返回临时对象来代替返回本地对象,因为这样代码
的效率会比返回本地对象的效率高。以下通过代码说明两者的区别 (更多讲解在注释中已说明):
1.返回本地对象代码示例:
#include <iostream>
using namespace std;
class A {
public:
int m_k;
int m_t;
A(int k, int t) :m_k(k), m_t(t) {
cout << "construct...." << endl;
}
~A() {
cout << "destruct...." << endl;
}
A(A &a) {
cout << "copy construct..." << endl;
}
};
// 如果函数返回值是一个对象,要考虑return语句的效率
A getObj() {
/************** 返回本地对象 ****************/
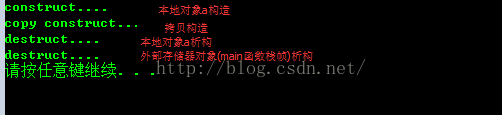
/* 以下这种写法实际上执行了三步:
1. 构造本地对象a
2. 调用拷贝构造,将本地对象a拷贝到外部存储器
3. 调用析构函数析构本地对象a
*/
/******************************************/
A a(3, 4);
return a;
}
int main() {
getObj(); // 外部存储单元
return 0;
}
运行结果:
2.返回临时对象代码示例:
#include <iostream>
using namespace std;
class A {
public:
int m_k;
int m_t;
A(int k, int t) :m_k(k), m_t(t) {
cout << "construct...." << endl;
}
~A() {
cout << "destruct...." << endl;
}
A(A &a) {
cout << "copy construct..." << endl;
}
};
// 如果函数返回值是一个对象,要考虑return语句的效率
A getObj() {
/*********** 直接返回临时对象 *************/
// 编译器直接把临时对象创建并初始化在外部
// 存储单元(主调函数的栈帧上)中,省去了拷
// 贝和析构的花费,提高了效率
/*****************************************/
return A(3, 4);
}
int main() {
getObj(); // 外部存储单元
return 0;
}
运行结果:

所以总的来说返回临时对象能减少多余的拷贝构造函数和析构函数的调用,从而提高了效率。
关于Node对象和Element对象的区别?和xml node element区别的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于.net – 比较XElement对象的最佳方法、angularjs – element.bind和element.on之间有什么区别?、c# – XElement Nodes()与Elements()有什么区别?、C++中函数返回临时对象和本地对象的区别的相关信息,请在本站寻找。
本文标签:




