在这篇文章中,我们将为您详细介绍JavaWeb爬网程序库的内容,并且讨论关于javaweb爬虫的相关问题。此外,我们还会涉及一些关于javaweb----模拟javaweb,首先web服务器、Java
在这篇文章中,我们将为您详细介绍Java Web爬网程序库的内容,并且讨论关于javaweb爬虫的相关问题。此外,我们还会涉及一些关于java web----模拟java web,首先web服务器、Java Web开发自学笔记二:新建一个java web 工程、java – 如何删除Chrome Web驱动程序和IE Web驱动程序的日志、java – 如何在Web爬网中获取内容的知识,以帮助您更全面地了解这个主题。
本文目录一览:- Java Web爬网程序库(javaweb爬虫)
- java web----模拟java web,首先web服务器
- Java Web开发自学笔记二:新建一个java web 工程
- java – 如何删除Chrome Web驱动程序和IE Web驱动程序的日志
- java – 如何在Web爬网中获取内容
")
Java Web爬网程序库(javaweb爬虫)
我想做一个基于Java的网络爬虫进行实验。我听说如果您是第一次使用Java编写Web爬虫,那是必须走的路。但是,我有两个重要问题。
我的程序如何“访问”或“连接”到网页?请简要说明。(我了解从硬件到软件的抽象层的基础,这里我对Java抽象感兴趣)
我应该使用哪些库?我假设我需要一个用于连接到网页的库,一个用于HTTP / HTTPS协议的库和一个用于HTML解析的库。
答案1
小编典典这是您的程序“访问”或“连接”到网页的方式。
URL url; InputStream is = null; DataInputStream dis; String line; try { url = new URL("http://stackoverflow.com/"); is = url.openStream(); // throws an IOException dis = new DataInputStream(new BufferedInputStream(is)); while ((line = dis.readLine()) != null) { System.out.println(line); } } catch (MalformedURLException mue) { mue.printStackTrace(); } catch (IOException ioe) { ioe.printStackTrace(); } finally { try { is.close(); } catch (IOException ioe) { // nothing to see here } }这将下载html页面的源代码。
对于HTML解析看到这个
还看看jSpider和jsoup

java web----模拟java web,首先web服务器
说明:模拟tomcat+Servlet给用户提供服务
1、创建web服务器
Server类(模拟tomcat服务)
public class Server {
public static void main(String[] args) {
try {
ServerSocket server = new ServerSocket(8080);
System.out.println("服务器启动成功");
//解析web.xml
ParseWebXml.parse();
System.out.println("开始解析web.xml");
while (true){
Socket socket = server.accept();
System.out.println(socket);
System.out.println("有一个客户端连接....");
new Thread(new ServerThread(socket)).start();
}
} catch (IOException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InstantiationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
}
}
}
class ServerThread implements Runnable{
private Socket socket;
private BufferedWriter bufferedWriter;
private InputStream inputStream;
public ServerThread(Socket socket) throws IOException {
this.socket = socket;
bufferedWriter = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
//bufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
inputStream = socket.getInputStream();
}
@Override
public void run() {
try {
//处理请求,封装请求参数
MyHttpRequest httpRequest = new MyHttpRequest(inputStream);
MyHttpResponse httpResponse = new MyHttpResponse();
String url = httpRequest.getUrl();
// 浏览器会自动请求/favicon.ico,我们给他返回一个图片
if("/favicon.ico".equals(url)){
this.fileReponse();
return;
}
//通过反射创建Servlet对象
String clz = WebContext.getClz(url);
if (clz!=null){
MyServlet servlet = (MyServlet) Class.forName(clz).getConstructor().newInstance();
servlet.service(httpRequest,httpResponse);
}else {
//return 404
httpResponse.sendMessage(bufferedWriter,404);
return;
}
//正文,响应给浏览器的
httpResponse.sendMessage(bufferedWriter,200);
} catch (InstantiationException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
try {
if (inputStream!=null){
inputStream.close();
System.out.println("inputStream 已关闭");
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void fileReponse(){
//获取图片大小
String fileName = this.getClass().getClassLoader().getResource("favicon.ico").getPath();//获取文件路径
long length = new File(fileName).length();
//使用字节输出流
OutputStream outputStream = null;
try {
outputStream = socket.getOutputStream();
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("HTTP/1.1 200 OK\r\n");
stringBuilder.append("Date:").append(new Date()).append("\r\n");
stringBuilder.append("Server:").append("Test Server/0.0.1;charset=GBK").append("\r\n");
stringBuilder.append("Content-type:").append("bytes").append("\r\n");
stringBuilder.append("accept-ranges:").append("image/x-icon").append("\r\n");
stringBuilder.append("Content-length:").append(length).append("\r\n").append("\r\n");
outputStream.write(stringBuilder.toString().getBytes());
InputStream fileInputStream = Thread.currentThread().getContextClassLoader().getResourceAsStream("favicon.ico");
int len = -1;
byte[] bytes = new byte[1024];
while ((len = fileInputStream.read(bytes))!=-1){
outputStream.write(bytes,0,len);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
if (outputStream!=null){
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}ParseWebXml (解析web.xml,相当于java web 中我们配置的web.xml被解析的实现原理)
public class ParseWebXml{
public static void parse() throws ParserConfigurationException, SAXException, IOException, ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
//创建一个SAX解析器工厂对象;
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
//通过工厂对象创建SAX解析器
SAXParser saxParser = saxParserFactory.newSAXParser();
//创建一个数据处理器(自己实现)
PersonHandle personHandle = new PersonHandle();
//开始解析
InputStream resourceAsStream = Thread.currentThread().getContextClassLoader().getResourceAsStream("web.xml");
saxParser.parse(resourceAsStream,personHandle);
personHandle.mappingEntityList.forEach(new Consumer<MappingEntity>() {
@Override
public void accept(MappingEntity mappingEntity) {
System.out.println(mappingEntity.name);
}
});
//personHandle.mappingEntityList.forEach((MappingEntity mappingEntity)->{System.out.println(mappingEntity);});
//personHandle.servletEntityList.forEach((ServletEntity servletEntity)->{System.out.println(servletEntity);});
WebContext.test1(personHandle.mappingEntityList, personHandle.servletEntityList);
//WebContext webContext = new WebContext(personHandle.mappingEntityList, personHandle.servletEntityList);
}
}
class PersonHandle extends DefaultHandler {
public List<MappingEntity> mappingEntityList = null;
public MappingEntity mappingEntity = null;
public List<ServletEntity> servletEntityList = null;
public ServletEntity servletEntity = null;
private String tag; //用来存储当前解析的标签名字
private boolean isMapping = false;
//开始解析文档时调用,只会执行一次
@Override
public void startDocument() throws SAXException {
super.startDocument();
mappingEntityList = new ArrayList<>();
servletEntityList = new ArrayList<>();
System.out.println("开始解析文档.....");
}
//结束解析文档时调用
@Override
public void endDocument() throws SAXException {
super.endDocument();
System.out.println("结束解析文档.....");
}
//每一个标签开始时调用
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
super.startElement(uri, localName, qName, attributes);
//获取每一个标签的person_id属性,如果没有返回null;
//System.out.println(attributes.getValue("person_id"));
if("servlet".equals(qName)){
servletEntity = new ServletEntity();
}
if("servlet-mapping".equals(qName)){
mappingEntity = new MappingEntity();
isMapping = true;
}
tag = qName;
}
//每一个标签结束时调用
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
super.endElement(uri, localName, qName);
if ("servlet".equals(qName)){
servletEntityList.add(servletEntity);
}
if("servlet-mapping".equals(qName)){
mappingEntityList.add(mappingEntity);
isMapping = false;
}
tag=null;
}
//当解析到标签中的内容的时候调用(换行也是文本内容)
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
super.characters(ch, start, length);
if(tag!=null){
if (!isMapping){
if ("servlet-name".equals(tag)){
servletEntity.name = new String(ch,start,length);
}
if ("servlet-class".equals(tag)){
servletEntity.className = new String(ch,start,length);
}
}else {
if ("servlet-name".equals(tag)){
mappingEntity.name = new String(ch,start,length);
}
if ("url-pattern".equals(tag)){
mappingEntity.pattern.add(new String(ch,start,length));
}
}
}
}
}MappingEntiry (封装了 servlet-name和url-pattern),xml解析的时候用这个对象进行封装
public class MappingEntity {
public String name;
public Set<String> pattern = new HashSet<>();
@Override
public String toString() {
return "MappingEntity{" +
"name=''" + name + ''\'''' +
", pattern=" + pattern +
''}'';
}
}ServletEntity(封装了servlet-name和servlet-class),xml解析的时候用这个进行封装
public class ServletEntity {
public String name;
public String className;
@Override
public String toString() {
return "ServletEntity{" +
"name=''" + name + ''\'''' +
", className=''" + className + ''\'''' +
''}'';
}
}WebContext (封装了请求对应的servelet,用于反射来实例化对应的servlet)
public class WebContext {
public static List<MappingEntity> mappingEntityList;
public static HashMap<String,String> mappingEntity_map = new HashMap<>();
public static List<ServletEntity> servletEntityList;
public static HashMap<String,String> servletEntity_map = new HashMap<>();
public static void test1(List<MappingEntity> mappingEntityList, List<ServletEntity> servletEntityList){
servletEntityList.forEach((ServletEntity servletEntity)->{servletEntity_map.put(servletEntity.name,servletEntity.className);});
for(MappingEntity m:mappingEntityList){
for (String str:m.pattern){
mappingEntity_map.put(str,m.name);
}
}
}
public static String getClz(String string){
String s = mappingEntity_map.get(string);
String s1 = servletEntity_map.get(s);
return s1;
}
}
解析请求,并封装请求的信息
public class MyHttpRequest {
private String url;
private InputStream inputStream;
//封装请求参数
private HashMap<String,String> hashMap = new HashMap<>();
//解析参数
public MyHttpRequest(InputStream inputStream) {
byte[] bytes = new byte[1024*10];
System.out.println("等待接收数据");
int len = 0;
try {
len = inputStream.read(bytes);
} catch (IOException e) {
e.printStackTrace();
}
//如果在读取就会堵塞,原因可能没有读取到一个结束标志,未解决(采取一次性读取)
//int read1 = inputStream.read();
//System.out.println("read1-------"+read1);
//浏览器会发送两个请求(其中有一个请求应该是/favicon.ico),这个/favicon.ico请求有时候读出不了数据返回-1(未解之谜)
if(len!=-1){
String s = new String(bytes, 0, len);
String method = s.substring(0, s.indexOf(" "));
url = s.substring(s.indexOf("/"), s.indexOf(" ",s.indexOf("/")));
//表示有参数
if (url.indexOf("?")!=-1){
String parameter = url.substring(url.indexOf("?")+1, url.lastIndexOf(""));
System.out.println(parameter);
//parameter类似username=1&password=2可以将他存储为HashMap中
String[] split1 = parameter.split("&");
for (String str:split1){
String[] split = str.split("=");
String[] strings = Arrays.copyOf(split, 2);
hashMap.put(strings[0],strings[1]);
}
url = url.substring(0,url.indexOf("?"));
}
// System.out.println(method);
// System.out.println(url);
}
System.out.println(len+"int");
}
public String getParmater(String key){
return hashMap.get(key);
}
public String getUrl(){
return url;
}
}用户响应信息
public class MyHttpResponse {
private StringBuilder content = new StringBuilder();
private StringBuilder header = new StringBuilder();
//正文长度一定要对,浏览器根据这个大小获得对应的数据.
private int len;
public void createHeader(int code) throws IOException {
switch (code) {
case 200: {
header.append("HTTP/1.1 200 OK\r\n");
break;
}
case 404: {
header.append("HTTP/1.0 404 NOT FOUND\r\n");
InputStream resourceAsStream = this.getClass().getClassLoader().getResourceAsStream("404.html");
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(resourceAsStream));
String msg;
while ((msg = bufferedReader.readLine())!=null){
System.out.println(msg);
content.append(msg);
}
len = content.toString().getBytes().length;
break;
}
case 500: {
header.append("HTTP/1.1 500 SERVER ERROR\r\n");
break;
}
}
//以下消息不是必须的,如果下面的这些信息不写,上面就必须写成stringBuilder.append("HTTP/1.1 200 ok\r\n\n");
header.append("Date:").append(new Date()).append("\r\n");
header.append("Server:").append("Test Server/0.0.1;charset=GBK").append("\r\n");
header.append("Content-type:").append("text/html").append("\r\n");
header.append("Content-length:").append(len).append("\r\n").append("\r\n"); //和正文之间必须有两个换行
}
public void print(String str) {
content.append(str);
len += str.getBytes().length;
}
public void sendMessage(BufferedWriter bufferedWriter, int code) {
try {
this.createHeader(code);
bufferedWriter.write(header.toString());
bufferedWriter.write(content.toString());
bufferedWriter.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (bufferedWriter != null) {
try {
bufferedWriter.close();
System.out.println("bufferedWriter 已关闭");
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}所有的servlet必须实现这个接口
public interface MyServlet {
public void service(MyHttpRequest myHttpRequest, MyHttpResponse myHttpReponser);
}
LoginServlet
public class LoginServlet implements MyServlet{
@Override
public void service(MyHttpRequest myHttpRequest, MyHttpResponse myHttpReponser) {
myHttpReponser.print("<!DOCTYPE html>");
myHttpReponser.print("<html lang=\"en\">");
myHttpReponser.print("<head>");
myHttpReponser.print("<meta charset=\"UTF-8\">");
myHttpReponser.print("<title>测试</title>");
myHttpReponser.print("</head>");
myHttpReponser.print("<body>");
myHttpReponser.print("<h1>servlet</h1>");
myHttpReponser.print("</body>");
myHttpReponser.print("</html>");
}
}
RegisterServlet
public class RegisterServlet implements MyServlet {
@Override
public void service(MyHttpRequest myHttpRequest, MyHttpResponse myHttpReponser) {
myHttpReponser.print("<!DOCTYPE html>");
myHttpReponser.print("<html lang=\"en\">");
myHttpReponser.print("<head>");
myHttpReponser.print("<meta charset=\"UTF-8\">");
myHttpReponser.print("<title>title</title>");
myHttpReponser.print("</head>");
myHttpReponser.print("<body>");
myHttpReponser.print("<h1>注册成功</h1>");
myHttpReponser.print("</body>");
myHttpReponser.print("</html>");
}
}
resources资源
404.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
当输入的网址不存在的时候,自动定位到404html页面
</body>
</html>favicon.ioc
网址https://www.cnblogs.com/favicon.ico 自己下载
web.xml
<?xml version="1.0" encoding="UTF-8"?>
<web-app>
<!--配置servlet-->
<servlet>
<!--配置servlet类路径,servlet-name任意,servlet-class是一开始创建的servlet类的路径-->
<servlet-name>ServletDemo</servlet-name>
<servlet-class>com.zy.servlet.LoginServlet</servlet-class>
</servlet>
<!--servlet-name必须和上面的名字一样,url-pattern配置访问的路由 localhost:8080/my-->
<servlet-mapping>
<servlet-name>ServletDemo</servlet-name>
<url-pattern>/</url-pattern>
<url-pattern>/login</url-pattern>
</servlet-mapping>
<servlet>
<!--配置servlet类路径,servlet-name任意,servlet-class是一开始创建的servlet类的路径-->
<servlet-name>RegisterServlet</servlet-name>
<servlet-class>com.zy.servlet.RegisterServlet</servlet-class>
</servlet>
<!--servlet-name必须和上面的名字一样,url-pattern配置访问的路由 localhost:8080/my-->
<servlet-mapping>
<servlet-name>RegisterServlet</servlet-name>
<url-pattern>/register</url-pattern>
</servlet-mapping>
</web-app>
代码并不完整,只是大体实现功能(可能有一些bug)
git地址 https://github.com/zhengyanzy/Web_Server
上面编程过程中遇到的问题,未解决
1、如果循环recv,一般读取到数据尾部返回-1,但是服务器却会堵塞在最后。
2、在监听开始之后,用浏览器访问服务器,服务器的监听代码如下,accept为阻塞模式的但是总会多余的接收到一个请求(浏览器中发现只有一个请求,但是accept到了),从连接中读取recv返回值为-1(recv会堵塞很长时间,然后返回一个-1),我猜可能是浏览器自带发送/favicon.ico 请求,有时候通过开发者模式确实可以看到浏览器发送了一个/favicon.ico请求,但是有时候却看不到(屏蔽了?)

Java Web开发自学笔记二:新建一个java web 工程
之前看到红薯大哥说过,不推荐使用myEclipse和Eclipse的JEE版本。但是纯Eclipse的环境,对我这个0基础的java入门者来说实在吃力。
myEclipse固然强大,但是感觉体积庞大,而且收费的,我有不喜欢用破解的。所以最后选择了Eclipse IDE for Java EE Developers。
Eclipse真是好哇,直接解压即可运行,比VS好多了,以前搞.NET的时候。装个VS要好久,烦死人。
现在开始记录新建一个web工程。
新建一个web工程:File->New->Dynamic Web Project

这里需要配置下项目的runtime,点击“New Runtime”,选择tomcat7(因为之前装的是7),然后制定下tomcat的目录,确定就行了。
关于Dynamic web module version这里选择2.4,因为我看了下struts示例里面的web.xml,用的是2.4的版本,所以这里也就选择2.4了。点”Next>“

这个暂时我不知道什么用...以后补充吧,继续"Next>"吧
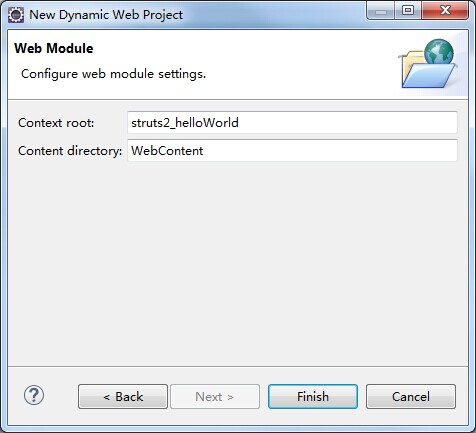
这个应该也不用怎么改吧,咱就先Finish了
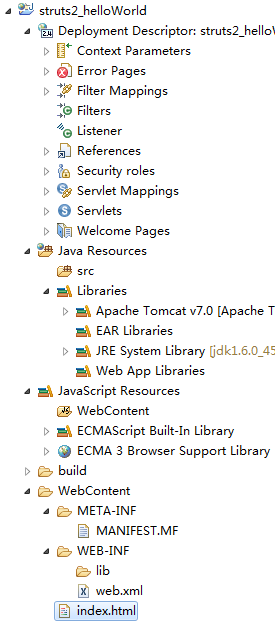
整个项目的结构。至于这些目录是干啥的以后慢慢记录。有些还不太清楚。
这里就简单记录一个WEB-INF:这个玩意儿很关键,有点像.NET里面bin文件夹。
WEB-INF/lib/里面放一些项目中需要使用的类库,目前为止我知道的就是一些jar的包。
web.xml就更好理解了。就相当于web.config当前web应用的一些配置信息。比如在自动创建的web.xml中就包含了默认文档的相关配置。
index.html是我新建的,然后尝试运行下吧

此时会弹出一个,Run on server 的对话框
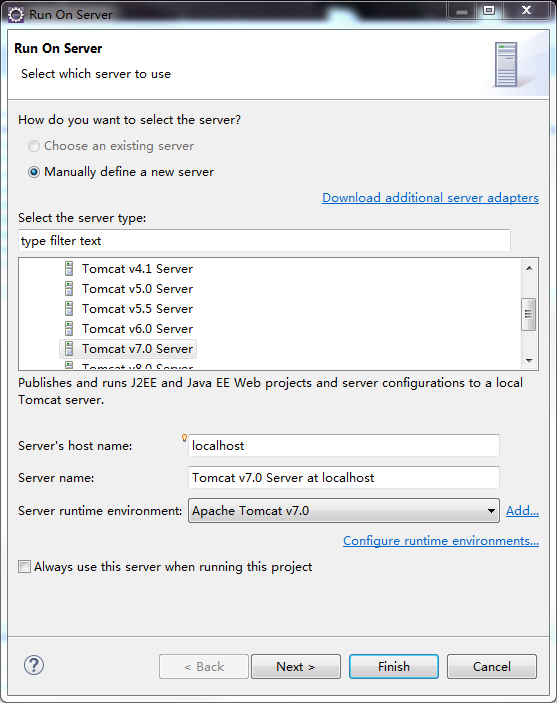
选择Always use this server when running this project,不然你每次运行都要弹出这个玩意儿。其他不做修改。
这会儿就能在Eclipse里面能浏览运行页面

我换了个index.jsp试试,可以运行。
Eclipse在这里自动会把当前项目名称当做二级目录来运行,这个不错,还是比较方便的。

java – 如何删除Chrome Web驱动程序和IE Web驱动程序的日志
WebDriver driver=new InternetExplorerDriver();
在这种情况下,它显示日志
Started InternetExplorerDriver server (32-bit) 2.24.2.0 Listening on port 41437
而对于铬
WebDriver driver =new ChromeDriver();
而日志是
Started ChromeDriver port=42458 version=21.0.1180.4 log=G:\Workspace_Selenium\WebTestSelenium_ToResolveTheReview\chromedriver.log
寻求帮助
解决方法
Logger shutUp = Logger.getLogger("");
shutUp.setLevel(Level.WARNING);
做的工作.那应该只输出警告.当然,您可以使用Level.SEVERE使其仅输出错误,甚至使Level.OFF绝对安静.

java – 如何在Web爬网中获取内容

嗨!我正在尝试为蜘蛛算法实现这个伪代码来探索网络.
我需要一些关于伪代码下一步的想法:“使用SpiderLeg来获取内容”,
我在另一个类SpiderLeg中有一个方法,它有一个方法来获取该网页的所有URL,但想知道如何在这个类中使用它?
// method to crawl web and print out all URLs that the spider visit
public List<String> crawl(String url,String keyword) throws IOException{
String currentUrl;
// while list of unvisited URLs is not empty
while(unvisited != null ){
// take URL from list
currentUrl = unvisited.get(0);
//using spiderLeg to fetch content
SpiderLeg leg = new SpiderLeg();
}
return unvisited;
}
干杯!!将尝试…但是我尝试了这个没有使用队列D.S,它几乎工作,但不会在搜索某些单词时停止程序.
当它发现它只显示网页的链接而不是它找到该单词的所有特定URL.
想知道可以这样做吗?
private static final int MAX_PAGES_TO_SEARCH = 10;
private Set<String> pagesVisited = new HashSet<String>();
private List<String> pagesToVisit = new LinkedList<String>();
public void crawl(String url,String searchWord)
{
while(this.pagesVisited.size() < MAX_PAGES_TO_SEARCH)
{
String currentUrl;
SpiderLeg leg = new SpiderLeg();
if(this.pagesToVisit.isEmpty())
{
currentUrl = url;
this.pagesVisited.add(url);
}
else
{
currentUrl = this.nextUrl();
}
leg.getHyperlink(currentUrl);
boolean success = leg.searchForWord(searchWord);
if(success)
{
System.out.println(String.format("**Success** Word %s found at %s",searchWord,currentUrl));
break;
}
this.pagesToVisit.addAll(leg.getLinks());
}
System.out.println("\n**Done** Visited " + this.pagesVisited.size() + " web page(s)");
}
解决方法
将URL添加到队列的条件取决于您,但通常您需要将URL与种子URL的距离保持为停止点,这样您就不会永远遍历Web.这些规则还可能包含您对搜索感兴趣的细节,以便您只添加相关的URL.
我们今天的关于Java Web爬网程序库和javaweb爬虫的分享就到这里,谢谢您的阅读,如果想了解更多关于java web----模拟java web,首先web服务器、Java Web开发自学笔记二:新建一个java web 工程、java – 如何删除Chrome Web驱动程序和IE Web驱动程序的日志、java – 如何在Web爬网中获取内容的相关信息,可以在本站进行搜索。
本文标签:




