关于JNI-具有ByteBuffer参数的本机方法和jnibytebuffer的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于.net–在哪里IBufferbyte[].AsBuffer的
关于JNI-具有ByteBuffer参数的本机方法和jni bytebuffer的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于.net – 在哪里IBuffer byte [] .AsBuffer的扩展方法?、Buffer的创建及使用源码分析——ByteBuffer为例、ByteBuffer、ByteBuffer / IntBuffer / ShortBuffer Java类是否快速?等相关知识的信息别忘了在本站进行查找喔。
本文目录一览:- JNI-具有ByteBuffer参数的本机方法(jni bytebuffer)
- .net – 在哪里IBuffer byte [] .AsBuffer的扩展方法?
- Buffer的创建及使用源码分析——ByteBuffer为例
- ByteBuffer
- ByteBuffer / IntBuffer / ShortBuffer Java类是否快速?
")
JNI-具有ByteBuffer参数的本机方法(jni bytebuffer)
我有一个方法:
public native void doSomething(ByteBuffer in, ByteBuffer out);由javah C / C ++头生成的此方法是:
JNIEXPORT void JNICALL Java__MyClass_doSomething (JNIEnv *, jobject, jobject, jobject, jint, jint);如何从jobject(即ByteBuffer实例)获取数据数组?
答案1
小编典典假设您使用ByteBuffer.allocateDirect()分配了ByteBuffer,则可以使用GetDirectBufferAddress
jbyte* bbuf_in; jbyte* bbuf_out;bbuf_in = (*env)->GetDirectBufferAddress(env, buf1); bbuf_out= (*env)->GetDirectBufferAddress(env, buf2);![.net – 在哪里IBuffer byte [] .AsBuffer的扩展方法?](http://www.gvkun.com/zb_users/upload/2025/01/3ce96d34-f9c7-4831-8f22-4df07b9d2bb21737810347109.jpg ".net – 在哪里IBuffer byte [] .AsBuffer的扩展方法?")
.net – 在哪里IBuffer byte [] .AsBuffer的扩展方法?
VS对象浏览器是您的朋友 – 请务必相应地设置框架切换器.对于Metro应用程序中可用的.NET库,您需要“.NET Framework Core 4.5”.

Buffer的创建及使用源码分析——ByteBuffer为例
目录
- Buffer概述
- Buffer的创建
- Buffer的使用
- 总结
- 参考资料
Buffer概述
注:全文以ByteBuffer类为例说明
在Java中提供了7种类型的Buffer,每一种类型的Buffer根据分配内存的方式不同又可以分为
直接缓冲区和非直接缓冲区。
Buffer的本质是一个定长数组,并且在创建的时候需要指明Buffer的容量(数组的长度)。
而这个数组定义在不同的Buffer当中。例如ByteBuffer的定义如下:
public abstract class ByteBuffer
extends Buffer
implements Comparable<ByteBuffer>
{
// These fields are declared here rather than in Heap-X-Buffer in order to
// reduce the number of virtual method invocations needed to access these
// values, which is especially costly when coding small buffers.
//
//在这里定义Buffer对应的数组,而不是在Heap-X-Buffer中定义
//目的是为了减少访问这些纸所需的虚方法调用,但是对于小的缓冲区,代价比较高
final byte[] hb; // Non-null only for heap buffers
final int offset;
boolean isReadOnly; // Valid only for heap buffers
// Creates a new buffer with the given mark, position, limit, capacity,
// backing array, and array offset
//
ByteBuffer(int mark, int pos, int lim, int cap, // package-private
byte[] hb, int offset)
{
//调用父类Buffer类的构造函数构造
super(mark, pos, lim, cap);
this.hb = hb;
this.offset = offset;
}
// Creates a new buffer with the given mark, position, limit, and capacity
//
ByteBuffer(int mark, int pos, int lim, int cap) { // package-private
this(mark, pos, lim, cap, null, 0);
}
......
}
尽管数组在这里定义,但是这个数组只对非直接缓冲区有效。
ByteBuffer类有两个子类分别是:DirectByteBuffer(直接缓冲区类)和HeapByteBuffer(非直接缓冲区)。
但是这两个类并不能直接被访问,因为这两个类是包私有的,而创建这两种缓冲区的方式就是通过调用Buffer
类提供的创建缓冲区的静态方法:allocate()和allocateDirect()。
Buffer的创建
Buffer要么是直接的要么是非直接的,非直接缓冲区的内存分配在JVM内存当中,
而直接缓冲区使用物理内存映射,直接在物理内存中分配缓冲区,既然分配内存的地方不一样,
BUffer的创建方式也就不一样。
非直接缓冲区内存的分配
创建非直接缓冲区可以通过调用allocate()方法,这样会将缓冲区建立在JVM内存(堆内存)当中。
allocate()方法是一个静态方法,因此可以直接使用类来调用。
具体的创建过程如下:
/**
* Allocates a new byte buffer.
*
* <p> The new buffer''s position will be zero, its limit will be its
* capacity, its mark will be undefined, and each of its elements will be
* initialized to zero. It will have a {@link #array backing array},
* and its {@link #arrayOffset array offset} will be zero.
*
* @param capacity
* The new buffer''s capacity, in bytes
*
* @return The new byte buffer
*
* @throws IllegalArgumentException
* If the <tt>capacity</tt> is a negative integer
*/
//分配一个缓冲区,最后返回的其实是一个HeapByteBuffer的对象
public static ByteBuffer allocate(int capacity) {
if (capacity < 0)
throw new IllegalArgumentException();
//这里调用到HeapByteBuffer类的构造函数,创建非直接缓冲区
//并将需要的Buffer容量传递
//从名称也可以看出,创建的位置在堆内存上。
return new HeapByteBuffer(capacity, capacity);
}
HeapByteBuffer(capacity, capacity)用于在堆内存上创建一个缓冲区。
该方法优惠调回ByteBuffer构造方法,HeapByteBuffer类没有任何的字段,他所需的字段全部定义在父类当中。
源码分析如下:
HeapByteBuffer(int cap, int lim) {
// 调用父类的构造方法创建非直接缓冲区 // package-private
// 调用时根据传递的容量创建了一个数组。
super(-1, 0, lim, cap, new byte[cap], 0);
}
//ByteBuffer类的构造方法,也就是上面代码调用的super方法
ByteBuffer(int mark, int pos, int lim, int cap, // package-private
byte[] hb, int offset)
{
//接着调用Buffer类的构造方法给用于操作数组的四个属性赋值
super(mark, pos, lim, cap);
//将数组赋值给ByteBuffer的hb属性,
this.hb = hb;
this.offset = offset;
}
//Buffer类的构造方法
Buffer(int mark, int pos, int lim, int cap) { // package-private
//容量参数校验,原始容量不能小于0
if (cap < 0)
throw new IllegalArgumentException("Negative capacity: " + cap);
//设定容量
this.capacity = cap;
//这里的lim从上面传递过来的时候就是数组的容量
//limit在写模式下默认可操作的范围就是整个数组
//limit在读模式下可以操作的范围是数组中写入的元素
//创建的时候就是写模式,是整个数组
limit(lim);
//初始的position是0
position(pos);
//设定mark的值,初始情况下是-1,因此有一个参数校验,
//-1是数组之外的下标,不可以使用reset方法使得postion到mark的位置。
if (mark >= 0) {
if (mark > pos)
throw new IllegalArgumentException("mark > position: ("
+ mark + " > " + pos + ")");
this.mark = mark;
}
}
在堆上创建缓冲区还是很简单的,本质就是创建了一个数组以及一些用于辅助操作数组的其他属性。
最后返回的其实是一个HeapByteBuffer的对象,因此对其的后续操作大多应该是要调用到HeapByteBuffer类中
直接缓冲区的创建
创建直接俄缓冲区可以通过调用allocateDirect()方法创建,源码如下:
/**
* Allocates a new direct byte buffer.
*
* <p> The new buffer''s position will be zero, its limit will be its
* capacity, its mark will be undefined, and each of its elements will be
* initialized to zero. Whether or not it has a
* {@link #hasArray backing array} is unspecified.
*
* @param capacity
* The new buffer''s capacity, in bytes
*
* @return The new byte buffer
*
* @throws IllegalArgumentException
* If the <tt>capacity</tt> is a negative integer
*/
//创建一个直接缓冲区
public static ByteBuffer allocateDirect(int capacity) {
//同非直接缓冲区,都是创建的子类的对象
//创建一个直接缓冲区对象
return new DirectByteBuffer(capacity);
}
DirectByteBuffer(capacity)是DirectByteBuffer的构造函数,具体代码如下:
DirectByteBuffer(int cap) { // package-private
//初始化mark,position,limit,capacity
super(-1, 0, cap, cap);
//内存是否按页分配对齐,是的话,则实际申请的内存可能会增加达到对齐效果
//默认关闭,可以通过-XX:+PageAlignDirectMemory控制
boolean pa = VM.isDirectMemoryPageAligned();
//获取每页内存的大小
int ps = Bits.pageSize();
//分配内存的大小,如果是按页对其的方式,需要加一页内存的容量
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//预定内存,预定不到则进行回收堆外内存,再预定不到则进行Full gc
Bits.reserveMemory(size, cap);
long base = 0;
try {
//分配堆外内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
/**
*创建堆外内存回收Cleanner,Cleanner对象是一个PhantomFerence幽灵引用,
*DirectByteBuffer对象的堆内存回收了之后,幽灵引用Cleanner会通知Reference
*对象的守护进程ReferenceHandler对其堆外内存进行回收,调用Cleanner的
*clean方法,clean方法调用的是Deallocator对象的run方法,run方法调用的是
*unsafe.freeMemory回收堆外内存。
*堆外内存minor gc和full gc的时候都不会进行回收,而是ReferenceHandle守护进程调用
*cleanner对象的clean方法进行回收。只不过gc 回收了DirectByteBuffer之后,gc会通知Cleanner进行回收
*/
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
由于是在物理内存中直接分配一块内存,而java并不直接操作内存需要交给JDK中native方法的实现分配
Bits.reserveMemory(size, cap)预定内存源码,预定内存,说穿了就是检查堆外内存是否足够分配
// These methods should be called whenever direct memory is allocated or
// freed. They allow the user to control the amount of direct memory
// which a process may access. All sizes are specified in bytes.
// 在分配或释放直接内存时应当调用这些方法,
// 他们允许用控制进程可以访问的直接内存的数量,所有大小都以字节为单位
static void reserveMemory(long size, int cap) {
//memoryLimitSet的初始值为false
//获取允许的最大堆外内存赋值给maxMemory,默认为64MB
//可以通过-XX:MaxDirectMemorySize参数控制
if (!memoryLimitSet && VM.isBooted()) {
maxMemory = VM.maxDirectMemory();
memoryLimitSet = true;
}
// optimist!
//理想情况,maxMemory足够分配(有足够内存供预定)
if (tryReserveMemory(size, cap)) {
return;
}
final JavaLangRefAccess jlra = SharedSecrets.getJavaLangRefAccess();
// retry while helping enqueue pending Reference objects
// which includes executing pending Cleaner(s) which includes
// Cleaner(s) that free direct buffer memory
// 这里会尝试回收堆外空间,每次回收成功尝试进行堆外空间的引用
while (jlra.tryHandlePendingReference()) {
if (tryReserveMemory(size, cap)) {
return;
}
}
// trigger VM''s Reference processing
// 依然分配失败尝试回收堆空间,触发full gc
//
System.gc();
// a retry loop with exponential back-off delays
// (this gives VM some time to do it''s job)
boolean interrupted = false;
// 接下来会尝试最多9次的内存预定,应该说是9次的回收堆外内存失败的内存预定
// 如果堆外内存回收成功,则直接尝试一次内存预定,只有回收失败才会sleep线程。
// 每次预定的时间间隔为1ms,2ms,4ms,等2的幂递增,最多256ms。
try {
long sleepTime = 1;
int sleeps = 0;
while (true) {
// 尝试预定内存
if (tryReserveMemory(size, cap)) {
return;
}
if (sleeps >= MAX_SLEEPS) {
break;
}
// 预定内存失败则进行尝试释放堆外内存,
// 累计最高可以允许释放堆外内存9次,同时sleep线程,对应时间以2的指数幂递增
if (!jlra.tryHandlePendingReference()) {
try {
Thread.sleep(sleepTime);
sleepTime <<= 1;
sleeps++;
} catch (InterruptedException e) {
interrupted = true;
}
}
}
// no luck
throw new OutOfMemoryError("Direct buffer memory");
} finally {
if (interrupted) {
// don''t swallow interrupts
Thread.currentThread().interrupt();
}
}
}
为什么调用System.gc?引用自JVM原始码分析之堆外内存完全解读
既然要调用System.gc,那肯定是想通过触发一次gc操作来回收堆外部内存,不过我想先说的是堆外部内存不会对gc造成什么影响(这里的System.gc除外),但是堆外层内存的回收实际上依赖于我们的gc机制,首先我们要知道在java尺寸和我们在堆外分配的这块内存分配的只有与之关联的DirectByteBuffer对象了,它记录了这块内存的基地址以及大小,那么既然和gc也有关,那就是gc能通过DirectByteBuffer对象来间接操作对应的堆外部内存了。DirectByteBuffer对象在创建的时候关联了一个PhantomReference,说到PhantomReference时被回收的,它不能影响gc方法,但是gc过程中如果发现某个对象只有只有PhantomReference引用它之外,并没有其他的地方引用它了,那将会把这个引用放到java.lang.ref .Reference.pending物理里,在gc完成的时候通知ReferenceHandler这个守护线程去执行一些后置处理,而DirectByteBuffer关联的PhantomReference是PhantomReference的一个子类,在最终的处理里会通过Unsafe的免费接口来释放DirectByteBuffer对应的堆外内存块
Buffer的使用
切换读模式flip()
切换为读模式的代码分厂简单,就是使limit指针指向buffer中最后一个插入的元素的位置,即position,指针的位置。
而position代表操作的位置,那么从0开始,所以需要将position指针归0.源码如下:
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
get()读取
get()读取的核心是缓冲区对应的数组中取出元素放在目标数组中(get(byte[] dst)方法是有一个参数的,传入的就是目标数组)。
public ByteBuffer get(byte[] dst) {
return get(dst, 0, dst.length);
}
public ByteBuffer get(byte[] dst, int offset, int length) {
checkBounds(offset, length, dst.length);
if (length > remaining())
throw new BufferUnderflowException();
int end = offset + length;
//shiyongfor循环依次放入目标数组中
for (int i = offset; i < end; i++)
// get()对于直接缓冲区和非直接缓冲区是不一样的,所以交由子类实现。
dst[i] = get();
return this;
}
rewind()重复读
既然要重复读就需要把position置0了
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
clear()清空缓冲区与compact()方法
public final Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}
在clear()方法中,仅仅是将三个指针还原为创建时的状态供后续写入,但是之前写入的数据并没有被删除,依然可以使用get(int index)获取
但是有一种情况,缓冲区已经满了还想接着写入,但是没有读取完又不能从头开始写入该怎么办,答案是compact()方法
非直接缓冲区:
public ByteBuffer compact() {
//将未读取的部分拷贝到缓冲区的最前方
System.arraycopy(hb, ix(position()), hb, ix(0), remaining());
//设置position位置到缓冲区下一个可以写入的位置
position(remaining());
//设置limit是最大容量
limit(capacity());
//设置mark=-1
discardMark();
return this;
}
直接缓冲区:
public ByteBuffer compact() {
int pos = position();
int lim = limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
//调用native方法拷贝未读物部分
unsafe.copyMemory(ix(pos), ix(0), (long)rem << 0);
//设定指针位置
position(rem);
limit(capacity());
discardMark();
return this;
}
mark()标记位置以及reset()还原
mark()标记一个位置,准确的说是当前的position位置
public final Buffer mark() {
mark = position;
return this;
}
标记了之后并不影响写入或者读取,position指针从这个位置离开再次想从这个位置读取或者写入时,
可以使用reset()方法
public final Buffer reset() {
int m = mark;
if (m < 0)
throw new InvalidMarkException();
position = m;
return this;
}
总结
本文其实还有很多不清楚的地方,对于虚引用以及引用队列的操作还不是很清楚去,对于虚引用和堆外内存的回收的关系源码其实也没看到,
需要再看吧,写这篇的目的其实最开始就是想研究看看直接缓冲区内存的分配,没想到依然糊涂,后面填坑。路过的大佬也就指导下虚引用这部分相关的东西,谢谢。
参考资料
- JVM原始码分析之堆外内存完全解读
- Java Nio 之直接内存
- Java直接内存分配与释放原理

ByteBuffer
ByteBuffer 是 NIO 中用的最多的缓存,ByteBuffer 是一个抽象类,HeapByteBuffer 继承了 ByteBuffer,DirectByteBuffer 继承抽象类 MappedByteBuffer,抽象类 MappedByteBuffer 继承了 ByteBuffer
DirectByteBuffer 使用 Native 函数直接分配堆外内存,然后对一个存储在 Java 堆里面的该对象作为这块内存的引用操作,这样在一些地方显著提高了性能,避免了 Java 堆和 Native 堆中来回的复制 。由于他是使用 unsafe 进行堆外实现,所以我们这里只说一下 HeapByteBuffer 的实现。

mark:标志位,对当前 position 做标志。
position:从哪个位置开始读写元素,每次读或者写 position+1
limit:表示缓存中实际存了多少元素,当 limit 和 position 相等时表示缓存中数据满了或者空了。
capacity:缓存区的容量,在 ByteBuffer 创建的时候定好的并且不能修改。 ByteBuffer.allocate (128); 则 capacity = 128。
创建缓冲区:其实就是在堆内存中创建一个 byte [] 数组
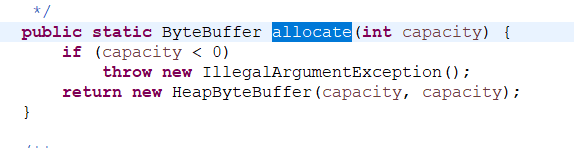
HeapByteBuffer 调用父类的方法 super (mark,post,lim,cap)

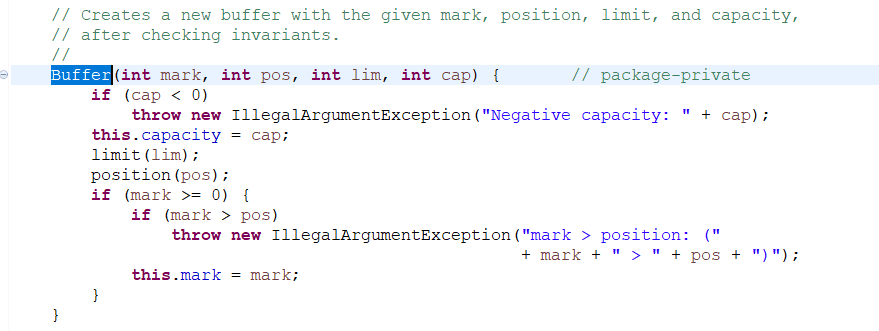
如果 cap 容量小于零抛出异常,反之设置容量值,lim 值,pos 值 分别调用 limit (lim) 和 position (pos) 方法

初始化 limit 的值。如果 limit 的值 > 缓存容量或者 limit 的值小于 0 就抛出异常,否则设置 limit 的值,如果 position>limit 则将 position 的值设置为 limit,如果 mark 的值大于 limit 将 limit 的值设置为初始值 - 1.

初始化 position 的值 就不详细说了,看就能看懂的吧
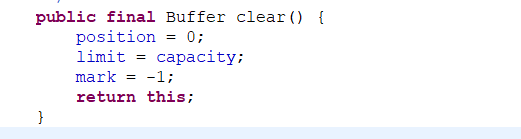
clear () 方法 不会把它里的内容清除,只是重置了 position ,limit,mark 的值
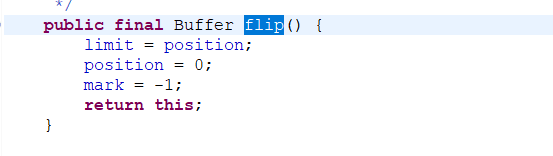
在每次写完数据准备读的时候都会调用该方法,意思就是将一个处于存数据状态的缓冲区变为一个处于准备取数据的
自己的理解:在存数据的时候 postion 指向的都是要存的下一个地址,该地址是一个空的;而在取数据的时候 postion 指向的是下一个要读取的地址,该地址是有值的。
public static void main(String[] args) { ByteBuffer byteBuffer = ByteBuffer.allocate(3);//[pos=2 lim=3 cap=3] byteBuffer.put((byte) 1);//[pos=1 lim=3 cap=3] byteBuffer.put((byte) 2);//[pos=2 lim=3 cap=3] System.out.println(byteBuffer); System.out.println(byteBuffer.remaining() + "************"); System.out.println(byteBuffer.get() + ":111111111111111");//取的是pos=2位置的元素,该位置没有元素。取完之后把pos+1 System.out.println(byteBuffer);//[pos=3 lim=3 cap=3] System.out.println(byteBuffer.remaining()); byteBuffer.put(2, (byte) 3); System.out.println(byteBuffer); }
结果是:
java.nio.HeapByteBuffer[pos=2 lim=3 cap=3]
1************
0:111111111111111
java.nio.HeapByteBuffer[pos=3 lim=3 cap=3]
0
java.nio.HeapByteBuffer[pos=3 lim=3 cap=3]
压缩缓冲区 compact()
public static void main(String[] args) { ByteBuffer byteBuffer = ByteBuffer.allocate(10);//[pos=2 lim=3 cap=3] byteBuffer.put((byte) 1);//[pos=1 lim=3 cap=3] byteBuffer.put((byte) 2); byteBuffer.put((byte) 3); byteBuffer.put((byte) 4); System.out.println(byteBuffer); System.out.println(byteBuffer.remaining()); byteBuffer.compact(); System.out.println(byteBuffer);
结果是:
java.nio.HeapByteBuffer[pos=4 lim=10 cap=10]
6
java.nio.HeapByteBuffer[pos=6 lim=10 cap=10]

ByteBuffer / IntBuffer / ShortBuffer Java类是否快速?
我正在研究Android应用程序(显然是Java),最近我更新了我的UDP阅读器代码.在这两个版本中,我设置了一些缓冲区并接收UDP数据包:
byte[] buf = new byte[10000];
short[] soundData = new short[1000];
DatagramPacket packet = new DatagramPacket (buf,buf.length);
socket.receive (packet);
在初始版本中,我将数据一次放回一个字节(实际上是16个PCM音频数据):
for (int i = 0; i < count; i++)
soundData[i] = (short) (((buf[k++]&0xff) << 8) + (buf[k++]&0xff));
在更新的版本中,我使用了一些我开始时不知道的很酷的Java工具:
bBuffer = ByteBuffer.wrap (buf);
sBuffer = bBuffer.asShortBuffer();
sBuffer.get (soundData,count);
在这两种情况下,“计数”正在正确填充(我检查过).然而,我的流媒体音频似乎出现了新的问题 – 也许它的处理速度不够快 – 这对我来说没有任何意义.显然,缓冲区代码正在编译成三个以上的JVM代码语句,但是当我开始这个时,第二个版本会比第一个版本更快,这似乎是一个合理的假设.
很明显,我并不是说我的代码必须使用Java NIO缓冲区,但至少乍一看,它看起来似乎很难做到这一点.
任何人都有一个快速,简单的Java UDP阅读器的建议,以及是否有一个普遍接受的“最佳方式”?
谢谢,
R.
有理由使用速度以外的实用程序对象:方便性,安全性等.
在这种特殊情况下测试差异的最佳方法是实际测量它.尝试使用大型数据集的两种方法并计时.然后,您可以决定在这种情况下是否值得获益.
您还可以使用Android的分析器来查看问题的确切位置.见TraceView.
今天的关于JNI-具有ByteBuffer参数的本机方法和jni bytebuffer的分享已经结束,谢谢您的关注,如果想了解更多关于.net – 在哪里IBuffer byte [] .AsBuffer的扩展方法?、Buffer的创建及使用源码分析——ByteBuffer为例、ByteBuffer、ByteBuffer / IntBuffer / ShortBuffer Java类是否快速?的相关知识,请在本站进行查询。
本文标签:




