如果您想了解Swift没有将变量传递给PHPWeb服务来查询我的SQL数据库的相关知识,那么本文是一篇不可错过的文章,我们将为您提供关于41-数据库-pymysql41-数据库-pymysql-DBU
如果您想了解Swift 没有将变量传递给 PHP Web 服务来查询我的 SQL 数据库的相关知识,那么本文是一篇不可错过的文章,我们将为您提供关于41 - 数据库-pymysql41 - 数据库-pymysql-DBUtils、AJAX 没有将变量传递给 PHP 文件、Azure Synapse、Azure SQL 数据库、Azure 托管实例和本地 SQL Server 中的跨数据库查询、bat脚本备份SQL Server 数据库 - cmd命令备份SQL Server 数据库的有价值的信息。
本文目录一览:- Swift 没有将变量传递给 PHP Web 服务来查询我的 SQL 数据库
- 41 - 数据库-pymysql41 - 数据库-pymysql-DBUtils
- AJAX 没有将变量传递给 PHP 文件
- Azure Synapse、Azure SQL 数据库、Azure 托管实例和本地 SQL Server 中的跨数据库查询
- bat脚本备份SQL Server 数据库 - cmd命令备份SQL Server 数据库

Swift 没有将变量传递给 PHP Web 服务来查询我的 SQL 数据库
如何解决Swift 没有将变量传递给 PHP Web 服务来查询我的 SQL 数据库
我有一个 PHP Web 服务,如果我直接将值硬编码到 sql 查询中,它可以向我的数据库中插入一个新行。但是当我尝试使用从我的 Swift 函数传递给 PHP 脚本的变量来执行此操作时,它会崩溃。我已经在我的 Swift 中添加了打印语句,所以我确信这些值被正确地传递给了函数,并且错误必须在之后的行中。
PHP:我已经用硬编码值 - Carrots 注释了 sql 查询行,但是这个查询确实有效,所以我认为 PHP->sql 工作正常,但 Swift->PHP 是问题所在。
<?PHP
$servername = "localhost";
$username = "*******";
$password = "*****";
$dbname = "*******";
$product_name = $_POST[''product_name''] ?? ''DefaultProduct'';
$code = $_POST[''code''] ?? ''DefaultCode'';
$Brands = $_POST[''brands''] ?? ''1'';
$Comp1Mat = $_POST[''Comp1Mat''] ?? ''DefaultMat'';
$Comp2Mat = $_POST[''Comp2Mat''] ?? ''1'';
// Create connection
$conn = new MysqLi($servername,$username,$password,$dbname);
// Check connection
if ($conn->connect_error) {
die("Connection Failed: " . $conn->connect_error);
}
//$sql = "INSERT INTO Products (product_name,code) VALUES (''Carrots'',''0135'')";
$sql = $conn->prepare("INSERT INTO Products (product_name,code,brands,Comp1Mat,Comp2Mat) VALUES (?,?,?)";
$sql->bind_param("isssi",$product_name,$code,$Brands,$Comp1Mat,$Comp2Mat);
$sql->execute();
$sql->close();
if ($conn->query($sql) === TRUE) {
echo "New record created successfully";
} else {
echo "Error: " . $sql . "<br>" . $conn->error;
}
$conn->close();
?>
斯威夫特:
func addProduct(product_name: String,code: String,brands: String,Comp1Mat: String,Comp2Mat: String){
print(product_name)
print(code)
print(brands)
print(Comp1Mat)
print(Comp2Mat)
let insertProductURL = URL(string: "http://recyclingmadesimple.xyz/insertproduct.PHP")!
var urlRequest = URLRequest(url: insertProductURL)
urlRequest.httpMethod = "POST"
// Set HTTP Request Headers
urlRequest.setValue("application/json",forHTTPHeaderField: "Accept");
urlRequest.setValue("application/json",forHTTPHeaderField: "Content-Type");
let postString = "product_name=\\(product_name)&code=\\(code)&brands=\\(brands)&Comp1Mat=\\(Comp1Mat)&Comp2Mat=\\(Comp2Mat)"
urlRequest.httpBody = postString.data(using: .utf8)
let task = URLSession.shared.dataTask(with: urlRequest) { (data,response,error) in
if error != nil {
print("error = \\(String(describing: error))")
return
}
print("response - \\(String(describing: response))")
let responseString = Nsstring(data: data!,encoding: String.Encoding.utf8.rawValue)
print("response string - \\(String(describing: responseString))")
}
task.resume()
}
错误:
response - Optional(<NSHTTPURLResponse: 0x281191600> { URL: http://recyclingmadesimple.xyz/insertproduct.PHP } { Status Code: 500,Headers {
Connection = (
"Upgrade,close"
);
"Content-Length" = (
0
);
"Content-Type" = (
"text/html; charset=UTF-8"
);
Date = (
"Thu,17 Jun 2021 12:38:25 GMT"
);
Server = (
Apache
);
Upgrade = (
"h2,h2c"
);
vary = (
"User-Agent"
);
"X-Powered-By" = (
"PHP/7.4.16"
);
} })
response string - Optional()
非常感谢。
解决方法
当您收到 500 错误时,这可能是格式错误的请求。或者它可能是 PHP 代码中的语法错误。或者两者兼而有之。
在这种情况下,很可能是 PHP 语法错误,因为在 ) 调用的末尾缺少 prepare。但也可能是前者(因为 Swift 代码不是对 application/x-www-urlencoded 请求进行百分比编码)。
当您得到 500 个代码时,请查看服务器 error_log 的末尾(通常在您的 PHP 文件所在的目录中)。在这种情况下,我看了看它说:
[19-Jun-2021 13:45:00 America/Boise] PHP 解析错误:语法错误,意外的“;”,在第 103 行的 /.../insert.php 中需要“)”
这是必须修复的 PHP 语法错误。
话虽如此,Swift 代码中也存在问题。它正在手动构建 HTTP 请求的主体。应该对请求正文中的值进行百分比编码。有一些库,比如 Alamofire,会自动对 application/x-www-urlencoded 请求(这是)进行百分比编码。如果编写自己的 Swift 代码来构建请求,您希望按照 HTTP Request in Swift with POST method 中的概述手动对它们进行百分比编码。
请注意,如果 (a) 您的请求包含需要百分比编码的字符(例如,空格或某些符号); (b) 如果您没有这样做,那么也可能导致 Web 服务器出现 500 错误。同样,error_log 文件会告诉您出了什么问题,但如果值可能包含任何保留字符,则对 URLRequest 的主体进行百分比编码很重要。
话虽如此,还有一些其他观察:
问题中提供的代码不太合理。您将
prepare调用的结果(这是一个“语句”)存储到名为$sql的变量中。 (顺便说一句,因为它是一个语句,将该变量命名为$stmt或$statement会更有意义。)稍后您将其提供给query。但是query需要一个 SQL 字符串,而不是prepare返回的“语句”。相反,您应该只检查prepare、bind_param和execute的返回值。不要在准备、绑定和执行语句后调用query。s中的i与bind_param值与您为具有$_POST内容的五个变量提供的默认值不匹配.您可能需要仔细检查一下。与手头的问题没有直接关系,但我会提出一些建议。也就是说,在编写像这样的 Web 服务时,我可能会建议以下建议:
设置 HTTP 状态代码(例如,插入成功时为
http_response_code(201),插入失败时为http_response_code(422))。我也会以 JSON 形式返回结果(例如,使用 PHP 关联数组作为结果,然后使用
json_encode构建响应以供 PHP 回显),而不是文本字符串。然后客户端应用程序可以轻松解析响应。我会设置
Content-Type(例如header("Content-Type: application/json")),以便客户端应用程序知道如何解析响应。
一个非常细微/微妙的观察:在 PHP 中,初始
<?php之前有一个空格。在 PHP 启动之前,您不需要任何字符。它可能会导致非常微妙的问题。 (希望这只是在准备问题时引入的一个错字,但只是一个警告。)
我接受了这些建议后才开始工作。谢谢你们。我在swift中将解析更改为JSON,并改进了PHP文件中变量的绑定。
PHP:
<?php
$code = $_POST["code"];
// Create connection
$con=mysqli_connect("localhost","X","X");
// Check connection
// Return the error code if the connection is not successful.
if (mysqli_connect_errno())
{
echo "Failed to connect to MySQL: " . mysqli_connect_error();
}
/* create a prepared statement */
// A prepared statement is one that is loaded initially and then executed many times over and over when we attach (bind) new variables to the placeholders we have inserted. We use ? marks to signify placeholders than must be later filled with values.
$stmt = mysqli_prepare($con,"SELECT product_name,brands,Comp1Mat,Comp2Mat,Comp3Mat,Comp1Name,Comp2Name,Comp3Name FROM Products WHERE code=?");
// Bind the parameters the user has entered with the ? marks in the SQL query
mysqli_stmt_bind_param($stmt,"s",$code);
/* execute query */
mysqli_stmt_execute($stmt);
// Bind the results we get with some new variable that we will output in the print statement.
mysqli_stmt_bind_result($stmt,$product_name,$brands,$Comp1Mat,$Comp2Mat,$Comp3Mat,$Comp1Name,$Comp2Name,$Comp3Name);
/* fetch value */
mysqli_stmt_fetch($stmt);
//create an array
$emparray = array("code" => $code,"product_name" => $product_name,"brands" => $brands,"Comp1Mat" => $Comp1Mat,"Comp2Mat" => $Comp2Mat,"Comp3Mat" => $Comp3Mat,"Comp1Name" => $Comp1Name,"Comp2Name" => $Comp2Name,"Comp3Name" => $Comp3Name);
printf(json_encode($emparray));
// Close connections
mysqli_close($con);
?><?php
斯威夫特:
func findSingleProduct(code: String){
// Completes an SQL query on the Products database to find a product by it''s barcode number.
// prepare json data
let insertProductURL = URL(string: "http://recyclingmadesimple.xyz/service.php")!
var urlRequest = URLRequest(url: insertProductURL)
urlRequest.httpMethod = "POST"
let postString = "code=\\(code)"
urlRequest.httpBody = postString.data(using: String.Encoding.utf8)
let task = URLSession.shared.dataTask(with: urlRequest) { data,response,error in
guard let data = data,error == nil else {
print(error?.localizedDescription ?? "No data")
return
}
let responseJSON = try? JSONSerialization.jsonObject(with: data,options: [])
if let responseJSON = responseJSON as? [String: Any] {
let code = responseJSON["code"]!
let product_name = responseJSON["product_name"]!
let brands = responseJSON["brands"]!
let Comp1Mat = responseJSON["Comp1Mat"]!
let Comp2Mat = responseJSON["Comp2Mat"]!
let Comp3Mat = responseJSON["Comp3Mat"]!
let Comp1Name = responseJSON["Comp1Name"]!
let Comp2Name = responseJSON["Comp2Name"]!
let Comp3Name = responseJSON["Comp3Name"]!
print(code,product_name,Comp3Name)
}
}
task.resume()
}

41 - 数据库-pymysql41 - 数据库-pymysql-DBUtils
[toc]
1 Python操作数据库
Python 提供了程序的DB-API,支持众多数据库的操作。由于目前使用最多的数据库为MySQL,所以我们这里以Python操作MySQL为例子,同时也因为有成熟的API,所以我们不必去关注使用什么数据,因为操作逻辑和方法是相同的。
2 安装模块
Python 程序想要操作数据库,首先需要安装 模块 来进行操作,Python 2 中流行的模块为 MySQLdb,而该模块在Python 3 中将被废弃,而使用PyMySQL,这里以PyMySQL模块为例。下面使用pip命令安装PyMSQL模块
pip3 install pymysql
如果没有pip3命令那么需要确认环境变量是否有添加,安装完毕后测试是否安装完毕。
lidaxindeMacBook-Pro:~ DahlHin$ python3
Python 3.6.1 (v3.6.1:69c0db5050, Mar 21 2017, 01:21:04)
[GCC 4.2.1 (Apple Inc. build 5666) (dot 3)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import pymysql
>>>
# 如果没有报错,则表示安装成功
3 基本使用
首先我们需要手动安装一个MySQL数据库,这里不再赘述,参考博文:http://www.cnblogs.com/dachenzi/articles/7159510.html
连接数据库并执行sql语句的一般流程是:
- 建立连接
- 获取游标(创建)
- 执行SQL语句
- 提交事务
- 释放资源
对应到代码上的逻辑为:
- 导入相应的Python模块
- 使用connect函数连接数据库,并返回一个Connection对象
- 通过Connection对象的cursor方法,返回一个Cursor对象
- 通过Cursor对象的execute方法执行SQL语句
- 如果执行的是查询语句,通过Cursor对象的fetchall语句获取返回结果
- 调用Cursor对象的close关闭Cursor
- 调用Connection对象的close方法关闭数据库连接
3.1 创建一个连接
使用pymysql.connect方法来连接数据库
import pymysql
pymysql.connect(host=None, user=None, password="",
database=None, port=0, unix_socket=None,
charset=''''......)
主要的参数有:
- host:表示连接的数据库的地址
- user:表示连接使用的用户
- password:表示用户对应的密码
- database:表示连接哪个库
- port:表示数据库的端口
- unix_socket:表示使用socket连接时,socket文件的路径
- charset:表示连接使用的字符集
- read_default_file:读取mysql的配置文件中的配置进行连接
3.2 连接数据库
调用connect函数,将创建一个数据库连接并得到一个Connection对象,Connection对象定义了很多的方法和异常。
host = ''10.0.0.13''
port = 3306
user = ''dahl''
password = ''123456''
database = ''test''
conn = pymysql.connect(host, user, password, database, port)
print(conn) # <pymysql.connections.Connection object at 0x000001ABD3063550>
conn.ping() # 没有返回值,无法连接会提示异常
这里conn就是一个Connection对象,它具有一下属性和方法:
begin:开始事务commit:提交事务rollback:回滚事务cursor:返回一个Cursor对象autocommit:设置事务是否自动提交set_character_set:设置字符集编码get_server_info:获取数据库版本信息ping(reconnect=True): 测试数据库是否活着,reconnect表示断开与服务器连接后是否重连,连接关闭时抛出异常(一般用来测通断)
在实际的编程过程中,一般不会直接调用begin、commit和rollback函数,而是通过上下文管理器实现事务的提交与回滚操作。
3.3 游标
游标是系统为用户开设的一个数据缓存区,存放SQL语句执行的结果,用户可以用SQL语句逐一从游标中获取记录,并赋值给变量,交由Python进一步处理。
在数据库中,游标是一个十分重要的概念。游标提供了一种对从表中检索出的数据进行操作的灵活手段,就本质而言,游标实际上是一种能从包括多条数据记录的结果集中每次提取一条记录的机制。游标总是与一条SQL 选择语句相关联因为游标由结果集(可以是零条、一条或由相关的选择语句检索出的多条记录)和结果集中指向特定记录的游标位置组成。当决定对结果集进行处理时,必须声明一个指向该结果集的游标。
正如前面我们使用Python对文件进行处理,那么游标就像我们打开文件所得到的文件句柄一样,只要文件打开成功,该文件句柄就可代表该文件。对于游标而言,其道理是相同的。
3.3.1 利用游标操作数据库
在进行数据库的操作之前需要创建一个游标对象,来执行sql语句。
cursor = conn.cursor()
下面利用游标来执行sql语句:
import pymysql
def connect_mysql():
db_config = {
''host'':''127.0.0.1'',
''port'':3306,
''user'':''root'',
''password'':''abc.123'',
''charset'':''utf8''
}
return pymysql.connect(**db_config)
if __name__ == ''__main__'':
conn = connect_mysql()
cursor = conn.cursor() # 创建游标
sql = r" select user,host from mysql.user " # 要执行的sql语句
cursor.execute(sql) # 交给 游标执行
result = cursor.fetchall() # 获取游标执行结果
print(result)
3.3.2 事务管理
Connection对象包含如下三个方法用于事务管理:
- begin:开始事务
- commit:提交事务
- rollback:回滚事务
import pymysql
def connect_mysql():
db_config = {
''host'': ''10.0.0.13'',
''port'': 3306,
''user'': ''dahl'',
''password'': ''123456'',
''charset'': ''utf8''
}
return pymysql.connect(**db_config)
if __name__ == ''__main__'':
conn = connect_mysql()
cursor = conn.cursor() # 创建游标
conn.begin()
sql = r"insert into test.student (id,name,age) VALUES (5,''dahl'',23)" # 要执行的sql语句
res = cursor.execute(sql) # 交给 游标执行
print(res)
conn.commit()
这样使用是极其不安全的,因为sql语句有可能执行失败,当失败时,我们应该进行回滚
if __name__ == ''__main__'':
conn = None
cursor = None
try:
conn = connect_mysql()
cursor = conn.cursor() # 创建游标
sql = r"insert into test.student (id,name,age) VALUES (6,''dahl'',23)" # 要执行的sql语句
cursor.execute(sql) # 交给 游标执行
conn.commit() # 提交事务
except:
conn.rollback() # 当SQL语句执行失败时,回滚
finally:
if cursor:
cursor.close() # 关闭游标
if conn:
conn.close() # 关闭连接
3.3.3 执行SQL语句
用于执行SQL语句的两个方法为:
- cursor.execute(sql):执行一条sql语句
- executemany(sql,parser):执行多条语句
sql = r"select * from test.student"
res = cursor.execute(sql)
3.3.3.1 批量执行
executemany用于批量执行sql语句,
- sql 为模板,c风格的占位符。
- parser:为模板填充的数据(可迭代对象)
sql = r"insert into test.student (id,name,age) values (%s,''daxin'',20)"
cursor.executemany(sql,(7,8,9,))
3.3.3.2 SQL注入攻击
我们一般在程序中使用sql,可能会有如下代码:
# 接受用户id,然后拼接查询用户信息的SQL语句,然后查询数据库。
userid = 10 # 来源于程序
sql = ''select * from user where user_id = {}''.format(userid)
userid是可变的,比如通过客户端发来的request请求,直接拼接到查询字符串中。如果客户端传递的userid是 ''5 or 1=''呢
sql = ''select * from test.student where id = {}''.format(''5 or 1=1'')
此时真正在数据库中查询的sql语句就变成了
select * from test.student where id = 5 or 1=1
这条语句的where条件的函数含义是:当id等于5,或者1等于1时,列出所有匹配的字段,这样就轻松的查到了标准所有的数据!!!
永远不要相信客户端传来的数据是规范及安全的。
3.3.3.3 参数化查询
cursor.execute(sql)方法还额外提供了一个args参数,用于进行参数化查询,它的类型可以为元组、列表、字典。如果查询字符串使用命名关键字(%(name)s),那么就必须使用字典进行传参。
sql = ''select * from test.student where id = %s''
cursor.execute(sql,args=(2,))
sql = ''select * from test.student where id = %(id)s''
cursor.execute(sql,args={''id'':2})
我们说使用参数化查询,效率会高一点,为什么呢?因为SQL语句缓存。数据库一般会对SQL语句编译和缓存,编译只对SQL语句部分,所以参数中就算有SQL指令也不会被执行。编译过程,需要此法分析、语法分析、生成AST、优化、生成执行计划等过程,比较耗费资源。服务端会先查找是否是同一条语句进行了缓存,如果缓存未失效,则不需要再次编译,从而降低了编译的成本,降低了内存消耗。
可以认为SQL语句字符串就是一个key,如果使用拼接方案,每次发过去的SQL语句都不一样,都需要编译并缓存。大量查询的时候,首选使用参数化查询,以节省资源。
3.4 获取查询结果
Cursor类提供了三种查询结果集的方法:(返回值为元组,多个值为嵌套元组)
fetchone():获取一条fetchmany(size=None):获取多条,当size为None时,返回一个包含一个元素的嵌套元组fetchall():获取所有
sql = ''select * from test.student''
cursor.execute(sql)
print(cursor.fetchall())
print(cursor.fetchone()) # None
print(cursor.fetchmany(2)) # None
fetch存在一个指针,fetchone一次,就读取结果集中的一个结果,如果fetchall,那么一次就会读取完所有的结果。可以通过调整这个指针来重复读取
- cursor.rownumber: 返回当前行号,可以修改,支持 负数
- cursor.rowcount: 返回总行数
sql = ''select * from test.student''
cursor.execute(sql)
print(cursor.fetchall()) # ((2, ''dahl'', 20), (3, ''dahl'', 21), (4, ''daxin'', 22), (5, ''dahl'', 23), (6, ''dahl'', 23), (7, ''daxin'', 20), (8, ''daxin'', 20), (9, ''daxin'', 20))
cursor.rownumber = 0
print(cursor.fetchone()) # (2, ''dahl'', 20)
print(cursor.fetchmany()) # ((3, ''dahl'', 21),)
fetch操作的是结果集,结果集是保存在客户端的,也就是说fetch的时候,查询已经结束了。
3.4.1 带列明的查询
结果中不包含字段名,除非我们记住字段的顺序,不然很麻烦,那么下面来解决这个问题。
观察cursor原码,我们发现,它接受一个参数cursor,有一个参数是:DictCursor,查看源码得知,它是Cursor的Mixin子类。
def cursor(self, cursor=None):
"""
Create a new cursor to execute queries with.
:param cursor: The type of cursor to create; one of :py:class:`Cursor`,
:py:class:`SSCursor`, :py:class:`DictCursor`, or :py:class:`SSDictCursor`.
None means use Cursor.
"""
if cursor:
return cursor(self)
return self.cursorclass(self)
观察DictCursor的原码,得知结果集会返回一个字典,一个字段名:值的结果,所以,只需要传入cursor参数即可
from pymysql import cursors # DictCursor存在与cursors模块中
... ...
cursor = conn.cursor(cursors.DictCursor)
sql = ''select * from test.student''
cursor.execute(sql)
print(cursor.fetchone()) # {''id'': 2, ''name'': ''dahl'', ''age'': 20}
3.5 上下文支持
Connection和Cursor类实现了__enter__和__exit__方法,所以它支持上下文管理。
- Connection:进入时返回一个cursor,退出时如果有异常,则回滚,否则提交
- Cursor: 进入时返回cursor本身,退出时,关闭cursor连接
所以利用上下文的特性,我们可以这样使用
import pymysql
def connect_mysql():
db_config = {
''host'': ''10.0.0.13'',
''port'': 3306,
''user'': ''dahl'',
''password'': ''123456'',
''charset'': ''utf8''
}
return pymysql.connect(**db_config)
if __name__ == ''__main__'':
conn = connect_mysql()
with conn as cursor:
sql = ''select * from student''
cursor.execute(sql)
print(cursor.fetchmany(2))
# conn的exit只是提交了,并没有关闭curosr
cursor.close()
conn.close()
如果要自动关闭cursor,可以进行如下改写
if __name__ == ''__main__'':
conn = connect_mysql()
with conn as cursor:
with cursor # curosr的exit会关闭cursor
sql = ''select * from student''
cursor.execute(sql)
print(cursor.fetchmany(2))
conn.close()
多个 cursor共享一个 conn
4 DBUtils连接池
在python编程中可以使用MySQLdb/pymysql等模块对数据库的连接及诸如查询/插入/更新等操作,但是每次连接mysql数据库请求时,都是独立的去请求访问,相当浪费资源,而且访问数量达到一定数量时,对mysql的性能会产生较大的影响。因此,实际使用中,通常会使用数据库的连接池技术,来访问数据库达到资源复用的目的。
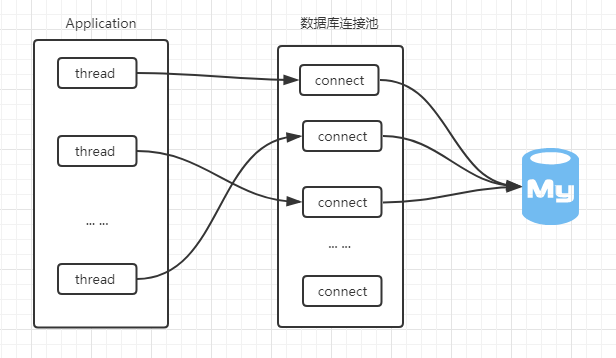
连接池对性能的提升表现在:
- 在程序创建连接的时候,可以从一个空闲的连接中获取,不需要重新初始化连接,提升获取连接的速度
- 关闭连接的时候,把连接放回连接池,而不是真正的关闭,所以可以减少频繁地打开和关闭连接
DBUtils是一套Python数据库连接池包,并允许对非线程安全的数据库接口进行线程安全包装。DBUtils来自Webware for Python。
DBUtils提供两种外部接口:
- PersistentDB:提供线程专用的数据库连接,并自动管理连接。(为每一个线程创建一个)
PooledDB:提供线程间可共享的数据库连接,并自动管理连接。
为每个线程创建一个,资源消耗太大,所以我们常用的是PooledDB.
PooledDB常用的参数为:
creator=pymysql: 使用链接数据库的模块maxconnections=6: 连接池允许的最大连接数,0和None表示不限制连接数mincached=2: 初始化时,链接池中至少创建的空闲的链接,0表示不创建,如果空闲连接数小于这个数,pool会创建一个新的连接maxcached=5: 链接池中最多闲置的链接,0和None不限制,如果空闲连接数大于这个数,pool会关闭空闲连接- maxshared=3: 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。
blocking=True: 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错- maxusage=None: 一个链接最多被重复使用的次数,None表示无限制
- setsession=[]: 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."]
- ping=0: ping MySQL服务端,检查是否服务可用。
0= None = never- 1 = default = whenever it is requested
- 2 = when a cursor is created
4= when a query is executed- 7 = always
- host=''127.0.0.1'',
- port=3306,
- user=''root'',
- password=''123'',
- database=''pooldb'',
- charset=''utf8''
安装DBUtils
pip install DBUtils
示例代码:
import threading
import time
from DBUtils.PooledDB import PooledDB
import pymysql
POOL = PooledDB(
creator=pymysql,
maxconnections=6,
mincached=2,
maxcached=5,
# maxshared=3,
blocking=True,
maxusage=None,
setsession=[],
ping=0,
host=''10.0.0.13'',
port=3306,
user=''dahl'',
password=''123456'',
database=''test'',
charset=''utf8''
)
def func():
conn = POOL.connection()
cursor = conn.cursor(pymysql.cursors.DictCursor)
time.sleep(2)
cursor.execute(''select * from employees'')
res = cursor.fetchall()
conn.close()
print(threading.get_ident(), res)
if __name__ == ''__main__'':
for i in range(10):
threading.Thread(target=func).start()

AJAX 没有将变量传递给 PHP 文件
open 的第三个参数是请求是否应该异步处理。它不是您放置数据的地方。
如果您要发出 POST 请求,那么您会将数据作为 send 方法的第一个参数放入……但这不接受普通对象。
由于您发出的是 GET 请求,因此您需要将数据编码到作为第二个参数传递给 open 的 URL 的查询字符串中。
const admin_id = "12345";
const relativeUrl = 'includes/check_privileges.php';
const url = new URL(relativeUrl,location.href);
url.searchParams.append('admin_id',admin_id);
console.log(url.toString())
Azure Synapse、Azure SQL 数据库、Azure 托管实例和本地 SQL Server 中的跨数据库查询
如何解决Azure Synapse、Azure SQL 数据库、Azure 托管实例和本地 SQL Server 中的跨数据库查询
我们正在研究将本地 sql Server 迁移到 Azure 的选项,并试图了解如果我们在 Azure(特别是 Azure Managed实例、Azure Synapse Analytics、Azure sql 数据库),并在本地 sql Server 实例中。
我们在任何地方都找不到关于这些是否受支持的太多信息,如果你们中的任何人能帮助填写下表,我们将不胜感激:
| TO-> | Azure sql 数据库 | Azure 托管实例 | Azure Synapse 分析 | 本地 sql Server |
|---|---|---|---|---|
| Azure sql DB | 通过弹性搜索查询支持(参考:https://azure.microsoft.com/en-us/blog/querying-remote-databases-in-azure-sql-db/) | ? | Azure Data Share 支持共享来自 Azure sql 数据库和 Azure Synapse Analytics(以前称为 Azure sql DW)的表和视图,以及共享来自 Azure Synapse Analytics(工作区)专用 sql 池的表。当前不支持从 Azure Synapse Analytics(工作区)无服务器 sql 池共享。 (参考:https://docs.microsoft.com/en-us/azure/data-share/how-to-share-from-sql) | Azure sql 数据库不支持链接服务器属性,因此您将无法访问 Azure sql 数据库中的 prem 表,并且 Azure sql 数据库中的弹性查询是在 2 个 Azure sql 数据库之间查询表,而不是 On prem。 (参考:https://docs.microsoft.com/en-us/answers/questions/289105/how-can-i-query-on-premise-sql-server-database-fro.html) |
| Azure 托管实例 | ? | ? | ? | 可通过使用链接服务器获得(参考:http://thewindowsupdate.com/2019/03/22/lesson-learned-81-how-to-create-a-linked-server-from-azure-sql-managed-instance-to-sql-server-onpremise-or-azure-vm/) |
| Azure Synapse Analytics | ? | ? | ? | ? |
| 本地 sql Server | ? | ? | ? | 使用链接服务器,您可以从本地 sql Server 查询 Azure sql 数据库中的数据(参考:https://docs.microsoft.com/en-us/answers/questions/289105/how-can-i-query-on-premise-sql-server-database-fro.html) |
解决方法
AFAIK 没有提供单个接口来同时与多个数据库通信的跨数据库外观。无论是在本地/云端还是 SQL-Server/Synapse/MySQL/...
您可以通过多种方式和方法从某处/任何地方访问单个数据库。例如。从云中的代码访问本地数据库或从本地“服务器”上运行的代码访问云数据库。可用接口列表特定于每个“源”和“目标”组合。
,Azure SQL 数据库需要 elastic query 来实现跨数据库查询。不支持创建链接服务器。
Azure 托管实例与本地 SQL 服务器具有几乎相同的功能,您可以使用 USE statement 执行跨数据库查询。与本地 SQL Server 相同。
Azure Synapse Analytics 也不支持跨数据库查询。
根据我的知识和经验,我会在表中放✔或X来表示支持或不支持。请参考:
| TO-> | Azure SQL 数据库 | Azure 托管实例 | Azure Synapse 分析 | 本地 SQL Server |
|---|---|---|---|---|
| Azure SQL DB | 通过弹性搜索查询支持(参考:https://azure.microsoft.com/en-us/blog/querying-remote-databases-in-azure-sql-db/) | X,不支持 | Azure Data Share 支持共享来自 Azure SQL 数据库和 Azure Synapse Analytics(以前称为 Azure SQL DW)的表和视图,以及共享来自 Azure Synapse Analytics(工作区)专用 SQL 池的表。当前不支持从 Azure Synapse Analytics(工作区)无服务器 SQL 池共享。 (参考:https://docs.microsoft.com/en-us/azure/data-share/how-to-share-from-sql) | Azure SQL 数据库不支持链接服务器属性,因此您将无法访问 Azure SQL 数据库中的 prem 表,并且 Azure SQL 数据库中的弹性查询是在 2 个 Azure SQL 数据库之间查询表,而不是 On prem。 (参考:https://docs.microsoft.com/en-us/answers/questions/289105/how-can-i-query-on-premise-sql-server-database-fro.html) |
| Azure 托管实例 | X,不支持 | ✔,与本地 SQL Server 相同 | X,不支持 | 可通过使用链接服务器获得(参考:http://thewindowsupdate.com/2019/03/22/lesson-learned-81-how-to-create-a-linked-server-from-azure-sql-managed-instance-to-sql-server-onpremise-or-azure-vm/) |
| Azure Synapse Analytics | Azure 数据共享 | X,不支持 | X,不支持 | X,不支持 |
| 本地 SQL Server | ✔,链接服务器 | ✔,链接服务器 | X,不支持 | 使用链接服务器,您可以从本地 SQL Server 查询 Azure SQL 数据库中的数据(参考:https://docs.microsoft.com/en-us/answers/questions/289105/how-can-i-query-on-premise-sql-server-database-fro.html) |
请根据您的要求选择合适的 Azure 数据库版本。
HTH。

bat脚本备份SQL Server 数据库 - cmd命令备份SQL Server 数据库
bat脚本备份SQL Server 数据库 - cmd命令备份SQL Server 数据库
如何用命令或者脚本来备份 SQL Server 备份数据库。
实现方法
通过bat脚本或者cmd命令来执行sql脚本实现备份;
开始
mybackup.sql 脚本内容如下
BACKUP DATABASE [database_name]
TO DISK=''E:\DataBaseBAK\database_name.bak''
解释
database_name 需要备份的数据库名称;
E:\DataBaseBAK\database_name.bak 数据库备份位置;
编辑打开,填入如下命令
sqlcmd -S 127.0.0.1 -U sa -P 123 -i E:\DataBaseBAK\mybackup.sql
解释
127.0.0.1 数据库服务器IP;
sa 数据库用户名
123 sa用户密码;
E:\DataBaseBAK\mybackup.sql mybackup.sql 脚本位置;
以上。
关于Swift 没有将变量传递给 PHP Web 服务来查询我的 SQL 数据库的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于41 - 数据库-pymysql41 - 数据库-pymysql-DBUtils、AJAX 没有将变量传递给 PHP 文件、Azure Synapse、Azure SQL 数据库、Azure 托管实例和本地 SQL Server 中的跨数据库查询、bat脚本备份SQL Server 数据库 - cmd命令备份SQL Server 数据库的相关信息,请在本站寻找。
本文标签:




