这篇文章主要围绕Elasticsearch嵌套过滤器包含与不包含和elasticsearch嵌套对象展开,旨在为您提供一份详细的参考资料。我们将全面介绍Elasticsearch嵌套过滤器包含与不包含
这篇文章主要围绕Elasticsearch嵌套过滤器包含与不包含和elasticsearch嵌套对象展开,旨在为您提供一份详细的参考资料。我们将全面介绍Elasticsearch嵌套过滤器包含与不包含的优缺点,解答elasticsearch嵌套对象的相关问题,同时也会为您带来Elastic Search嵌套对象查询、Elasticsearch 2.4,对嵌套对象不起作用存在过滤器、Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana、elasticsearch NEST 不包含指定关键词数组集合精确过滤,后加其他过滤条件的实用方法。
本文目录一览:- Elasticsearch嵌套过滤器包含与不包含(elasticsearch嵌套对象)
- Elastic Search嵌套对象查询
- Elasticsearch 2.4,对嵌套对象不起作用存在过滤器
- Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana
- elasticsearch NEST 不包含指定关键词数组集合精确过滤,后加其他过滤条件
")
Elasticsearch嵌套过滤器包含与不包含(elasticsearch嵌套对象)
我有一个对象映射,它props以类似标签的方式使用嵌套对象(在我们的示例中)。每个标签可以属于一个客户/用户,并且当我们要允许我们的用户针对生成query_string样式搜索时props.name。
问题是,当我们运行查询时,如果一个对象有多个道具,并且当其他道具不返回时,如果多个道具之一与过滤器匹配,则当我们想要相反时-
如果一个道具返回false,则不返回vs。如果返回true,则返回true。
我在这里发布了一个完整的示例:https :
//gist.github.com/d2kagw/1c9d4ef486b7a2450d95
提前致谢。
答案1
小编典典我相信在这里您可能需要一个扁平化的值列表的优势,例如值数组。数组和嵌套对象之间的主要区别在于,后者“知道”嵌套属性的哪个值对应于 同一
嵌套对象中另一个属性的另一个值。另一方面,值数组将使某个属性的值变平,并且您将失去a client_id和a 之间的“关联”name。含义是,您拥有props.client_id = [null, 2]和的数组props.name = ["petlover","premiumshopper"]。
使用nested过滤器,您希望将该字符串与所有值匹配,以props.name表示一个父文档的 所有
嵌套props.names都需要匹配。嗯,嵌套对象不会发生这种情况,因为嵌套文档是分开的,并且要分别查询。并且,如果至少一个嵌套文档匹配,则将其视为匹配。
换句话说,对于像"query": "props.name:(carlover NOTpetlover)"您这样的查询,基本上需要像数组一样针对扁平化的值列表运行它。您需要针对[“ carlover”,“ petlover”]运行查询。
我对您的建议是制作嵌套文档"include_in_parent": true(即在父级中保留一个扁平的,类似数组的值列表)并稍微更改一下查询:
- 对于
query_string零件,请使用扁平化的属性方法来匹配您查询的元素组合列表,而不是逐个元素。 - 对于
match(或term参见下文),missing零件使用嵌套属性方法,因为您可以null在其中使用。一个missing阵列上只会匹配,如果整个阵列丢失,而不是在它的一个值,所以在这里我们不能使用相同的方法作为查询,那里的值在数组中夷为平地。 - 可选,但对于
querymatch整数,我将使用term,因为它不是字符串而是整数,并且默认为not_analyzed。
说了这些,有了以上更改,这些更改就是:
{ "mappings" : { ... "props": { "type": "nested", "include_in_parent": true, ...应该(并且确实)返回零结果
GET /nesting-test/_search?pretty=true
{
“query”: {
“filtered”: {
“filter”: {
“and”: [
{
“query”: {
“query_string”: { “query”: “props.name:((carlover AND premiumshopper) NOT petlover)” }
}
},
{
“nested”: {
“path”: “props”,
“filter”: {
“or”: [ { “query”: { “match”: { “props.client_id”: 1 } } }, { “missing”: { “field”: “props.client_id” } } ]
}
}
}
]
}
}
}
}应该(并且确实)只返回1
GET /nesting-test/_search?pretty=true
{
“query”: {
“filtered”: {
“filter”: {
“and”: [
{“query”: {“query_string”: { “query”: “props.name:(carlover NOT petlover)” } } },
{
“nested”: {
“path”: “props”,
“filter”: {
“or”: [{ “query”: { “match”: { “props.client_id”: 1 } } },{ “missing”: { “field”: “props.client_id” } } ]
}
}
}
]
}
}
}
}应该(并且确实)只返回2
GET /nesting-test/_search?pretty=true
{
“query”: {
“filtered”: {
“filter”: {
“and”: [
{ “query”: {“query_string”: { “query”: “props.name:(* NOT carlover)” } } },
{
“nested”: {
“path”: “props”,
“filter”: {
“or”: [{ “query”: { “term”: { “props.client_id”: 1 } } },{ “missing”: { “field”: “props.client_id” } }
]
}
}
}
]
}
}
}
}

Elastic Search嵌套对象查询
我有一个如下所示的elasticsearch索引集合,
"_index":"test","_type":"abc","_source":{ "file_name":"xyz.ex" "metadata":{ "format":".ex" "profile":[ {"date_value" : "2018-05-30T00:00:00", "key_id" : "1", "type" : "date", "value" : [ "30-05-2018" ] }, { "key_id" : "2", "type" : "freetext", "value" : [ "New york" ] }}现在,我需要通过匹配key_id其值来搜索文档。(key_id是一些字段,其值存储在其中"value")对于key_id=''1''字段,如果value= "30-05-2018"与上面的文档匹配。
我尝试将其映射为嵌套对象,但是无法编写查询来搜索2个或更多key_id匹配其各自值的查询。
答案1
小编典典这就是我要做的。您需要通过bool/filter(或bool/must)两个嵌套查询对每个条件对进行AND
运算,因为您要匹配同一父文档中的两个不同的嵌套元素。
{ "query": { "bool": { "filter": [ { "nested": { "path": "metadata.profile", "query": { "bool": { "filter": [ { "term": { "metadata.profile.f1": "a" } }, { "term": { "metadata.profile.f2": true } } ] } } } }, { "nested": { "path": "metadata.profile", "query": { "bool": { "filter": [ { "term": { "metadata.profile.f1": "b" } }, { "term": { "metadata.profile.f2": false } } ] } } } } ] } }}
Elasticsearch 2.4,对嵌套对象不起作用存在过滤器
我的映射是:
"properties": {
"user": {
"type": "nested","properties": {
"id": {
"type": "integer"
},"is_active": {
"type": "boolean","null_value": false
},"username": {
"type": "string"
}
}
},我想获取所有没有user字段的文档。
我试过了:
GET /index/type/_search
{
"query": {
"bool": {
"must_not": [
{
"exists": {
"field": "user"
}
}
]
}
}
}
返回所有文档。基于ElasticSearch2.x,存在用于嵌套字段的过滤器不起作用的问题,我也尝试过:
GET /index/type/_search
{
"query": {
"nested": {
"path": "user","query": {
"bool": {
"must_not": [
{
"exists": {
"field": "user"
}
}
]
}
}
}
}
}
返回0个文档。
使所有缺少该user字段的文档的正确查询是什么?

Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana
CentOS6.5下安装ElasticSearch6.2.4
(1)配置JDK环境
配置环境变量
export JAVA_HOME="/opt/jdk1.8.0_144"
export PATH="$JAVA_HOME/bin:$PATH"
export CLASSPATH=".:$JAVA_HOME/lib"
(2)安装ElasticSearch6.2.4
下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-2-4
启动报错:
解决方式:
bin/elasticsearch -Des.insecure.allow.root=true
或者修改bin/elasticsearch,加上ES_JAVA_OPTS属性:
ES_JAVA_OPTS="-Des.insecure.allow.root=true"
再次启动: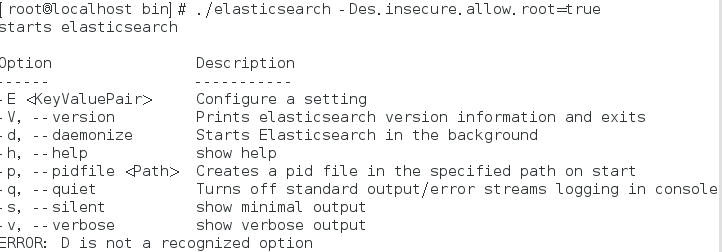
这是出于系统安全考虑设置的条件。由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考 虑,建议创建一个单独的用户用来运行ElasticSearch。
如果没有普通用户就要创建一个普通用户组和普通用户,下面介绍一下怎么创建用户组和普通用户
创建用户组和用户:
groupadd esgroup
useradd esuser -g esgroup -p espassword
更改elasticsearch文件夹及内部文件的所属用户及组:
cd /opt
chown -R esuser:esgroup elasticsearch-6.2.4
切换用户并运行:
su esuser
./bin/elasticsearch
再次启动显示已杀死: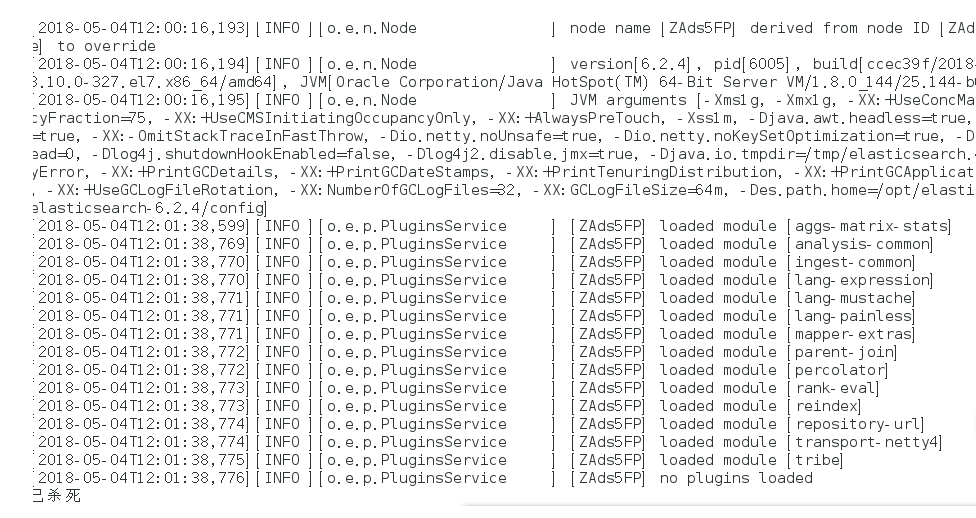
需要调整JVM的内存大小:
vi bin/elasticsearch
ES_JAVA_OPTS="-Xms512m -Xmx512m"
再次启动:启动成功
如果显示如下类似信息:
[INFO ][o.e.c.r.a.DiskThresholdMonitor] [ZAds5FP] low disk watermark [85%] exceeded on [ZAds5FPeTY-ZUKjXd7HJKA][ZAds5FP][/opt/elasticsearch-6.2.4/data/nodes/0] free: 1.2gb[14.2%], replicas will not be assigned to this node
需要清理磁盘空间。
后台运行:./bin/elasticsearch -d
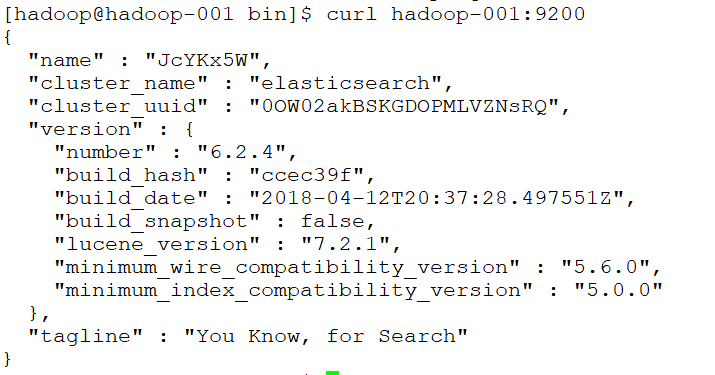
测试连接:curl 127.0.0.1:9200
会看到一下JSON数据:
[root@localhost ~]# curl 127.0.0.1:9200
{
"name" : "rBrMTNx",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "-noR5DxFRsyvAFvAzxl07g",
"version" : {
"number" : "5.1.1",
"build_hash" : "5395e21",
"build_date" : "2016-12-06T12:36:15.409Z",
"build_snapshot" : false,
"lucene_version" : "6.3.0"
},
"tagline" : "You Know, for Search"
}
实现远程访问:
需要对config/elasticsearch.yml进行 配置:
network.host: hadoop-001
再次启动报错:Failed to load settings from [elasticsearch.yml]
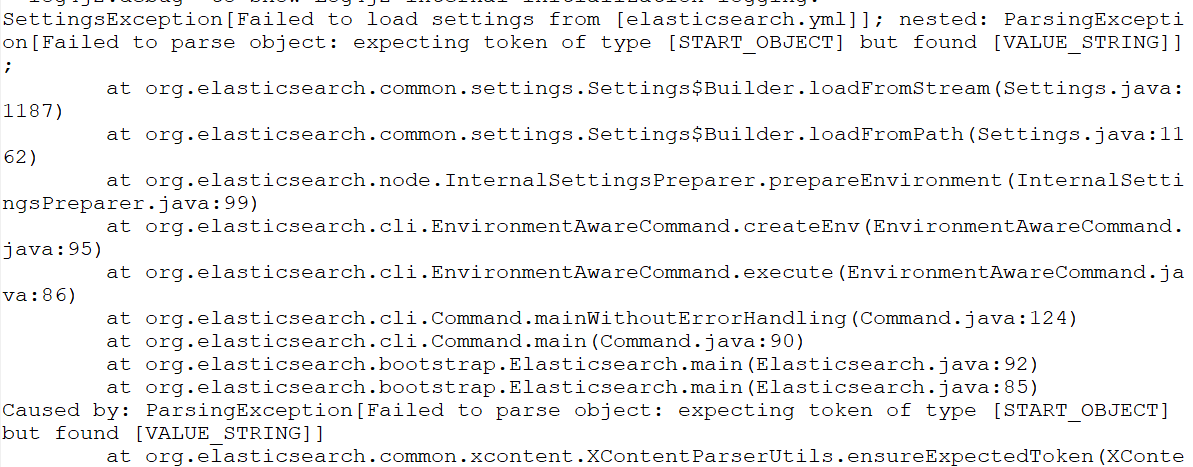
这个错就是参数的冒号前后没有加空格,加了之后就好,我找了好久这个问题;
后来在一个外国网站找到了这句话.
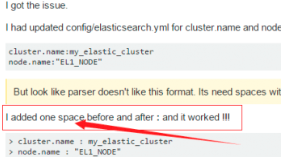
Exception in thread "main" SettingsException[Failed to load settings from [elasticsearch.yml]]; nested: ElasticsearchParseException[malformed, expected end of settings but encountered additional content starting at line number: [3], column number: [1]]; nested: ParserException[expected ''<document start>'', but found BlockMappingStart
in ''reader'', line 3, column 1:
node.rack : r1
^
];
Likely root cause: expected ''<document start>'', but found BlockMappingStart
in ''reader'', line 3, column 1:
node.rack : r1
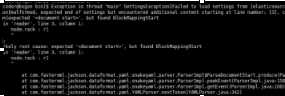
这个是行的开头没有加空格,fuck!
Exception in thread "main" SettingsException[Failed to load settings from [elasticsearch.yml]]; nested: ScannerException[while scanning a simple key
in ''reader'', line 11, column 2:
discovery.zen.ping.unicast.hosts ...
^

参数冒号后加空格,或者是数组中间加空格
例如:
# discovery.zen.minimum_master_nodes: 3
再次启动
还是报错
max file descriptors [4096] for elasticsearch process is too low
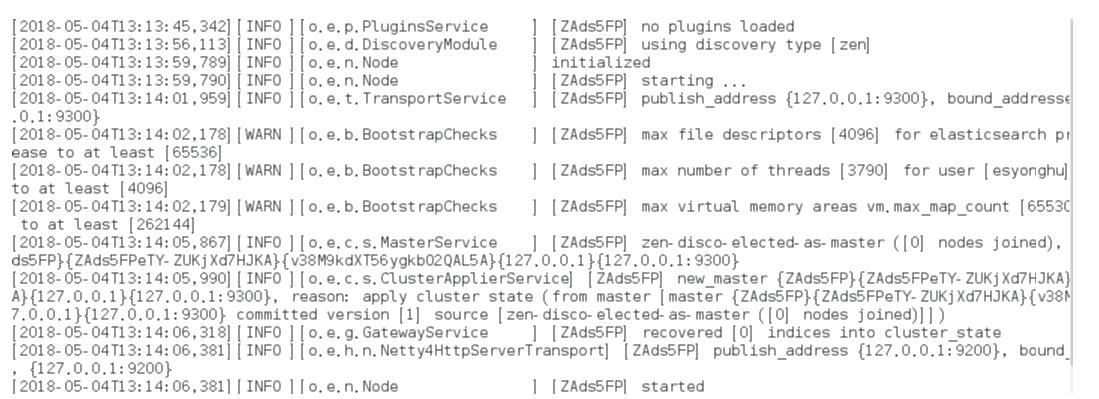
处理第一个错误:
vim /etc/security/limits.conf //文件最后加入
esuser soft nofile 65536
esuser hard nofile 65536
esuser soft nproc 4096
esuser hard nproc 4096
处理第二个错误:
进入limits.d目录下修改配置文件。
vim /etc/security/limits.d/20-nproc.conf
修改为 esuser soft nproc 4096
注意重新登录生效!!!!!!!!
处理第三个错误:
vim /etc/sysctl.conf
vm.max_map_count=655360
执行以下命令生效:
sysctl -p
关闭防火墙:systemctl stop firewalld.service
启动又又又报错
system call filters failed to install; check the logs and fix your configuration or disable sys

直接在
config/elasticsearch.yml 末尾加上一句
bootstrap.system_call_filter: false再次启动成功!
安装Head插件
Head是elasticsearch的集群管理工具,可以用于数据的浏览和查询
(1)elasticsearch-head是一款开源软件,被托管在github上面,所以如果我们要使用它,必须先安装git,通过git获取elasticsearch-head
(2)运行elasticsearch-head会用到grunt,而grunt需要npm包管理器,所以nodejs是必须要安装的
nodejs和npm安装:
http://blog.java1234.com/blog/articles/354.html
git安装
yum install -y git
(3)elasticsearch5.0之后,elasticsearch-head不做为插件放在其plugins目录下了。
使用git拷贝elasticsearch-head到本地
cd ~
git clone git://github.com/mobz/elasticsearch-head.git
(4)安装elasticsearch-head依赖包
[root@localhost local]# npm install -g grunt-cli
[root@localhost _site]# cd /usr/local/elasticsearch-head/
[root@localhost elasticsearch-head]# cnpm install
(5)修改Gruntfile.js
[root@localhost _site]# cd /usr/local/elasticsearch-head/
[root@localhost elasticsearch-head]# vi Gruntfile.js
在connect-->server-->options下面添加:hostname:’*’,允许所有IP可以访问
(6)修改elasticsearch-head默认连接地址
[root@localhost elasticsearch-head]# cd /usr/local/elasticsearch-head/_site/
[root@localhost _site]# vi app.js
将this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200";中的localhost修改成你es的服务器地址
(7)配置elasticsearch允许跨域访问
打开elasticsearch的配置文件elasticsearch.yml,在文件末尾追加下面两行代码即可:
http.cors.enabled: true
http.cors.allow-origin: "*"
(8)打开9100端口
[root@localhost elasticsearch-head]# firewall-cmd --zone=public --add-port=9100/tcp --permanent
重启防火墙
[root@localhost elasticsearch-head]# firewall-cmd --reload
(9)启动elasticsearch
(10)启动elasticsearch-head
[root@localhost _site]# cd ~/elasticsearch-head/
[root@localhost elasticsearch-head]# node_modules/grunt/bin/grunt server 或者 npm run start
(11)访问elasticsearch-head
关闭防火墙:systemctl stop firewalld.service
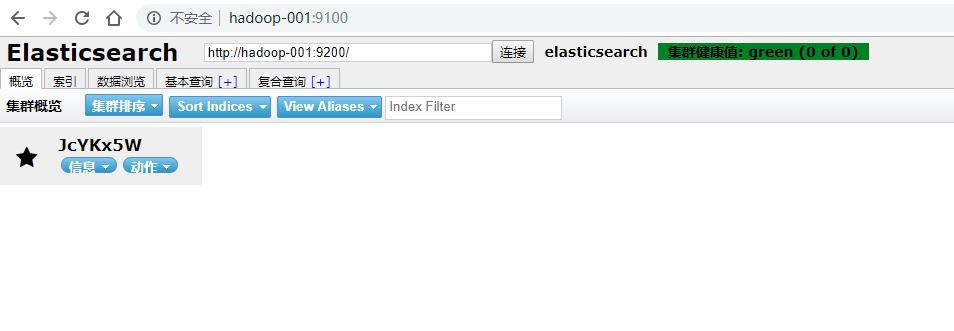
浏览器输入网址:hadoop-001:9100/
安装Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,使用Kibana可以查询、查看并与存储在ES索引的数据进行交互操作,使用Kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据
(1)下载Kibana
https://www.elastic.co/downloads/kibana
(2)把下载好的压缩包拷贝到/soft目录下
(3)解压缩,并把解压后的目录移动到/user/local/kibana
(4)编辑kibana配置文件
[root@localhost /]# vi /usr/local/kibana/config/kibana.yml
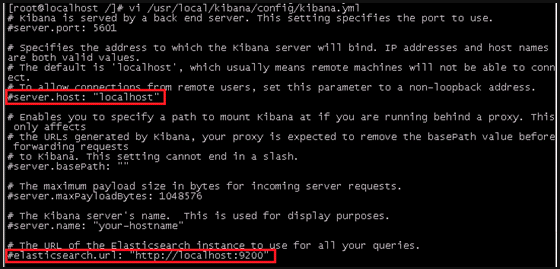
将server.host,elasticsearch.url修改成所在服务器的ip地址
server.port: 5601 //监听端口
server.host: "hadoo-001" //监听IP地址,建议内网ip
elasticsearch.url: "http:/hadoo-001" //elasticsearch连接kibana的URL,也可以填写192.168.137.188,因为它们是一个集群
(5)开启5601端口
Kibana的默认端口是5601
开启防火墙:systemctl start firewalld.service
开启5601端口:firewall-cmd --permanent --zone=public --add-port=5601/tcp
重启防火墙:firewall-cmd –reload
(6)启动Kibana
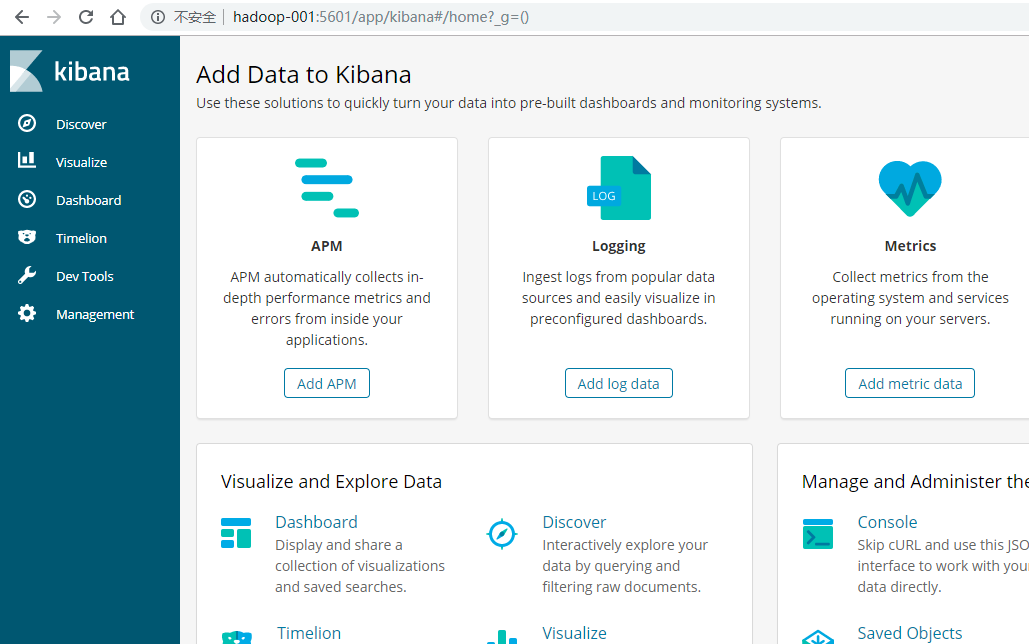
[root@localhost /]# /usr/local/kibana/bin/kibana
浏览器访问:http://192.168.137.188:5601
安装中文分词器
一.离线安装
(1)下载中文分词器
https://github.com/medcl/elasticsearch-analysis-ik
下载elasticsearch-analysis-ik-master.zip
(2)解压elasticsearch-analysis-ik-master.zip
unzip elasticsearch-analysis-ik-master.zip
(3)进入elasticsearch-analysis-ik-master,编译源码
mvn clean install -Dmaven.test.skip=true
(4)在es的plugins文件夹下创建目录ik
(5)将编译后生成的elasticsearch-analysis-ik-版本.zip移动到ik下,并解压
(6)解压后的内容移动到ik目录下
二.在线安装
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip

elasticsearch NEST 不包含指定关键词数组集合精确过滤,后加其他过滤条件
elasticsearch 不包含指定关键词精确过滤,后加其他过滤条件
ES Code:
GET order/list/_search
{
"size": 10,
"query": {
"bool": {
"must_not": [
{
"bool": {
"should": [
{
"terms": {
"order": [
"iphone","","iphone4","iphone5","iphone5c"
]
}
}
]
}
}
],
"must": [
{
"range": {
"date": {
"gte": "2014-01-02",
"lte": "2015-12-01"
}
}
}
]
}
},
"sort": [
{
"date": {
"order": "desc"
}
}
]
}NEST Code:
// findArrList = string[] {"iphone","iphone4" ...}
query &= q.Bool(
k => k.MustNot(
p => p.Bool(
l => l.Should(
f => f.Terms(
oq => oq.order, findArrList //order 需要过滤的字段
)
)
)
)
);谢谢
今天关于Elasticsearch嵌套过滤器包含与不包含和elasticsearch嵌套对象的讲解已经结束,谢谢您的阅读,如果想了解更多关于Elastic Search嵌套对象查询、Elasticsearch 2.4,对嵌套对象不起作用存在过滤器、Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana、elasticsearch NEST 不包含指定关键词数组集合精确过滤,后加其他过滤条件的相关知识,请在本站搜索。
本文标签:




