如果您想了解Elasticsearch组和聚合嵌套值和elasticsearch聚合的知识,那么本篇文章将是您的不二之选。我们将深入剖析Elasticsearch组和聚合嵌套值的各个方面,并为您解答e
如果您想了解Elasticsearch组和聚合嵌套值和elasticsearch 聚合的知识,那么本篇文章将是您的不二之选。我们将深入剖析Elasticsearch组和聚合嵌套值的各个方面,并为您解答elasticsearch 聚合的疑在这篇文章中,我们将为您介绍Elasticsearch组和聚合嵌套值的相关知识,同时也会详细的解释elasticsearch 聚合的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- Elasticsearch组和聚合嵌套值(elasticsearch 聚合)
- docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器
- Elastic Search 6嵌套查询聚合
- Elasticsearch (8) --- 聚合查询 (Metric 聚合)
- ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?
")
Elasticsearch组和聚合嵌套值(elasticsearch 聚合)
我想获得一个请求数据来构建这样的东西:
Categories: - laptops (5) - accessories (50) - monitors (10) -- above part is easy --Attributest for actual category ex. laptops: - card reder: - MMC (1) - SD (5) - resolution: - 1024x768 (2) - 2048x1536 (3)首先,我在Elasticsearch上进行映射,如下所示:
{ "mappings": { "product": { "properties": { "name": { "type": "string" }, "categoryName": { "type": "string", "index": "not_analyzed" }, "priceBrutto": { "type": "float" }, "categoryCode": { "type": "integer" }, "productAttributeFields" : { "properties" : { "name" : { "index" : "not_analyzed", "type" : "string" }, "value" : { "index" : "not_analyzed", "type" : "string" } } } } } }}然后我添加对象,如下所示。在productAttributeFields将许多属性。如果笔记本电脑有许多端口,则每个端口都是中的另一个阵列productAttributeFields。
Array( [name] => Macbook Pro [categoryCode] => 123 [categoryName] => Notebooks [priceBrutto] => 1500 [productAttributeFields] => Array ( [0] => Array ( [name] => Resolution [value] => 2048x1536 ) [1] => Array ( [name] => Memory Readers [value] => MMC ) [2] => Array ( [name] => Memory Readers [value] => SD ) ))现在我想要这样的结果:
Array( [took] => 132 [timed_out] => [_shards] => Array ( [total] => 1 [successful] => 1 [failed] => 0 ) [hits] => Array ( [total] => 631 [max_score] => 0 [hits] => Array ( ) ) [aggregations] => Array ( [attrs] => Array ( [doc_count_error_upper_bound] => 0 [sum_other_doc_count] => 4608 [buckets] => Array ( [0] => Array ( [key] => Resolution [doc_count] => 619 [attrsValues] => Array ( [doc_count_error_upper_bound] => 0 [sum_other_doc_count] => 14199 [buckets] => Array ( [0] => Array ( [key] => 2048x1536 [doc_count] => 123 ) [1] => Array ( [key] => 1024x768 [doc_count] => 3 ) ) ) ) [1] => Array ( [key] => Memory Readers [doc_count] => 618 [wartosci] => Array ( [doc_count_error_upper_bound] => 0 [sum_other_doc_count] => 14185 [buckets] => Array ( [0] => Array ( [key] => MMC [doc_count] => 431 ) [1] => Array ( [key] => SD [doc_count] => 430 ) ) ) ) ) ) ))我接近解决问题(我下面的查询),但在第二级聚集我所有的值(例如,在“决议”我有2048x1536,MMC和SD)。我想有"resolution"只"2048x1536","1024x768"并具有其他关键值"resolution",对"cardreaders"只"MMC","SD"以及其他价值具有关键"card readers"。
''body'' => [ ''query'' => [ ''match'' => [ categoryCode = 123 ], ], ''aggs'' => [ ''attrs'' => [ ''terms'' => [ ''field'' => ''productAttributeFields.name'', ], ''aggs'' => [ ''attrsValues'' => [ ''terms'' => [ ''field'' => ''productAttributeFields.value'', ''size'' => 100, ], ], ], ], ],]答案1
小编典典你需要改变你的映射,使productAttributeFields一个nested字段,以便您可以保留之间的关联productAttributeFields.name和productAttributeFields.value。
映射应如下所示:
{ "mappings": { "product": { "properties": { "name": { "type": "string" }, "categoryName": { "type": "string", "index": "not_analyzed" }, "priceBrutto": { "type": "float" }, "categoryCode": { "type": "integer" }, "productAttributeFields": { "type": "nested", "include_in_parent": true, "properties": { "name": { "index": "not_analyzed", "type": "string" }, "value": { "index": "not_analyzed", "type": "string" } } } } } }}然后查询更改为
{ "query": { "match": { "categoryCode": 123 } }, "aggs": { "attrs_root": { "nested": { "path": "productAttributeFields" }, "aggs": { "attrs": { "terms": { "field": "productAttributeFields.name" }, "aggs": { "attrsValues": { "terms": { "field": "productAttributeFields.value", "size": 100 } } } } } } }}
docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器
0. docker pull 拉取 elasticsearch + elasticsearch-head 镜像
1. 启动 elasticsearch Docker 镜像
docker run -di --name tensquare_elasticsearch -p 9200:9200 -p 9300:9300 elasticsearch![]()
对应 IP:9200 ---- 反馈下边 json 数据,表示启动成功

2. 启动 elasticsearch-head 镜像
docker run -d -p 9100:9100 elasticsearch-head![]()
对应 IP:9100 ---- 得到下边页面,即启动成功
3. 解决跨域问题
进入 elasticsearch-head 页面,出现灰色未连接状态 , 即出现跨域问题

1. 根据 docker ps 得到 elasticsearch 的 CONTAINER ID
2. docker exec -it elasticsearch 的 CONTAINER ID /bin/bash 进入容器内
3. cd ./config
4. 修改 elasticsearch.yml 文件
echo "
http.cors.enabled: true
http.cors.allow-origin: ''*''" >> elasticsearch.yml
4. 重启 elasticsearch
docker restart elasticsearch的CONTAINER ID重新进入 IP:9100 进入 elasticsearch-head, 出现绿色标注,配置成功 !

5. ik 分词器的安装
将在 ik 所在的文件夹下,拷贝到 /usr/share/elasticsearch/plugins --- 注意: elasticsearch 的版本号必须与 ik 分词器的版本号一致
docker cp ik elasticsearch的CONTAINER ID:/usr/share/elasticsearch/plugins
重启elasticsearch
docker restart elasticsearch
未添加ik分词器:http://IP:9200/_analyze?analyzer=chinese&pretty=true&text=我爱中国
添加ik分词器后:http://IP:9200/_analyze?analyzer=ik_smart&pretty=true&text=我爱中国
Elastic Search 6嵌套查询聚合
我是elasticsearch查询和聚合的新手。我有一个带有以下映射的嵌套文档
PUT /company{ "mappings": { `"data": { "properties": { "deptId": { "type": "keyword" }, "deptName": { "type": "keyword" }, "employee": { "type": "nested", "properties": { "empId": { "type": "keyword" }, "empName": { "type": "text" }, "salary": { "type": "float" } }}}}}}我已插入示例数据,如下所示
PUT company/data/1{"deptId":"1","deptName":"HR", "employee": [ { "empId": "1", "empName": "John", "salary":"1000" }, { "empId": "2", "empName": "Will", "salary":"2000" } ]}PUT company/data/3{ "deptId":"3", "deptName":"FINANCE", "employee": [ { "empId": "1", "empName": "John", "salary":"1000" }, { "empId": "2", "empName": "Will", "salary":"2000" }, { "empId": "3", "empName": "Mark", "salary":"4000" }] }我如何为以下内容构建查询DSL
- 员工人数最多的部门
- 大多数部门的员工
我正在使用Elastic Search 6.2.4
答案1
小编典典您的第一个问题答案是在此链接中嵌套的内部文档数哪个统计信息
POST test/_search{ "query": { "nested": { "path": "employee", "inner_hits": {} } }}这回答了您的第二个问题,同时也阅读了链接。
GET /my_index/blogpost/_search{ "size" : 0, "aggs": { "employee": { "nested": { "path": "employee" }, "aggs": { "by_name": { "terms": { "field": "employee.empName" } } } } }}阅读嵌套的Agg
我希望这能给您您所需要的。
 --- 聚合查询 (Metric 聚合)")
Elasticsearch (8) --- 聚合查询 (Metric 聚合)
<center> 聚合查询 (Metric 聚合)</center>
说明:该博客对于的 Elasticsearch 的版本为 7.3。
在 Mysql 中,我们可以获取一组数据的 最大值 (Max)、最小值 (Min)。同样我们能够对这组数据进行 分组 (Group)。那么对于 Elasticsearch 中
我们也可以实现同样的功能,聚合有关资料官方文档内容较多,这里大概分两篇博客写这个有关 Elasticsearch 聚合。
官方对聚合有四个关键字: Metric(指标)、Bucketing(桶)、Matrix(矩阵)、Pipeline(管道)。
<font color=#FFD700> 一、聚合概念 </font>
1. ES 聚合分析是什么?
概念 Elasticsearch 除全文检索功能外提供的针对 Elasticsearch 数据做统计分析的功能。它的实时性高,所有的计算结果都是即时返回。 Elasticsearch 将聚合分析主要分为如下 4 类:
Metric(指标): 指标分析类型,如计算最大值、最小值、平均值等等 (对桶内的文档进行聚合分析的操作)
Bucket(桶): 分桶类型,类似SQL中的GROUP BY语法 (满足特定条件的文档的集合)
Pipeline(管道): 管道分析类型,基于上一级的聚合分析结果进行在分析
Matrix(矩阵): 矩阵分析类型(聚合是一种面向数值型的聚合,用于计算一组文档字段中的统计信息)
2.ES 聚合分析查询的写法
在查询请求体中以 aggregations 节点按如下语法定义聚合分析:
"aggregations" : {
"<aggregation_name>" : { <!--聚合的名字 -->
"<aggregation_type>" : { <!--聚合的类型 -->
<aggregation_body> <!--聚合体:对哪些字段进行聚合 -->
}
[,"meta" : { [<meta_data_body>] } ]? <!--元 -->
[,"aggregations" : { [<sub_aggregation>]+ } ]? <!--在聚合里面在定义子聚合 -->
}
[,"<aggregation_name_2>" : { ... } ]* <!--聚合的名字 -->
}
说明:aggregations 也可简写为 aggs
3、指标(metric)和 桶(bucket)
虽然 Elasticsearch 有四种聚合方式,但在一般实际开发中,用到的比较多的就是 Metric 和 Bucket。
**(1) 桶(bucket) **
a、简单来说桶就是满足特定条件的文档的集合。
b、当聚合开始被执行,每个文档里面的值通过计算来决定符合哪个桶的条件,如果匹配到,文档将放入相应的桶并接着开始聚合操作。
c、桶也可以被嵌套在其他桶里面。
(2)指标(metric)
a、桶能让我们划分文档到有意义的集合,但是最终我们需要的是对这些桶内的文档进行一些指标的计算。分桶是一种达到目的地的手段:它提供了一种给文档分组的方法来让
我们可以计算感兴趣的指标。
b、大多数指标是简单的数学运算(如:最小值、平均值、最大值、汇总),这些是通过文档的值来计算的。 <br>
<font color=#FFD700> 二、指标(Metric)详解 </font>
官网: 指标聚合官网文档:Metric
Metric 聚合分析分为单值分析和多值分析两类:
#1、单值分析,只输出一个分析结果
min,max,avg,sum,cardinality
#2、多值分析,输出多个分析结果
stats,extended_stats,percentile,percentile_rank,top hits
1、Avg (平均值)
计算从聚合文档中提取的数值的平均值。
POST /exams/_search?size=0
{
"aggs" : {
"avg_grade" : { "avg" : { "field" : "grade" } }
}
}
2、Max (最大值)
计算从聚合文档中提取的数值的最大值。
POST /sales/_search?size=0
{
"aggs" : {
"max_price" : { "max" : { "field" : "price" } }
}
}
3、Min (最小值)
计算从聚合文档中提取的数值的最小值。
POST /sales/_search?size=0
{
"aggs" : {
"min_price" : { "min" : { "field" : "price" } }
}
}
4、Sum (总和)
计算从聚合文档中提取的数值的总和。
POST /sales/_search?size=0
{
"query" : {
"constant_score" : {
"filter" : {
"match" : { "type" : "hat" }
}
}
},
"aggs" : {
"hat_prices" : { "sum" : { "field" : "price" } }
}
}
5、 Cardinality (唯一值)
cardinality 求唯一值,即不重复的字段有多少(相当于 mysql 中的 distinct)
POST /sales/_search?size=0
{
"aggs" : {
"type_count" : {
"cardinality" : {
"field" : "type"
}
}
}
}
6、Stats
stats 统计,请求后会直接显示多种聚合结果
POST /exams/_search?size=0
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "grade" } }
}
}
返回
{
...
"aggregations": {
"grades_stats": {
"count": 2,
"min": 50.0,
"max": 100.0,
"avg": 75.0,
"sum": 150.0
}
}
}
7、Percentiles
对指定字段的值按从小到大累计每个值对应的文档数的占比,返回指定占比比例对应的值。
1)默认取百分比
默认按照 [1, 5, 25, 50, 75, 95, 99] 来统计
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time"
}
}
}
}
返回结果可以理解为:占比为 50% 的文档的 age 值 <= 445,或反过来:age<=445 的文档数占总命中文档数的 50%
{
...
"aggregations": {
"load_time_outlier": {
"values" : {
"1.0": 5.0,
"5.0": 25.0,
"25.0": 165.0,
"50.0": 445.0,
"75.0": 725.0,
"95.0": 945.0,
"99.0": 985.0
}
}
}
}
2)指定分位值
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_outlier" : {
"percentiles" : {
"field" : "load_time",
"percents" : [95, 99, 99.9]
}
}
}
}
Keyed Response
默认情况下,keyed 标志设置为 true,它将唯一的字符串键与每个存储桶相关联,并将范围作为哈希而不是数组返回。
GET latency/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "load_time",
"keyed": false
}
}
}
}
返回结果
{
...
"aggregations": {
"load_time_outlier": {
"values": [
{
"key": 1.0,
"value": 5.0
},
{
"key": 5.0,
"value": 25.0
},
{
"key": 25.0,
"value": 165.0
},
{
"key": 50.0,
"value": 445.0
},
{
"key": 75.0,
"value": 725.0
},
{
"key": 95.0,
"value": 945.0
},
{
"key": 99.0,
"value": 985.0
}
]
}
}
}
8、 Percentile Ranks
上面是通过百分比求文档值,这里通过文档值求百分比。
GET latency/_search
{
"size": 0,
"aggs" : {
"load_time_ranks" : {
"percentile_ranks" : {
"field" : "load_time",
"values" : [500, 600]
}
}
}
}
返回结果
{
...
"aggregations": {
"load_time_ranks": {
"values" : {
"500.0": 55.1,
"600.0": 64.0
}
}
}
}
结果说明:时间小于 500 的文档占比为 55.1%,时间小于 600 的文档占比为 64%,
9、Top Hits
一般用于分桶后获取该桶内匹配前 n 的文档列表
POST /sales/_search?size=0
{
"aggs": {
"top_tags": {
"terms": {
"field": "type", #根据type进行分组 每组显示前3个文档
"size": 3
},
"aggs": {
"top_sales_hits": {
"top_hits": {
"sort": [
{
"date": {
"order": "desc" #按照时间进行倒叙排序
}
}
],
"_source": {
"includes": [ "date", "price" ] #只显示文档指定字段
},
"size" : 1
}
}
}
}
}
}
<br>
<font color=#FFD700> 三、示例 </font>
下面会针对上面官方文档的例子进行举例说明。
####1、添加测试数据
1)创建索引
DELETE /employees
PUT /employees/
{
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"gender" : {
"type" : "keyword"
},
"job" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 50
}
}
},
"name" : {
"type" : "keyword"
},
"salary" : {
"type" : "integer"
}
}
}
}
2) 添加数据
添加 10 条数据,每条数据包含:姓名、年龄、工作、性别、薪资
PUT /employees/_bulk
{ "index" : { "_id" : "1" } }
{ "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 }
{ "index" : { "_id" : "2" } }
{ "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000}
{ "index" : { "_id" : "3" } }
{ "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 }
{ "index" : { "_id" : "4" } }
{ "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000}
{ "index" : { "_id" : "5" } }
{ "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 }
{ "index" : { "_id" : "6" } }
{ "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000}
{ "index" : { "_id" : "7" } }
{ "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 }
{ "index" : { "_id" : "8" } }
{ "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000}
{ "index" : { "_id" : "9" } }
{ "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 }
{ "index" : { "_id" : "10" } }
{ "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000}
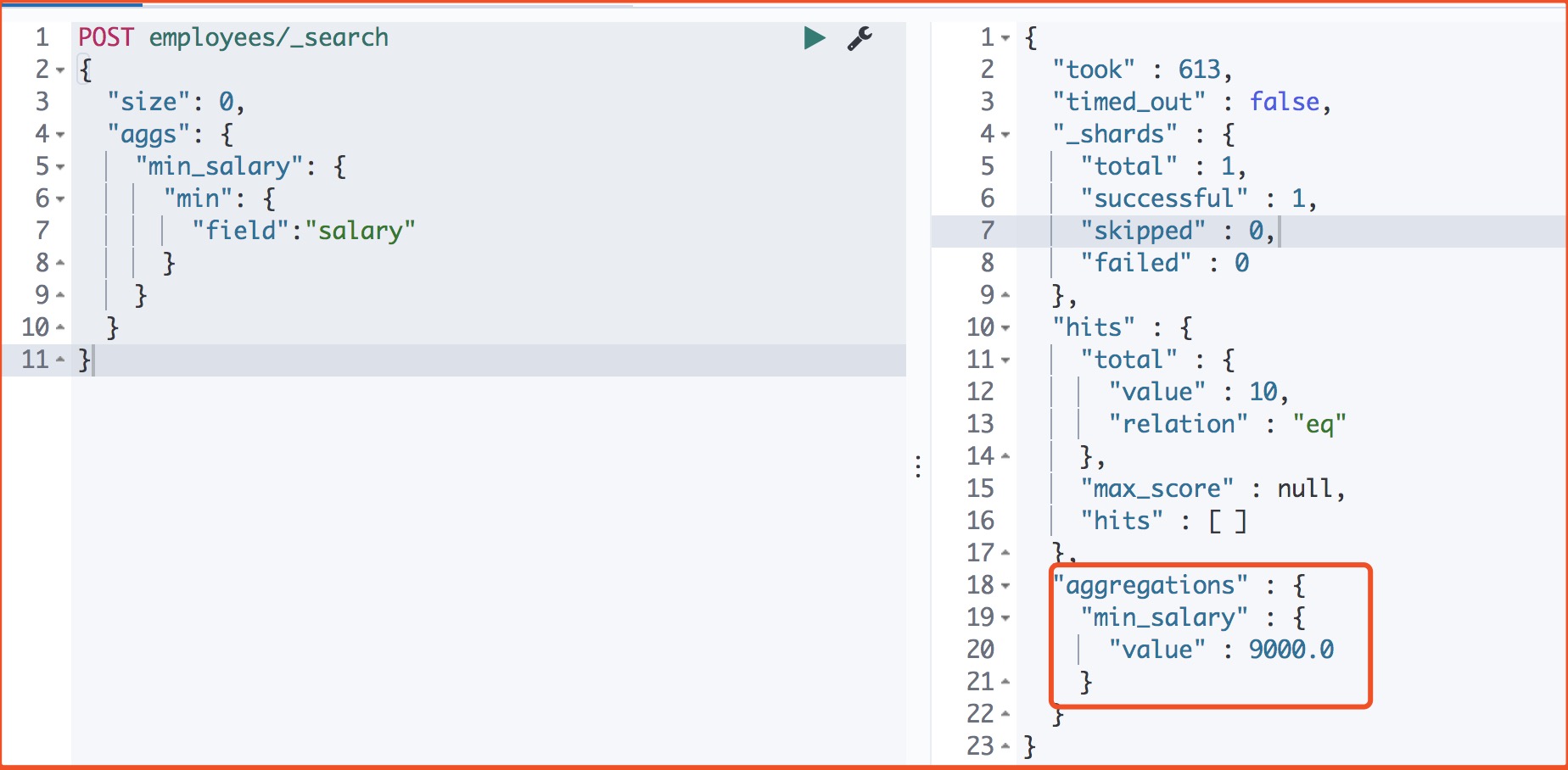
####2、求薪资最低值
POST employees/_search
{
"size": 0,
"aggs": {
"min_salary": {
"min": {
"field":"salary"
}
}
}
}
返回
####3、找到最低、最高和平均工资
POST employees/_search
{
"size": 0,
"aggs": {
"max_salary": {
"max": {
"field": "salary"
}
},
"min_salary": {
"min": {
"field": "salary"
}
},
"avg_salary": {
"avg": {
"field": "salary"
}
}
}
}
####4、一个聚合,输出多值
POST employees/_search
{
"size": 0,
"aggs": {
"stats_salary": {
"stats": {
"field":"salary"
}
}
}
}
返回

####5、求一共有多少工作类型
POST employees/_search
{
"size": 0,
"aggs": {
"cardinate": {
"cardinality": {
"field": "job.keyword"
}
}
}
}
返回
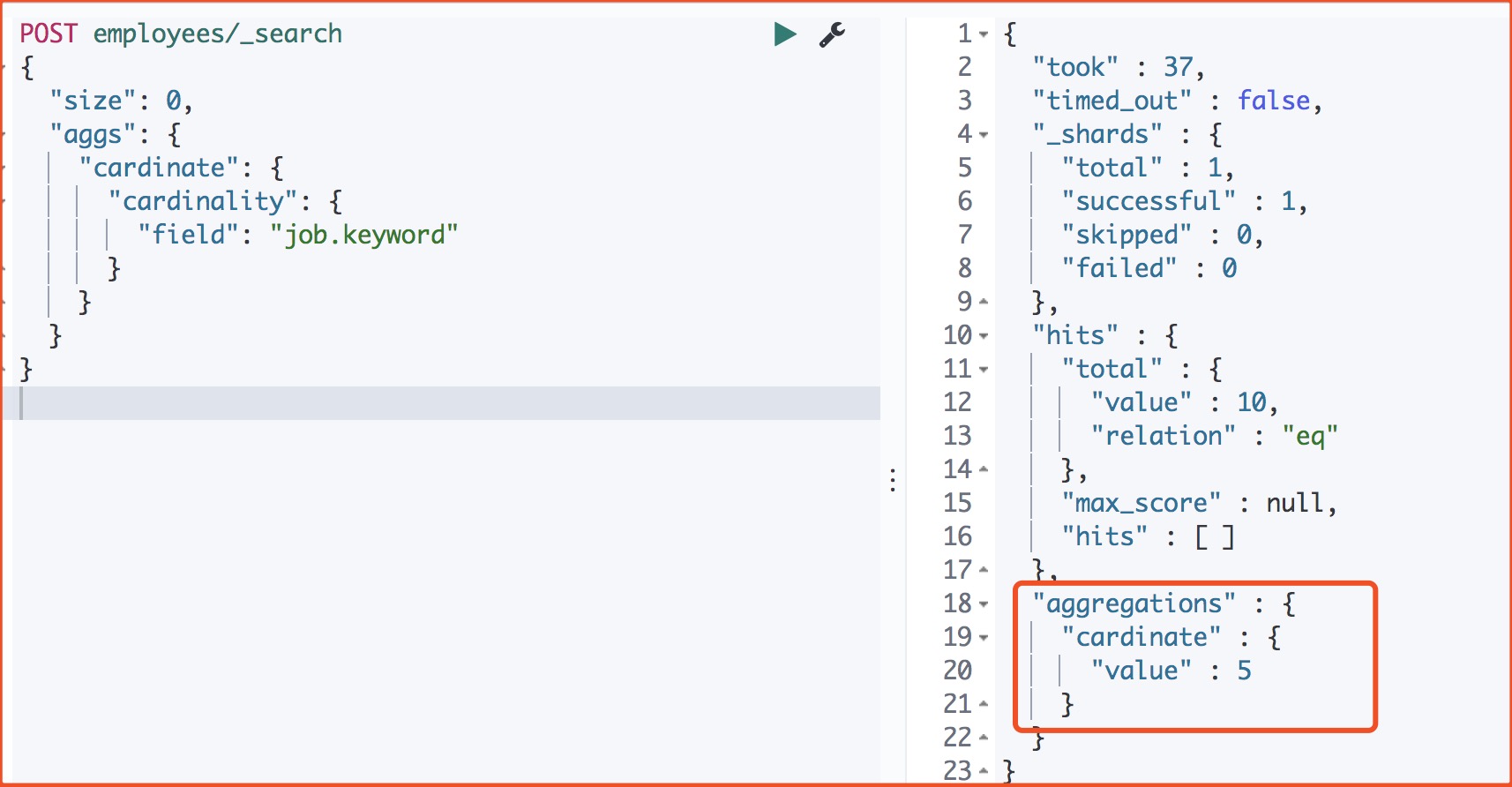
注意 我们需要把 job 的类型为 keyword 类型,这样就不会分词,把它当成一个整体。
####6、查看中位数的薪资
POST employees/_search
{
"size": 0,
"aggs": {
"load_time_outlier": {
"percentiles": {
"field": "salary",
"percents" : [50, 99],
"keyed": false
}
}
}
}
返回
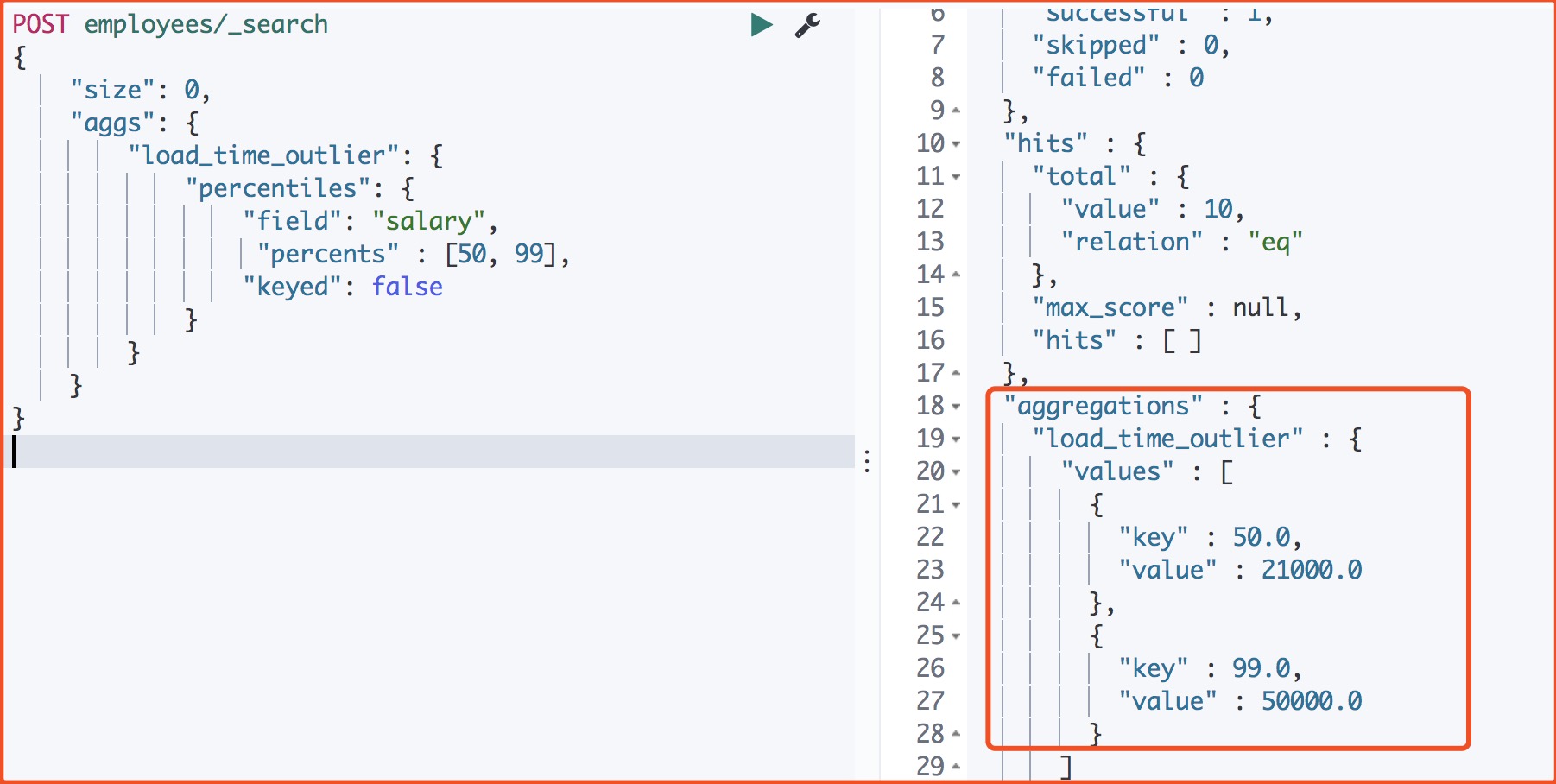
发现这些工作的中位数是:21000 元。
####7、取每个工作类型薪资最高的数据
多层嵌套 根据工作类型分桶,然后按照性别分桶,计算每个桶中工资的最高的薪资。
POST employees/_search
{
"size": 0,
"aggs": {
"Job_gender_stats": {
"terms": {
"field": "job.keyword"
},
"aggs": {
"gender_stats": {
"terms": {
"field": "gender"
},
"aggs": {
"salary_stats": {
"max": {
"field": "salary"
}
}
}
}
}
}
}
}
返回

<br>
<font color=#FFD700> 参考 </font>
1、Elasticsearch 核心技术与实战 --- 阮一鸣 (eBay Pronto 平台技术负责人
2、ES7.3 版官方聚合查询 API
3、Elasticsearch 聚合分析 <br> <br>
我相信,无论今后的道路多么坎坷,只要抓住今天,迟早会在奋斗中尝到人生的甘甜。抓住人生中的一分一秒,胜过虚度中的一月一年!(12)
<br>
原文出处:https://www.cnblogs.com/qdhxhz/p/11556764.html
 ElasticSearch 的应用场景及为什么要选择 ElasticSearch?")
ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?
先了解一下数据的分类
结构化数据
又可以称之为行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。其实就是可以能够用数据或者统一的结构加以表示的数据。比如在数据表存储商品的库存,可以用整型表示,存储价格可以用浮点型表示,再比如给用户存储性别,可以用枚举表示,这都是结构化数据。
非结构化数据
无法用数字或者统一的结构表示的数据,称之为飞结构化数据。如:文本、图像、声音、网页。
其实结构化数据又数据非结构化数据。商品标题、描述、文章描述都是文本,其实文本就是非结构化数据。那么就可以说非结构化数据即为全文数据。
什么是全文检索?
一种将文件或者数据库中所有文本与检索项相匹配的文字资料检索方法,称之为全文检索。
全文检索的两种方法
顺序扫描法:将数据表的所有数据逐个扫描,再对文字描述扫描,符合条件的筛选出来,非常慢!
索引扫描法:全文检索的基本思路,也就是将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对快的目的。
全文检索的过程:
先索引的创建,然后索引搜索
为什么要选择用 ElasticSearch?
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
分布式的实时文件存储,每个字段都被索引可被搜索。
分布式的实时分析搜索引擎。
可以扩展到上百台服务器,处理 PB 级别结构化或者非结构化数据。
所有功能集成在一个服务器里,可以通过 RESTful API、各种语言的客户端甚至命令与之交互。
上手容易,提供了很多合理的缺省值,开箱即用,学习成本低。
可以免费下载、使用和修改。
配置灵活,比 Sphinx 灵活的多。
关于Elasticsearch组和聚合嵌套值和elasticsearch 聚合的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于docker 部署 elasticsearch + elasticsearch-head + elasticsearch-head 跨域问题 + IK 分词器、Elastic Search 6嵌套查询聚合、Elasticsearch (8) --- 聚合查询 (Metric 聚合)、ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?等相关内容,可以在本站寻找。
本文标签:




