如果您对在elasticsearch实例上打开开放的GCE防火墙以进行外部连接和elasticsearch对外访问感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解在elasticsearch实例
如果您对在elasticsearch实例上打开开放的GCE防火墙以进行外部连接和elasticsearch对外访问感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解在elasticsearch实例上打开开放的GCE防火墙以进行外部连接的各种细节,并对elasticsearch对外访问进行深入的分析,此外还有关于Debezium Postgres和ElasticSearch-在ElasticSearch中存储复杂对象、ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?、Elasticsearch - Logstash实现mysql同步数据到elasticsearch、Elasticsearch - 如何对多个用户进行 elasticsearch 身份验证的实用技巧。
本文目录一览:- 在elasticsearch实例上打开开放的GCE防火墙以进行外部连接(elasticsearch对外访问)
- Debezium Postgres和ElasticSearch-在ElasticSearch中存储复杂对象
- ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?
- Elasticsearch - Logstash实现mysql同步数据到elasticsearch
- Elasticsearch - 如何对多个用户进行 elasticsearch 身份验证
")
在elasticsearch实例上打开开放的GCE防火墙以进行外部连接(elasticsearch对外访问)
我刚刚使用“单击部署”在GCE中创建了Elasticsearch集群,但是我只能使用隧道来访问它。就我而言,这不是一个选择,因为我不想让gcloud访问其他开发人员。我想为elasticsearch打开端口9200,以便他们可以通过IP地址而不是通过隧道连接到它。
我该如何实现?
答案1
小编典典在GCE防火墙中为elasticsearch实例打开端口9200。通过“单击部署”创建的elasticsearch实例已定义了“
elasticsearch”标签,因此,您可以使用以下命令:
gcloud compute --project PROJECT firewall-rules create allow-elasticsearch \ --allow TCP:9200 \ --target-tags elasticsearch-编辑以纠正Elasticsearch的拼写错误

Debezium Postgres和ElasticSearch-在ElasticSearch中存储复杂对象
您需要使用发件箱模式,请参见https://debezium.io/documentation/reference/1.2/configuration/outbox-event-router.html
或者您可以使用聚合对象,请参见 https://github.com/debezium/debezium-examples/tree/master/jpa-aggregations https://github.com/debezium/debezium-examples/tree/master/kstreams-fk-join
 ElasticSearch 的应用场景及为什么要选择 ElasticSearch?")
ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?
先了解一下数据的分类
结构化数据
又可以称之为行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据。其实就是可以能够用数据或者统一的结构加以表示的数据。比如在数据表存储商品的库存,可以用整型表示,存储价格可以用浮点型表示,再比如给用户存储性别,可以用枚举表示,这都是结构化数据。
非结构化数据
无法用数字或者统一的结构表示的数据,称之为飞结构化数据。如:文本、图像、声音、网页。
其实结构化数据又数据非结构化数据。商品标题、描述、文章描述都是文本,其实文本就是非结构化数据。那么就可以说非结构化数据即为全文数据。
什么是全文检索?
一种将文件或者数据库中所有文本与检索项相匹配的文字资料检索方法,称之为全文检索。
全文检索的两种方法
顺序扫描法:将数据表的所有数据逐个扫描,再对文字描述扫描,符合条件的筛选出来,非常慢!
索引扫描法:全文检索的基本思路,也就是将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对快的目的。
全文检索的过程:
先索引的创建,然后索引搜索
为什么要选择用 ElasticSearch?
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
分布式的实时文件存储,每个字段都被索引可被搜索。
分布式的实时分析搜索引擎。
可以扩展到上百台服务器,处理 PB 级别结构化或者非结构化数据。
所有功能集成在一个服务器里,可以通过 RESTful API、各种语言的客户端甚至命令与之交互。
上手容易,提供了很多合理的缺省值,开箱即用,学习成本低。
可以免费下载、使用和修改。
配置灵活,比 Sphinx 灵活的多。

Elasticsearch - Logstash实现mysql同步数据到elasticsearch
有的时候,我们在做查询时,由于查询条件的多样、变化多端(比如根据时间查、根据名称模糊查、根据id查等等),或者查询的数据来自很多不同的库表或者系统,这时就很难以一个较快的速度(几百毫秒)去从关系型数据库中直接获取我们想要的数据。
针对上面的情况,可以考虑使用elasticsearch来进行数据的汇总,然后提供给后台进行搜索,可以大大提高检索的效率。
数据在存储在关系型数据库(如mysql)中,我们怎样将这部分数据转移到elasticsearch中。这篇文章将介绍一个同步神器:logstash-input-jdbc
安装
- 在官网下载最新的安装包:
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz解压并转移目录:
tar zxvf logstash-6.2.4.tar.gz mv ./logstash-6.2.4 /usr/local/logstash
配置
- 安装插件
由于这里是从mysql同步数据到elasticsearch,所以需要安装jdbc的入插件和elasticsearch的出插件:logstash-input-jdbc、logstash-output-elasticsearch
安装效果图如下所示:
- 下载mysql连接库
由于logstash是ruby开发的,所以这里要下载mysql的连接库jar包,从官网下载,我这里下载的是:mysql-connector-java-5.1.46.jar
将下载好的mysql-connector-java-5.1.46.jar,放至/usr/local/logstash/config/目录下。- 修改配置文件
在config目录下,创建配置文件(logstash-mysql-es.conf):这里有几个注意点:input { jdbc { # mysql相关jdbc配置 jdbc_connection_string => "jdbc:mysql://10.112.76.30:3306/jack_test?useUnicode=true&characterEncoding=utf-8&useSSL=false" jdbc_user => "root" jdbc_password => "123456" # jdbc连接mysql驱动的文件目录,可去官网下载:https://dev.mysql.com/downloads/connector/j/ jdbc_driver_library => "./config/mysql-connector-java-5.1.46.jar" # the name of the driver class for mysql jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_paging_enabled => true jdbc_page_size => "50000" jdbc_default_timezone =>"Asia/Shanghai" # mysql文件, 也可以直接写SQL语句在此处,如下: # statement => "select * from t_order where update_time >= :sql_last_value;" statement_filepath => "./config/jdbc.sql" # 这里类似crontab,可以定制定时操作,比如每分钟执行一次同步(分 时 天 月 年) schedule => "* * * * *" #type => "jdbc" # 是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中 #record_last_run => true # 是否需要记录某个column 的值,如果record_last_run为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值. use_column_value => true # 如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的. 一般是mysql主键 tracking_column => "update_time" tracking_column_type => "timestamp" last_run_metadata_path => "./logstash_capital_bill_last_id" # 是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录 clean_run => false #是否将 字段(column) 名称转小写 lowercase_column_names => false } } output { elasticsearch { hosts => "10.112.76.31:9200" index => "mysql_order" document_id => "%{id}" template_overwrite => true } # 这里输出调试,正式运行时可以注释掉 stdout { codec => json_lines } }
(1)jdbc_driver_library
mysql-connector-java-5.1.46.jar的存放目录,这个一定要配置正确,支持全路径和相对路径。如果配置不对,将会报“can ”错误。
(2)sql_last_value
标志目前logstash同步的位置信息(类似offset)。比如id、updatetime。logstash通过这个标志,可以判断目前同步到哪一条数据。
(3)statement、statement_filepath
statement:执行同步的sql语句,可以同步部分数据。
statement_filepath:存储执行同步的sql语句。不和statement同时使用。
(4)schedule
定时器,表示每隔多长时间同步一次数据。格式类似crontab。
(5)tracking_column、tracking_column_type
tracking_column:表示表中哪一列用于判断logstash同步的位置信息。与sql_last_value比较判断是否需要同步这条数据。
tracking_column_type:racking_column指定列的类型。支持两种类型:numeric(默认)、timestamp。注意:如果列是时间字段(比如updateTime),一定要指定这个类型为timestamp。我就踩了这个大坑。。。一直同步不成功!!!
(6)last_run_metadata_path
存储sql_last_value值的文件名称及位置。
(7)document_id
生成elasticsearch的文档值,尽量使用同步的数据中已有的唯一标识。比如同步订单数据,可以使用订单号。


启动
在根目录下,执行命令:
nohup bin/logstash -f config/logstash-mysql-es.conf > logs/logstash.out &效果图如下:
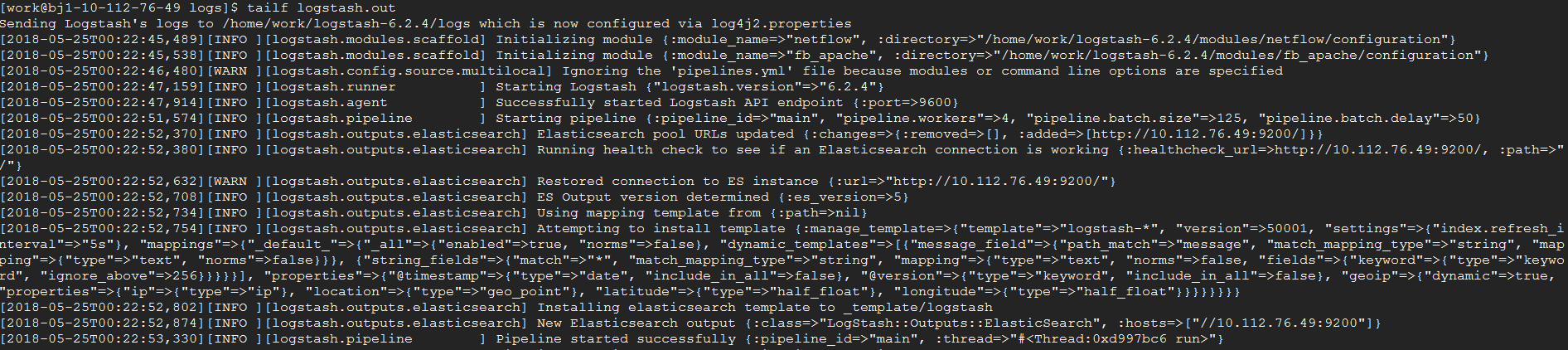
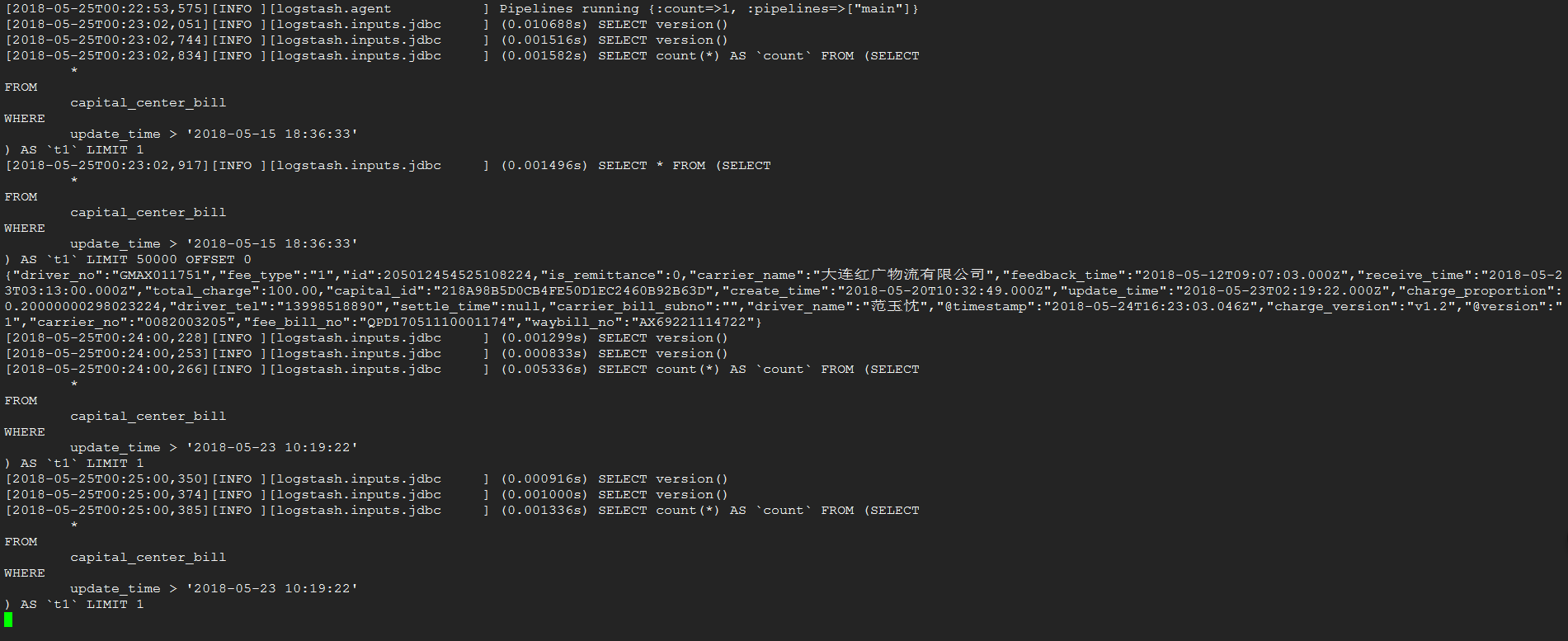
同步
完成了一条数据的同步

Elasticsearch - 如何对多个用户进行 elasticsearch 身份验证
如何解决Elasticsearch - 如何对多个用户进行 elasticsearch 身份验证?
我们正在尝试在 AWS 单独的租户(客户)之上创建管理弹性并分配每个 tetant 到不同的指标。
每个客户都有他的用户名/通行证或类似令牌等''。
我们在 aws 上设置了托管 ES 并与原生 Elastic sdk HighRestClinet
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10</version>
</dependency>
一切正常,我们从java代码执行的所有操作,如创建索引/管理/搜索等''
这种代码的和平模拟这里描述的基本身份验证 https://www.elastic.co/guide/en/elasticsearch/client/java-rest/master/_basic_authentication.html
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,new UsernamePasswordCredentials(settings.getEsUserName(),settings.getEsUserPass()));
restClientBuilder.setHttpClientConfigCallback(builder -> builder.setDefaultCredentialsProvider(credentialsProvider));
现在我们为每个客户创建不同的索引,这是可以的,但是
问题是现在我们所有的客户都将使用相同的用户名/密码。
是否有可能以某种方式对多个用户进行处理,拥有多个用户/通行证?
因此每个用户只能与其通过密码验证的索引进行交互。
我看到了这个案例 - https://docs.aws.amazon.com/elasticsearch-service/latest/developerguide/fgac.html#fgac-walkthrough-basic
正如我从阅读中了解到的,他们谈论的是 kibana 用户的多租户
我是否遗漏了什么,是否有可能以不同的方式实现我们的目标?
谢谢,
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
今天关于在elasticsearch实例上打开开放的GCE防火墙以进行外部连接和elasticsearch对外访问的介绍到此结束,谢谢您的阅读,有关Debezium Postgres和ElasticSearch-在ElasticSearch中存储复杂对象、ElasticSearch (一) ElasticSearch 的应用场景及为什么要选择 ElasticSearch?、Elasticsearch - Logstash实现mysql同步数据到elasticsearch、Elasticsearch - 如何对多个用户进行 elasticsearch 身份验证等更多相关知识的信息可以在本站进行查询。
本文标签:




