本文将介绍更新生产中的ElasticSearch映射的详细情况,特别是关于tyre的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于Elasticse
本文将介绍更新生产中的ElasticSearch映射的详细情况,特别是关于 tyre的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于Elasticsearch 2.3.3 搜索引擎的elasticsearch-jdbc插件安装、Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana、Elasticsearch 参考指南(重要的Elasticsearch配置)、ElasticSearch 工具类封装(基于ElasticsearchTemplate)的知识。
本文目录一览:- 更新生产中的ElasticSearch映射( tyre)(elasticsearch映射类型)
- Elasticsearch 2.3.3 搜索引擎的elasticsearch-jdbc插件安装
- Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana
- Elasticsearch 参考指南(重要的Elasticsearch配置)
- ElasticSearch 工具类封装(基于ElasticsearchTemplate)
(elasticsearch映射类型)")
更新生产中的ElasticSearch映射( tyre)(elasticsearch映射类型)
我想对如何处理以下情况有清楚的了解:
我正在从activerecord模型中添加或删除属性,所以我想在生产中的ElasticSearch中更新其映射。
据我了解,我应该…
1-创建一个新索引并从mysql导入所有内容
这是正确的命令吗?rake environment tire:importBow'' INDEX=''new-bows''
为了创建正确的映射,我应该已经在模型中更新了映射,对吗?
2-删除旧的映射并创建一个别名bows为new-bows
我会那样做,对吗?
old_index_name = Bow.tire.index.nameBow.tire.index.deletealias = Tire::Alias.newalias.name(old_index_name)alias.index(''new-bows'')alias.save3-重启应用
我是否缺少某些东西,或者是否有更简单的方法来使用Tyre实现我想要的?
我应该在什么时候删除旧索引? 在使用相同名称创建别名之前,还是可以在以后使用别名?
答案1
小编典典您应该保留旧索引,直到确定新索引是所需的100%。如果不是这种情况,您可以向后翻转别名。
Tire测试套件中有一个针对“翻转别名”的集成测试。

Elasticsearch 2.3.3 搜索引擎的elasticsearch-jdbc插件安装
Elasticsearch 2.3.3的jdbc插件安装跟之前的版本是不一样的,之前的版本,网上的内容介绍的都是elasticsearch使用river同步mysql数据 ,哪些都是老的文章了,最新的版本是不适用的。那么我们如何从数据库导入数据呢?其实安装 Elasticsearch 2.3.3 的JDBC插件很简单,只不过,安装完以后的配置,稍微有些麻烦。
第一步:下载JDBC链接包
具体可以执行下面的命令:
wget http://xbib.org/repository/org/xbib/elasticsearch/importer/elasticsearch-jdbc/2.3.3.0/elasticsearch-jdbc-2.3.3.0-dist.zip
第二步: 解压 elasticsearch-jdbc-2.3.3.0-dist.zip
unzip elasticsearch-jdbc-2.3.3.0-dist.zip
第三步:进入elasticsearch-jdbc-2.3.3.0/bin目录
我们看到下面有很多链接数据库的样例文件。
我们以MSYQL为例,做一个基本的介绍。
第四步:编辑mysql-blog.sh,修改成如下的样子。
#!/bin/sh
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
bin=${DIR}/../bin
lib=${DIR}/../lib
echo ''
{
"type" : "jdbc",
"jdbc" : {
"url" : "jdbc:mysql://192.168.1.100:3306/hotel?useUnicode=true&characterEncoding=gbk",
"statefile" : "statefile.json",
"user" : "root",
"password" : "root",
"sql" : "select * from hotel",
"index" : "hotel",
"type" : "hotel",
"elasticsearch" : {
"cluster" : "elasticsearch",
"host" : "192.168.133.134",
"port" : 9300
}
}
}
'' | java \
-cp "${lib}/*" \
-Dlog4j.configurationFile=${bin}/log4j2.xml \
org.xbib.tools.Runner \
org.xbib.tools.JDBCImporter
上述脚本的意思是:链接192.168.1.100这个机器上的hotel数据库,将此数据库中的hotel数据全部导入到hotel索引中。导入的集群名称是elasticsearch,搜索引擎访问地址是192.168.133.132.
第五步,结合之前的内容,我们搭建了 elasticsearch 集群,但是没有建立索引。
我们可以再head插件中新建索引.
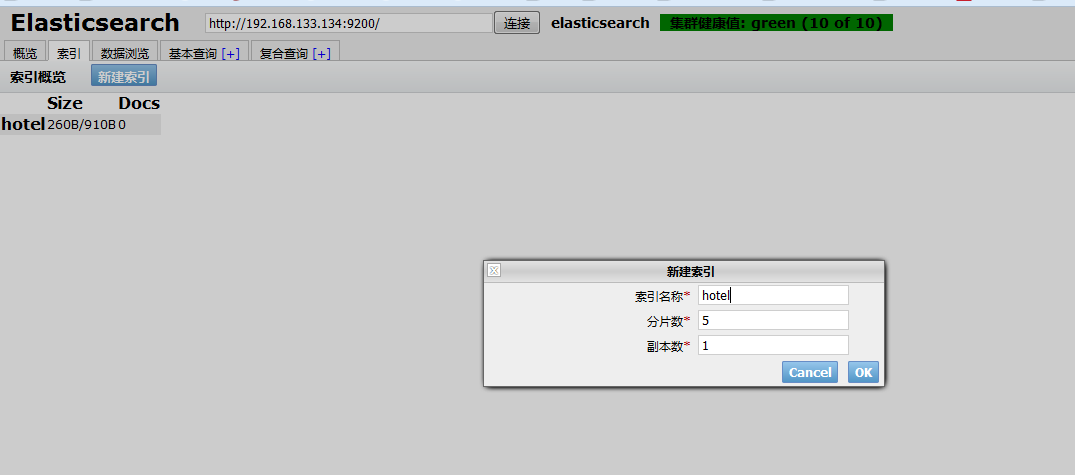
索引创建成功后,我们可以在 “概览”里面看到新建的索引。

暂且不表分片和复制。我们看到我们成功了创建了一个hotel索引,目前索引中文档个数为0.
第六步,执行刚才修改的mysql-blog.sh脚本。
执行之前确定你的Mysql数据库已经启动,并且数据库的链接账号和密码存在。
我的数据库中是5W条酒店的数据。

脚本执行完成后,5W条数据从导入到索引创建完成,大约是2分钟,速度还是蛮快的。,我们再次查看head插件,可以看到,文件个数已经发生了变化。

好了,本篇文章就写到这里,其实ElasticSerach-jdbc导入数据还有很多的参数。
大家可以看https://github.com/jprante/elasticsearch-jdbc 文章,或者点击链接观看 数航教育的在线视频教程

Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana
CentOS6.5下安装ElasticSearch6.2.4
(1)配置JDK环境
配置环境变量
export JAVA_HOME="/opt/jdk1.8.0_144"
export PATH="$JAVA_HOME/bin:$PATH"
export CLASSPATH=".:$JAVA_HOME/lib"
(2)安装ElasticSearch6.2.4
下载地址:https://www.elastic.co/cn/downloads/past-releases/elasticsearch-6-2-4
启动报错:
解决方式:
bin/elasticsearch -Des.insecure.allow.root=true
或者修改bin/elasticsearch,加上ES_JAVA_OPTS属性:
ES_JAVA_OPTS="-Des.insecure.allow.root=true"
再次启动:
这是出于系统安全考虑设置的条件。由于ElasticSearch可以接收用户输入的脚本并且执行,为了系统安全考 虑,建议创建一个单独的用户用来运行ElasticSearch。
如果没有普通用户就要创建一个普通用户组和普通用户,下面介绍一下怎么创建用户组和普通用户
创建用户组和用户:
groupadd esgroup
useradd esuser -g esgroup -p espassword
更改elasticsearch文件夹及内部文件的所属用户及组:
cd /opt
chown -R esuser:esgroup elasticsearch-6.2.4
切换用户并运行:
su esuser
./bin/elasticsearch
再次启动显示已杀死:
需要调整JVM的内存大小:
vi bin/elasticsearch
ES_JAVA_OPTS="-Xms512m -Xmx512m"
再次启动:启动成功
如果显示如下类似信息:
[INFO ][o.e.c.r.a.DiskThresholdMonitor] [ZAds5FP] low disk watermark [85%] exceeded on [ZAds5FPeTY-ZUKjXd7HJKA][ZAds5FP][/opt/elasticsearch-6.2.4/data/nodes/0] free: 1.2gb[14.2%], replicas will not be assigned to this node
需要清理磁盘空间。
后台运行:./bin/elasticsearch -d
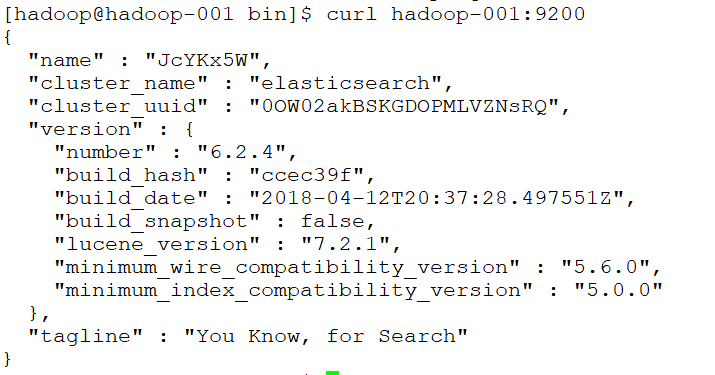
测试连接:curl 127.0.0.1:9200
会看到一下JSON数据:
[root@localhost ~]# curl 127.0.0.1:9200
{
"name" : "rBrMTNx",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "-noR5DxFRsyvAFvAzxl07g",
"version" : {
"number" : "5.1.1",
"build_hash" : "5395e21",
"build_date" : "2016-12-06T12:36:15.409Z",
"build_snapshot" : false,
"lucene_version" : "6.3.0"
},
"tagline" : "You Know, for Search"
}
实现远程访问:
需要对config/elasticsearch.yml进行 配置:
network.host: hadoop-001
再次启动报错:Failed to load settings from [elasticsearch.yml]
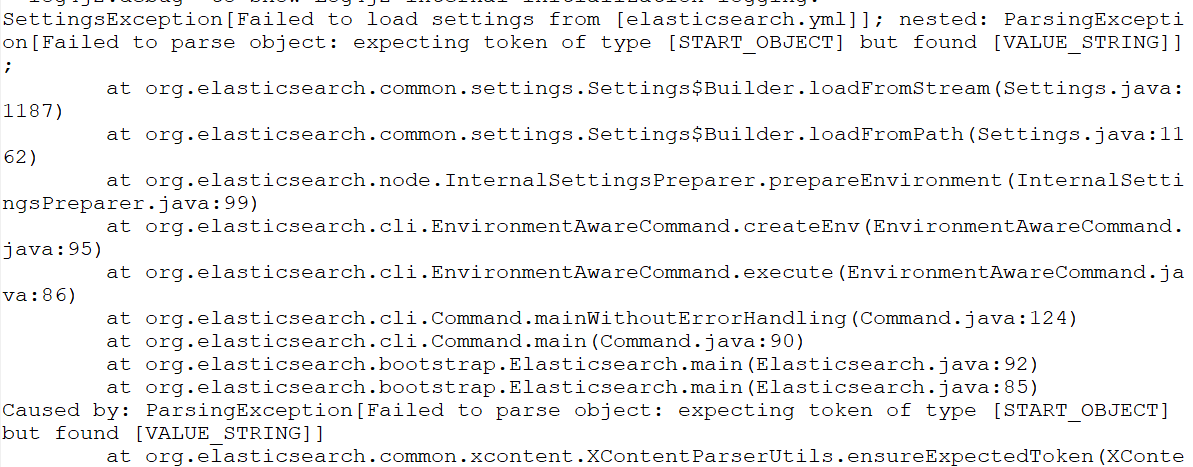
这个错就是参数的冒号前后没有加空格,加了之后就好,我找了好久这个问题;
后来在一个外国网站找到了这句话.
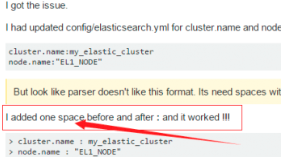
Exception in thread "main" SettingsException[Failed to load settings from [elasticsearch.yml]]; nested: ElasticsearchParseException[malformed, expected end of settings but encountered additional content starting at line number: [3], column number: [1]]; nested: ParserException[expected ''<document start>'', but found BlockMappingStart
in ''reader'', line 3, column 1:
node.rack : r1
^
];
Likely root cause: expected ''<document start>'', but found BlockMappingStart
in ''reader'', line 3, column 1:
node.rack : r1
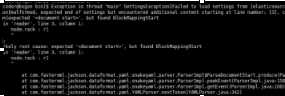
这个是行的开头没有加空格,fuck!
Exception in thread "main" SettingsException[Failed to load settings from [elasticsearch.yml]]; nested: ScannerException[while scanning a simple key
in ''reader'', line 11, column 2:
discovery.zen.ping.unicast.hosts ...
^

参数冒号后加空格,或者是数组中间加空格
例如:
# discovery.zen.minimum_master_nodes: 3
再次启动
还是报错
max file descriptors [4096] for elasticsearch process is too low
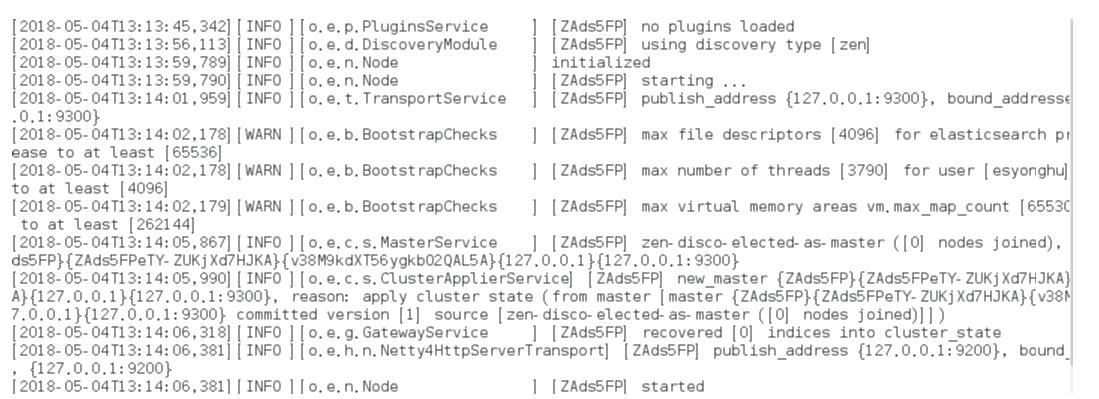
处理第一个错误:
vim /etc/security/limits.conf //文件最后加入
esuser soft nofile 65536
esuser hard nofile 65536
esuser soft nproc 4096
esuser hard nproc 4096
处理第二个错误:
进入limits.d目录下修改配置文件。
vim /etc/security/limits.d/20-nproc.conf
修改为 esuser soft nproc 4096
注意重新登录生效!!!!!!!!
处理第三个错误:
vim /etc/sysctl.conf
vm.max_map_count=655360
执行以下命令生效:
sysctl -p
关闭防火墙:systemctl stop firewalld.service
启动又又又报错
system call filters failed to install; check the logs and fix your configuration or disable sys

直接在
config/elasticsearch.yml 末尾加上一句
bootstrap.system_call_filter: false再次启动成功!
安装Head插件
Head是elasticsearch的集群管理工具,可以用于数据的浏览和查询
(1)elasticsearch-head是一款开源软件,被托管在github上面,所以如果我们要使用它,必须先安装git,通过git获取elasticsearch-head
(2)运行elasticsearch-head会用到grunt,而grunt需要npm包管理器,所以nodejs是必须要安装的
nodejs和npm安装:
http://blog.java1234.com/blog/articles/354.html
git安装
yum install -y git
(3)elasticsearch5.0之后,elasticsearch-head不做为插件放在其plugins目录下了。
使用git拷贝elasticsearch-head到本地
cd ~
git clone git://github.com/mobz/elasticsearch-head.git
(4)安装elasticsearch-head依赖包
[root@localhost local]# npm install -g grunt-cli
[root@localhost _site]# cd /usr/local/elasticsearch-head/
[root@localhost elasticsearch-head]# cnpm install
(5)修改Gruntfile.js
[root@localhost _site]# cd /usr/local/elasticsearch-head/
[root@localhost elasticsearch-head]# vi Gruntfile.js
在connect-->server-->options下面添加:hostname:’*’,允许所有IP可以访问
(6)修改elasticsearch-head默认连接地址
[root@localhost elasticsearch-head]# cd /usr/local/elasticsearch-head/_site/
[root@localhost _site]# vi app.js
将this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200";中的localhost修改成你es的服务器地址
(7)配置elasticsearch允许跨域访问
打开elasticsearch的配置文件elasticsearch.yml,在文件末尾追加下面两行代码即可:
http.cors.enabled: true
http.cors.allow-origin: "*"
(8)打开9100端口
[root@localhost elasticsearch-head]# firewall-cmd --zone=public --add-port=9100/tcp --permanent
重启防火墙
[root@localhost elasticsearch-head]# firewall-cmd --reload
(9)启动elasticsearch
(10)启动elasticsearch-head
[root@localhost _site]# cd ~/elasticsearch-head/
[root@localhost elasticsearch-head]# node_modules/grunt/bin/grunt server 或者 npm run start
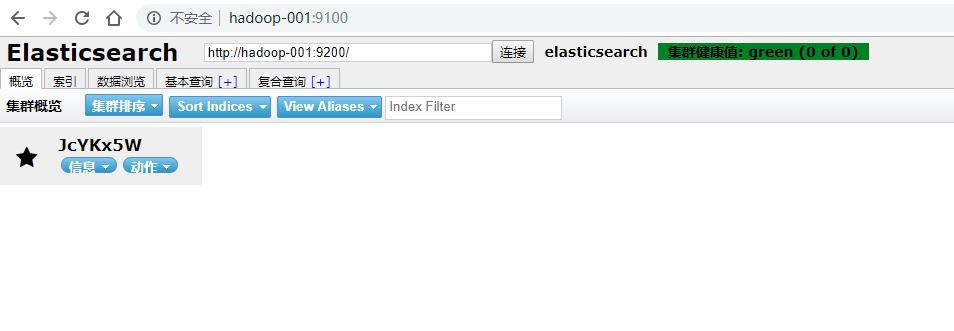
(11)访问elasticsearch-head
关闭防火墙:systemctl stop firewalld.service
浏览器输入网址:hadoop-001:9100/
安装Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,使用Kibana可以查询、查看并与存储在ES索引的数据进行交互操作,使用Kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据
(1)下载Kibana
https://www.elastic.co/downloads/kibana
(2)把下载好的压缩包拷贝到/soft目录下
(3)解压缩,并把解压后的目录移动到/user/local/kibana
(4)编辑kibana配置文件
[root@localhost /]# vi /usr/local/kibana/config/kibana.yml
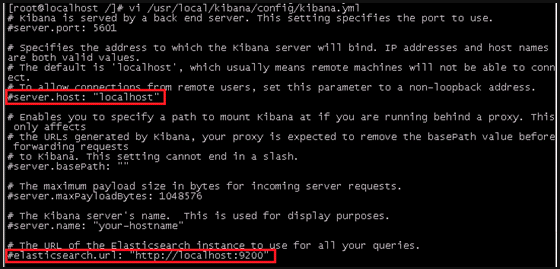
将server.host,elasticsearch.url修改成所在服务器的ip地址
server.port: 5601 //监听端口
server.host: "hadoo-001" //监听IP地址,建议内网ip
elasticsearch.url: "http:/hadoo-001" //elasticsearch连接kibana的URL,也可以填写192.168.137.188,因为它们是一个集群
(5)开启5601端口
Kibana的默认端口是5601
开启防火墙:systemctl start firewalld.service
开启5601端口:firewall-cmd --permanent --zone=public --add-port=5601/tcp
重启防火墙:firewall-cmd –reload
(6)启动Kibana
[root@localhost /]# /usr/local/kibana/bin/kibana
浏览器访问:http://192.168.137.188:5601
安装中文分词器
一.离线安装
(1)下载中文分词器
https://github.com/medcl/elasticsearch-analysis-ik
下载elasticsearch-analysis-ik-master.zip
(2)解压elasticsearch-analysis-ik-master.zip
unzip elasticsearch-analysis-ik-master.zip
(3)进入elasticsearch-analysis-ik-master,编译源码
mvn clean install -Dmaven.test.skip=true
(4)在es的plugins文件夹下创建目录ik
(5)将编译后生成的elasticsearch-analysis-ik-版本.zip移动到ik下,并解压
(6)解压后的内容移动到ik目录下
二.在线安装
./elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.2.4/elasticsearch-analysis-ik-6.2.4.zip
")
Elasticsearch 参考指南(重要的Elasticsearch配置)
重要的Elasticsearch配置
虽然Elasticsearch只需要很少的配置,但是在投入生产之前需要考虑许多设置。
path.data和path.logs
如果你使用.zip或.tar.gz归档,数据和日志目录都是$ES_HOME的子文件夹,如果这些重要的文件夹被保留在它们的默认位置,那么在升级到新版本时,它们很有可能被删除。
在生产使用中,你几乎肯定希望更改数据和日志文件夹的位置:
path:
logs: /var/log/elasticsearch
data: /var/data/elasticsearchRPM和Debian发行版已经为数据和日志使用了自定义路径。
path.data设置可以设置为多个路径,在这种情况下,所有路径都将用于存储数据(尽管属于单个碎片的文件都将存储在相同的数据路径上):
path:
data:
- /mnt/elasticsearch_1
- /mnt/elasticsearch_2
- /mnt/elasticsearch_3cluster.name
节点只有在与集群中的所有其他节点共享其cluster.name时才能加入集群,默认的名称是elasticsearch,但是应该将其更改为描述集群用途的适当名称。
cluster.name: logging-prod确保不要在不同的环境中重用相同的集群名称,否则可能会导致节点加入错误的集群。
node.name
默认情况下,Elasticsearch将使用随机生成的UUID的前7个字符作为节点id。注意,节点id是持久的并且在节点重新启动时不会更改,因此默认节点名也不会更改。
值得配置一个更有意义的名称,这个名称在重新启动节点之后也具有持久化的优势:
node.name: prod-data-2节点名也可以设置为服务器的主机名如下:
node.name: ${HOSTNAME}network.host
在默认情况下,Elasticsearch只绑定回环地址 — 例如,127.0.0.1和[::1],这足以在服务器上运行单个开发节点。
实际上,可以从单个节点上相同的$ES_HOME位置启动多个节点,这对于测试Elasticsearch形成集群的能力是很有用的,但是这并不是推荐用于生产的配置。
为了与其他服务器上的节点进行通信并形成集群,你的节点将需要绑定到非回环地址,虽然有许多网络设置,但通常你需要配置的只是network.host:
network.host: 192.168.1.10network.host设置还可以理解一些特殊值,如_local_、_site_、_global_和像:ip4和:ip6的修饰符,详细信息可以在network.host的特殊值中找到。
很快你就可以为network.host提供一个自定义设置,Elasticsearch假定你正在从开发模式转换到生产模式,并将许多系统启动检查从警告升级到异常,有关更多信息,请参见开发模式与生产模式。
发现设置
Elasticsearch使用一种名为“Zen discovery”的自定义发现实现,用于节点到节点的集群和主选择,在开始生产之前应该配置两个重要的发现设置。
discovery.zen.ping.unicast.hosts
在没有任何网络配置的情况下,Elasticsearch将绑定到可用的回环地址,并扫描端口9300到9305,以尝试连接到同一服务器上运行的其他节点,这提供了自动集群体验,而无需进行任何配置。
当节点在其他服务器上形成集群时,你必须提供集群中可能存在的其他节点的种子列表,可以指定如下:
discovery.zen.ping.unicast.hosts:
- 192.168.1.10:9300
- 192.168.1.11
- seeds.mydomain.com- 如果没有指定端口号,端口将默认为
transport.profiles.default.port,并且回退到transport.tcp.port - 解析到多个IP地址的主机名将尝试所有已解析的地址
discovery.zen.minimum_master_nodes
为了防止数据丢失,配置discovery.zen.minimum_master_nodes非常重要,使每个适合的主节点都知道要形成集群必须可见的适合的主节点的最小数目。
如果没有这种设置,遭受网络故障的集群有可能被分割成两个独立的集群 - 脑分裂 - 这将导致数据丢失,使用minimum_master_nodes避免脑分裂提供了一个更详细的解释。
为了避免脑分裂,这个设置应该设置为适合的主节点的法定数量:
(master_eligible_nodes / 2) + 1换句话说,如果有三个适合的主节点,那么最小主节点应该设置为(3 / 2) + 1或2:
discovery.zen.minimum_master_nodes: 2堆大小设置
在默认情况下,Elasticsearch告诉JVM使用最小和最大大小为1GB的堆,在迁移到生产时,重要的是配置堆大小以确保Elasticsearch有足够的可用堆。
Elasticsearch将在jvm.options中通过Xms(最小堆大小)和Xmx(最大堆大小)的设置分配指定的整个堆。
这些设置的值取决于服务器上可用RAM的总数,好的经验法则是:
- 设置最小堆大小(
Xms)和最大堆大小(Xmx)彼此相等。 - 对Elasticsearch可用的堆越多,它用于缓存的内存就越多。但是请注意,过多的堆可能会使你陷入长时间的垃圾收集停顿。
- 将
Xmx设置为不超过物理RAM的50%,以确保有足够的物理RAM留给内核文件系统缓存。 -
不要将
Xmx设置在JVM用于压缩对象指针的截点之上(被压缩的oops)。确切的截点不同,但接近32GB,你可以通过在日志中查找如下所示的行来验证你是否处于限制之下:heap size [1.9gb], compressed ordinary object pointers [true] -
更好的方法是,尽量低于零基础被压缩的oops阈值。确切的截点不同,但在大多数系统中26GB是安全的,但在某些系统中可能高达30GB。你可以通过使用JVM选项
-XX:+UnlockDiagnosticVMOptions -XX:+PrintCompressedOopsMode启动Elasticsearch,并查找如下所示的行来验证你是否处于限制之下:heap address: 0x000000011be00000, size: 27648 MB, zero based Compressed Oops显示零基础被压缩的oops被启用,而不是:
heap address: 0x0000000118400000, size: 28672 MB, Compressed Oops with base: 0x00000001183ff000
下面是如何通过jvm.options设置堆大小的示例:
-Xms2g
-Xmx2g - 设置最小堆大小为2g
- 设置最大堆大小为2g
还可以通过环境变量设置堆大小,这可以通过注释jvm.options文件中的Xms和Xmx设置来实现,并通过ES_JAVA_OPTS设置这些值:
ES_JAVA_OPTS="-Xms2g -Xmx2g" ./bin/elasticsearch
ES_JAVA_OPTS="-Xms4000m -Xmx4000m" ./bin/elasticsearch- 设置最小和最大堆大小为2GB
- 设置最小和最大堆大小为4000MB
为Windows服务配置堆与上面的不同,最初为Windows服务填充的值可以如上所述进行配置,但在被安装为服务之后会有所不同,有关更多细节,请参阅Windows服务文档。
JVM堆转储文件路径
默认情况,Elasticsearch配置JVM将内存溢出异常堆转储到默认数据目录(RPM和Debian包发行版的/var/lib/elasticsearch目录,和Elasticsearch的tar和zip存档发行版的安装根目录下的的data目录)。如果此路径不适合接收堆转储,你应该在jvm.options中修改条目-XX:HeapDumpPath=...。如果你指定了一个目录,JVM将根据运行实例的PID为堆转储生成一个文件名。如果你指定了一个固定的文件名而不是目录,那么当JVM需要在内存溢出的异常上执行堆转储时,该文件必须不存在,否则堆转储将失败。
GC日志记录
默认情况下,Elasticsearch支持GC日志,它们在jvm.options中配置,并默认为与Elasticsearch日志相同的默认位置。默认配置每64MB滚动日志一次,最多可以占用2g的磁盘空间。
临时目录
默认情况下,Elasticsearch使用一个私有的临时目录,启动脚本直接在系统临时目录下创建它。
在一些Linux发行版中,如果文件和目录最近没有被访问过,系统实用程序将从/tmp中清除它们。如果需要临时目录的特性长时间没有使用,这可能导致在Elasticsearch运行时删除私有临时目录,如果随后使用了需要临时目录的特性,则会导致问题。
如果你使用.deb或.rpm包安装Elasticsearch,并在systemd下运行,那么Elasticsearch使用的私有临时目录将被排除在定期清理之外。
但是,如果你打算在Linux上运行.tar.gz发行版一段较长的时间,那么你应该考虑为Elasticsearch创建一个专用的临时目录,它不在清除旧文件和目录的路径下。这个目录应该有权限设置,以便只有Elasticsearch运行的用户才能访问它,然后在启动Elasticsearch之前设置$ES_TMPDIR环境变量指向它。
JVM致命错误日志
默认情况下,Elasticsearch配置JVM将致命错误日志写入默认日志目录(这里是RPM和Debian软件包发行版的/var/log/elasticsearch,以及tar和zip归档发行版的Elasticsearch安装根目录下的logs目录)。这些是JVM在遇到致命错误(例如,分段故障)时生成的日志。如果此路径不适合接收日志,你应该修改在jvm.options中-XX:ErrorFile=…条目到另一个路径。
上一篇:配置Elasticsearch
下一篇:重要的系统配置
")
ElasticSearch 工具类封装(基于ElasticsearchTemplate)
1.抽象接口定义
1 public abstract class SearchQueryEngine<T> {
2
3 @Autowired
4 protected ElasticsearchTemplate elasticsearchTemplate;
5
6 public abstract int saveOrUpdate(List<T> list);
7
8 public abstract <R> List<R> aggregation(T query, Class<R> clazz);
9
10 public abstract <R> Page<R> scroll(T query, Class<R> clazz, Pageable pageable, ScrollId scrollId);
11
12 public abstract <R> List<R> find(T query, Class<R> clazz, int size);
13
14 public abstract <R> Page<R> find(T query, Class<R> clazz, Pageable pageable);
15
16 public abstract <R> R sum(T query, Class<R> clazz);
17
18 protected Document getDocument(T t) {
19 Document annotation = t.getClass().getAnnotation(Document.class);
20 if (annotation == null) {
21 throw new SearchQueryBuildException("Can''t find annotation @Document on " + t.getClass().getName());
22 }
23 return annotation;
24 }
25
26 /**
27 * 获取字段名,若设置column则返回该值
28 *
29 * @param field
30 * @param column
31 * @return
32 */
33 protected String getFieldName(Field field, String column) {
34 return StringUtils.isNotBlank(column) ? column : field.getName();
35 }
36
37 /**
38 * 设置属性值
39 *
40 * @param field
41 * @param obj
42 * @param value
43 */
44 protected void setFieldValue(Field field, Object obj, Object value) {
45 boolean isAccessible = field.isAccessible();
46 field.setAccessible(true);
47 try {
48 switch (field.getType().getSimpleName()) {
49 case "BigDecimal":
50 field.set(obj, new BigDecimal(value.toString()).setScale(5, BigDecimal.ROUND_HALF_UP));
51 break;
52 case "Long":
53 field.set(obj, new Long(value.toString()));
54 break;
55 case "Integer":
56 field.set(obj, new Integer(value.toString()));
57 break;
58 case "Date":
59 field.set(obj, new Date(Long.valueOf(value.toString())));
60 break;
61 default:
62 field.set(obj, value);
63 }
64 } catch (IllegalAccessException e) {
65 throw new SearchQueryBuildException(e);
66 } finally {
67 field.setAccessible(isAccessible);
68 }
69 }
70
71 /**
72 * 获取字段值
73 *
74 * @param field
75 * @param obj
76 * @return
77 */
78 protected Object getFieldValue(Field field, Object obj) {
79 boolean isAccessible = field.isAccessible();
80 field.setAccessible(true);
81 try {
82 return field.get(obj);
83 } catch (IllegalAccessException e) {
84 throw new SearchQueryBuildException(e);
85 } finally {
86 field.setAccessible(isAccessible);
87 }
88 }
89
90 /**
91 * 转换为es识别的value值
92 *
93 * @param value
94 * @return
95 */
96 protected Object formatValue(Object value) {
97 if (value instanceof Date) {
98 return ((Date) value).getTime();
99 } else {
100 return value;
101 }
102 }
103
104 /**
105 * 获取索引分区数
106 *
107 * @param t
108 * @return
109 */
110 protected int getNumberOfShards(T t) {
111 return Integer.parseInt(elasticsearchTemplate.getSetting(getDocument(t).index()).get(IndexMetaData.SETTING_NUMBER_OF_SHARDS).toString());
112 }
113 }
2.接口实现
1 @Component
2 @ComponentScan
3 public class SimpleSearchQueryEngine<T> extends SearchQueryEngine<T> {
4
5 private int numberOfRowsPerScan = 10;
6
7 @Override
8 public int saveOrUpdate(List<T> list) {
9 if (CollectionUtils.isEmpty(list)) {
10 return 0;
11 }
12
13 T base = list.get(0);
14 Field id = null;
15 for (Field field : base.getClass().getDeclaredFields()) {
16 BusinessID businessID = field.getAnnotation(BusinessID.class);
17 if (businessID != null) {
18 id = field;
19 break;
20 }
21 }
22 if (id == null) {
23 throw new SearchQueryBuildException("Can''t find @BusinessID on " + base.getClass().getName());
24 }
25
26 Document document = getDocument(base);
27 List<UpdateQuery> bulkIndex = new ArrayList<>();
28 for (T t : list) {
29 UpdateQuery updateQuery = new UpdateQuery();
30 updateQuery.setIndexName(document.index());
31 updateQuery.setType(document.type());
32 updateQuery.setId(getFieldValue(id, t).toString());
33 updateQuery.setUpdateRequest(new UpdateRequest(updateQuery.getIndexName(), updateQuery.getType(), updateQuery.getId()).doc(JSONObject.toJSONString(t, SerializerFeature.WriteMapNullValue)));
34 updateQuery.setDoUpsert(true);
35 updateQuery.setClazz(t.getClass());
36 bulkIndex.add(updateQuery);
37 }
38 elasticsearchTemplate.bulkUpdate(bulkIndex);
39 return list.size();
40 }
41
42 @Override
43 public <R> List<R> aggregation(T query, Class<R> clazz) {
44 NativeSearchQueryBuilder nativeSearchQueryBuilder = buildNativeSearchQueryBuilder(query);
45 nativeSearchQueryBuilder.addAggregation(buildGroupBy(query));
46 Aggregations aggregations = elasticsearchTemplate.query(nativeSearchQueryBuilder.build(), new AggregationResultsExtractor());
47 try {
48 return transformList(null, aggregations, clazz.newInstance(), new ArrayList());
49 } catch (Exception e) {
50 throw new SearchResultBuildException(e);
51 }
52 }
53
54 /**
55 * 将Aggregations转为List
56 *
57 * @param terms
58 * @param aggregations
59 * @param baseObj
60 * @param resultList
61 * @param <R>
62 * @return
63 * @throws NoSuchFieldException
64 * @throws IllegalAccessException
65 * @throws InstantiationException
66 */
67 private <R> List<R> transformList(Aggregation terms, Aggregations aggregations, R baseObj, List<R> resultList) throws NoSuchFieldException, IllegalAccessException, InstantiationException {
68 for (String column : aggregations.asMap().keySet()) {
69 Aggregation childAggregation = aggregations.get(column);
70 if (childAggregation instanceof InternalSum) {
71 // 使用@Sum
72 if (!(terms instanceof InternalSum)) {
73 R targetObj = (R) baseObj.getClass().newInstance();
74 BeanUtils.copyProperties(baseObj, targetObj);
75 resultList.add(targetObj);
76 }
77 setFieldValue(baseObj.getClass().getDeclaredField(column), resultList.get(resultList.size() - 1), ((InternalSum) childAggregation).getValue());
78 terms = childAggregation;
79 } else {
80 Terms childTerms = (Terms) childAggregation;
81 for (Terms.Bucket bucket : childTerms.getBuckets()) {
82 if (CollectionUtils.isEmpty(bucket.getAggregations().asList())) {
83 // 未使用@Sum
84 R targetObj = (R) baseObj.getClass().newInstance();
85 BeanUtils.copyProperties(baseObj, targetObj);
86 setFieldValue(targetObj.getClass().getDeclaredField(column), targetObj, bucket.getKey());
87 resultList.add(targetObj);
88 } else {
89 setFieldValue(baseObj.getClass().getDeclaredField(column), baseObj, bucket.getKey());
90 transformList(childTerms, bucket.getAggregations(), baseObj, resultList);
91 }
92 }
93 }
94 }
95 return resultList;
96 }
97
98 @Override
99 public <R> Page<R> scroll(T query, Class<R> clazz, Pageable pageable, ScrollId scrollId) {
100 if (pageable.getPageSize() % numberOfRowsPerScan > 0) {
101 throw new SearchQueryBuildException("Page size must be an integral multiple of " + numberOfRowsPerScan);
102 }
103 SearchQuery searchQuery = buildNativeSearchQueryBuilder(query).withPageable(new PageRequest(pageable.getPageNumber(), numberOfRowsPerScan / getNumberOfShards(query), pageable.getSort())).build();
104 if (StringUtils.isEmpty(scrollId.getValue())) {
105 scrollId.setValue(elasticsearchTemplate.scan(searchQuery, 10000l, false));
106 }
107 Page<R> page = elasticsearchTemplate.scroll(scrollId.getValue(), 10000l, clazz);
108 if (page == null || page.getContent().size() == 0) {
109 elasticsearchTemplate.clearScroll(scrollId.getValue());
110 }
111 return page;
112 }
113
114 @Override
115 public <R> List<R> find(T query, Class<R> clazz, int size) {
116 // Caused by: QueryPhaseExecutionException[Result window is too large, from + size must be less than or equal to: [10000] but was [2147483647].
117 // See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level parameter.]
118 if (size % numberOfRowsPerScan > 0) {
119 throw new SearchQueryBuildException("Parameter ''size'' must be an integral multiple of " + numberOfRowsPerScan);
120 }
121 int pageNum = 0;
122 List<R> result = new ArrayList<>();
123 ScrollId scrollId = new ScrollId();
124 while (true) {
125 Page<R> page = scroll(query, clazz, new PageRequest(pageNum, numberOfRowsPerScan), scrollId);
126 if (page != null && page.getContent().size() > 0) {
127 result.addAll(page.getContent());
128 } else {
129 break;
130 }
131 if (result.size() >= size) {
132 break;
133 } else {
134 pageNum++;
135 }
136 }
137 elasticsearchTemplate.clearScroll(scrollId.getValue());
138 return result;
139 }
140
141 @Override
142 public <R> Page<R> find(T query, Class<R> clazz, Pageable pageable) {
143 NativeSearchQueryBuilder nativeSearchQueryBuilder = buildNativeSearchQueryBuilder(query).withPageable(pageable);
144 return elasticsearchTemplate.queryForPage(nativeSearchQueryBuilder.build(), clazz);
145 }
146
147 @Override
148 public <R> R sum(T query, Class<R> clazz) {
149 NativeSearchQueryBuilder nativeSearchQueryBuilder = buildNativeSearchQueryBuilder(query);
150 for (SumBuilder sumBuilder : getSumBuilderList(query)) {
151 nativeSearchQueryBuilder.addAggregation(sumBuilder);
152 }
153 Aggregations aggregations = elasticsearchTemplate.query(nativeSearchQueryBuilder.build(), new AggregationResultsExtractor());
154 try {
155 return transformSumResult(aggregations, clazz);
156 } catch (Exception e) {
157 throw new SearchResultBuildException(e);
158 }
159 }
160
161 private <R> R transformSumResult(Aggregations aggregations, Class<R> clazz) throws IllegalAccessException, InstantiationException, NoSuchFieldException {
162 R targetObj = clazz.newInstance();
163 for (Aggregation sum : aggregations.asList()) {
164 if (sum instanceof InternalSum) {
165 setFieldValue(targetObj.getClass().getDeclaredField(sum.getName()), targetObj, ((InternalSum) sum).getValue());
166 }
167 }
168 return targetObj;
169 }
170
171 private NativeSearchQueryBuilder buildNativeSearchQueryBuilder(T query) {
172 Document document = getDocument(query);
173 NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder()
174 .withIndices(document.index())
175 .withTypes(document.type());
176
177 QueryBuilder whereBuilder = buildBoolQuery(query);
178 if (whereBuilder != null) {
179 nativeSearchQueryBuilder.withQuery(whereBuilder);
180 }
181
182 return nativeSearchQueryBuilder;
183 }
184
185 /**
186 * 布尔查询构建
187 *
188 * @param query
189 * @return
190 */
191 private BoolQueryBuilder buildBoolQuery(T query) {
192 BoolQueryBuilder boolQueryBuilder = boolQuery();
193 buildMatchQuery(boolQueryBuilder, query);
194 buildRangeQuery(boolQueryBuilder, query);
195 BoolQueryBuilder queryBuilder = boolQuery().must(boolQueryBuilder);
196 return queryBuilder;
197 }
198
199 /**
200 * and or 查询构建
201 *
202 * @param boolQueryBuilder
203 * @param query
204 */
205 private void buildMatchQuery(BoolQueryBuilder boolQueryBuilder, T query) {
206 Class clazz = query.getClass();
207 for (Field field : clazz.getDeclaredFields()) {
208 MatchQuery annotation = field.getAnnotation(MatchQuery.class);
209 Object value = getFieldValue(field, query);
210 if (annotation == null || value == null) {
211 continue;
212 }
213 if (Container.must.equals(annotation.container())) {
214 boolQueryBuilder.must(matchQuery(getFieldName(field, annotation.column()), formatValue(value)));
215 } else if (should.equals(annotation.container())) {
216 if (value instanceof Collection) {
217 BoolQueryBuilder shouldQueryBuilder = boolQuery();
218 Collection tmp = (Collection) value;
219 for (Object obj : tmp) {
220 shouldQueryBuilder.should(matchQuery(getFieldName(field, annotation.column()), formatValue(obj)));
221 }
222 boolQueryBuilder.must(shouldQueryBuilder);
223 } else {
224 boolQueryBuilder.must(boolQuery().should(matchQuery(getFieldName(field, annotation.column()), formatValue(value))));
225 }
226 }
227 }
228 }
229
230 /**
231 * 范围查询构建
232 *
233 * @param boolQueryBuilder
234 * @param query
235 */
236 private void buildRangeQuery(BoolQueryBuilder boolQueryBuilder, T query) {
237 Class clazz = query.getClass();
238 for (Field field : clazz.getDeclaredFields()) {
239 RangeQuery annotation = field.getAnnotation(RangeQuery.class);
240 Object value = getFieldValue(field, query);
241 if (annotation == null || value == null) {
242 continue;
243 }
244 if (Operator.gt.equals(annotation.operator())) {
245 boolQueryBuilder.must(rangeQuery(getFieldName(field, annotation.column())).gt(formatValue(value)));
246 } else if (Operator.gte.equals(annotation.operator())) {
247 boolQueryBuilder.must(rangeQuery(getFieldName(field, annotation.column())).gte(formatValue(value)));
248 } else if (Operator.lt.equals(annotation.operator())) {
249 boolQueryBuilder.must(rangeQuery(getFieldName(field, annotation.column())).lt(formatValue(value)));
250 } else if (Operator.lte.equals(annotation.operator())) {
251 boolQueryBuilder.must(rangeQuery(getFieldName(field, annotation.column())).lte(formatValue(value)));
252 }
253 }
254 }
255
256 /**
257 * Sum构建
258 *
259 * @param query
260 * @return
261 */
262 private List<SumBuilder> getSumBuilderList(T query) {
263 List<SumBuilder> list = new ArrayList<>();
264 Class clazz = query.getClass();
265 for (Field field : clazz.getDeclaredFields()) {
266 Sum annotation = field.getAnnotation(Sum.class);
267 if (annotation == null) {
268 continue;
269 }
270 list.add(AggregationBuilders.sum(field.getName()).field(field.getName()));
271 }
272 if (CollectionUtils.isEmpty(list)) {
273 throw new SearchQueryBuildException("Can''t find @Sum on " + clazz.getName());
274 }
275 return list;
276 }
277
278
279 /**
280 * GroupBy构建
281 *
282 * @param query
283 * @return
284 */
285 private TermsBuilder buildGroupBy(T query) {
286 List<Field> sumList = new ArrayList<>();
287 Object groupByCollection = null;
288 Class clazz = query.getClass();
289 for (Field field : clazz.getDeclaredFields()) {
290 Sum sumAnnotation = field.getAnnotation(Sum.class);
291 if (sumAnnotation != null) {
292 sumList.add(field);
293 }
294 GroupBy groupByannotation = field.getAnnotation(GroupBy.class);
295 Object value = getFieldValue(field, query);
296 if (groupByannotation == null || value == null) {
297 continue;
298 } else if (!(value instanceof Collection)) {
299 throw new SearchQueryBuildException("GroupBy filed must be collection");
300 } else if (CollectionUtils.isEmpty((Collection<String>) value)) {
301 continue;
302 } else if (groupByCollection != null) {
303 throw new SearchQueryBuildException("Only one @GroupBy is allowed");
304 } else {
305 groupByCollection = value;
306 }
307 }
308 Iterator<String> iterator = ((Collection<String>) groupByCollection).iterator();
309 TermsBuilder termsBuilder = recursiveAddAggregation(iterator, sumList);
310 return termsBuilder;
311 }
312
313 /**
314 * 添加Aggregation
315 *
316 * @param iterator
317 * @return
318 */
319 private TermsBuilder recursiveAddAggregation(Iterator<String> iterator, List<Field> sumList) {
320 String groupBy = iterator.next();
321 TermsBuilder termsBuilder = AggregationBuilders.terms(groupBy).field(groupBy).size(0);
322 if (iterator.hasNext()) {
323 termsBuilder.subAggregation(recursiveAddAggregation(iterator, sumList));
324 } else {
325 for (Field field : sumList) {
326 termsBuilder.subAggregation(AggregationBuilders.sum(field.getName()).field(field.getName()));
327 }
328 sumList.clear();
329 }
330 return termsBuilder.order(Terms.Order.term(true));
331 }3.存储scrollId值对象
import lombok.Data;
@Data
public class ScrollId {
private String value;
}4.用于判断查询操作的枚举类
public enum Operator {
gt, gte, lt, lte
}public enum Container {
must, should
}
关于更新生产中的ElasticSearch映射和 tyre的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于Elasticsearch 2.3.3 搜索引擎的elasticsearch-jdbc插件安装、Elasticsearch CentOS6.5下安装ElasticSearch6.2.4+elasticsearch-head+Kibana、Elasticsearch 参考指南(重要的Elasticsearch配置)、ElasticSearch 工具类封装(基于ElasticsearchTemplate)的相关信息,请在本站寻找。
本文标签:




