在本文中,我们将带你了解如何在ApacheKafka中删除主题在这篇文章中,我们将为您详细介绍如何在ApacheKafka中删除主题的方方面面,并解答kafka删除主题命令常见的疑惑,同时我们还将给您
在本文中,我们将带你了解如何在Apache Kafka中删除主题在这篇文章中,我们将为您详细介绍如何在Apache Kafka中删除主题的方方面面,并解答kafka删除主题命令常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的apache kafka & CDH kafka源码编译、Apache Kafka 1.1.0 发布,改进 Kafka controller、Apache Kafka KRaft - Kafka 存储工具、apache kafka-01-kafka 入门介绍。
本文目录一览:- 如何在Apache Kafka中删除主题(kafka删除主题命令)
- apache kafka & CDH kafka源码编译
- Apache Kafka 1.1.0 发布,改进 Kafka controller
- Apache Kafka KRaft - Kafka 存储工具
- apache kafka-01-kafka 入门介绍
")
如何在Apache Kafka中删除主题(kafka删除主题命令)
我需要在kafka-0.8.2.2.3中删除一个主题。我已使用以下命令删除该主题:
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic DummyTopic该命令已成功执行,但是当我运行命令以列出主题时,我可以看到该主题仍然存在,并且显示 标记为“删除” 。
bin/kafka-topics.sh --list --zookeeper localhost:2181DummyTopic - marked for deletion当我创建主题DummyTopic时,它会输出异常,该主题已存在,下面是堆栈跟踪:
Error while executing topic command Topic "DummyTopic" already exists.kafka.common.TopicExistsException: Topic "DummyTopic" already exists. at kafka.admin.AdminUtils$.createOrUpdateTopicPartitionAssignmentPathInZK(AdminUtils.scala:248) at kafka.admin.AdminUtils$.createTopic(AdminUtils.scala:233) at kafka.admin.TopicCommand$.createTopic(TopicCommand.scala:92) at kafka.admin.TopicCommand$.main(TopicCommand.scala:54) at kafka.admin.TopicCommand.main(TopicCommand.scala)请让我知道如何删除该主题。
答案1
小编典典从0.8.2.x版本开始支持删除主题。您必须delete.topic.enable首先在所有代理上启用主题删除(设置为true)。
注意:从1.0.x开始,delete.topic.enable默认情况下功能是稳定的true。
请按照以下逐步过程手动删除主题
- 停止 Kafka 服务器
- 删除主题目录,每个 代理 (如在定义
logs.dirs和log.dir属性)与rm -rf命令 - 连接到 Zookeeper 实例:
zookeeper-shell.sh host:port - 在 Zookeeper 实例中:
- 使用以下方式列出主题:
ls /brokers/topics - 使用以下方法从 ZooKeeper中 删除主题文件夹:
rmr /brokers/topics/yourtopic - 退出Zookeeper实例(Ctrl + C)
- 使用以下方式列出主题:
- 重新启动 Kafka 服务器
- 使用此命令确认是否已删除
kafka-topics.sh --list --zookeeper host:port

apache kafka & CDH kafka源码编译
Apache kafka编译
前言
github网站kafka项目的README.md有关于kafka源码编译的说明
github地址:https://github.com/apache/kafka
编译环境准备 java maven gradle
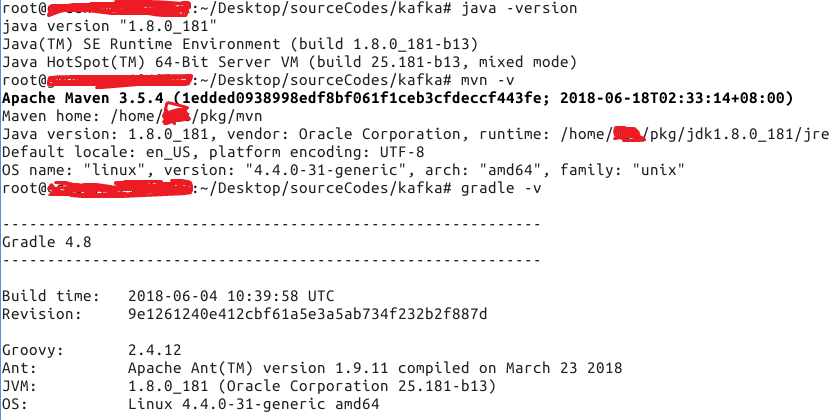
编译
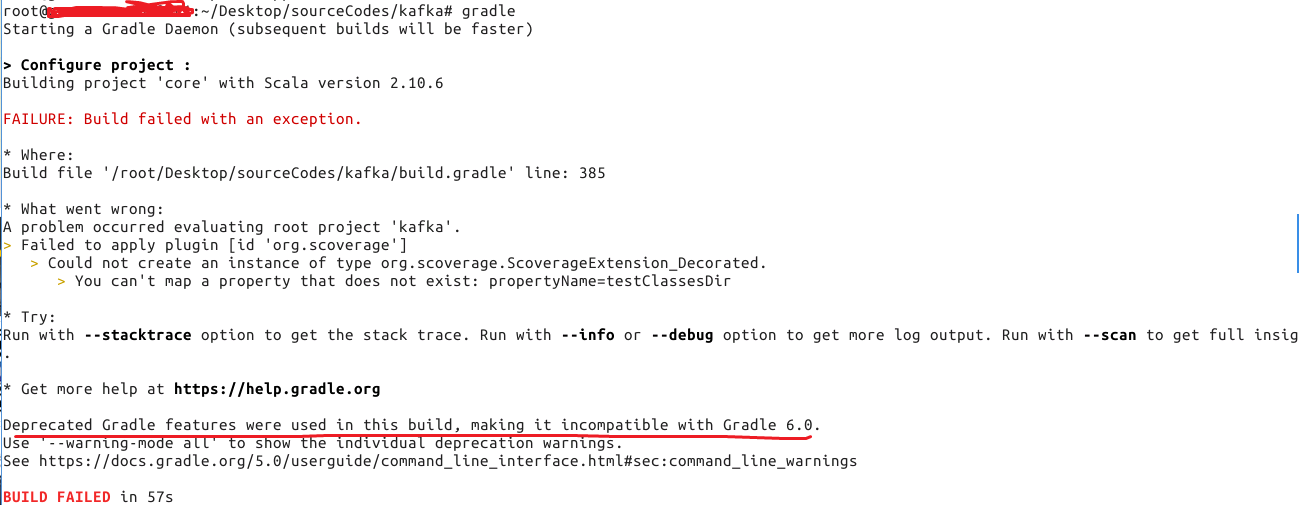
失败原因:gradle版本太高,降低到4.8就ok了
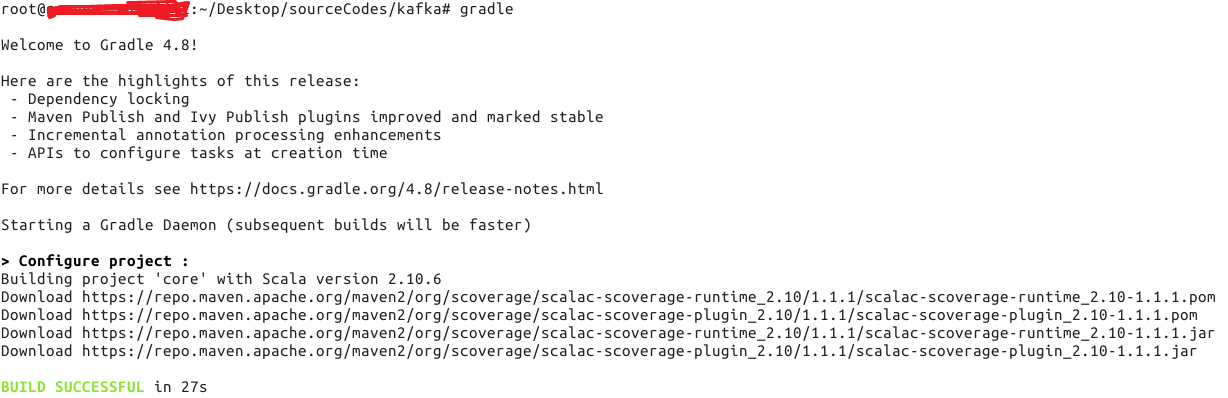
编译(执行如下命令)
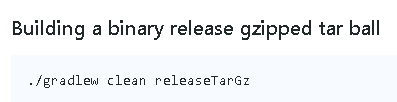
会在kafka/core/build/distributions目录下生成需要的tar包

CDH kafka编译
源码还是从github获取
git clone https://github.com/cloudera/kafka.git注意:修改gradle.properties中的mavenUrl,因为maven.jenkins.cloudera.com是私有的,需要改成公有的
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
group=org.apache.kafka
# NOTE: When you change this version number, you should also make sure to update
# the version numbers in tests/kafkatest/__init__.py and kafka-merge-pr.py.
cdhversion=6.1.0
version=2.0.0-cdh6.1.0
scalaVersion=2.11.12
task=build
org.gradle.jvmargs=-Xmx1024m -Xss2m
mavenUrl=https://repository.cloudera.com/artifactory/cloudera-repos
#http://maven.jenkins.cloudera.com:8081/artifactory/cdh-snapshot-local
mavenSnapshotUrl=http://maven.jenkins.cloudera.com:8081/artifactory/cdh-snapshot-local
mavenArtifactoryUrl=http://maven.jenkins.cloudera.com:8081/artifactory/cloudera-mirrors
mavenUsername=
mavenPassword=
之后的编译过程参考apache kafka编译打包命令!
结果:


Apache Kafka 1.1.0 发布,改进 Kafka controller
Apache Kafka 1.1.0 已发布,带来了大量改进和修复。主要亮点包括:
Kafka 1.1.0 includes significant improvements to the Kafka Controller that speed up controlled shutdown. ZooKeeper session expiration edge cases have also been fixed as part of this effort.
Controller improvements also enable more partitions to be supported on a single cluster. KIP-227 introduced incremental fetch requests, providing more efficient replication when the number of partitions is large.
KIP-113 added support for replica movement between log directories to enable data balancing with JBOD.
Some of the broker configuration options like SSL keystores can now be updated dynamically without restarting the broker. See KIP-226 for details and the full list of dynamic configs.
Delegation token based authentication (KIP-48) has been added to Kafka brokers to support large number of clients without overloading Kerberos KDCs or other authentication servers.
Several new features have been added to Kafka Connect, including header support (KIP-145), SSL and Kafka cluster identifiers in the Connect REST interface (KIP-208 and KIP-238), validation of connector names (KIP-212) and support for topic regex in sink connectors (KIP-215). Additionally, the default maximum heap size for Connect workers was increased to 2GB.
Several improvements have been added to the Kafka Streams API, including reducing repartition topic partitions footprint, customizable error handling for produce failures and enhanced resilience to broker unavailability. See KIPs 205, 210, 220, 224 and 239 for details.
完整更新内容请查阅:
Release Notes
下载地址:
kafka-1.1.0-src.tgz
kafka_2.11-1.1.0.tgz
kafka_2.12-1.1.0.tgz

Apache Kafka KRaft - Kafka 存储工具
如何解决Apache Kafka KRaft - Kafka 存储工具?
在 documentation 中提到:
如上文快速入门部分所述,您必须使用 kafka-storage.sh 工具为您的新集群生成集群 ID,然后在启动节点之前在每个节点上运行 format 命令。
生成集群 ID
./bin/kafka-storage.sh random-uuid
xtzWWN4bTjitpL3kfd9s5g
格式化存储目录
./bin/kafka-storage.sh format -t <uuid> -c ./config/kraft/server.properties
Formatting /tmp/kraft-combined-logs
用不同的程序而不是用 <uuid> 生成 kafka-storage.sh 会不会有问题?
解决方法
它需要是一个与 Kafka 内部 UUID 不匹配的 type-4 UUID
来自 Kafka 源代码
/**
* Static factory to retrieve a type 4 (pseudo randomly generated) UUID.
*/
public static Uuid randomUuid() {
java.util.UUID uuid = java.util.UUID.randomUUID();
while (uuid.equals(METADATA_TOPIC_ID_INTERNAL) || uuid.equals(ZERO_ID_INTERNAL)) {
uuid = java.util.UUID.randomUUID();
}
return new Uuid(uuid.getMostSignificantBits(),uuid.getLeastSignificantBits());
}

apache kafka-01-kafka 入门介绍
kafka 名字背后的故事
说到卡夫卡,不知道你脑海中第一个想到的是什么?
是《变形记》的作者弗兰兹·卡夫卡(Franz Kafka)?还是村上春树的《海边的卡夫卡》?
不知道为何,我脑海中浮现的第一个竟然是契诃夫的《装在套子里的人》。后来去查了一下,主角是别里科夫,大概是自己的记忆产生了混乱。
在开始正式的介绍之前,我们先来学习一下,卡夫卡这个词是什么意思。
卡夫卡在捷克语中是【寒鸦】的意思,而卡夫卡在希伯来语中是【穴鸟】的意思。
那么我们今天的主角 apache kafka 和 我们提到的 kafka 是否有联系呢?
查了一下,还真是有联系的。
根据作者(Jay Kreps)原话,因为 apache kafka 是一个用来优化读写的系统,所以用一个作家的名字来命名并不奇怪。而且作者在大学时非常喜欢 Franz Kafka。对于开源项目来说,这个名字很酷。(这个才是重点,酷就完事了!)
这个故事告诉我们,大佬就是大佬,读文学一点也不影响自己敲代码。
发布与订阅消息系统
在正式讨论 Apache Kafka(以下简称Kafka)之前,先来了解发布与订阅消息系统的概念,并认识这个系统的重要性。
数据(消息)的发送者(发布者)不会直接把消息发送给接收者,这是发布与订阅消息系统的一个特点。
发布者以某种方式对消息进行分类,接收者(订阅者)订阅它们,以便接收特定类型的消息。
发布与订阅系统一般会有一个broker,也就是发布消息的中心点。
为什么需要发布-订阅系统
发布与订阅消息系统的大部分应用场景都是从一个简单的消息队列或一个进程间通道开始的。
例如,你的应用程序需要往别处发送监控信息,可以直接在你的应用程序和另一个可以在仪表盘上显示度量指标的应用程序之间建立连接,然后通过这个连接推送度量指标,如图1-1所示。
- 图1-1:单个直连的度量指标发布者
这是刚接触监控系统时简单问题的应对方案。
过了不久,你需要分析更长时间片段的度量指标,而此时的仪表盘程序满足不了需求,于是,你启动了一个新的服务来接收度量指标。
该服务把度量指标保存起来,然后进行分析。
与此同时,你修改了原来的应用程序把度量指标同时发送到两个仪表盘系统上。现在,你又多了3个可以生成度量指标的应用程序,它们都与这两个服务直接相连。而你的同事认为最好可以对这些服务进行轮询以便获得告警功能,于是你为每一个应用程序增加了一个服务器,用于提供度量指标。再过一阵子,有更多的应用程序出于各自的目的,都从这些服务器获取度量指标。
这时的架构看起来就像图1-2所示的那样,节点间的连接一团糟。
- 图1-2:多个直连的度量指标发布者
这时,技术债务开始凸显出来,于是你决定偿还掉一些。
你创建了一个独立的应用程序,用于接收来自其他应用程序的度量指标,并为其他系统提供了一个查询服务器。
这样,之前架构的复杂度被降低到图1-3所示的那样。
那么恭喜你,你已经创建了一个基于发布与订阅的消息系统。
独立的队列系统
在你跟度量指标打得不可开交的时候,你的一个同事也正在跟日志消息奋战。
还有另一个同事正在跟踪网站用户的行为,为负责机器学习开发的同事提供信息,同时为管理团队生成报告。你和同事们使用相同的方式创建这些系统,解耦信息的发布者和订阅者。
图1-4所示的架构包含了3个独立的发布与订阅系统。
- 图1-4:多个发布与订阅系统
这种方式比直接使用点对点的连接(图1-2)要好得多,但这里有太多重复的地方。
你的公司因此要为数据队列维护多个系统,每个系统又有各自的缺陷和不足。
而且,接下来可能会有更多的场景需要用到消息系统。
此时,你真正需要的是一个单一的集中式系统,它可以用来发布通用类型的数据,其规模可以随着公司业务的增长而增长。
ps: 实际上我们工作中就是这样,甚至一个系统就是用了:kafka/activemq/rocketmq,还有自定义开发的,完全不考虑新人的学习成本和后期的维护成本。
这里,我们的主角,kafka 就闪亮登场了!
为什么选择 kafka?
成熟的 mq 框架
那么问题来了,我们的发布-订阅系统选择还是很多的,比如:
- activemq
骨灰级 mq 玩家,用过都说好。
https://houbb.github.io/2017/06/07/activemq
- rocketsmq
阿里开源 mq,产品经过多年双 11 打磨。
https://houbb.github.io/2016/10/25/rocketmq
- rabbitmq
基于 AMQP 协议的 mq 实现,JMS?我远在你之上,我的目标是统一 mq 界。
https://houbb.github.io/2018/09/17/rabbitmq-in-action-01-hello
- Confluo
性能是 kafka 的 4-10 倍
https://houbb.github.io/2018/12/18/confluo
- Pulsar
流批一体,自己才是未来,才是方向。
https://houbb.github.io/2018/11/12/apache-pulsar
其他的还有 zero-mq、QMQ、openmq、zbus 等等,不再一一赘述。
那么问题,来了,为什么要选择 kafka?
这个问题,面试官会问你,你在项目中引入新技术,项目主管和其他同事也会问你,甚至你也会问你自己。
个人理解
我们一般决定引入一个中间件,下面几个问题是主要考虑的:
(1)哪个公司开源的?
大公司一般有较为雄厚的技术的沉淀,而且经过了一定的生产验证。质量值得信赖。
(2)是否活跃?
也就是生命力怎么样。一般一个欣欣向荣的项目,受欢迎程度会超过一个常年不更新的老项目。
出问题了能否在社区得到有效解决等。
生态如果完善,对于未来系统升级的支撑也会比较好。
(3)迁移成本
公司的历史数据迁移的成本,以后的发展考虑等等。
(4)学习成本
文档是否齐全?是否是比较常用的技术?
新来的开发者能否很快上手,学习成本这些都是需要考量的。
(5)使用成本
硬件成本是否过高?维护成本是否过高?
kafka 一个很大的优点就是使用磁盘,同时性能也不错。
后续我们将单开一篇,详细讲解 kafka 的性能为何这么好。
应用场景
公司一般都是用来做日志收集,还有一些数据传输,数据分析等等。
活动跟踪
Kafka最初的使用场景是跟踪用户的活动。网站用户与前端应用程序发生交互,前端应用程序生成用户活动相关的消息。这些消息可以是一些静态的信息,比如页面访问次数和点击量,也可以是一些复杂的操作,比如添加用户资料。这些消息被发布到一个或多个主题上,由后端应用程序负责读取。这样,我们就可以生成报告,为机器学习系统提供数据,更新搜索结果,或者实现其他更多的功能。
传递消息
Kafka的另一个基本用途是传递消息。应用程序向用户发送通知(比如邮件)就是通过传递消息来实现的。这些应用程序组件可以生成消息,而不需要关心消息的格式,也不需要关心消息是如何被发送的。一个公共应用程序会读取这些消息,对它们进行处理:格式化消息(也就是所谓的装饰);
将多个消息放在同一个通知里发送:
根据用户配置的首选项来发送数据。
使用公共组件的好处在于,不需要在多个应用程序上开发重复的功能,而且可以在公共组件上做一些有趣的转换,比如把多个消息聚合成一个单独的通知,而这些工作是无法在其他地方完成的。
度量指标和日志记录
Kafka也可以用于收集应用程序和系统度量指标以及日志。Kafka支持多个生产者的特性在这个时候就可以派上用场。应用程序定期把度量指标发布到Kafka主题上,监控系统或告警系统读取这些消息。Kafka也可以用在像Hadoop这样的离线系统上,进行较长时间片段 的数据分析,比如年度增长走势预测。日志消息也可以被发布到Kafka主题上,然后被路由到专门的日志搜索系统(比如Elasticsearch)或安全分析应用程序。更改目标系统(比如日志存储系统)不会影响到前端应用或聚合方法,这是Kafka的另一个优点。
提交日志
Kafka的基本概念来源于提交日志,所以使用Kafka作为提交日志是件顺理成章的事。我们可以把数据库的更新发布到Kafka上,应用程序通过监控事件流来接收数据库的实时更新。这种变更日志流也可以用于把数据库的更新复制到远程系统上,或者合并多个应用程序的更新到一个单独的数据库视图上。数据持久化为变更日志提供了缓冲区,也就是说,如果消费者应用程序发生故障,可以通过重放这些日志来恢复系统状态。另外,紧凑型日志主题只为每个键保留一个变更数据,所以可以长时间使用,不需要担心消息过期问题。
流处理
流处理是又一个能提供多种类型应用程序的领域。可以说,它们提供的功能与Hadoop里的map和reduce有点类似,只不过它们操作的是实时数据流,而Hadoop则处理更长时间片段的数据,可能是几个小时或者几天,Hadoop会对这些数据进行批处理。通过使用流式处理框架,用户可以编写小型应用程序来操作Kafka消息,比如计算度量指标,为其他应用程序有效地处理消息分区,或者对来自多个数据源的消息进行转换。第11章将通过其他案例介绍流处理。
Kafka 基本概念
Kafka就是为了解决上述问题而设计的一款基于发布与订阅的消息系统。它一般被称为“分布式提交日志”或者“分布式流平台”。
文件系统或数据库提交日志用来提供所有事务的持久记录,通过重放这些日志可以重建系统的状态。同样地,Kafka的数据是按照一定顺序持久化保存的,可以按需读取,此外,Kafka的数据分布在整个系统里,具备数据故障保护和性能伸缩能力。
消息和批次
Kafka的数据单元被称为消息。如果你在使用Kafka之前已经有数据库使用经验,那么可以把消息看成是数据库里的一个“数据行”或一条“记录”。消息由字节数组组成,所以对于Kafka来说,消息里的数据没有特别的格式或含义,消息可以有一个可选的元数据,也就是键,键也是一个字节数组,与消息一样,对于Kafka来说也没有特殊的含义。当消息以一种可控的方式写人不同的分区时,会用到创。最简单的例子就是为键生成一个一致性散列值,然后使用散列值对主题分区数进行取模,为消息选取分区。这样可以保证具有相同键的消息总是被写到相同的分区上。第3章将详细介绍键的用法。
为了提高效率,消息被分批次写人Kafka。批次就是一组消息,这些消息属于同一个主题和分区。如果每一个消息都单独穿行于网络,会导致大量的网络开销,把消息分成批次传输可以减少网络开销。不过,这要在时间延迟和吞吐量之间作出权衡;批次越大,单位时间内处理的消息就越多,单个消息的传输时间就越长。批次数据会被压缩,这样可以提升数据的传输和存储能力,但要做更多的计算处理。
模式
对于Kafka来说,消息不过是晦涩难懂的字节数组,所以有人建议用一些额外的结构来定义消息内容,让它们更易于理解。根据应用程序的需求,消息模式(schema)有许多可用的选项。像JSON和XML这些简单的系统,不仅易用,而且可读性好。不过,它们缺乏强类型处理能力,不同版本之间的兼容性也不是很好。Kafka的许多开发者喜欢使用ApacheAvro,它最初是为Hadoop开发的一款序列化框架,Avro提供了一种紧凑的序列化格式,模式和消息体是分开的,当模式发生变化时,不需要重新生成代码:它还支持强类型和模式进化,其版本既向前兼容,也向后兼容。
数据格式的一致性对于Kafka来说很重要,它消除了消息读写操作之间的耦合性。如果读写操作紧密地耦合在一起,消息订阅者需要升级应用程序才能同时处理新旧两种数据格式,在消息订阅者升级了之后,消息发布者才能跟着升级,以便使用新的数据格式。新的应用程序如果需要使用数据,就要与消息发布者发生耦合,导致开发者需要做很多繁杂的工作。定义良好的模式,并把它们存放在公共仓库,可以方便我们理解Kafka的消息结构。
主题和分区
Kafka的消息通过主题进行分类。
主题就好比数据库的表,或者文件系统里的文件夹。主题可以被分为若干个分区,一个分区就是一个提交日志。
消息以追加的方式写人分区,然后以先人先出的顺序读取,要注意,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
图1-5所示的主题有4个分区,消息被追加写人每个分区的尾部。Kafka通过分区来实现数据冗余和伸缩性。分区可以分布在不同的服务器上,也就是说,一个主题可以横跨多个服务器,以此来提供比单个服务器更强大的性能。
- 图1-5:包含多个分区的主题表示
我们通常会使用流这个词来描述Kafka这类系统的数据。很多时候,人们把一个主题的数据看成一个流,不管它有多少个分区。流是一组从生产者移动到消费者的数据。当我们讨论流式处理时,一般都是这样描述消息的。
Kafka Streams、Apache Samza和 Storm 这些框架以实时的方式处理消息,也就是所谓的流式处理。
我们可以将流式处理与离线处理进行比较,比如Hadoop就是被设计用于在稍后某个时刻处理大量的数据。
生产者和消费者
Kafka的客户端就是Kafka系统的用户,它们被分为两种基本类型:生产者和消费者。
除此之外,还有其他高级客户端API——用于数据集成的Kafka Connect API和用于流式处理的Kafka Streams。
这些高级客户端API使用生产者和消费者作为内部组件,提供了高级的功能。
创造消息
生产者创建消息。在其他发布与订阅系统中,生产者可能被称为发布者或写入者。一般情况下,一个消息会被发布到一个特定的主题上。生产者在默认情况下把消息均衡地分布到主题的所有分区上,而并不关心特定消息会被写到哪个分区。不过,在某些情况下,生产者会把消息直接写到指定的分区。这通常是通过消息键和分区器来实现的,分区器为键生成一个散列值,并将其映射到指定的分区上。这样可以保证包含同一个键的消息会被写到同一个分区上。生产者也可以使用自定义的分区器,根据不同的业务规则将消息映射到分区。
消费消息
消费者读取消息。在其他发布与订阅系统中,消费者可能被称为订阅者或读者。
消费者订阅一个或多个主题,并按照消息生成的顺序读取它们。消费者通过检查消息的偏移量来区分已经读取过的消息。偏移量是另一种元数据,它是一个不断递增的整数值,在创建消息时,Kafka会把它添加到消息里。在给定的分区里,每个消息的偏移量都是唯一的。消费者把每个分区最后读取的消息偏移量保存在Zookeeper或Kafka上,如果消费者关闭或重启,它的读取状态不会丢失。
消费者是消费者群组的一部分,也就是说,会有一个或多个消费者共同读取一个主题。群组保证每个分区只能被一个消费者使用。
图1-6所示的群组中,有3个消费者同时读取一个主题。其中的两个消费者各自读取一个分区,另外一个消费者读取其他两个分区。消费者与分区之间的映射通常被称为消费者对分区的所有权关系。
通过这种方式,消费者可以消费包含大量消息的主题。而且,如果一个消费者失效,群组里的其他消费者可以接管失效消费者的工作。第4章将详细介绍消费者和消费者群组。
- 图1-6:消费者群组从主题读取消息
broker 和集群
一个独立的Kafka服务器被称为broker。broker接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存。broker为消费者提供服务,对读取分区的请求作出响应,返回已经提交到磁盘上的消息。根据特定的硬件及其性能特征,单个broker可以轻松处理数千个分区以及每秒百万级的消息量。
broker 是集群的组成部分。每个集群都有一个broker同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。控制器负责管理工作,包括将分区分配给broker和监控broker。
在集群中,一个分区从属于一个broker,该broker被称为分区的首领。一个分区可以分配给多个broker,这个时候会发生分区复制(见图1-7)。
这种复制机制为分区提供了消息冗余,如果有一个broker失效,其他broker可以接管领导权。不过,相关的消费者和生产者都要重新连接到新的首领。
保留消息(在一定期限内)是Kafka的一个重要特性。Kafkabroker默认的消息保留策略是这样的:要么保留一段时间(比如7天),要么保留到消息达到一定大小的字节数(比如1GB)。
当消息数量达到这些上限时,旧消息就会过期并被删除,所以在任何时刻,可用消息的总量都不会超过配置参数所指定的大小。主题可以配置自己的保留策略,可以将消息保留到不再使用它们为止。
例如,用于跟踪用户活动的数据可能需要保留几天,而应用程序的度量指标可能只需要保留几个小时。可以通过配置把主题当作紧凑型日志,只有最后一个带有特定键的消息会被保留下来。这种情况对于变更日志类型的数据来说比较适用,因为人们只关心最后时刻发生的那个变更。
多集群
随着Kafka部署数量的增加,基于以下几点原因,最好使用多个集群。
-
数据类型分离
-
安全需求隔离
- 多数据中心(灾难恢复)
如果使用多个数据中心,就需要在它们之间复制消息。这样,在线应用程序才可以访问到多个站点的用户活动信息
。例如,如果一个用户修改了他们的资料信息,不管从哪个数据中心都应该能看到这些改动。或者多个站点的监控数据可以被聚集到一个部署了分析程序和告警系统的中心位置。
不过,Kafka的消息复制机制只能在单个集群里进行,不能在多个集群之间进行。
Kafka提供了一个叫作MirrorMaker的工具,可以用它来实现集群间的消息复制。MirrorMaker的核心组件包含了一个生产者和一个消费者,两者之间通过一个队列相连。
消费者从一个集群读取消息,生产者把消息发送到另一个集群上。
图1-8展示了一个使用MirrorMaker的例子,两个“本地”集群的消息被聚集到一个“聚合”集群上,然后将该集群复制到其他数据中心。
不过,这种方式在创建复杂的数据管道方面显得有点力不从心。
- 图1-8:多数据中心架构
总结
本文主要讲解了 kafka 名字的来源,kafka 的应用场景,以及 kafka 的优势。
并对 kafka 的基本概念进行介绍,下一节我们将一起学习如何搭建一个 kafka 服务。
今天的关于如何在Apache Kafka中删除主题和kafka删除主题命令的分享已经结束,谢谢您的关注,如果想了解更多关于apache kafka & CDH kafka源码编译、Apache Kafka 1.1.0 发布,改进 Kafka controller、Apache Kafka KRaft - Kafka 存储工具、apache kafka-01-kafka 入门介绍的相关知识,请在本站进行查询。
本文标签:




