此处将为大家介绍关于如何在SpringDataJpa中编写一个选择查询,该查询接受参数的四个组合的详细内容,并且为您解答有关springdatajpain查询的相关问题,此外,我们还将为您介绍关于JD
此处将为大家介绍关于如何在Spring Data Jpa中编写一个选择查询,该查询接受参数的四个组合的详细内容,并且为您解答有关spring data jpa in查询的相关问题,此外,我们还将为您介绍关于JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择 SpringDataJPA 的理由!、JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择SpringDataJPA的理由!、spring data jpa 参数为 null 查询所有,否则根据参数查询、spring data jpa 条件查询 如何模糊查询 mysql 的 date 类型数据的有用信息。
本文目录一览:- 如何在Spring Data Jpa中编写一个选择查询,该查询接受参数的四个组合(spring data jpa in查询)
- JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择 SpringDataJPA 的理由!
- JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择SpringDataJPA的理由!
- spring data jpa 参数为 null 查询所有,否则根据参数查询
- spring data jpa 条件查询 如何模糊查询 mysql 的 date 类型数据
")
如何在Spring Data Jpa中编写一个选择查询,该查询接受参数的四个组合(spring data jpa in查询)
当用户搜索几种组合时,我试图显示结果,他可以通过-搜索
- country
- state
- district
- zipCode
他可以搜索的示例组合是(国家/地区),(国家/地区),(国家/地区,邮政编码)等。
我也在使用Spring Data Jpa进行查询和分页。
我是Spring Jpa的新手,我们将不胜感激。
谢谢!
答案1
小编典典有一个非常简单的技巧可以执行您需要的;)
@Query("select e from Entity e where " +"(:country = '''' or e.country like ''%:country%'') and " +"(:state = '''' or e.state like ''%:state%'') and " +"(:district = '''' or e.district like ''%:district%'') and " +"(:zipCode = '''' or e.zipCode like ''%:zipCode%'')"Page<Entity> advancedSearch(@Param("country") String country, @Param("state") String state, @Param("district") String district, @Param("zipCode") String zipCode, Pageable page);因此,当您需要调用时advancedSearch,可以仅设置需要的参数,而其他设置为"":
Page<Entity> enityPages = advancedSearch("", "California", "1st", "", new PageRequest(...));
JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择 SpringDataJPA 的理由!

序言
Spring Data JPA作为Spring Data中对于关系型数据库支持的一种框架技术,属于ORM的一种,通过得当的使用,可以大大简化开发过程中对于数据操作的复杂度。本文档隶属于《
Spring Data JPA用法与技能探究》系列的第一篇。本系列文档规划对Spring Data JPA进行全方位的使用介绍,一共分为 5 篇文档,如果感兴趣,欢迎关注交流。《Spring Data JPA 用法与技能探究》系列涵盖内容:
- 开篇介绍 —— 《JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择 SpringDataJPA 的理由!》
- 快速上手 —— 《SpringBoot 集成 JPA 介绍》
- 深度进阶 —— 《JPA 核心类型与用法介绍》
- 可靠保障 —— 《聊一聊数据库的事务,以及 Spring 体系下对事务的使用》
- 周边扩展 —— 《JPA 开发辅助效率提升方案介绍》
本章节主要对 Spring Data JPA 的整体情况以及与其相关的一些概念进行一个简单的介绍。
在具体介绍 Spring Data JPA 之前,我们可以先来思考一个问题: 在 JAVA 中,如果需要操作 DB,应该怎么做?
很多人可能首先想到的就是集成一些框架然后去操作就行了、比如 mybatis、Hibernate 框架之类的。 当然,也可能会有人想起 JDBC。
再往深入想一下:
- JAVA 里面的写的一段 DB 操作逻辑,是如何一步步被传递到 DB 中执行了的呢?
- 为什么 JAVA 里面可以去对接不同产商的 DB 产品?
- 为什么有 JDBC、还会有各种 mybatis 或者诸如 Hibernate 等 ORM 框架呢?
- 这些 JDBC、JPA、ORM、Hibernate 等等相互之间啥关系?
- 除了 MyBatis、Hibernate 等习以为常的内容,是否还有其他操作 DB 的方案呢?
- ...
带着这些问题,我们接下来一步步的进行探讨,先树立对 Spring Data JPA 的正确印象。
1. 需要厘清的若干概念
1.1. JDBC
谈到 JAVA 操作数据库相关的概念,JDBC 是绕不过去的一个概念。
先来介绍下 JDBC 究竟是个什么概念。
JDBC(Java DataBase Connectivity),是 java 连接数据库操作的原生接口。 JDBC 对 Java 程序员而言是 API,为数据库访问提供标准的接口。由各个数据库厂商及第三方中间件厂商依照 JDBC 规范为数据库的连接提供的标准方法。

概念阐述的可能稍微有点抽象,说的直白点可以这么理解:各个产商的 DB 产品很多,JAVA 联合各个 DB 产商定了个规范,JAVA 可以按照规范去编写代码,就可以用相同的操作方法去操作不同产商的 DB 了。也就是说 JDBC 是 JAVA 与各个 DB 产商之间的一个约定规范、约束的是 DB 产商的实现规范。
基于 JDBC,我们可以在 JAVA 代码中去执行 DB 操作,如下示意:
package com.txw.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
@SuppressWarnings("all") // 注解警告信息
public class JdbcTest01 {
public static void main(String[] args) throws Exception {
// 1.加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2 创建和数据库之间的连接
String username = "testdb";
String password = "testxxxxxx";
String url = "jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai";
Connection conn = DriverManager.getConnection(url,username,password);
// 3.准备发送SQL
String sql = "select * from t_person";
PreparedStatement pstm = conn.prepareStatement(sql);
// 4.执行SQL,接收结果集
ResultSet rs = pstm.executeQuery();
// 5 处理结果集
while(rs.next()){
int personId1 = rs.getInt("person_id");
String personName1 = rs.getString("person_name");
int age1 = rs.getInt("age");
String sex1 = rs.getString("sex");
String mobile1 = rs.getString("mobile");
String address1 = rs.getString("address");
System.out.println("personId="+personId1+",personName="+personName1
+",age="+age1+",sex="+sex1+",mobile="+mobile1+",address="+address1);
}
// 6.释放资源
rs.close();
pstm.close();
conn.close();
}
}
从上面代码示例中可以看出 JDBC 的几个操作关键环节:
- 根据使用的 DB 类型不同,加载对应的 JdbcDriver
- 连接 DB
- 编写 SQL 语句
- 发送到 DB 中执行,并接收结果返回
- 对结果进行处理解析
- 释放过程中的连接资源
从演示代码里面,还可以看出,直接基于 JDBC 进行操作 DB 的时候,其弊端还是比较明显的:
- 业务代码里面耦合了字符串格式 SQL 语句,复杂场景维护起来比较麻烦;
- 非结构化的 key-value 映射方式处理结果,操作过于复杂,且不符合 JAVA 面向对象的思想;
- 需要关注过程资源的释放、操作不当容易造成泄露。
也正是由于 JDBC 上述比较明显的弊端,纯基于 JDBC 操作 DB 一般仅用于一些小型简单的场景,正式大型项目中,往往很少有直接基于 JDBC 进行编码开发的,而是借助一些封装框架来实现。
1.2. ORM 框架
对象 - 关系映射(Object-Relational Mapping,简称 ORM)。ORM 框架中贯穿着 JAVA 面向对象编程的思想,是面向对象编程的优秀代言人。
直白点说,ORM 就是将代码里面的 JAVA 类与 DB 中的 table 表进行映射,代码中对相关 JAVA 类的操作,即体现为 DB 中对相关 Table 的操作。
ORM 框架很好的解决了 JDBC 存在的一系列问题,简化了 JAVA 开发人员的编码复杂度。
1.3. JPA 介绍
JPA, 即 Java Persistence API 的缩写,也即 JAVA 持久化层 API,这个并非是一个新的概念,其实在 JDK5.x 版本中就已经引入的一个概念。其宗旨是为 POJO 提供一个基于 ORM 的持久化操作的标准规范。
涵盖几个方面:
-
一套标准 API 在 javax.persistence 的包下面提供,用来操作实体对象,执行 CRUD 操作,将开发者从烦琐的 JDBC 和 SQL 代码中解脱出来,按照 JAVA 思路去编写代码操作 DB。
-
面向对象操作语言 通过面向对象的思路,避免代码与 SQL 的深度耦合。
-
ORM 元数据映射 ORM,即 Object Relation Mapping,对象关系映射。
JAVA 应用程序,可以通过 JPA 规范,利用一些常见的基于 JPA 规范的框架来实现对 DB 的操作。而常见的一些 ORM 框架,比如 Hibernate、EclipseLink、OpenJPA 等等,其实都是提供了对 JPA 规范的支持,是 JPA 规范的具体实现提供者,用于辅助 JAVA 程序对数据库数据的操作。

1.4. Spring Data JPA
基于前面介绍,我们了解到 JPA 的基本概念,知晓 JPA 其实是一个基于 ORM 的 JAVA API 规范定义,那么这里提及的 Spring Data JPA 又是什么呢?其与 JPA 之间的关系又是如何呢?
Spirng Data JPA 是 Spring 提供的一套简化 JPA 开发的框架,按照约定好的【方法命名规则】写 DAO 层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作,同时提供了很多除了 CRUD 之外的功能,如分页、排序、复杂查询等等。

注意 Spring Data JPA 不是一个完整 JPA 规范的实现,它只是一个代码抽象层,主要用于减少为各种持久层存储实现数据访问层所需的代码量。其底层依旧是 Hibernate。
可以把 Spring Data JPA 理解为 JPA 规范的再次封装抽象。
1.5. Hibernate
hibernate 是一个标准的 orm 框架,实现 jpa 接口。
1.6. JDBC,ORM,JPA,Spring Data JPA 之间到底啥关系
一个简单粗暴的理解方式:
- JDBC 是 JAVA 操作最终数据库的底层接口,JDBC 是与各个 DB 产商之间约定的协议规范,基于这些规范,可在 JAVA 代码中往 DB 执行 SQL 操作。
- 因为 JDBC 负责将 SQL 语句执行到 DB 中,属于相对原始的接口,业务代码里面需要构建拼接出 SQL 语句,然后基于 JDBC 去 DB 中执行对应 SQL 语句。这样存在的问题会比较明显,JAVA 代码中需要耦合大量的 SQL 语句、且因为缺少封装,实际业务编码使用时会比较繁琐、维护复杂。
- 为了能够将代码与 SQL 语句分离开,以一种更符合 JAVA 面向对象编程思维的方式来操作 DB,诞生了 ORM(Object Relation Mapping, 对象关系映射)概念,ORM 将 JAVA 的 Object 与 DB 中的 Table 进行映射起来,管理 Object 也等同于对 Table 的管理与操作,这样就可以实现没有 SQL 的情况下实现对 DB 的操作。常见的 ORM 框架有
Hibernate、EclipseLink、OpenJPA等等。 - 为了规范 ORM 的具体使用,JAVA 5.x 开始制定了基于 ORM 思想的 Java 持久化层操作 API 规范,也即 JPA(注意,JPA 只是一个基于 ORM 的 JAVA API 规范,供各个 ORM 框架提供 API 时遵循),当前主流 ORM 框架都是支持 JPA 规范的。
- Spring 框架盛行的时代,为了能够更好适配,Spring Data JPA 诞生, 这个可以理解为对 JPA 规范的二次封装(可以这么理解:Spring Data JPA 不是一个完整 JPA 规范的实现,它只是一个代码抽象层,主要用于减少为各种持久层存储实现数据访问层所需的代码量),其底层使用的依旧是常规 ORM 框架(Hibernate)。
相互之间的关系详解,见下图示意。

2. 选择 Spring Data JPA 的理由
2.1. Spring Data JPA 的优势
在介绍 Spring Data JPA 的优势前,先看个代码例子。
场景: 一张用户表(UserEntity),信息如下: | ID | UserName | Department | Role | | --- | -------- | ---------- | ------ | | 1 | Jack | DevDept | Normal | | 2 | Tom | DevDept | Admin | | 3 | Tony | SaleDept | Normal |
代码中实现如下诉求: (1)获取所有研发部门的人员:
List<UserEntity> users = userReposity.findAllByDepartment("DevDept");
(2)获取研发部门的管理员:
List<UserEntity> users = userReposity.findAllByDepartmentAndRole("DevDept", "Admin");
看完上面的例子,一个最直观的感受是什么? 简单!
没错,“简单” 就是 Spring Data JPA 最大的优势!
对于大部分的常规操作,基于 Spring Data JPA,开发人员可以更加专注于业务逻辑的开发,而不用花费太多的精力去关注 DB 层面的封装处理以及 SQL 的编写维护,甚至在 DAO 层都不需要去定义接口。
除了简化开发,JPA 还有的另一个比较大的优势,就是其可移植性比较好,因为其通过 JPQL 的方式进行操作,与原生 SQL 之间几乎没有耦合,所以可以方便的将底层 DB 切换到别的类型。
2.2. Spring Data JPA 整体实现逻辑
基于前面的介绍,我们可以这样理解,JAVA 业务层调用 SpringData JPA 二次封装提供的 Repository 层接口,进而基于 JPA 标准 API 进行处理,基于 Hibernate 提供的 JPA 具体实现,接着基于 JDBC 标准 API 接口,完成与实际 DB 之间的请求交互。整体的处理逻辑全貌图如下:

这里可以看出,JPA、Hibernate、SpringData JPA 三者之间的关系:
- JPA(Java Persistence API)是规范,它指明了持久化、读取和管理 Java 对象映射到数据库表时的规范。
- Hibernate 则是一个 ORM 框架,它实现了 Java 对象到数据库表的映射。也就是说,Hibernate 提供了 JPA 的一种实现。
- Spring Data JPA 是 Spring Framework 的一部分。它不是 JPA 的实现,而是在 JPA 之上提供更高层次的抽象,可以减少很多模板代码。而 Spring Data JAP 的默认实现是 Hibernate,当然也可以其他的 JPA Provider。
2.3. Spring Data JPA 还是 MyBatis?如何抉择
提到 JPA, 那么 MyBatis 绝对是无法回避的一个内容。的确,作为 JAVA 持久化层的优秀框架,MyBatis 甚至是很多开发人员在项目构建初期脑海中唯一的选型方案。那么,JPA 想要从 MyBatis 占领地中分一杯羹,究竟是具有哪方面的优势呢?
先来了解下 MyBatis。 MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎全部的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs (Plain Old Java Objects, 普通的 Java 对象) 映射成数据库中的记录。 优势:
- MyBatis 则是一个可以灵活编写 sql 语句
- MyBatis 避免了几乎全部的 JDBC 代码和手动设置参数以及获取结果集,相比 JDBC 更方便
MyBatis 与 JPA 的差异点:
- 设计哲学不同,MyBatis 偏向于面向过程,JPA 则将面向对象发挥到极致;
- MyBatis 定制起来更加灵活,支持高度定制化的 sql 语句,支持任意编写 sql 语句;JPA 相对更注重对已有高频简单操作场景的封装,简化开发人员的重复操作,虽然 JPA 也支持定制 SQL 语句,但是相比 MyBatis 灵活度略差。
至此,到底如何在 JPA 与 MyBatis 之间抉择,就比较清晰了:
- 如果你的系统中对 DB 的操作没有太多额外的深度定制、对 DB 的执行性能也不是极度敏感、不需要基于 SQL 语句做一些深度的优化,大部分场景都是一些基础 CRUD 操作,则无疑 Spring Data JPA 是比较理想的选择,它将大大降低开发人员在 DB 操作层面的投入精力。
- 如果你的业务中对 DB 高阶逻辑依赖太深,比如大部分场景都需要额外定制复杂 SQL 语句来实现,或者系统对性能及其敏感,需要基于 Table 甚至 column 维度进行深度优化,或者数据量特别巨大的场景,则相比较而言,MyBatis 提供的调优定制灵活性上要更有优势一些。
综上分析,其实 MyBatis 与 Spring Data JPA 其实没有一个绝对的维度来评价谁更优一些,具体需要结合自身的实际诉求来选择。
再看个有意思的数据,此前有人统计过使用百度、谷歌等搜素引擎搜素 JPA 与 Mybatis 关键字的搜索热度与区域的数据,如下所示:

从图中可以看出,MyBatis 在中国地区相对更受欢迎一些,但是在国外 JPA 的受欢迎度要更高一些。
3. 小结,承上启下
好啦,本篇内容就介绍到这里。
通过本篇内容,对 JAVA 体系中 DB 操作相关的组件、规范等有了一定初步的了解,也大致了解了应该如何选择是使用 JPA 还是 MyBatis 选型。
后续几篇系列文章中,将会一步步的介绍下 Spring Data JPA 的核心内容与具体项目实现,一步步的揭开 JPA 的庐山真面目。
如果通过本文介绍,你对 JPA 也有进一步了解的兴趣,欢迎关注我的后续系列文档。 如果对本文有自己的见解,或者有任何的疑问或建议,都可以留言,我们一起探讨、共同进步。
我是悟道君,聊技术、又不仅仅聊技术~ 期待与你一起探讨,一起成长为更好的自己。


JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择SpringDataJPA的理由!
序言
Spring Data JPA作为Spring Data中对于关系型数据库支持的一种框架技术,属于ORM的一种,通过得当的使用,可以大大简化开发过程中对于数据操作的复杂度。本文档隶属于《
Spring Data JPA用法与技能探究》系列的第一篇。本系列文档规划对Spring Data JPA进行全方位的使用介绍,一共分为5篇文档,如果感兴趣,欢迎关注交流。《Spring Data JPA用法与技能探究》系列涵盖内容:
- 开篇介绍 —— 《JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择SpringDataJPA的理由!》
- 快速上手 —— 《SpringBoot集成JPA介绍》
- 深度进阶 —— 《JPA核心类型与用法介绍》
- 可靠保障 —— 《聊一聊数据库的事务,以及Spring体系下对事务的使用》
- 周边扩展 —— 《JPA开发辅助效率提升方案介绍》
本章节主要对Spring Data JPA的整体情况以及与其相关的一些概念进行一个简单的介绍。
在具体介绍Spring Data JPA之前,我们可以先来思考一个问题: 在JAVA中,如果需要操作DB,应该怎么做?
很多人可能首先想到的就是集成一些框架然后去操作就行了、比如mybatis、Hibernate框架之类的。
当然,也可能会有人想起JDBC。
再往深入想一下:
- JAVA里面的写的一段DB操作逻辑,是如何一步步被传递到DB中执行了的呢?
- 为什么JAVA里面可以去对接不同产商的DB产品?
- 为什么有JDBC、还会有各种mybatis或者诸如Hibernate等ORM框架呢?
- 这些JDBC、JPA、ORM、Hibernate等等相互之间啥关系?
- 除了MyBatis、Hibernate等习以为常的内容,是否还有其他操作DB的方案呢?
- ...
带着这些问题,我们接下来一步步的进行探讨,先树立对Spring Data JPA的正确印象。
1. 需要厘清的若干概念
1.1. JDBC
谈到JAVA操作数据库相关的概念,JDBC是绕不过去的一个概念。
先来介绍下JDBC究竟是个什么概念。
JDBC(Java DataBase Connectivity),是java连接数据库操作的原生接口。
JDBC对Java程序员而言是API,为数据库访问提供标准的接口。由各个数据库厂商及第三方中间件厂商依照JDBC规范为数据库的连接提供的标准方法。
概念阐述的可能稍微有点抽象,说的直白点可以这么理解:各个产商的DB产品很多,JAVA联合各个DB产商定了个规范,JAVA可以按照规范去编写代码,就可以用相同的操作方法去操作不同产商的DB了。也就是说JDBC是JAVA与各个DB产商之间的一个约定规范、约束的是DB产商的实现规范。
基于JDBC,我们可以在JAVA代码中去执行DB操作,如下示意:
package com.txw.jdbc;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
@SuppressWarnings("all") // 注解警告信息
public class JdbcTest01 {
public static void main(String[] args) throws Exception {
// 1.加载驱动
Class.forName("com.MysqL.cj.jdbc.Driver");
// 2 创建和数据库之间的连接
String username = "testdb";
String password = "testxxxxxx";
String url = "jdbc:MysqL://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai";
Connection conn = DriverManager.getConnection(url,username,password);
// 3.准备发送sql
String sql = "select * from t_person";
PreparedStatement pstm = conn.prepareStatement(sql);
// 4.执行sql,接收结果集
ResultSet rs = pstm.executeQuery();
// 5 处理结果集
while(rs.next()){
int personId1 = rs.getInt("person_id");
String personName1 = rs.getString("person_name");
int age1 = rs.getInt("age");
String sex1 = rs.getString("sex");
String mobile1 = rs.getString("mobile");
String address1 = rs.getString("address");
System.out.println("personId="+personId1+",personName="+personName1
+",age="+age1+",sex="+sex1+",mobile="+mobile1+",address="+address1);
}
// 6.释放资源
rs.close();
pstm.close();
conn.close();
}
}
从上面代码示例中可以看出JDBC的几个操作关键环节:
- 根据使用的DB类型不同,加载对应的JdbcDriver
- 连接DB
- 编写sql语句
- 发送到DB中执行,并接收结果返回
- 对结果进行处理解析
- 释放过程中的连接资源
从演示代码里面,还可以看出,直接基于JDBC进行操作DB的时候,其弊端还是比较明显的:
- 业务代码里面耦合了字符串格式sql语句,复杂场景维护起来比较麻烦;
- 非结构化的key-value映射方式处理结果,操作过于复杂,且不符合JAVA面向对象的思想;
- 需要关注过程资源的释放、操作不当容易造成泄露。
也正是由于JDBC上述比较明显的弊端,纯基于JDBC操作DB一般仅用于一些小型简单的场景,正式大型项目中,往往很少有直接基于JDBC进行编码开发的,而是借助一些封装框架来实现。
1.2. ORM框架
对象-关系映射(Object-Relational Mapping,简称ORM)。ORM框架中贯穿着JAVA面向对象编程的思想,是面向对象编程的优秀代言人。
直白点说,ORM就是将代码里面的java类与DB中的table表进行映射,代码中对相关java类的操作,即体现为DB中对相关Table的操作。
ORM框架很好的解决了JDBC存在的一系列问题,简化了JAVA开发人员的编码复杂度。
1.3. JPA介绍
JPA, 即Java Persistence API的缩写,也即JAVA持久化层API,这个并非是一个新的概念,其实在JDK5.x版本中就已经引入的一个概念。其宗旨是为POJO提供一个基于ORM的持久化操作的标准规范。
涵盖几个方面:
-
一套标准API
在javax.persistence的包下面提供,用来操作实体对象,执行CRUD操作,将开发者从烦琐的JDBC和sql代码中解脱出来,按照JAVA思路去编写代码操作DB。 -
面向对象操作语言
通过面向对象的思路,避免代码与sql的深度耦合。 -
ORM元数据映射
ORM,即Object Relation Mapping,对象关系映射。
JAVA应用程序,可以通过JPA规范,利用一些常见的基于JPA规范的框架来实现对DB的操作。而常见的一些ORM框架,比如Hibernate、EclipseLink、OpenJPA等等,其实都是提供了对JPA规范的支持,是JPA规范的具体实现提供者,用于辅助JAVA程序对数据库数据的操作。
1.4. Spring Data JPA
基于前面介绍,我们了解到JPA的基本概念,知晓JPA其实是一个基于ORM的JAVA API规范定义,那么这里提及的Spring Data JPA又是什么呢?其与JPA之间的关系又是如何呢?
Spirng Data JPA是Spring提供的一套简化JPA开发的框架,按照约定好的【方法命名规则】写DAO层接口,就可以在不写接口实现的情况下,实现对数据库的访问和操作,同时提供了很多除了CRUD之外的功能,如分页、排序、复杂查询等等。
注意
Spring Data JPA不是一个完整JPA规范的实现,它只是一个代码抽象层,主要用于减少为各种持久层存储实现数据访问层所需的代码量。其底层依旧是Hibernate。
可以把Spring Data JPA理解为JPA规范的再次封装抽象。
1.5. Hibernate
hibernate是一个标准的orm框架,实现jpa接口。
1.6. JDBC,ORM,JPA,Spring Data JPA之间到底啥关系
一个简单粗暴的理解方式:
- JDBC是JAVA操作最终数据库的底层接口,JDBC是与各个DB产商之间约定的协议规范,基于这些规范,可在JAVA代码中往DB执行sql操作。
- 因为JDBC负责将sql语句执行到DB中,属于相对原始的接口,业务代码里面需要构建拼接出sql语句,然后基于JDBC去DB中执行对应sql语句。这样存在的问题会比较明显,JAVA代码中需要耦合大量的sql语句、且因为缺少封装,实际业务编码使用时会比较繁琐、维护复杂。
- 为了能够将代码与sql语句分离开,以一种更符合JAVA面向对象编程思维的方式来操作DB,诞生了ORM(Object Relation Mapping, 对象关系映射)概念,ORM将JAVA的Object与DB中的Table进行映射起来,管理Object也等同于对Table的管理与操作,这样就可以实现没有sql的情况下实现对DB的操作。常见的ORM框架有
Hibernate、EclipseLink、OpenJPA等等。 - 为了规范ORM的具体使用,JAVA 5.x开始制定了基于ORM思想的Java持久化层操作API规范,也即JPA(注意,JPA只是一个基于ORM的JAVA API规范,供各个ORM框架提供API时遵循),当前主流ORM框架都是支持JPA规范的。
- Spring框架盛行的时代,为了能够更好适配,Spring Data JPA诞生, 这个可以理解为对JPA规范的二次封装(可以这么理解:Spring Data JPA不是一个完整JPA规范的实现,它只是一个代码抽象层,主要用于减少为各种持久层存储实现数据访问层所需的代码量),其底层使用的依旧是常规ORM框架(Hibernate)。
相互之间的关系详解,见下图示意。
2. 选择Spring Data JPA的理由
2.1. Spring Data JPA的优势
在介绍Spring Data JPA的优势前,先看个代码例子。
场景:
一张用户表(UserEntity),信息如下:
| ID | UserName | Department | Role |
|---|---|---|---|
| 1 | Jack | DevDept | normal |
| 2 | Tom | DevDept | Admin |
| 3 | Tony | SaleDept | normal |
代码中实现如下诉求:
(1)获取所有研发部门的人员:
List<UserEntity> users = userReposity.findAllByDepartment("DevDept");
(2)获取研发部门的管理员:
List<UserEntity> users = userReposity.findAllByDepartmentAndRole("DevDept", "Admin");
看完上面的例子,一个最直观的感受是什么?
简单!
没错,“简单”就是Spring Data JPA最大的优势!
对于大部分的常规操作,基于Spring Data JPA,开发人员可以更加专注于业务逻辑的开发,而不用花费太多的精力去关注DB层面的封装处理以及sql的编写维护,甚至在DAO层都不需要去定义接口。
除了简化开发,JPA还有的另一个比较大的优势,就是其可移植性比较好,因为其通过JPQL的方式进行操作,与原生sql之间几乎没有耦合,所以可以方便的将底层DB切换到别的类型。
2.2. Spring Data JPA整体实现逻辑
基于前面的介绍,我们可以这样理解,JAVA业务层调用SpringData JPA二次封装提供的Repository层接口,进而基于JPA标准API进行处理,基于Hibernate提供的JPA具体实现,接着基于JDBC标准API接口,完成与实际DB之间的请求交互。整体的处理逻辑全貌图如下:
这里可以看出,JPA、Hibernate、SpringData JPA三者之间的关系:
- JPA(Java Persistence API)是规范,它指明了持久化、读取和管理 Java 对象映射到数据库表时的规范。
- Hibernate 则是一个 ORM 框架,它实现了 Java 对象到数据库表的映射。也就是说,Hibernate 提供了 JPA 的一种实现。
- Spring Data JPA 是 Spring Framework 的一部分。它不是 JPA 的实现,而是在 JPA 之上提供更高层次的抽象,可以减少很多模板代码。而 Spring Data JAP 的默认实现是 Hibernate,当然也可以其他的 JPA Provider。
2.3. Spring Data JPA还是MyBatis?如何抉择
提到JPA, 那么MyBatis绝对是无法回避的一个内容。的确,作为JAVA持久化层的优秀框架,MyBatis甚至是很多开发人员在项目构建初期脑海中唯一的选型方案。那么,JPA想要从MyBatis占领地中分一杯羹,究竟是具有哪方面的优势呢?
先来了解下MyBatis。
MyBatis是一款优秀的持久层框架,它支持定制化sql、存储过程以及高级映射。MyBatis 避免了几乎全部的JDBC代码和手动设置参数以及获取结果集。MyBatis可使用简单的XML或注解来配置和映射原生信息,将接口和Java的POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
优势:
- MyBatis则是一个可以灵活编写sql语句
- MyBatis避免了几乎全部的JDBC代码和手动设置参数以及获取结果集,相比JDBC更方便
MyBatis与JPA的差异点:
- 设计哲学不同,MyBatis偏向于面向过程,JPA则将面向对象发挥到极致;
- MyBatis定制起来更加灵活,支持高度定制化的sql语句,支持任意编写sql语句;JPA相对更注重对已有高频简单操作场景的封装,简化开发人员的重复操作,虽然JPA也支持定制sql语句,但是相比MyBatis灵活度略差。
至此,到底如何在JPA与MyBatis之间抉择,就比较清晰了:
- 如果你的系统中对DB的操作没有太多额外的深度定制、对DB的执行性能也不是极度敏感、不需要基于sql语句做一些深度的优化,大部分场景都是一些基础CRUD操作,则无疑Spring Data JPA是比较理想的选择,它将大大降低开发人员在DB操作层面的投入精力。
- 如果你的业务中对DB高阶逻辑依赖太深,比如大部分场景都需要额外定制复杂sql语句来实现,或者系统对性能及其敏感,需要基于Table甚至column维度进行深度优化,或者数据量特别巨大的场景,则相比较而言,MyBatis提供的调优定制灵活性上要更有优势一些。
综上分析,其实MyBatis与Spring Data JPA其实没有一个绝对的维度来评价谁更优一些,具体需要结合自身的实际诉求来选择。
再看个有意思的数据,此前有人统计过使用百度、谷歌等搜素引擎搜素JPA与Mybatis关键字的搜索热度与区域的数据,如下所示:
从图中可以看出,MyBatis在中国地区相对更受欢迎一些,但是在国外JPA的受欢迎度要更高一些。
3. 小结,承上启下
好啦,本篇内容就介绍到这里。
通过本篇内容,对JAVA体系中DB操作相关的组件、规范等有了一定初步的了解,也大致了解了应该如何选择是使用JPA还是MyBatis选型。
后续几篇系列文章中,将会一步步的介绍下Spring Data JPA的核心内容与具体项目实现,一步步的揭开JPA的庐山真面目。
如果通过本文介绍,你对JPA也有进一步了解的兴趣,欢迎关注我的后续系列文档。
如果对本文有自己的见解,或者有任何的疑问或建议,都可以留言,我们一起探讨、共同进步。
我是悟道君,聊技术、又不仅仅聊技术~
期待与你一起探讨,一起成长为更好的自己。

spring data jpa 参数为 null 查询所有,否则根据参数查询
分页结果集封装
public class PageResult<T> {
private long total;//总条数
private Integer totalPage;//总页数
private List<T> list;
public PageResult() {
}
public PageResult(long total, List<T> list) {
this.total = total;
this.list = list;
}
public PageResult(long total, Integer totalPage, List<T> list) {
this.total = total;
this.totalPage = totalPage;
this.list = list;
}
public long getTotal() {
return total;
}
public void setTotal(long total) {
this.total = total;
}
public Integer getTotalPage() {
return totalPage;
}
public void setTotalPage(Integer totalPage) {
this.totalPage = totalPage;
}
public List<T> getList() {
return list;
}
public void setList(List<T> list) {
this.list = list;
}
}
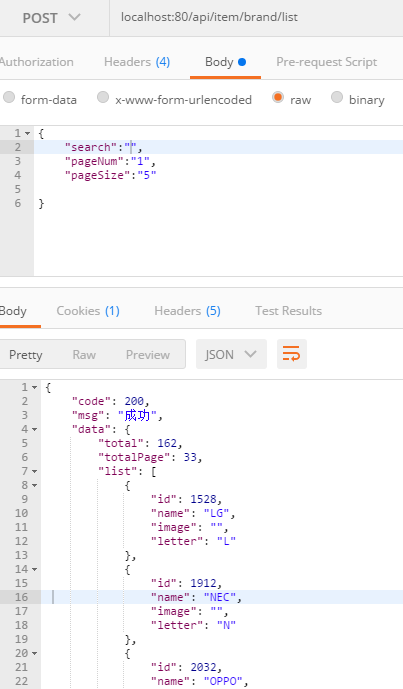
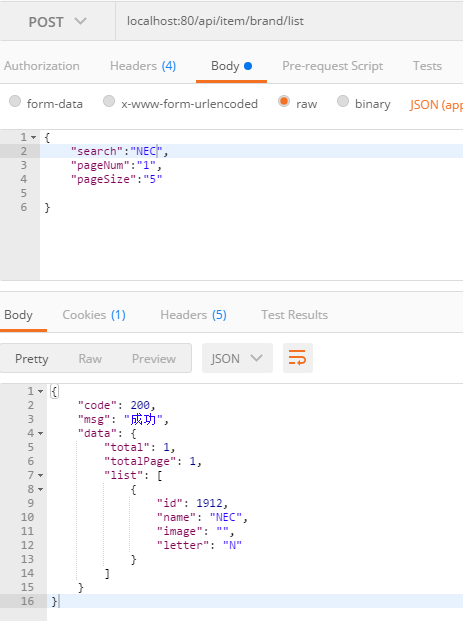
@RequestMapping(value = "/list",method = RequestMethod.POST)
public Result getBrandList(@RequestBody Map<String,String> map ){
String search = map.get("search");
String pageNum = map.get("pageNum");
String pageSize = map.get("pageSize");
if (StringUtils.isEmpty(pageNum)){
pageNum="1";
}
if (StringUtils.isEmpty(pageSize)){
pageSize="5";
}
PageResult<Brand> list=brandService.getBrandList(search,Integer.valueOf(pageNum),Integer.valueOf(pageSize));
return ResultUtil.success(list);
}
PageResult<Brand> getBrandList(String search, Integer pageNum, Integer pageSize);@Autowired
private BrandDao brandDao;
@Override
public PageResult<Brand> getBrandList(String search, Integer pageNum, Integer pageSize) {
Specification<Brand> specification=new Specification<Brand>() {
//select * from tb_brand where name like? limit 0,10;
@Override
public Predicate toPredicate(Root<Brand> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
Path<Object> name = root.get("name");
List<Predicate> predicateList = new ArrayList<>();
if (search!=null){
Predicate p1 = criteriaBuilder.like(name.as(String.class),"%"+search+"%");
predicateList.add(p1);
return criteriaQuery.where(p1).getRestriction();
}
Predicate[] pre = new Predicate[predicateList.size()];
return criteriaQuery.where(predicateList.toArray(pre)).getRestriction();
}
};
Pageable pageable=new PageRequest(pageNum-1,pageSize);
Page<Brand> page=brandDao.findAll(specification,pageable);
List<Brand> list = page.getContent();//数据
int totalPages = page.getTotalPages();//总页数
long total = page.getTotalElements();//总条数
return new PageResult<>(total,totalPages,list);
}
public interface BrandDao extends JpaRepository<Brand,Long>, JpaSpecificationExecutor<Brand> {
}

spring data jpa 条件查询 如何模糊查询 mysql 的 date 类型数据
我在使用 spring data jpa 然后需要写个多条件查询 其中一个条件对应数据库字段是 date 类型我的问题是
在数据库中我们写 mysql 针对 date 类型字段的查询可以写成
select * from table where date_m like ''2014-08%''
但是在代码里我像下面这么写却报类型不匹配的错误
注:myCode 和 myTime 均为方法参数 myTime 为字符串类型格式为 "2018-08"
Page<MyObject> page = myObjectRepository.findAll(new Specification<MyObject>() {
public Predicate toPredicate(Root<MyObject> root, CriteriaQuery<?> query, CriteriaBuilder cb) {
List<Predicate> predicates = new ArrayList<Predicate>();
predicates.add(cb.equal(root.get("code"), myCode));
predicates.add(cb.like(root.get("time"), myTime + "%"));
return cb.and(predicates.toArray(new Predicate[0]));
}
},pageable);
数据库为 mysql 字段 time 类型为 date 格式 "yyyy-MM-dd HHmm"
我的一个解决思路是 将传进来的参数 myTime 转换成 两个时间点
一个是 "2014-08-01 00:00:00" 另一个是 "2014-08-31 23:59:59"
查询这段时间间隔内的数据量
可能是写法不对,也没有成功
还请大家多指教。
今天关于如何在Spring Data Jpa中编写一个选择查询,该查询接受参数的四个组合和spring data jpa in查询的讲解已经结束,谢谢您的阅读,如果想了解更多关于JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择 SpringDataJPA 的理由!、JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?一文带你厘清个中曲直,给你个选择SpringDataJPA的理由!、spring data jpa 参数为 null 查询所有,否则根据参数查询、spring data jpa 条件查询 如何模糊查询 mysql 的 date 类型数据的相关知识,请在本站搜索。
本文标签:




