本文将带您了解关于Pandas分组删除异常值的新内容,同时我们还将为您解释pandas删除异常值的相关知识,另外,我们还将为您提供关于40期《Pandas数据处理与分析》|pandas基础笔记2|pa
本文将带您了解关于Pandas分组删除异常值的新内容,同时我们还将为您解释pandas 删除异常值的相关知识,另外,我们还将为您提供关于40期《Pandas数据处理与分析》|pandas基础笔记2|pandas 基础|joyfulPandas、7-pandas分组计算、Matlab IQR准则剔除异常值、matlab 编程代写使用 hampel 滤波,去除异常值的实用信息。
本文目录一览:- Pandas分组删除异常值(pandas 删除异常值)
- 40期《Pandas数据处理与分析》|pandas基础笔记2|pandas 基础|joyfulPandas
- 7-pandas分组计算
- Matlab IQR准则剔除异常值
- matlab 编程代写使用 hampel 滤波,去除异常值
")
Pandas分组删除异常值(pandas 删除异常值)
我想按组明智地删除基于百分位数99值的离群值。
import pandas as pd df = pd.DataFrame({''Group'': [''A'',''A'',''A'',''B'',''B'',''B'',''B''], ''count'': [1.1,11.2,1.1,3.3,3.40,3.3,100.0]})在输出中,我想从A组中删除11.2,从B组中删除100。因此在最终数据集中只有5个观测值。
wantdf = pd.DataFrame({''Group'': [''A'',''A'',''B'',''B'',''B''], ''count'': [1.1,1.1,3.3,3.40,3.3]})我已经尝试过了这一步,但没有得到理想的结果
df[df.groupby("Group")[''count''].transform(lambda x : (x<x.quantile(0.99))&(x>(x.quantile(0.01)))).eq(1)]答案1
小编典典我不希望使用分位数,因为您将排除较低的值:
import pandas as pddf = pd.DataFrame({''Group'': [''A'',''A'',''A'',''B'',''B'',''B'',''B''], ''count'': [1.1,11.2,1.1,3.3,3.40,3.3,100.0]})print(pd.DataFrame(df.groupby(''Group'').quantile(.01)[''count'']))输出:
countGroup A 1.1B 3.3这些不是离群值,对吧?因此,您不想排除它们。
您可以尝试通过使用与中位数之间的标准偏差来设置左右极限吗?这有点冗长,但是它为您提供了正确的答案:
left = pd.DataFrame(df.groupby(''Group'').median() - pd.DataFrame(df.groupby(''Group'').std()))right = pd.DataFrame(df.groupby(''Group'').median() + pd.DataFrame(df.groupby(''Group'').std()))left.columns = [''left'']right.columns = [''right'']df = df.merge(left, left_on=''Group'', right_index=True)df = df.merge(right, left_on=''Group'', right_index=True)df = df[(df[''count''] > df[''left'']) & (df[''count''] < df[''right''])]df = df.drop([''left'', ''right''], axis=1)print(df)输出:
Group count0 A 1.12 A 1.13 B 3.34 B 3.45 B 3.3
40期《Pandas数据处理与分析》|pandas基础笔记2|pandas 基础|joyfulPandas
目录
- 一、文件的读取和写入
- 基本数据结构
- 1. Series
- 2. DataFrame
- 方法一(data,index,columns)
- 方法二(data(columns),index)
- 常用基本函数
- 1. 汇总函数
- 2. 特征统计函数
- 3.唯一值函数
- 4. 替换函数
- 数值替换 round,abs,clip
- 练习
- 5.排序函数
- 6.apply 方法
- 四、窗口对象
- 1. 滑窗对象
- 练习2
- 2. 扩张窗口
- 五、练习
- Ex2:指数加权窗口
import numpy as np
import pandas as pd
查看pandas 版本pd.__version__
一、文件的读取和写入
-
文件的读取
pd.read_csv()#csv
pd.read_table()#txt
pd.read_excel()#excel
常用的公共参数
header=None# 第一行不作为列名
index_col#表示把某一列或几列作为索引
usecols#读取列的集合
parse_dates#表示需要转化为时间的列
nrows#读取的数据的行数
Attention:
读取txt文件的时候,经常遇到分隔符非空格的情况,read_table有个分割参数 sep,用户可以自定义分割符号,进行txt数据的读取.
sep是正则参数,|需要转义成|

pd.read_table('../data/my_table_special_sep.txt', sep=' \|\|\|\| ', engine='python')
- 数据的写入
df.to_csv('...',index=False)
#当索引没有任何意义的时候可以在保存的时候去除
***** to_csv可以保存txt文件,可以自定义分隔符sep参数,一般设置成制表符'\t'
如果要将表格转换成markdown和latex可以使用to_markdown和to_latex,需要安装tabulate包。
基本数据结构
1. Series
Series一般由四个部分组成,分别是序列的值data、索引index(name)、存储类型dtype、序列的名字name。
其中,索引也可以指定它的名字,默认为空。
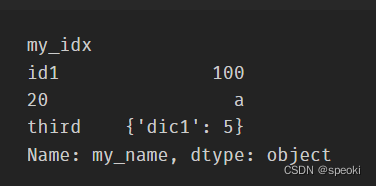
s=pd.Series(data=[100,'a',{'dic1':5}],
index=pd.Index(['id1':20,'third'],name='my_idx'),
dtype='object',
name='my_name')
#获取属性
s.values
s.index //s.index.name#获取索引的名字
s[index_item]#取出单个索引的值 如s['third']
s.dtype
s.name
s.shape
2. DataFrame
DataFrame在Series的基础上增加了列索引
方法一(data,index,columns)
data=[[1,'a',1.2],[2,'b',2.2],[3,'c',3.2]]
df=pd.DataFrame(data=data,
index=['row_%d'%i for i in range(3)], ⭐
columns=['col_0','col_1','col_2'])
方法二(data(columns),index)
一般而言,更多的时候会采用从列索引名到数据的映射来构造数据框,同时再加上行索引:
df=pd.Dataframe(data={'col_0':[1,2,3]
'col_1':list('abc'),
'col_2':[1.2,2.2,3.2]},
index=['row_%d'%i for i in range(3)])
索引
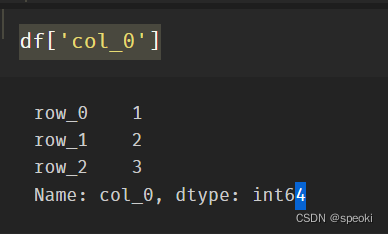
df['col_0']
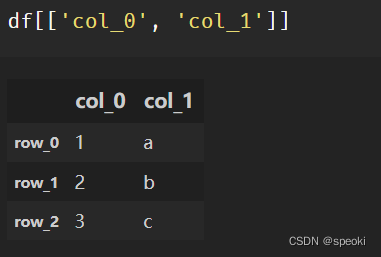
df[['col_0','col_1']]
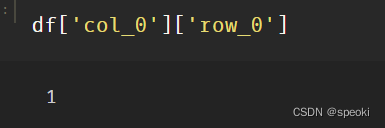
df['col_0']['row_0']
常用属性
df.values
df.index
df.columns
df.dtypes
df.shape
df.T
常用基本函数
1. 汇总函数
引入数据
df=pd.read_csv('')

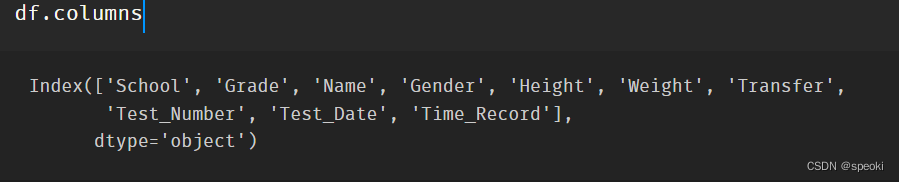
上述列名依次代表学校、年级、姓名、性别、身高、体重、是否为转系生、体测场次、测试时间、1000米成绩,本章只需使用其中的前七列。
取出数据前7列
df=df[df.columns[:7]]
取出数据前2行
df.head(2)
取出数据后3行
df.tail(3)
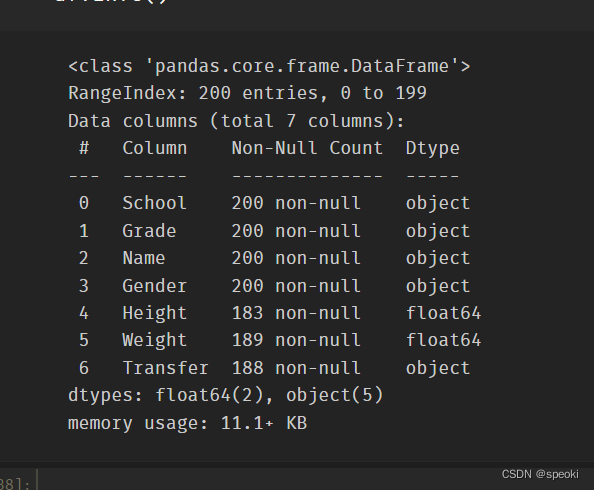
info()返回表的信息概况
df.info()
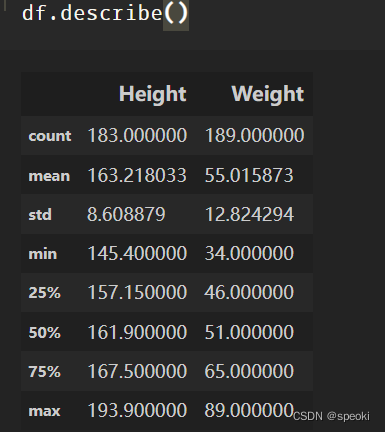
**describe表中数据数值列对应的主要统计量 **
df.describe()
更全面的数据汇总 使用pandas-profiling
2. 特征统计函数
sum, mean, median, var, std, max, min
引入df.demo数据
df_demo=df[['Height','Weight']]
df_demo.mean()
df_demo.max()
df_demo.quantile(0.75)
df_demo.count()
df_demo.idxmax() #获取pandas中series最大值对应的索引。
# idxmin是对应的函数
3.唯一值函数
对序列使用unique,nunique可以分别其唯一值组成的列表和唯一值的个数
df['School'].unique()#唯一值组成的列表
df['School'].nunique()#求某列有多少种不同的数
df['School'].value_counts()#得到唯一值及其对应的频数
观察多个列组合的唯一值 drop_duplicates()
关键参数:
keep:
'first’保留第一次出现的所在行,
‘last’保留最后一行所在行,
False:把所有重复组合所在的行删除
df_demo=df[['Gender','Transfer','Name']]
df_demo.drop_duplicates(['Gender','Transfer'],keep='last')
df['School'].drop_duplicates() # 在Series上也可以使用
duplicated和drop_duplicates的功能类似,但前者返回了是否为唯一值的布尔列表,其keep参数与后者一致。
drop_duplicates等价于把duplicated为True的对应行剔除。
4. 替换函数
替换操作是针对某一个列进行的
pandas中的替换函数可以归纳为三类:映射替换、逻辑替换、数值替换。
映射替换
其中映射替换包含replace方法、第八章中的str.replace方法,第九章中的cat.codes方法
在replace中,可以通过字典构造,或者传入两个列表来进行替换
df['Gender'].replace({'Female':0,'Male':1}).head()
df['Gender'].replace(['Female','Male'],[0,1]).head()
replace特殊方向替换
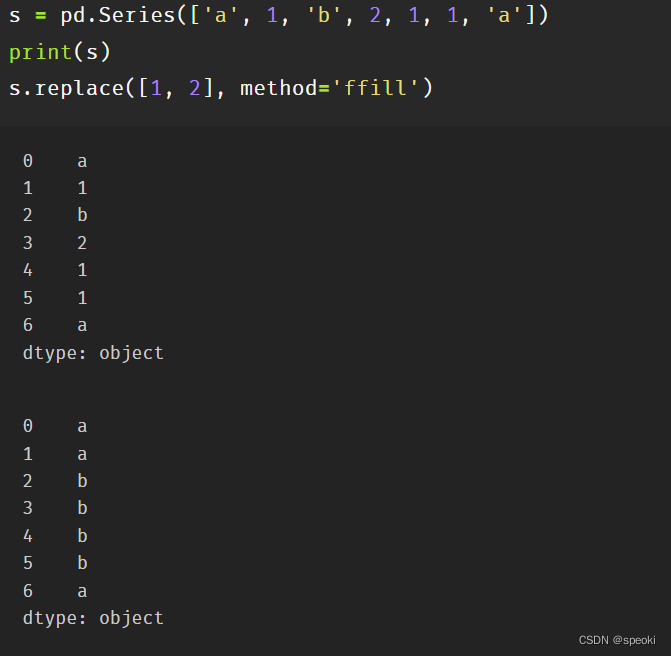
method参数
ffill:用前面一个最近的未被替换的值进行替换
bfill:使用后面最近的未被替换的值进行替换
正则替换使用str.replace()
当前版本下对于string类型的正则替换还存在bug,因此如有此需求,请选择str.replace进行替换操作
逻辑替换
s=pd.Series([-1,1.2345,100,-50])
s.where(s<0)
s.where(s<0,100)
s.mask(s<0)#替换满足条件的值为Nan
s.mask(s<10,100)#替换满足条件的值为100
#构造一个bool序列类型,替换满足条件相应的数据
#传入的条件只需是与被调用的Series索引一致的布尔序列
s_condition=pd.Series([True,False,False,True],index=s.index)
s.mask(s_condition,-50)
数值替换 round,abs,clip
它们分别表示按照给定精度round四舍五入、abs取绝对值和clip截断
s=pd.Series([-1,1.2345,100,-50])
s.round(2)
s.clip(0,2)#前两个数分别表示上下截断边界
练习
clip 中,超过边界的只能截断为边界值,如果要把超出边界的替换为自定义的值,应当如何做?
s.clip(0,2).replace({2:100,0:-100})
5.排序函数
其一为值排序(sort_values),其二为索引排序(sort_index)
利用set_index方法把年级和姓名两列作为索引
df_demo = df[['Grade', 'Name', 'Height', 'Weight']].set_index(['Grade','Name'])
df_demo.head(3)
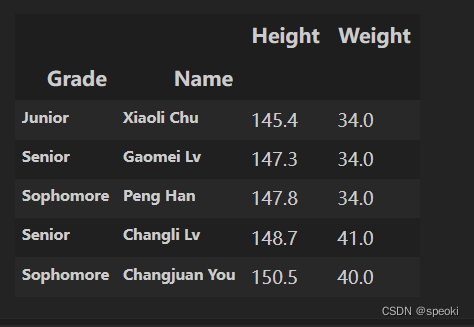
#对身高进行排序,默认参数ascending=True为升序:
df_demo.sort_values('Height').head()
df_demo.sort_values('Height', ascending=False).head()
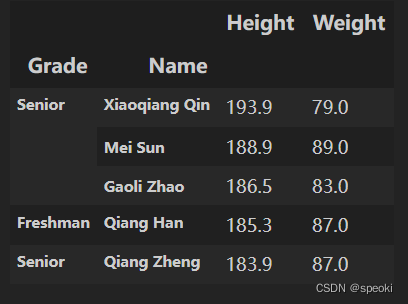
在排序中,经常遇到多列排序的问题,比如在体重相同的情况下,对身高进行排序,并且保持身高降序排列,体重升序排列:
df_demo.sort_values(['Weight','Height'],ascending=[True,False]).head()
索引排序的用法和值排序完全一致,只不过元素的值在索引中,此时需要指定索引层的名字或者层号,用参数level表示。
另外,需要注意的是字符串的排列顺序由字母顺序决定。
df_demo.sort_index(level=['Grade','Name'],ascending=[True,False]).head()
6.apply 方法
apply方法常用于DataFrame的行迭代或者列迭代
apply的参数往往是一个以序列为输入的函数
df_demo = df[['Height', 'Weight']]
def my_mean(x):
res = x.mean()
return res
df_demo.apply(my_mean)
=>
df_demo.apply(lambda x:x.mean())
=>
df_demo.apply(lambda x:x.mean(), axis=1).head()
mad函数返回的是一个序列中偏离该序列均值的绝对值大小的均值
df_demo.apply(lambda x:(x-x.mean()).abs().mean())
=>
df_demo.mad()
四、窗口对象
pandas中有3类窗口,分别是滑动窗口rolling、扩张窗口expanding以及指数加权窗口ewm
1. 滑窗对象
要使用滑窗函数,就必须先要对一个序列使用.rolling得到滑窗对象,其最重要的参数为窗口大小window。
roller使用的函数
s = pd.Series([1,2,3,4,5])
roller = s.rolling(window = 3)
roller. Mean()
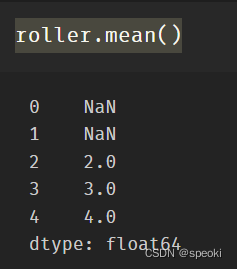
roller.sum()
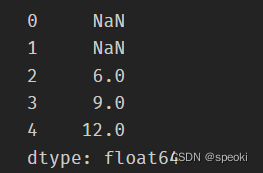
滑动相关系数或滑动协方差
roller.cov(s2)
roller.corr(s2)
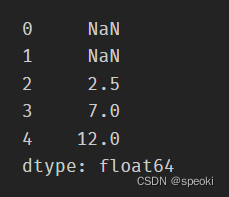
支持使用apply传入自定义函数,其传入值是对应窗口的Series
roller.apply(lambda x:x.mean())
series使用的函数
shift, diff, pct_change是一组类滑窗函数,它们的公共参数为periods=n,默认为1,
分别表示取向前第n个元素的值、与向前第n个元素做差(与Numpy中不同,后者表示n阶差分)、
与向前第n个元素相比计算增长率。这里的n可以为负,表示反方向的类似操作。
s = pd.Series([1,3,6,10,15])
s.shift(2)
它们的功能可以用窗口大小为n+1的rolling方法等价代替:
s.rolling(3).apply(lambda x:list(x)[0]) # s.shift(2)
s.rolling(4).apply(lambda x:list(x)[-1]-list(x)[0]) # s.diff(3)
def my_pct(x):
L = list(x)
return L[-1]/L[0]-1
s.rolling(2).apply(my_pct) # s.pct_change()
练习2
rolling对象的默认窗口方向都是向前的,某些情况下用户需要向后的窗口,
例如对1,2,3设定向后窗口为2的sum操作,结果为3,5,NaN,此时应该如何实现向后的滑窗操作?
sd = pd.Series([1, 2, 3])
sd + sd[::-1].shift(1)
2. 扩张窗口
扩张窗口又称累计窗口,可以理解为一个动态长度的窗口,其窗口的大小就是从序列开始处到具体操作的对应位置,其使用的聚合函数会作用于这些逐步扩张的窗口上。具体地说,设序列为a1, a2, a3, a4,则其每个位置对应的窗口即[a1]、[a1, a2]、[a1, a2, a3]、[a1, a2, a3, a4]。
s = pd.Series([1, 3, 6, 10])
s.expanding().mean()
cummax, cumsum, cumprod函数是典型的类扩张窗口函数,请使用expanding对象依次实现它们
s.expanding().sum() # cummax()
s.expanding().max() # cumsum()
s.expanding().apply(lambda x:np.prod(x))# cumprod
五、练习
Ex1:口袋妖怪数据集
现有一份口袋妖怪的数据集,下面进行一些背景说明:
#代表全国图鉴编号,不同行存在相同数字则表示为该妖怪的不同状态
妖怪具有单属性和双属性两种,对于单属性的妖怪,Type 2为缺失值
Total, HP, Attack, Defense, Sp. Atk, Sp. Def, Speed分别代表种族值、体力、物攻、防御、特攻、特防、速度,其中种族值为后6项之和
-
对
HP, Attack, Defense, Sp. Atk, Sp. Def, Speed进行加总,验证是否为Total值。 -
对于
#重复的妖怪只保留第一条记录,解决以下问题:
- 求第一属性的种类数量和前三多数量对应的种类
- 求第一属性和第二属性的组合种类
- 求尚未出现过的属性组合
- 按照下述要求,构造
Series:
- 取出物攻,超过120的替换为
high,不足50的替换为low,否则设为mid - 取出第一属性,分别用
replace和apply替换所有字母为大写 - 求每个妖怪六项能力的离差,即所有能力中偏离中位数最大的值,添加到
df并从大到小排序
Ex2:指数加权窗口
- 作为扩张窗口的
ewm窗口
在扩张窗口中,用户可以使用各类函数进行历史的累计指标统计,但这些内置的统计函数往往把窗口中的所有元素赋予了同样的权重。事实上,可以给出不同的权重来赋给窗口中的元素,指数加权窗口就是这样一种特殊的扩张窗口。
其中,最重要的参数是alpha,它决定了默认情况下的窗口权重为
w
i
=
(
1
−
α
)
i
,
i
∈
{
0
,
1
,
.
.
.
,
t
}
w_i=(1−\alpha)^i,i\in\{0,1,...,t\}
wi=(1−α)i,i∈{0,1,...,t},其中
i
=
t
i=t
i=t表示当前元素,
i
=
0
i=0
i=0表示序列的第一个元素。
从权重公式可以看出,离开当前值越远则权重越小,若记原序列为 x x x,更新后的当前元素为 y t y_t yt,此时通过加权公式归一化后可知:
y t = ∑ i = 0 t w i x t − i ∑ i = 0 t w i = x t + ( 1 − α ) x t − 1 + ( 1 − α ) 2 x t − 2 + . . . + ( 1 − α ) t x 0 1 + ( 1 − α ) + ( 1 − α ) 2 + . . . + ( 1 − α ) t \begin{split}y_t &=\frac{\sum_{i=0}^{t} w_i x_{t-i}}{\sum_{i=0}^{t} w_i} \\&=\frac{x_t + (1 - \alpha)x_{t-1} + (1 - \alpha)^2 x_{t-2} + ...+ (1 - \alpha)^{t} x_{0}}{1 + (1 - \alpha) + (1 - \alpha)^2 + ...+ (1 - \alpha)^{t}}\\\end{split} yt=∑i=0twi∑i=0twixt−i=1+(1−α)+(1−α)2+...+(1−α)txt+(1−α)xt−1+(1−α)2xt−2+...+(1−α)tx0
对于Series而言,可以用ewm对象如下计算指数平滑后的序列:
np.random.seed(0)
s = pd.Series(np.random.randint(-1,2,30).cumsum())
s.head()
s.ewm(alpha=0.2).mean().head()
请用expanding窗口实现。
- 作为滑动窗口的
ewm窗口
从第1问中可以看到,ewm作为一种扩张窗口的特例,只能从序列的第一个元素开始加权。现在希望给定一个限制窗口n,只对包含自身的最近的n个元素作为窗口进行滑动加权平滑。请根据滑窗函数,给出新的wi与yt的更新公式,并通过rolling窗口实现这一功能。
教程来源:http://joyfulpandas.datawhale.club/Content/ch2.html

7-pandas分组计算
#encoding:utf8
import numpy as np
import pandas as pd
''''''
分组计算:
拆分:根据什么进行分组
应用:每个分组进行怎样的计算
合并:每个分组的计算结果合并起来
''''''
df = pd.DataFrame(
{
''key1'':[''a'',''a'',''b'',''b'',''a''],
''key2'':[''one'',''two'',''one'',''two'',''one''],
''data1'':np.random.randint(1,10,5),
''data2'':np.random.randint(1,10,5),
}
)
print(df)
''''''
data1 data2 key1 key2
0 3 9 a one
1 3 5 a two
2 7 3 b one
3 1 1 b two
4 2 1 a one
''''''
print(df[''data1''])
''''''
0 7
1 7
2 4
3 1
4 8
''''''
#计算data1列按照key1字段聚合求平均值
print(df[''data1''].groupby(df[''key1'']).mean())
''''''
data1 data2 key1 key2
0 1 3 a one
1 4 4 a two
2 3 9 b one
3 7 3 b two
4 1 3 a one
key1
a 2
b 5
''''''
#除了可以在数据内按照聚合,也可以自定义聚合
#这里列表中元素表示data1列的元素位置聚合
#data1列下的第1,3,4个元素聚合,第2,5个元素聚合,然后求平均值
key = [1,2,1,1,2]
print(df)
print(df[''data1''].groupby(key).mean())
''''''
data1 data2 key1 key2
0 9 9 a one
1 5 2 a two
2 4 8 b one
3 2 4 b two
4 1 3 a one
1 5
2 3
''''''
#分组也可以是多级列表
#在groupby中按照元素索引顺序进行排组的依据先后
print(df)
print(df[''data1''].groupby([df[''key1''],df[''key2'']]).sum())
print(df[''data1''].groupby([df[''key2''],df[''key1'']]).sum())
''''''
data1 data2 key1 key2
0 9 8 a one
1 3 4 a two
2 7 8 b one
3 4 1 b two
4 3 7 a one
a[9,3,3]---->one[9,3]....
key1 key2
a one 12
two 3
b one 7
two 4
one[9,7,3]---->a[9,3]....
key2 key1
one a 12
b 7
two a 3
b 4
''''''
#查看分组的个数
print(df[''data1''].groupby([df[''key1''],df[''key2'']]).size())
''''''
key1 key2
a one 2
two 1
b one 1
two 1
''''''
#按照key1进行分组
#生成的是一个DataFrame
print(df.groupby(''key1'').sum())
''''''
data1 data2
key1
a 16 12
b 10 6
''''''
#对分组之后可进行索引的选取
print(df.groupby(''key1'').sum()[''data1''])
''''''
key1
a 14
b 15
''''''
#当然也可以进行多级分组,然后转换为DataFrame
mean = df.groupby([''key1'',''key2'']).sum()
print(mean)
print(mean.unstack())
''''''
data1 data2
key1 key2
a one 17 6
two 1 3
b one 7 3
two 1 6
data1 data2
key2 one two one two
key1
a 17 1 6 3
b 7 1 3 6
''''''
#groupby支持迭代
for name,group in df.groupby(''key1''):
print(name)
print(group)
''''''
a
data1 data2 key1 key2
0 9 8 a one
1 8 8 a two
4 7 7 a one
b
data1 data2 key1 key2
2 6 1 b one
3 5 8 b two
''''''
#也可以对groupby转换为字典
print(dict(list(df.groupby(''key1''))))
print(dict(list(df.groupby(''key1'')))[''a''])
print(dict(list(df.groupby(''key1'')))[''b''])
''''''
{''a'': data1 data2 key1 key2
0 9 4 a one
1 4 3 a two
4 5 6 a one, ''b'': data1 data2 key1 key2
2 3 7 b one
3 2 8 b two}
data1 data2 key1 key2
0 9 4 a one
1 4 3 a two
4 5 6 a one
data1 data2 key1 key2
2 3 7 b one
3 2 8 b two
''''''
#按照列类型进行分组
print(df.groupby(df.dtypes,axis=1).sum())
''''''
0 4 aone
1 15 atwo
2 10 bone
3 8 btwo
4 18 aone
''''''
#以上都是按照列表进行分组
#下面用其他分组形式来进行分组
#通过字典进行分组
df = pd.DataFrame(
np.random.randint(1,10,(5,5)),
columns=list(''abcde''),
index=[''Alice'',''Bob'',''Candy'',''Dark'',''Emily'']
)
#看一下处理非数字
df.ix[1,1:3] = np.NaN
print(df)
''''''
a b c d e
Alice 3 3.0 7.0 7 9
Bob 4 NaN NaN 3 4
Candy 9 5.0 1.0 4 1
Dark 6 3.0 9.0 9 9
Emily 8 4.0 2.0 3 6
''''''
mapping = {
''a'':''red'',
''b'':''red'',
''c'':''blue'',
''d'':''orange'',
''e'':''blue''
}
grouped = df.groupby(mapping,axis=1)
print(grouped.sum())
''''''
a b c d e
Alice 4 5.0 2.0 2 2
Bob 3 NaN NaN 8 1
Candy 6 7.0 6.0 9 7
Dark 7 8.0 1.0 4 3
Emily 8 6.0 8.0 3 3
blue orange red
Alice 4.0 2.0 9.0
Bob 1.0 8.0 3.0
Candy 13.0 9.0 13.0
Dark 4.0 4.0 15.0
Emily 11.0 3.0 14.0
可以看对Nan和数字分组计算是按照Nan=0来处理的
''''''
print(grouped.size())
print(grouped.count())
''''''
blue 2
orange 1
red 2
blue orange red
Alice 2 1 2
Bob 1 1 1
Candy 2 1 2
Dark 2 1 2
Emily 2 1 2
Nan是没有统计个数的
''''''
#通过函数进行分组
df = pd.DataFrame(
np.random.randint(1,10,(5,5)),
columns=list(''abcde''),
index=[''Alice'',''Bob'',''Candy'',''Dark'',''Emily'']
)
#按照行索引
def _group_by(idx):
print(idx)
return idx
print(df.groupby(_group_by).size())
print(df.groupby(_group_by).count())
''''''
Alice
Bob
Candy
Dark
Emily
a b c d e
Alice 1 1 1 1 1
Bob 1 1 1 1 1
Candy 1 1 1 1 1
Dark 1 1 1 1 1
Emily 1 1 1 1 1
按照行来进行分组的
''''''
#按照行索引长度
def _group_by2(idx):
print(idx)
return len(idx)
print(df.groupby(_group_by2).size())
print(df.groupby(_group_by2).count())
''''''
Alice
Bob
Candy
Dark
Emily
a b c d e
3 1 1 1 1 1
4 1 1 1 1 1
5 3 3 3 3 3
''''''
#通过索引级别进行分组
columns = pd.MultiIndex.from_arrays(
[
[''China'',''USA'',''China'',''USA'',''China''],
[''A'',''A'',''B'',''C'',''B'']
],
names=[''country'',''index'']
)
df = pd.DataFrame(np.random.randint(1,10,(5,5)),columns=columns)
print(df)
''''''
country China USA China USA China
index A A B C B
0 9 5 4 5 2
1 8 5 4 6 9
2 2 7 3 1 3
3 2 1 6 5 5
4 5 3 6 9 4
''''''
print(df.groupby(level=''country'',axis=1).sum())
''''''
country China USA
0 17 12
1 19 12
2 19 8
3 21 13
4 18 9
''''''
print(df.groupby(level=''index'',axis=1).sum())
''''''
index A B C
0 7 7 6
1 11 12 3
2 12 11 9
3 14 11 4
4 17 15 8
''''''

Matlab IQR准则剔除异常值
时间序列分析中,要先进行数据的预处理工作,也即异常值的剔除和插补。
先介绍异常值的剔除。异常值的剔除方法有很多种,在此实现很多论文中提到过的所谓的IQR准则。
理论基础:

(摘自《区域CORS站坐标时间序列特征分析》硕士论文)
代码实现:
1 N1=N(1:337);
2 Q1=prctile(N1,25); 3 Q2=prctile(N1,75);
4 R=iqr(N1);
5 num = find(N<Q1-1.5*R | N>Q2+1.5*R)
6
7 %1、根据多篇文献的经验,窗长选取为1年(在这里选了从1到337个数
8 %据),N为6年的数据
9 %2、Q1为上四分位数
10 %3、Q2为下四分位数
11 %4、R为四分位数的极差,其实R也等于Q2-Q1
12 %5、求取异常值,num为包含异常值的向量
13 %6、从以上代码基础上剔除异常值,比如,num = [1 2 3],则
14 %输入代码:
15 N1(N1 == 1 | N1 == 2 | N1 ==3) = [];
16 % 解释:逻辑与(或)|和||表达意思是一样的,只不过|应用范围更广一些
17 % 以上代码表示把N1中的值为num的那些元素剔除掉。--------------------------------------------------------------------补充---------------------------------------------------------------
注意:上述步骤有些问题,摘自硕士论文的最后两句抹去,应该是对最后的噪声进行异常值的去除而不是对原始时间序列。
IQR是在时间序列为标准正态分布的前提下,是以标准正态分布为基础的。
所以以上对于gps原始时间序列,如果没有进行公式拟合、去趋势化之后是不适用于IQR准则的。
在趋势化之后得到的噪声才适用于本准则。

matlab 编程代写使用 hampel 滤波,去除异常值
原文链接:http://tecdat.cn/?p=7181
此示例显示了 Hampel 用于检测和删除异常值的过程的 实现。
产生一个包含 24 个样本的随机信号 x。 重置随机数生成器以获得可重复的结果。
rng default
lx = 24;
x = randn(1,lx);围绕 x 的每个元素生成观察窗口。 在样本的任一边取 k = 2 个邻居。 产生的移动窗口的长度为 2×2 + 1 = 5 个样本。
k = 2;
iLo = (1:lx)-k;
iHi = (1:lx)+k;截断窗口,以便函数在到达信号边缘时计算较小段的中值。
iLo(iLo<1) = 1;
iHi(iHi>lx) = lx;记录每个周围窗口的中位数。 找到每个元素相对于窗口中位数的绝对偏差的中位数。
for j = 1:lx
w = x(iLo(j):iHi(j));
medj = median(w);
mmed(j) = medj;
mmad(j) = median(abs(w-medj));
end缩放中位数绝对偏差
1G2erf−1(1/2)≈1.4826
以获得正态分布标准偏差的估计值。
sd = mmad/(erfinv(1/2)*sqrt(2));
查找与中位数相差超过nd = 2个标准偏差的样本。 将这些离群值替换为其周围窗口的中间值。 这是Hampel算法的本质。
yu = x;
yu(ki) = mmed(ki);使用 hampel 计算滤波后的信号并注释异常值。 覆盖在此示例中计算的过滤值。
plot(yu,''o'',''HandleVisibility'',''off'')
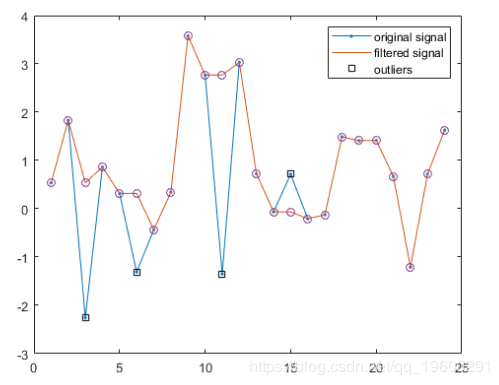
如果您有任何疑问,请在下面发表评论。
大数据部落 - 中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() QQ:3025393450
QQ:3025393450
QQ 交流群:186388004
【服务场景】
科研项目;公司项目外包;线上线下一对一培训;数据爬虫采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询

欢迎选修我们的 R 语言数据分析挖掘必知必会课程!


关于Pandas分组删除异常值和pandas 删除异常值的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于40期《Pandas数据处理与分析》|pandas基础笔记2|pandas 基础|joyfulPandas、7-pandas分组计算、Matlab IQR准则剔除异常值、matlab 编程代写使用 hampel 滤波,去除异常值等相关知识的信息别忘了在本站进行查找喔。
本文标签:




