本文的目的是介绍Compass学习笔记的详细情况,特别关注compasslearning的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解Compass学习笔记的机会,
本文的目的是介绍Compass学习笔记的详细情况,特别关注compass learning的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解Compass学习笔记的机会,同时也不会遗漏关于Android Architecture Components学习笔记、AngularJs学习笔记--html compiler、AngularJs学习笔记--IE Compatibility 兼容老版本IE、Class与ID区别 margin和padding区别 CSS学习笔记的知识。
本文目录一览:- Compass学习笔记(compass learning)
- Android Architecture Components学习笔记
- AngularJs学习笔记--html compiler
- AngularJs学习笔记--IE Compatibility 兼容老版本IE
- Class与ID区别 margin和padding区别 CSS学习笔记
")
Compass学习笔记(compass learning)
Compass概念:
1:Compass相当于hb的SessionFactory
2:CompassSession相当于hb的Session
3:CompassTransaction相当于hb的transaction。
Compass 也是采用CompassConfiguration(装载配置和映射文件)进行创建的。创建Compass时将会链接已经存在的索引或者创建一个新的索引。当Compass创建完后,就可以用compass得到compassSession。compassSession主要是起管理搜索引擎的数据。和 hb的SessionFactory一样,compass通常在系统启动时创建,在所有compassSession创建时使用。
当使用CompassSession查询数据时,将会返回CompassHits接口的实例。compassHits可以得到scores,resources和mapped objects.
Compass也提供了CompassTemplate和CompassCallback类处理会话和事务的处理。CompassTemplate template = new CompassTemplate(compass);
为了简化CompassConfiguration的建立,compass提供了CompassConfigurationFactory类来建立CompassConfiguration
CompassConfiguration conf =CompassConfigurationFactory.newConfiguration();
除了通过xml文件设置外,可以通过CompassConfiguration.addXXX方法更改设置,也可以通过CompassSetting来设置。compassSetting和java 的Properties相似。也可以通过CompassEnvironment和LuceneEnvironment类来设置。
Compass中必须设置的项包括:compass.engine.connection。
一个重要的设置方面是组设置。如下面设置一个test的转换器:
org.compass.converter.test.type=eg.TestConverter
org.compass.converter.test.param1=value1
org.compass.converter.test.param2=value2
所有的compass的操作性设置都可以定义在一个配置文件中,文件的名字默认为:compass.cfg.xml,如果取名不一样这在初始化 CompassConfiguration时,使用CompassConfiguration.config(fileName)。
因为索引是事务性的。所以在进行操作的过程中,就存在锁的概念。可以设置锁文件的位置,默认为java.io.tmp,<transaction lockDir="/shared/index-lock" />
别名、资源和属性的概念:
资源(Resource):资源表示属性的集合,相当于虚拟文档。一个资源通常和一个别名联系在一起,几个资源可以属于同一个别名。别名担当资源和映射定义的联系角色。属性是指一个键值对。
在OSEM/XSEM中,容易忽视的是资源在何处被使用,因为处理内容都被转换成应用程序的模型或者是xml的结构数据。资源很少被使用。
通过资源和属性,可以采用统一的方式访问相同语义的模型。比如应用程序中有两个模型:学生和教师。我们将学生和教师的名字都设置成相同语义的元数据:name(资源属性名),这样将会允许我们所有的name搜索显示结果在资源层次上。
分析器:该组件主要是预处理输入文本。用于搜索和索引的文本分析上。要求搜索和索引使用相同的分析器。
Compass内置两个分析器名称:default和search。缺省分析器用户没有其它分析器配置时使用。search用于搜索查询的分析。
配置定制的分析器的参数可以通过Setting方式置入:
<analyzer name="deault" type="CustomAnalyzer" analyzer>
<setting name="threshold">5</setting>
</analyzer>
分析过滤器:
分析过滤器能够被不同的分析器穿插使用。配置如下:
<analyzer name="deafult" type="Standard" filters="test1, test2" />
<analyzerFilter name="test1" type="eg.AnalyzerTokenFilterProvider1">
<setting name="param1" value="value1" />
</analyzerFilter>
<analyzerFilter name="test2" type="eg.AnalyzerTokenFilterProvider2">
<setting name="paramX" value="valueY" />
</analyzerFilter>
同义处理:同义处理分析过滤器:返回给定词的同义词
<analyzer name="deafult" type="Standard" filters="synonymFilter" />
<analyzerFilter name="synonymFilter" type="synonym">
<setting name="lookup" value="eg.MySynonymLookupProvider" />
</analyzerFilter>
查询分析器:
<queryParser name="test" type="eg.MyQueryParser">
<setting name="param1" value="value1" />
</queryParser>
索引文件的结构:
compass的子索引相当于lucene的一个索引。当compound设置为true时,lucene次采用一个segments文件存储所有索引内容。子索引对事务型操作尤为重要。
compass支持read_committed和serializable、batch_insert级别的事务
compass事务锁用在自索引级别上,这意味着脏操作只发生在各自的子索引上。
compass事务在脏操作(创建,保存,删除)时要求一个锁。搜索时应该只用read only事务。锁超时一般设置为10秒。
<transaction lockTimeout="15" lockPollInterval="200" />
事务隔离:
1:read_committed:当开始该事务时,是不需要锁的。因此速度会快。
2:serializable:和上面一样。只是当事务开始时,对所有的自索引有一个锁。性能降低。
3:batch_insert:使用了lucene提供的快速的批量索引的功能。这个事务操作只支持create操作。如果已经有同名的别名和ids的资源已经存在,那么将会在一个索引中出现两个资源。这种事务是不能回滚的。
FS Transaction Log:存储许多事务数据到文件系统中。
<transaction isolation="read_committed">
<readCommittedSettings>
<fsTransLog path="/tmp" readBufferSize="32" writeBufferSize="4098" />
</readCommittedSettings>
</transaction>
常量子索引hash:
影射别名到子索引的最简单办法是将某个别名的所有的可搜索内容索引到相同的子索引里面。如:
<compass-core-mapping>
<[mapping] alias="test-alias" sub-index="test-subindex">
<!-- ... -->
</[mapping]>
</compass-core-mapping>
test-alias将会影射所有的实例到test-subindex子索引中。如果sub-index没有定义,则将缺省为alias。
Modulo Sub Index Hashing:允许将一个别名代表的实例索引到不同的子索引中。根据给定的大小对索引进行分割。文件名是给定的前缀+“_"+数字。
<compass-core-mapping>
<[mapping] alias="A">
<sub-index-hash type="org.compass.core.engine.subindex.ModuloSubIndexHash">
<setting name="prefix" value="test" />
<setting name="size" value="2" />
</sub-index-hash>
<!-- ... -->
</[mapping]>
</compass-core-mapping>
会产生[test_0]和[test_1]两个子索引文件。
Custom Sub Index Hashing:
ConstantSubIndexHash 和 ModuloSubIndexHash都实现了compass的SubIndexHash接口。定制子索引hash必须实现getSubIndexes和 mapSubIndex(String alias,Property[] ids)两个方法。
Optimizers:优化器,每个脏操作提交成功都会在各自的子索引中产生另一个segment,子索引中的segment越多,搜索操作就越慢,因此保持索引优化,控制segment的数量很重要。要做的就是合并小segment到大的segment 。
索引优化器在子索引级别执行。在优化的过程中,优化器将锁定子索引,以便于脏操作。
调度优化:compass的每一个优化器都能包装为调度方式执行。
<optimizer scheduleInterval="90" schedule="true" />
Aggressive Optimizer:通过设置segments的大小,当达到指定的大小时,将所有的segement合并到一个segment。这样搜索的效率最高。
Adaptive Optimizer:和Aggressive Optimizer不同的是,该优化器只合并新的小segment。
Null Optimizer:不做任何优化。当做batch_insert事务时,离线创建索引或已经全部优化索引,一般使用它。
直接访问Lucene:compass提供了LuceneHelper类,该类可以直接访问lucene的api。
索引的对象遵循以下原则:
实现默认的无参数构造器,不要是public的。便于compass采用Constants.newInstance()
提供identifier,
提供访问和设置方法
建议重载equals和hashcode方法。建议以业务主键为参考。
alias:每一个影射定义都注册了一个别名。这个别名用来联系类的osem定义和类本身。
Root:在compass中有两类可搜索的类:root searchable和non-root searchable 类。root searchable类最好定义作为hits结果返回的类。non-root searchable类不要求定义id影射。
子索引:默认情况下,每一个root searchable类都有自己的子索引,名称缺省为alias。子索引的名称也可以自由控制。允许几个root searchable类索引到相同的子索引中。或者用子索引hash功能。
searchable id不要求定义搜索的元数据,如果没有定义,compass自动创建内部的元数据id。如果searchable id不需要被搜索,那么需要为它定义一个可搜索元数据。注意下面的元数据定义方式:
@Searchable
public class Author {
@SearchableId(name = "id")
private Long id;
// ...
}
@Searchable
public class Author {
@SearchableId
@SearchableMetaData(name = "id")
private Long id;
//
Searchable Constant:允许对一个类定义一系列的的常量数据。对于添加静态元数据是非常有用的。
<constant>
<meta-data>type</meta-data>
<meta-data-value>person</meta-data-value>
<meta-data-value>author</meta-data-value>
</constant>
Searchable Dynamic Meta Data:允许将表达式的结果保存到搜索引擎中。该影射不能影射任何类属性。动态元数据的值是根据动态转换器计算表达式得到的。compass内建了比如 el,jexl,velocity,ognl,groovy等转换器。当定义表达式后。root 类被注册为data key下的值。
<dynamic-meta-data name="test" converter="jexl">
data.value + data.value2
</dynamic-meta-data>
Searchable Reference:映射root类和其它类之间的关系。在marshals的过程中,只marshal参考对象的id。但是在unmarshal过程中根据id装载参考的对象。
compass在参考对象上不执行任何级联操作,也不提供延迟加载。
<class name="A" alias="a">
<id name="id" />
OSEM - Object/Search Engine Mapping
Compass - Java Search Engine 40
<reference name="b" />
<!-- ... -->
</class>
<class name="B" alias="b">
<id name="id" />
<!-- ... -->
</class>
Searchable Component:嵌入一个可搜索类到本身的搜索类中。组件参考搜索类能够设置为 Root。为Root的组件一般都是具有id属性。比如人员和姓名组件(non-root),人员和帐户(root)。
<class name="A" alias="a">
<id name="id" />
<component name="b" />
<!-- ... -->
</class>
<class name="B" alias="b" root="false">
<!-- ... -->
</class>
继承处理:
<class name="A" alias="a">
<id name="id" />
<property name="aValue">
<meta-data>aValue</meta-data>
</property>
</class>
<class name="B" alias="b" extends="a">
<property name="bValue">
<meta-data>aValue</meta-data>
</property>
</class>
Root 类有自己的索引,而依赖Root类的非Root类不需要索引。
Class mapping能够继承其它class mapping(可以超过一个)。也能够继承contract mapping。
contract:相当于java语言中的接口。如果有几个相同的类具有相似的属性。就可以定义一个contract。然后在子类中extend该contract。
通用元数据提供了将元数据名称和别名定义从osem文件提取到外面的方式。当你的应用程序有大量的域模型时尤其有用。另外一个优势就是添加额外的信息倒元数据中,不如描述。也能制定元数据定义的格式,这样就不用在osem 文件中定义了 。
通过集中话元数据,其它工具也能更好地利用这些信息。
OSEM文件引用通用元数据的方式是采用${}.
query syntax:
jack :缺省的查询域中包括jack字段。
jack london:缺省的查询域中包括 jack 或 london, 或者2者都有。
+jack +london: 缺省的查询域中必须包括jack和london。
name:jack:name字段中包括jack。
name:jack -city:london :name字段中包括jack但是city字段中不包括london。
name:"jack london" :name字段中包括jack london短语。
name:"jack london"~5 :name字段包括至少5次jack and london短语
jack* 包含以jack开头的词条。
jack~ 包括以jack结尾的词条。
birthday:[1870/01/01 TO 1920/01/01] birthday从1870-01-01到1920-01-01。
CompassHits, CompassDetachedHits & CompassHitsOperations:
compassHits:所有的搜索结果都是通过该接口访问。只能用在事务上下文中。如果脱离上下文,则需要detached。compassHits和compassDetachedHits都共享相同的操作接口:compassHitsOperation。
getLength() or length() :得到搜索资源的长度
score(n) 第n个搜索资源的分值。
resource(n) 第n个搜索资源
data(n) 第n个对象实例。
CompassQuery and CompassQueryBuilder:
CompassQueryBuilder提供了程序创建compassQuery的功能。compassQuery能够用来添加排序和执行查询。
CompassHits hits = session.createQueryBuilder()
.queryString("+name:jack +familyName:london")
.setAnalyzer("an1") // use a different analyzer
.toQuery()
.addSort("familyName", CompassQuery.SortPropertyType.STRING)
.addSort("birthdate", CompassQuery.SortPropertyType.INT)
.hits();
CompassQueryBuilder queryBuilder = session.createQueryBuilder();
CompassHits hits = queryBuilder.bool()
.addMust( queryBuilder.term("name", "jack") )
.addMustNot( queryBuilder.term("familyName", "london") )
.toQuery()
.addSort("familyName", CompassQuery.SortPropertyType.STRING)
.addSort("birthdate", CompassQuery.SortPropertyType.INT)
.hits();
注意排序的属性必须是un_tokenized。
OSEM映射文件:
<class name="eg.A" alias="a">
<id name="id" />
<property name="familyName">
<meta-data>family-name</meta-data>
</property>
<property name="date">
<meta-data converter-param="YYYYMMDD">date-sem</meta-data>
</property>
Working with objects
Compass - Java Search Engine 78
</class>
查询方式:采用compassQueryBuilder,许多查询可以直接工作在mapping的层次上。
CompassQueryBuilder queryBuilder = session.createQueryBuilder();
CompassHits hits = queryBuilder.term("a.familyName.family-name", "london").hits();
// 采用类属性的元数据id, 在上面的例子中将采用第一个元数据.
CompassHits hits = queryBuilder.term("a.familyName", "london").hits();
//查询编辑器将会采用相应的转化器转换数据。
CompassHits hits = queryBuilder.term("a.date.date-sem", new Date()).hits();
CompassHits hits = queryBuilder.bool()
.addMust( queryBuilder.alias("a") )
.addMust( queryBuilder.term("a.familyName", "london") )
.toQuery().hits();
CompassHighlighter:提供高亮度匹配搜索的文字字段。
CompassHits hits = session.find("london");
String fragment = hits.highlighter(0).fragment("description");
高亮度只能用于CompassHits,只能用在事务上下文中。
在detachedHits中使用高亮度:
CompassHits hits = session.find("london");
//在事务上下文中处理高亮度。
for (int i = 0.; i < 10; i++) {
hits.highlighter(i).fragment("description"); // this will cache the highlighted fragment
}
CompassHit[] detachedHits = hits.detach(0, 10).getHits();
// outside of a transaction (maybe in a view technology)
for (int i = 0; i < detachedHits.length; i++) {
// this will return the first fragment
detachedHits[i].getHighlightedText().getHighlightedText();
// this will return the description fragment, note that the implementation
// implements the Map interface, which allows it to be used simply in JSTL env and others
detachedHits[i].getHighlightedText().getHighlightedText("description");
}
GPS通过2个概念提供了整合不同的可索引的数据源:CompassGps和CompassGpsDevice。Device可以结合任何类型的可索引数据来源,它提供索引数据、搜索数据、敏感数据变化的能力。 GPS建立在Compass基础之上。利用Compass的特征,如:事务、OSEM以及 API等。
CompassGps是GPS的主要接口,它拥有一系列的CompassGpsDevices,并且管理他们的生命周期。
Compass提供了两个Gps的实现:
SingleCompassGps:拥有一个compass实例。这个compass实例用来做索引和镜像操作。
DualCompassGps:拥有两个Compass实例。indexCompass和mirrorCompass。主要处理两个事务级别。indexCompass一般采用 batch_insert隔离级别,而mirrorCompass采用read_committed事务级别。
hibernate Gps Device
hb3新的基于时间的机制提供了实时数据改变的镜像。数据的传送顺序为:Database -- Hibernate -- Objects -- Compass::Gps --Compass::Core (Search Engine).
在hb3中,程序配置:
Compass compass = ... // set compass instance
CompassGps gps = new SingleCompassGps(compass);
CompassGpsDevice hibernateDevice =
new Hibernate3GpsDevice("hibernate", sessionFactory);
gps.addDevice(hibernateDevice);
.... // configure other devices
gps.start();
hibernate device提供了一个fetchCount参数,这个参数控制索引一个类的分页进程。
实时数据镜像:在hb3中是基于新的时间机制。数据改变将会反射给compass index。配置时要注意的是系统和compass必须使用相同的SessionFactory。如果使用hb3和spring,请使用 SpringHibernate3GpsDevice。
Compass与spring结合:
1:支持compass级别的工厂bean。采用Spring ioc的配置选项。
2:提供Compass DAO级别的支持。采用事务整合和DAO支持类。
3:扩展GPS Hiberante3 device。
4:提供OJB的整合支持。
5:提供Spring MVC的搜索控制器和索引控制器。
spring中配置compass bean:
<bean id="compass"
>
<property name="resourceLocations">
<list>
<value>classpath:org/compass/spring/test/A.cpm.xml</value>
</list>
</property>
<property name="compassSettings">
<props>
<prop key="compass.engine.connection">
target/testindex
</prop>
<!-- This is the default transaction handling
(just explicitly setting it) -->
<prop key="compass.transaction.factory">
org.compass.core.transaction.LocalTransactionFactory
</prop>
</props>
</property>
</bean>
compass提供CompassDaoSupport类来执行Dao操作。
public class LibraryCompassDao extends CompassDaoSupport {
public int getNumberOfHits(final String query) {
Integer numberOfHits = (Integer)getCompassTemplate().execute(
new CompassCallback() {
public Object doInCompass(CompassSession session) {
CompassHits hits = session.find(query);
return new Integer(hits.getLength());
}
}
);
}
return numberOfHits.intValue();
}
然后配置该DAO类使用的Compass实例:
<beans>
<bean id="libraryCompass">
<property name="compass">
<ref local="compass" />
</property>
</bean>
</beans>
SpringSyncTransaction:compass将同步spring本身的事务.
SpringHibernate3GpsDevice:对Hibernate3GpsDevice的扩展,能够处理spring带来的sessionFactory以便使用时间机制监听实时数据改变。

Android Architecture Components学习笔记
#前言
Android Architecture Components是谷歌在Google I/O 2017发布的。官方的描述:
https://developer.android.google.cn/jetpack/docs/guide#recommended_app_architecture
A new collection of libraries that help you design robust testable and maintainable apps.
全新的库集合,可帮助您设计稳健、可测试和易维护的应用。
转眼Android Architecture Components(下文简称AAC)的发布将近一年了,我们的项目也基本可以使用这套框架。
曾经被质问懂不懂瀑布或敏捷开发模式,从而指责我不断尝试新工具(我也不知道此命题从何而出)。其实我的经验告诉我,很多项目所有者或许根本不懂技术,作为项目管理者的基本职能就是要利用有效的工具(比如AAC)让项目更高效的去实现可见的功能。只要能够柔性的均衡客户需求与研发周期之间的矛盾,并且兼顾维护周期那就是一个好的项目。也就是“工欲善其事必先利其器”借助于好的工具来做出好的项目。
跟很多小伙伴聊到MVC、MVP或者MVVM等模式的问题,我觉得不需要纠结于这些,还是要看项目管理的目的。分层更多的是为了权衡项目未来规模及持有周期。如果你打算长期维护一个项目(从小开始越做越大),那么就应该用更多的时间考虑如何优雅的分层、分组件以适应持续迭代的需求。
一定要客观的选择,而不是习惯性的抵制新发布的东西。早在2005年微软就提出了MVVM模式,那又能怎么样呢,甚至很多开发人员或许并不了解这段历史~~通过仔细了解AAC其实不难发现很多理念其实不是新的,只是被官方优化并规范了,通过官方发布出来而已。这样的好处不言而喻:让更多的开发者交流的时候有了官方口径。
#基于AAC官方示例的学习笔记
看到这个框架感觉不错,下载了官方示例看看。里面比较新的内容是生命周期相关以及数据库解决方案,同时也包含了很多官方或官方推荐的框架。这套官方示例麻雀虽小五脏俱全,对我们现在的项目可说受益匪浅。于是就将学习过程结合官方示例做了个记录~~
可以下载github上的Android Architecture Components官方示例,整个这一系列文档都是围绕着其中两个使用Java开发的示例展开的:
BasicSample : 演示了使用sqlite数据库、Room保存数据以及viewmodels和LiveData的使用
GithubbrowserSample :比较完整的展示了AAC,包含了Dagger和Github API。运行这个示例需要Android Studio 3.0以上版本。
这两个示例主要演示了AAC,也包含了诸如DataBinding、Dagger、Mockito等。我是随着不断学习随机记录下来,所以这个系列的文章也会涉及到这些内容,难免错误也比较琐碎,不当之处望不吝指教。
#两个示例简述
##BasicSample
包含了一个Activity两个Fragment,分层也非常清晰。主要是演示了一个产品列表,以及产品详情。在产品详情Fragment里包含了评论列表。
这个示例是没有网络请求组件的,数据是通过DataGenerator.java生成并填充。
几个全局类
AppExecutors.java是一个全局执行池,通过对任务分组,避免互斥等待的情形。比如数据的获取可以通过磁盘读取而不用等待网络请求。这里声明了三个Executor,分别是:diskIO、NetworkIO、MainThread。
BasicApp.java是这个示例的Application。
DataRepository.java实现了Repository,是处理products、comments的仓库。
##GithubbrowserSample
代码及资源部分包含了20个文件夹72个文件。整个项目由一个Activity(MainActivity)三个Fragment(SearchFragment、RepoFragment、UserFragment)组成。MainActivity会先加载SearchFragment,通过录入的关键字在GitHub上搜索相关的库。
repo = repository 一般指Github上repository(代码仓库)的缩写
这个示例在BasicSample的基础上增加很多东西比如Binding、LiveData等高级用法,并且增加了Dagger、Mockito等。
就Binding与Dagger本身而言也是存在很多新内容的(起码我感觉是这样~~)。所以从零开始学习这个示例还是得费些周折的,如果是不太熟悉这些概念,建议多了解一下。
#这一堆的内容
《升级Android Studios3.1.1以及手动配置Gradle》
《AAC学习笔记——Binding(一)》
《AAC学习笔记——Binding(二)》
《AAC学习笔记——Binding(二)》
《AAC学习笔记——Binding(二)》
《AAC学习笔记——Dagger(一)》
《AAC学习笔记——Dagger(二)》
《AAC学习笔记——Dagger(三)》
《AAC学习笔记——Dagger(四)》
《AAC学习笔记——viewmodel(一)》
《AAC学习笔记——viewmodel(二)》
《AAC学习笔记——Lifecycle(一)》
《AAC学习笔记——Lifecycle(二)》
《AAC学习笔记——LiveData(一)》
《AAC学习笔记——LiveData(二)》
《AAC学习笔记——LiveData(三)》
《AAC学习笔记——Repository》
《AAC学习笔记——Room(一)》
《AAC学习笔记——Room(二)》
《AAC学习笔记——Espresso》
《AAC学习笔记——Mockito》

AngularJs学习笔记--html compiler
一、总括
Angular的HTML compiler允许开发者自定义新的HTML语法。compiler允许我们对任意HTML元素或属性,甚至是新的HTML标签、属性(如<beautiful girl=”cf”></beautiful >)附加行为。Angular将这些附加行为称为directives。
HTML有很多专门格式化静态文档的预定义HTML样式结构(可以告诉浏览器如何显示标记的内容)。假设某东东需要被居中,而我们不需要教浏览器如何去做(此处省略N字)。我们只需要简单地对需要居中的标签加入align=”center”即可。这就是声明式语言(declarative language)的牛X之处。
但是声明式语言也有它的局限性,即你不能告诉浏览器如何处理在预定义范围外的语法。例如,我们不能很简单地告诉浏览器如何让文本在浏览器的1/3处对齐。所以,我们正需要一个让浏览器与时俱进,学学新语法的途径。
Angular预先绑定了一些对构建应用有帮助的directives。我们也可以自己创建属于自己应用的独特的directives。这些directive扩展将成为我们自己的应用的“特定领域语言”(Domain Specific Language)。
这些编译将仅仅发生在浏览器端,无须服务端或者预编译步骤。
二、Compiler
Compiler作为Angular的一个服务(Service),负责遍历DOM结构,寻找属性。编译过程分成两个阶段:
1. 编译(Compile):遍历DOM节点树,收集所有directives。返回结果是一个链接函数(linking function)。
2. 链接(Link):将directives绑定到一个作用域(scope)中,创建一个实况视图(live view)。在scope中的任何改变,将会在视图中得到体现(更新视图);任何用户对模版的活动(改变),将会体现在scope model中(双向绑定)。这使得scope model能够反映正确的值。
一些directives,诸如ng-repeat,会为每一个在集合(collection)中的元素复制一次特定的元素(组合)。编译和链接两个阶段,使性能得以提升。因为克隆出来的模版(template)只需要编译一次,然后为每一个集合中的元素进行一次链接(类似模版缓存)。
三、Directive
Directive是一个行为,在编译过程中遇到特定的HTML结构时,它会被触发。Directives可以放置在元素的name、attribute、class甚至注释中。以下是几种引用ng-bind(一个内置directive)的方法:
<span ng-bind="exp"></span>
<span ></span>
<ng-bind></ng-bind>
<!-- directive: ng-bind exp -->Directive只是一个当编译器在DOM中遇到时会执行的一个函数(function)。directive API文档中有详细讲解如何创建一个directive。下面是一个样例,可以让一个元素跟你的鼠标玩躲猫猫……
<!DOCTYPE html>
<html ng-app="HideAnkSeek">
<head>
<meta charset="UTF-8">
<title>躲猫猫</title>
<style type="text/css">
.ng-cloak {
display: none;
}
</style>
</head>
<body>
<span wildcat>一碰我就跑~~来点我啊~~</span>
<script src="../angular-1.0.1.js" type="text/javascript"></script>
<script type="text/javascript">
angular.module("HideAnkSeek", []).directive("wildcat", function ($document) {
var maxLeft = 400,maxTop = 300;
var msg = ["我闪~~", "抓我呀~~~", "雅蠛蝶~~", "噢耶~~", "你真逊~!","就差那么一点点了!","继续吧~~总有一天我会累的"];
return function (scope, element, attr) {
element.css({
"position":"absolute",
"border":"1px solid green"
});
element.bind("mouseenter", function (event) {
element.css({
"left":parseInt(Math.random() * 10000 % maxLeft) + "px",
"top":parseInt(Math.random() * 10000 % maxTop) + "px"
}).text(msg[parseInt(Math.random() * 10000 % msg.length)]);
}).bind("click",function (event) {
element.text("噢My Lady Gaga。。。被你逮到了。。。");
element.unbind("mouseenter");
});
};
});
</script>
</body>
</html>在任意元素中添加“wildcat”这个属性,将会使该元素拥有新的行为。就这样,我们教会了浏览器如何处理会躲猫猫的元素(放心,你不是在某个房间,你不会挂的-_-!)。我们通过这一途径扩展了浏览器的“词汇量”。对于任意一个熟悉HTML规则的人,这算是一个比较自然的方式
四、理解视图(View)
外面有许多模版系统,它们通常都通过模版字符串与数据进行连接,生成最终的HTML字符串,并将结果通过innerHTML属性写入某元素里。
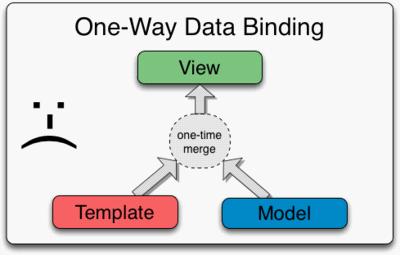
这意味着任何数据发生改变时,都需要重新将数据、模版合并成字符串,然后当作innerHTML写回对应元素中。这里存在一些问题:(这里直译实在没法懂..唯有YY)假设有这么一个场景,模版里包含输入框。用户对在输入框进行输入,模版同步更新。普通模版通过innerHTML、字符串与数据连接的方式更新视图,这样会打断用户的输入,体验不好。 Angular是与众不同的。Angular编译器(compiler)通过directives处理DOM,而不是通过处理字符串模版。处理结果是一个与scope model组合并生成实时模版的链接函数(linking function)。视图与scope model的绑定对我们来说是透明的。开发者无须为更新视图、model做任何动作。而且,因为没有使用innerHTML更新视图模版,所以用户输入不会被打断。此外,angular directives不仅可以绑定文本值,而且还可以是拥有行为的结构(behavioral constructs)。
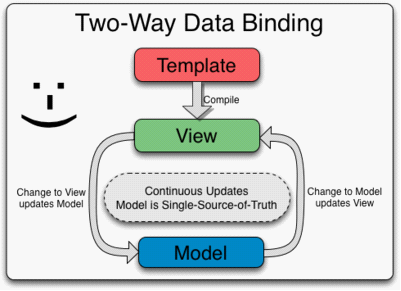
Angular的这个处理方式,产生了一个稳定的DOM。这意味着在DOM元素的生命周期里,一直与某model的实例绑定着,这个关系不会发生改变。这也意味着代码可以保持对某DOM对象的引用,对其注册事件函数,并且这个引用不会被模版数据合并所销毁。

AngularJs学习笔记--IE Compatibility 兼容老版本IE
Short Version(简述)
为了让我们的angular应用在IE上工作,请确保:
1. 按需引入JSON.stringify(IE7或以下的都需要这玩意)。我们可以使用JSON2(https://github.com/douglascrockford/JSON-js)或者JSON3(http://bestiejs.github.com/json3/)。
2. 不要使用自定义标签,诸如<ng:view>(用属性版代替,如<div ng-view>)。如果还是想使用,则请看第3点。
3. 如果你确实想使用自定义标签,那么你必须做以下步骤,让老IE认识你的自定义标签。
<html xmlns:ng="http://angularjs.org">
<head>
<!--[if lte IE 8]>
<script>
document.createElement(''ng-include'');
document.createElement(''ng-pluralize'');
document.createElement(''ng-view'');
// Optionally these for CSS
document.createElement(''ng:include'');
document.createElement(''ng:pluralize'');
document.createElement(''ng:view'');
</script>
<![endif]-->
</head>
<body>
...
</body>
</html>需要关注的是:
xmls:ng - 命名空间 - 对于每一个我们计划使用的自定义标签,都需要有一个命名空间。
document.createElement(“自定义标签名称”) - 自定义标签名称的创建 - 因为这是旧版IE一个问题,我们需要通过IE判断注释(<!--[if lte IE 8]>…<![endif]-->)来特殊处理。对于每一个没有命名空间或者非HTML默认标签,都需要进行这种预定义,以让IE不会犯傻(例如没样式…)。
Long Version(详情)
IE对于非标准HTML标签的处理会有问题。这大致可以氛围两类(有、无命名空间),每一类都有他自己的一个解决方式。
如果标签名称以”my:”开头的话,将被当作命名空间,必须要一个想对应的命名空间定义(<html xmlns:my=”ignored”>)。
如果标签没有命名空间(xx:开头),但并非一个标准的HTML的话,需要通过document.createElement(“标签名称”)进行声明。
如果我们打算对自定义标签定义样式的话,我们必须使用document.createElement(“标签名称”)来进行自定义,regardless of XML命名空间(实验证明,regardless of XML namespace意思很有可能是:不用管有命名空间的自定义标签)。
The Good News(好消息)
好消息是,这个限制仅仅是对于元素名称的,对属性名称没影响。所以不需要对自定义属性(<div> my-tag your:tag></div>)做特殊处理。
What happens if I fail to do this?(没做这些处理的话,会发生什么事呢?!)
假设我们有一个非标准的HTML标签(对于my:tag或者my-tag都有一样的结果。但测试过后,发现命名空间方式不会有这种烦恼)。
<html>
<body>
<mytag>some text</mytag>
</body></html>一般来说,将会转换为一下的DOM结构:
#document
+- HTML
+- BODY
+- mytag
+-
#text: some text
|
我们期望的,是BODY元素有一个mytag子元素,mytag又有一个文本子元素”some text”。
但IE不是这么干的(如果做了纠正措施,则不包括在内)!
#document
+- HTML
+- BODY
+- mytag
+-
#text: some text
+- /mytag
|
在IE里面,BODY将会有3个孩子元素:
1. 一个自闭合的” mytag”,与<br/>类似。末尾的“/”是可选的,但<br>标签不允许有任何子元素,所以浏览器将其分为<br>、some text、</br>三个兄弟元素,而不是单独的<br>元素中含有some text元素。
2. 一个文本节点“some text”。这本来应该是mytag元素的子节点,不是它的兄弟节点。
3. 一个错误的自闭合标签” /mytag”,说它错误,是因为元素名称不允许含有”/”字符(在最后应该是允许的<br/>)。此外,闭合元素不应该是DOM的一部分(不应该以元素形式出现),因为它只用作勾画DOM结构的边界。
六、CSS Styling of Custom Tag Names(对自定义标签进行CSS样式定义)
如果想让CSS选择器对自定义元素有效,那么自定义元素必须通过document.createElement(“元素名称”)进行预定义,regardless of XML namespace(实验证明,这里是不用管有XML命名空间的?!)
这里是自定义标签样式定义的例子:
<!DOCTYPE html>
<html xmlns:ng="needed for ng: namespace">
<head>
<title>IE Compatbility</title>
<!--[if lte IE 8]>
<script>
// needed to make ng-include parse properly
document.createElement(''ng-include'');
// needed to enable CSS reference
document.createElement(''ng:view'');//注释掉也可以?!
</script>
<![endif]-->
<style>
ng\:view {
display: block;
border: 1px solid red;
width:100px;
height:100px;
}
ng-include {
display: block;
border: 1px solid blue;
width:100px;
height:100px;
}
</style>
</head>
<body>
<ng:view></ng:view>
<ng-include></ng-include>
</body>
</html>
Class与ID区别 margin和padding区别 CSS学习笔记
由于现在百分之99.99%的CMS都是用div+css来构建网页模板的,被逼无奈,一大把年纪了还要学习CSS,说实话没觉得用div来布局比table好在什么地方!但迫于行势,先硬着头皮看吧,能学多少是多少。根据数据与结构分离的原则,CSS最好要独立于网页文件,用
<link rel="stylesheet" type="text/css" href="../xxx/web.css" />
语句将CSS文件调入网页文件,不推荐直接在网页文件中写CSS代码。这么做的优点一是修改方便,二是对搜索引擎友好,那些搜索引擎爬虫爬起来也畅快。
margin和padding属性
margin和padding属性可简单理解为元素的外边距和内边距:margin-top, margin-right, margin-bottom, margin-left, padding-top, padding-right, padding-bottom and padding-left
Class与ID区别
简单来说一个ID名在一个页面中只能出现一次而CLASS可以出现多次,当然如果一个ID名在一个页面中出现了两次,对面页的外观不过造成什么影响,只是不符合W3规范。单一的元素,或需要程序、JS控制的东西,需要用id定义;重复使用的元素,用class定义。
- css下margin、padding、border、background和font缩写示例
- CSS学习笔记Padding 属性中参数的定义与使用
- CSS百分比padding制作图片自适应布局
今天关于Compass学习笔记和compass learning的讲解已经结束,谢谢您的阅读,如果想了解更多关于Android Architecture Components学习笔记、AngularJs学习笔记--html compiler、AngularJs学习笔记--IE Compatibility 兼容老版本IE、Class与ID区别 margin和padding区别 CSS学习笔记的相关知识,请在本站搜索。
本文标签:




