在本文中,您将会了解到关于WPS的Word排版的注意事项介绍的新资讯,同时我们还将为您解释wps中排版具体要做些什么的相关在本文中,我们将带你探索WPS的Word排版的注意事项介绍的奥秘,分析wps中
在本文中,您将会了解到关于WPS的Word排版的注意事项介绍的新资讯,同时我们还将为您解释wps中排版具体要做些什么的相关在本文中,我们将带你探索WPS的Word排版的注意事项介绍的奥秘,分析wps中排版具体要做些什么的特点,并给出一些关于for循环及其注意事项,C语言使用for循环的注意事项总结、Java Spring-Cache key配置注意事项介绍、JSON的使用场景及注意事项介绍、Linux使用kill命令的注意事项介绍的实用技巧。
本文目录一览:- WPS的Word排版的注意事项介绍(wps中排版具体要做些什么)
- for循环及其注意事项,C语言使用for循环的注意事项总结
- Java Spring-Cache key配置注意事项介绍
- JSON的使用场景及注意事项介绍
- Linux使用kill命令的注意事项介绍
")
WPS的Word排版的注意事项介绍(wps中排版具体要做些什么)
Word排版的注意事项介绍 WPS排版需要注意的事项有哪些我们在编辑文档的时候一般都会使用Word或者WPS来进行排版,虽然大部分用户都觉得使用这类型软件进行排版是一件很简单的事情,但是Word/WPS背后往往隐藏着许多让人忽略不用的基本技能,下载就给大家介绍Word排版/WPS排版的注意事项。
用Word或WPS写文章排版,这对于一般人来说是一件太容易的事情,只要会录入汉字,能分清段落和段前空格,插入想要的图片,一篇像模像样的文章就产生了。然而,就在像模像样文章产生的同时,一些影响效率的不良排版习惯也在不知不觉中养成了。
用Word或WPS写的文档,文章版式看起来像模像样,而一旦你发现其中有错误,改正的时候,问题就来了
当你将文章的字体整体调整到更大一号的时候,你会发现每个段落的开头并不是空两格了,有时候多余两个,有时候少于两个。当你在文章的大标题、小标题文字上做修改,增加或删除了内容之后,你会发现,标题不是太靠前,就是太靠后了。
这是空格犯下的“罪孽”。这些用户均是用空格来作为“万能武器”来应对段落缩进和标题居中问题。
若是使用WPS 2012,先通过“开始”按钮选择“段落”分组右下角的小箭头图标,激活“段落”设置窗口;在“度量值”下右侧下拉列表中选择度量单位为“字符”,“特殊格式”一项选择“首行缩进”,“度量值”选择为2,选择之后按“确定”。这样设置之后,每个自然段在回车之后就会自动空两格字的位置,不用你人为去输入首行空格了。
标题居中、段落左右对齐等也不用很麻烦地每次都去人为地设置,也有更省事办法:仍然到“段落”设置窗口,依次在“常规”一组的“大纲级别”下拉列表框中选择“正文”“1级”“2级”……“9级”,然后分别设置左侧的“对齐方式”,对于正文我们选择“左对齐”或“两端对齐”,而对于1到9级标题,通常版式是选择“居中对齐”。这样设置之后,当你输入各级标题或正文并应用了这种样式后,各自的对齐便自动完成,不需要人为去设置或调整。
当你帮别人修改一本书稿,当我从他的第一章中发现一段内容重复,删除之后,发现第二章主动跑到第一章的页面来凑热闹,以后各章均有向前移位的现象。分析一下,这个老师给章节划分用的是笨办法——用反复回车的办法换页来实现章节划分的,因此才引出这么多麻烦。其实只要正确使用分页和分节的技术,问题接迎刃而解了。

使用Word 2007或WPS Office 2012的用户,只要选择“页面布局”选项卡,执行“分隔符→分页符”命令,或者按动快捷键组合Ctrl+Enter;若使用Word 2003,只需执行“插入→分隔符→分页符”命令,插入一个分页符号,作为文章自动换页的标志。这样,如果以后对该文档作了任何编辑修改,无论增删多少内容,都不会发生后面的章节串到前面章节页面的情况了。
通过类似的方法,还可以进行分栏、自动换行、文章分节等特殊符号的插入。通过这些符号,我们的文档在排版打印时就能按规矩自动排版,不再用人为干预。
分隔符号作为一种特殊的不可打印的格式标记,一般情况下不会显示在文档窗口中。我们可以根据需要让其显示出来:在Word 2007编辑环境下,在选项卡一栏内的空白处单击鼠标右键,执行“自定义快速访问工具栏”命令,接着选择Word选项“显示→显示所有格式标记”命令并确定;仍在使用Word 2003的用户,通过执行“工具→选项→视图→格式标记”命令,勾选“全部”复选框;WPS 2012使用者直接点击“开始”选项卡页面下的“显示/隐藏编辑标记”按钮,就可以显示出文中所有的分隔符号格式标记。
文字排版方式处理出了问题,由于其中涉及到竖排版式,文字排列顺序与Word默认的先左后右的方式有很大不同,如果只用反复按空格再结合回车的办法来实现古文段落的排版和对齐。这样就产生的竖向对齐的困难。实际上,Word中有现成的方便办法可以解决古文格式排版问题。
第一种方法:用文字方向来设置竖排。以Word 2007为例,选中需要设置竖排的文字段落,然后点击右键,在弹出的菜单中选择“文字方向”命令,然后选择文字方向设置页面中文字方向式样中间的一种竖排方式,右侧出现竖排效果预览,我们可以看到类似于古书竖排的方式,点击“确定”按钮即可看到竖排效果。设置好竖排效果后,我们仍然可以像横排那样设置字体和行列等属性。
第二种方法:用文本框来设定局部竖排。直接在版面文字上设置竖排效果,可能不利于调整竖排文字在版面中的位置。这时,我们可以借助于文字框在设置竖排效果。
以WPS文字 2013抢鲜版为例来说明。依次选择“插入→文本框→竖向文本框”,弹出空白文本框,将文字内容粘贴或录入到其中,竖排的效果马上就显示出来了。选中文本框,选择右键菜单中的“设置对象格式”,在弹出的“设置对象格式”窗口中切换到“文本框”选项卡,选中“允许文字随对象旋转”“文字在自选图形中换行”,确定之后,通过文本框的旋转句柄,即可连同文本框和其中的文字实现任意角度旋转。将设置好的文本框移动到文章的任意位置,可实现竖排文字在整个文档中的版面灵活调整。
以上便是使用Word排版/WPS排版的注意事项,当然在使用的过程中,每个人的使用习惯不同,这也会导致每个人容易出现的错误也不同,本文主要是给大家总结一下比较容易被忽略的问题,到此关于Word排版/WPS排版的注意事项就介绍到这。

for循环及其注意事项,C语言使用for循环的注意事项总结
C 语言 for 循环语句的一般形式为:
for (<初始化>;<条件表达式>;<增量>)
{
循环体语句;
}
尽量使循环控制变量的取值采用半开半闭区间写法
从功能上看,虽然半开半闭区间写法和闭区间写法的功能是完全相同的,但相比之下,半开半闭区间写法更能够直观地表达意思,具有更高的可读性。下面,我们就通过示例代码看看两者之间的区别。其中,闭区间的写法示例如下面的代码所示:
for(i=0;i<=n-1;i++)
{
/*处理代码*/
}
在上面的代码中,i 值属于闭区间写法。半开半闭区间的写法示例如下面的代码所示:
for(i=0;i<n;i++)
{
/*处理代码*/
}
在上面的代码中,i 值属于半开半闭区间写法,即“0=<i<n”,起点到终点的间隔为 n,循环次数为 n。从上面的两段示例代码中可以看出,尽管它们的功能是完全相同的,但相比之下,第二个程序示例(半开半闭区间写法)具有更高的可读性。因此,在 for 循环中,我们应该尽量使循环控制变量的取值采用半开半闭区间写法。
尽量使循环体内工作量达到最小化
我们知道,for 循环随着循环次数的增加,会加大对系统资源的消耗。如果你写的一个循环体内的代码相当耗费资源,或者代码行数众多(一般来说循环体内的代码不要超过 20 行),甚至超过一显示屏,那么这样的程序不仅可读性不高,而且还会让你的程序的运行效率大大降低。这个时候,我们通常可以通过如下两种方法进行优化。1) 重新设计这个循环,确认这些操作是否都必须放在这个循环里,并仔细考虑循环体内的语句是否可以放在循环体之外,从而使循环体内工作量最小化,提高程序的时间效率。如下面的示例代码所示:
for (i = 0;i < n;i++)
{
tmp += i;
sum = tmp;
}
很显然,在上面的代码中每执行一次 for 循环,就要执行一次“sum=tmp”语句来重新为变量 sum 进行赋值,这样的写法很浪费资源。因此,我们完全可以将“sum=tmp”语句放在 for 语句之后,如下面的示例代码所示:
for (i = 0;i < n;i++)
{
tmp += i;
}
sum = tmp;
这样,“sum=tmp”语句只执行一次,不仅可以提高程序执行效率,而且程序也具有更高的可读性。2) 可以考虑将这些代码改写成一个子函数,在循环中只调用这个子函数即可。
避免在循环体内修改循环变量
在 for 循环语句中,我们应该严格避免在循环体内修改循环变量,否则很有可能导致循环失去控制,从而使程序执行违背我们的原意,如下面的示例代码所示:for(i=0;i<10;i++)
{
i=10;
}
在上面的代码中,在循环体内对循环变量i进行赋值之后,for 循环中止执行,从而使程序执行违背我们的原意,更严重的情况会给程序带来灾难性的后果。尽量使逻辑判断语句置于循环语句外层
一般情况下,我们应该尽量避免在程序的循环体内包含逻辑判断语句。当循环体内不得已而存在逻辑判断语句,并且循环次数很大时,我们应该尽量想办法将逻辑判断语句移到循环语句的外层,从而使程序减少执行逻辑判断语句的次数,提高程序的执行效率。如下面的示例代码所示:for (i = 0;i < n;i++)
{
if (condition)
{
DoSomething();
}
else
{
DoOtherthing();
}
}
在上面的代码中,每执行一次 for 循环,都要执行一次 if 语句判断。当 for 循环的次数很大时,执行多余的判断不仅会消耗系统的资源,而且会打断循环“流水线”作业,使得编译器不能对循环进行优化处理,降低程序的执行效率。因此,我们可以通过将逻辑判断语句移到循环语句的外层的方法来减少判断的次数,如下面的代码所示:if (condition)
{
for (i = 0;i < n;i++)
{
DoSomething();
}
}
else
{
for (i = 0;i < n;i++)
{
DoOtherthing();
}
}
虽然上面的代码没有前面的看起来简洁,但却使程序执行逻辑判断语句减少 n-1 次,在 for 循环次数很大时,这种优化显然是值得的。最后还需要注意的是,循环体中的判断语句是否可以移到循环体外,要视程序的具体情况而定。一般情况下,与循环变量无关的判断语句可以移到循环体外,而有关的则不可以。
尽量将多重循环中最长的循环放在最内层,最短的循环放在最外层
在多重 for 循环中,如果有可能,应当尽量将最长的循环放在最内层,最短的循环放在最外层,以减少 cpu 跨切循环层的次数。如下面的示例代码所示:
for (i=0;i<100;i++)
{
for (j=0;j<5;j++)
{
/*处理代码*/
}
}
为了提高上面代码的执行效率,我们可以依照这条建议将上面的代码修改为如下形式:for (j=0;j<5;j++)
{
for (i=0;i<100;i++)
{
/*处理代码*/
}
}
这样,既不会失去程序原有的可读性,同时也提高了程序的执行效率。尽量将循环嵌套控制在 3 层以内
有研究数据表明,当循环嵌套超过 3 层,程序员对循环的理解能力会极大地降低。同时,这样程序的执行效率也会很低。因此,如果代码循环嵌套超过 3 层,建议重新设计循环或将循环内的代码改写成一个子函数。
Java Spring-Cache key配置注意事项介绍
为了提升项目的并发性能,考虑引入本地内存Cache,对:外部数据源访问、Restful API调用、可重用的复杂计算 等3种类型的函数处理结果进行缓存。目前采用的是spring Cache的@Cacheable注解方式,缓存具体实现选取的是Guava Cache。
具体缓存的配置此处不再介绍,重点对于key的配置进行说明:
1、基本形式
@Cacheable(value="cacheName",key"#id") public ResultDTO method(int id);
2、组合形式
@Cacheable(value="cacheName",key"T(String).valueOf(#name).concat('-').concat(#password))
public ResultDTO method(int name,String password);
3、对象形式
@Cacheable(value="cacheName",key"#user.id) public ResultDTO method(User user);
4、自定义key生成器
@Cacheable(value="gomeo2oCache",keyGenerator = "keyGenerator") public ResultDTO method(User user);
注意:Spring默认的SimpleKeyGenerator是不会将函数名组合进key中的
如下:
@Component
public class CacheTestImpl implements CacheTest {
@Cacheable("databaseCache")
public Long test1()
{ return 1L; }
@Cacheable("databaseCache")
public Long test2()
{ return 2L; }
@Cacheable("databaseCache")
public Long test3()
{ return 3L; }
@Cacheable("databaseCache")
public String test4()
{ return "4"; }
}
我们期望输出:
1 2 3 4
实际却输出:
1 1 1 ClassCastException: java.lang.Long cannot be cast to java.lang.String
此外,原子类型的数组,直接作为key使用也是不会生效的
为了解决上述2个问题,自定义了一个KeyGenerator如下:
class CacheKeyGenerator implements KeyGenerator {
// custom cache key
public static final int NO_ParaM_KEY = 0;
public static final int NULL_ParaM_KEY = 53;
@Override
public Object generate(Object target,Method method,Object... params) {
StringBuilder key = new StringBuilder();
key.append(target.getClass().getSimpleName()).append(".").append(method.getName()).append(":");
if (params.length == 0) {
return key.append(NO_ParaM_KEY).toString();
}
for (Object param : params) {
if (param == null) {
log.warn("input null param for Spring cache,use default key={}",NULL_ParaM_KEY);
key.append(NULL_ParaM_KEY);
} else if (ClassUtils.isPrimitiveArray(param.getClass())) {
int length = Array.getLength(param);
for (int i = 0; i < length; i++) {
key.append(Array.get(param,i));
key.append(',');
}
} else if (ClassUtils.isPrimitiveOrWrapper(param.getClass()) || param instanceof String) {
key.append(param);
} else {
log.warn("Using an object as a cache key may lead to unexpected results. " +
"Either use @Cacheable(key=..) or implement CacheKey. Method is " + target.getClass() + "#" + method.getName());
key.append(param.hashCode());
}
key.append('-');
}
String finalKey = key.toString();
long cacheKeyHash = Hashing.murmur3_128().hashString(finalKey,Charset.defaultCharset()).asLong();
log.debug("using cache key={} hashCode={}",finalKey,cacheKeyHash);
return key.toString();
}
}
采用此方式后可以解决:多参数、原子类型数组、方法名识别 等问题
总结
以上就是本文关于Java spring-cache key配置注意事项介绍的全部内容,感兴趣的朋友可以继续参阅:spark之Standalone模式部署配置详解、struts2开发流程及详细配置、Java之Spring注解配置bean实例代码解析等,如有不足之处,欢迎留言指出,小编会及时回复大家并修正,给广大编程爱好者提供更好的阅读体验,希望对大家有所帮助。在此也非常希望朋友们对本站多多支持!

JSON的使用场景及注意事项介绍
上篇我们讲解了JSON的诞生原因是因为XML整合到HTML中各个浏览器实现的细节不尽相同,所以道格拉斯·克罗克福特(Douglas Crockford) 和 奇普·莫宁斯达(Chip Morningstar)一起从JS的数据类型中提取了一个子集,作为新的数据交换格式,因为主流的浏览器使用了通用的JavaScript引擎组件,所以在解析这种新数据格式时就不存在兼容性问题,于是他们将这种数据格式命名为 “JavaScript Object Notation”,缩写为 JSON,由此JSON便诞生了!
今天我们来学习一下JSON的结构形式、数据类型、使用场景以及注意事项吧!
一、JSON格式
上面我们知道JSON是从JavaScript的数据类型中提取出来的子集,那JSON有几种结构形式呢?又有哪些数据类型呢?他们又分别对应着JavaScript中的哪些数据类型呢?
1.JSON的2种结构形式
1、键值对形式
上期我们举了一个JSON的实例,就是键值对形式的,如下:
{
"person": {
"name": "pig",
"age": "18",
"sex": "man",
"hometown": {
"province": "江西省",
"city": "抚州市",
"county": "崇仁县"
}
}
}
这种结构的JSON数据规则是:一个无序的“‘名称/值’对”集合。一个对象以 {左括号 开始, }右括号 结束。每个“名称”后跟一个 :冒号 ;“‘名称/值’ 对”之间使用 ,逗号 分隔,。 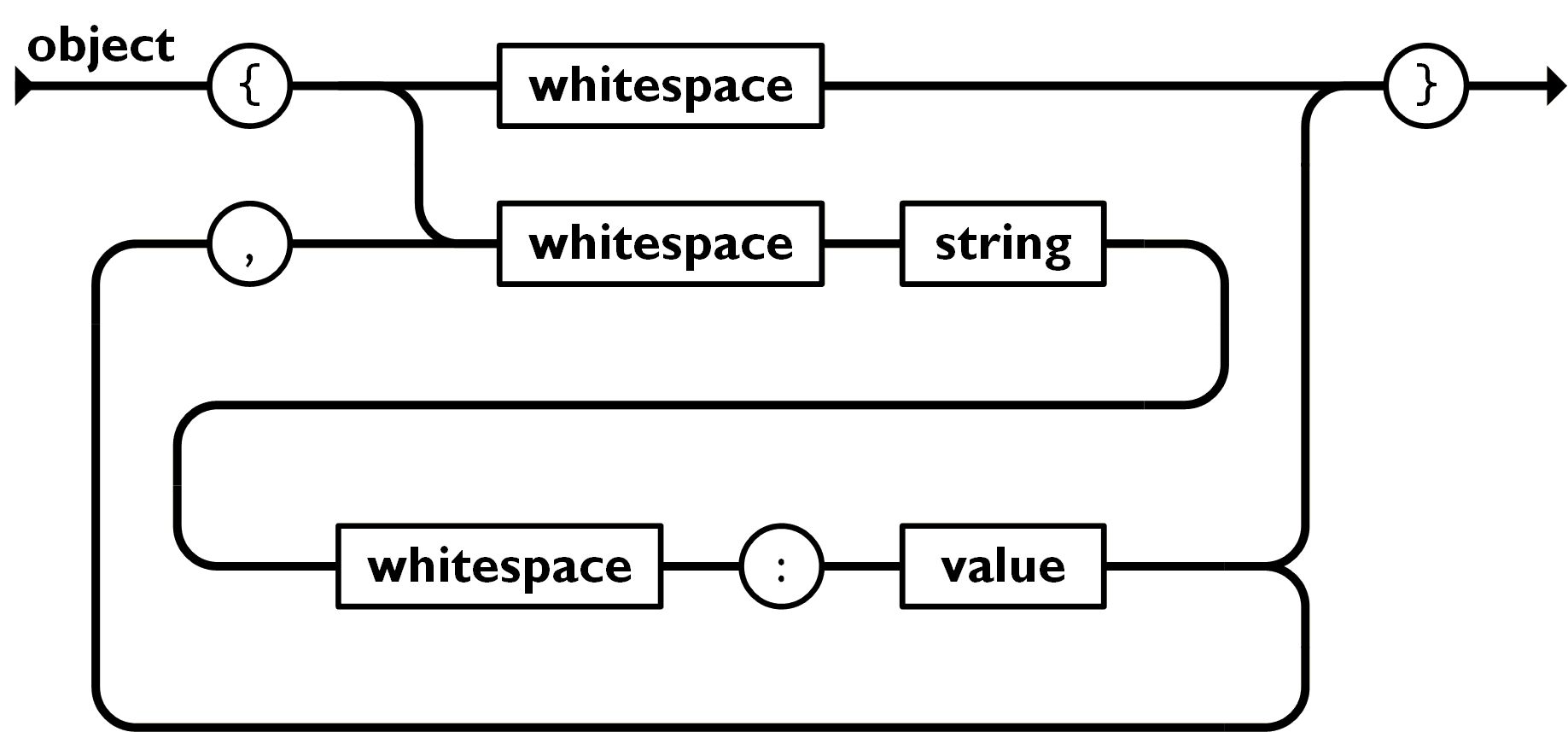 2、数组形式 因为大多数时候大家用的JSON可能都是上面那种key-value形式,所以很多人在讲解JSON的时候总是会忽略数组形式,这一点是需要注意的。
2、数组形式 因为大多数时候大家用的JSON可能都是上面那种key-value形式,所以很多人在讲解JSON的时候总是会忽略数组形式,这一点是需要注意的。
那JSON的数组形式是怎么样的呢?猪哥也举一个实例吧!
["pig", 18, "man", "江西省抚州市崇仁县"]
数组形式的JSON数据就是值(value)的有序集合。一个数组以 [左中括号 开始, ]右中括号 结束。值之间使用 ,逗号 分隔。 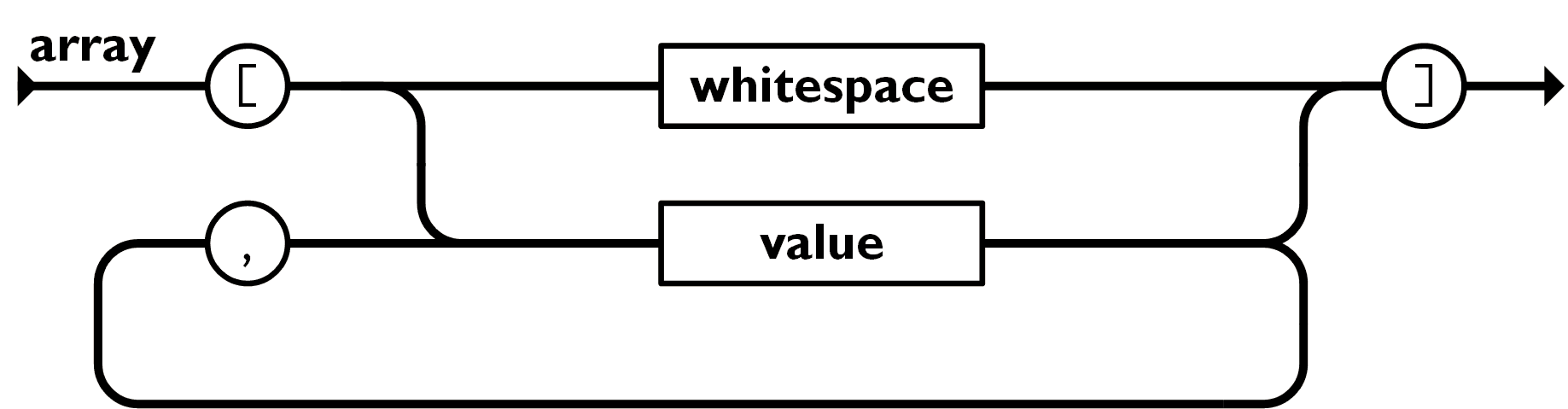
2.JOSN的6种数据类型
上面两种JSON形式内部都是包含value的,那JSON的value到底有哪些类型,而且上期我们说JSON其实就是从Js数据格式中提取了一个子集,那具体有哪几种数据类型呢?
- string:字符串,必须要用双引号引起来。
- number:数值,与JavaScript的number一致,整数(不使用小数点或指数计数法)最多为 15 位。小数的最大位数是 17。
- object:JavaScript的对象形式,{ key:value }表示方式,可嵌套。
- array:数组,JavaScript的Array表示方式[ value ],可嵌套。
- true/false:布尔类型,JavaScript的boolean类型。
- null:空值,JavaScript的null。
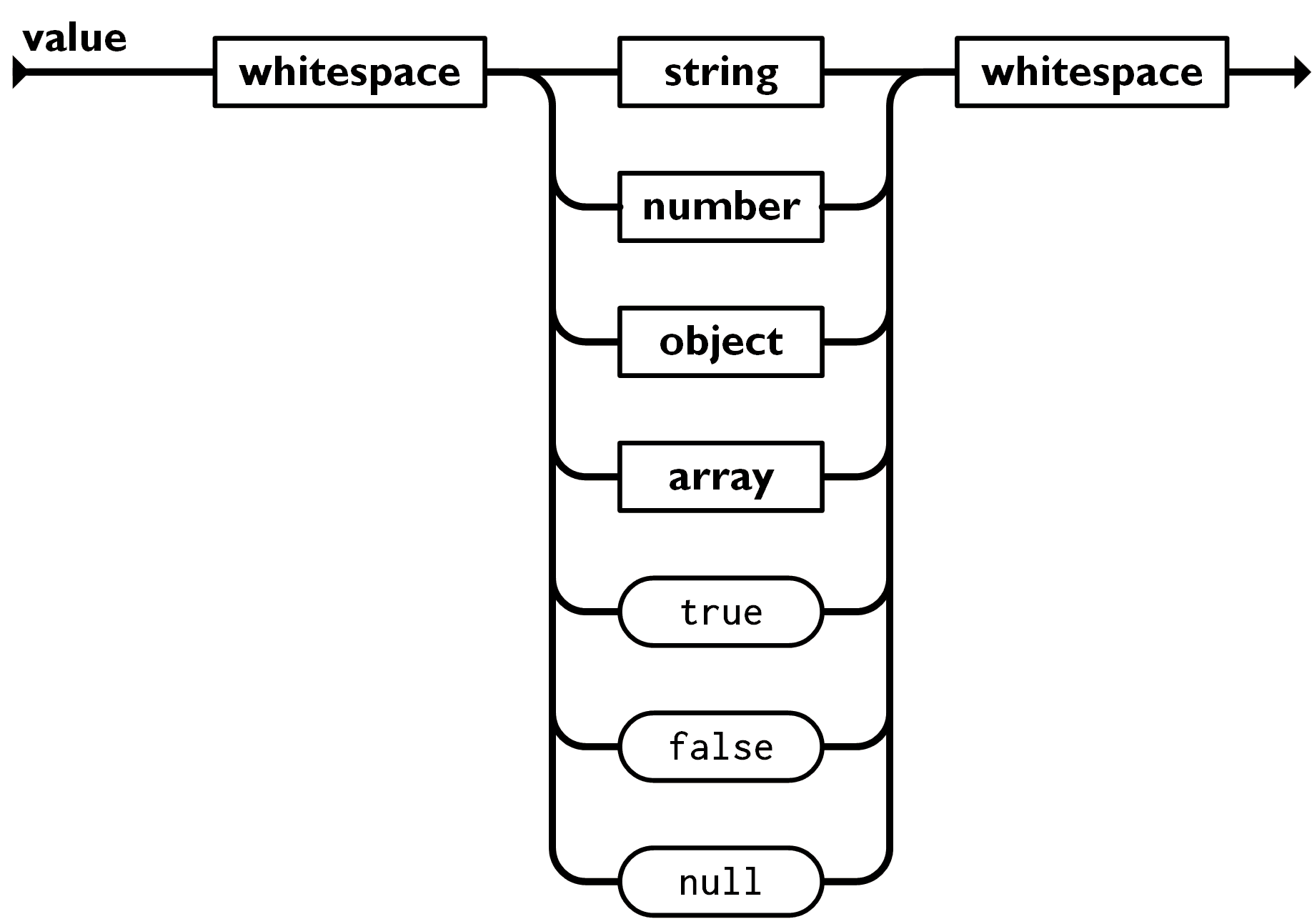 以上数据形式图片来源JSON官方文档:http://www.json.org/json-zh.html
以上数据形式图片来源JSON官方文档:http://www.json.org/json-zh.html
二、JSON使用场景
介绍完JSON的数据格式,那我们来看看JSON在企业中使用的比较多的场景。
1.接口返回数据
JSON用的最多的地方莫过于Web了,现在的数据接口基本上都是返回的JSON,具体细化的场景有:
- Ajxa异步访问数据
- RPC远程调用
- 前后端分离后端返回的数据
- 开放API,如百度、高德等一些开放接口
- 企业间合作接口
这种API接口一般都会提供一个接口文档,说明接口的入参、出参等,  一般的接口返回数据都会封装成JSON格式,比如类似下面这种
一般的接口返回数据都会封装成JSON格式,比如类似下面这种
{
"code": 1,
"msg": "success",
"data": {
"name": "pig",
"age": "18",
"sex": "man",
"hometown": {
"province": "江西省",
"city": "抚州市",
"county": "崇仁县"
}
}
}
2.序列化
程序在运行时所有的变量都是保存在内存当中的,如果出现程序重启或者机器宕机的情况,那这些数据就丢失了。一般情况运行时变量并不是那么重要丢了就丢了,但有些内存中的数据是需要保存起来供下次程序或者其他程序使用。
保存内存中的数据要么保存在数据库,要么保存直接到文件中,而将内存中的数据变成可保存或可传输的数据的过程叫做序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
正常的序列化是将编程语言中的对象直接转成可保存或可传输的,这样会保存对象的类型信息,而JSON序列化则不会保留对象类型!
为了让大家更直观的感受区别,猪哥用代码做一个测试,大家一目了然 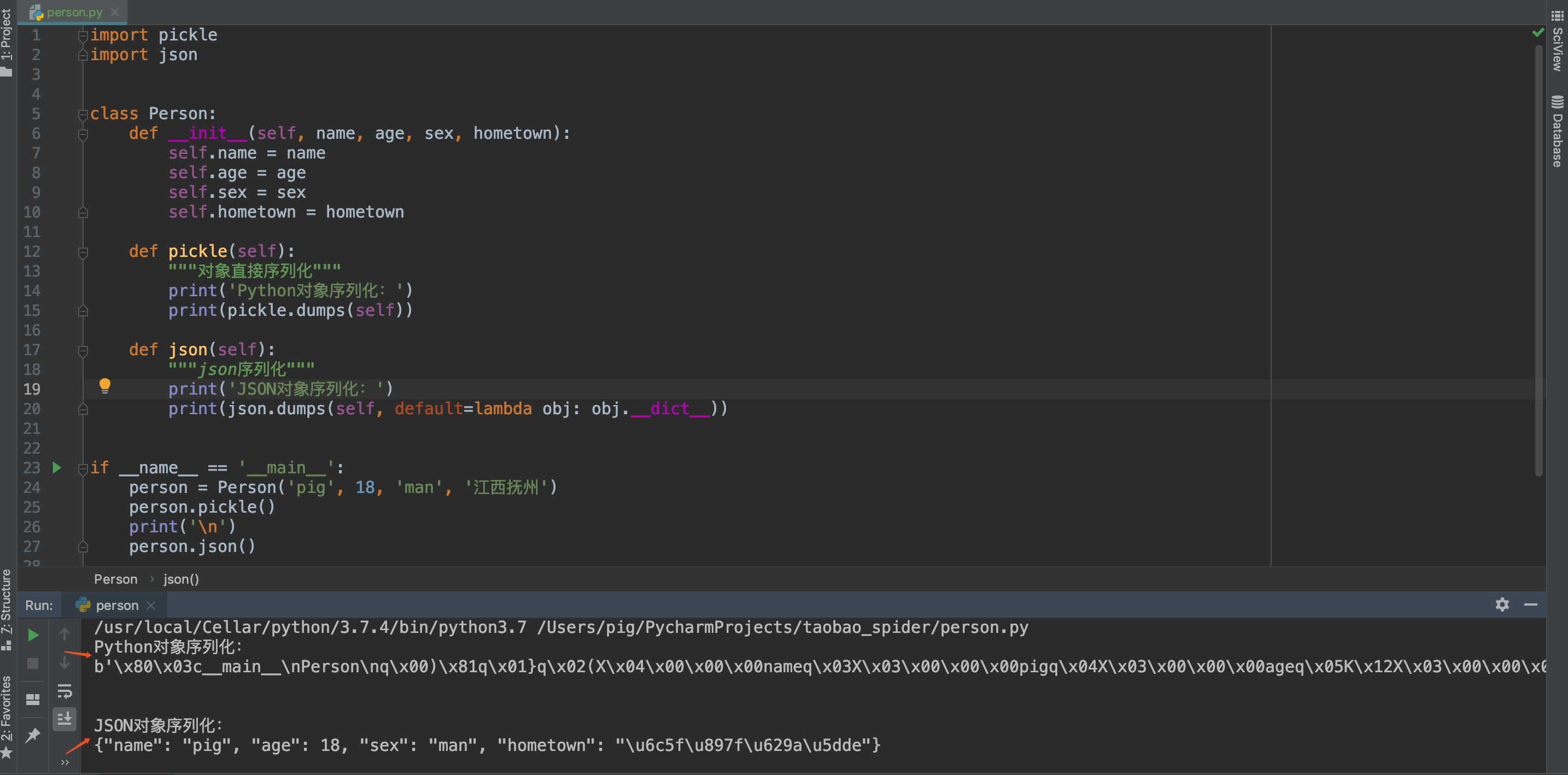
- Python对象直接序列化会保存class信息,下次使用loads加载到内存时直接变成Python对象。
- JSON对象序列化只保存属性数据,不保留class信息,下次使用loads加载到内存可以直接转成dict对象,当然也可以转为Person对象,但是需要写辅助方法。
对于JSON序列化不能保存class信息的特点,那JSON序列化还有什么用?答案是当然游有用,对于不同编程语言序列化读取有用,比如:我用Python爬取数据然后转成对象,现在我需要将它序列化磁盘,然后使用Java语言读取这份数据,这个时候由于跨语言数据类型不同,所以就需要用到JSON序列化。
存在即合理,两种序列化可根据需求自行选择!
3.生成Token
首先声明Token的形式多种多样,有JSON、字符串、数字等等,只要能满足需求即可,没有规定用哪种形式。
JSON格式的Token最有代表性的莫过于JWT(JSON Web Tokens)。  随着技术的发展,分布式web应用的普及,通过Session管理用户登录状态成本越来越高,因此慢慢发展成为Token的方式做登录身份校验,然后通过Token去取Redis中的缓存的用户信息,随着之后JWT的出现,校验方式更加简单便捷化,无需通过Redis缓存,而是直接根据Token取出保存的用户信息,以及对Token可用性校验,单点登录更为简单。
随着技术的发展,分布式web应用的普及,通过Session管理用户登录状态成本越来越高,因此慢慢发展成为Token的方式做登录身份校验,然后通过Token去取Redis中的缓存的用户信息,随着之后JWT的出现,校验方式更加简单便捷化,无需通过Redis缓存,而是直接根据Token取出保存的用户信息,以及对Token可用性校验,单点登录更为简单。 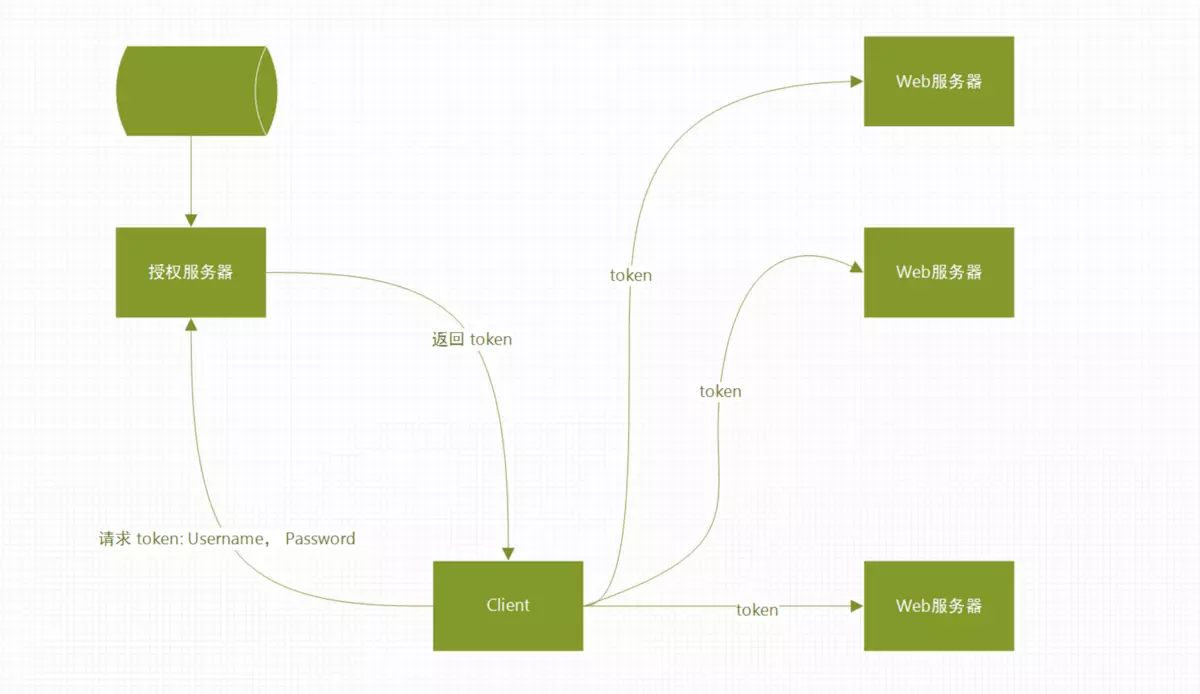 猪哥也曾经使用JWT做过app的登录系统,大概的流程就是:
猪哥也曾经使用JWT做过app的登录系统,大概的流程就是:
- 用户输入用户名密码
- app请求登录中心验证用户名密码
- 如果验证通过则生成一个Token,其中Token中包含:用户的uid、Token过期时间、过期延期时间等,然后返回给app
- app获得Token,保存在cookie中,下次请求其他服务则带上
- 其他服务获取到Token之后调用登录中心接口验证
- 验证通过则响应
JWT登录认证有哪些优势:
- 性能好:服务器不需要保存大量的session
- 单点登录(登录一个应用,同一个企业的其他应用都可以访问):使用JWT做一个登录中心基本搞定,很容易实现。
- 兼容性好:支持移动设备,支持跨程序调用,Cookie 是不允许垮域访问的,而 Token 则不存在这个问题。
- 安全性好:因为有签名,所以JWT可以防止被篡改。
更多JWT相关知识自行在网上学习,本文不过多介绍!
4.配置文件
说实话JSON作为配置文件使用场景并不多,最具代表性的就是npm的package.json包管理配置文件了,下面就是一个npm的package.json配置文件内容。
{
"name": "server", //项目名称
"version": "0.0.0",
"private": true,
"main": "server.js", //项目入口地址,即执行npm后会执行的项目
"scripts": {
"start": "node ./bin/www" ///scripts指定了运行脚本命令的npm命令行缩写
},
"dependencies": {
"cookie-parser": "~1.4.3", //指定项目开发所需的模块
"debug": "~2.6.9",
"express": "~4.16.0",
"http-errors": "~1.6.2",
"jade": "~1.11.0",
"morgan": "~1.9.0"
}
}
但其实JSON并不合适做配置文件,因为它不能写注释、作为配置文件的可读性差等原因。
配置文件的格式有很多种如:toml、yaml、xml、ini等,目前很多地方开始使用yaml作为配置文件。
三、JSON在Python中的使用
最后我们来看看Python中操作JSON的方法有哪些,在Python中操作JSON时需要引入json标准库。
import json
1.类型转换
1、Python类型转JSON:json.dump()
# 1、Python的dict类型转JSON
person_dict = {''name'': ''pig'', ''age'': 18, ''sex'': ''man'', ''hometown'': ''江西抚州''}
# indent参数为缩进空格数
person_dict_json = json.dumps(person_dict, indent=4)
print(person_dict_json, ''\n'')
# 2、Python的列表类型转JSON
person_list = [''pig'', 18, ''man'', ''江西抚州'']
person_list_json = json.dumps(person_list)
print(person_list_json, ''\n'')
# 3、Python的对象类型转JSON
person_obj = Person(''pig'', 18, ''man'', ''江西抚州'')
# 中间的匿名函数是获得对象所有属性的字典形式
person_obj_json = json.dumps(person_obj, default=lambda obj: obj.__dict__, indent=4)
print(person_obj_json, ''\n'')
执行结果: 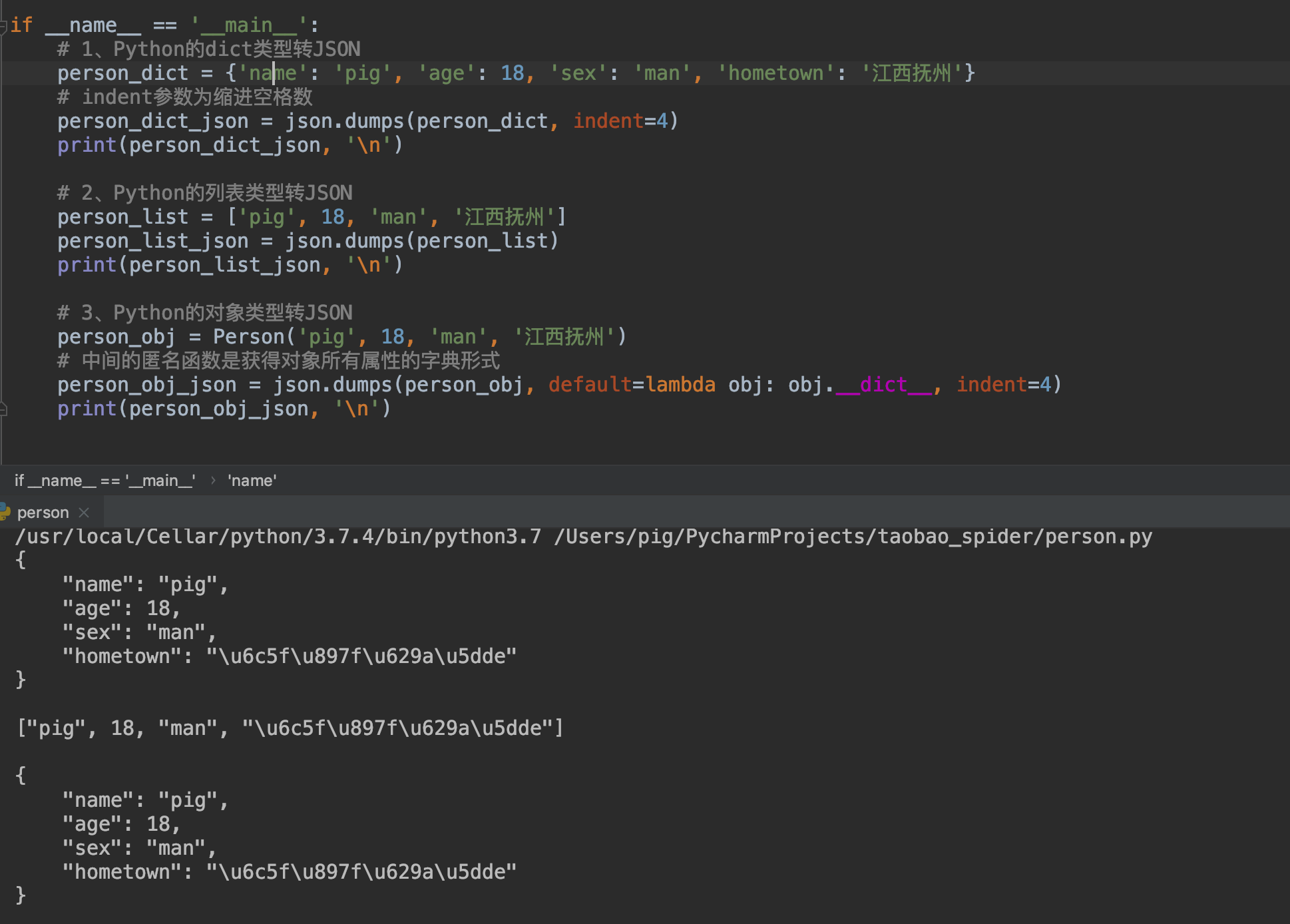
2、JSON转Python类型:json.loads()
# 4、JSON转Python的dict类型
person_json = ''{ "name": "pig","age": 18, "sex": "man", "hometown": "江西抚州"}''
person_json_dict = json.loads(person_json)
print(type(person_json_dict), ''\n'')
# 5、JSON转Python的列表类型
person_json2 = ''["pig", 18, "man", "江西抚州"]''
person_json_list = json.loads(person_json2)
print(type(person_json_list), ''\n'')
# 6、JSON转Python的自定义对象类型
person_json = ''{ "name": "pig","age": 18, "sex": "man", "hometown": "江西抚州"}''
# object_hook参数是将dict对象转成自定义对象
person_json_obj = json.loads(person_json, object_hook=lambda d: Person(d[''name''], d[''age''], d[''sex''], d[''hometown'']))
print(type(person_json_obj), ''\n'')
执行结果如下: 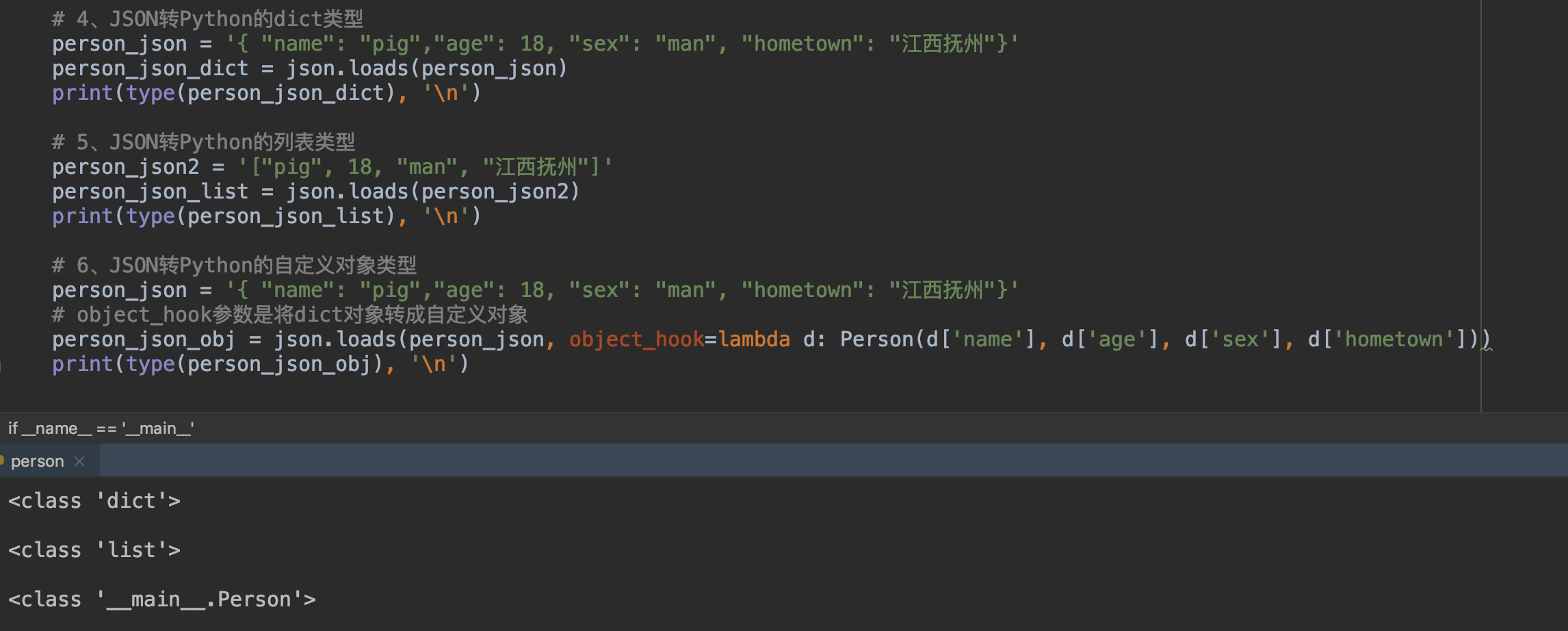
2.对应的数据类型
上面我们演示了Python类型与JSON的相互转换,最开始的时候我们讲过JSON有6种数据类型,那这6种数据类型分别对应Python中的哪些数据类型呢? 
3.需要注意的点
- JSON的键名和字符串都必须使用双引号引起来,而Python中单引号也可以表示为字符串,所以这是个比较容易犯的错误!
- Python类型与JSON相互转换的时候到底是用
load/dump还是用loads\dumps?他们之间有什么区别?什么时候该加s什么时候不该加s?这个我们可以通过查看源码找到答案:不加s的方法入参多了一个fp表示filepath,最后多了一个写入文件的操作。所以我们在记忆的时候可以这样记忆:加s表示转成字符串(str),不加s表示转成文件。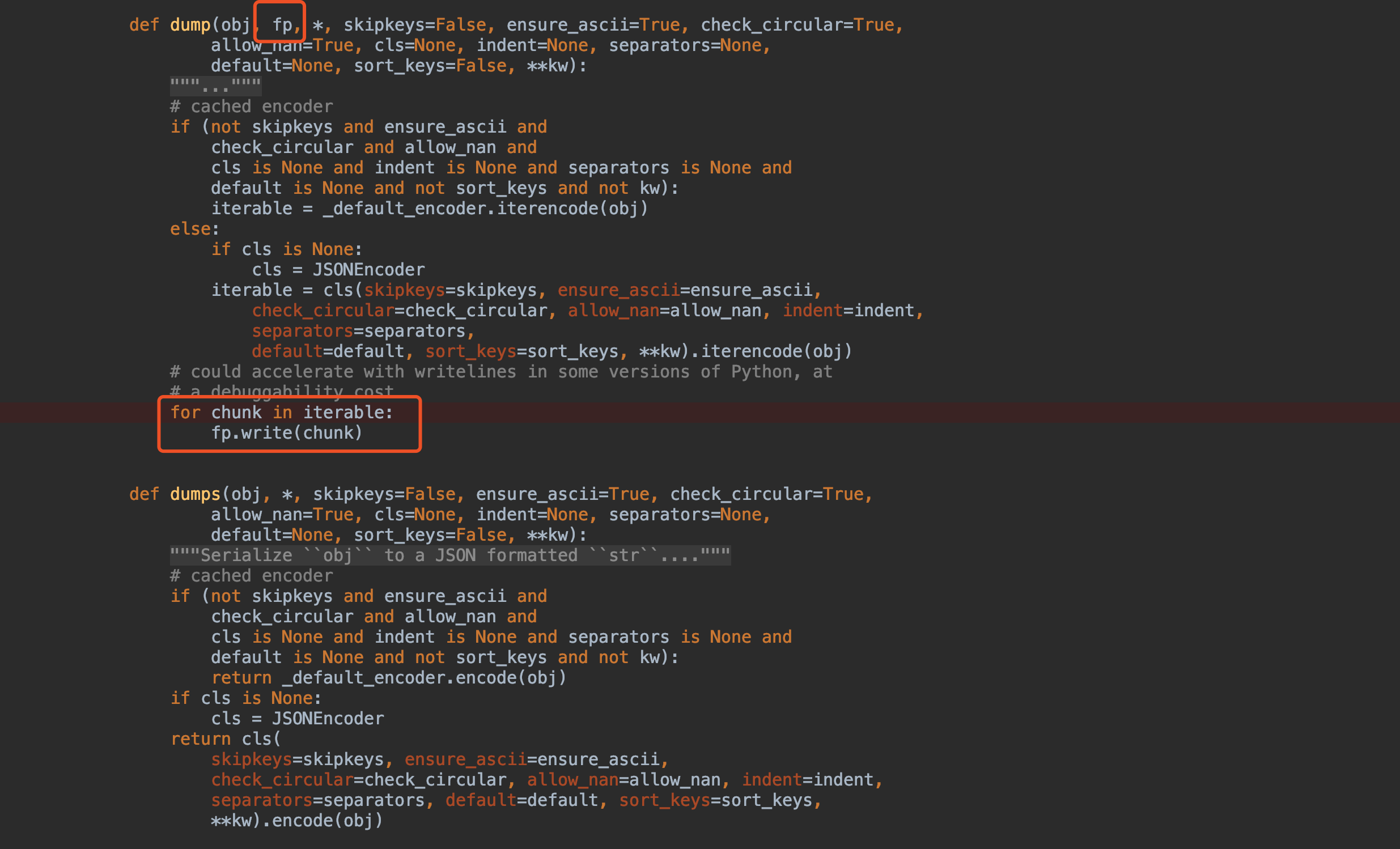
- Python自定义对象与JSON相互转换的时候需要辅助方法来指明属性与键名的对应关系,如果不指定一个方法则会抛出异常!
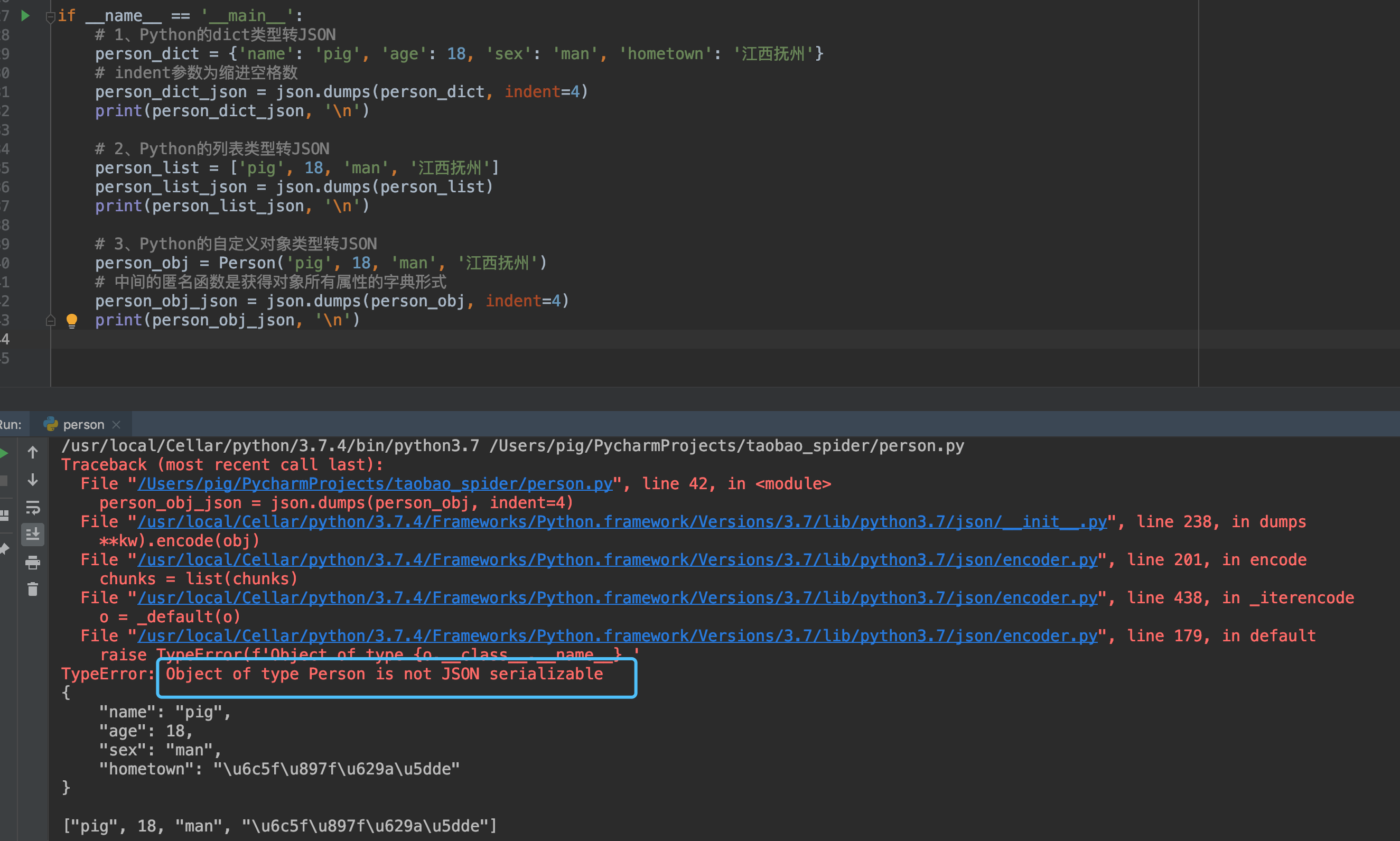
- 相信有些看的仔细的同学会好奇上面猪哥使用json.dumps方法将Python类型转JSON的时候,如果出现中文,则会出现:\u6c5f\u897f\u629a\u5dde这种东西,这是为什么呢?原因是:Python 3中的json在做dumps操作时,会将中文转换成unicode编码,并以16进制方式存储,而并不是UTF-8格式!
四、总结
今天我们学习了JSON的2种形式,切记JSON还有[...]这种形式的。
学习了JSON的6种数据类型他们分别对于Python中的哪些类型。
了解了JSON的一些使用场景以及实际的例子。
还学习了在Python中如何使用JSON以及需要注意的事项。
结合上期的JSON的诞生与发展介绍,我们JSON相关的知识基本就介绍的差不多,后面会出一些爬虫实际案例来教大家如何解析返回JSON数据。
一个JSON知识点却分两篇长文(近万字)来讲,其重要性不言而喻。因为不管你是做爬虫、还是做数据分析、web、甚至前端、测试、运维,JSON都是你必须要掌握的一个知识点!
原文出处:https://www.cnblogs.com/pig66/p/11959035.html

Linux使用kill命令的注意事项介绍
众所周知,Linux系统下有一个直接终止进程的命令,这个命令的代码也是非常霸气,直接就是英文的kill。既然这个命令这么有“杀气”,为了防止“误伤”,下面,小编就给大家介绍下Linux使用kill命令的注意事项。

Linux系统
使用kill命令注意事项
1、在检查一个角本Bug的时候,你会发现killall命令与kill命令的一个不同之处: 假设有脚本 test.pl ,假设内容如下: #!/usr/bin/perl -w sleep 60;
则测试结果如下: 1、如果通过 /home/MNET/m_yancyliu/tmp/x.pl 命令启动,此时ps下命令行显示如下: /usr/bin/perl -w /home/MNET/m_yancyliu/tmp/x.pl
结果如下: killall x.pl 命令可以杀掉该脚本,
killall perl 命令则无法杀掉该进程
2、 如果通过 /usr/bin/perl -w /home/MNET/myancyliu/tmp/x.pl 命令启动,此时ps下命令行显示: /usr/bin/perl -w /home/MNET/m_yancyliu/tmp/x.pl
结果如下: killall perl 命令可以杀掉该进程
killall x.pl 命令则无法杀掉该进程 此时,如果通过 ps uxfww 命令查看对应的进程树,会发现上面两种启动方式的进程树是一样的: (如果要查看所有进程的进程树,可以使用命令 ps axfww) -eash | _ /bin/bash | _ /usr/bin/perl -w /home/MNET/m_yancyliu/tmp/test.pl
上面的结果显示,尽管通过 ps -ef 命令看到的命令行显示是相同的,但操作系统仍然会记录该进程的启动信息。
1、直接通过脚本名调用时,OS认为进程对应的程序名就是脚本名,因为进程是通过脚本名启动的。 2、如果通过 perl 或 shell 加载脚本名的方式调用时,操作系统会认为进程的程序名称是 perl/shell,而脚本名则是做为进程的参数传入,因为此时进程是通过perl/shell启动的。
至于操作系统是如何区分出这两种方式的呢,这里对比两种启动方式下的 /proc/$pid 目录: 1、直接通过脚本名调用时,/proc/$pid 目录下内容如下: cmdline文件中内容为: usr/bin/perl -w /home/MNET/m_yancyliu/tmp/test.pl stat文件内容为:
12242 (test.pl) S 3102 12242 3102 9472041 12242 8396800 456 0 3 0 0 0 0 0 18 0 1 0 357357658 4358144 361 4294967295 134512640 135656772 3215679088 3215678100 3084573003 0 0 128 0 3741425540 0 0 17 3 0 0
2、通过 perl 加载脚本名时,/proc/$pid 目录下内容如下:
cmdline文件中内容为: usr/bin/perl -w /home/MNET/m_yancyliu/tmp/test.pl
stat文件内容为:
13372 (perl) S 3102 13372 3102 9472041 13372 8396800 460 0 0 0 0 0 0 0 18 0 1 0 357376374 4358144 362 4294967295 134512640 135656772 3218100000 3218099012 3084704075 0 0 128 0 3577044868 0 0 17 2 0 0
显然,我们使用 ps 命令看到的进程统计信息,是与 /proc/$pid/cmdline中看到的一致。 而在进程的cpu统计信息 /proc/$pid/stat 中看到的内容则是不同的,这里标识了操作系统认可的程序名称,即进程是如何启动的。上面第一个数字均为进程ID。
于是,根据进程的cpu活动统计信息,killall命令能够区分两种不同的方式启动的进程,从而做出不同的处理。 对于这两种启动方式引起的不同,在使用 killall 命令时要注意,在使用命令行启动进程时也要注意。
以上就是Linux使用kill命令的注意事项介绍,更多精彩内容继续关注系统部落官网。
我们今天的关于WPS的Word排版的注意事项介绍和wps中排版具体要做些什么的分享已经告一段落,感谢您的关注,如果您想了解更多关于for循环及其注意事项,C语言使用for循环的注意事项总结、Java Spring-Cache key配置注意事项介绍、JSON的使用场景及注意事项介绍、Linux使用kill命令的注意事项介绍的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

