本文将介绍Thanksforthememory,Linux的详细情况,。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于(OK)PerformanceEnhan
本文将介绍Thanks for the memory, Linux的详细情况,。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于(OK) Performance Enhancement of Multipath TCP in Mobile Ad Hoc Networks、11g 报错 ORA-27102: out of memory Linux Error: 22: Invalid arg、An experiment in porting the Android init system to GNU/Linux、Attempted to read or write protected memory. This is often an indication that other memory is corrupt.的知识。
本文目录一览:- Thanks for the memory, Linux
- (OK) Performance Enhancement of Multipath TCP in Mobile Ad Hoc Networks
- 11g 报错 ORA-27102: out of memory Linux Error: 22: Invalid arg
- An experiment in porting the Android init system to GNU/Linux
- Attempted to read or write protected memory. This is often an indication that other memory is corrupt.

Thanks for the memory, Linux
Contents
Introduction
A recap of native memory
How the Java runtime uses native memory
How can I tell if I''m running out of native memory?
Examples of running out of native memory
Debugging approaches and techniques
Removing the limit: Making the change to 64-bit
Conclusion
Downloadable resources
Related topics
Comments
Understanding how the JVM uses native memory on Windows and Linux Andrew Hall Published on April 21, 2009
Facebook Twitter Linked In Google+ E-mail this page Comments 13
Learn more. Develop more. Connect more.
The new developerWorks Premium membership program provides an all-access pass to powerful development tools and resources, including 500 top technical titles (dozens specifically for Java developers) through Safari Books Online, deep discounts on premier developer events, video replays of recent O''Reilly conferences, and more. Sign up today.
The Java heap, where every Java object is allocated, is the area of memory you''re most intimately connected with when writing Java applications. The JVM was designed to insulate us from the host machine''s peculiarities, so it''s natural to think about the heap when you think about memory. You''ve no doubt encountered a Java heap OutOfMemoryError — caused by an object leak or by not making the heap big enough to store all your data — and have probably learned a few tricks to debug these scenarios. But as your Java applications handle more data and more concurrent load, you may start to experience OutOfMemoryErrors that can''t be fixed using your normal bag of tricks — scenarios in which the errors are thrown even though the Java heap isn''t full. When this happens, you need to understand what is going on inside your Java Runtime Environment (JRE).
Java applications run in the virtualized environment of the Java runtime, but the runtime itself is a native program written in a language (such as C) that consumes native resources, including native memory. Native memory is the memory available to the runtime process, as distinguished from the Java heap memory that a Java application uses. Every virtualized resource — including the Java heap and Java threads — must be stored in native memory, along with the data used by the virtual machine as it runs. This means that the limitations on native memory imposed by the host machine''s hardware and operating system (OS) affect what you can do with your Java application.
This article is one of two covering the same topic on different platforms. In both, you''ll learn what native memory is, how the Java runtime uses it, what running out of it looks like, and how to debug a native OutOfMemoryError. This article covers Windows and Linux and does not focus on any particular runtime implementation. The companion article covers AIX and focuses on the IBM® Developer Kit for Java. (The information in that article about the IBM implementation is also true for platforms other than AIX, so if you use the IBM Developer Kit for Java on Linux or the IBM 32-bit Runtime Environment for Windows, you might find that article useful too.) A recap of native memory
I''ll start by explaining the limitations on native memory imposed by the OS and the underlying hardware. If you''re familiar with managing dynamic memory in a language such as C, then you may want to skip to the next section. Hardware limitations
Many of the restrictions that a native process experiences are imposed by the hardware, not the OS. Every computer has a processor and some random-access memory (RAM), also known as physical memory. A processor interprets a stream of data as instructions to execute; it has one or more processing units that perform integer and floating-point arithmetic as well as more advanced computations. A processor has a number of registers — very fast memory elements that are used as working storage for the calculations that are performed; the register size determines the largest number that a single calculation can use.
The processor is connected to physical memory by the memory bus. The size of the physical address (the address used by the processor to index physical RAM) limits the amount of memory that can be addressed. For example, a 16-bit physical address can address from 0x0000 to 0xFFFF, which gives 2^16 = 65536 unique memory locations. If each address references a byte of storage, a 16-bit physical address would allow a processor to address 64KB of memory.
Recommended resources
"Thanks for the memory (for AIX)"
"IBM Monitoring and Diagnostic Tools for Java - Memory Analyzer"
"Guided debugging for Java"
Processors are described as being a certain number of bits. This normally refers to the size of the registers, although there are exceptions — such as 390 31-bit — where it refers to the physical address size. For desktop and server platforms, this number is 31, 32, or 64; for embedded devices and microprocessors, it can be as low as 4. The physical address size can be the same as the register width but could be larger or smaller. Most 64-bit processors can run 32-bit programs when running a suitable OS.
Table 1 lists some popular Linux and Windows architectures with their register and physical address sizes: Table 1. Register and physical address size of some popular processor architectures Architecture Register width (bits) Physical address size (bits) (Modern) Intel® x86 32 32 36 with Physical Address Extension (Pentium Pro and above) x86 64 64 Currently 48-bit (scope to increase later) PPC64 64 50-bit at POWER 5 390 31-bit 32 31 390 64-bit 64 64 Operating systems and virtual memory
If you were writing applications to run directly on the processor without an OS, you could use all memory that the processor can address (assuming enough physical RAM is connected). But to enjoy features such as multitasking and hardware abstraction, nearly everybody uses an OS of some kind to run their programs.
In multitasking OSs such as Windows and Linux, more than one program uses system resources, including memory. Each program needs to be allocated regions of the physical memory to work in. It''s possible to design an OS such that every program works directly with physical memory and is trusted to use only the memory it has been given. Some embedded OSs work like this, but it''s not practical in an environment consisting of many programs that are not tested together because any program could corrupt the memory of other programs or the OS itself.
Virtual memory allows multiple processes to share physical memory without being able to corrupt one another''s data. In an OS with virtual memory (such as Windows, Linux, and many others), each program has its own virtual address space — a logical region of addresses whose size is dictated by the address size on that system (so 31, 32, or 64 bits for desktop and server platforms). Regions in a process''s virtual address space can be mapped to physical memory, to a file, or to any other addressable storage. The OS can move data held in physical memory to and from a swap area (the page file on Windows or a swap partition on Linux) when it isn''t being used, to make the best use of physical memory. When a program tries to access memory using a virtual address, the OS in combination with on-chip hardware maps that virtual address to the physical location. That location could be physical RAM, a file, or the page file/swap partition. If a region of memory has been moved to swap space, then it is loaded back into physical memory before being used. Figure 1 shows how virtual memory works by mapping regions of process address space to shared resources: Figure 1. Virtual memory mapping process address spaces to physical resources Virtual memory mapping
Each instance of a program runs as a process. A process on Linux and Windows is a collection of information about OS-controlled resources (such as file and socket information), typically one virtual address space (more than one on some architectures), and at least one thread of execution.
The virtual address space size can be smaller than the processor''s physical address size. Intel x86 32-bit originally had a 32-bit physical address that allowed the processor to address 4GB of storage. Later, a feature called Physical Address Extension (PAE) was added that expanded the physical address size to 36-bit — allowing up to 64GB of RAM to be installed and addressed. PAE allowed OSs to map 32-bit 4GB virtual address spaces onto a large physical address range, but it did not allow each process to have a 64GB virtual address space. This means that if you put more than 4GB of memory into a 32-bit Intel server, you can''t map all of it directly into a single process.
The Address Windowing Extensions feature allows a Windows process to map a portion of its 32-bit address space as a sliding window into a larger area of memory. Linux uses similar technologies based on mapping regions into the virtual address space. This means that although you can''t directly reference more than 4GB of memory, you can work with larger regions of memory. Kernel space and user space
Although each process has its own address space, a program typically can''t use all of it. The address space is divided into user space and kernel space. The kernel is the main OS program and contains the logic for interfacing to the computer hardware, scheduling programs, and providing services such as networking and virtual memory.
As part of the computer boot sequence, the OS kernel runs and initialises the hardware. Once the kernel has configured the hardware and its own internal state, the first user-space process starts. If a user program needs a service from the OS, it can perform an operation — called a system call — that jumps into the kernel program, which then performs the request. System calls are generally required for operations such as reading and writing files, networking, and starting new processes.
The kernel requires access to its own memory and the memory of the calling process when executing a system call. Because the processor that is executing the current thread is configured to map virtual addresses using the address-space mapping for the current process, most OSs map a portion of each process address space to a common kernel memory region. The portion of the address space mapped for use by the kernel is called kernel space; the remainder, which can be used by the user application, is called user space.
The balance between kernel and user space varies by OS and even among instances of the same OS running on different hardware architectures. The balance is often configurable and can be adjusted to give more space to user applications or the kernel. Squeezing the kernel area can cause problems such as restricting the number of users that can be logged on simultaneously or the number of processes that can run; smaller user space means that the application programmer has less room to work in.
By default, 32-bit Windows has a 2GB user space and a 2GB kernel space. The balance can be shifted to a 3GB user space and a 1GB kernel space on some versions of Windows by adding the /3GB switch to the boot configuration and relinking applications with the /LARGEADDRESSAWARE switch. On 32-bit Linux, the default is a 3GB user space and 1GB kernel space. Some Linux distributions provide a hugemem kernel that supports a 4GB user space. To achieve this, the kernel is given an address space of its own that is used when a system call is made. The gains in user space are offset by slower system calls because the OS must copy data between address spaces and reset the process address-space mappings each time a system call is made. Figure 2 shows the address-space layout for 32-bit Windows: Figure 2. Address-space layout for 32-bit Windows Windows 32 bit address spaces
Figure 3 shows the address-space arrangements for 32-bit Linux: Figure 3. Address-space layout for 32-bit Linux Linux 32 bit address spaces
A separate kernel address space is also used on Linux 390 31-bit, where the smaller 2GB address space makes dividing a single address space undesirable; however, the 390 architecture can work with multiple address spaces simultaneously without compromising performance.
The process address space must contain everything a program requires — including the program itself and the shared libraries (DLLs on Windows, .so files on Linux) that it uses. Not only can shared libraries take up space that a program can''t use to store data in, they can also fragment the address space and reduce the amount of memory that can be allocated as a continuous chunk. This is noticeable in programs running on Windows x86 with a 3GB user space. DLLs are built with a preferred loading address: when a DLL is loaded, it''s mapped into the address space at a particular location unless that location is already occupied, in which case it''s rebased and loaded elsewhere. With the 2GB user space available when Windows NT was originally designed, it made sense for the system libraries to be built to load near the 2GB boundary — thereby leaving most of the user region free for the application to use. When the user region is extended to 3GB, the system shared libraries still load near 2GB — now in the middle of the user space. Although there''s a total user space of 3GB, it''s impossible to allocate a 3GB block of memory because the shared libraries get in the way.
Using the /3GB switch on Windows reduces the kernel space to half what it was originally designed to be. In some scenarios it''s possible to exhaust the 1GB kernel space and experience slow I/O or problems creating new user sessions. Although the /3GB switch can be extremely valuable for some applications, any environment using it should be thoroughly load tested before being deployed.
A native-memory leak or excessive native memory use will cause different problems depending on whether you exhaust the address space or run out of physical memory. Exhausting the address space normally happens only with 32-bit processes — because the maximum 4GB is easy to allocate. A 64-bit process has a user space of hundreds or thousands of gigabytes, which is hard to fill up even if you try. If you do exhaust the address space of a Java process, then the Java runtime can start to display strange symptoms that I''ll describe later in the article. When running on a system with more process address space than physical memory, a memory leak or excessive use of native memory forces the OS to swap out the backing storage for some of the native process''s virtual address space. Accessing a memory address that has been swapped is much slower than reading a resident (in physical memory) address because the OS must pull the data from the hard drive. It''s possible to allocate enough memory to exhaust all physical memory and all swap memory (paging space); on Linux, this triggers the kernel out-of-memory (OOM) killer, which forcibly kills the most memory-hungry process. On Windows, allocations start failing in the same way as they would if the address space were full.
If you simultaneously try to use more virtual memory than there is physical memory, it will be obvious there''s a problem long before the process is killed for being a memory hog. The system will thrash — that is, spend most of its time copying memory back and forth from swap space. When this happens, the performance of the computer and the individual applications will become so poor that the user can''t fail to notice there''s a problem. When a JVM''s Java heap is swapped out, the garbage collector''s performance becomes extremely poor, to the extent that the application can appear to hang. If multiple Java runtimes are in use on a single machine at the same time, the physical memory must be sufficient to fit all of the Java heaps. How the Java runtime uses native memory
The Java runtime is an OS process that is subject to the hardware and OS constraints I outlined in the preceding section. Runtime environments provide capabilities that are driven by some unknown user code; that makes it impossible to predict which resources the runtime environment will require in every situation. Every action a Java application takes inside the managed Java environment can potentially affect the resource requirements of the runtime that provides that environment. This section describes how and why Java applications consume native memory. The Java heap and garbage collection
The Java heap is the area of memory where objects are allocated. Most Java SE implementations have one logical heap, although some specialist Java runtimes such as those implementing the Real Time Specification for Java (RTSJ) have multiple heaps. A single physical heap can be split up into logical sections depending on the garbage collection (GC) algorithm used to manage the heap memory. These sections are typically implemented as contiguous slabs of native memory that are under the control of the Java memory manager (which includes the garbage collector).
The heap''s size is controlled from the Java command line using the -Xmx and -Xms options (mx is the maximum size of the heap, ms is the initial size). Although the logical heap (the area of memory that is actively used) can grow and shrink according to the number of objects on the heap and the amount of time spent in GC, the amount of native memory used remains constant and is dictated by the -Xmx value: the maximum heap size. Most GC algorithms rely on the heap being allocated as a contiguous slab of memory, so it''s impossible to allocate more native memory when the heap needs to expand. All heap memory must be reserved up front.
Reserving native memory is not the same as allocating it. When native memory is reserved, it is not backed with physical memory or other storage. Although reserving chunks of the address space will not exhaust physical resources, it does prevent that memory from being used for other purposes. A leak caused by reserving memory that is never used is just as serious as leaking allocated memory.
Some garbage collectors minimise the use of physical memory by decommitting (releasing the backing storage for) parts of the heap as the used area of heap shrinks.
More native memory is required to maintain the state of the memory-management system maintaining the Java heap. Data structures must be allocated to track free storage and record progress when collecting garbage. The exact size and nature of these data structures varies with implementation, but many are proportional to the size of the heap. The Just-in-time (JIT) compiler
The JIT compiler compiles Java bytecode to optimised native executable code at run time. This vastly improves the run-time speed of Java runtimes and allows Java applications to run at speeds comparable to native code.
Bytecode compilation uses native memory (in the same way that a static compiler such as gcc requires memory to run), but both the input (the bytecode) and the output (the executable code) from the JIT must also be stored in native memory. Java applications that contain many JIT-compiled methods use more native memory than smaller applications. Classes and classloaders
Java applications are composed of classes that define object structure and method logic. They also use classes from the Java runtime class libraries (such as java.lang.String) and may use third-party libraries. These classes need to be stored in memory for as long as they are being used.
How classes are stored varies by implementation. The Sun JDK uses the permanent generation (PermGen) heap area. The IBM implementation from Java 5 onward allocates slabs of native memory for each classloader and stores the class data in there. Modern Java runtimes have technologies such as class sharing that may require mapping areas of shared memory into the address space. To understand how these allocation mechanisms affect your Java runtime''s native footprint, you need to read the technical documentation for that implementation. However, some universal truths affect all implementations.
At the most basic level, using more classes uses more memory. (This may mean your native memory usage just increases or that you must explicitly resize an area — such as the PermGen or the shared-class cache — to allow all the classes to fit in.) Remember that it''s not only your application that needs to fit; frameworks, application servers, third-party libraries, and Java runtimes contain classes that are loaded on demand and occupy space.
Java runtimes can unload classes to reclaim space, but only under strict conditions. It''s impossible to unload a single class; classloaders are unloaded instead, taking all the classes they loaded with them. A classloader can be unloaded only if:
The Java heap contains no references to the java.lang.ClassLoader object that represents that classloader.
The Java heap contains no references to any of the java.lang.Class objects that represent classes loaded by that classloader.
No objects of any class loaded by that classloader are alive (referenced) on the Java heap.
It''s worth noting that the three default classloaders that the Java runtime creates for all Java applications — bootstrap, extension, and application — can never meet these criteria; therefore, any system classes (such as java.lang.String) or any application classes loaded through the application classloader can''t be released at run time.
Even when a classloader is eligible for collection, the runtime collects classloaders only as part of a GC cycle. Some implementations unload classloaders only on some GC cycles.
It''s also possible for classes to be generated at run time, without you realising it. Many JEE applications use JavaServer Pages (JSP) technology to produce Web pages. Using JSP generates a class for each .jsp page executed that will last the lifetime of the classloader that loaded them — typically the lifetime of the Web application.
Another common way to generate classes is by using Java reflection. The way reflection works varies among Java implementations, but Sun and IBM implementations both use the method I''ll describe now.
When using the java.lang.reflect API, the Java runtime must connect the methods of a reflecting object (such as java.lang.reflect.Field) to the object or class being reflected on. This can be done by using a Java Native Interface (JNI) accessor that requires very little setup but is slow to use, or by building a class dynamically at run time for each object type you want to reflect on. The latter method is slower to set up but faster to run, making it ideal for applications that reflect on a particular class often.
The Java runtime uses the JNI method the first few times a class is reflected on, but after being used a number of times, the accessor is inflated into a bytecode accessor, which involves building a class and loading it through a new classloader. Doing lots of reflection can cause many accessor classes and classloaders to be created. Holding references to the reflecting objects causes these classes to stay alive and continue occupying space. Because creating the bytecode accessors is quite slow, the Java runtime can cache these accessors for later use. Some applications and frameworks also cache reflection objects, thereby increasing their native footprint. JNI
JNI allows native code (applications written in native compiled languages such as C and C++) to call Java methods and vice versa. The Java runtime itself relies heavily on JNI code to implement class-library functions such as file and network I/O. A JNI application can increase a Java runtime''s native footprint in three ways:
The native code for a JNI application is compiled into a shared library or executable that''s loaded into the process address space. Large native applications can occupy a significant chunk of the process address space simply by being loaded.
The native code must share the address space with the Java runtime. Any native-memory allocations or memory mappings performed by the native code take memory away from the Java runtime.
Certain JNI functions can use native memory as part of their normal operation. The GetTypeArrayElements and GetTypeArrayRegion functions can copy Java heap data into native memory buffers for the native code to work with. Whether a copy is made or not depends on the runtime implementation. (The IBM Developer Kit for Java 5.0 and higher makes a native copy.) Accessing large amounts of Java heap data in this manner can use a correspondingly large amount of native heap.
NIO
The new I/O (NIO) classes added in Java 1.4 introduced a new way of performing I/O based on channels and buffers. As well as I/O buffers backed by memory on the Java heap, NIO added support for direct ByteBuffers (allocated using the java.nio.ByteBuffer.allocateDirect() method) that are backed by native memory rather than Java heap. Direct ByteBuffers can be passed directly to native OS library functions for performing I/O — making them significantly faster in some scenarios because they can avoid copying data between Java heap and native heap.
It''s easy to become confused about where direct ByteBuffer data is being stored. The application still uses an object on the Java heap to orchestrate I/O operations, but the buffer that holds the data is held in native memory — the Java heap object only contains a reference to the native heap buffer. A non-direct ByteBuffer holds its data in a byte[] array on the Java heap. Figure 4 shows the difference between direct and non-direct ByteBuffer objects: Figure 4. Memory topology for direct and non-direct java.nio.ByteBuffers ByteBuffer memory arrangements
Direct ByteBuffer objects clean up their native buffers automatically but can only do so as part of Java heap GC — so they do not automatically respond to pressure on the native heap. GC occurs only when the Java heap becomes so full it can''t service a heap-allocation request or if the Java application explicitly requests it (not recommended because it causes performance problems).
The pathological case would be that the native heap becomes full and one or more direct ByteBuffers are eligible for GC (and could be freed to make some space on the native heap), but the Java heap is mostly empty so GC doesn''t occur. Threads
Every thread in an application requires memory to store its stack (the area of memory used to hold local variables and maintain state when calling functions). Every Java thread requires stack space to run. Depending on implementation, a Java thread can have separate native and Java stacks. In addition to stack space, each thread requires some native memory for thread-local storage and internal data structures.
The stack size varies by Java implementation and by architecture. Some implementations allow you to specify the stack size for Java threads. Values between 256KB and 756KB are typical.
Although the amount of memory used per thread is quite small, for an application with several hundred threads, the total memory use for thread stacks can be large. Running an application with many more threads than available processors to run them is usually inefficient and can result in poor performance as well as increased memory usage. How can I tell if I''m running out of native memory?
A Java runtime copes quite differently with running out of Java heap compared to running out of native heap, although both conditions can present with similar symptoms. A Java application finds it extremely difficult to function when the Java heap is exhausted — because it''s difficult for a Java application to do anything without allocating objects. The poor GC performance and OutOfMemoryErrors that signify a full Java heap are produced as soon as the Java heap fills up.
In contrast, once a Java runtime has started up and the application is in steady state, it can continue to function with complete native-heap exhaustion. It doesn''t necessarily show any odd behaviour, because actions that require a native-memory allocation are much rarer than actions that require Java-heap allocations. Although actions that require native memory vary by JVM implementation, some popular examples are: starting a thread, loading a class, and performing certain kinds of network and file I/O.
Native out-of-memory behaviour is also less consistent than Java heap out-of-memory behaviour, because there''s no single point of control for native heap allocations. Whereas all Java heap allocations are under control of the Java memory-management system, any native code — whether it is inside the JVM, the Java class libraries, or application code — can perform a native-memory allocation and have it fail. The code that attempts the allocation can then handle it however its designer wants: it could throw an OutOfMemoryError through the JNI interface, print a message on the screen, silently fail and try again later, or do something else.
The lack of predictable behaviour means there''s no one simple way to identify native-memory exhaustion. Instead, you need to use data from the OS and from the Java runtime to confirm the diagnosis. Examples of running out of native memory
To help you see how native-memory exhaustion affects the Java implementation you''re using, this article''s sample code (see Download) contains some Java programs that trigger native-heap exhaustion in different ways. The examples use a native library written in C to consume all of the native address space and then try to perform some action that uses native memory. The examples are supplied already built, although instructions on compiling them are provided in the README.html file in the sample package''s top-level directory.
The com.ibm.jtc.demos.NativeMemoryGlutton class provides the gobbleMemory() method, which calls malloc in a loop until nearly all native memory is exhausted. When it has completed its task, it prints the number of bytes allocated to standard error like this: 1
Allocated 1953546736 bytes of native memory before running out
The output for each demo has been captured for a Sun and an IBM Java runtime running on 32-bit Windows. The binaries provided have been tested on:
Linux x86
Linux PPC 32
Linux 390 31
Windows x86
The following version of the Sun Java runtime was used to capture the output: 1 2 3
java version "1.5.0_11" Java(TM) 2 Runtime Environment, Standard Edition (build 1.5.0_11-b03) Java HotSpot(TM) Client VM (build 1.5.0_11-b03, mixed mode)
The version of the IBM Java runtime used was: 1 2 3 4 5 6 7 8 9
java version "1.5.0" Java(TM) 2 Runtime Environment, Standard Edition (build pwi32devifx-20071025 (SR 6b)) IBM J9 VM (build 2.3, J2RE 1.5.0 IBM J9 2.3 Windows XP x86-32 j9vmwi3223-2007100 7 (JIT enabled) J9VM - 20071004_14218_lHdSMR JIT - 20070820_1846ifx1_r8 GC - 200708_10) JCL - 20071025 Trying to start a thread when out of native memory
The com.ibm.jtc.demos.StartingAThreadUnderNativeStarvation class tries to start a thread when the process address space is exhausted. This is a common way to discover that your Java process is out of memory because many applications start threads throughout their lifetime.
The output from the StartingAThreadUnderNativeStarvation demo when run on the IBM Java runtime is: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
Allocated 1019394912 bytes of native memory before running out JVMDUMP006I Processing Dump Event "systhrow", detail "java/lang/OutOfMemoryError" - Please Wait. JVMDUMP007I JVM Requesting Snap Dump using ''C:\Snap0001.20080323.182114.5172.trc'' JVMDUMP010I Snap Dump written to C:\Snap0001.20080323.182114.5172.trc JVMDUMP007I JVM Requesting Heap Dump using ''C:\heapdump.20080323.182114.5172.phd'' JVMDUMP010I Heap Dump written to C:\heapdump.20080323.182114.5172.phd JVMDUMP007I JVM Requesting Java Dump using ''C:\javacore.20080323.182114.5172.txt'' JVMDUMP010I Java Dump written to C:\javacore.20080323.182114.5172.txt JVMDUMP013I Processed Dump Event "systhrow", detail "java/lang/OutOfMemoryError". java.lang.OutOfMemoryError: ZIP006:OutOfMemoryError, ENOMEM error in ZipFile.open at java.util.zip.ZipFile.open(Native Method) at java.util.zip.ZipFile.<init>(ZipFile.java:238) at java.util.jar.JarFile.<init>(JarFile.java:169) at java.util.jar.JarFile.<init>(JarFile.java:107) at com.ibm.oti.vm.AbstractClassLoader.fillCache(AbstractClassLoader.java:69) at com.ibm.oti.vm.AbstractClassLoader.getResourceAsStream(AbstractClassLoader.java:113) at java.util.ResourceBundle$1.run(ResourceBundle.java:1101) at java.security.AccessController.doPrivileged(AccessController.java:197) at java.util.ResourceBundle.loadBundle(ResourceBundle.java:1097) at java.util.ResourceBundle.findBundle(ResourceBundle.java:942) at java.util.ResourceBundle.getBundleImpl(ResourceBundle.java:779) at java.util.ResourceBundle.getBundle(ResourceBundle.java:716) at com.ibm.oti.vm.MsgHelp.setLocale(MsgHelp.java:103) at com.ibm.oti.util.Msg$1.run(Msg.java:44) at java.security.AccessController.doPrivileged(AccessController.java:197) at com.ibm.oti.util.Msg.<clinit>(Msg.java:41) at java.lang.J9VMInternals.initializeImpl(Native Method) at java.lang.J9VMInternals.initialize(J9VMInternals.java:194) at java.lang.ThreadGroup.uncaughtException(ThreadGroup.java:764) at java.lang.ThreadGroup.uncaughtException(ThreadGroup.java:758) at java.lang.Thread.uncaughtException(Thread.java:1315) K0319java.lang.OutOfMemoryError: Failed to fork OS thread at java.lang.Thread.startImpl(Native Method) at java.lang.Thread.start(Thread.java:979) at com.ibm.jtc.demos.StartingAThreadUnderNativeStarvation.main( StartingAThreadUnderNativeStarvation.java:22)
Calling java.lang.Thread.start() tries to allocate memory for a new OS thread. This attempt fails and causes an OutOfMemoryError to be thrown. The JVMDUMP lines notify the user that the Java runtime has produced its standard OutOfMemoryError debugging data.
Trying to handle the first OutOfMemoryError caused a second — the :OutOfMemoryError, ENOMEM error in ZipFile.open. Multiple OutOfMemoryErrors are common when the native process memory is exhausted. The Failed to fork OS thread message is probably the most commonly encountered sign of running out of native memory.
The examples supplied with this article trigger clusters of OutOfMemoryErrors that are more severe than anything you are likely to see with your own applications. This is partly because virtually all of the native memory has been used up and, unlike in a real application, that memory isn''t freed later. In a real application, as OutOfMemoryErrors are thrown, threads shut down and the native-memory pressure is likely to be relieved for a bit, giving the runtime a chance to handle the error. The trivial nature of the test cases also means that whole sections of the class library (such as the security system) have not been initialised yet — and their initialisation is driven by the runtime trying to handle the out-of-memory condition. In a real application, you may see some of the errors shown here, but it''s unlikely you will see them all together.
When the same test case is executed on the Sun Java runtime, the following console output is produced: 1 2 3 4 5 6
Allocated 1953546736 bytes of native memory before running out Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread at java.lang.Thread.start0(Native Method) at java.lang.Thread.start(Thread.java:574) at com.ibm.jtc.demos.StartingAThreadUnderNativeStarvation.main( StartingAThreadUnderNativeStarvation.java:22)
Although the stack trace and the error message are slightly different, the behaviour is essentially the same: the native allocation fails and a java.lang.OutOfMemoryError is thrown. The only thing that distinguishes the OutOfMemoryErrors thrown in this scenario from those thrown because of Java-heap exhaustion is the message. Trying to allocate a direct ByteBuffer when out of native memory
The com.ibm.jtc.demos.DirectByteBufferUnderNativeStarvation class tries to allocate a direct (that is, natively backed) java.nio.ByteBuffer object when the address space is exhausted. When run on the IBM Java runtime, it produces the following output: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Allocated 1019481472 bytes of native memory before running out JVMDUMP006I Processing Dump Event "uncaught", detail "java/lang/OutOfMemoryError" - Please Wait. JVMDUMP007I JVM Requesting Snap Dump using ''C:\Snap0001.20080324.100721.4232.trc'' JVMDUMP010I Snap Dump written to C:\Snap0001.20080324.100721.4232.trc JVMDUMP007I JVM Requesting Heap Dump using ''C:\heapdump.20080324.100721.4232.phd'' JVMDUMP010I Heap Dump written to C:\heapdump.20080324.100721.4232.phd JVMDUMP007I JVM Requesting Java Dump using ''C:\javacore.20080324.100721.4232.txt'' JVMDUMP010I Java Dump written to C:\javacore.20080324.100721.4232.txt JVMDUMP013I Processed Dump Event "uncaught", detail "java/lang/OutOfMemoryError". Exception in thread "main" java.lang.OutOfMemoryError: Unable to allocate 1048576 bytes of direct memory after 5 retries at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:167) at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:303) at com.ibm.jtc.demos.DirectByteBufferUnderNativeStarvation.main( DirectByteBufferUnderNativeStarvation.java:29) Caused by: java.lang.OutOfMemoryError at sun.misc.Unsafe.allocateMemory(Native Method) at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:154) ... 2 more
In this scenario, an OutOfMemoryError is thrown that triggers the default error documentation. The OutOfMemoryError reaches the top of the main thread''s stack and is printed on stderr.
When run on the Sun Java runtime, this test case produces the following console output: 1 2 3 4 5 6 7
Allocated 1953546760 bytes of native memory before running out Exception in thread "main" java.lang.OutOfMemoryError at sun.misc.Unsafe.allocateMemory(Native Method) at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:99) at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:288) at com.ibm.jtc.demos.DirectByteBufferUnderNativeStarvation.main( DirectByteBufferUnderNativeStarvation.java:29) Debugging approaches and techniques
The first thing to do when faced with a java.lang.OutOfMemoryError or an error message about lack of memory is to determine which kind of memory has been exhausted. The easiest way to do this is to first check if the Java heap is full. If the Java heap did not cause the OutOfMemory condition, then you should analyse the native-heap usage.
Checking your vendor''s documentation
The guidelines in this article are general debugging principles applied to understanding native out-of-memory scenarios. Your runtime vendor may supply its own debugging instructions that it expects you to follow when working with its support teams. If you are raising a problem ticket with your runtime vendor (including IBM), always check its debugging and diagnostic documentation to see what steps you are expected to take when submitting a problem report. Checking the Java heap
The method for checking the heap utilisation varies among Java implementations. On IBM implementations of Java 5 and 6, the javacore file produced when the OutOfMemoryError is thrown will tell you. The javacore file is usually produced in the working directory of the Java process and has a name of the form javacore.date.time.pid.txt. If you open the file in a text editor, you can find a section that looks like this: 1 2 3 4
0SECTION MEMINFO subcomponent dump routine NULL ================================= 1STHEAPFREE Bytes of Heap Space Free: 416760 1STHEAPALLOC Bytes of Heap Space Allocated: 1344800
This section shows how much Java heap was free when the javacore was produced. Note that the values are in hexadecimal format. If the OutOfMemoryError was thrown because an allocation could not be satisfied, then the GC trace section will show this: 1 2 3
1STGCHTYPE GC History
3STHSTTYPE 09:59:01:632262775 GMT j9mm.80 - J9AllocateObject() returning NULL! 32 bytes requested for object of class 00147F80
J9AllocateObject() returning NULL! means that the Java heap allocation routine completed unsuccessfully and an OutOfMemoryError will be thrown.
It is also possible for an OutOfMemoryError to be thrown because the garbage collector is running too frequently (a sign that the heap is full and the Java application will be making little or no progress). In this case, you would expect the Heap Space Free value to be very small, and the GC trace will show one of these messages: 1 2 3
1STGCHTYPE GC History
3STHSTTYPE 09:59:01:632262775 GMT j9mm.83 - Forcing J9AllocateObject() to fail due to excessive GC 1 2 3
1STGCHTYPE GC History
3STHSTTYPE 09:59:01:632262775 GMT j9mm.84 - Forcing J9AllocateIndexableObject() to fail due to excessive GC
When the Sun implementation runs out of Java heap memory, it uses the exception message to show that it is Java heap that is exhausted: 1
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
IBM and Sun implementations both have a verbose GC option that produces trace data showing how full the heap is at every GC cycle. This information can be plotted with a tool such as the IBM Monitoring and Diagnostic Tools for Java - Garbage Collection and Memory Visualizer (GCMV) to show if the Java heap is growing. Measuring native heap usage
If you have determined that your out-of-memory condition was not caused by Java-heap exhaustion, the next stage is to profile your native-memory usage.
The PerfMon tool supplied with Windows allows you to monitor and record many OS and process metrics, including native-memory use. It allows counters to be tracked in real time or stored in a log file to be reviewed offline. Use the Private Bytes counter to show the total address-space usage. If this approaches the limit of the user space (between 2 and 3GB as previously discussed), you should expect to see native out-of-memory conditions.
Linux has no PerfMon equivalent, but you have several alternatives. Command-line tools such as ps, top, and pmap can show an application''s native-memory footprint. Although getting an instant snapshot of a process''s memory usage is useful, you get a much greater understanding of how native memory is being used by plotting memory use over time. One way to do this is to use GCMV.
GCMV was originally written to plot verbose GC logs, allowing users to view changes in Java heap usage and GC performance when tuning the garbage collector. GCMV was later extended to allow it to plot other data sources, including Linux and AIX native-memory data. GCMV is shipped as a plug-in for the IBM Support Assistant (ISA).
To plot a Linux native-memory profile with GCMV, you must first collect native-memory data using a script. GCMV''s Linux native-memory parser reads output from the Linux ps command interleaved with time stamps. A script is provided in the GCMV help documentation that collects data in the correct form. To find the script:
Download and install ISA Version 4 (or above) and install the GCMV tool plug-in.
Start ISA.
Click Help >> Help Contents from the menu bar to open the ISA help menu.
Find the Linux native-memory instructions in the left-hand pane under Tool:IBM Monitoring and Diagnostic Tools for Java - Garbage Collection and Memory Visualizer >> Using the Garbage Collection and Memory Visualizer >> Supported Data Types >> Native memory >> Linux native memory.
Figure 5 shows the location of the script in the ISA help file. If you do not have the GCMV Tool entry in your help file, it is most likely you do not have the GCMV plug-in installed. Figure 5. Location of Linux native memory data capture script in ISA help dialog IBM Support Assistant Help File
The script provided in the GCMV help uses a ps command that only works with recent versions of ps. On some older Linux distributions, the command in the help file will not produce the correct information. To check the behaviour on your Linux distribution, try running ps -o pid,vsz=VSZ,rss=RSS. If your version of ps supports the new command-line argument syntax, the output will look like this: 1 2 3
PID VSZ RSS 5826 3772 1960 5675 2492 760
If your version of ps does not support the new syntax, the output will look like this: 1 2 3
PID VSZ,rss=RSS 5826 3772 5674 2488
If you are running an older version of ps, modify the native memory script replacing the line 1
ps -p $PID -o pid,vsz=VSZ,rss=RSS
with 1
ps -p $PID -o pid,vsz,rss
Copy the script from the help panel into a file (in this example called memscript.sh), find the process id (PID) of the Java process you want to monitor (in this example, 1234), and run: 1
./memscript.sh 1234 > ps.out
This will write the native-memory log into ps.out. To plot memory usage:
In ISA, select Analyze Problem from the Launch Activity drop-down menu.
Select the Tools tab near the top of the Analyze Problem panel.
Select IBM Monitoring and Diagnostic Tools for Java - Garbage Collection and Memory Visualizer.
Click the Launch button near the bottom of the tools panel.
Click the Browse button and locate the log file. Click OK to launch GCMV.
Once you have the profile of the native-memory use over time, you need to decide whether you are seeing a native-memory leak or are just trying to do too much in the available space. The native-memory footprint for even a well-behaved Java application is not constant from start-up. Several of the Java runtime systems — particularly the JIT compiler and classloaders — initialise over time, which can consume native memory. The memory growth from initialisation will plateau, but if your scenario has an initial native-memory footprint close to the limit of the address space, then this warm-up phase can be enough to cause native out-of-memory. Figure 6 shows an example GCMV native-memory plot from a Java stress test with the warm-up phase highlighted. Figure 6. Example Linux native-memory plot from GCMV showing warm-up phase GCMV native memory plot
It''s also possible to have a native footprint that varies with workload. If your application creates more threads to handle incoming workload or allocates native-backed storage such as direct ByteBuffers proportionally to how much load is being applied to your system, it''s possible that you will run out of native memory under high load.
Running out of native memory because of JVM warm-up-phase native-memory growth, and growth proportional to load, are examples of trying to do too much in the available space. In these scenarios your options are:
Reduce your native-memory use. Reducing your Java heap size is a good place to start.
Restrict your native-memory use. If you have native-memory growth that changes with load, find a way to cap the load or the resources that are allocated because of it.
Increase the amount of address space available to you. You can do this by tuning your OS (increasing your user space with the /3GB switch on Windows or a hugemem kernel on Linux, for example), changing platform (Linux typically has more user space than Windows), or moving to a 64-bit OS.
A genuine native-memory leak manifests as a continual growth in native heap that doesn''t drop when load is removed or when the garbage collector runs. The rate of memory leak can vary with load, but the total leaked memory will not drop. Memory that is leaked is unlikely to be referenced, so it can be swapped out and stay swapped out.
When faced with a leak, your options are limited. You can increase the amount of user space (so there is more room to leak into) but that will only buy you time before you eventually run out of memory. If you have enough physical memory and address space, you can allow the leak to continue on the basis that you will restart your application before the process address space is exhausted. What''s using my native memory?
Once you have determined you are running out of native memory, the next logical question is: What''s using that memory? Answering this question is hard because, by default, Windows and Linux do not store information about which code path is allocated a particular chunk of memory.
Your first step when trying to understand where your native memory has gone is to work out roughly how much native memory will be used based on your Java settings. An accurate value is difficult to work out without in-depth knowledge of the JVM''s workings, but you can make a rough estimate based on the following guidelines:
The Java heap occupies at least the -Xmx value.
Each Java thread requires stack space. Stack size varies among implementations, but with default settings, each thread could occupy up to 756KB of native memory.
Direct ByteBuffers occupy at least the values supplied to the allocate() routine.
If your total is much less than your maximum user space, you are not necessarily safe. Many other components in a Java runtime could allocate enough memory to cause problems; however, if your initial calculations suggest you are close to your maximum user space, it is likely that you will have native-memory issues. If you suspect you have a native-memory leak or you want to understand exactly where your memory is going, several tools can help.
Microsoft provides the UMDH (user-mode dump heap) and LeakDiag tools for debugging native-memory growth on Windows. They both work in a similar way: recording which code path allocated a particular area of memory and providing a way to locate sections of code that allocate memory that isn''t freed later. I refer you to the article "Umdhtools.exe: How to use Umdh.exe to find memory leaks on Windows" for instructions on using UMDH. In this article, I''ll focus on what the output of UMDH looks like when run against a leaky JNI application.
The samples pack for this article contains a Java application called LeakyJNIApp; it runs in a loop calling a JNI method that leaks native memory. The UMDH command takes a snapshot of the current native heap together with native stack traces of the code paths that allocated each region of memory. By taking two snapshots and using the UMDH tool to analyse the difference, you get a report of the heap growth between the two snapshots.
For LeakyJNIApp, the difference file contains this information: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
// _NT_SYMBOL_PATH set by default to C:\WINDOWS\symbols // // Each log entry has the following syntax: // // + BYTES_DELTA (NEW_BYTES - OLD_BYTES) NEW_COUNT allocs BackTrace TRACEID // + COUNT_DELTA (NEW_COUNT - OLD_COUNT) BackTrace TRACEID allocations // ... stack trace ... // // where: // // BYTES_DELTA - increase in bytes between before and after log // NEW_BYTES - bytes in after log // OLD_BYTES - bytes in before log // COUNT_DELTA - increase in allocations between before and after log // NEW_COUNT - number of allocations in after log // OLD_COUNT - number of allocations in before log // TRACEID - decimal index of the stack trace in the trace database // (can be used to search for allocation instances in the original // UMDH logs). //
- 412192 ( 1031943 - 619751) 963 allocs BackTrace00468
Total increase == 412192
The important line is + 412192 ( 1031943 - 619751) 963 allocs BackTrace00468. It shows that one backtrace has made 963 allocations that have not been freed — that have consumed 412192 bytes of memory. By looking in one of the snapshot files, you can associate BackTrace00468 with the meaningful code path. Searching for BackTrace00468 in the first snapshot shows: 1 2 3 4 5
000000AD bytes in 0x1 allocations (@ 0x00000031 + 0x0000001F) by: BackTrace00468 ntdll!RtlpNtMakeTemporaryKey+000074D0 ntdll!RtlInitializeSListHead+00010D08 ntdll!wcsncat+00000224 leakyjniapp!Java_com_ibm_jtc_demos_LeakyJNIApp_nativeMethod+000000D6
This shows the leak coming from the leakyjniapp.dll module in the Java_com_ibm_jtc_demos_LeakyJNIApp_nativeMethod function.
At the time of writing, Linux does not have a UMDH or LeakDiag equivalent. But there are still ways to debug native-memory leaks on Linux. The many memory debuggers available on Linux typically fall into one of the following categories:
Preprocessor level. These require a header to be compiled in with the source under test. It''s possible to recompile your own JNI libraries with one of these tools to track a native memory leak in your code. Unless you have the source code for the Java runtime itself, this cannot find a leak in the JVM (and even then compiling this kind of tool into a large project like a JVM would almost certainly be difficult and time-consuming). Dmalloc is an example of this kind of tool.
Linker level. These require the binaries under test to be relinked with a debugging library. Again, this is feasible for individual JNI libraries but not recommended for entire Java runtimes because it is unlikely that the runtime vendor would support you running with modified binaries. Ccmalloc is an example of this kind of tool.
Runtime-linker level. These use the LD_PRELOAD environment variable to preload a library that replaces the standard memory routines with instrumented versions. They do not require recompilation or relinking of source code, but many of them do not work well with Java runtimes. A Java runtime is a complicated system that can use memory and threads in unusual ways that can confuse or break this kind of tool. It is worth experimenting with a few to see if they work in your scenario. NJAMD is an example of this kind of tool.
Emulator-based. The Valgrind memcheck tool is the only example of this type of memory debugger. It emulates the underlying processor in a similar way to how a Java runtime emulates the JVM. It is possible to run Java under Valgrind, but the heavy performance impact (10 to 30 times slower) means that it would be very hard to run large, complicated Java applications in this manner. Valgrind is currently available on Linux x86, AMD64, PPC 32, and PPC 64. If you use Valgrind, try to narrow down the problem to the smallest test case you can (preferably cutting out the entire Java runtime if possible) before using it.
For simple scenarios that can tolerate the performance overhead, Valgrind memcheck is the most simple and user-friendly of the available free tools. It can provide a full stack trace for code paths that are leaking memory in the same way that UMDH can on Windows.
The LeakyJNIApp is simple enough to run under Valgrind. The Valgrind memcheck tool can print out a summary of leaked memory when the emulated program ends. By default, the LeakyJNIApp program runs indefinitely; to make it shut down after a fixed time period, pass the run time in seconds as the only command-line argument.
Some Java runtimes use thread stacks and processor registers in unusual ways; this can confuse some debugging tools, which expect native programs to abide by standard conventions of register use and stack structure. When using Valgrind to debug leaking JNI applications, you may find that many warnings are thrown up about the use of memory, and some thread stacks will look odd; these are due to the way the Java runtime structures its data internally and are nothing to worry about.
To trace the LeakyJNIApp with the Valgrind memcheck tool, use this command (on a single line): 1 2
valgrind --trace-children=yes --leak-check=full java -Djava.library.path=. com.ibm.jtc.demos.LeakyJNIApp 10
The --trace-children=yes option to Valgrind makes it trace any processes that are started by Java launcher. Some versions of the Java launcher reexecute themselves (they restart themselves from the beginning, again having set environment variables to change behaviour). If you don''t specify --trace-children, you might not trace the actual Java runtime.
The --leak-check=full option requests that full stack traces of leaking areas of code are printed at the end of the run, rather than just summarising the state of the memory.
Valgrind prints many warnings and errors while the command runs (most of which are uninteresting in this context), and finally prints a list of leaking call stacks in ascending order of amount of memory leaked. The end of the summary section of the Valgrind output for LeakyJNIApp on Linux x86 is: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50
==20494== 8,192 bytes in 8 blocks are possibly lost in loss record 36 of 45 ==20494== at 0x4024AB8: malloc (vg_replace_malloc.c:207) ==20494== by 0x460E49D: Java_com_ibm_jtc_demos_LeakyJNIApp_nativeMethod (in /home/andhall/LeakyJNIApp/libleakyjniapp.so) ==20494== by 0x535CF56: ??? ==20494== by 0x46423CB: gpProtectedRunCallInMethod (in /usr/local/ibm-java2-i386-50/jre/bin/libj9vm23.so) ==20494== by 0x46441CF: signalProtectAndRunGlue (in /usr/local/ibm-java2-i386-50/jre/bin/libj9vm23.so) ==20494== by 0x467E0D1: j9sig_protect (in /usr/local/ibm-java2-i386-50/jre/bin/libj9prt23.so) ==20494== by 0x46425FD: gpProtectAndRun (in /usr/local/ibm-java2-i386-50/jre/bin/libj9vm23.so) ==20494== by 0x4642A33: gpCheckCallin (in /usr/local/ibm-java2-i386-50/jre/bin/libj9vm23.so) ==20494== by 0x464184C: callStaticVoidMethod (in /usr/local/ibm-java2-i386-50/jre/bin/libj9vm23.so) ==20494== by 0x80499D3: main (in /usr/local/ibm-java2-i386-50/jre/bin/java) ==20494== ==20494== ==20494== 65,536 (63,488 direct, 2,048 indirect) bytes in 62 blocks are definitely lost in loss record 42 of 45 ==20494== at 0x4024AB8: malloc (vg_replace_malloc.c:207) ==20494== by 0x460E49D: Java_com_ibm_jtc_demos_LeakyJNIApp_nativeMethod (in /home/andhall/LeakyJNIApp/libleakyjniapp.so) ==20494== by 0x535CF56: ??? ==20494== by 0x46423CB: gpProtectedRunCallInMethod (in /usr/local/ibm-java2-i386-50/jre/bin/libj9vm23.so) ==20494== by 0x46441CF: signalProtectAndRunGlue (in /usr/local/ibm-java2-i386-50/jre/bin/libj9vm23.so) ==20494== by 0x467E0D1: j9sig_protect (in /usr/local/ibm-java2-i386-50/jre/bin/libj9prt23.so) ==20494== by 0x46425FD: gpProtectAndRun (in /usr/local/ibm-java2-i386-50/jre/bin/libj9vm23.so) ==20494== by 0x4642A33: gpCheckCallin (in /usr/local/ibm-java2-i386-50/jre/bin/libj9vm23.so) ==20494== by 0x464184C: callStaticVoidMethod (in /usr/local/ibm-java2-i386-50/jre/bin/libj9vm23.so) ==20494== by 0x80499D3: main (in /usr/local/ibm-java2-i386-50/jre/bin/java) ==20494== ==20494== LEAK SUMMARY: ==20494== definitely lost: 63,957 bytes in 69 blocks. ==20494== indirectly lost: 2,168 bytes in 12 blocks. ==20494== possibly lost: 8,600 bytes in 11 blocks. ==20494== still reachable: 5,156,340 bytes in 980 blocks. ==20494== suppressed: 0 bytes in 0 blocks. ==20494== Reachable blocks (those to which a pointer was found) are not shown. ==20494== To see them, rerun with: --leak-check=full --show-reachable=yes
The second line of the stacks shows that the memory was leaked by the com.ibm.jtc.demos.LeakyJNIApp.nativeMethod() method.
Several proprietary debugging applications that can debug native-memory leaks are also available. More tools (both open-source and proprietary) are being developed all the time, and it''s worth researching the current state of the art.
Currently debugging native-memory leaks on Linux with the freely available tools is more challenging than doing the same on Windows. Whereas UMDH allows native leaks on Windows to be debugged in situ, on Linux you will probably need to do some traditional debugging rather than rely on a tool to solve the problem for you. Here are some suggested debugging steps:
Extract a test case. Produce a stand-alone environment that you can reproduce the native leak with. It will make debugging much simpler.
Narrow the test case as far as possible. Try stubbing out functions to identify which code paths are causing the native leak. If you have your own JNI libraries, try stubbing them out entirely one at a time to determine if they are causing the leak.
Reduce the Java heap size. The Java heap is likely to be the largest consumer of virtual address space in the process. By reducing the Java heap, you make more space available for other users of native memory.
Correlate the native process size. Once you have a plot of native-memory use over time, you can compare it to application workload and GC data. If the leak rate is proportional to the level of load, it suggests that the leak is caused by something on the path of each transaction or operation. If the native process size drops significantly when a GC happens, it suggests that you are not seeing a leak — you are seeing a buildup of objects with a native backing (such as direct ByteBuffers). You can reduce the amount of memory held by native-backed objects by reducing the Java heap size (thereby forcing collections to occur more frequently) or by managing them yourself in an object cache rather than relying on the garbage collector to clean up for you.
If you identify a leak or memory growth that you think is coming out of the Java runtime itself, you may want to engage your runtime vendor to debug further. Removing the limit: Making the change to 64-bit
It is easy to hit native out-of-memory conditions with 32-bit Java runtimes because the address space is relatively small. The 2 to 4GB of user space that 32-bit OSs provide is often less than the amount of physical memory attached to the system, and modern data-intensive applications can easily scale to fill the available space.
If your application cannot be made to fit in a 32-bit address space, you can gain a lot more user space by moving to a 64-bit Java runtime. If you are running a 64-bit OS, then a 64-bit Java runtime will open the door to huge Java heaps and fewer address-space-related headaches. Table 2 lists the user spaces currently available with 64-bit OSs: Table 2. User space sizes on 64-bit OSs OS Default user space size Windows x86-64 8192GB Windows Itanium 7152GB Linux x86-64 500GB Linux PPC64 1648GB Linux 390 64 4EB
Moving to 64-bit is not a universal solution to all native-memory problems, however; you still need sufficient physical memory to hold all of your data. If your Java runtime won''t fit in physical memory then performance will be intolerably poor because the OS is forced to thrash Java runtime data back and forth from swap space. For the same reason, moving to 64-bit is no permanent solution to a memory leak — you are just providing more space to leak into, which will only buy time between forced restarts.
It''s not possible to use 32-bit native code with a 64-bit runtime; any native code (JNI libraries, JVM Tool Interface [JVMTI], JVM Profiling Interface [JVMPI], and JVM Debug Interface [JVMDI] agents) must be recompiled for 64-bit. A 64-bit runtime''s performance can also be slower than the corresponding 32-bit runtime on the same hardware. A 64-bit runtime uses 64-bit pointers (native address references), so the same Java object on 64-bit takes up more space than an object containing the same data on 32-bit. Larger objects mean a bigger heap to hold the same amount of data while maintaining similar GC performance, which makes the OS and hardware caches less efficient. Surprisingly, a larger Java heap does not necessarily mean longer GC pause times, because the amount of live data on the heap might not have increased, and some GC algorithms are more effective with larger heaps.
Some modern Java runtimes contain technology to mitigate 64-bit "object bloat" and improve performance. These features work by using shorter references on 64-bit runtimes. This is called compressed references on IBM implementations and compressed oops on Sun implementations.
A comparative study of Java runtime performance is beyond this article''s scope, but if you are considering a move to 64-bit it is worth testing your application early to understand how it performs. Because changing the address size affects the Java heap, you will need to retune your GC settings on the new architecture rather than just port your existing settings. Conclusion
An understanding of native memory is essential when you design and run large Java applications, but it''s often neglected because it is associated with the grubby hardware and OS details that the Java runtime was designed to save us from. The JRE is a native process that must work in the environment defined by these grubby details. To get the best performance from your Java application, you must understand how the application affects the Java runtime''s native-memory use.
Running out of native memory can look similar to running out of Java heap, but it requires a different set of tools to debug and solve. The key to fixing native-memory issues is to understand the limits imposed by the hardware and OS that your Java application is running on, and to combine this with knowledge of the OS tools for monitoring native-memory use. By following this approach, you''ll be equipped to solve some of the toughest problems your Java application can throw at you.
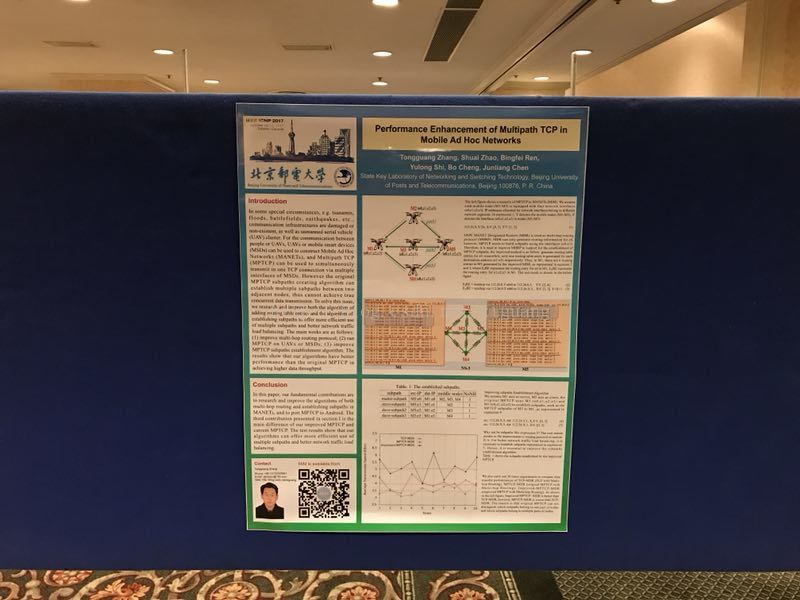
 Performance Enhancement of Multipath TCP in Mobile Ad Hoc Networks")
(OK) Performance Enhancement of Multipath TCP in Mobile Ad Hoc Networks
The 25th IEEE International Conference on Network Protocols (ICNP 2017)
http://ieeexplore.ieee.org/document/8117578/
T. Zhang, S. Zhao, B. Ren, Y. Shi, B. Cheng and J. Chen, "Performance enhancement of multipath TCP in mobile Ad Hoc networks," 2017 IEEE 25th International Conference on Network Protocols (ICNP), Toronto, ON, Canada, 2017, pp. 1-2.
doi: 10.1109/ICNP.2017.8117578
Abstract—In some special circumstances, e.g. tsunamis, floods, battlefields, earthquakes, etc., communication infrastructures are damaged or non-existent, as well as unmanned aerial vehicle (UAV) cluster. For the communication between people or UAVs, UAVs or mobile smart devices (MSDs) can be used to construct Mobile Ad Hoc Networks (MANETs), and Multipath TCP (MPTCP) can be used to simultaneously transmit in one TCP connection via multiple interfaces of MSDs. However the original MPTCP subpaths creating algorithm can establish multiple subpaths between two adjacent nodes, thus cannot achieve true concurrent data transmission. To solve this issue, we research and improve both the algorithm of adding routing table entries and the algorithm of establishing subpaths to offer more efficient use of multiple subpaths and better network traffic load balancing. The main works are as follows: (1) improve multi-hop routing protocol; (2) run MPTCP on UAVs or MSDs; (3) improve MPTCP subpaths establishment algorithm. The results show that our algorithms have better performance than the original MPTCP in achieving higher data throughput.

11g 报错 ORA-27102: out of memory Linux Error: 22: Invalid arg
11g 报错 ORA-27102: out of memory Linux Error: 22: Invalid argument
没事装了个11g玩,安装软件dbca建库使用一切正常。今天启动发现报错
[Oracle@OEL54db11gR2 dbs]$ sqlplus / as sysdba
SQL*Plus: Release 11.2.0.1.0 Production on Thu Nov 22 20:07:45 2012
Copyright (c) 1982, 2009, Oracle. All rights reserved.
Connected to an idle instance.
SQL> startup
ORA-27102: out of memory
Linux Error: 22: Invalid argument
处理流程如下:
1、查看数据库内存大小
[oracle@OEL54db11gR2 ~]$ cd /u01/app/oracle/product/11.2.0/db_1/dbs/
[oracle@OEL54db11gR2 dbs]$ ls
hc_DBUA0.dat init.ora orapworcl peshm_orcl_0
hc_orcl.dat lkORCL peshm_DBUA0_0 spfileorcl.ora
[oracle@OEL54db11gR2 dbs]$ cat spfileorcl.ora
C"挌m盈/CC"6Porcl.__db_cache_size=205520896
orcl.__java_pool_size=4194304
orcl.__large_pool_size=4194304
orcl.__oracle_base=''/u01/app/oracle''#ORACLE_BASE set from environment
orcl.__pga_aggregate_target=218103808
orcl.__sga_target=322961408
orcl.__shared_io_pool_size=0
orcl.__shared_pool_size=100663296
orcl.__streams_pool_size=0
*.audit_file_dest=''/u01/app/oracle/admin/orcl/adump''
*.audit_trail=''db''
*.compatible=''11.2.0.0.0''
*.control_files=''/u01/app/oracle/oradata/orcl/control01.ctl'',''/u01/app/oCC"/racle/oradata/orcl/control02.ctl''
*.db_block_size=8192
*.db_domain=''''
*.db_name=''orcl''
*.diagnostic_dest=''/u01/app/oracle''
*.dispatchers=''(PROTOCOL=TCP) (SERVICE=orclXDB)''
*.memory_target=541065216
*.open_cursors=300
*.processes=150
*.remote_login_passwordfile=''EXCLUSIVE''
*.undo_tablespace=''UNDOTBS1''
2、切换到root用户,,查看内核内存大小
[oracle@OEL54db11gR2 ~]$ su -
Password:
[root@OEL54db11gR2 ~]# vi /etc/sysctl.conf
# Kernel sysctl configuration file for Oracle Enterprise Linux
#
# For binary values, 0 is disabled, 1 is enabled. See sysctl(8) and
# sysctl.conf(5) for more details.
# Controls IP packet forwarding
net.ipv4.ip_forward = 0
# Controls source route verification
net.ipv4.conf.default.rp_filter = 2
# Do not accept source routing
net.ipv4.conf.default.accept_source_route = 0
# Controls the System Request debugging functionality of the kernel
kernel.sysrq = 0
# Controls whether core dumps will append the PID to the core filename
# Useful for debugging multi-threaded applications
kernel.core_uses_pid = 1
# Controls the use of TCP syncookies
net.ipv4.tcp_syncookies = 1
# Controls the maximum size of a message, in bytes
kernel.msgmnb = 65536
# Controls the default maxmimum size of a mesage queue
kernel.msgmax = 65536
# Controls the maximum shared segment size, in bytes
kernel.shmmax = 68719476736
# Controls the maximum number of shared memory segments, in pages
kernel.shmall =322961408
kernel.shmmni = 4096
kernel.sem = 250 32000 100 128
fs.file-max = 6815744
net.ipv4.ip_local_port_range = 9000 65500
net.core.rmem_default = 4194304
net.core.rmem_max = 4194304
net.core.wmem_default = 1048576
"/etc/sysctl.conf" 44L, 1265C written
![]()

An experiment in porting the Android init system to GNU/Linux
https://blog.darknedgy.net/technology/2015/08/05/0-androidinit/
by V.R.
Yes I’m trolling/mocking you anti-systemd retards. That’s what Schopenhauer recommends as a strategy against irrational rhetoric (here of the reactionary kind). I couldn’t care less for irrational people’s reading recommendations.
P.S.: “Self-projection” is psychobabble grounded in no science."
– cjsthompson
Preface
Being the author of the now dead uselessd project, I harbor a knack and appreciation for all things that are useless, or that use less, depending on your point of view.
While sitting in my room drinking absinthe, I was struck with a flash of brilliance. An idea for a project, so devoid of utility, that it is making John Stuart Mill do the tube snake boogie in his grave as we speak.
Take the Android init daemon… and boot a GNU/Linux system with it.
(Slackware Linux, as usual.)
Marvelous.
Now the word shall be able to point at this work and be able to see the true icon I aim to promote, that of Robert Nozick fighting the utility monster.
There are, however, some serious reasons to embark on this project:
- To study the core system platform (low-level userspace) of Android.
- To see how much Android diverts from GNU/Linux in practice, and whether porting its core daemons and libraries is a practical effort to pursue.
- To observe discrepancies between Bionic libc and glibc.
- To figure out what Android brings to the table of init daemons and process managers.
- It’s a fun idea for a hack.
The porting process itself roughly follows this order:
- Write a standalone Makefile.
- Identify all Android-specific interfaces. Insert, rewrite or remove as needed.
- Force everything into C++ semantics (see “The C/C++ quagmire” section below).
- Write a suitable init.rc file.
- Build, copy, append the init parameter on boot and give it a spin.
Android ain’t GNU/Linux, as we shall observe.
Let us dive right in to the overview, then.
Overview of Android init
The Android init daemon’s documentation is rather scant. Technical information about Android in general before its first formal unveiling in November 2007 is difficult to find, but Git logs at googlesource.com do seem to put the origin of Android init to that same time period, 2007-2008.
It thus came out after launchd and Upstart, but also predates systemd.
The intended use case for Android init is quite different compared to most init systems for Unix-like operating systems. Whereas most exist to be proactively used by the sysadmin or to empower them in some way, Android init’s purpose is for device manufacturers to have something they can configure once, shove into an initramfs, fire and never touch again.
As a result, Android init is configured in a thoroughly monolithic fashion, with a long and elaborate boot time logic being codified largely into one file, though it does support basic imports.
It is distinguished by its ad-hoc, line-oriented, section-based configuration language, which Rob Landley once said of (paraphrasing) that it “looks like a shell script, but is not”.
The likely motivation for the language was to encapsulate several common POSIX operations and process manager directives into a mini-shell that can be parsed and executed with minimal overhead, particularly not invoking any environmental and security baggage of a full Unix shell. This made sense for the limited system resources of mobile devices as recently as 2007, and still to this day given the relative heterogeneity of Android installations. Though, one wonders whether writing a basic lexer for chain loading programs, in the vein of execline, would have been a better approach.
Android init is actually composed of three programs: init, ueventd and watchdogd. However, they all hook into the basename of the argv[0] of the init program, meaning that the latter two are usually accessed as symlinks to init.
The init configuration language, as read from /init.rc, has five main statements (or semantic constructs): actions, commands, triggers, services and options.
An action is not unlike a queued event. In fact, it is quite reminiscent of the event mechanism in Upstart jobs. Given Google’s internal usage of Ubuntu as Goobuntu, and their use of Upstart in ChromeOS, it is very likely, though speculation, that the mechanism was influenced from it. The action itself actually just opens a new block scope, whereas the event itself is called a trigger. The init daemon automatically registers several intrinsic triggers like early-init, init and boot, whereas others can be user-defined either through Android system properties (described below), or by using the trigger command within another action.
They follow the syntax of:
on boot
mount tmpfs tmpfs /dev/shm nodev nosuid
exec -- /bin/mount -a
# insert other commands here
A command is a tokened directive which encapsulates a function to some POSIX, Android or init-specific interface, not unlike a command line you would execute from a shell. Commands include exec, copy, write, symlink, chmod, hostname, insmod, mount_all and others.
A service is what you’d expect it to be. It’s a definition encapsulating a system service/daemon or one-shot job that accepts an absolute pathname and program arguments. Within its scope it accepts modifiers called options, which include socket definitions for inetd-like superserver functionality, setenv, user, group, class for creating logical groups and so forth. The options are not as featureful as most server/desktop-oriented init(8)s, largely reflecting the fire-and-forget embedded heritage. For example:
service surfaceflinger /system/bin/surfaceflinger
class core
user system
group graphics drmrpc
onrestart restart zygote
The Android init comes with built-in bootcharting and some scripts to process the output, with its intended usage being booting from an emulator with the -bootchart option and interacting with files on the /data partition. The scripts are unportable, and I have not tested bootcharting itself.
There is no dependency resolution or automatic ordering of any form (other than pre-opening sockets), this being settled once in the init.rc file and tuned per a vendor’s needs. The only way to express service relationships, other than grouping them into classes (though this is more akin to a target or runlevel) is onrestart, so as to resynchronize the state of any services that interact with the one undergoing a restart from the SIGCHLD handler’s state change watcher.
init.rc files can be complemented or overridden on a hardware-specific basis. This is usually done by vendors for specific SoCs or single-boards.
The full list of commands and options can be found registered in the keywords.h file, with the implementations in builtins.cpp, and their invocations in init_parser.cpp.
The main init loop sets $PATH, mounts its reserved socket namespace at /dev/socket, as well as devtmpfs, /dev/pts, procfs and sysfs, sets the SIGCHLD handler for tracking state changes and doing autorestarts, initializes the system property workspace (described below), and then polls on the action queue.
init can optionally display a boot splash, otherwise defaulting on a console message of “A N D R O I D” in the console_init_action() function of init.cpp.
ueventd is a hotplug device node manager which subscribes to kernel uevents from a Netlink channel and performs operations on devtmpfs, much like udev, except lighter weight. It reads its rule sets from a static /uevent.rc file, a stock example of which can be found here. Android understands a kernel command line parameter android.hardwareboot for dispatching device-specific uevent-.rc files on startup. It is symlinked to init and its entry point is ueventd_main() from init.cpp.
ueventd performs as so-called coldboot process, which init explicitly anticipates. It is described in a source code comment in init/devices.cpp as such:
/* Coldboot walks parts of the /sys tree and pokes the uevent files
** to cause the kernel to regenerate device add events that happened
** before init''s device manager was started
**
** We drain any pending events from the netlink socket every time
** we poke another uevent file to make sure we don''t overrun the
** socket''s buffer.
*/
watchdogd is just a really basic interface to the Linux kernel software watchdog (/dev/watchdog), encapsulating various hardware watchdog timers. It pings into the driver’s buffer under a specified clock interval, triggering a system reset if the response interval is not met. It is symlinked to init and its entry point is watchdogd_main() from init.cpp.
In conclusion, Android init implements a small event-driven architecture meant for ease of configurability for device manufacturers and of little relevance to most other perspectives, even reasonably technical users.
The porting process, a.k.a. remove Android-isms from the premises
The C/C++ quagmire
The Android core platform, from 2007 onwards, has haphazardly evolved from pure C into a “C with classes” usage of C++. Much of the code between utility libraries and daemons thus remains mixed, and even within C++ programs (compiled with -std=c++11) the level of C versus C++ constructs varies between source files.
For this port, I decided to force the entire source tree into C++ semantics. One of the classic pitfalls is that C++ does not implicitly convert types from a pointer to void. As such, I needed to statically cast return values of functions like calloc(3) and strrchr(3) in several places.
Some missing header files for constructs like smart pointers had to be included.
Android build system
Android uses a recursive Makefile scheme where there is only one top-level Makefile, and all project subdirectories have an Android.mk file that is ultimately sourced into top-level. A full AOSP build also involves setting up environment variables and some shell macros, but that is outside our scope. More information can be found here.
For our purposes, we want a standalone project with its own Makefile. I quickly hacked up something similar to this repetitive but sufficient cruft:
# ueventd and watchdogd are traditionally symlinked to init
# they''re conditionally invoked depending on basename(argv[0])
# here we just build the binary three-fold
CC=g++
CFLAGS=-Wall -Wextra -Wno-unused-parameter -Wno-write-strings \
-Wno-missing-field-initializers \
-std=c++11 -DGTEST_LINKED_AS_SHARED_LIBRARY=1
LDLIBS=-lpthread -lrt -lgtest
INIT_SRCS = bootchart.cpp builtins.cpp devices.cpp init.cpp init_parser.cpp \
log.cpp parser.cpp signal_handler.cpp util.cpp watchdogd.cpp \
ueventd_parser.cpp ueventd.cpp
UTIL_SRCS = klog.cpp stringprintf.cpp file.cpp strings.cpp android_reboot.cpp \
iosched_policy.cpp multiuser.cpp uevent.cpp fs_mgr.cpp \
fs_mgr_fstab.cpp strlcat.cpp strlcpy.cpp logwrap.cpp
TEST_SRCS = init_parser_test.cpp util_test.cpp
INIT_OBJS = $(SRCS:.c=.o)
INIT_MAIN = android-init
all: init ueventd watchdogd
init: $(OBJS)
@echo "Building init."
$(CC) $(CFLAGS) $(INIT_SRCS) $(UTIL_SRCS) \
-o $(INIT_MAIN) $(INIT_OBJS) \
$(LDLIBS)
ueventd: $(OBJS)
@echo "Building ueventd, which is hooked to argv[0] of init."
$(CC) $(CFLAGS) $(INIT_SRCS) $(UTIL_SRCS) \
-o ueventd $(INIT_OBJS) \
$(LDLIBS)
watchdogd: $(OBJS)
@echo "Building watchdogd, which is hooked to argv[0] of init."
$(CC) $(CFLAGS) $(INIT_SRCS) $(UTIL_SRCS) \
-o watchdogd $(INIT_OBJS) \
$(LDLIBS)
tests: $(OBJS)
$(CC) $(CFLAGS) init_parser_test.cpp $(UTIL_SRCS) \
-o init_parser_test $(INIT_OBJS) \
$(LDLIBS)
$(CC) $(CFLAGS) util_test.cpp $(UTIL_SRCS) \
-o util_test $(INIT_OBJS) \
$(LDLIBS)
clean:
rm -f android-init watchdogd ueventd
Not the use of the Google Tests library in two files. The init parser test had to be modified to remove SELinux seclabel code (which is an indicator that SELinux security context information is being stored in the xattrs of the FS) and to fix the pathnames to match the Unix FHS.
libbase
AOSP refactored some of their internal functions for buffered file I/O, string building, string formatting and logging into a Base class linked to a library called libbase.
I simply copied base/stringprintf.h, base/strings.h and base/file.h verbatim with their source files and included them to the Makefile. Some headers had to be included for definitions like BUFSIZ and the stdint types. Additionally, instead of using the cutils logging macros, I replaced their usages with calls to fprintf(stderr, “…”) [corresponding to ALOGE].
Android FHS
Android does not follow the FHS, instead using its own directory layout optimized for things like easy factory reset. Though variations are seen across device vendors, in general you have everything lumped into /system (including /system/bin, /system/etc and so forth), Dalvik/ART bytecode in /cache, miscellaneous configuration, app cache, crash/debug info and backups in /data, the recovery image partition in /recovery and so forth. More details can be found here.
The init.rc and ueventd.rc files are actually stored in /. I ended up remapping several pathnames from /system/bin to /sbin (for things like e2fsck and f2fs.fsck), /data to /etc and the .rc configuration files to /etc, as well.
BSD libc
Android’s own libc, Bionic, is in fact based in large part to OpenBSD libc. As such, it inherits several of Ulrich Drepper’s archnemeses, namely strlcpy(3) and strlcat(3), in addition to getprogname(3) in the init logging functions.
I copied and included the strlc* functions, while I replaced getprogname(3) with the glibc-specific program_invocation_short_name, which is akin to the basename of a global scope argv[0] in main().
There was also the __printflike macro, specific to <sys/cdefs.h> seen in most BSD libcs, which in GCC can be recreated as __attribute__ ((format(printf, 2, 3))), as documented here, allowing for the compiler to type check function arguments as matching printf(3) format string rules.
System properties
Android has its Bionic libc-specific feature called system properties, or just properties. They represent an odd blend between sysctl-like key-value pairs (the same dot.separated.string.format) and registry keys. They are used by both low-level Android programs and Android apps running in the Dalvik/ART VM for runtime configuration and feature toggles.
Android properties are implemented as a region of shared memory called the property workspace, which resides in the property service, implemented as part of Android init and initialized in the PID1 main loop. Properties will then be loaded from the /default.prop, /system/build.prop, /system/default.prop and /data/local.prop files in persistent storage.
The property service itself listens on /dev/socket/property_service, which init polls on for events. Only the property service can manipulate the property workspace. Processes wanting to use properties go through the libcutils property functions (or a higher level Java wrapper), themselves calling the Bionic libc functions. The shared memory block is loaded into their own virtual address space for properties to be read, however writing operations are further redirected to the property service’s control socket.
In essence, they’re used as a rather ad-hoc IPC and synchronization based on top of shared memory and file descriptors. Android init itself can create custom triggers from init.rc based on reacting to property changes, and uses them in its core logic in several places to probe for subsystems.
Because they’re not exactly portable (they actually might be in theory, since the Bionic code doesn’t appear to do anything too low-level, but I didn’t bother to go that far and that might actually be a research topic and blog article for another time), I eviscerated them entirely. The property service, all property checks, set/getprop, load_all_prop, load_persist_prop commands, initialization and so forth were removed, and so the ability to have properties act as triggers.
The fs_mgr
The fs_mgr is an object bundled into a library, with an optional standalone utility, for parsing, traversing and performing mount operations based on fstab(5) operation. It is written purely in C.
Only portions of it from its source files were added, particularly the basic parsing, swapon, mount/umount, tmpfs mount and fsck logic (which simply exec()s /sbin/e2fsck). Code for low-level ext4 superblock parsing, encryptable partitions and the Verified Boot (signed bootloader and initramfs; see below) scheme was not kept. Static casts and adjustments to mount calls were made where necessary.
libcutils
libcutils are rather self-explanatory. They are AOSP’s low-level C interfaces for the kernel and libc subsystems used all throughout core system platform.
In our case, we imported the following:
<cutils/klog.h> for logging to /dev/kmsg. The __printflike macro had to be expanded as explained in the “BSD libc” section.
<cutils/android_reboot.h for the system reboot callbacks. The <linux/reboot.h> header had to be included, and the __unused macro expanded to __attribute__((unused)) in the flags parameter of the android_reboot_with_callback() function, which itself is called from the higher-level android_reboot().
<cutils/iosched_priority.h for wrapping the ioprio_get(2) and ioprio_set(2) system calls.
<cutils/multiuser.h for calculating application UIDs.
<cutils/uevent.h> for the low-level Netlink connection that ueventd uses to subscribe to kernel uevents. To avoid a C++ scope boundary crossing error where a jump label skips some struct initializations, those had to be moved to the top level of the uevent_kernel_rcv() function.
<cutils/list.h> for simple doubly linked list macros.
Of <cutils/sockets.h, all we needed was to set two macros: ANDROID_SOCKET_ENV_PREFIX and ANDROID_SOCKET_DIR (/dev/socket).
SELinux
Android init uses SELinux security contexts very liberally. Though I’m not one to yell “OH GOD SELINUX IS NSA BACKDOOR, YOU’RE ALL PART OF THE BOTNET NOW”, I legitimately am not a fan of its convoluted RBAC model. I have instead always appreciated the elegance of a nice capability-based system (not to be confused with the deceptively named POSIX capabilities).
Furthermore, Slackware has never officially supported SELinux, nor PAM. These are all blessings in my mind, but I wasn’t willing to go through the effort of being distribution SELinux maintainer just for this one-off project.
The Android init also uses AOSP-specific SELinux extensions, which are unportable.
SELinux removal entailed ridding of the setcon, restorecon, restorecon_recursive and seclabel commands, as well as SELinux initialization, policy loading and context creation/checking code sprinkled throughout init, ueventd and utilities. The open_devnull_stdio() function in utils.cpp retained its attempt to open /sys/fs/selinux/null, since it can handle failures gracefully and default to /dev/null anyway.
Keychord driver and keycodes
Android has a scarcely documented keychord driver registered as a device node at /dev/keychord, which is used for, among other things, setting keycode combinations to trigger debug actions for Android init-supervised services during adb sessions.
As it is heavily system-specific and irrelevant to our use cases, it was removed, along with the (undocumented) keycodes option in the init.rc parser.
Logwrapper
logwrapper is a basic superserver utility library that forks/execs a program while redirecting its stdout/stderr either to the Android system log by priority, or the kernel ring buffer log.
In our case, we imported it with C++ type casting modifications, and again the ALOGE macros redefined to fprintf(stderr, …).
It was needed largely because of the android_fork_execvp_ext() function, used in the fs_mgr for launching /sbin/mkswap and /sbin/e2fsck on the parsed fstab(5) structure, as well as in the built-in unmount_and_fsck() function which is called as part of the shutdown procedure.
Verified boot
Android since 4.4 “Kit Kat” has a so-called “verified boot” system based on a DeviceMapper extension which uses signed Merkle trees of an ext4 image, verifying each read block by comparing it to the tree passed during setup. It is officially documented here.
There are two commands verity_get_state and verity_load_state related to said DeviceMapper module, which have been removed. These functions internally delegate to the fs_mgr, this portion of which we have not copied over. It is specifically in fs_mgr/fs_mgr_verity.c, which is where the bulk of the verified boot logic in general resides.
ext4_utils
AOSP ships with the ext4_utils for manipulating the low-level disk layout of ext4fs, which is well specified in this kernel wiki article. Particularly, AOSP implemented their ext4_crypt_init_extensions as part of the verified boot scheme described above, later merged into upstream Linux.
Since we did not need this and did not want to meddle with aligning ext4 structure definitions, it was removed entirely in the device management along with the installkey command.
File system config definitions
Android’s system image generation tools like mkbootfs define some system properties and definitions for user and group IDs matching various subsystems, like debug bridge, camera, NFC, DHCP client and so forth. These are defined in <private/android_filesystem_config.h>.
In our case, there was a setegid(2) operation taking the value of AID_ROOT, which is unsurprisingly just 0.
That’s mostly it. On to the final phase.
Build, configure, run
Well, shit.
After building the thing, I copied it over to /sbin/android-init. I then wrote a crude init.rc (parsed in /etc/init.rc in the port) file based on the Slackware Linux rc scripts.
It’s quite ugly, but elegance was no priority here:
# Android init.rc file for a Slackware Linux 14.1 system
on early-init
loglevel 3
export PATH=/sbin:/usr/sbin:/bin:/usr/bin
export LANG=C
on boot
hostname thatmemeisdank
# RTC tick rate
sysctltkz 10000
exec -- /sbin/hwclock --hctosys
exec -- /sbin/swapon -a
rm /etc/mtab
symlink /proc/mtab /etc/mtab
# kmods
exec -- /sbin/depmod -A
insmod parport_pc
insmod lp
insmod agpgart
insmod loop
mount tmpfs cgroup_root /sys/fs/cgroup mode=0750,uid=0,gid=1000
mount tmpfs none /run mode=0755
# Create location for fs_mgr to store abbreviated output from filesystem
# checker programs.
mkdir /dev/fscklogs 0770 root system
exec -- /sbin/sysctl -e -p /etc/sysctl.conf
# new utmp entry
exec -- /bin/touch /var/run/utmp
chown root:utmp /var/run/utmp
chmod 664 /var/run/utmp
chmod 664 /var/log/dmesg
rm /etc/nologin
mount_all /etc/fstab
# entropy pool
exec -- /bin/cat /etc/random-seed > /dev/urandom
exec -- /usr/bin/dd if=/dev/urandom of=/etc/random-seed count=1 bs=512 2> /dev/null
chmod 600 /etc/random-seed
# services
class_start core
class_start network
class_start jobs
class_start gettys
service syslogd /usr/sbin/syslogd -a -d /var/log
class core
onrestart restart klogd
service klogd /usr/sbin/klogd -c 3 -x
class core
service bring-up-network-interfaces /etc/rc.d/rc.inet1 start
class network
oneshot
service port-forwarding /etc/rc.d/rc.ip_forward start
class network
oneshot
service inetd /usr/sbin/inetd
class network
service acpid /usr/sbin/acpid
class core
service crond /usr/sbin/crond -l notice
class core
service atd /usr/sbin/atd -b 15 -l 1
class core
service dbus-uuidgen /usr/bin/dbus-uuidgen --ensure
class jobs
oneshot
service dbus-system /usr/bin/dbus-daemon --system
class core
service httpd /usr/sbin/apachectl -k start
class core
service update-so-links /sbin/ldconfig
class jobs
oneshot
service update-font-cache /usr/bin/fc-cache -f
class jobs
oneshot
service gpm /usr/sbin/gpm -m /dev/mouse -t ps2
class core
service load-alsa-mixing /usr/sbin/alsactl restore
class jobs
oneshot
service update-mime-database /usr/bin/update-mime-database /usr/share/mime
class jobs
oneshot
service rc-local /etc/rc.d/rc.local
class jobs
oneshot
service pulseaudio /usr/bin/pulseaudio --start --log-target syslog
class core
service getty1 /sbin/agetty --noclear 38400 tty1 linux
class gettys
service getty2 /sbin/agetty 38400 tty2 linux
class gettys
service getty3 /sbin/agetty 38400 tty3 linux
class gettys
service getty4 /sbin/agetty 38400 tty4 linux
class gettys
service getty5 /sbin/agetty 38400 tty5 linux
class gettys
We resort to cheap exec()s a lot, beside the generally messy logic.
Slackware uses the venerable LILO, which I actually quite enjoy despite most people looking at you like you’re a fossil for using it.
Anyway, I added an entry to my /etc/lilo.conf like so:
image = /boot/vmlinuz-huge-smp-$KERNEL_VSN-smp
root = /dev/sda1
label = androidinit
append="init=/sbin/android-init"
read-only
Committed to MBR:
/sbin/lilo -v
And reboot.
The moment of truth
There’s some good news and some bad news.
The bad news is this particular experiment failed. The fs_mgr object crashes, but this in of itself isn’t too bad, we can always do a /sbin/mount -a.
However, despite the init.rc file parsing, the SIGCHLD handler is FUBAR along with the command execution logic, and my suspicion is that this is precisely because of the lack of property service and workspace. Particularly, service state change notifications relied on property getting and setting, which we don’t have, and thus there probably isn’t any information for init(8) to deduce its sequence.
Now, the interesting thing is that someone did an Android-based init thing for GNU/Linux 5 years prior. I actually don’t know if it’s from 2010, but that was the commit date on GitHub. It might actually be earlier. It doesn’t have system properties at all, and it’s a much smaller pure C program, lacking nearly all of the interfaces we described above. It thus appears to be only loosely based on the Android init code, as compared to my rather faithful porting attempt.
And it worked… but only barely. Shutdown logic is broken, I’m unaware if it even handles autorestart properly, and way I got it to boot my system was to just lazily exec the /etc/rc.d/rc.S and /etc/rc.d/rc.M scripts, then wrap a few gettys in a class and start those.
Closing remarks
(My raw source files can be found at this GitHub repository. Use at your own discretion. If you get something working, open an issue/PR or contact V.R. at the Dark n'' Edgy forums.)
Android ain’t GNU/Linux, and it shows. The amount of AOSP-specific interfaces that diverge and pose practical problems for interoperability with regular GNU/Linux systems, the ones we actually call “Linux” at all in daily speech, are numerous.
As such, the only practical strategy is not to port, as much as to loosely adapt (as in the aforementioned absabs/init project). Another possibility is that system properties and other intricacies are in fact doable to port, as they simply appear to be shared memory, fds and sockets, even if residing in the libc level. That indeed might be left as an experiment for a later time (if ever), perhaps for totally orthogonal reasons to running Android init.
The Android init is generally very purpose-built, and in any event it is probably of little interest for servers and desktops. It’s a niche, system-specific thing that to reiterate, solves the problem of being a small event-driven design meant to be configured once and chucked into an initramfs never to be touched again.
But, then again, say what you will about Android init. At least it doesn’t warrant a goddamned annual conference.

Attempted to read or write protected memory. This is often an indication that other memory is corrupt.
Attempted to read or write protected memory. This is often an indication that other memory is corrupt.
Description: An unhandled exception occurred during the execution of the current web request. Please review the stack trace for more information about the error and where it originated in the code.Exception Details: System.AccessViolationException: Attempted to read or write protected memory. This is often an indication that other memory is corrupt.
Source Error:
Line 37: protected void Application_Start(Object sender, EventArgs e)
Line 38: {
Line 39: AppStartLogger.ResetLog();
Line 40: AppStartLogger.WriteLine("Starting AspDotNetStorefront...");
Line 41:
Source File: e:\Just\JustWeb\App_Code\Global.asax.cs Line: 39
Symptoms
Accessing the site results in an "Attempted To Read Or Write Protected Memory" error.
Cause
There are 2 potential causes of this issue:
1 - A site running a version of the ASPDNSF software older than 7.0.2.5 is attempting to run in a medium-trust hosting environment.
2 - A site running a version of the ASPDNSF software older than 7.0.2.5 is running on a host that has just applied the .NET 3.5 SP1 upgrade to the servers.
NOTE: In both of these cases, the problem lies with the environment the software is running in, as configured by the host. These are not flaws in the software, and are beyond our control.
Procedure
The best solution (regardless of which of the 2 causes above is creating your issue) is to upgrade to version 7.0.2.5 SP1 or higher of the ASPDNSF software. Those later versions can run natively in medium-trust (thus avoiding issue #1) and work fine with the latest .NET service pack (which didn't even exist before then for us to test against).
If upgrading is not an option at the moment, there are other workarounds for each possible cause. Note that these are the ONLY workarounds. We can provide no other advice than these steps:
Medium Trust:
1 - First, have the host or server admin apply the Microsoft-created hotfix available at
http://connect.microsoft.com/VisualStudio/Downloads/DownloadDetails.aspx?DownloadID=6003
2 - Contact support and request a special medium-trust build of the software. We will need a valid order number to provide that.
3 - Move to a full-trust environment (this may mean switching hosts).
.NET 3.5 SP1 Patch:
1 - Have the host roll back the changes on the server, or move your site to a server that has not had the patch applied.
https://support.aspdotnetstorefront.com/index.php?_m=knowledgebase&_a=viewarticle&kbarticleid=208
If you are using aspdotnetstorefront and are getting the following error: Attempted to read or write protected memory. This is often an indication that other memory is corrupt.
then please contact aspdotnetstorefront in regards to the error as you will have to upgrade your aspdotnetstorefront storefront application to version 7.0.2.5 SP1 or version 7.1.0.0 if the .NET 3.5 service pack is installed.
If you are not using aspdotnetstorefront and are getting this error, you will need to verify that you code works with the lates dotnet service packs for all versions. This error is usually remoting related, but not always.
我们今天的关于Thanks for the memory, Linux的分享就到这里,谢谢您的阅读,如果想了解更多关于(OK) Performance Enhancement of Multipath TCP in Mobile Ad Hoc Networks、11g 报错 ORA-27102: out of memory Linux Error: 22: Invalid arg、An experiment in porting the Android init system to GNU/Linux、Attempted to read or write protected memory. This is often an indication that other memory is corrupt.的相关信息,可以在本站进行搜索。
本文标签:




