在本文中,我们将详细介绍Dockerd资源泄露怎么办的各个方面,并为您提供关于docker内存泄露的相关解答,同时,我们也将为您带来关于167dockerdocker构建nginx容器系列问题dock
在本文中,我们将详细介绍Dockerd 资源泄露怎么办的各个方面,并为您提供关于docker内存泄露的相关解答,同时,我们也将为您带来关于167 docker docker构建nginx容器系列问题 docker registry docker run docker toolbo、Docker (二十)-Docker 容器 CPU、memory 资源限制、Docker (十九)-Docker 监控容器资源的占用情况、Docker in Docker(实际上是 Docker outside Docker): /var/run/docker.sock的有用知识。
本文目录一览:- Dockerd 资源泄露怎么办(docker内存泄露)
- 167 docker docker构建nginx容器系列问题 docker registry docker run docker toolbo
- Docker (二十)-Docker 容器 CPU、memory 资源限制
- Docker (十九)-Docker 监控容器资源的占用情况
- Docker in Docker(实际上是 Docker outside Docker): /var/run/docker.sock
")
Dockerd 资源泄露怎么办(docker内存泄露)

更多奇技淫巧欢迎订阅博客:https://fuckcloudnative.io
1. 现象
线上 k8s 集群报警,宿主 fd 利用率超过 80%,登陆查看 dockerd 内存使用 26G
2. 排查思路
由于之前已经遇到过多次 dockerd 资源泄露的问题,先看是否是已知原因导致的,参考前面两篇
3. fd 的对端是谁?
执行 ss -anp | grep dockerd,结果如下图,可以看到和之前遇到的问题不同,第 8 列显示为 0,与之前遇到的的情况不符,无法找到对端。
4. 内存为什么泄露?
为了可以使用 pprof 分析内存泄露位置,首先为 dockerd 打开 debug 模式,需要修改 service 文件,添加如下两句
ExecReload=/bin/kill -s HUP $MAINPID
KillMode=process
同时在 /etc/docker/daemon.json 文件中添加 “debug”: true 的配置,修改完之后执行 systemctl daemon-reload 重新加载 docker 服务配置,然后执行 systemctl reload docker,重进加载 docker 配置,开启 debug 模式
dockerd 默认使用 uds 对未提供服务,为了方便我们调试,可以使用 socat 对 docker 进行端口转发,如下 sudo socat -d -d TCP-LISTEN:8080,fork,bind=0.0.0.0 UNIX:/var/run/docker.sock,意思是外部可以通过访问宿主机的 8080 端口来调用 docker api,至此一切就绪
在本地执行 go tool pprof http://ip:8080/debug/pprof/heap 查看内存使用情况,如下图
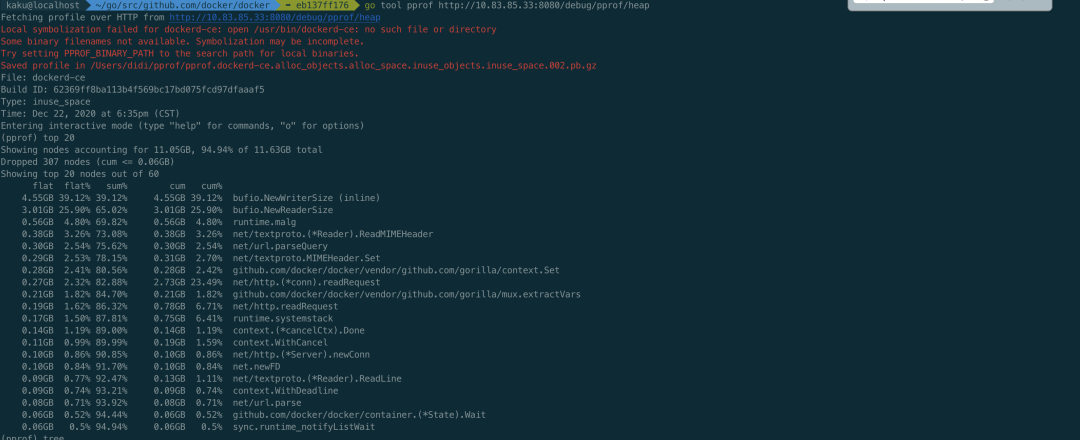
可以看到占用多的地方在 golang 自带的 bufio NewWriterSize 和 NewReaderSize 处,每次 http 调用都会都这里,也看出来有什么问题。
5. Goroutine 也泄露?
泄露位置
通过内存还是无法知道具体出问题的位置,问题不大,再看看 goroutine 的情况,直接在浏览器访问 http://ip:8080/debug/pprof/goroutine?debug=1,如下图
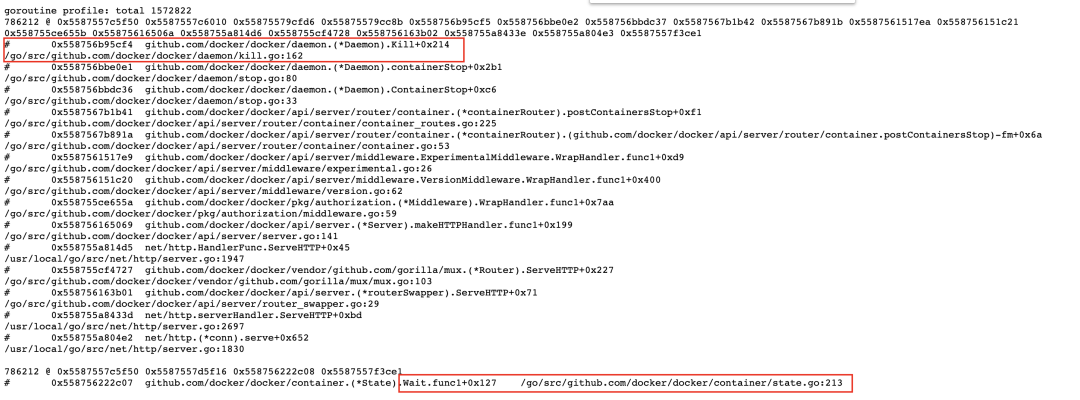
一共 1572822 个 goroutine,两个大头各占一半,各有 786212 个。看到这里基本就可以沿着文件行数去源码中查看了,这里我们用的 docker 18.09.2 版本,把源码切换到对应版本下,通过查看源码可以知道这两大类的 goroutine 泄露的原因,dockerd 与 containerd 相关处理流程如下图
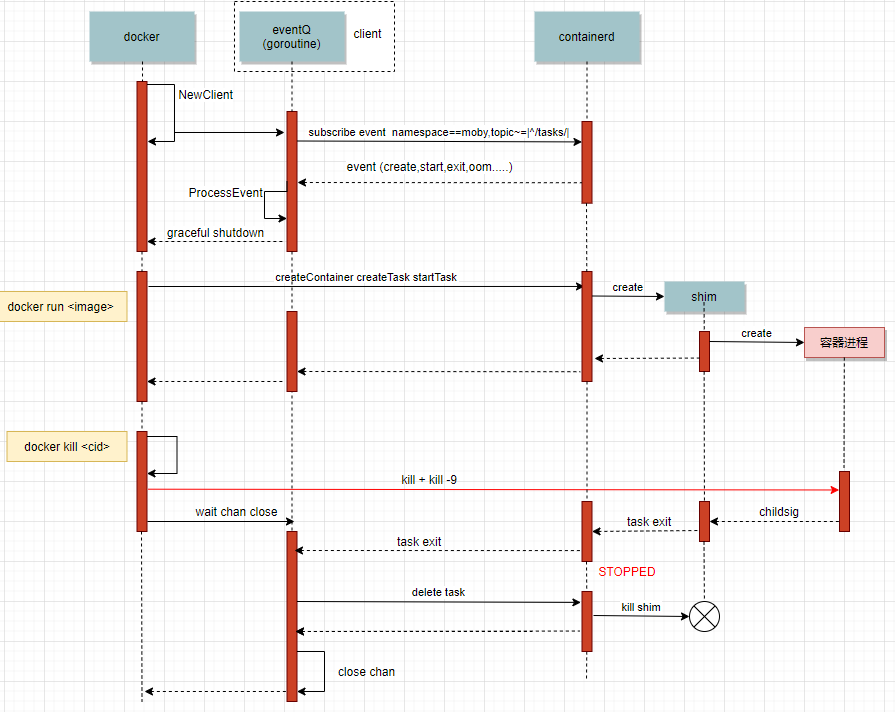
对应上图的话,goroutine 泄露是由上面最后 docker kill 时的 wait chan close 导致的,wait 的时候会启动另一个 goroutine,每次 docker kill 都会造成这两个 goroutine 的泄露。对应代码如下
// Kill forcefully terminates a container.
func (daemon *Daemon) Kill(container *containerpkg.Container) error {
if !container.IsRunning() {
return errNotRunning(container.ID)
}
// 1. Send SIGKILL
if err := daemon.killPossiblyDeadProcess(container, int(syscall.SIGKILL)); err != nil {
// While normally we might "return err" here we''re not going to
// because if we can''t stop the container by this point then
// it''s probably because it''s already stopped. Meaning, between
// the time of the IsRunning() call above and now it stopped.
// Also, since the err return will be environment specific we can''t
// look for any particular (common) error that would indicate
// that the process is already dead vs something else going wrong.
// So, instead we''ll give it up to 2 more seconds to complete and if
// by that time the container is still running, then the error
// we got is probably valid and so we return it to the caller.
if isErrNoSuchProcess(err) {
return nil
}
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
if status := <-container.Wait(ctx, containerpkg.WaitConditionNotRunning); status.Err() != nil {
return err
}
}
// 2. Wait for the process to die, in last resort, try to kill the process directly
if err := killProcessDirectly(container); err != nil {
if isErrNoSuchProcess(err) {
return nil
}
return err
}
// Wait for exit with no timeout.
// Ignore returned status.
<-container.Wait(context.Background(), containerpkg.WaitConditionNotRunning)
return nil
}
// Wait waits until the container is in a certain state indicated by the given
// condition. A context must be used for cancelling the request, controlling
// timeouts, and avoiding goroutine leaks. Wait must be called without holding
// the state lock. Returns a channel from which the caller will receive the
// result. If the container exited on its own, the result''s Err() method will
// be nil and its ExitCode() method will return the container''s exit code,
// otherwise, the results Err() method will return an error indicating why the
// wait operation failed.
func (s *State) Wait(ctx context.Context, condition WaitCondition) <-chan StateStatus {
s.Lock()
defer s.Unlock()
if condition == WaitConditionNotRunning && !s.Running {
// Buffer so we can put it in the channel now.
resultC := make(chan StateStatus, 1)
// Send the current status.
resultC <- StateStatus{
exitCode: s.ExitCode(),
err: s.Err(),
}
return resultC
}
// If we are waiting only for removal, the waitStop channel should
// remain nil and block forever.
var waitStop chan struct{}
if condition < WaitConditionRemoved {
waitStop = s.waitStop
}
// Always wait for removal, just in case the container gets removed
// while it is still in a "created" state, in which case it is never
// actually stopped.
waitRemove := s.waitRemove
resultC := make(chan StateStatus)
go func() {
select {
case <-ctx.Done():
// Context timeout or cancellation.
resultC <- StateStatus{
exitCode: -1,
err: ctx.Err(),
}
return
case <-waitStop:
case <-waitRemove:
}
s.Lock()
result := StateStatus{
exitCode: s.ExitCode(),
err: s.Err(),
}
s.Unlock()
resultC <- result
}()
return resultC
}
对照 goroutine 的图片,两个 goroutine 分别走到了 Kill 最后一次的 container.Wait 处、Wait 的 select 处,正因为 Wait 方法的 select 一直不返回,导致 resultC 无数据,外面也就无法从 container.Wait 返回的 chan 中读到数据,从而导致每次 docker stop 调用阻塞两个 goroutine。
为什么泄露?
为什么 select 一直不返回呢?可以看到 select 在等三个 chan,任意一个有数据或者关闭都会返回
-
ctx.Done():不返回是因为最后一次调用 Wait 的时候传入的是 context.Background()。这里其实也是 dockerd 对请求的处理方式,既然客户端要删除容器,那我就等着容器删除,什么时间删除什么时间退出,只要容器没删,就一直有个 goroutine 在等待。 -
waitStop和waitRemove:不返回是因为没收到 containerd 发来的 task exit 的信号,可以对照上图看下,在收到 task exit 后才会关闭 chan。
为什么没收到 task exit 事件?
问题逐渐明确,但还需要进一步排查为什么没有收到 task exit 的事件,两种可能
-
发出但没收收到:这里首先想到的是之前腾讯遇到的一个问题,也是在 18 版本的 docker 上, processEvent的 goroutine 异常退出了,导致无法接收到 containerd 发来的信号,参考 这里 [1] -
没有发出
首先看有没有收到,还是看 goroutine 的内容,如下图,可以看到处理事件的 goroutine:processEventStream 和接收事件的 goroutine:Subscribe 都存在,可以排除第一种可能

接着看第二种可能,根本没发出 task exit 事件。经过上面分析,已知存在 goroutine 泄露,且是通过 docker stop 引起的,所以可以肯定 kubelet 发起了删除容器的请求,并且是在一直尝试,要不然也不会一直泄露。那剩下唯一的问题就是找出来是在不断的删除哪个容器,又为什么删不掉。其实这个时候,聪明的你们可能已经想到容器里大概率是有 D 进程了,所有即使发送 Kill 信号容器进程无法正常退出。接下来就是去验证一下这个猜想,首先去找一下哪个容器出的问题,先看 Kubelet 日志和 docker 日志,如下
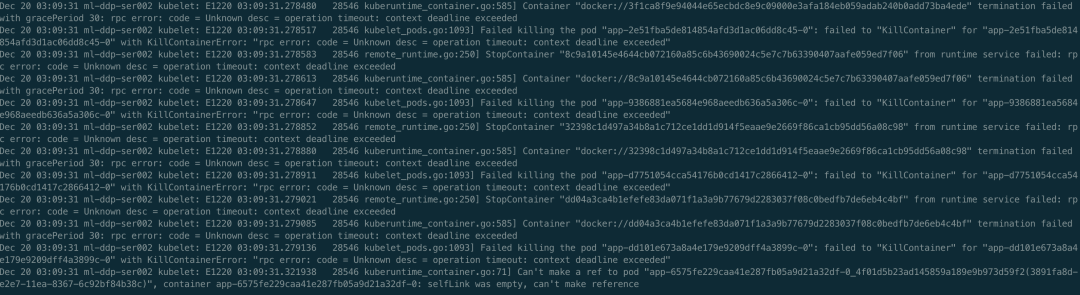
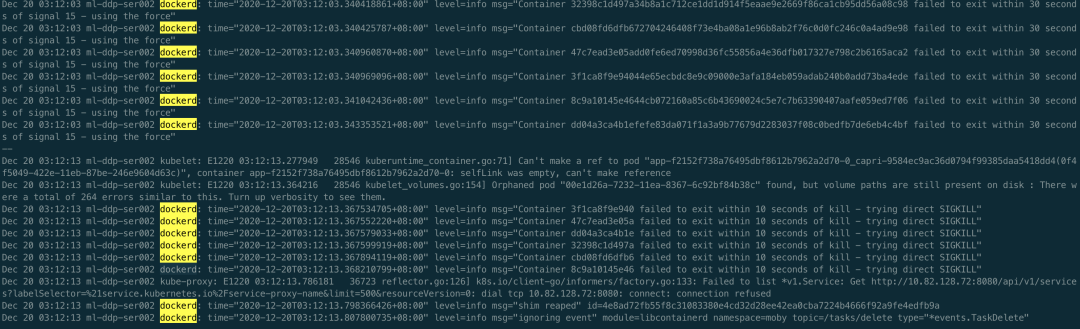
好家伙,不止一个容器删不掉。验证了确实在不断删除容器,但是删不掉,接下来看下是不是有 D 进程,如下
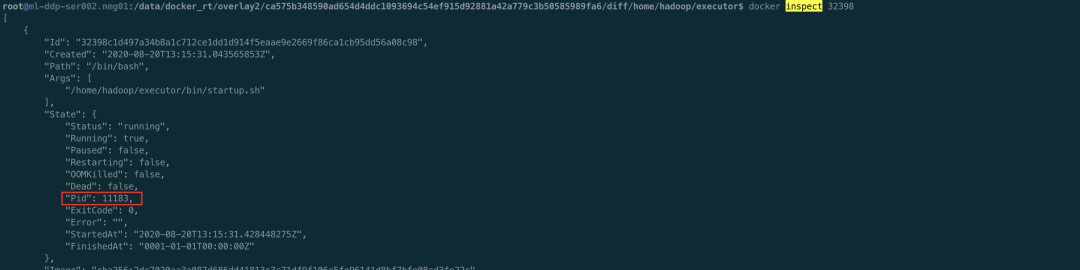


确实容器内有 D 进程了,可以去宿主上看下,ps aux | awk ‘$8=“D”'',特别多的 D 进程。
总结
Kubelet 为了保证最终一致性,发现宿主上还有不应该存在的容器就会一直不断的去尝试删除,每次删除都会调用 docker stop 的 api,与 dockerd 建立一个 uds 连接,dockerd 删除容器的时候会启动一个 goroutine 通过 rpc 形式调用 containerd 来删除容器并等待最终删除完毕才返回,等待的过程中会另起一个 goroutine 来获取结果,然而 containerd 在调用 runc 去真正执行删除的时候因为容器内 D 进程,无法删除容器,导致没有发出 task exit 信号,dockerd 的两个相关的 goroutine 也就不会退出。整个过程不断重复,最终就导致 fd、内存、goroutine 一步步的泄露,系统逐渐走向不可用。
回过头来想想,其实 kubelet 本身的处理都没有问题,kubelet 是为了确保一致性,要去删除不应该存在的容器,直到容器被彻底删除,每次调用 docker api 都设置了 timeout。dockerd 的逻辑有待商榷,至少可以做一些改进,因为客户端请求时带了 timeout,且 dockerd 后端在接收到 task exit 事件后是会去做 container remove 操作的,即使当前没有 docker stop 请求。所以可以考虑把最后传入 context.Background() 的 Wait 函数调用去掉,当前面带超时的 Wait 返回后直接退出就可以,这样就不会造成资源泄露了。
参考资料
这里: https://segmentfault.com/a/1190000023809654
原文链接:https://www.likakuli.com/posts/docker-leak3/


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰
扫码关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
❤️
给个
「在看」
,是对我最大的支持❤️
本文分享自微信公众号 - 云原生实验室(cloud_native_yang)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

167 docker docker构建nginx容器系列问题 docker registry docker run docker toolbo
background : 最近为小伙伴们筹划docker系列的技术分享,研究了一会docker相关技术, 在此记录一下构建nginx容器时候的坑
1.nginx服务器根目录问题
docker 官方镜像提供的nginx基于debian/jessie平台,其文件结构和ubuntu中的nginx中并不相同
eg:
run一个niginx容器
<span>//80端口被占用,so...</span> $ sudo docker run <span>-it</span><span>-p</span><span>800</span>:<span>800</span> nginx $ sudo docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES <span>1801</span>a32aab54 nginx <span>"nginx -g ''daemon off"</span><span>2</span> minutes ago Up <span>2</span> minutes <span>80</span>/tcp, <span>443</span>/tcp, <span>0.0</span><span>.0</span><span>.0</span>:<span>800</span><span>-></span><span>800</span>/tcp berserk_kare
进入容器内部
<span>$ </span>sudo docker exec -it <span>1801</span>a32aab54 /bin/bash root<span>@1801a32aab54</span><span>:/</span><span># </span>
查看nginx目录
<span># cd /etc/nginx/</span> conf<span>.d</span>/ koi-utf mime<span>.types</span> nginx<span>.conf</span> uwsgi_params fastcgi_params koi-win modules/ scgi_params win-utf
可以看到不仅没有熟悉的 /sites-available,也没有 /sites-enabled
继续查看nginx配置
<span># cat /conf.d/default.conf</span><span>server</span> {
listen <span>80</span>;
server_name localhost;
<span>#charset koi8-r;</span><span>#access_log /var/log/nginx/log/host.access.log main;</span> location / {
root /usr/share/nginx/html;
<span>index</span><span>index</span>.html <span>index</span>.htm;
}
<span>#error_page 404 /404.html;</span><span># redirect server error pages to the static page /50x.html</span><span>#</span>
error_page <span>500</span><span>502</span><span>503</span><span>504</span> /<span>50</span>x.html;
location = /<span>50</span>x.html {
root /usr/share/nginx/html;
}
<span>#...省略php-fpm配置,好长..</span>
}根目录配置: root /usr/share/nginx/html;
测试
<span># cd /usr/share/nginx/html</span><span># touch index.html</span><span># echo "test nginx in docker" >index.html</span>
php-fpm配置相关
'').addClass(''pre-numbering'').hide(); $(this).addClass(''has-numbering'').parent().append($numbering); for (i = 1; i '').text(i)); }; $numbering.fadeIn(1700); }); });以上就介绍了167 docker docker构建nginx容器系列问题,包括了docker,nginx方面的内容,希望对PHP教程有兴趣的朋友有所帮助。
-Docker 容器 CPU、memory 资源限制")
Docker (二十)-Docker 容器 CPU、memory 资源限制
背景
在使用 docker 运行容器时,默认的情况下,docker 没有对容器进行硬件资源的限制,当一台主机上运行几百个容器,这些容器虽然互相隔离,但是底层却使用着相同的 CPU、内存和磁盘资源。如果不对容器使用的资源进行限制,那么容器之间会互相影响,小的来说会导致容器资源使用不公平;大的来说,可能会导致主机和集群资源耗尽,服务完全不可用。
docker 作为容器的管理者,自然提供了控制容器资源的功能。正如使用内核的 namespace 来做容器之间的隔离,docker 也是通过内核的 cgroups 来做容器的资源限制;包括 CPU、内存、磁盘三大方面,基本覆盖了常见的资源配额和使用量控制。
Docker 内存控制 OOME 在 linxu 系统上,如果内核探测到当前宿主机已经没有可用内存使用,那么会抛出一个 OOME (Out Of Memory Exception: 内存异常),并且会开启 killing 去杀掉一些进程。
一旦发生 OOME,任何进程都有可能被杀死,包括 docker daemon 在内,为此,docker 特地调整了 docker daemon 的 OOM_Odj 优先级,以免他被杀掉,但容器的优先级并未被调整。经过系统内部复制的计算后,每个系统进程都会有一个 OOM_Score 得分,OOM_Odj 越高,得分越高,(在 docker run 的时候可以调整 OOM_Odj)得分最高的优先被 kill 掉,当然,也可以指定一些特定的重要的容器禁止被 OMM 杀掉,在启动容器时使用 –oom-kill-disable=true 指定。
参考:Docker 监控容器资源的占用情况
cgroup 简介
cgroup 是 Control Groups 的缩写,是 Linux 内核提供的一种可以限制、记录、隔离进程组所使用的物理资源 (如 cpu、memory、磁盘 IO 等等) 的机制,被 LXC、docker 等很多项目用于实现进程资源控制。cgroup 将任意进程进行分组化管理的 Linux 内核功能。cgroup 本身是提供将进程进行分组化管理的功能和接口的基础结构,I/O 或内存的分配控制等具体的资源管理功能是通过这个功能来实现的。这些具体的资源管理功能称为 cgroup 子系统,有以下几大子系统实现:
- blkio:设置限制每个块设备的输入输出控制。例如:磁盘,光盘以及 usb 等等。
- cpu:使用调度程序为 cgroup 任务提供 cpu 的访问。
- cpuacct:产生 cgroup 任务的 cpu 资源报告。
- cpuset:如果是多核心的 cpu,这个子系统会为 cgroup 任务分配单独的 cpu 和内存。
- devices:允许或拒绝 cgroup 任务对设备的访问。
- freezer:暂停和恢复 cgroup 任务。
- memory:设置每个 cgroup 的内存限制以及产生内存资源报告。
- net_cls:标记每个网络包以供 cgroup 方便使用。
- ns:命名空间子系统。
- perf_event:增加了对每 group 的监测跟踪的能力,即可以监测属于某个特定的 group 的所有线程以及运行在特定 CPU 上的线程。
目前 docker 只是用了其中一部分子系统,实现对资源配额和使用的控制。
可以使用 stress 工具来测试 CPU 和内存。使用下面的 Dockerfile 来创建一个基于 Ubuntu 的 stress 工具镜像。
FROM ubuntu:14.04
RUN apt-get update &&apt-get install stress
资源监控的关键目录:cat 读出
已使用内存:
/sys/fs/cgroup/memory/docker/应用ID/memory.usage_in_bytes
分配的总内存:
/sys/fs/cgroup/memory/docker/应用ID/memory.limit_in_bytes
已使用的 cpu:单位纳秒
/sys/fs/cgroup/cpuacct/docker/应用ID/cpuacct.usage
系统当前 cpu:
$ cat /proc/stat | grep ''cpu ''(周期/时间片/jiffies)
#得到的数字相加/HZ(cat /boot/config-`uname -r` | grep ''^CONFIG_HZ=''
ubuntu 14.04为250)就是系统时间(秒)
#再乘以10*9就是系统时间(纳秒)例子
[~]$ cat /proc/stat
cpu 432661 13295 86656 422145968 171474 233 5346
cpu0 123075 2462 23494 105543694 16586 0 4615
cpu1 111917 4124 23858 105503820 69697 123 371
cpu2 103164 3554 21530 105521167 64032 106 334
cpu3 94504 3153 17772 105577285 21158 4 24
intr 1065711094 1057275779 92 0 6 6 0 4 0 3527 0 0 0 70 0 20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
ctxt 19067887
btime 1139187531
processes 270014
procs_running 1
procs_blocked 0
输出解释
CPU 以及CPU0、CPU1、CPU2、CPU3每行的每个参数意思(以第一行为例)为:
参数 解释
user (432661) 从系统启动开始累计到当前时刻,用户态的CPU时间(单位:jiffies) ,不包含 nice值为负进程。
nice (13295) 从系统启动开始累计到当前时刻,nice值为负的进程所占用的CPU时间(单位:jiffies)
system (86656) 从系统启动开始累计到当前时刻,核心时间(单位:jiffies)
idle (422145968) 从系统启动开始累计到当前时刻,除硬盘IO等待时间以外其它等待时间(单位:jiffies)
iowait (171474) 从系统启动开始累计到当前时刻,硬盘IO等待时间(单位:jiffies) ,
irq (233) 从系统启动开始累计到当前时刻,硬中断时间(单位:jiffies)
softirq (5346) 从系统启动开始累计到当前时刻,软中断时间(单位:jiffies) cpu 使用率:
(已使用 2 - 已使用 1)/(系统当前 2 - 系统当前 1)*100%
内存限制
Docker 提供的内存限制功能有以下几点:
- 容器能使用的内存和交换分区大小。
- 容器的核心内存大小。
- 容器虚拟内存的交换行为。
- 容器内存的软性限制。
- 是否杀死占用过多内存的容器。
- 容器被杀死的优先级
一般情况下,达到内存限制的容器过段时间后就会被系统杀死。
内存限制相关的参数
执行 docker run 命令时能使用的和内存限制相关的所有选项如下。
| 选项 | 描述 |
|---|---|
-m,--memory |
内存限制,格式是数字加单位,单位可以为 b,k,m,g。最小为 4M |
--memory-swap |
内存 + 交换分区大小总限制。格式同上。必须必 -m 设置的大 |
--memory-reservation |
内存的软性限制。格式同上 |
--oom-kill-disable |
是否阻止 OOM killer 杀死容器,默认没设置 |
--oom-score-adj |
容器被 OOM killer 杀死的优先级,范围是 [-1000, 1000],默认为 0 |
--memory-swappiness |
用于设置容器的虚拟内存控制行为。值为 0~100 之间的整数 |
--kernel-memory |
核心内存限制。格式同上,最小为 4M |
用户内存限制
用户内存限制就是对容器能使用的内存和交换分区的大小作出限制。使用时要遵循两条直观的规则:-m,--memory 选项的参数最小为 4 M。--memory-swap 不是交换分区,而是内存加交换分区的总大小,所以 --memory-swap 必须比 -m,--memory 大。在这两条规则下,一般有四种设置方式。
你可能在进行内存限制的实验时发现
docker run命令报错:WARNING: Your kernel does not support swap limit capabilities, memory limited without swap.这是因为宿主机内核的相关功能没有打开。按照下面的设置就行。
step 1:编辑
/etc/default/grub文件,将GRUB_CMDLINE_LINUX一行改为GRUB_CMDLINE_LINUX="cgroup_enable=memory swapaccount=1"step 2:更新 GRUB,即执行
$ sudo update-grubstep 3: 重启系统。
1. 不设置
如果不设置 -m,--memory 和 --memory-swap,容器默认可以用完宿舍机的所有内存和 swap 分区。不过注意,如果容器占用宿主机的所有内存和 swap 分区超过一段时间后,会被宿主机系统杀死(如果没有设置 --00m-kill-disable=true 的话)。
2. 设置 -m,--memory,不设置 --memory-swap
给 -m 或 --memory 设置一个不小于 4M 的值,假设为 a,不设置 --memory-swap,或将 --memory-swap 设置为 0。这种情况下,容器能使用的内存大小为 a,能使用的交换分区大小也为 a。因为 Docker 默认容器交换分区的大小和内存相同。
如果在容器中运行一个一直不停申请内存的程序,你会观察到该程序最终能占用的内存大小为 2a。
比如 $ docker run -m 1G ubuntu:16.04,该容器能使用的内存大小为 1G,能使用的 swap 分区大小也为 1G。容器内的进程能申请到的总内存大小为 2G。
3. 设置 -m,--memory=a,--memory-swap=b,且 b > a
给 -m 设置一个参数 a,给 --memory-swap 设置一个参数 b。a 时容器能使用的内存大小,b 是容器能使用的 内存大小 + swap 分区大小。所以 b 必须大于 a。b -a 即为容器能使用的 swap 分区大小。
比如 $ docker run -m 1G --memory-swap 3G ubuntu:16.04,该容器能使用的内存大小为 1G,能使用的 swap 分区大小为 2G。容器内的进程能申请到的总内存大小为 3G。
4. 设置 -m,--memory=a,--memory-swap=-1
给 -m 参数设置一个正常值,而给 --memory-swap 设置成 -1。这种情况表示限制容器能使用的内存大小为 a,而不限制容器能使用的 swap 分区大小。
这时候,容器内进程能申请到的内存大小为 a + 宿主机的 swap 大小。
Memory reservation
这种 memory reservation 机制不知道怎么翻译比较形象。Memory reservation 是一种软性限制,用于节制容器内存使用。给 --memory-reservation 设置一个比 -m 小的值后,虽然容器最多可以使用 -m 使用的内存大小,但在宿主机内存资源紧张时,在系统的下次内存回收时,系统会回收容器的部分内存页,强迫容器的内存占用回到 --memory-reservation 设置的值大小。
没有设置时(默认情况下)--memory-reservation 的值和 -m 的限定的值相同。将它设置为 0 会设置的比 -m 的参数大 等同于没有设置。
Memory reservation 是一种软性机制,它不保证任何时刻容器使用的内存不会超过 --memory-reservation 限定的值,它只是确保容器不会长时间占用超过 --memory-reservation 限制的内存大小。
例如:
$ docker run -it -m 500M --memory-reservation 200M ubuntu:16.04 /bin/bash如果容器使用了大于 200M 但小于 500M 内存时,下次系统的内存回收会尝试将容器的内存锁紧到 200M 以下。
例如:
$ docker run -it --memory-reservation 1G ubuntu:16.04 /bin/bash容器可以使用尽可能多的内存。--memory-reservation 确保容器不会长时间占用太多内存。
OOM killer
默认情况下,在出现 out-of-memory (OOM) 错误时,系统会杀死容器内的进程来获取更多空闲内存。这个杀死进程来节省内存的进程,我们姑且叫它 OOM killer。我们可以通过设置 --oom-kill-disable 选项来禁止 OOM killer 杀死容器内进程。但请确保只有在使用了 -m/--memory 选项时才使用 --oom-kill-disable 禁用 OOM killer。如果没有设置 -m 选项,却禁用了 OOM-killer,可能会造成出现 out-of-memory 错误时,系统通过杀死宿主机进程或获取更改内存。
下面的例子限制了容器的内存为 100M 并禁止了 OOM killer:
$ docker run -it -m 100M --oom-kill-disable ubuntu:16.04 /bin/bash是正确的使用方法。
而下面这个容器没设置内存限制,却禁用了 OOM killer 是非常危险的:
$ docker run -it --oom-kill-disable ubuntu:16.04 /bin/bash容器没用内存限制,可能或导致系统无内存可用,并尝试时杀死系统进程来获取更多可用内存。
一般一个容器只有一个进程,这个唯一进程被杀死,容器也就被杀死了。我们可以通过 --oom-score-adj 选项来设置在系统内存不够时,容器被杀死的优先级。负值更教不可能被杀死,而正值更有可能被杀死。
核心内存
核心内存和用户内存不同的地方在于核心内存不能被交换出。不能交换出去的特性使得容器可以通过消耗太多内存来堵塞一些系统服务。核心内存包括:
- stack pages(栈页面)
- slab pages
- socket memory pressure
- tcp memory pressure
可以通过设置核心内存限制来约束这些内存。例如,每个进程都要消耗一些栈页面,通过限制核心内存,可以在核心内存使用过多时阻止新进程被创建。
核心内存和用户内存并不是独立的,必须在用户内存限制的上下文中限制核心内存。
假设用户内存的限制值为 U,核心内存的限制值为 K。有三种可能地限制核心内存的方式:
- U != 0,不限制核心内存。这是默认的标准设置方式
- K < U,核心内存时用户内存的子集。这种设置在部署时,每个 cgroup 的内存总量被过度使用。过度使用核心内存限制是绝不推荐的,因为系统还是会用完不能回收的内存。在这种情况下,你可以设置 K,这样 groups 的总数就不会超过总内存了。然后,根据系统服务的质量自有地设置 U。
- K > U,因为核心内存的变化也会导致用户计数器的变化,容器核心内存和用户内存都会触发回收行为。这种配置可以让管理员以一种统一的视图看待内存。对想跟踪核心内存使用情况的用户也是有用的。
例如:
$ docker run -it -m 500M --kernel-memory 50M ubuntu:16.04 /bin/bash容器中的进程最多能使用 500M 内存,在这 500M 中,最多只有 50M 核心内存。
$ docker run -it --kernel-memory 50M ubuntu:16.04 /bin/bash没用设置用户内存限制,所以容器中的进程可以使用尽可能多的内存,但是最多能使用 50M 核心内存。
Swappiness
默认情况下,容器的内核可以交换出一定比例的匿名页。--memory-swappiness 就是用来设置这个比例的。--memory-swappiness 可以设置为从 0 到 100。0 表示关闭匿名页面交换。100 表示所有的匿名页都可以交换。默认情况下,如果不适用 --memory-swappiness,则该值从父进程继承而来。
例如:
$ docker run -it --memory-swappiness=0 ubuntu:16.04 /bin/bash
将 --memory-swappiness 设置为 0 可以保持容器的工作集,避免交换代理的性能损失。
$ docker run -tid —name mem1 —memory 128m ubuntu:16.04 /bin/bash
$ cat /sys/fs/cgroup/memory/docker/<容器的完整ID>/memory.limit_in_bytes
$ cat /sys/fs/cgroup/memory/docker/<容器的完整ID>/memory.memsw.limit_in_bytes
CPU 限制
概述
Docker 的资源限制和隔离完全基于 Linux cgroups。对 CPU 资源的限制方式也和 cgroups 相同。Docker 提供的 CPU 资源限制选项可以在多核系统上限制容器能利用哪些 vCPU。而对容器最多能使用的 CPU 时间有两种限制方式:一是有多个 CPU 密集型的容器竞争 CPU 时,设置各个容器能使用的 CPU 时间相对比例。二是以绝对的方式设置容器在每个调度周期内最多能使用的 CPU 时间。
CPU 限制相关参数
docker run 命令和 CPU 限制相关的所有选项如下:
| 选项 | 描述 |
|---|---|
--cpuset-cpus="" |
允许使用的 CPU 集,值可以为 0-3,0,1 |
-c,--cpu-shares=0 |
CPU 共享权值(相对权重) |
cpu-period=0 |
限制 CPU CFS 的周期,范围从 100ms~1s,即 [1000, 1000000] |
--cpu-quota=0 |
限制 CPU CFS 配额,必须不小于 1ms,即 >= 1000 |
--cpuset-mems="" |
允许在上执行的内存节点(MEMs),只对 NUMA 系统有效 |
其中 --cpuset-cpus 用于设置容器可以使用的 vCPU 核。-c,--cpu-shares 用于设置多个容器竞争 CPU 时,各个容器相对能分配到的 CPU 时间比例。--cpu-period 和 --cpu-quata 用于绝对设置容器能使用 CPU 时间。
--cpuset-mems 暂用不上,这里不谈。
CPU 集
我们可以设置容器可以在哪些 CPU 核上运行。
例如:
$ docker run -it --cpuset-cpus="1,3" ubuntu:14.04 /bin/bash表示容器中的进程可以在 cpu 1 和 cpu 3 上执行。
$ docker run -it --cpuset-cpus="0-2" ubuntu:14.04 /bin/bash
$ cat /sys/fs/cgroup/cpuset/docker/<容器的完整长ID>/cpuset.cpus
表示容器中的进程可以在 cpu 0、cpu 1 及 cpu 3 上执行。
在 NUMA 系统上,我们可以设置容器可以使用的内存节点。
例如:
$ docker run -it --cpuset-mems="1,3" ubuntu:14.04 /bin/bash表示容器中的进程只能使用内存节点 1 和 3 上的内存。
$ docker run -it --cpuset-mems="0-2" ubuntu:14.04 /bin/bash表示容器中的进程只能使用内存节点 0、1、2 上的内存。
CPU 资源的相对限制
默认情况下,所有的容器得到同等比例的 CPU 周期。在有多个容器竞争 CPU 时我们可以设置每个容器能使用的 CPU 时间比例。这个比例叫作共享权值,通过 -c 或 --cpu-shares 设置。Docker 默认每个容器的权值为 1024。不设置或将其设置为 0,都将使用这个默认值。系统会根据每个容器的共享权值和所有容器共享权值和比例来给容器分配 CPU 时间。
假设有三个正在运行的容器,这三个容器中的任务都是 CPU 密集型的。第一个容器的 cpu 共享权值是 1024,其它两个容器的 cpu 共享权值是 512。第一个容器将得到 50% 的 CPU 时间,而其它两个容器就只能各得到 25% 的 CPU 时间了。如果再添加第四个 cpu 共享值为 1024 的容器,每个容器得到的 CPU 时间将重新计算。第一个容器的 CPU 时间变为 33%,其它容器分得的 CPU 时间分别为 16.5%、16.5%、33%。
必须注意的是,这个比例只有在 CPU 密集型的任务执行时才有用。在四核的系统上,假设有四个单进程的容器,它们都能各自使用一个核的 100% CPU 时间,不管它们的 cpu 共享权值是多少。
在多核系统上,CPU 时间权值是在所有 CPU 核上计算的。即使某个容器的 CPU 时间限制少于 100%,它也能使用各个 CPU 核的 100% 时间。
例如,假设有一个不止三核的系统。用 -c=512 的选项启动容器 {C0},并且该容器只有一个进程,用 -c=1024 的启动选项为启动容器 C2,并且该容器有两个进程。CPU 权值的分布可能是这样的:
PID container CPU CPU share
100 {C0} 0 100% of CPU0 101 {C1} 1 100% of CPU1 102 {C1} 2 100% of CPU2
$ docker run -it --cpu-shares=100 ubuntu:14.04 /bin/bash
$ cat /sys/fs/cgroup/cpu/docker/<容器的完整长ID>/cpu.shares
表示容器中的进程 CPU 份额值为 100。
CPU 资源的绝对限制
Linux 通过 CFS(Completely Fair Scheduler,完全公平调度器)来调度各个进程对 CPU 的使用。CFS 默认的调度周期是 100ms。
关于 CFS 的更多信息,参考 CFS documentation on bandwidth limiting。
我们可以设置每个容器进程的调度周期,以及在这个周期内各个容器最多能使用多少 CPU 时间。使用 --cpu-period 即可设置调度周期,使用 --cpu-quota 即可设置在每个周期内容器能使用的 CPU 时间。两者一般配合使用。
例如:
$ docker run -it --cpu-period=50000 --cpu-quota=25000 ubuntu:16.04 /bin/bash将 CFS 调度的周期设为 50000,将容器在每个周期内的 CPU 配额设置为 25000,表示该容器每 50ms 可以得到 50% 的 CPU 运行时间。
$ docker run -it --cpu-period=10000 --cpu-quota=20000 ubuntu:16.04 /bin/bash
$ cat /sys/fs/cgroup/cpu/docker/<容器的完整长ID>/cpu.cfs_period_us
$ cat /sys/fs/cgroup/cpu/docker/<容器的完整长ID>/cpu.cfs_quota_us
将容器的 CPU 配额设置为 CFS 周期的两倍,CPU 使用时间怎么会比周期大呢?其实很好解释,给容器分配两个 vCPU 就可以了。该配置表示容器可以在每个周期内使用两个 vCPU 的 100% 时间。
CFS 周期的有效范围是 1ms~1s,对应的 --cpu-period 的数值范围是 1000~1000000。而容器的 CPU 配额必须不小于 1ms,即 --cpu-quota 的值必须 >= 1000。可以看出这两个选项的单位都是 us。
正确的理解 “绝对”
注意前面我们用 --cpu-quota 设置容器在一个调度周期内能使用的 CPU 时间时实际上设置的是一个上限。并不是说容器一定会使用这么长的 CPU 时间。比如,我们先启动一个容器,将其绑定到 cpu 1 上执行。给其 --cpu-quota 和 --cpu-period 都设置为 50000。
$ docker run --rm --name test01 --cpu-cpus 1 --cpu-quota=50000 --cpu-period=50000 deadloop:busybox-1.25.1-glibc调度周期为 50000,容器在每个周期内最多能使用 50000 cpu 时间。
再用 docker stats test01 可以观察到该容器对 CPU 的使用率在 100% 左右。然后,我们再以同样的参数启动另一个容器。
$ docker run --rm --name test02 --cpu-cpus 1 --cpu-quota=50000 --cpu-period=50000 deadloop:busybox-1.25.1-glibc再用 docker stats test01 test02 可以观察到这两个容器,每个容器对 cpu 的使用率在 50% 左右。说明容器并没有在每个周期内使用 50000 的 cpu 时间。
使用 docker stop test02 命令结束第二个容器,再加一个参数 -c 2048 启动它:
$ docker run --rm --name test02 --cpu-cpus 1 --cpu-quota=50000 --cpu-period=50000 -c 2048 deadloop:busybox-1.25.1-glibc再用 docker stats test01 命令可以观察到第一个容器的 CPU 使用率在 33% 左右,第二个容器的 CPU 使用率在 66% 左右。因为第二个容器的共享值是 2048,第一个容器的默认共享值是 1024,所以第二个容器在每个周期内能使用的 CPU 时间是第一个容器的两倍。
磁盘 IO 配额控制
相对于 CPU 和内存的配额控制,docker 对磁盘 IO 的控制相对不成熟,大多数都必须在有宿主机设备的情况下使用。主要包括以下参数:
- –device-read-bps:限制此设备上的读速度(bytes per second),单位可以是 kb、mb 或者 gb。
- –device-read-iops:通过每秒读 IO 次数来限制指定设备的读速度。
- –device-write-bps :限制此设备上的写速度(bytes per second),单位可以是 kb、mb 或者 gb。
- –device-write-iops:通过每秒写 IO 次数来限制指定设备的写速度。
- –blkio-weight:容器默认磁盘 IO 的加权值,有效值范围为 10-100。
- –blkio-weight-device: 针对特定设备的 IO 加权控制。其格式为 DEVICE_NAME:WEIGHT
存储配额控制的相关参数,可以参考 Red Hat 文档中 blkio 这一章,了解它们的详细作用。
磁盘 IO 配额控制示例
blkio-weight
要使–blkio-weight 生效,需要保证 IO 的调度算法为 CFQ。可以使用下面的方式查看:
root@ubuntu:~# cat /sys/block/sda/queue/scheduler
noop [deadline] cfq
使用下面的命令创建两个–blkio-weight 值不同的容器:
docker run -ti –rm –blkio-weight 100 ubuntu:stress
docker run -ti –rm –blkio-weight 1000 ubuntu:stress
在容器中同时执行下面的 dd 命令,进行测试:
time dd if=/dev/zero of=test.out bs=1M count=1024 oflag=direct
最终输出如下图所示:
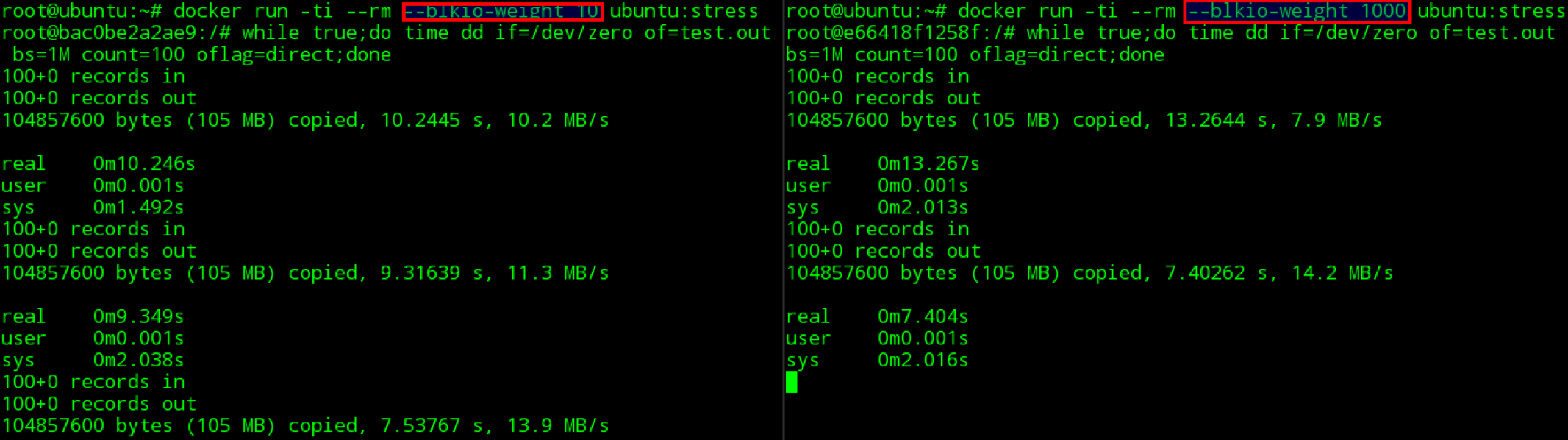
在我的测试环境上没有达到理想的测试效果,通过 docker 官方的 blkio-weight doesn’t take effect in docker Docker version 1.8.1 #16173,可以发现这个问题在一些环境上存在,但 docker 官方也没有给出解决办法。
device-write-bps
使用下面的命令创建容器,并执行命令验证写速度的限制。
docker run -tid –name disk1 –device-write-bps /dev/sda:1mb ubuntu:stress
通过 dd 来验证写速度,输出如下图示:

可以看到容器的写磁盘速度被成功地限制到了 1MB/s。device-read-bps 等其他磁盘 IO 限制参数可以使用类似的方式进行验证。
容器空间大小限制
在 docker 使用 devicemapper 作为存储驱动时,默认每个容器和镜像的最大大小为 10G。如果需要调整,可以在 daemon 启动参数中,使用 dm.basesize 来指定,但需要注意的是,修改这个值,不仅仅需要重启 docker daemon 服务,还会导致宿主机上的所有本地镜像和容器都被清理掉。
使用 aufs 或者 overlay 等其他存储驱动时,没有这个限制。
-Docker 监控容器资源的占用情况")
Docker (十九)-Docker 监控容器资源的占用情况
启动一个容器并限制资源
启动一个 centos 容器,限制其内存为 1G ,可用 cpu 数为 2
[root@localhost ~]# docker run --name os1 -it -m 1g --cpus=2 centos:latest bash启动容器后,可以使用 docker 的监控指令查看容器的运行状态
- docker top 容器名: 查看容器的进程,不加容器名即查看所有
- docker stats 容器名:查看容器的 CPU,内存,IO 等使用信息
[root@localhost ~]# docker stats os1
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
f9420cbbd2a9 os1 45.94% 47.09MiB / 1GiB 4.60% 54.6MB / 352kB 0B / 21.1MB 3安装 stress
在容器中安装 docker 容器压测工具 stress
#先安装一些基础工具
[root@f9420cbbd2a9 /]# yum install wget gcc gcc-c++ make -y
#下载stress
[root@f9420cbbd2a9 ~]# wget http://people.seas.harvard.edu/~apw/stress/stress-1.0.4.tar.gz
#安装 [root@f9420cbbd2a9 ~]# tar zxf stress-1.0.4.tar.gz [root@f9420cbbd2a9 ~]# cd stress-1.0.4 [root@f9420cbbd2a9 stress-1.0.4]./configure [root@f9420cbbd2a9 stress-1.0.4]# make [root@f9420cbbd2a9 stress-1.0.4]# make installstress 压测
在容器使用 stress 指令进行负载压测
[root@f9420cbbd2a9 ~]# stress -m 1204m --vm 2
#模拟出4个繁忙的进程消耗cpu,然后使用-m 模拟进程最大使用的内存数1024,使用--vm 指定进程数
使用 docker 指令查看容器运行状态,可以 os1 容器的内存和 cpu 都得到了限制,即使给压测时超出了最大内存,也不会额外占用资源
[root@localhost ~]# docker stats os1
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
f9420cbbd2a9 os1 127.46% 319.7MiB / 1GiB 31.22% 54.8MB / 356kB 0B / 33.6MB 9
Stress 参数说明
-? 显示帮助信息
-v 显示版本号
-q 不显示运行信息
-n,--dry-run 显示已经完成的指令执行情况
-t --timeout N 指定运行N秒后停止
--backoff N 等待N微妙后开始运行
-c --cpu 产生n个进程 每个进程都反复不停的计算随机数的平方根
-i --io 产生n个进程 每个进程反复调用sync(),sync()用于将内存上的内容写到硬盘上
-m --vm n 产生n个进程,每个进程不断调用内存分配malloc和内存释放free函数
--vm-bytes B 指定malloc时内存的字节数 (默认256MB)
--vm-hang N 指示每个消耗内存的进程在分配到内存后转入休眠状态,与正常的无限分配和释放内存的处理相反,这有利于模拟只有少量内存的机器
-d --hadd n 产生n个执行write和unlink函数的进程
--hadd-bytes B 指定写的字节数,默认是1GB
--hadd-noclean 不要将写入随机ASCII数据的文件Unlink时间单位可以为秒s,分m,小时h,天d,年y,文件大小单位可以为K,M,GStress 使用实例
-
产生 13 个 cpu 进程 4 个 io 进程 1 分钟后停止运行
$ stress -c 13 -i 4 --verbose --timeout 1m-
产生 3 个 cpu 进程、3 个 io 进程、2 个 10M 的 malloc ()/free () 进程,并且 vm 进程中 malloc 的字节不释放
$ stress --cpu 3 --io 3 --vm 2 --vm-bytes 10000000 --vm-keep --verbose-
测试硬盘,通过 mkstemp () 生成 800K 大小的文件写入硬盘,对 CPU、内存的使用要求很低
$ stress -d 1 --hdd-noclean --hdd-bytes 800k-
产生 13 个进程,每个进程都反复不停的计算由 rand () 产生随机数的平方根
$ stress -c 13-
产生 1024 个进程,仅显示出错信息
$ stress --quiet --cpu 1k-
产生 4 个进程,每个进程反复调用 sync (),sync () 用于将内存上的内容写到硬盘上
$ stress -i 4-
向磁盘中写入固定大小的文件,这个文件通过调用 mkstemp () 产生并保存在当前目录下,默认是文件产生后就被执行 unlink (清除) 操作,但是可以使用
--hdd-bytes选项将产生的文件全部保存在当前目录下,这会将你的磁盘空间逐步耗尽
# 生成小文件
$ stress -d 1 --hdd-noclean --hdd-bytes 13
# 生成大文件
$ stress -d 1 --hdd-noclean --hdd-bytes 3G : /var/run/docker.sock")
Docker in Docker(实际上是 Docker outside Docker): /var/run/docker.sock
在 Docker 容器里面使用 docker run/docker build?
Docker 容器技术目前是微服务/持续集成/持续交付领域的第一选择。而在 DevOps 中,我们需要将各种后端/前端的测试/构建环境打包成 Docker 镜像,然后在需要的时候,Jenkins 会使用这些镜像启动容器以执行 Jenkins 任务。
为了方便维护,我们的 CI 系统如 Jenkins,也会使用 Docker 方式部署。 Jenkins 任务中有些任务需要将微服务构建成 Docker 镜像,然后推送到 Harbor 私有仓库中。 或者我们所有的 Jenkins Master 镜像和 Jenkins Slave 镜像本身都不包含任何额外的构建环境,执行任务时都需要启动包含对应环境的镜像来执行任务。
我们的 Jenkins Master、Jenkins Slaves 都是跑在容器里面的,该如何在这些容器里面调用 docker run 命令启动包含 CI 环境的镜像呢? 在这些 CI 镜像里面,我们从源码编译完成后,又如何通过 docker build 将编译结果打包成 Docker 镜像,然后推送到内网仓库呢?
答案下面揭晓。
一、原理说明:/var/run/docker.sock
Docker 采取的是 Client/Server 架构,我们常用的 docker xxx 命令工具,只是 docker 的 client,我们通过该命令行执行命令时,实际上是在通过 client 与 docker engine 通信。
我们通过 apt/yum 安装 docker-ce 时,会自动生成一个 systemd 的 service,所以安装完成后,需要通过 sudo systemctl enable docker.service 来启用该服务。 这个 Docker 服务启动的,就是 docker engine,查看 /usr/lib/systemd/system/docker.service,能看到有这样一条语句:
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
默认情况下,Docker守护进程会生成一个 socket(/var/run/docker.sock)文件来进行本地进程通信,因此只能在本地使用 docker 客户端或者使用 Docker API 进行操作。 sock 文件是 UNIX 域套接字,它可以通过文件系统(而非网络地址)进行寻址和访问。
因此只要以数据卷的形式将 docker 客户端和上述 socket 套接字挂载到容器内部,就能实现 "Docker in Docker",在容器内使用 docker 命令了。具体的命令见后面的「示例」部分。
要记住的是,真正执行我们的 docker 命令的是 docker engine,而这个 engine 跑在宿主机上。所以这并不是真正的 "Docker in Docker".
二、示例
在容器内部使用宿主机的 docker,方法有二:
- 命令行方式:将
/usr/bin/docker映射进容器内部,然后直接在容器内部使用这个命令行工具docker- 需要的时候,也可以将
/etc/docker文件夹映射到容器内,这样容器内的docker命令行工具也会使用与宿主机同样的配置。
- 需要的时候,也可以将
- 编程方式:在容器内部以编程的方式使用 docker
- 通过 python 使用 docker: 在 Dockerfile 中通过
pip install docker将 docker client 安装到镜像中来使用
- 通过 python 使用 docker: 在 Dockerfile 中通过
容器的启动方式也有两种,如下:
1. 直接通过 docker 命令启动
示例命令如下:
docker run --name <name> \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /usr/bin/docker:/usr/bin/docker \
--user root \
<image-name>:<tag>
**必须以 root 用户启动!(或者其他有权限读写 /var/run/docker.sock 的用户)**然后,在容器内就能正常使用 docker 命令,或者访问宿主机的 docker api 了。
2. 使用 docker-compose 启动
docker-compose.yml 文件内容如下:
version: ''3.3''
services:
jenkins-master:
image: jenkinsci/blueocean:latest
container_name: jenkins-master
environment:
- TZ=Asia/Shanghai # 时区
ports:
- "8080:8080"
- "50000:50000"
volumes:
- ./jenkins_home:/var/jenkins_home # 将容器中的数据映射到宿主机
- /usr/bin/docker:/usr/bin/docker # 为容器内部提供 docker 命令行工具(这个随意)
- /var/run/docker.sock:/var/run/docker.sock # 容器内部通过 unix socket 使用宿主机 docker engine
user: root # 必须确保容器以 root 用户启动!(这样它才有权限读写 docker.socket)
restart: always
然后通过 docker-compose up -d 即可后台启动容器。
Docker 中的 uid 与 gid
通过上面的操作,我们在容器内执行 docker ps 时,还是很可能会遇到一个问题:权限问题。
如果你容器的默认用户是 root,那么你不会遇到这个问题,因为 /var/run/docker.sock 的 onwer 就是 root.
但是一般来说,为了限制用户的权限,容器的默认用户一般都是 uid 和 gid 都是 1000 的普通用户。这样我们就没有权限访问 /var/run/docker.sock 了。
解决办法:
方法一(不一定有效):在构建镜像时,最后一层添加如下内容:
# docker 用户组的 id,通常都是 999
RUN groupadd -g 999 docker \
&& usermod -aG docker <your_user_name>
这样我们的默认用户,就能使用 docker 命令了。
P.S.
999不一定是 docker 用户组,所以上述方法某些情况下可能失效。这时还是老老实实通过docker run -u root启动容器吧。(或者在docker-compose.yml中添加user: root属性)
参考
- Docker in Docker - 王柏元
关于Dockerd 资源泄露怎么办和docker内存泄露的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于167 docker docker构建nginx容器系列问题 docker registry docker run docker toolbo、Docker (二十)-Docker 容器 CPU、memory 资源限制、Docker (十九)-Docker 监控容器资源的占用情况、Docker in Docker(实际上是 Docker outside Docker): /var/run/docker.sock等相关知识的信息别忘了在本站进行查找喔。
本文标签:




