在本文中,您将会了解到关于Prometheus入门到放弃(4)之cadvisor监控docker容器的新资讯,同时我们还将为您解释prometheus监控docker容器的相关在本文中,我们将带你探索
在本文中,您将会了解到关于Prometheus入门到放弃(4)之cadvisor监控docker容器的新资讯,同时我们还将为您解释prometheus监控docker 容器的相关在本文中,我们将带你探索Prometheus入门到放弃(4)之cadvisor监控docker容器的奥秘,分析prometheus监控docker 容器的特点,并给出一些关于4.Docker容器学习之Dockerfile入门到放弃、CAdvisor + InfluxDB + Grafana是怎么搭建Docker容器监控系统、cAdvisor+InfluxDB+Grafana 监控Docker、cAdvisor+Prometheus+Grafana监控docker的实用技巧。
本文目录一览:- Prometheus入门到放弃(4)之cadvisor监控docker容器(prometheus监控docker 容器)
- 4.Docker容器学习之Dockerfile入门到放弃
- CAdvisor + InfluxDB + Grafana是怎么搭建Docker容器监控系统
- cAdvisor+InfluxDB+Grafana 监控Docker
- cAdvisor+Prometheus+Grafana监控docker
之cadvisor监控docker容器(prometheus监控docker 容器)")
Prometheus入门到放弃(4)之cadvisor监控docker容器(prometheus监控docker 容器)
Prometheus监控docker容器运行状态,我们用到cadvisor服务,cadvisor我们这里也采用docker方式直接运行。
1、下载镜像
[root@prometheus-server ~]# docker pull google/cadvisor2、运行
cadvisor我们需要运行在docker宿主机上(与node_exporter类似),然后通过HTTP方式供Prometheus获取数据
[root@prometheus-server ~]# docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--volume=/cgroup:/cgroup:ro \
--privileged=true \
--publish=9101:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor注意:这里是把容器8080端口映射到主机9101,cadvisor有web界面地址:http://IP:9101
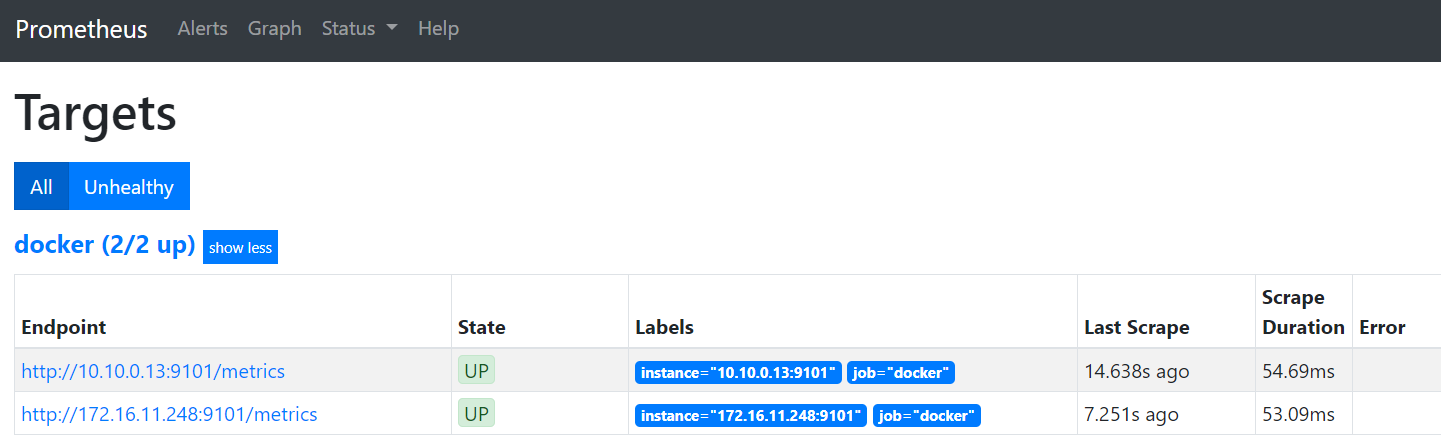
3、配置 Prometheus 添加docker容器监控目标
[root@prometheus-server ~]# vim /etc/prometheus/prometheus.yml
.....
### 新增对对docker容器的监控
- job_name: ''docker''
static_configs:
- targets: [''172.16.11.248:9101'',''10.10.0.13:9101''] ## 目标主机然后重启prometheus,看Prometheus界面targets是否有新增加的主机
4、接入Grafana展示容器监控数据
这里我们去Grafana官网,找别人做好的Dashboard模板,地址:https://grafana.com/dashboards/4170,下载模板json文件然后导入本地Grafana。关于导入Dashbozrd模板参考https://www.cnblogs.com/tchua/p/11115146.html
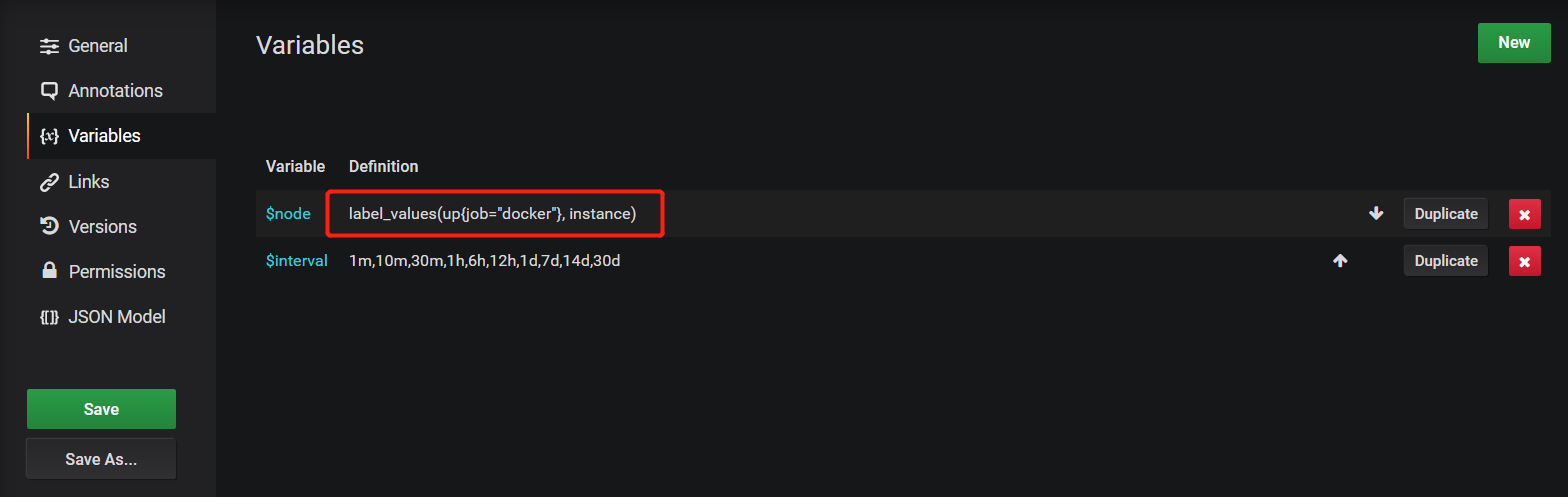
模板导入后需要修改几个地方:
1)修改label_values(up{job="container"}, instance),container改为对应的值,可以通过Prometheus界面查询具体的job对应名称。
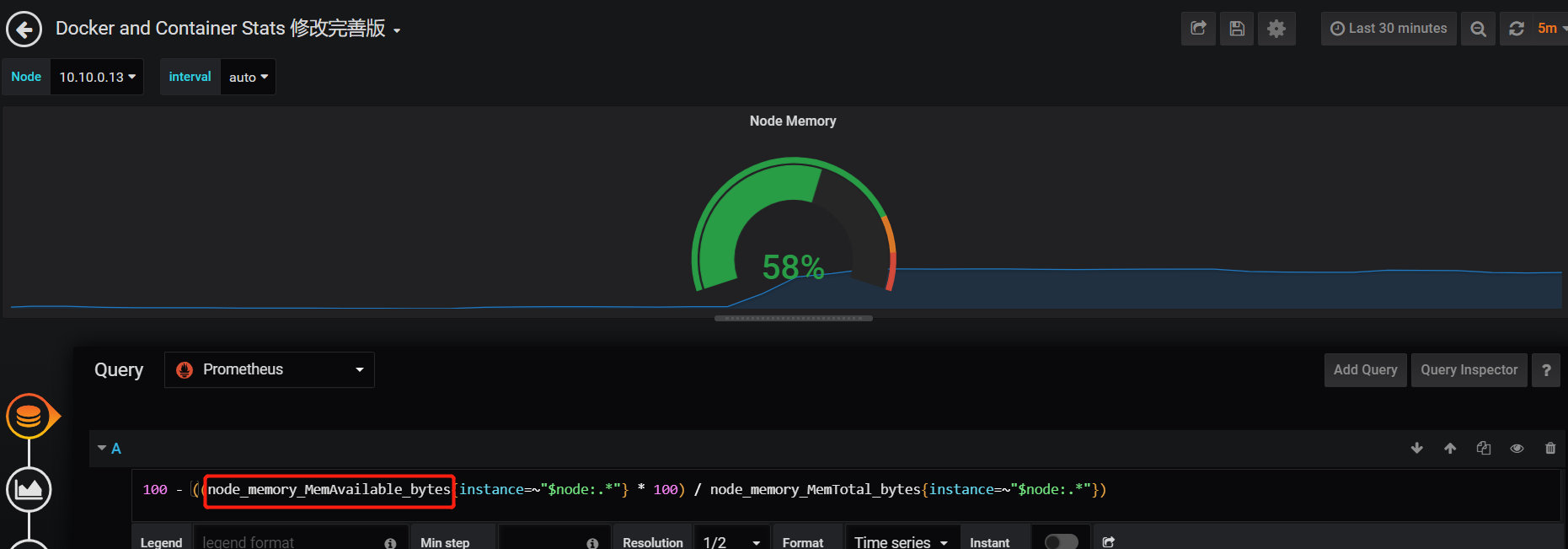
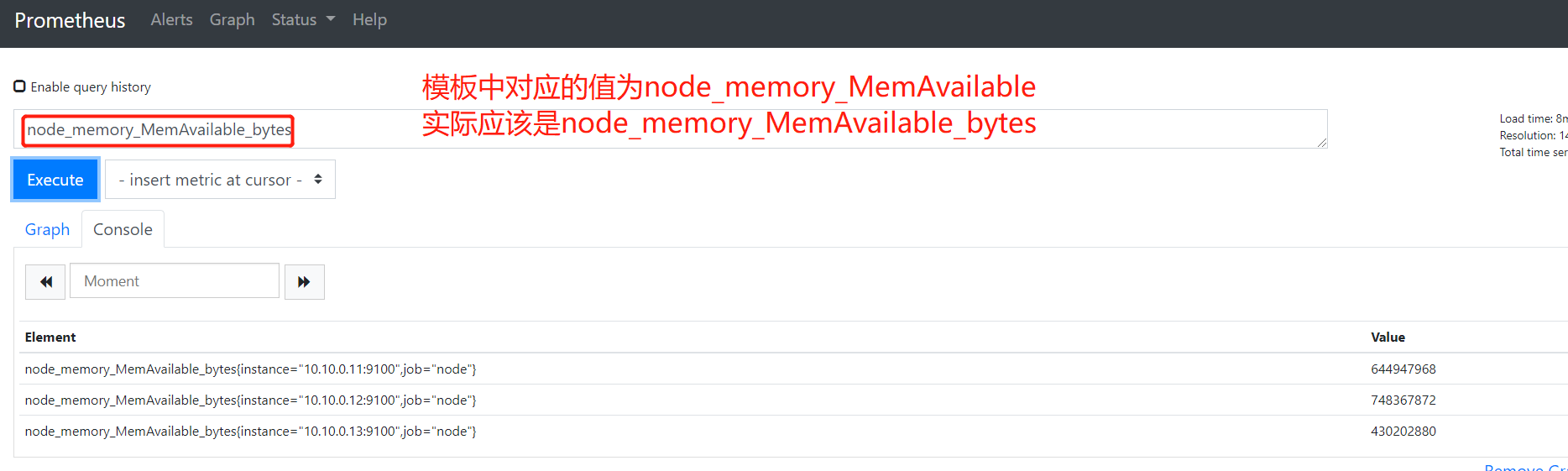
2)修改监控图形中公式值,因为该模板不是基于最新版Node_exporter开发,有些值并不适用,我们需要修改对应的值,具体我们也可以通过Prometheus查询界面确定value值。
5、查看Dashboard面板
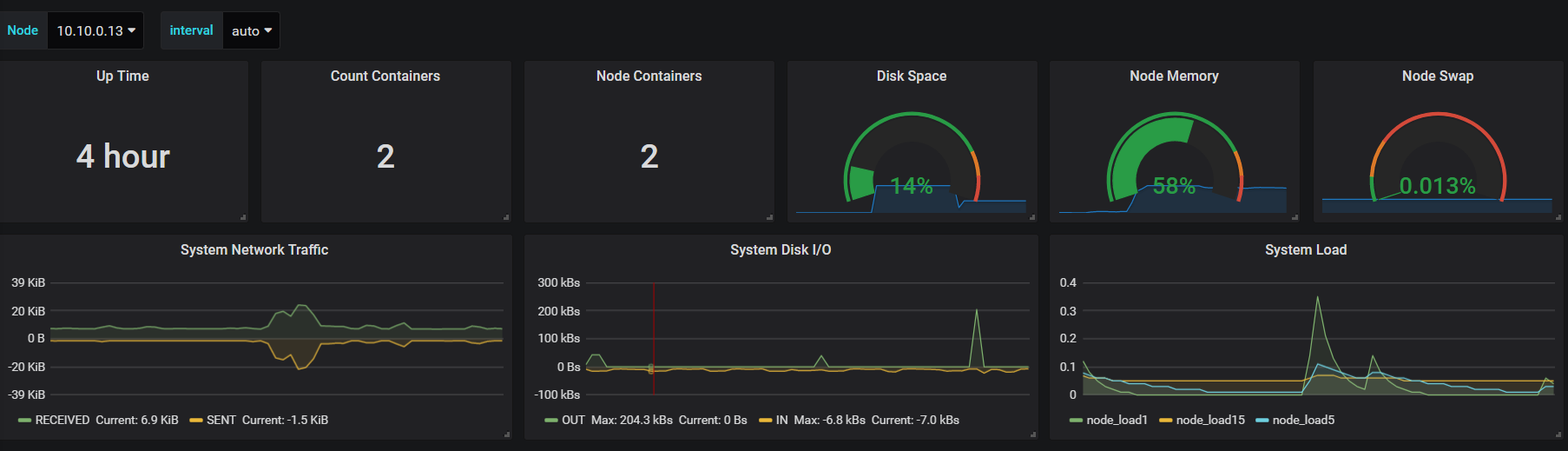
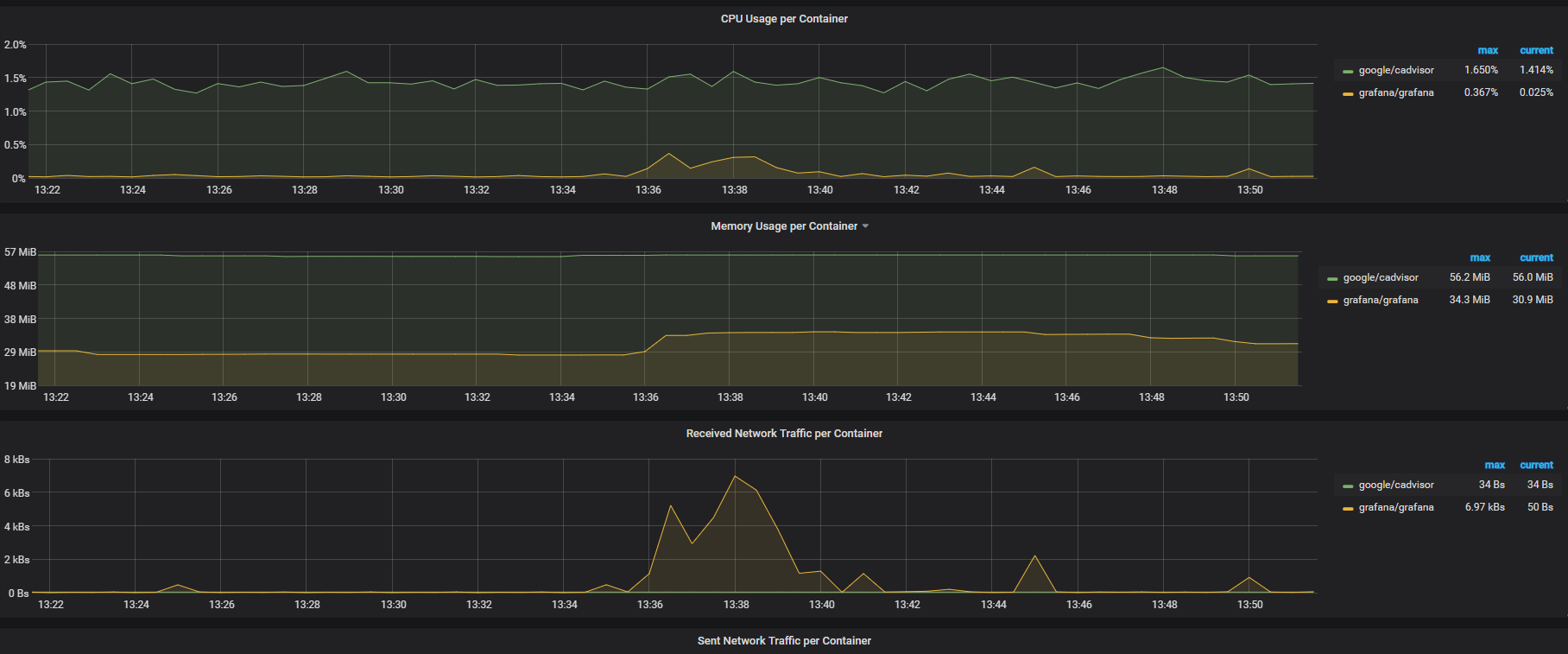
可以看到不仅可以监控node节点容器的信息,还可以简单展示dokcer容器宿主机的系统状况,并可以在左上角Node处选择不同的node节点查看不同的node节点上的docker运行信息。

4.Docker容器学习之Dockerfile入门到放弃
文章目录
-
-
-
- 0x01 Dockerfile 编写
-
- 1.基本结构与格式
- 2.指令参数
-
- 1)FROM - 基础镜像信息
- 2)LABEL - 标签信息
- 3)MAINTAINER - 维护者信息
- 4)RUN - 镜像操作命令:
- 5)CMD- 容器启动时执行指令
- 6)EXPOSE - 端口映射指令
- 7)env - 修改环境变量指令
- 8)ARG - 构建参数
- 9)ADD - 添加指定目录文件到容器指令
- 10)COPY - 复制指定文件或者目录到容器中
- 11)ENTRYPOINT - 配置容器启动进入后的执行命令-应用运行前的准备工作
- 13)VOLUME- 创建本地主机或其他主机挂载点-定义匿名卷
- 13)USER- 指定容器运行时名用户名或者UID
- 14) WORKDIR - 配置工作目录
- 15) ONBUILD - 为他人做嫁衣裳
- 16)STOPSIGNAL - 指定所创建镜像启动的容器接收退出的信号值:
- 17)SHELL - 指定其他命令使用shell时默认的shell类型
- 18)HEALTHCHECK - 健康检查
- 3.补充知识
- 4.dockerfile实战
- 0x02 Docker 优化使用
-
- 1.Dockerfile 最佳实践
- 2.Dockerfile 指令最佳实践
- 3.Dockerfile 操作系统
-
-
0x01 Dockerfile 编写
描述:Dockerfile是一个文本格式的配置文件,其内包含了一条条的指令(Instruction),每一条指令构建一层,因此每一条指令的内容,就是描述该层应当如何构建。
用户可以使用Dockerfile快速创建自定义的镜像;通过它所支持的内部指令,以及使用它创建镜像的基本过程,Docker拥有"一点修改代替大量更新"的灵活之处;
- 文本化的镜像生成操作让其方便版本管理和自动化部署;
- 每条命令对应镜像的一层,细化操作后保证其可增量更新,复用镜像块减小镜像体积(后面您会体验到);
总结为一点就是将每一层修改、安装、构建、操作命令都写入到一个脚本之中
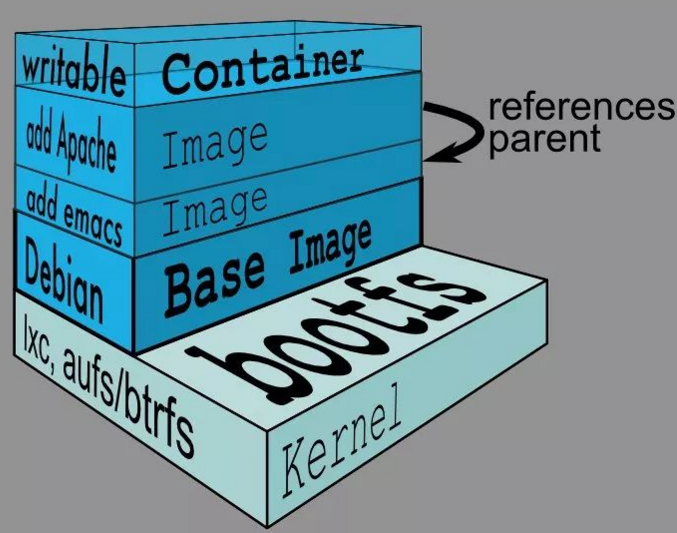
1.基本结构与格式
Dockerfile分为四个部分:
- 基础镜像信息:
FROM \<image\> 或者 FROM \<image\>:\<tag\> - 维护者信息: MAINTAINER
- 镜像操作指令: RUN
- 容器启动时执行指令: CMD
例如:在/opt/dockerfile/目录中利用dockerfile创建一个基于ubuntu的nginx容器与vnc服务;
#Usage: docker build -t create_repo/first_tag /opt/dockerfile/
#copycrity
#1.第一行必须指定基于的基础镜像
FROM ubuntu
#2.前期操作处理
LABEL version="1.0" #容器元信息,帮助信息,Metadata,类似于代码注释
LABEL maintainer="weiyigeek@163.com"
MAINTAINER weiyigeek weiyigeek@qq.com #会影响实际仓库的拉取
WORKDIR /opt/demo #切换工作空间(建议使用绝对路径)
ADD /opt/package /data/ # 把本地文件目录添加到镜像中
ENV MYSQL_VERSION 5.6 # 设置一个mysql常量 环境变量,尽可能使用ENV增加可维护性
#3.镜像的操作命令
#RUN指令时对镜像执行跟随的命令,每运行一条RUN指令,镜像添加新的一层并提交;
RUN echo "deb http://archive.ubuntu.com/ubuntu/ raring main uiverse" >> /etc/apt/source.list
RUN apt-het update && apt-get install -y nginx \
net-tools mysql-server="${MYSQL_VERSION}"
RUN echo "\ndaemon off;" >> /etc/nginx/nginx.conf
#4.镜像启动时候执行的命令
CMD /usr/sbin/nginx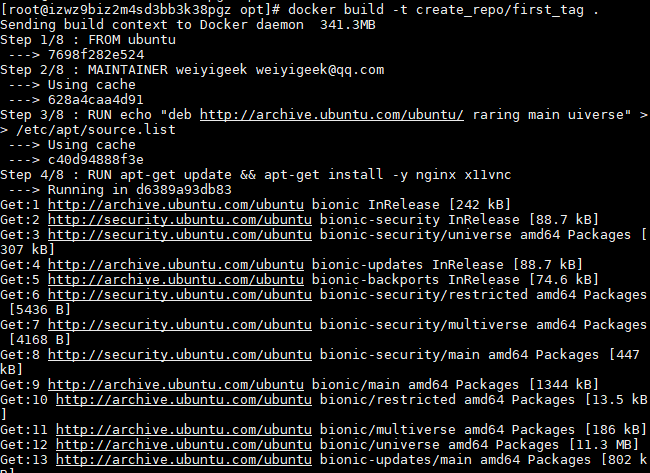
在编写完成Dockerfile之后可以通过docker build 命令来创建镜像,该命令读取指定路径下(包括子目录)的dockerfile(实际上是构建上下文Context),并将该路径下的内容发送给Docker服务端由它创建镜像;
因此一般建议放置Dockerfile的目录为空另外可以通过dockerignore文件(每一行添加一条匹配模式)会让Docker忽略路径下的目录和文件;
docker 镜像生成常用命令:
docker build [选项]
- t :指定标签信息
--build-arg <参数名>=<值>
# 构建镜像的几种方式:
#1) 指定的Dockfile所在路径为/tmp/docker_builder
$docker build -t [TAG/version] /tmp/docker_builder
#2) 支持从 URL 构建
$docker build https://github.com/twang2218/gitlab-ce-zh.git#:11.1
#3) 用给定的 tar 压缩包构建
$docker build http://server/context.tar.gz
#4) 从标准输入中读取 Dockerfile 进行构建
$docker build - < Dockerfile
$cat Dockerfile | docker build -
#5) 从标准输入中读取上下文压缩包进行构建
$docker build - < context.tar.gz #标准输入的文件格式还可以是 gzip、bzip2 以及 xz 2.指令参数
Dockerfile指令参数(Instruction arguments)如下:
1)FROM - 基础镜像信息
描述:尽可能使用当前官方仓库作为你构建镜像的基础,推荐使用[Alpine](https://hub.docker.com/_/alpine/)镜像,因为它被严格控制并保持最小尺寸(目前小于 6 MB),但它仍然是一个完整的发行版。
# 基础语法
FROM <image> 或者 FROM <image>:<tag>
# 使用案例
FROM alpine
FROM golang:1.9-alpine as builder #注意:多阶段构建使用 as 来为某一阶段命名,例如2)LABEL - 标签信息
描述:可以给镜像添加标签来帮助组织镜像、记录许可信息、辅助自动化构建等
注意:如果你的字符串包含空格,那么它必须被引用或者空格必须被转义。如果您的字符串包含内部引号字符("),则也可以将其转义。
# 基础语法:每个标签一行,由 LABEL 开头加上一个或多个标签对。
LABEL key=<value>
# 使用案例
# Set one or more individual labels `#`开头的行是注释内容。
LABEL vendor="ACME Incorporated"
LABEL version=1.1
LABEL com.example.version="0.0.1-beta"
LABEL com.example.release-date="2015-02-12"Tips(1): 在 1.10 之前,建议将所有标签合并为一条LABEL指令,以防止创建额外的层,但是现在这个不再是必须的了,以上内容也可以写成下面这样:
# Set multiple labels at once, using line-continuation characters to break long lines
LABEL vendor=ACME\ Incorporated \
version=1.1 \
com.example.version="0.0.1-beta" \
com.example.release-date="2015-02-12"3)MAINTAINER - 维护者信息
# 基础语法
MAINTAINER key=<value>
# 使用案例
MAINTAINER WeiyiGeek master@weiyigeek.top4)RUN - 镜像操作命令:
描述:为了保持 Dockerfile 文件的可读性,以及可维护性,建议将长的或复杂的RUN指令用反斜杠\分割成多行。
RUN 指令最常见的用法是安装包用的apt-get,因为该指令会安装包,所以有几个问题需要注意。
-
- 不要使用
RUN apt-get upgrade 或 dist-upgrade, 如果基础镜像中的某个包过时了,你应该联系它的维护者。
- 不要使用
-
- 如果你确定某个特定的包比如 foo 需要升级,使用
apt-get install -y foo就行,该指令会自动升级 foo 包。
- 如果你确定某个特定的包比如 foo 需要升级,使用
-
- 最好将 RUN 多条语句汇集成为一条
apt-get update和apt-get install以及rm -rf /var/lib/apt/lists*组合成一条 RUN 声明
- 最好将 RUN 多条语句汇集成为一条
# 基础语法
RUN <COMMAND> 或者 RUN ["executable","param1","param2"]
# 使用案例
如:RUN ["/bin/bash","-c","echo Hello"],当命令较长时可以使用\来换行;
RUN apt-get update;\
apt-get install -y nginx ;\
rm -rf /var/lib/apt/lists/*
#展示了所有关于 apt-get 的建议
#其中 s3cmd 指令指定了一个版本号`1.1.*`。如果之前的镜像使用的是更旧的版本,指定新的版本会导致 apt-get udpate 缓存失效并确保安装的是新版本。
RUN apt-get update && apt-get install -y \
aufs-tools \
automake \
build-essential \
curl \
dpkg-sig \
libcap-dev \
libsqlite3-dev \
mercurial \
reprepro \
ruby1.9.1 \
ruby1.9.1-dev \
s3cmd=1.1.* \
&& rm -rf /var/lib/apt/lists/*Tips(1):为何建议将RUN写在一行目录之中?
- 1.比如假设你有一个 Dockerfile 文件:将 apt-get update 放在一条单独的 RUN 声明中会导致缓存问题以及后续的 apt-get install 失败。
FROM ubuntu:18.04
RUN apt-get update
RUN apt-get install -y curl- 2.构建镜像后所有的层都在 Docker 的缓存中。假设你后来又修改了其中的
apt-get install添加了一个包。
FROM ubuntu:18.04
RUN apt-get update
RUN apt-get install -y curl nginx- 3.Docker 发现修改后的 RUN apt-get update 指令和之前的完全一样。所以
apt-get update不会执行,而是使用之前的缓存镜像。因为 apt-get update 没有运行后面的apt-get install可能安装的是过时的 curl 和 nginx 版本。
解决办法:采用cache busting(缓存破坏)的方式进行:
#方式1.使用`RUN apt-get update && apt-get install -y` 可以确保你的`Dockerfiles`每次安装的都是包的最新的版本,而且这个过程不需要进一步的编码或额外干预。
#方式2.固定版本会迫使构建过程检索特定的版本来达到 `cache-busting`目的,而不管缓存中有什么,该项技术也可以减少因所需包中未预料到的变化而导致的失败。
RUN apt-get update && apt-get install -y \
package-bar \
package-baz \
package-foo=1.3.*Tips(2): 清理掉 apt 缓存 rm -rf /var/lib/apt/lists/* 可以减小镜像大小,因为 RUN 指令的开头为 apt-get udpate包缓存总是会在 apt-get install 之前刷新。
- 注意:官方的 Debian 和 Ubuntu 镜像会自动运行 apt-get clean,所以不需要显式的调用 apt-get clean。
5)CMD- 容器启动时执行指令
描述:指令用于执行目标镜像中包含的软件和任何参数, 实际上为容器提供一个默认的执行命令。
- 在Dockerfile中CMD被用来为ENTRYPOINT指令提供参数,则CMD和ENTRYPOINT指令都应该使用exec格式
- 当基于镜像的容器运行时将会自动执行CMD指令, 并且如果在docker run命令中指定了参数,这些参数将会覆盖在CMD指令中设置的参数。
多数情况下CMD 都需要一个交互式的 shell (bash, Python, perl 等),例如 CMD [“perl”, “-de0”],或者 CMD [“PHP”, “-a”]。使用这种形式意味着,当你执行类似docker run -it python时,你会进入一个准备好的 shell 中。
#基础语法
#CMD指令有如下三种格式
#exec格式
CMD ["executable","param1","param2"]
#为ENTRYPOINT提供参数
CMD ["param1","param2"]
#shell格式,在/bin/bash中执行提供给需要交互的应用
CMD command param1 param2
# 基础示例
#(1)如果创建镜像的目的是为了部署某个服务(比如 Apache)
CMD ["apache2", "-DFOREGROUND"]
#(2)如果使用 shell 格式的话,实际的命令会被包装为 sh -c 的参数的形式进行执行。比如:
CMD echo $HOME #在实际执行中,会将其变更为: CMD [ "sh", "-c", "echo $HOME" ]注意事项:
- (1)如果用户启动容器指定了运行命令则会覆盖掉CMD指定命令,注意每个Dockerfile只能有一条CMD命令,如果指定了多条命令只有最后一条执行;
- (2)CMD 在极少的情况下才会以 CMD [“param”, “param”] 的形式与
ENTRYPOINT协同使用,除非你和你的镜像使用者都对 ENTRYPOINT 的工作方式十分熟悉。
6)EXPOSE - 端口映射指令
描述:EXPOSE指令用于指定容器将要监听的端口。因此你应该为你的应用程序使用常见的端口。
对于外部访问,用户可以在执行 docker run 时使用一个标志来指示如何将指定的端口映射到所选择的端口。
#基础语法
EXPOSE <port> [<port>...]
#基础示例
# (1) 告诉dokcer服务端容器暴露的端口号,供互联系统使用; 也就是 docker run -P 时会自动随机映射 EXPOSE 的端口。
EXPOSE 22 80 8443
# (2) 例如提供 Apache web 服务的镜像应该使用 80,而提供 MongoDB 服务的镜像使用 27017
EXPOSE 80 270177)env - 修改环境变量指令
描述:为了方便新程序运行,你可以使用ENV来为容器中安装的程序更新 PATH 环境变量。例如使用ENV PATH /usr/local/nginx/bin:$PATH来确保CMD ["nginx"]能正确运行。类似于程序中的常量,该方法可以让你只需改变 ENV 指令来自动的改变容器中的软件版本。
# 基础语法
ENV <key> <value> #会被后续的RUN指令使用,并在容器运行时保持;
# 基础示例
#方式1: 如RUN还是运行时的应用,都可以直接使用这里定义的环境变量。
ENV PG_MAJOR 9.3
ENV PATH /usr/local/postgres-\$PG_MAJOR/bin:$PATH
RUN curl -SL http://example.com/postgre-$PG_MAJOR.tar.xz && ENV PATH /usr/local/postgres-$PG_MAJOR/bin:$PATH
#方式2: 将所有的环境变量定义在一条ENV语句中
ENV VERSION=1.0 DEBUG=on \
NAME="Happy Feet"8)ARG - 构建参数
描述:构建参数和 ENV 的效果一样都是设置环境变量不同点就是容器构建完成则失效;
ARG <参数名> [=<默认值>]
# 调用方式与Shell中一致
${IMG_PATH}9)ADD - 添加指定目录文件到容器指令
描述:该命令将复制指定的源文件<src>到容器中的目标文件<dest>,其中<src>可以是在Dockerfile所在的目录的一个相对路径(文件或者目录)/URL/tar文件(本地 tar 提取和远程 URL 支持);
# 基础语法
ADD <src> <dest>
# 基础示例
# (1)最佳用例是将本地tar文件自动提取到镜像中
ADD rootfs.tar.xz
# (2)下载后的文件权限自动设置为 600 这个自动解压缩的功能非常有用;
ADD ubuntu-xenial-core-cloudimg-amd64-root.tar.gz
ADD --chown=55:mygroup files* /mydir/
ADD $PWD /opt/blog/ #复制到目录之中注意事项:
- (1)为了让镜像尽量小,最好不要使用 ADD 指令从远程 URL 获取包,而是使用 curl 和 wget。
#你可以在文件提取完之后删掉不再需要的文件来避免在镜像中额外添加一层
#比如尽量避免下面的用法:
ADD http://example.com/big.tar.xz /usr/src/things/
RUN tar -xJf /usr/src/things/big.tar.xz -C /usr/src/things
RUN make -C /usr/src/things all
#而是应该使用下面这种方法:由于使用的管道操作,所以没有中间文件需要删除。
RUN mkdir -p /usr/src/things \
&& curl -SL http://example.com/big.tar.xz \
| tar -xJC /usr/src/things \
&& make -C /usr/src/things all10)COPY - 复制指定文件或者目录到容器中
描述:COPY只支持简单将本地文件拷贝到容器中它比 ADD 更透明,所以ADD和COPY功能类似但一般优先使用 COPY ;
COPY 指令将从构建上下文目录中 <源路径> 的文件/目录复制到新的一层的镜像内的 <目标路径> 位置。
当目标路径不存在时候自动创建,当使用本地目录作为源目录时候推荐使用COPY:
# 基础语法
COPY <src> <dest>
# 选项
--from=多阶段构建的镜像名称 #FROM Alpine AS [名称]
# 常规方式
COPY package.json /usr/src/app/
#<源路径> 可以是多个,甚至可以是通配符
COPY hom* /mydir/
COPY hom?.txt /mydir/
# 选项来改变文件的所属用户及所属组。
COPY --chown=55:mygroup files* /mydir/
COPY --from=0 /go/src/github.com/go/helloworld/app . #多阶段构建,从上一阶段的镜像中复制文件
COPY --from=nginx:latest /etc/nginx/nginx.conf /nginx.conf #复制任意镜像中的文件(但需要指定镜像名称)Tips:
- 对于其他不需要 ADD 的自动提取功能的文件或目录,你应该使用 COPY。
- 采用CPOY --from 从上一个构建阶段拷贝文件时,使用的路径是相对于上一阶段的根目录的,此时建议复制成果时候采用绝对路径;
11)ENTRYPOINT - 配置容器启动进入后的执行命令-应用运行前的准备工作
描述:设置镜像的主命令,允许将镜像当成命令本身来运行(用 CMD 提供默认选项)。
# 基础示例
#exec格式推荐的格式
ENTRYPOINT ["executable","param1","param2"]
#shell格式:使用ENTRYPONT指令并不可被docker run提供的参数覆盖(与CMD不同之处)
ENTRYPOINT command param1 param2 #shell中执行
# 基础示例
# 1.例如下面的示例镜像提供了命令行工具 s3cmd:
ENTRYPOINT ["s3cmd"]
CMD ["--help"]
#现在直接运行该镜像创建的容器会显示命令帮助: $ docker run s3cmd
#或者提供正确的参数来执行某个命令:$ docker run s3cmd ls s3://mybucket
# 2.使用ENTRYPOINT 的exec形式来设置相对稳定的默认命令和参数,然后使用任何形式的CMD指令来设置可能发生变化的参数。
FROM alpine
ENTRYPOINT ["top", "-b"]
CMD ["-c"]
#当运行容器是,可以看到只有一个top进程在运行:
$ docker run -it --rm --name alpine:test top -H
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 19744 2336 2080 R 0.0 0.1 0:00.04 top
$ docker exec -it alpine:test ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 2.6 0.1 19752 2352 ? Ss+ 08:24 0:00 top -b -H
root 7 0.0 0.1 15572 2164 ? R+ 08:25 0:00 ps aux
# 3.ENTRYPOINT指令的shell格式
#通过为ENTRYPOINT指定文本格式的参数,此参数将在`/bin /sh -c` 中进行执行
#该形式将使用shell处理而不是shell环境变量,并且将忽略任何的CMD或docker run运行命令行参数。
FROM alpine
ENTRYPOINT exec top -b补充说明:
-
- ENTRYPOINT 指令也可以结合一个辅助脚本使用,和前面命令行风格类似,即使启动工具需要不止一个步骤。
注意:该脚本使用了 Bash 的内置命令 exec,所以最后运行的进程就是容器的 PID 为 1 的进程。这样,进程就可以接收到任何发送给容器的 Unix 信号了。
#例如:Postgres 官方镜像使用下面的脚本作为 ENTRYPOINT;
#!/bin/bash
set -e
if [ "$1" = ''postgres'' ]; then
chown -R postgres "$PGDATA"
if [ -z "$(ls -A "$PGDATA")" ]; then
gosu postgres initdb
fi
exec gosu postgres "$@"
fi
exec "$@"该辅助脚本被拷贝到容器,并在容器启动时通过 ENTRYPOINT 执行:
COPY ./docker-entrypoint.sh /
ENTRYPOINT ["/docker-entrypoint.sh"]该脚本可以让用户用几种不同的方式和 Postgres 交互
$ docker run postgres
$ docker run postgres postgres --help
$ docker run --rm -it postgres bash #启动另外一个完全不同的工具,比如 Bash:- 2.通过ENTRYPOINT指令可以将容器设置作为可执行的文件
- docker run
<image>命令行参数将会被追加到exec格式的ENTRYPOINT所有元素之后,并将会覆盖使用CMD指定的所有元素,此时是允许将参数传递到入口点;
- docker run
#下面是是启动一个nginx的例子端口为80:
docker run -i -t --rm -p 80:80 nginx
#例如,docker run <Image> -d 将通过-d 参数传递到入口点
#例如,docker run –entrypoint 字段覆盖"ENTRYPOINT "指令下面的Dockerfile显示使用ENTRYPOINT在前台运行Apache:
FROM debian:stable
RUN apt-get update && apt-get install -y --force-yes apache2
EXPOSE 80 443
VOLUME ["/var/www", "/var/log/apache2", "/etc/apache2"]
ENTRYPOINT ["/usr/sbin/apache2ctl", "-D", "FOREGROUND"]注意:当指定多个ENTRYPOINT时候只有最后一个生效;
13)VOLUME- 创建本地主机或其他主机挂载点-定义匿名卷
描述:指令用于暴露任何数据库存储文件,配置文件,或容器创建的文件和目录。强烈建议使用 VOLUME来管理镜像中的可变部分和用户可以改变的部分。
- VOLUME指令只是起到了声明了容器中的目录作为匿名卷,
但是并没有将匿名卷绑定到宿主机指定目录的功能; - 镜像run了一个容器的时候,
docker会在安装目录下的指定目录下面生成一个目录来绑定容器的匿名卷(这个指定目录不同版本的docker会有所不同)
# 基础示例:
VOLUME ["<路径1>", "<路径2>"...]
# 实际示例:
#一般用来存放数据和需要保持的数据等,在运行的时候我们就可以利用 -v /Store/data(宿主机):/date(容器),数据就可以直接存在在宿主机上面;
VOLUME ["/data"]13)USER- 指定容器运行时名用户名或者UID
描述:如果某个服务不需要特权执行,建议使用 USER 指令切换到非 root 用户。
注意事项:
- 1.在镜像中用户和用户组每次被分配的 UID/GID 都是不确定的,下次重新构建镜像时被分配到的 UID/GID 可能会不一样。
如果要依赖确定的 UID/GID 你应该显示的指定一个 UID/GID。
# 方式1
RUN groupadd -r postgres -g 1001 && useradd -r -g postgres postgres -u 1001
# 方式2
RUN useradd -r -u 1001 -U postgres- 2.应该避免使用 sudo 命令因为它不可预期的 TTY 和信号转发行为可能造成的问题比它能解决的问题还多。如果你真的需要和 sudo 类似的功能(
例如以 root 权限初始化某个守护进程,以非 root 权限执行它)你可以使用 gosu 命令; 最后为了减少层数和复杂度,避免频繁地使用 USER 来回切换用户。
# 基础示例
#(1) 当服务不需要管理员权限时,可以通过该命令指定运行用户,并且可以在之前创建所需要的用户
USER daemon
#(2)要临时获取管理员权限可以使用gosu而不使用sudo;
#USER 只是帮助你切换到指定用户而已,这个用户必须是事先建立好的,否则无法切换。
RUN groupadd -r postgres && useradd -r -g postgres postgres
USER redis14) WORKDIR - 配置工作目录
描述:为了清晰性和可靠性,你应该总是在WORKDIR中使用绝对路径。另外你应该使用 WORKDIR 来替代类似于 RUN cd … && do-something 的指令,后者难以阅读、排错和维护。
# 基础示例
#(1)为后续的RUN CMD ENTRYPOINT 指令配置工作目录
WORKDIR /path/to/workdir
#(2)可以使用多个WORKDIR指令,后续命令如果参数是相对路径,则会基于之前的命令指定的路径
WORKDIR /a
WORKDIR b
WORKDIR C
RUN pwd #最终路径是/a/b/c15) ONBUILD - 为他人做嫁衣裳
描述:ONBUILD是一个特殊的指令在当前镜像构建时并不会被执行。只有当以当前镜像为基础镜像去构建下一级镜像的时候才会被执行。它后面跟的是其它指令比如 RUN, COPY 等
Dockerfile 中的其它指令都是为了定制当前镜像而准备的,唯有 ONBUILD 是为了帮助别人定制自己而准备的。
为了方便我们理解先来看一个示例:
假设我们要制作 Node.js 所写的应用的镜像。我们都知道 Node.js 使用 npm 进行包管理,所有依赖、配置、启动信息等会放到 package.json 文件里。在拿到程序代码后,需要先进行 npm install 才可以获得所有需要的依赖然后再通过 npm start 来启动应用。
Dockerfile
FROM node:slim
RUN mkdir /app
WORKDIR /app
COPY ./package.json /app
RUN [ "npm", "install" ]
COPY . /app/
CMD [ "npm", "start" ]把这个 Dockerfile 放到 Node.js 项目的根目录,构建好镜像后,就可以直接拿来启动容器运行。
但是如果我们还有第二个 Node.js 项目也差不多呢?
好吧那就再把这个 Dockerfile 复制到第二个项目里那如果有第三个项目呢?再复制么?文件的副本越多,版本控制就越困难,让我们继续看这样的场景维护的问题:如果第一个 Node.js 项目在开发过程中,发现这个 Dockerfile 里存在问题,比如敲错字了、或者需要安装额外的包,然后开发人员修复了这个 Dockerfile,再次构建,问题解决。
第一个项目没问题了,但是第二个项目呢?
虽然最初 Dockerfile 是复制、粘贴自第一个项目的,但是并不会因为第一个项目修复了他们的 Dockerfile,而第二个项目的 Dockerfile 就会被自动修复。
那么我们可不可以做一个基础镜像,然后各个项目使用这个基础镜像呢?
答案是显而易见这样基础镜像更新,各个项目不用同步 Dockerfile 的变化,重新构建后就继承了基础镜像的更新?好吧,可以让我们看看这样的结果。
那么上面的这个 Dockerfile 就会变为:
FROM my-node
RUN mkdir /app
WORKDIR /app
CMD [ "npm", "start" ]现在把相关构建的指令拿出来放在子项目里面,此时假如基础镜像名称为my-node各个项目内的自己Dockerfile变成如下:
FROM node:slim
COPY ./package.json /app
RUN [ "npm", "install" ]
COPY . /app/基础镜像变化后,各个项目都用这个 Dockerfile 重新构建镜像,会继承基础镜像的更新。
那么,问题解决了么?
没有准确说,只解决了一半。如果这个 Dockerfile 里面有些东西需要调整呢?比如 npm install 都需要加一些参数,那怎么办?这一行 RUN 是不可能放入基础镜像的,因为涉及到了当前项目的 ./package.json,难道又要一个个修改么?所以说这样制作基础镜像,只解决了原来的 Dockerfile 的前4条指令的变化问题,而后面三条指令的变化则完全没办法处理。
完整解决Dockerfile
#当我们需要在一个镜像中操作添加更新然后打包放在子项目中,在以后的日子里都以此镜像来更新创建容器,为了方便版本控制所以引入了ONBUILD指令
FROM node:slim
RUN mkdir /app
WORKDIR /app
ONBUILD COPY ./package.json /app
ONBUILD RUN [ "npm", "install" ]
ONBUILD COPY . /app/
CMD [ "npm", "start" ]
#在构建基础镜像的时候 -t my-node,这三行ONBUILD并不会被执行,然后各个项目的 Dockerfile 就变成了简单地:
FROM my-node
#当在各个项目目录中,用这个只有一行的 Dockerfile 构建镜像时,之前基础镜像的那三行 ONBUILD 就会开始执行,成功的将当前项目的代码复制进镜像、并且针对本项目执行 npm install,生成应用镜像。16)STOPSIGNAL - 指定所创建镜像启动的容器接收退出的信号值:
# 实际示例
STOPSIGNAL signal17)SHELL - 指定其他命令使用shell时默认的shell类型
# 实际示例
SHELL ["/bin/sh","-c"]18)HEALTHCHECK - 健康检查
描述:该命令设置检查容器健康状况的命令,它与 kubernetes 中的 Pod 探针类似;
在没有 HEALTHCHECK 指令前Docker 引擎只可以通过容器内主进程是否退出来判断容器是否状态异常。很多情况下这没问题,但是如果程序进入死锁状态,或者死循环状态,应用进程并不退出,但是该容器已经无法提供服务了。
- 在 1.12 以前,Docker 不会检测到容器的这种状态,从而不会重新调度,导致可能会有部分容器已经无法提供服务了却还在接受用户请求。
- 从 Docker 1.12 引入该指令
HEALTHCHECK指令是告诉 Docker 应该如何进行判断容器的状态是否正常,从而比较真实的反应容器实际状态。
当在一个镜像指定了 HEALTHCHECK 指令后,用其启动容器,初始状态会为 starting,在 HEALTHCHECK 指令检查成功后变为 healthy,如果连续一定次数失败,则会变为 unhealthy。
# 基础语法
#命令的返回值决定了该次健康检查的成功与否:0:成功;1:失败;2:保留,不要使用这个值。
HEALTHCHECK [选项] CMD <命令>
# 选项:
--interval=<间隔>:两次健康检查的间隔,默认为 30 秒;
--timeout=<时长>:健康检查命令运行超时时间,如果超过这个时间本次健康检查就被视为失败默认 30 秒;
--retries=<次数>:当连续失败指定次数后,则将容器状态视为 unhealthy,默认 3 次。
# 如果基础镜像有健康检查指令,使用这行可以屏蔽掉其健康检查指令
HEALTHCHECK NONE基础示例:
# Dockerfile 示例
# (1) 设置了每 5 秒检查一次(这里为了试验所以间隔非常短,实际应该相对较长),如果健康检查命令超过 3 秒没响应就视为失败
# 并且使用 curl -fs http://localhost/ || exit 1 作为健康检查命令。
FROM nginx
RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/*
HEALTHCHECK --interval=5s --timeout=3s \
CMD curl -fs http://localhost/ || exit 1
# (2) 使用 docker build 来构建这个镜像并启动;
docker build -t myweb:v1 .
$ docker run -d --name web -p 80:80 myweb:v1
# (3) 最初的状态为 (health: starting)在等待几秒钟后,再次 docker container ls 就会看到健康状态变化为了 (healthy);
# 如果健康检查连续失败超过了重试次数,状态就会变为 (unhealthy)。
$ docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
03e28eb00bd0 myweb:v1 "nginx -g ''daemon off" 18 seconds ago Up 16 seconds (healthy) 80/tcp, 443/tcp web
# (4) 健康检查命令的输出(包括 stdout 以及 stderr)都会被存储于健康状态里,可以用 docker inspect 来查看
$ docker inspect --format ''{
{json .State.Health}}'' web | python -m json.tool
{
"FailingStreak": 0,
"Log": [
{
"End": "2019-12-30T14:35:37.940957051Z",
"ExitCode": 0,
"Output": "<!DOCTYPE html>\n<html>\n<head>\n<title>Welcome to nginx!</title>....",
"Start": "2019-12-30T14:35:37.780192565Z"
}
],
"Status": "healthy"
}3.补充知识
Q:ADD与COPY之间的比较?
答:优先使用COPY命令,而ADD除了COPY功能还有解压功能(在多数情况下显得多余)
注意:ADD 指令会令镜像构建缓存失效从而可能会令镜像构建变得比较缓慢。
Q:RUN and CMD and ENTRYPOINT之间的差别?
- 区别在于 RUN 是在镜像构建过程中执行的,而 CMD/ENTRYPOINT 是在镜像生成实例的时候执行的
RUN:执行命令并创建新的Image Layer
CMD:设置容器启动后默认执行的命令和参数(如果定义多个CMD,只有最后一个执行)
ENTRYPOINT:设置容器启动时运行的命令,让容器以应用程序或服务形式运行
补充重点:前面我们说过CMD和ENTRYPOINT指令都可以定义容器运行时所执行的命令,下面是它们之间协调的一些规则:
- 在Dockerfile至少需要设置一条CMD或者ENTRYPOINT指令;
- 当将容器作为可执行文件使用时,建议定义ENTRYPOINT指令;
- CMD作为为ENTRYPOINT命令定义默认参数的一种方式;
- 当使用带有参数的命令运行容器时 CMD将会被覆盖。
下表是显示了不同的ENTRYPOINT / CMD指令组合的命令执行情况:
| No ENTRYPOINT | ENTRYPOINT exec_entry p1_entry | ENTRYPOINT [“exec_entry”, “p1_entry”] | |
|---|---|---|---|
| No CMD* | 报错,这种情况不运行出现 | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry |
| CMD [“exec_cmd”, “p1_cmd”] | exec_cmd p1_cmd | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry exec_cmd p1_cmd |
| CMD [“p1_cmd”, “p2_cmd”] | p1_cmd p2_cmd | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry p1_cmd p2_cmd |
| CMD exec_cmd p1_cmd | /bin/sh -c exec_cmd p1_cmd | /bin/sh -c exec_entry p1_entry | exec_entry p1_entry /bin/sh -c exec_cmd p1_cmd |
Q:命令指令的(shell 与 exec)不同格式异同?;
描述:通过shell格式去运行命令会读取$name变量,而exec格式是仅仅的执行一个命令而不是shell指令;
RUN/CMD/ENTRYPOINT yum install -y vim #Shell格式 如$PWD $LANG 宿主机
RUN/CMD/ENTRYPOINT ["apt-get","install","-y","vim"] #EXEC格式Q:ARG与ENV之间的区别?
答:ARG 所设置的构建环境的环境变量,在将来容器运行时是不会存在这些环境变量的,但是不要因此就使用 ARG 保存密码之类的信息,因为 docker history 还是可以看到所有值的。
而ENV会将变量通过镜像的entrypoint指令与容器中的应用传值;
Q:Docker前后台执行浅析问题?
描述:提到 CMD 就不得不提容器中应用在前台执行和后台执行的问题(初学者常出现的一个混淆)
Docker不是虚拟机在容器中的应用都应该以前台执行,而不是像虚拟机、物理机里面那样,用 systemd 去启动后台服务, 而容器内没有后台服务的概念。
对于容器而言,启动程序就是容器应用进程,容器就是为了主进程而存在的,主进程退出容器就失去了存在的意义从而退出,其它辅助进程不是它需要关心的东西。
#错误的形式
CMD service nginx start #发现容器执行后就立即退出了
#会被理解为
CMD [ "sh", "-c", "service nginx start"]
#因此主进程实际上是 sh。那么当 service nginx start 命令结束后,sh 也就结束了,sh 作为主进程退出了,自然就会令容器退出。
#正确的做法是直接执行 nginx 可执行文件,并且要求以前台形式运行。比如:
CMD ["nginx", "-g", "daemon off;"]那么什么是上下文路径呢?
首先我们要理解 docker build 的工作原理,由于Docker是C/S设计架构,Dockerclient通过这组 API 与 Docker 引擎交互,从而完成各种功能;
因此,虽然表面上我们好像是在本机执行各种 docker 功能,但实际上一切都是使用的远程调用形式在服务端(Docker 引擎)完成。
当我们进行镜像构建的时候,并非所有定制都会通过 RUN 指令完成,经常会需要将一些本地文件复制进镜像,比如通过 COPY 指令、ADD 指令等。
而 docker build 命令构建镜像,其实并非在本地构建,而是在服务端也就是 Docker 引擎中构建的;用户会指定构建镜像上下文的路径,docker build 命令得知这个路径后,会将路径下的所有内容打包,然后上传给 Docker 引擎。这样 Docker 引擎收到这个上下文包后,展开就会获得构建镜像所需的一切文件。
一般来说,应该会将 Dockerfile 置于一个空目录下,或者项目根目录下。如果该目录下没有所需文件,那么应该把所需文件复制一份过来。如果目录下有些东西确实不希望构建时传给 Docker 引擎,那么可以用 .gitignore 一样的语法写一个 .dockerignore,该文件是用于剔除不需要作为上下文传递给 Docker 引擎的。
COPY /opt/package.json /app/ #上下文路径错误或导致构造失败
COPY ./package.json /app/ #COPY 这类指令中的源文件的路径都是相对路
#这并不是要复制执行 docker build 命令所在的目录下的 package.json,也不是复制 Dockerfile 所在目录下的 package.json,而是复制 上下文(context) 目录下的 package.json。下列指令可以支持环境变量展开:
ADD、COPY、ENV、EXPOSE、LABEL、USER、WORKDIR、VOLUME、STOPSIGNAL、ONBUILD。
注意:对于Windows系统建议Dockerfile开头添加#escape=来指定转义信息
4.dockerfile实战
确保app.py和dockerfile在同一个目录
1.准备好app.py的flask程序
[root@localhost ~]# cat app.py
from flask import Flask
app=Flask(__name__)
@app.route(''/'')
def hello():
return "hello docker"
if __name__=="__main__":
app.run(host=''0.0.0.0'',port=8080)
[root@master home]# ls
app.py Dockerfile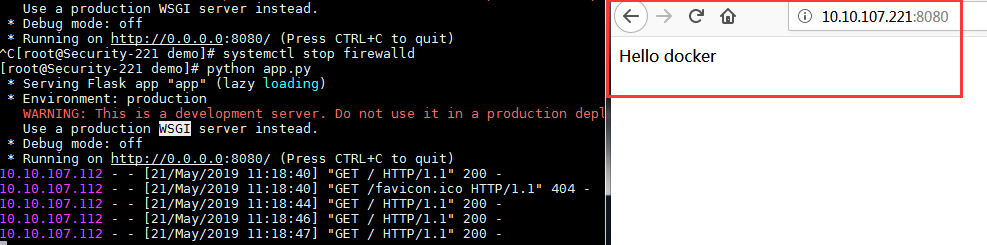
2.编写dockerfile
FROM python:2.7
LABEL version="1.0"
LABEL maintainer="weiyigeek"
RUN pip install flask
COPY app.py /app/
WORKDIR /app
EXPOSE 8080
CMD ["python","app.py"]使用.dockerignore文件(每一行添加一条匹配模式)来让Docker忽略匹配模式路径下的目录和文件;
#comment
*/temp*
*/*/temp*
tmp?
~*3.构建镜像image找到当前目录的dockerfile开始构建
docker build -t weiyigeek/flask-hello-docker .
docker image ls #.查看创建好的images4.启动此flask-hello-docker容器,映射一个端口供外部访问(检查运行的容器)
docker run -d -p 8080:8080 weiyigeek/flask-hello-docker
docker container ls5.提交修改并推送到我们的私有仓库中
docker tag weiyigeek/flask-hello-docker 192.168.11.37:5000/peng-flaskweb
docker push 192.168.11.37:5000/peng-flaskweb基础示例 Docker
- (1) Docker - Webp Server Go
FROM golang:alpine as builder
ARG IMG_PATH=/opt/pics
ARG EXHAUST_PATH=/opt/exhaust
RUN apk update ;\
apk add alpine-sdk ;\
git clone https://github.com/webp-sh/webp_server_go /build ;\
cd /build ;\
sed -i "s|.\/pics|${IMG_PATH}|g" config.json ;\
sed -i "s|\"\"|\"${EXHAUST_PATH}\"|g" config.json ;\
sed -i ''s/127.0.0.1/0.0.0.0/g'' config.json
WORKDIR /build
RUN go build -o webp-server .
FROM alpine
COPY --from=builder /build/webp-server /usr/bin/webp-server
COPY --from=builder /build/config.json /etc/config.json
WORKDIR /opt
VOLUME /opt/exhaust
CMD ["/usr/bin/webp-server", "--config", "/etc/config.json"]注意事项
- 1.在 RUN 指令的每行结尾我使用的是 ;\ 来接下一行 shell 而不是 && 其中缘由相信读者也猜到一二了吧(提高容错性),两则本质区别是
;运行失败时会继续运行而&&运行成功则继续执行; 笔者也逛了一圈 docker hub 官方镜像中用;较多一些,个人觉得是因为;比&&要美观一些
0x02 Docker 优化使用
1.Dockerfile 最佳实践
描述: 容器应该是短暂的,短暂意味着可以停止和销毁容器,并且创建一个新容器并部署好所需的设置和配置工作量应该是极小的;
下面列出了Dockerfile最佳实践的一些要素方法:
- 1.学习Docker的hub中官方仓库中镜像和对应的Dockerfile编写方法与习惯;
- 2.提高构建镜像的效率使用
.dockerignore文件来要忽略的文件和目录与指定上下文环境, .dockerignore 文件的排除模式语法和 Git 的 .gitignore 文件相似。(Dockerfile目录尽量为空,然后将构建镜像所需要的文件添加到该目录中); - 3.使用精简镜像(选择体积较小的基础镜像), 比如
alpine 或者 debian:buster-slim;
REPOSITORY TAG IMAGE ID CREATED SIZE
debian buster-slim e1af56d072b8 4 days ago 69.2MB
alpine latest cc0abc535e36 8 days ago 5.59MB
#注意:Alpine的C库是musl libc 而不是正统的 glic;- 4.网络环境受限的情况下,需将默认的软件源更换为国内的软件源镜像站,目前国内稳定可靠的镜像站主要有,
华为云、阿里云、腾讯云、163等,其中华为云的镜像站速度最快,平均 10MB/s,峰值可达到 20MB/s,极大的能加快构建镜像的速度。
# 备注:其他基础镜像可以通过 sed 命令替换软件源配置文件中的默认域名;
# 对于 alpine 基础镜像修改软件源
echo "http://mirrors.huaweicloud.com/alpine/latest-stable/main/" > /etc/apk/repositories ;\
echo "http://mirrors.huaweicloud.com/alpine/latest-stable/community/" >> /etc/apk/repositories ;\
apk update ;\
# debian 基础镜像修改默认软件源
sed -i ''s/deb.debian.org/mirrors.huaweicloud.com/g'' /etc/apt/sources.list ;\
sed -i ''s|security.debian.org/debian-security|mirrors.huaweicloud.com/debian-security|g'' /etc/apt/sources.list ;\-
4.减少镜像层数则要尽量合并指令(调整合理的指令顺序),例如多个RUN指令可以利用
反斜杠符号 \合并为一条; -
5.避免安装不必要的包(
指定软件版本号)来减少所构建镜像的大小(实际需要将各层安装的东西尽量最小),降低复杂性、减少依赖、节约构建时间 (别使用yum upgrade / apt-get upgrade / dist-upgrade 来更新依赖应用);
RUN apt update && apt-get --no-install-recommends install -y \
package-bar \
package-foo=1.3.* && \- 6.分阶段构建在 Docker 17.05 以上版本中可以采用此种方式来减少所构建镜像的大小。
#(1)比如我们现在有一个最简单的 golang 服务,需要构建一个最小的`Docker` 镜像,源码如下:
package main
import (
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
router := gin.Default()
router.GET("/ping", func(c *gin.Context) {
c.String(http.StatusOK, "PONG")
})
router.Run(":8080")
}
#(2)使用多阶段构建,你可以在一个 `Dockerfile` 中使用多个 FROM 语句;
#每个 FROM 指令都可以使用不同的基础镜像,并表示开始一个新的构建阶段。
#你可以很方便的将一个阶段的文件复制到另外一个阶段,在最终的镜像中保留下你需要的内容即可。
FROM golang AS build-env
ADD . /go/src/app
WORKDIR /go/src/app
RUN go get -u -v github.com/kardianos/govendor
RUN govendor sync
RUN GOOS=linux GOARCH=386 go build -v -o /go/src/app/app-server
FROM alpine
RUN apk add -U tzdata
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
COPY --from=build-env /go/src/app/app-server /usr/local/bin/app-server
EXPOSE 8080
CMD [ "app-server" ]
#(3)现在我们就把两个镜像的文件最终合并到一个镜像里面了。- 6.增加可读性将多行参数排序, 建议在反斜杠符号 \ 之前添加一个空格 ,并且只要有可能,就将
多行参数按字母顺序排序(比如要安装多个包时),帮助你避免重复包含同一个包,更新包列表时也更容易,也更容易阅读和审查;
LABEL Version="1.1" \
Author="WeiyiGeek" \
InnerVersion="0.1"
#来自buildpack-deps 镜像的例子
RUN apt-get update && apt-get install -y \
bzr \
cvs \
git \
mercurial \
subversion- 7.时区设置由于绝大多数 docker 镜像都是默认采用的 UTC 的时区,与北京时间相差 8 个小时,这将会导致容器内的时钟与北京时间不一致,因而会对一些应用造成一些影响,以及影响容器内日志和监控的数据;
#方式1.可以通过环境变量设置容器内的时区,在启动的时候可以通过设置环境变量-e TZ=Asia/Shanghai 来设定容器内的时区
#方式2.但对于 alpine 镜像无法通过环境变量的方式设定时区,需要安装 tzdata 来配置时区。
apk add --no-cache tzdata ;\
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime ;\
echo "Asia/Shanghai" > /etc/timezone ;\
apk del tzdata ;
#方式3.对于 debian 基础镜像,可通过复制时区文件设定容器内时区
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime ;\
echo "Asia/shanghai" > /etc/timezone ;\- 8.尽量使用 URL 添加源码,对于需要在容器内进行编译的项目,最好通过git 或者 wegt 的方式将源码打入到镜像内,而非采用 ADD 或者 COPY ,因为源码编译完成之后源码就不需要可以删掉了,
而通过 ADD 或者 COPY 添加进去的源码已经用在下一层镜像中了无法被删除掉。这种方法缺点就是网络可能受限下载缓慢
RUN set -x \
&& echo "http://mirrors.aliyun.com/alpine/latest-stable/main/" > /etc/apk/repositories \
&& echo "http://mirrors.aliyun.com/alpine/latest-stable/community/" >> /etc/apk/repositories \
&& apk update \
&& apk add --no-cache --virtual .build-deps gcc libc-dev make perl-dev openssl-dev pcre-dev zlib-dev git \
&& mkdir -p /usr/local/src \
&& cd /usr/local/src \
&& git clone https://github.com/happyfish100/libfastcommon.git --depth 1 \
&& git clone https://github.com/happyfish100/fastdfs.git --depth 1 \
&& git clone https://github.com/happyfish100/fastdfs-nginx-module.git --depth 1 \
&& wget http://nginx.org/download/nginx-1.15.4.tar.gz \
&& tar -xf nginx-1.15.4.tar.gz \
&& cd /usr/local/src/libfastcommon \
&& ./make.sh \
&& ./make.sh install \
&& cd /usr/local/src/fastdfs/ \
&& ./make.sh \
&& ./make.sh install \
&& cd /usr/local/src/nginx-1.15.4/ \
&& ./configure --add-module=/usr/local/src/fastdfs-nginx-module/src/ \
&& make && make install \
&& apk del .build-deps \
&& apk add --no-cache pcre-dev bash \
&& mkdir -p /home/dfs \
&& mv /usr/local/src/fastdfs/docker/dockerfile_network/fastdfs.sh /home \
&& mv /usr/local/src/fastdfs/docker/dockerfile_network/conf/* /etc/fdfs \
&& chmod +x /home/fastdfs.sh \
&& rm -rf /usr/local/src*
# 构建之后的对比确实比较明显
# 使用项目默认的 Dockerfile 进行构建的话,镜像大小接近 500MB ,而经过一些的优化,将所有的 RUN 指令合并为一条,最终构建出来的镜像大小为 30MB 。
REPOSITORY TAG IMAGE ID CREATED SIZE
fastdfs alpine e855bd197dbe 10 seconds ago 29.3MB
fastdfs debian e05ca1616604 20 minutes ago 103MB
fastdfs centos c1488537c23c 30 minutes ago 483MB- 10.使用虚拟编译环境,对于只在编译过程中使用到的依赖,我们可以将这些依赖安装在虚拟环境中,编译完成之后可以一并删除这些依赖
#(1) 比如 alpine 中可以使用 `apk add --no-cache --virtual .build-deps` 后面加上需要安装的相关依赖即可;
apk add --no-cache --virtual .build-deps gcc libc-dev make perl-dev openssl-dev pcre-dev zlib-dev git
#(2) 构建完成之后可以使用 `apk del .build-deps` 命令,一并将这些编译依赖全部删除。需要注意的是 `.build-deps` 后面接的是编译时以来的软件包,不要把运行时的依赖包接在后面,最好单独 add 一下- 容器应该是短暂的通过 Dockerfile 构建的镜像所启动的容器应该尽可能短暂(生命周期短),意味着可以停止和销毁容器,并且创建一个新容器并部署好所需的设置和配置工作量应该是极小的。们可以查看下[12 Factor(12要素)应用程序方法]的进程部分,可以让我们理解这种无状态方式运行容器的动机。
- 建立上下文,在执行docker build命令时所在工作目录被称为构建上下文,默认情况下,Dockerfile 就位于该路径下,当然您也可以使用-f参数来指定不同的位置,此时无论 Dockerfile 在什么地方,当前目录中的所有文件内容都将作为构建上下文发送到 Docker 守护进程中去。
#示例1.为构建上下文创建一个目录并 cd 放入其中。
#(1)将“hello”写入一个文本文件hello,然后并创建一个`Dockerfile`并运行`cat`。从构建上下文(.)中构建图像:
mkdir myproject && cd myproject
echo "hello" > hello
echo -e "FROM busybox\nCOPY /hello /\nRUN cat /hello" > Dockerfile
docker build -t helloapp:v1 .
#(2)现在移动 Dockerfile 和 hello 到不同的目录,并建立了图像的第二个版本(不依赖于缓存中的最后一个版本)。
#使用`-f`指向 Dockerfile 并指定构建上下文的目录:
mkdir -p dockerfiles context
mv Dockerfile dockerfiles && mv hello context
docker build --no-cache -t helloapp:v2 -f dockerfiles/Dockerfile context
#(3)在构建的时候包含不需要的文件会导致更大的构建上下文和更大的镜像大小。这会增加构建时间,拉取和推送镜像的时间以及容器的运行时间大小。要查看您的构建环境有多大,请在构建您的系统时查找这样的消息;
Dockerfile:
Sending build context to Docker daemon 187.8MB- 11.精简生成镜像的大小及时删除临时文件和缓存文件,特别是在执行apt-get指令后
/var/cache/apt和/var/lib/apt/lists下面会缓存一些安装包;- 删除中间文件:比如下载的压缩包
- 删除临时文件:如果命令产生了临时文件,也要及时删除
#安装完软件包清楚 `/var/lib/apt/list/` 缓存
rm -rf /var/lib/apt/lists/*
rm -rf /var/cache/apt- 12.构建缓存查找是否已经存在可重用的镜像,如果有就使用现存的镜像不再重复创建 , 在开启缓存的情况下,内容不变的指令尽量放在前面;当然如果你不想在构建过程中使用缓存,你可以在 docker build 命令中使用
--no-cache=true选项;Docker中缓存遵循的基本规则如下:
- 从基础镜像开始(即FROM指令指定),下一条指令将和该基础镜像的所有子镜像进行匹配,检查这些子镜像被创建时使用的指令是否和被检查的指令完全一样。IF 不是 则缓存失效;
- 多数情况下简单地对比 Dockerfile 中的指令和子镜像,然而有些指令需要更多的检查和解释;
- 对于 ADD 和 COPY 指令镜像中对应文件的内容也会被检查,每个文件都会计算出一个校验值;在缓存的查找过程中会将这些校验和和已存在镜像中的文件校验值进行对比,如果文件有任何改变,比如内容和元数据则缓存失效。
- 缓存匹配过程不会查看临时容器中的文件来决定缓存是否匹配,例如当执行完 `RUN apt-get -y update` 指令后,容器中一些文件被更新,但 Docker 不会检查这些文件。这种情况下只有指令字符串本身被用来匹配缓存。
- 一旦缓存失效所有后续的 Dockerfile 指令都将产生新的镜像,缓存不会被使用- 13.不要在 Dockerfile 中单独修改文件的权限, 因为 docker 镜像是分层的,任何修改都会新增一个层,修改文件或者目录权限也是如此, 如果有一个命令单独修改大文件或者目录的权限,会把这些文件复制一份这样很容易导致镜像很大。
#解决方案
- 在添加到 Dockerfile 之前就把文件的权限和用户设置好;
- 在容器启动脚本(entrypoint)做这些修改,或者拷贝文件和修改权限放在一起做(最终也只是增加一层)- 14.保证容器的横向扩展和复用, 一个容器只运行一个进程将多个应用解耦到不同容器中(
类似于微服务-K8s表现得淋漓精致)
docker build -t test:v1.1 .
Sending build context to Docker daemon 2.56kB
Step 1/6 : FROM alpine
latest: Pulling from library/alpine
df20fa9351a1: Pull complete
Digest: sha256:185518070891758909c9f839cf4ca393ee977ac378609f700f60a771a2dfe321
Status: Downloaded newer image for alpine:latest
---> a24bb4013296
Step 2/6 : LABEL Author="WeiyiGeek" Description="Test Dockerfile"
---> Running in 88827d239060
Removing intermediate container 88827d239060
---> 11d6ad764d64
Step 3/6 : MAINTAINER WeiyiGeek master@WeiyiGeek.top
---> Running in 5c939c83df34
Removing intermediate container 5c939c83df34
---> 3fcdbc7bd1d8
Step 4/6 : RUN echo "http://mirrors.huaweicloud.com/alpine/latest-stable/main/" > /etc/apk/repositories ; echo "http://mirrors.huaweicloud.com/alpine/latest-stable/community/" >> /etc/apk/repositories ; apk update ; apk add --no-cache tzdata ; cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime ; echo "Asia/Shanghai" > /etc/timezone ; apk del tzdata ;
---> Running in 2879a08f5f04
fetch http://mirrors.huaweicloud.com/alpine/latest-stable/main/x86_64/APKINDEX.tar.gz
fetch http://mirrors.huaweicloud.com/alpine/latest-stable/community/x86_64/APKINDEX.tar.gz
v3.12.0-74-gb8f92cf12a [http://mirrors.huaweicloud.com/alpine/latest-stable/main/]
v3.12.0-77-ge186c138b6 [http://mirrors.huaweicloud.com/alpine/latest-stable/community/]
OK: 12734 distinct packages available
fetch http://mirrors.huaweicloud.com/alpine/latest-stable/main/x86_64/APKINDEX.tar.gz
fetch http://mirrors.huaweicloud.com/alpine/latest-stable/community/x86_64/APKINDEX.tar.gz
(1/1) Installing tzdata (2020a-r0)
Executing busybox-1.31.1-r16.trigger
OK: 9 MiB in 15 packages
(1/1) Purging tzdata (2020a-r0)
Executing busybox-1.31.1-r16.trigger
OK: 6 MiB in 14 packages
Removing intermediate container 2879a08f5f04
---> afed82abd763
Step 5/6 : ENTRYPOINT ["top","-b"]
---> Running in ce8bc0f98fca
Removing intermediate container ce8bc0f98fca
---> c5fe50376063
Step 6/6 : CMD ["d2"]
---> Running in d6bbe5535a87
Removing intermediate container d6bbe5535a87
---> fe57118d688c
Successfully built fe57118d688c
Successfully tagged test:v1.12.Dockerfile 指令最佳实践
- FROM:尽可能使用当前官方仓库作为你构建镜像的基础
- LABEL: 一个镜像可以包含多个标签但建议将多个标签放入到一个 LABEL 指令中
- RUN:将长的或复杂的 RUN 指令用反斜杠 \ 分割成多行 (不要使用 RUN apt-get upgrade 或 dist-upgrade,因为许多基础镜像中的「必须」包不会在一个非特权容器中升级,而且建议使用指定版本的形式)
- CMD:用于执行目标镜像中包含的软件可以包含参数
- EXPOSE:在执行 docker run 时使用一个标志来指示如何将指定的端口映射到所选择的端口
- ENV: 为了方便新程序运行,你可以使用 ENV 来为容器中安装的程序更新 PATH 环境变量
- ADD 和 COPY(优先使用它),了让镜像尽量小最好不要使用 ADD 指令从远程 URL 获取包,而是使用 curl 和 wget
- ENTRYPOINT: 最佳用处是设置镜像的主命令,允许将镜像当成命令本身来运行(用 CMD 提供默认选项)。
- VOLUME: 强烈建议使用它来管理镜像中的可变部分和用户可以改变的部分。
- USER:如果某个服务不需要特权执行,建议使用 USER 指令切换到非 root 用户(你应该避免使用 sudo),同时也避免频繁地使用USER来回切换用户。
- 使用类似 RUN groupadd -r postgres && useradd -r -g postgres postgres 的指令创建用户和用户组。
- WORKDIR:为了清晰性和可靠性建议都使用结对路径;
3.Dockerfile 操作系统
Docker拥有自己的操作系统,完全基于于 Docker 的Linux发行版CoreOS。
目前常用的Linux发行版主要包括Debian/Ubuntu系列和CentOS/Fedora系列。
- 前者以自带软件包版本较新而出名
- 后者则宣称运行更稳定一些
WeiyiGeek Blog - 为了能到远方,脚下的每一步都不能少。
本文章来源 Blog 站点(友链交换请邮我哟):
- https://weiyigeek.top # 国内访问较慢
- https://blog.weiyigeek.top # 更新频繁
- https://weiyigeek.gitee.io # 国内访问快可能会有更新不及时得情况
更多学习笔记文章请关注 WeiyiGeek 公众账号
【点击我关注】


CAdvisor + InfluxDB + Grafana是怎么搭建Docker容器监控系统
CAdvisor + InfluxDB + Grafana是怎么搭建Docker容器监控系统,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
利用docker compose组合应用并利用scale可以快速对容器进行扩充,而docker compose启动的服务容器都在同一台宿主机上,对于一个宿主机上运行多个容器应用时,容器的运行情况,如:cpu使用率,内存使用率,网络状态,磁盘空间等一系列随时间变化的时序数据信息,都需要进行了解,因此监控是必须的。
容器监控方案选择
对于容器的监控方案可谓多种多样,除了docker本身自带的 docker stats 命令,还有Scout,Data Dog,Sysdig Cloud,Sensu Monitoring Framework,CAdvisor等都可以对容器进行监控。
通过 docker stats 命令可以很方便的看到当前宿主机上所有容器的cpu,内存,以及网络流量等数据。但 docker stats 命令的缺点是只是统计当前宿主机的所有容器,获取的数据是实时的,没有地方存储,也没有报警功能。

而Scout,Data Dog,Sysdig Cloud虽然都提供了较完善的服务,但是它们都是托管的服务且都是收费的,Sensu Monitoring Framework集成度较高,也免费,但是部署过于复杂,综合考虑选择CAdvisor做监控工具。
CAdvisor出自Google,优点是开源产品,监控指标齐全,部署方便,而且有官方的docker镜像。缺点是集成度不高,默认只在本地保存2分钟数据。不过,可以加上InfluxDB存储数据,对接Grafana展示图表,比较便利搭建容器监控系统,数据收集和图表展示效果良好,对系统性能也几乎没什么影响。
CAdvisor + InfluxDB + Grafana搭建容器监控系统
CAdvisor
CAdvisor是一个容器资源监控工具,包括容器的内存,cpu,网络IO,磁盘IO等,同时提供了一个WEB页面用于查看容器的实时运行状态。CAdvisor默认存储2分钟的数据,而且只是针对单物理机,不过,CAdvisor提供了很多数据集成接口,支持InfluxDB,Redis,Kafka,Elasticsearch等集成,可以加上对应配置将监控数据发往这些数据库存储起来。
CAdvisor功能主要有两点,展示Host,容器两个层次的监控数据和展示历史变化
InfluxDB
InfluxDB是用Go语言编写的一个开源分布式时序,事件和指标数据库,无需外部依赖。
由于CAdvisor默认只在本地保存最近2分钟的数据,为了持久化数据和统一收集展示监控数据,需要将数据存储到InfluxDB中。InfluxDB是一个时序数据库,专门用于存储时序相关数据,很适合存储CAdvisor数据,而且CAdvisor本身提供了InfluxDB集成的方法,在启动容器时指定配置即可。
InfluxDB主要功能:
基于时间序列,支持与时间有关的相关函数
可度量性,可以实时对大量数据进行计算
基于事件,支持任意的事件数据
InfluxDB主要特点:
无结构
可以是任意数量的列
可拓展
支持min,max等一系列的函数,方便统计
原生的HTTP支持,内置HTTP API
强大的类sql语法
Granfana
Grafana是一个开源的数据监控分析可视化平台,支持多种数据源配置(如InfluxDB,MySQL,Elasticserach,OpenTSDB,Graphite等)和丰富的插件及模板功能,支持图表权限控制和报警。
Grafana主要特点
灵活丰富的图形化选项
可以混合多种风格
支持白天和夜间模式
多数据源
CAdvisor负责收集容器随时间变化的数据
InfluxDB负责存储时序数据
Grafana负责分析和展示时序数据
安装部署
部署InfluxDB服务
启动InfluxDB的服务容器:
docker run -d --name influxdb -p 8086:8086 \
-v /data/influxdb:/var/lib/influxdb \
--hostname influexdb \
influxdb在容器中创建test数据库和root用户
docker exec -it influxdb influx
> CREATE DATABASE "test"
> CREATE USER "root" WITH PASSWORD 'root' WITH ALL PRIVILEGES
部署CAdvisor
启动CAdvisor的服务容器:
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:ro \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=8080:8080 \
--detach=true \
--name=cadvisor \
google/cadvisor:latest \
-storage_driver=influxdb \
-storage_driver_host=influxdb:8086 \
-storage_driver_db=test \
-storage_driver_user=root \
-storage_driver_password=root服务容器起来后可通过浏览器访问 http:///ip:8080

部署Grafana
启动Grafana服务容器:
docker run -d -p 3000:3000 \
-v /data/grafana:/var/lib/grafana \
--link=influxdb:influxdb \
--name grafana grafana/grafana直接运行该命令后有可能会发现容器并没有启起来,通过 docker logs 命令会发现”mkdir: can’t create directory ‘/var/lib/grafana/plugins’: Permission denied“的错误,其实就是没有 数据卷对应的主机上 /data/grafana 的权限,可以在运行启动命令前先创建 /data/grafana 目录并给定权限777,或者通过”docker run —entrypoint “id” grafana/grafana“ 查看uid,gid,groups (默认为472),然后通过”chown -R 472:472 /data/grafana“修改权限。

Grafana正常启动后就可以 http://ip:3000 访问,出现以下的登录页面,初次访问需要修改密码,默认用户名密码为:admin/admin
Docker Compose集成部署
准备docker-compose.yml文件
version: '3.1'
volumes:
grafana_data: {}
services:
influxdb:
image: influxdb
restart: always
environment:
- PRE_CREATE_DB=cadvisor
ports:
- "8086:8086"
expose:
- "8090"
- "8099"
volumes:
- ./data/influxdb:/data
cadvisor:
image: google/cadvisor
links:
- influxdb:influxdb-host
command: -storage_driver=influxdb -storage_driver_db=cadvisor -storage_driver_host=influxdb-host:8086
restart: always
ports:
- "8080:8080"
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker:/var/lib/docker:ro
grafana:
user: "104"
image: grafana/grafana
restart: always
links:
- influxdb:influxdb-host
ports:
- "3000:3000"
volumes:
- grafana_data:/var/lib/data
environment:
- HTTP_USER=admin
- HTTP_PASS=admin
- INFLUXDB_HOST=influxdb-host
- INFLUXDB_PORT=8086
- INFLUXDB_NAME=cadvisor
- INFLUXDB_USER=root
- INFLUXDB_PASS=root在docker-compose.yml文件目录运行以下命令启动服务:
docker-compose up -d
-d指定在后台启动,初次启动可以不加可以在控制台查看启动日志,当然后台启动也可以通过“docker-compose logs”进行查看启动日志。
服务正常启动后就可以 http://ip:3000 访问Granafa,在Home Dashboard页面点击添加data source

配置InfluxDB连接信息,当然在配置连接信息前需要进入InfluxDB容器创建相应的cadvisor数据库和用户root/root
在容器中创建cadvisor数据库和root用户
docker exec -it influxdb-contianer-id influx
> CREATE DATABASE "cadvisor"
> CREATE USER "root" WITH PASSWORD 'root' WITH ALL PRIVILEGES配置连接InfluxDB连接:


数据源配好之后可以回到Home Dashboard添加添加dashboard图表展示监控信息,Grafana提供了丰富的图片模板对监控数据进行展示。
添加dashboard:


可选模板:

编辑图表:

配置监控cadvisor容器的内存使用情况的图表展示,配置好之后点击保存就可以了。

看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注小编行业资讯频道,感谢您对小编的支持。

cAdvisor+InfluxDB+Grafana 监控Docker
容器的监控方案其实有很多,有docker自身的docker stats命令、有Scout、有Data Dog等等,本文主要和大家分享一下比较经典的容器开源监控方案组合:cAdvisor+InfluxDB+Grafan
一、概念
1). InfluxDB是什么
nfluxDB是用GO语言编写的一个开源分布式时序、事件和指标数据库,无需外部的依赖,类似的数据库有Elasticsearch、Graphite等等
InfluxDB主要的功能:
基于时间序列:支持与时间有关的相关函数(如最大、最小、求和等)
可度量性:可以实时对大量数据进行计算
基于事件:它支持任意的事件数据
InfluxDB的主要特点:
无结构(无模式):可以是任意数量的列
可拓展的
支持min, max, sum, count, mean, median 等一系列函数,方便统计
原生的HTTP支持,内置HTTP API
强大的类SQL语法
自带管理界面,方便使用
2). cAdvisor是什么
它是Google用来监测单节点的资源信息的监控工具。Cadvisor提供了一目了然的单节点多容器的资源监控功能。Google的Kubernetes中也缺省地将其作为单节点的资源监控工具,各个节点缺省会被安装上Cadvisor
cAvisor是利用docker status的数据信息,了解运行时容器资源使用和性能特征的一种工具
cAdvisor的容器抽象基于Google的lmctfy容器栈,因此原生支持Docker容器并能够“开箱即用”地支持其他的容器类型。
cAdvisor部署为一个运行中的daemon,它会收集、聚集、处理并导出运行中容器的信息。
这些信息能够包含容器级别的资源隔离参数、资源的历史使用状况、反映资源使用和网络统计数据完整历史状况的柱状图。
cAdvisor功能:
展示Host和容器两个层次的监控数据
展示历史变化数据
温馨提示:
由于 cAdvisor 提供的操作界面略显简陋,而且需要在不同页面之间跳转,并且只能监控一个 host,这不免会让人质疑它的实用性。
但 cAdvisor 的一个亮点是它可以将监控到的数据导出给第三方工具,由这些工具进一步加工处理。
我们可以把 cAdvisor 定位为一个监控数据收集器,收集和导出数据是它的强项,而非展示数据
3). Grafana是什么
Grafana是一个可视化面板(Dashboard),有着非常漂亮的图表和布局展示,功能齐全的度量仪表盘和图形编辑器,支持Graphite、zabbix、InfluxDB、Prometheus和OpenTSDB作为数据源
Grafana主要特性:
灵活丰富的图形化选项;
可以混合多种风格;
支持白天和夜间模式;
支持多个数据源;
温馨提示:
在这套监控方案中:InfluxDB用于数据存储,cAdvisor用户数据采集,Grafana用于数据展示二、单节点部署
温馨提示:
服务器信息:
主机IP:192.168.15.129
主机名:master1
docker版本:18.06.1-ce
1. 下载镜像(可做可不做,在创建容器的时候会如果本地没有会自动下载)
# 下载镜像
[root@master1 ~]# docker pull tutum/influxdb
[root@master1 ~]# docker pull google/cadvisor
[root@master1 ~]# docker pull grafana/grafana
# 查看镜像
[root@master1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
grafana/grafana latest 7038dbc9a50c 7 days ago 223MB
google/cadvisor latest 75f88e3ec333 10 months ago 62.2MB
tutum/influxdb latest c061e5808198 2 years ago 290MB2. 创建InfluxDB容器
# 创建InfluxDB容器
[root@master1 ~]# docker run -itd -p 8083:8083 -p 8086:8086 --name influxdb tutum/influxdb
参数详解:
-itd:已交互模式运行容器,并分配伪终端,并在后台启动容器
-p:端口映射 8083端口为influxdb后台控制端口,8086端口是influxdb的数据端口
--name:给容器起个名字
tutum/influxdb:以这个镜像运行容器(本地有使用本地,没有先去下载然后启动容器)
# 查看容器
[root@master1 ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f01c5e754bc0 tutum/influxdb "/run.sh" 3 seconds ago Up 2 seconds 0.0.0.0:8083->8083/tcp, 0.0.0.0:8086->8086/tcp influxdb配置InfluxDB
登录InfluxDB的8083端口,也是管理平台设置管理员用户名密码,并添加数据库
登录URL:http://192.168.15.129:8083
设置管理员用户名密码,并添加数据库
3. 创建cadvisor容器
# 创建cadvisor容器
[root@master1 ~]# docker run -itd --name cadvisor -p 8080:8080 --mount type=bind,src=/,dst=/rootfs,ro --mount type=bind,src=/var/run,dst=/var/run --mount type=bind,src=/sys,dst=/sys,ro --mount type=bind,src=/var/lib/docker/,dst=/var/lib/docker,ro google/cadvisor -storage_driver=influxdb -storage_driver_db=cadvisor -storage_driver_user=root -storage_driver_password=root -storage_driver_host=192.168.15.129:8086
参数详解:
-itd:已交互模式运行容器,并分配伪终端,并在后台启动容器
-p: 端口映射 8080为cadvisor的管理平台端口
--name:给容器起个名字
--mout:把宿主机的相文目录绑定到容器中,这些目录都是cadvisor需要采集的目录文件和监控内容
google/cadvisor:以这个镜像运行容器(本地有使用本地,没有先去下载然后启动容器)
-storage_driver:需要指定cadvisor的存储驱动这里是influxdb
-storage_driver_db:需要指定存储的数据库
-storage_driver_user:influxdb数据库的用户名(测试可以加可以不加)
-storage_driver_password:influxdb数据库的密码(测试可以加可以不加)
-storage_driver_host:influxdb数据库的地址和端口
# 查看容器
[root@master1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7c2005bb79d1 google/cadvisor "/usr/bin/cadvisor -…" 3 seconds ago Up 2 seconds 0.0.0.0:8080->8080/tcp cadvisor
2fa150d3c52b tutum/influxdb "/run.sh" 10 minutes ago Up 10 minutes 0.0.0.0:8083->8083/tcp, 0.0.0.0:8086->8086/tcp influxdb查看cadvisor管理平台
登录URL:http://192.168.15.129:8080
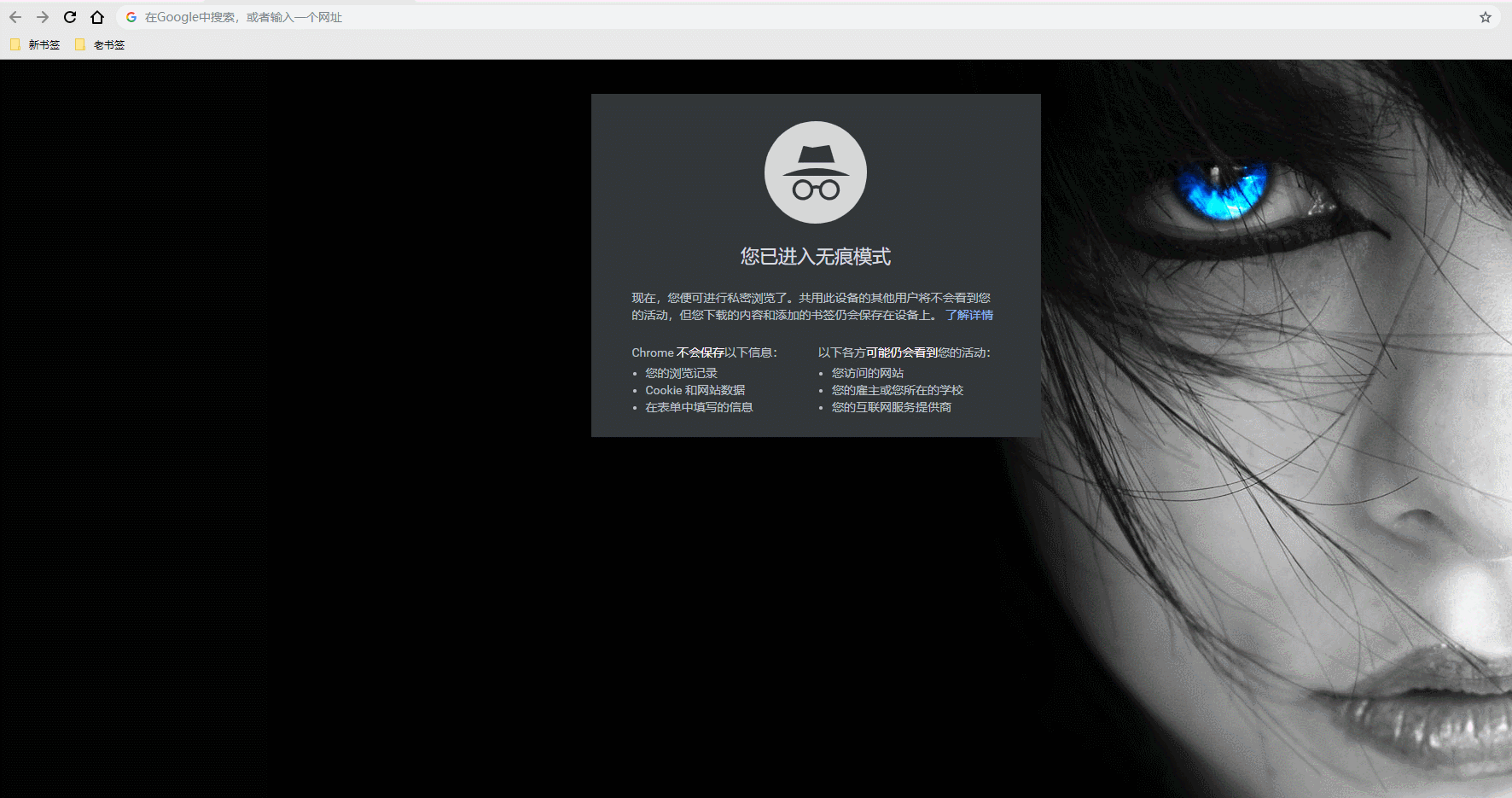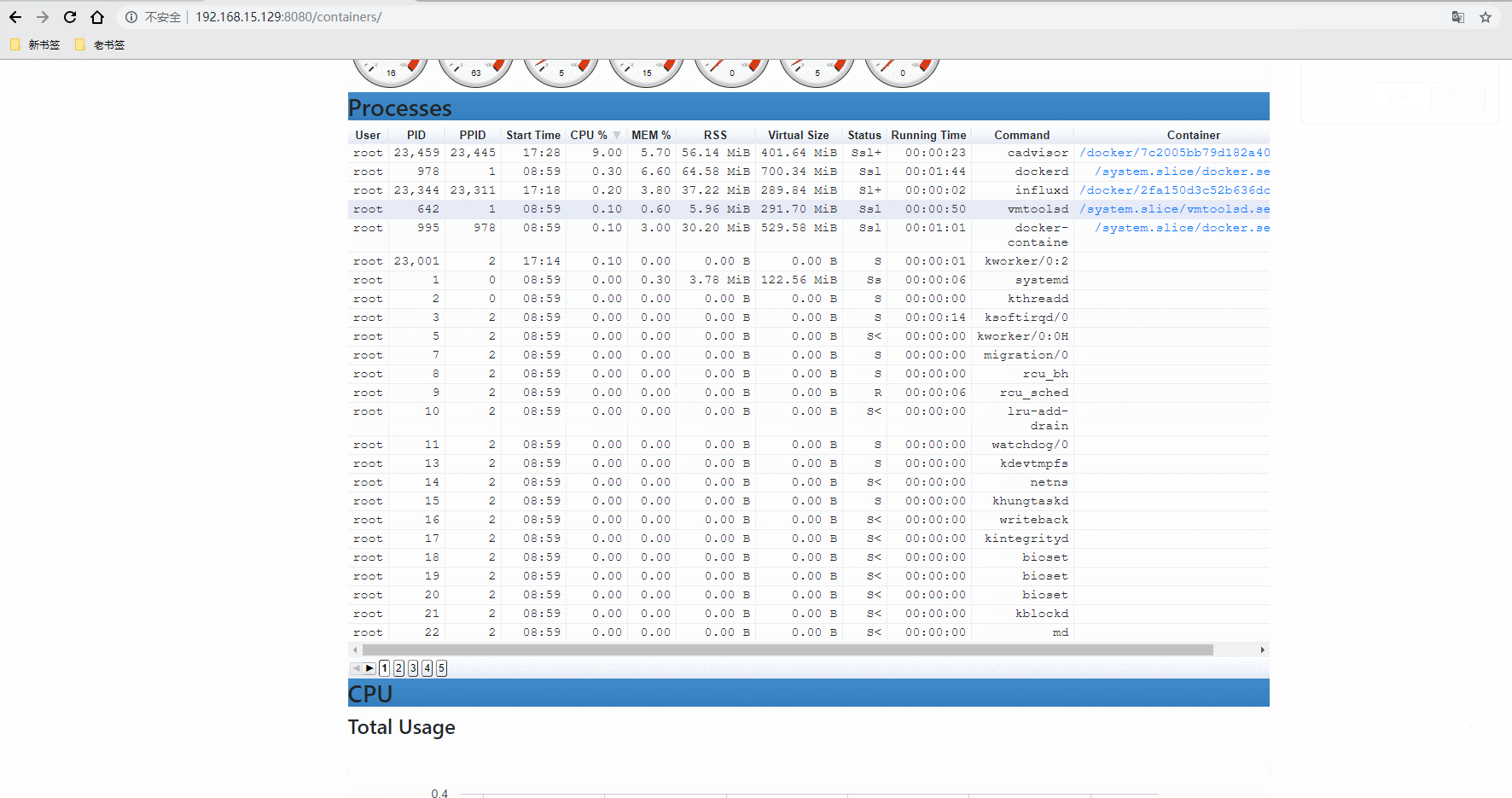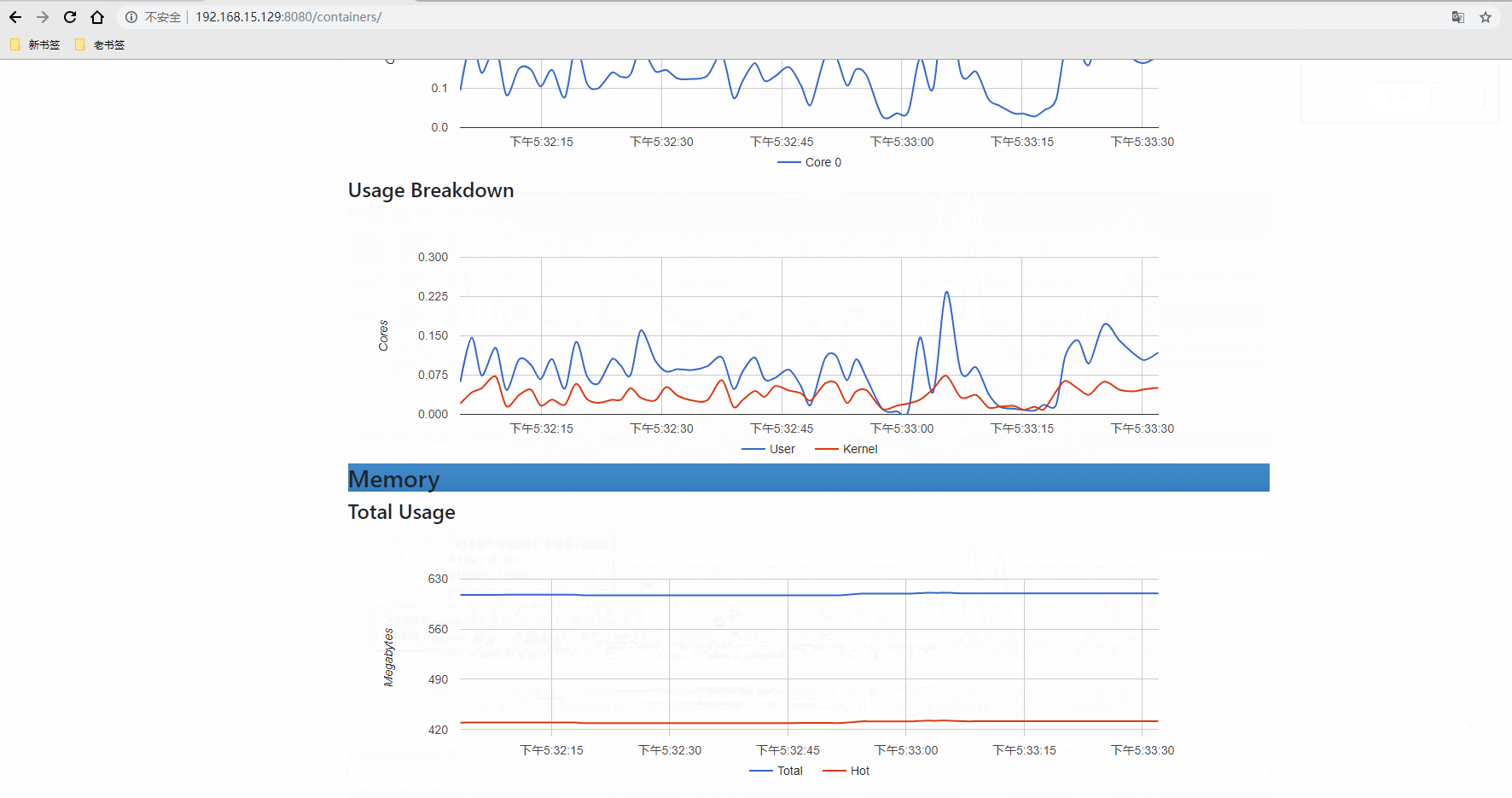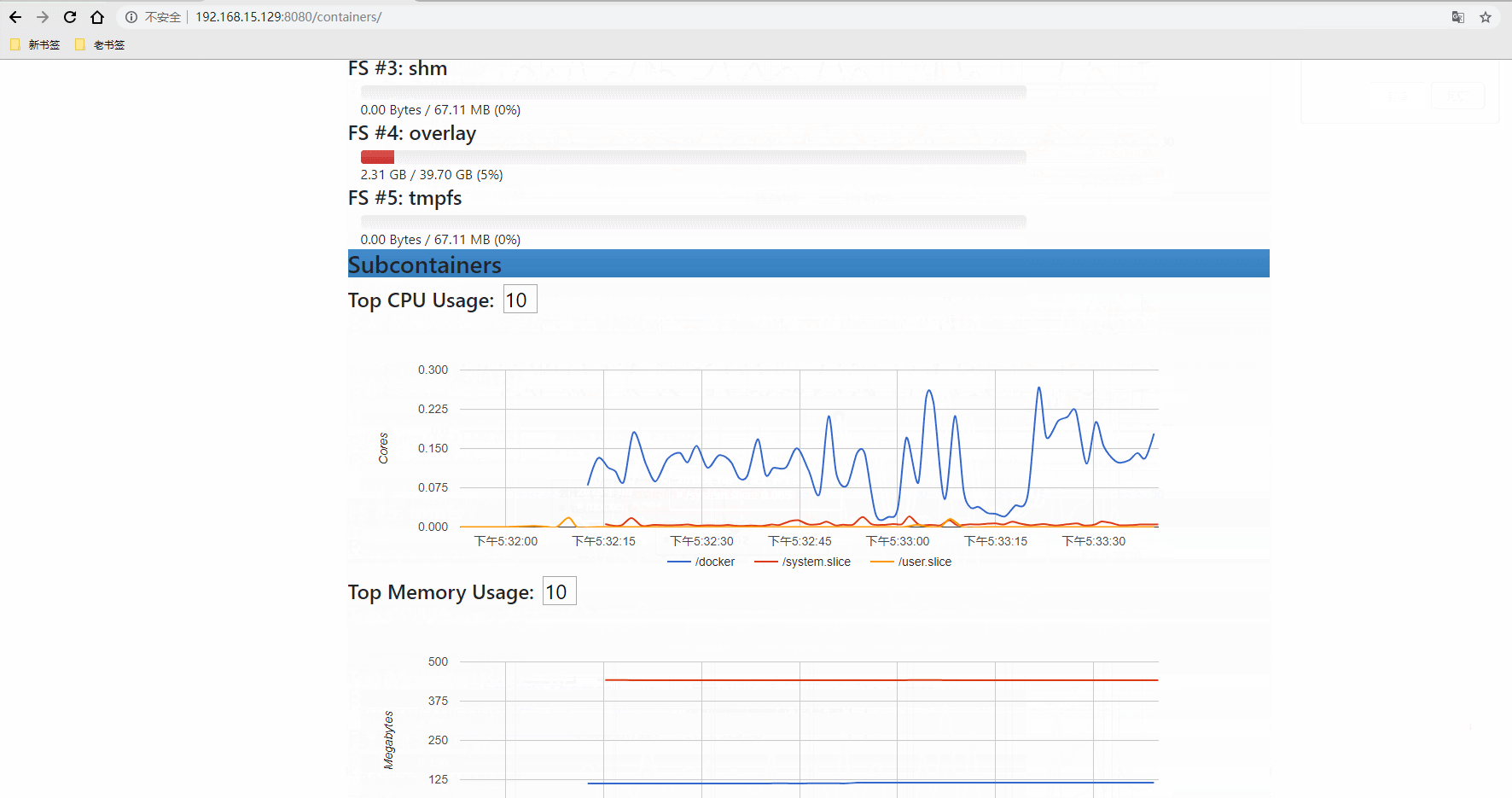
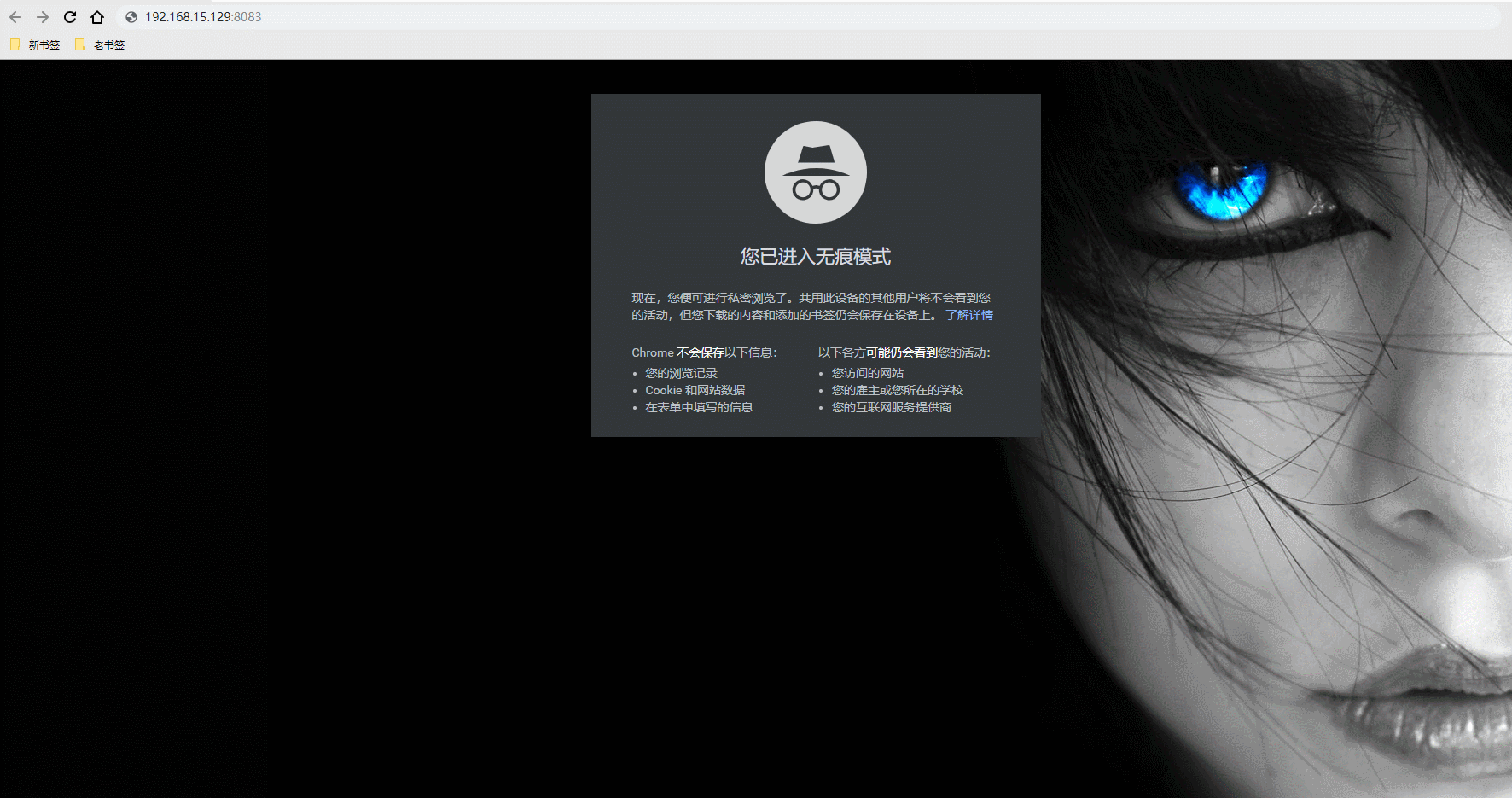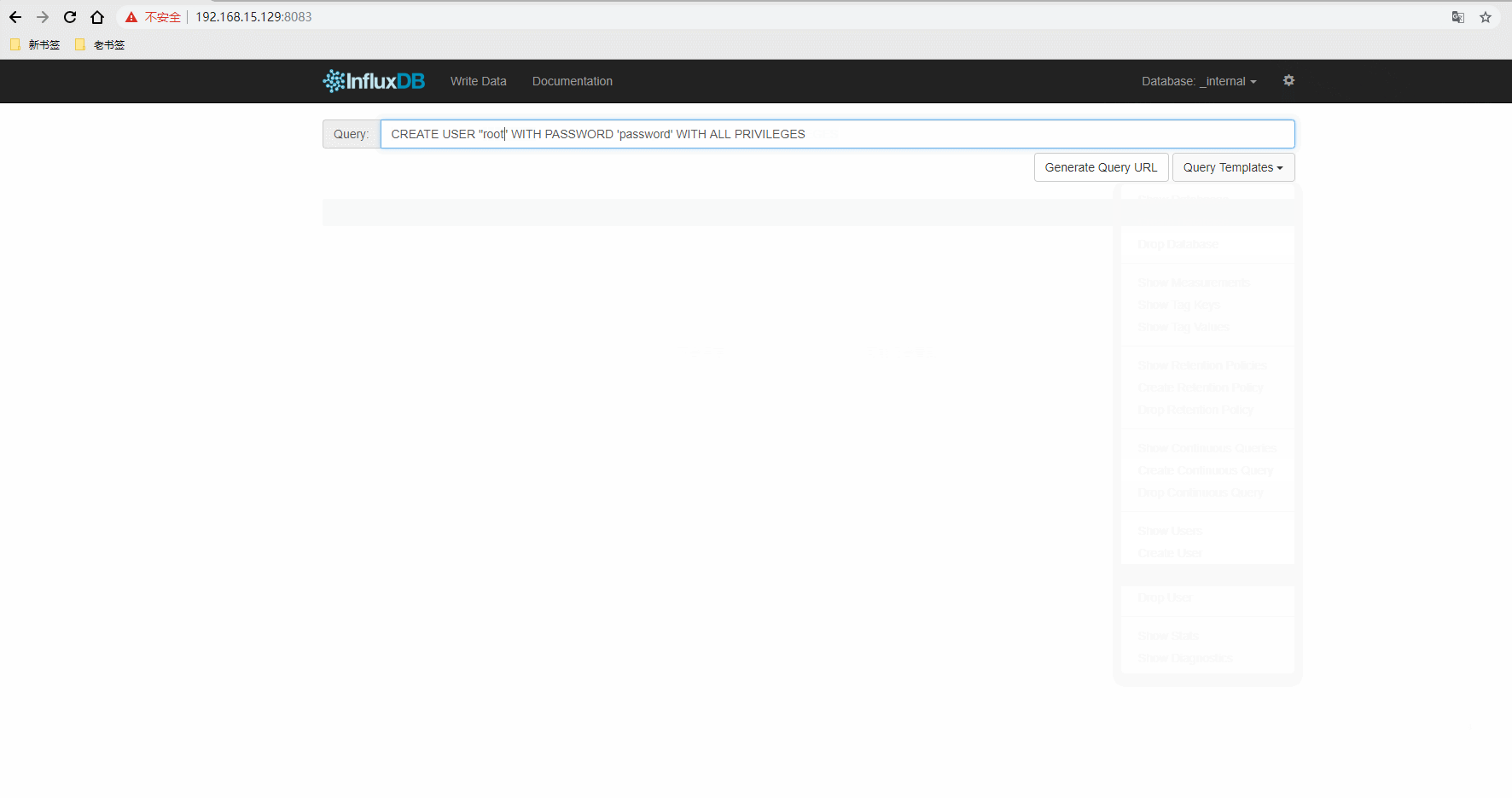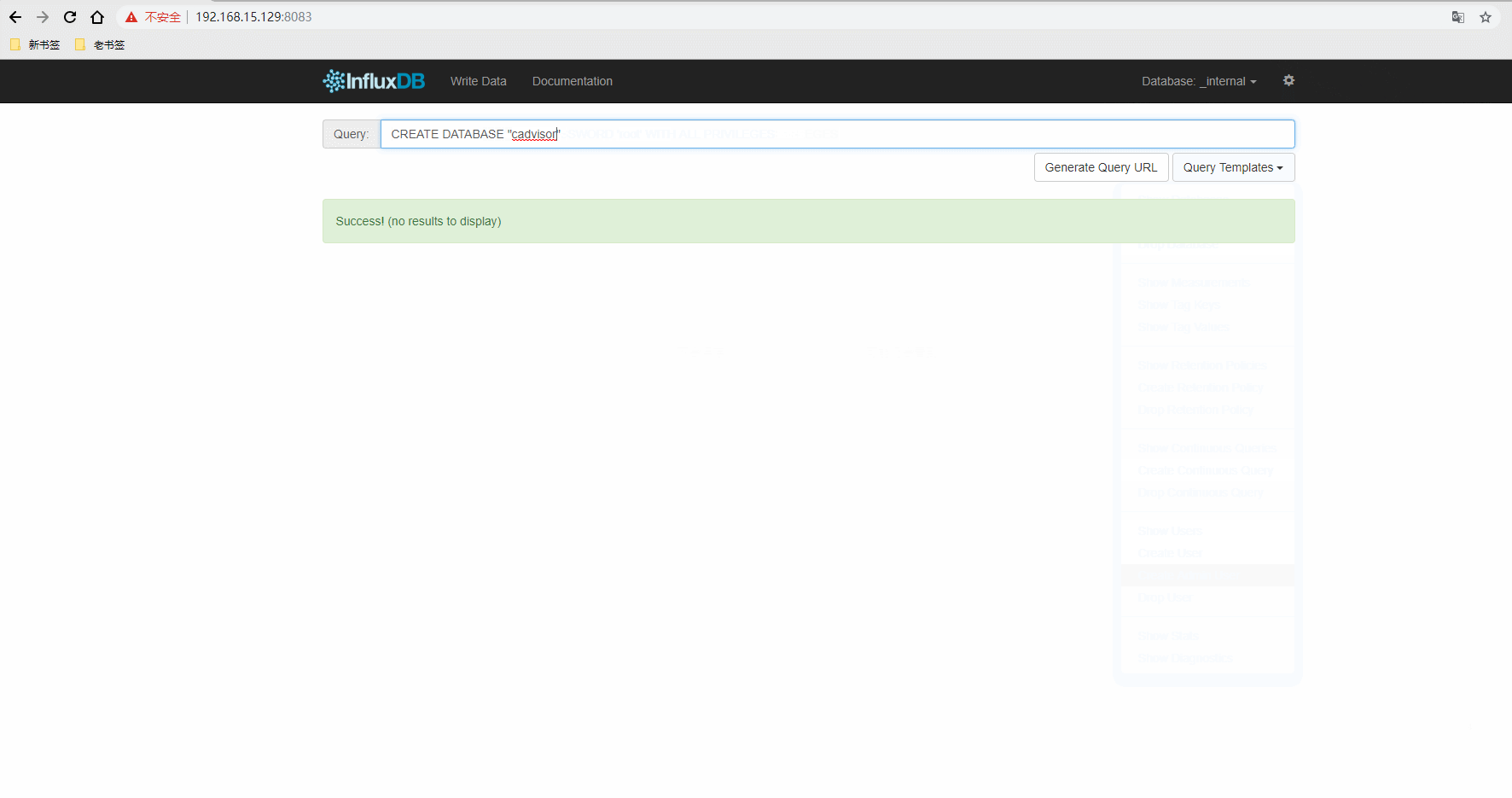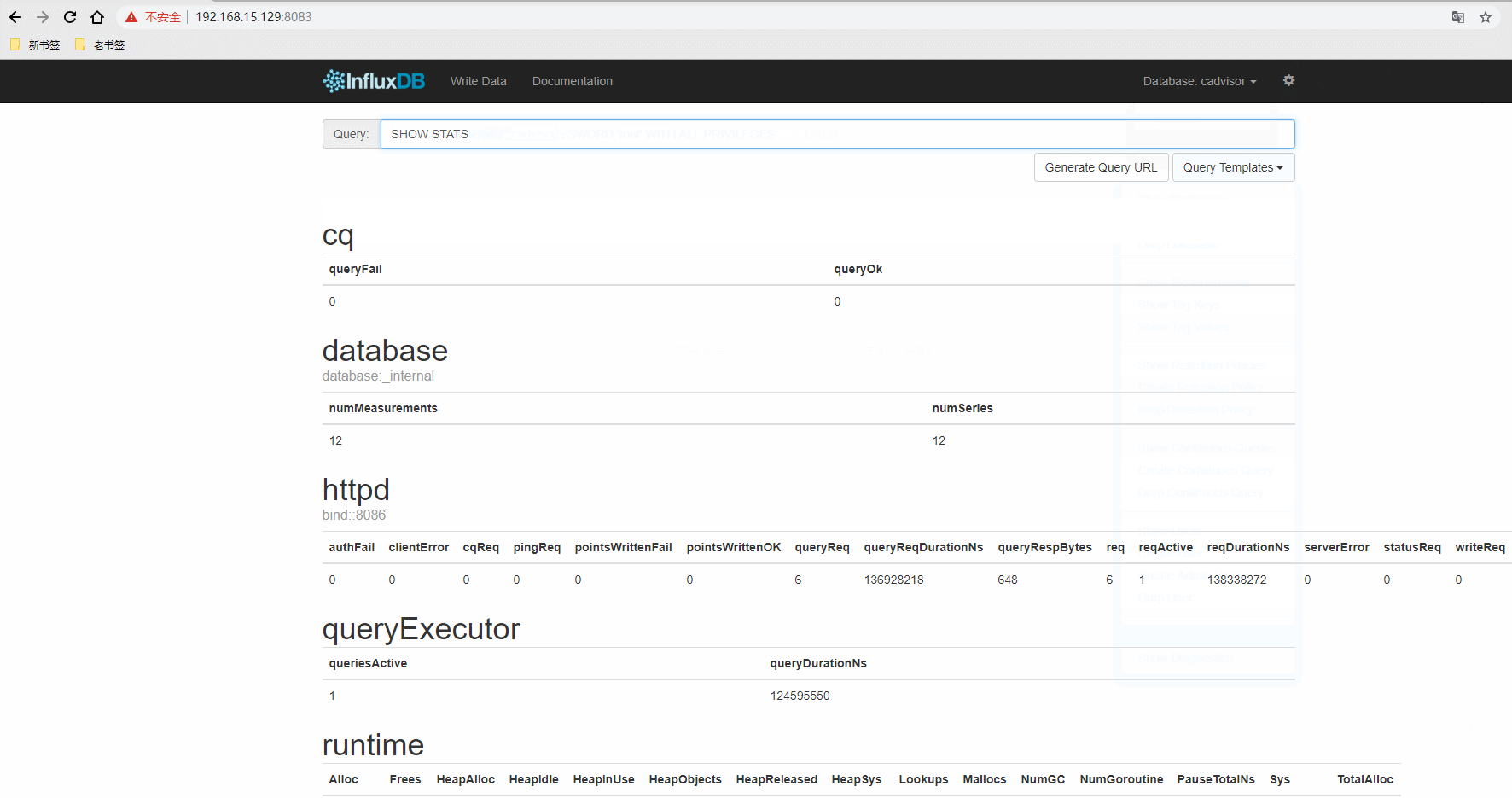
登录数据库查看有没有把采集的数据写入(SHOW MEASUREMENTS执行这个命令)
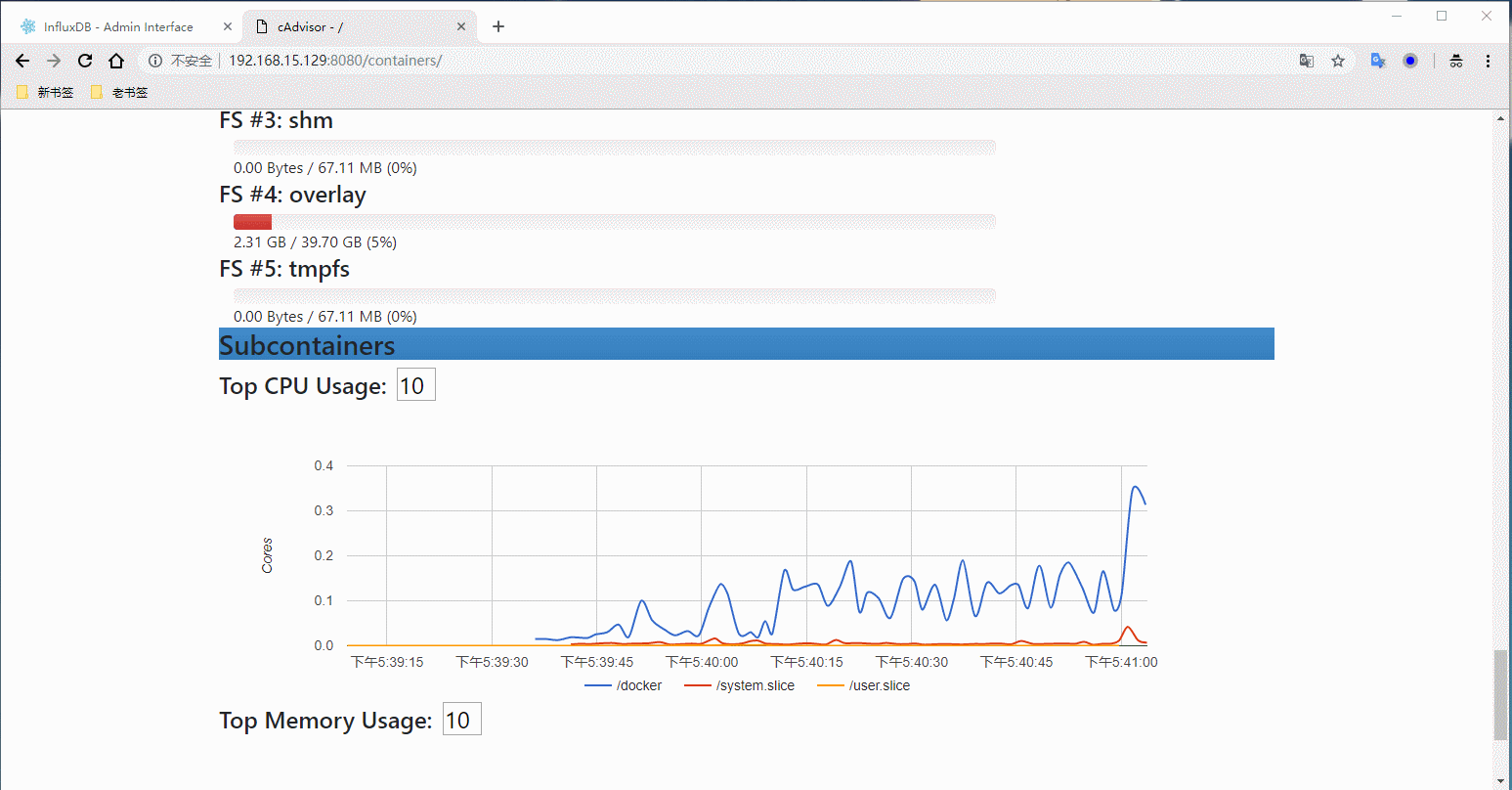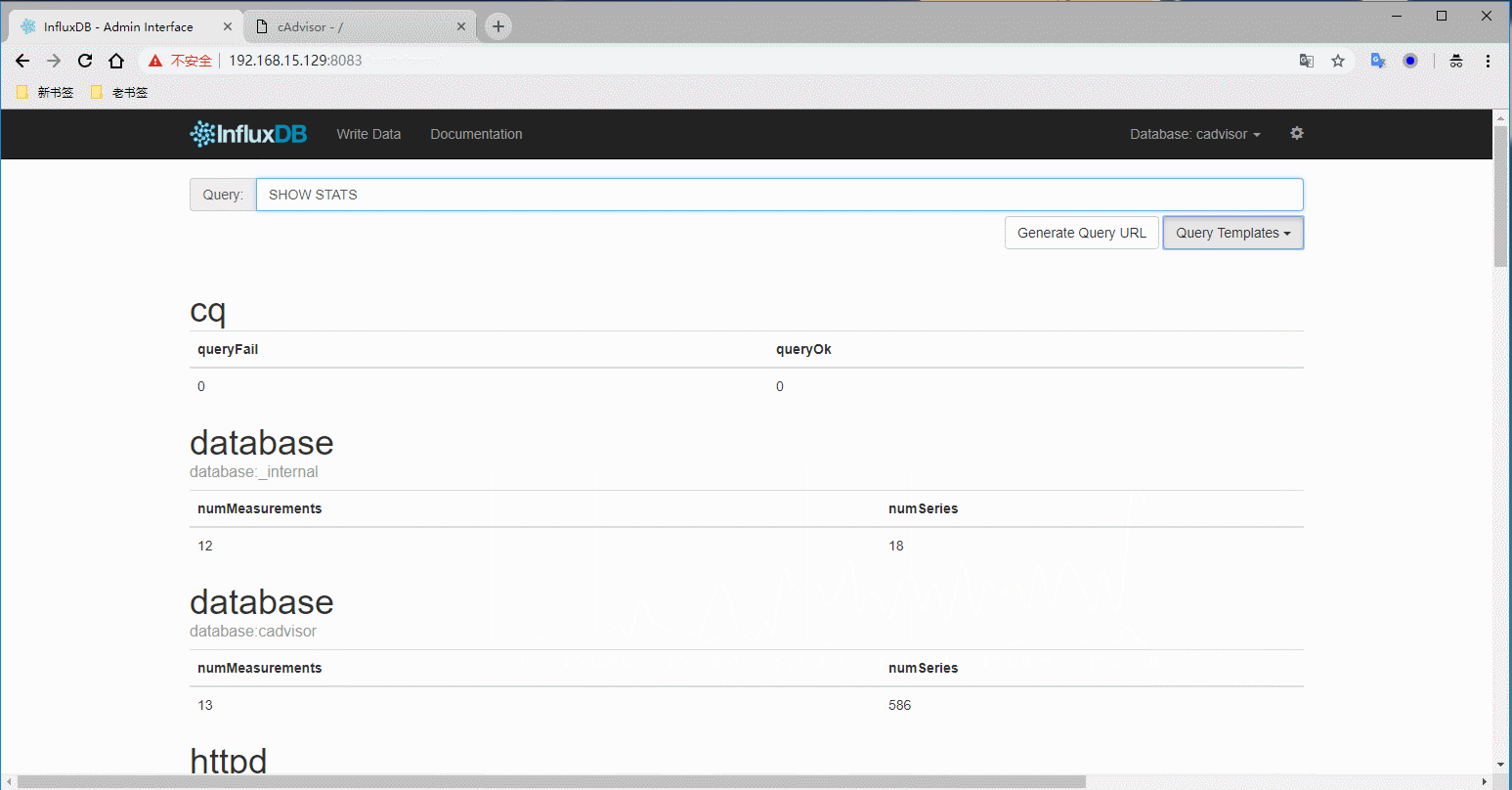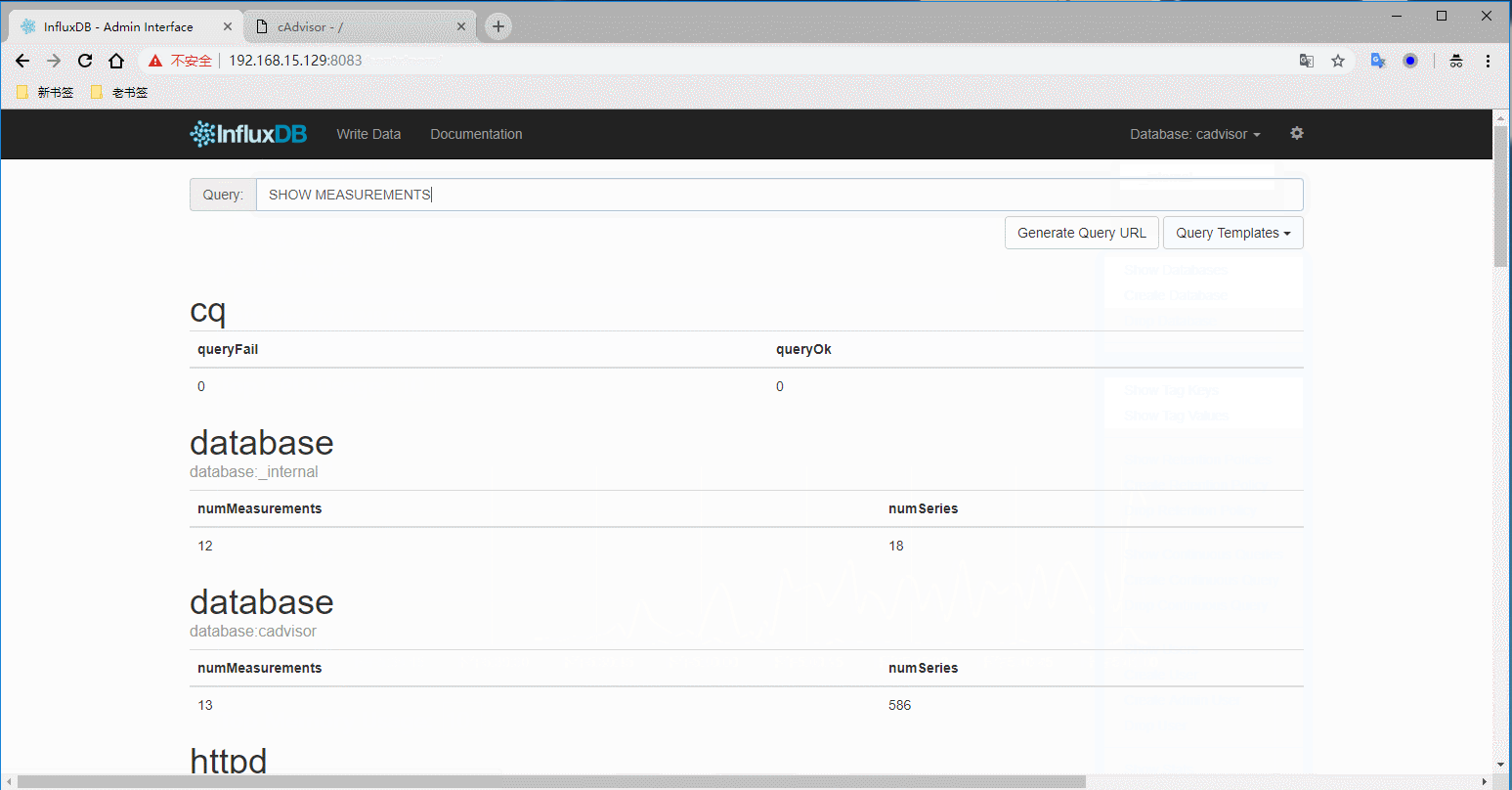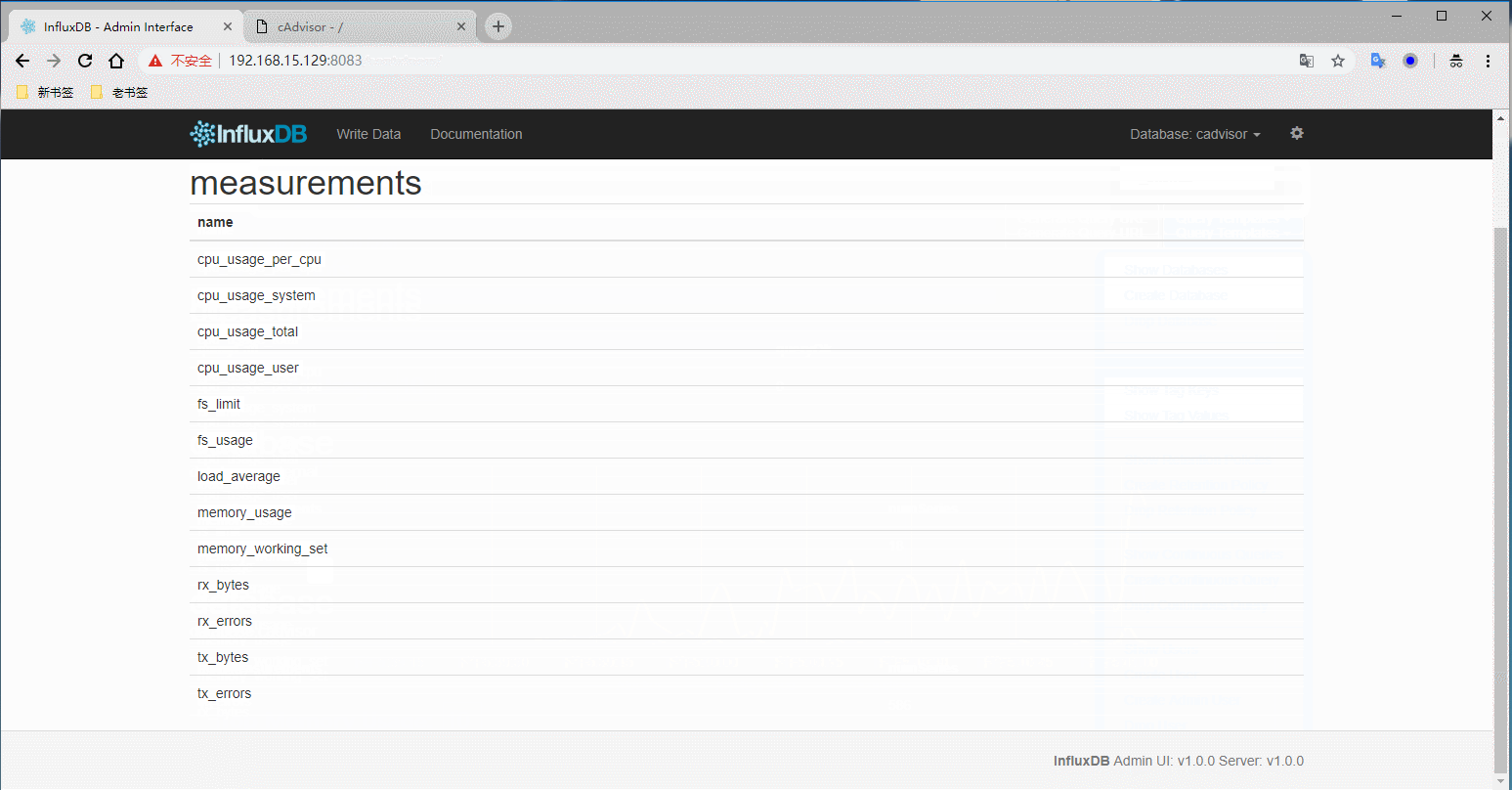
得到上面的结果说明已经采集到数据并且写入到数据库了
4. 创建grafana容器
# 创建grafana容器
[root@master1 ~]# docker run -itd --name grafana -p 3000:3000 grafana/grafana
参数详解:
-itd:已交互模式运行容器,并分配伪终端,并在后台启动容器
-p: 端口映射 3000为grafana的管理平台端口
--name:给容器起个名字
grafana/grafana:以这个镜像运行容器(本地有使用本地,没有先去下载然后启动容器)
# 查看容器
[root@master1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
57f335665902 grafana/grafana "/run.sh" 2 seconds ago Up 1 second 0.0.0.0:3000->3000/tcp grafana
7c2005bb79d1 google/cadvisor "/usr/bin/cadvisor -…" 15 minutes ago Up 15 minutes 0.0.0.0:8080->8080/tcp cadvisor
2fa150d3c52b tutum/influxdb "/run.sh" 25 minutes ago Up 25 minutes 0.0.0.0:8083->8083/tcp, 0.0.0.0:8086->8086/tcp influxdb配置granfana
登录URL:http://192.168.15.129:3000
默认用户名:admin
默认密码:admin
温馨提示:
首次登录会提示修改密码才可以登录,我这里修改密码为admin

得到上面的结果表示整个监控已经部署完成并可以对基础监控进行实施监控,具体需要监控什么,grafana怎么样排版,怎样起名字,根据个人的业务需求来进行设置即可
三、Swarm多节点部署
刚刚上面的例子是在一台主机上监控一台主机的容器信息,这里我们要使用Swarm的集群部署多台主机容器之间的监控
温馨提示:
主机IP:192.168.15.129 主机名:master1 角色:Swarm的主 granfana容器 influxdb容器 cadvisor容器
主机IP:192.168.15.130 主机名:node1 角色:Swarm的node节点 cadvisor容器
主机IP:192.168.15.131 主机名:node2 角色:Swarm的node节点 cadvisor容器
1. 准备工作
# 创建InfluxDB的宿主机目录挂载到容器
[root@master1 ~]# mkdir -p /opt/influxdb
# 下载镜像(可做可不做,在创建容器的时候会如果本地没有会自动下载)
[root@master1 ~]# docker pull tutum/influxdb
[root@master1 ~]# docker pull google/cadvisor
[root@master1 ~]# docker pull grafana/grafana
# 查看镜像
[root@master1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
grafana/grafana latest 7038dbc9a50c 7 days ago 223MB
google/cadvisor latest 75f88e3ec333 10 months ago 62.2MB
tutum/influxdb latest c061e5808198 2 years ago 290MB2. 编写创建容器的yml文件
# 编写docker-compose.yml文件
[root@master1 ~]# mkdir test
[root@master1 test]# cat docker-compose.yml
version: ''3.7''
services:
influx:
image: tutum/influxdb
ports:
- "8083:8083"
- "8086:8086"
volumes:
- "/opt/influxdb:/var/lib/influxdb"
deploy:
replicas: 1
placement:
constraints: [node.role==manager]
grafana:
image: grafana/grafana
ports:
- "3000:3000"
depends_on:
- "influx"
deploy:
replicas: 1
placement:
constraints: [node.role==manager]
cadvisor:
image: google/cadvisor
ports:
- "8080:8080"
hostname: ''{{.Node.Hostname}}''
command: -logtostderr -docker_only -storage_driver=influxdb -storage_driver_db=cadvisor -storage_driver_host=influx:8086
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
depends_on:
- influx
deploy:
mode: global
volumes:
influx:
driver: local
grafana:
driver: local3. 创建Swarm集群
# 在master1上执行
[root@master1 test]# docker swarm init --advertise-addr 192.168.15.129
Swarm initialized: current node (xtooqr30af6fdcu51jzdv79wh) is now a manager.
To add a worker to this swarm, run the following command:
# 这里已经提示使用下面的命令在node节点上执行就可以加入集群(前提docker服务一定是启动的)
docker swarm join --token SWMTKN-1-3yyjydabd8v340kptius215s29rbsq8tviy00s08g6md1y25k2-81tp7lpv114a393g4wlgx4a30 192.168.15.129:2377
To add a manager to this swarm, run ''docker swarm join-token manager'' and follow the instructions.
# 在node1和node2上执行
[root@node1 ~]# docker swarm join --token SWMTKN-1-3yyjydabd8v340kptius215s29rbsq8tviy00s08g6md1y25k2-81tp7lpv114a393g4wlgx4a30 192.168.15.129:2377
This node joined a swarm as a worker
[root@node2 ~]# docker swarm join --token SWMTKN-1-3yyjydabd8v340kptius215s29rbsq8tviy00s08g6md1y25k2-81tp7lpv114a393g4wlgx4a30 192.168.15.129:2377
This node joined a swarm as a worker.
# 在master1上查看集群主机
[root@master1 test]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
xtooqr30af6fdcu51jzdv79wh * master1 Ready Active Leader 18.06.1-ce
y24c6sfs3smv5sd5h7k66x8zv node1 Ready Active 18.06.1-ce
k554xe59lcaeu1suaguvxdnel node2 Ready Active 18.06.1-ce4. 创建集群容器
# 创建集群容器
[root@master1 test]# docker stack deploy -c docker-compose.yml swarm-monitor
Creating network swarm-monitor_default
Creating service swarm-monitor_cadvisor
Creating service swarm-monitor_influx
Creating service swarm-monitor_grafana
# 查看创建的容器
[root@master1 test]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
wn36f7be6i5a swarm-monitor_cadvisor global 3/3 google/cadvisor:latest *:8080->8080/tcp
ufn3lqbhbww3 swarm-monitor_grafana replicated 1/1 grafana/grafana:latest *:3000->3000/tcp
lf0z6dp1u8sn swarm-monitor_influx replicated 1/1 tutum/influxdb:latest *:8083->8083/tcp, *:8086->8086/tcp
# 查看容器的服务
[root@master1 test]# docker service ps swarm-monitor_cadvisor
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
vy1kqg5u8x3f swarm-monitor_cadvisor.k554xe59lcaeu1suaguvxdnel google/cadvisor:latest node2 Running Running about a minute ago
a08b5bysra3d swarm-monitor_cadvisor.y24c6sfs3smv5sd5h7k66x8zv google/cadvisor:latest node1 Running Running about a minute ago
kkca4kyojgr2 swarm-monitor_cadvisor.xtooqr30af6fdcu51jzdv79wh google/cadvisor:latest master1 Running Running 59 seconds ago
[root@master1 test]# docker service ps swarm-monitor_grafana
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
klyjl7rxzmoz swarm-monitor_grafana.1 grafana/grafana:latest master1 Running Running about a minute ago
[root@master1 test]# docker service ps swarm-monitor_influx
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
pan5yvwq7b79 swarm-monitor_influx.1 tutum/influxdb:latest master1 Running Running about a minute ago5. 访问web测试
1) 访问influxdb并创建数据库
登录InfluxDB的8083端口,并添加数据库
登录URL:http://192.168.15.129:8083
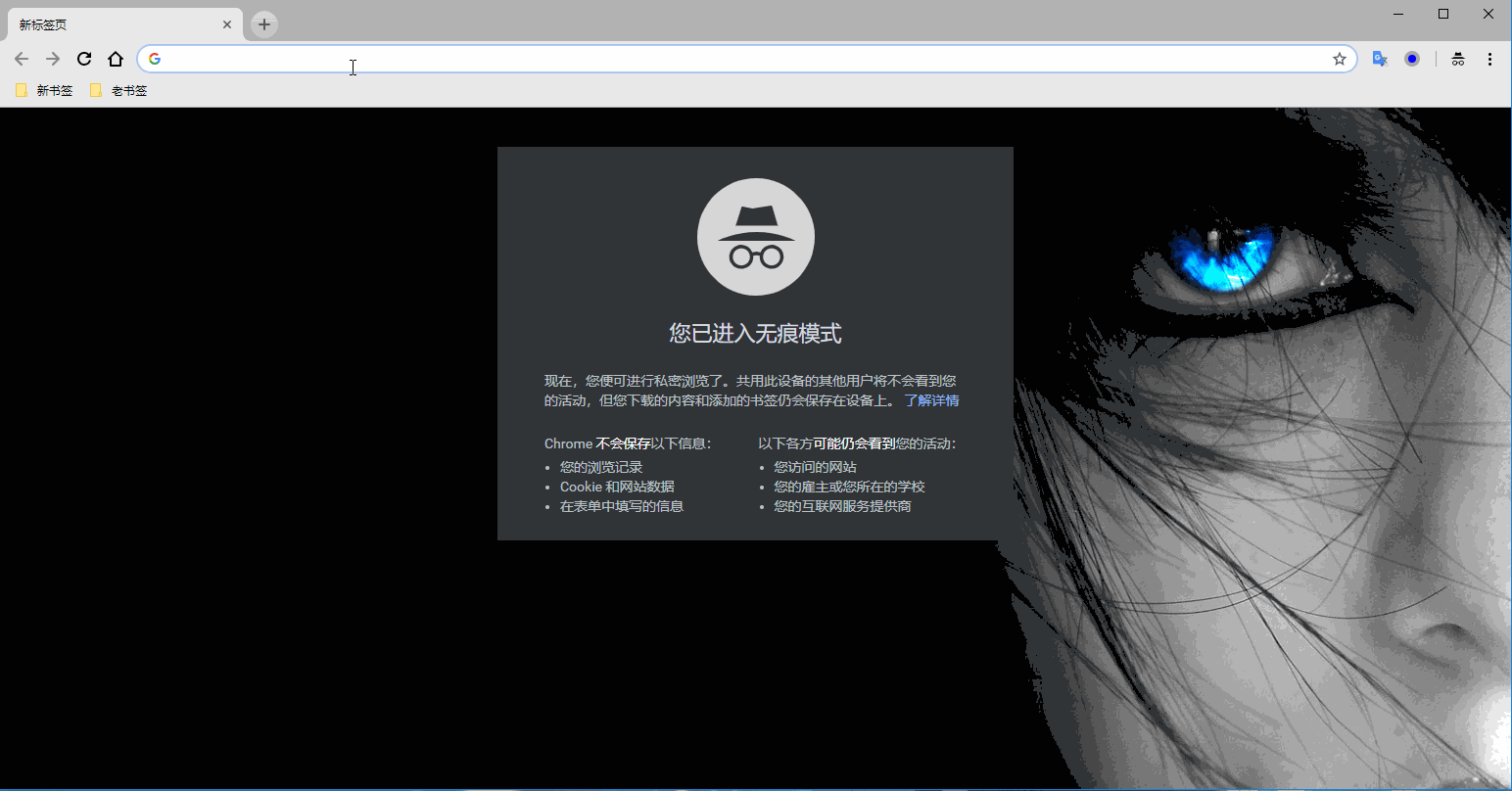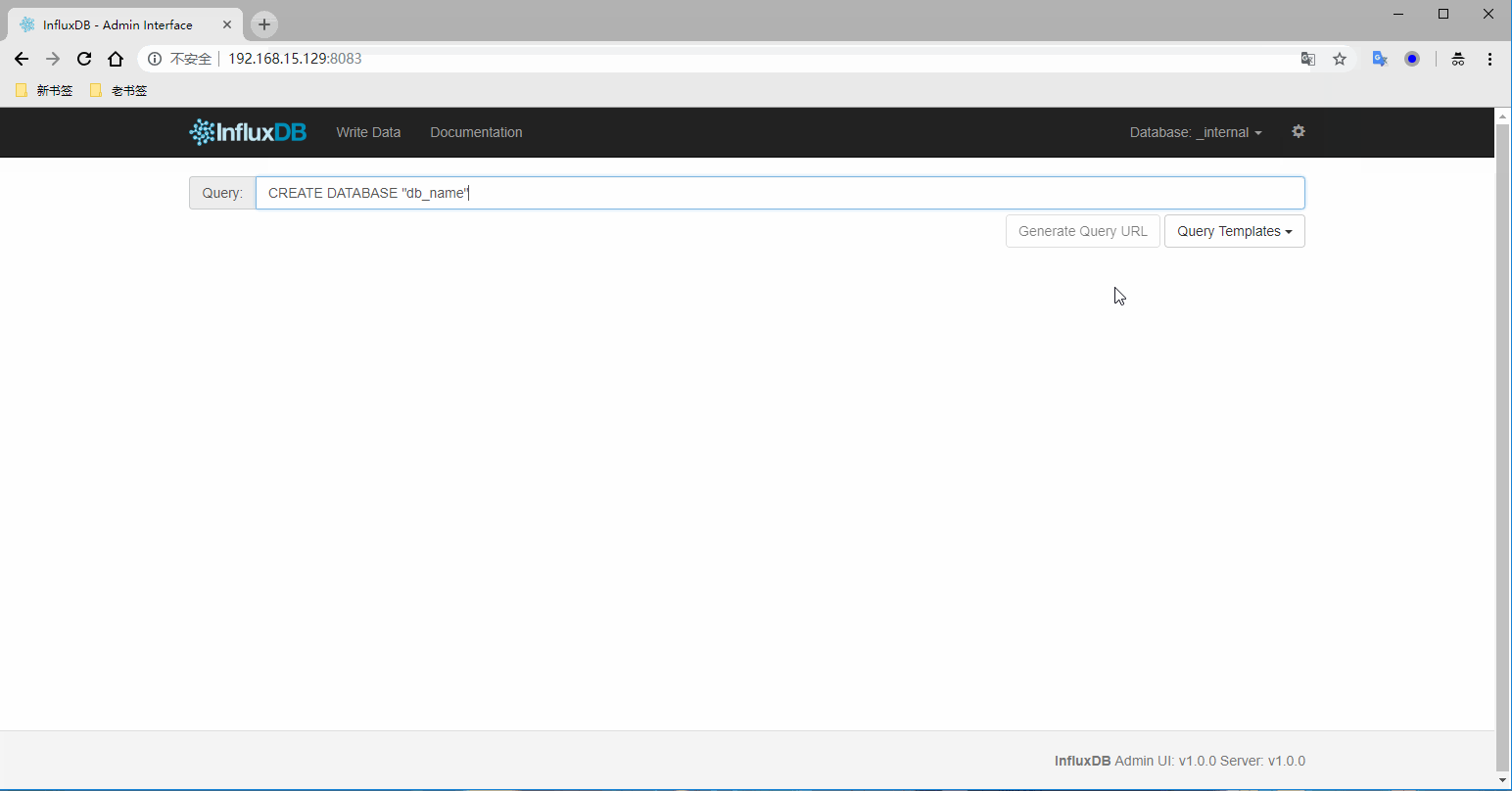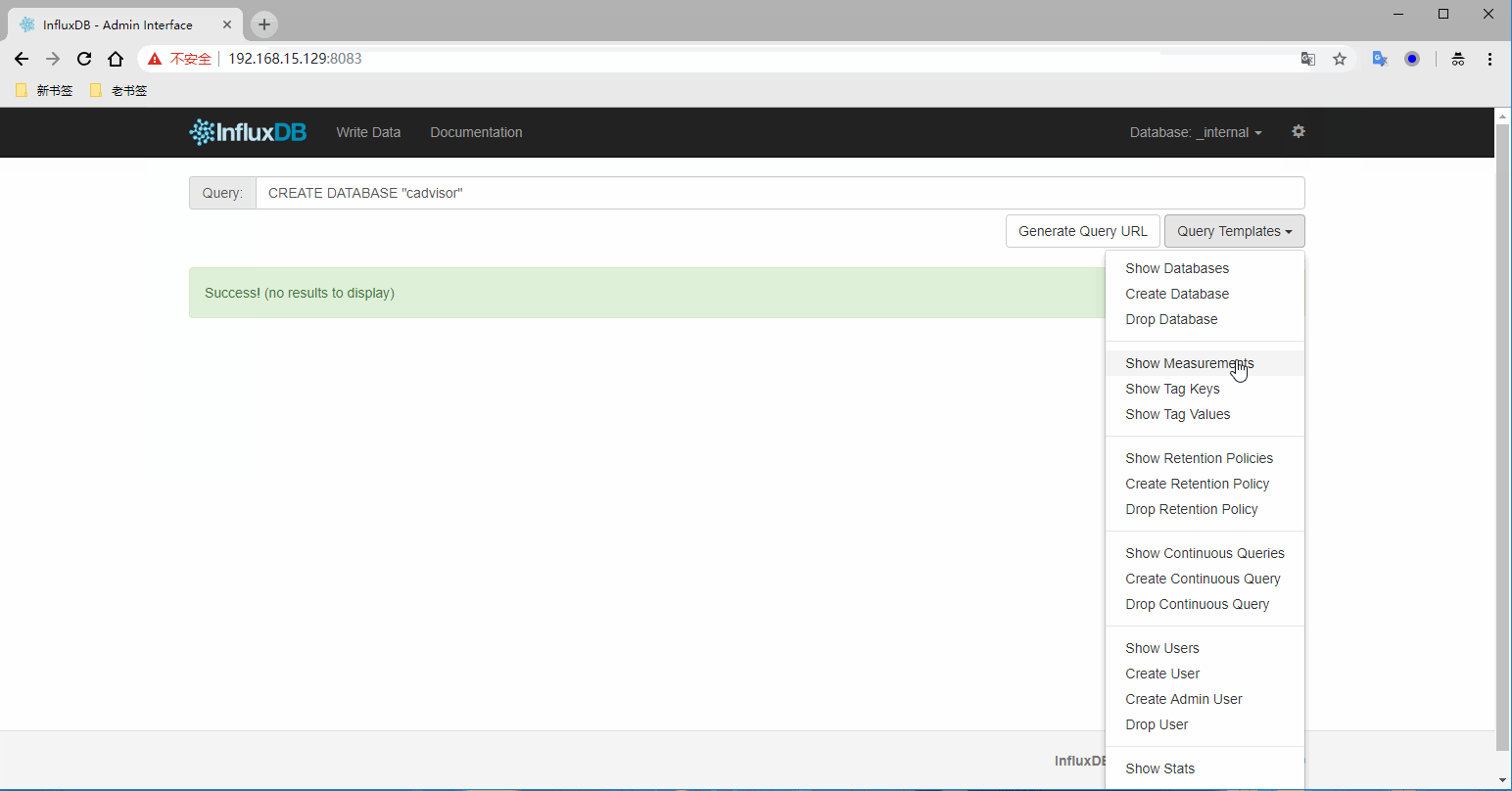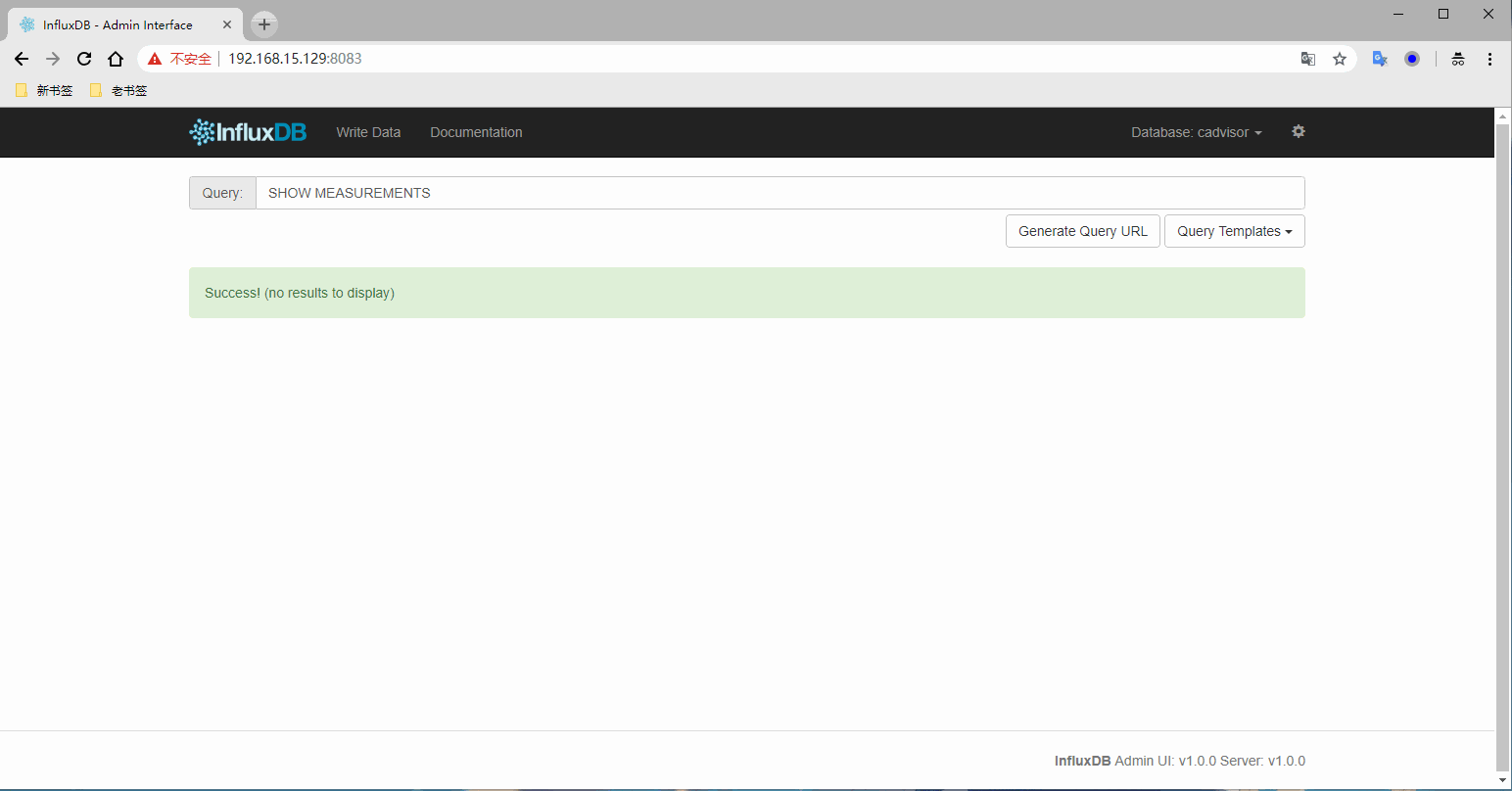
2) 访问cadvisor
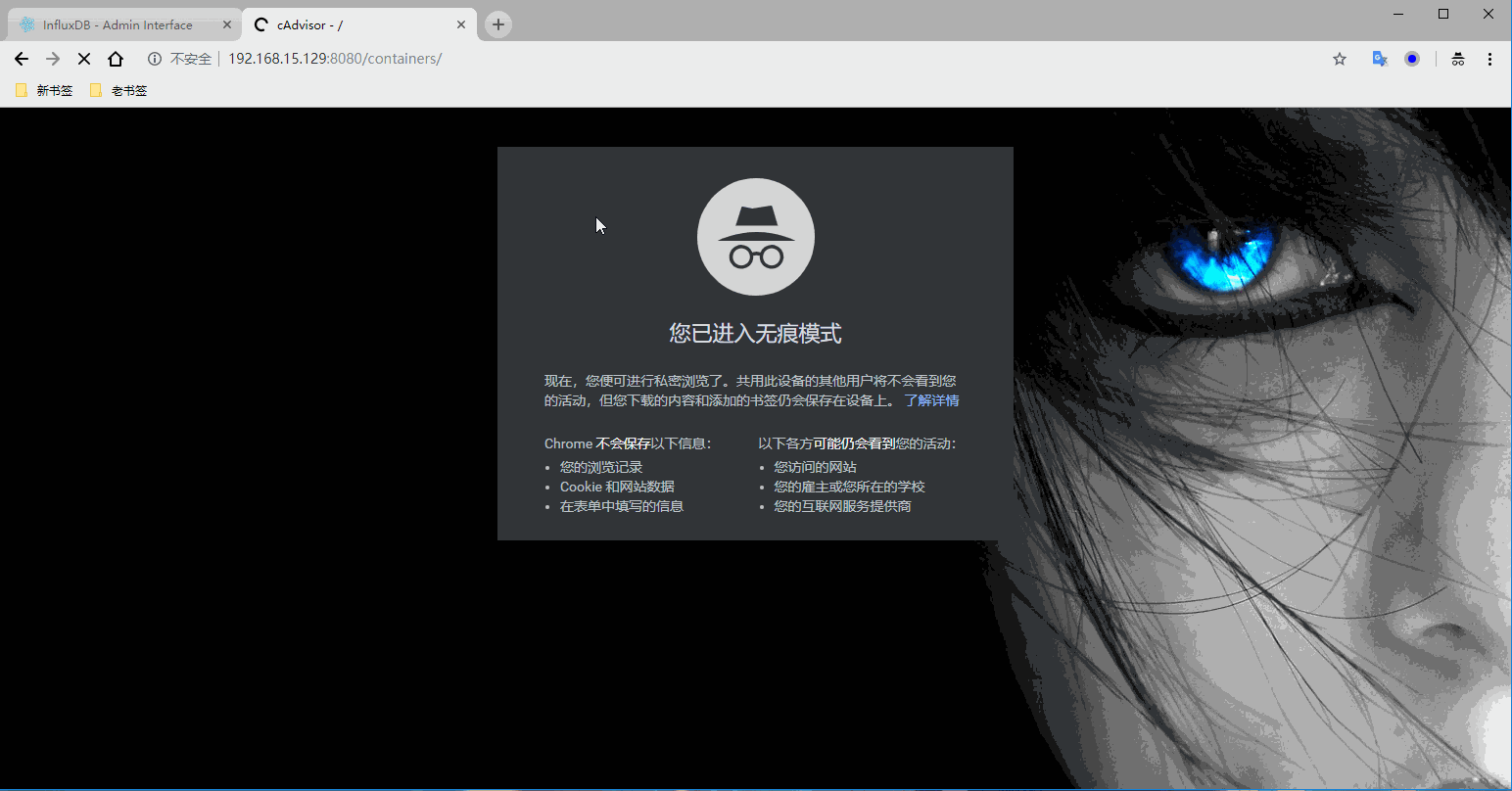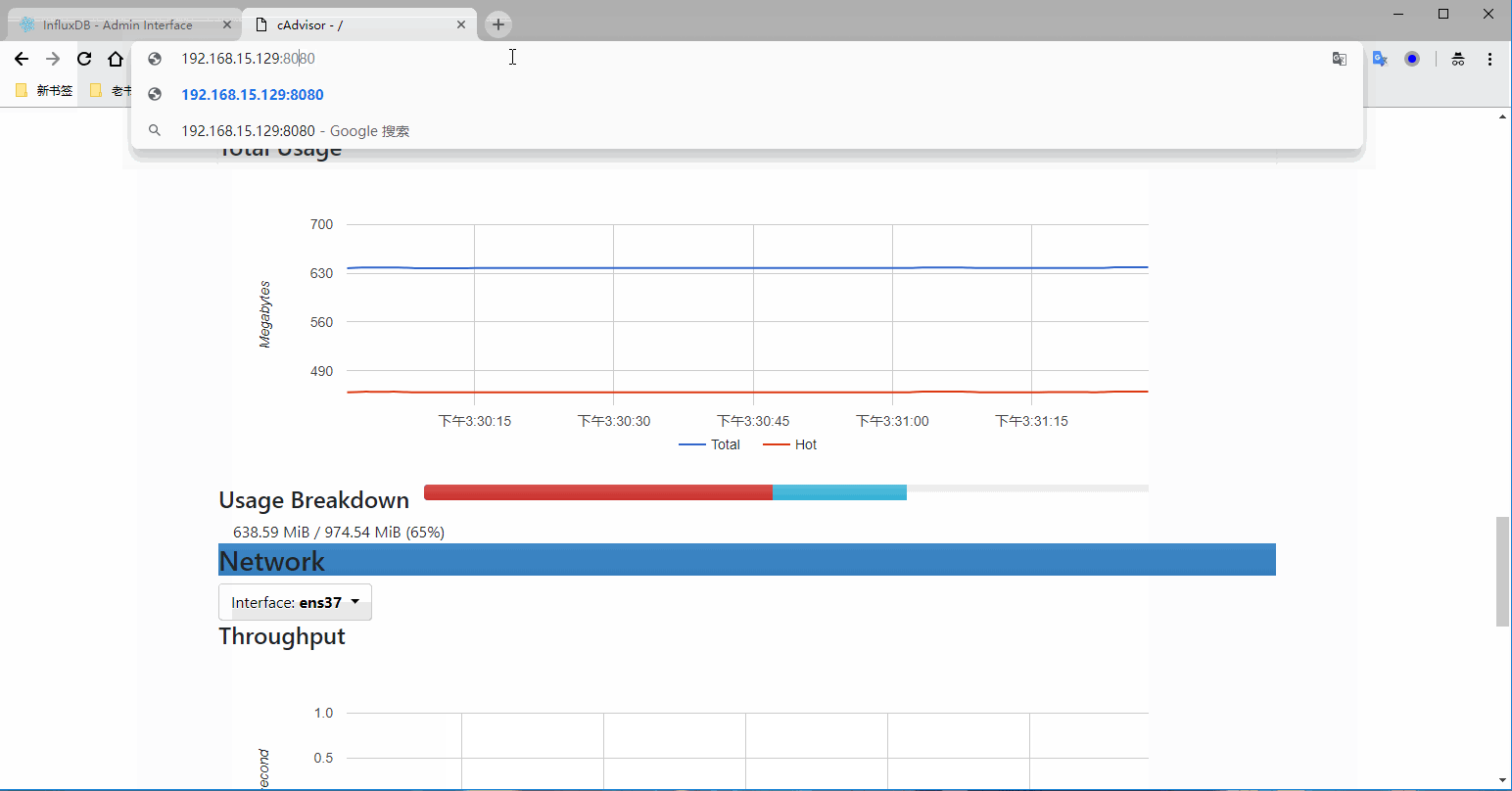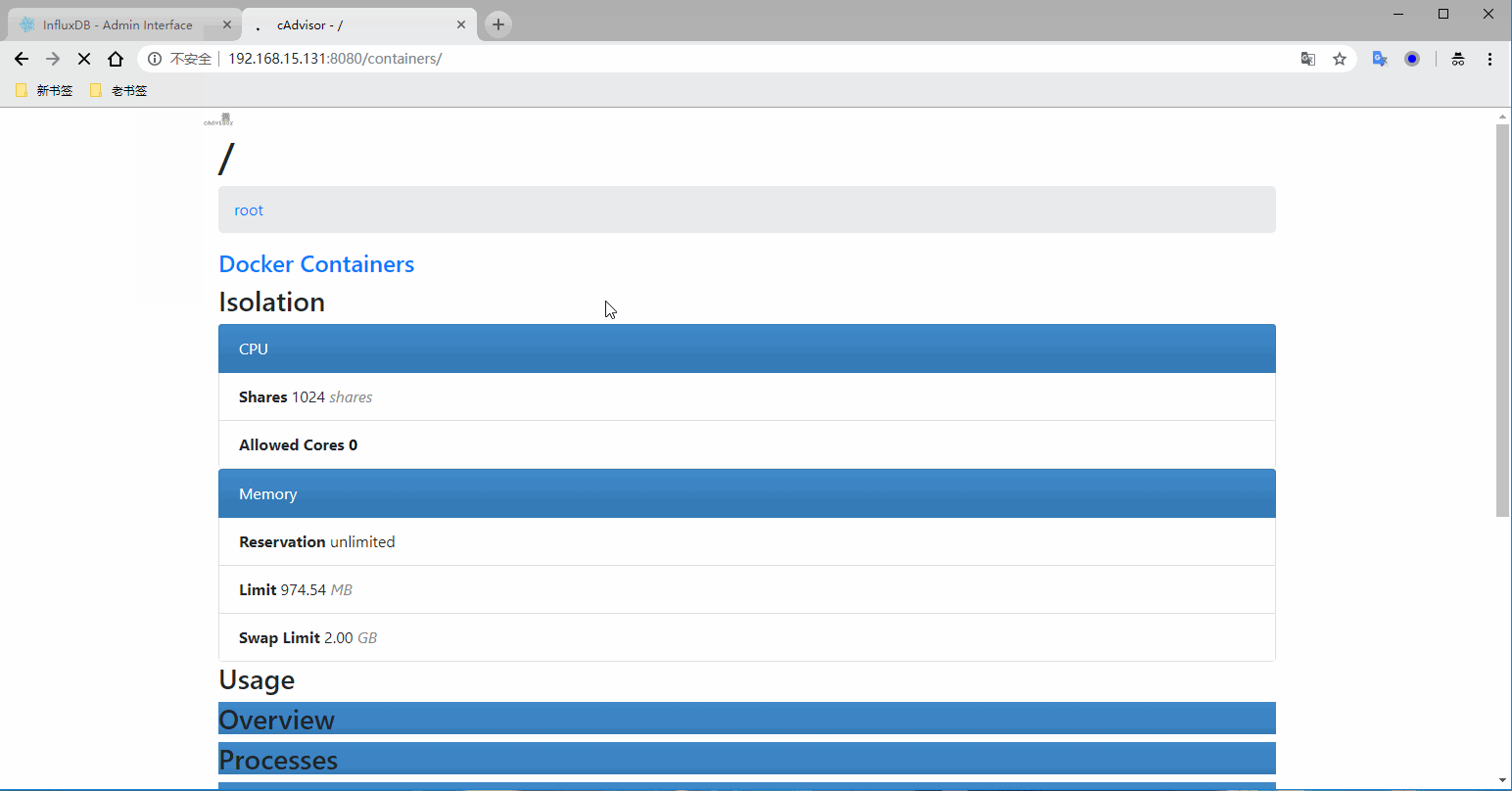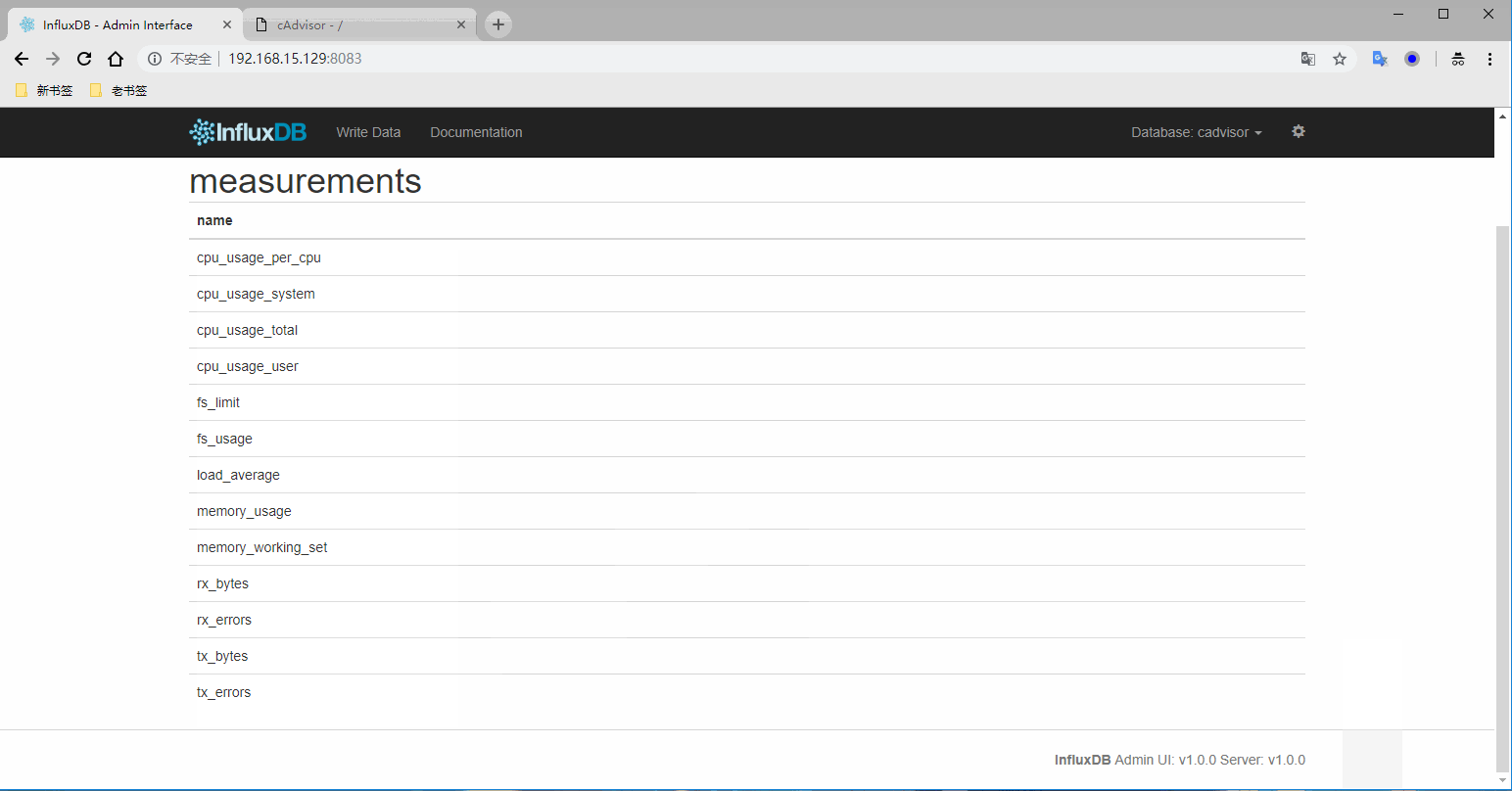
登录URL:http://192.168.15.129:8080
登录数据库查看有没有把采集的数据写入
3) 访问grafana并配置
登录URL:http://192.168.15.129:3000
默认用户名:admin
默认密码:admin
温馨提示:
首次登录会提示修改密码才可以登录,我这里修改密码为admin
这个动图比较长 主要是对grafana的配置操作,注意里面的alpine_test容器不是和集群一块创建的是我单独创建的

做到以上的效果,说明已经部署成功了,具体的配置方案就是因需求而异了

cAdvisor+Prometheus+Grafana监控docker
cAdvisor+Prometheus+Grafana监控docker
一、cAdvisor(需要监控的主机都要安装)
官方地址:https://github.com/google/cadvisor
CAdvisor是谷歌开发的用于分析运行中容器的资源占用和性能指标的开源工具。CAdvisor是一个运行时的守护进程,负责收集、聚合、处理和输出运行中容器的信息。
注意在查找相关资料后发现这是最新版cAdvisor的bug,换成版本为google/cadvisor:v0.24.1 就ok了,映射主机端口默认是8080,可以修改。
sudo docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:ro \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --volume=/dev/disk/:/dev/disk:ro \ --publish=8090:8080 \ --detach=true \ --name=cadvisor \ google/cadvisor:v0.24.1
cAdvisor exposes a web UI at its port:
http://<hostname>:<port>/
下图为cAdvisor的web界面,数据实时刷新但是不能存储。

查看json格式
http://192.168.247.212:8090/metrics

二、Prometheus
官方地址:https://prometheus.io/
随着容器技术的迅速发展,Kubernetes 已然成为大家追捧的容器集群管理系统。Prometheus 作为生态圈 Cloud Native Computing Foundation(简称:CNCF)中的重要一员,其活跃度仅次于 Kubernetes, 现已广泛用于 Kubernetes 集群的监控系统中。本文将简要介绍 Prometheus 的组成和相关概念,并实例演示 Prometheus 的安装,配置及使用,以便开发人员和云平台运维人员可以快速的掌握 Prometheus。
Prometheus 简介
Prometheus 是一套开源的系统监控报警框架。它启发于 Google 的 borgmon 监控系统,由工作在 SoundCloud 的 google 前员工在 2012 年创建,作为社区开源项目进行开发,并于 2015 年正式发布。2016 年,Prometheus 正式加入 Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项目。
作为新一代的监控框架,Prometheus 具有以下特点:
强大的多维度数据模型:
- 时间序列数据通过 metric 名和键值对来区分。
- 所有的 metrics 都可以设置任意的多维标签。
- 数据模型更随意,不需要刻意设置为以点分隔的字符串。
- 可以对数据模型进行聚合,切割和切片操作。
- 支持双精度浮点类型,标签可以设为全 unicode。
灵活而强大的查询语句(PromQL):在同一个查询语句,可以对多个 metrics 进行乘法、加法、连接、取分数位等操作。
易于管理: Prometheus server 是一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。
高效:平均每个采样点仅占 3.5 bytes,且一个 Prometheus server 可以处理数百万的 metrics。
使用 pull 模式采集时间序列数据,这样不仅有利于本机测试而且可以避免有问题的服务器推送坏的 metrics。
可以采用 push gateway 的方式把时间序列数据推送至 Prometheus server 端。
可以通过服务发现或者静态配置去获取监控的 targets。
有多种可视化图形界面。
易于伸缩。
需要指出的是,由于数据采集可能会有丢失,所以 Prometheus 不适用对采集数据要 100% 准确的情形。但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构
Prometheus 组成及架构
Prometheus 生态圈中包含了多个组件,其中许多组件是可选的:
- Prometheus Server: 用于收集和存储时间序列数据。
- Client Library: 客户端库,为需要监控的服务生成相应的 metrics 并暴露给 Prometheus server。当 Prometheus server 来 pull 时,直接返回实时状态的 metrics。
- Push Gateway: 主要用于短期的 jobs。由于这类 jobs 存在时间较短,可能在 Prometheus 来 pull 之前就消失了。为此,这次 jobs 可以直接向 Prometheus server 端推送它们的 metrics。这种方式主要用于服务层面的 metrics,对于机器层面的 metrices,需要使用 node exporter。
- Exporters: 用于暴露已有的第三方服务的 metrics 给 Prometheus。
- Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去除重复数据,分组,并路由到对收的接受方式,发出报警。常见的接收方式有:电子邮件,pagerduty,OpsGenie, webhook 等。一些其他的工具。
Prometheus 架构图

安装步骤:
wget https://github.com/prometheus/prometheus/releases/download/v2.8.0/prometheus-2.8.0.linux-amd64.tar.gz
tar -xf prometheus-2.8.0.linux-amd64.tar.gz
cd prometheus-2.8.0.linux-amd64
修改配置文件prometheus.yml,添加以下内容
static_configs:
- targets: ['192.168.247.211:9090']
- job_name: 'docker'
static_configs:
- targets:
- "192.168.247.211:8090"
- "192.168.247.212:8090"
cp prometheus promtool /usr/local/bin/
启动:
nohup prometheus --config.file=./prometheus.yml &
我的完整简单prometheus.yml配置文件:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['192.168.247.211:9090']
- job_name: 'docker'
static_configs:
- targets:
- "192.168.247.211:8090"
- "192.168.247.212:8090"
访问:http://192.168.247.211:9090

三、Grafana
官方地址:https://grafana.com/
安装步骤:
wget https://dl.grafana.com/oss/release/grafana-6.0.1-1.x86_64.rpm sudo yum localinstall grafana-6.0.1-1.x86_64.rpm -y systemctl daemon-reload systemctl start grafana-server systemctl status grafana-server #设置开机自启动 Enable the systemd service so that Grafana starts at boot. sudo systemctl enable grafana-server.service
1.访问:http://192.168.247.211:3000/login
默认密码:admin/admin

2.配置Prometheus数据源

3.下载模板模板地址:https://grafana.com/dashboards

4.导入模板

5.成品

关于Prometheus入门到放弃(4)之cadvisor监控docker容器和prometheus监控docker 容器的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于4.Docker容器学习之Dockerfile入门到放弃、CAdvisor + InfluxDB + Grafana是怎么搭建Docker容器监控系统、cAdvisor+InfluxDB+Grafana 监控Docker、cAdvisor+Prometheus+Grafana监控docker的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

