在本文中,我们将带你了解搜索引擎的分片在这篇文章中,我们将为您详细介绍搜索引擎的分片的方方面面,并解答shard和副本常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的009,elastics
在本文中,我们将带你了解搜索引擎的分片在这篇文章中,我们将为您详细介绍搜索引擎的分片的方方面面,并解答shard和副本常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的009,elasticsearch--[L10]--shard&replica 机制再次梳理以及单 node 环境中创建 index 图解、Docker 下,实战 mongodb 副本集(Replication)、elasticsearch shard 和 replica、ElasticSearch 基础分布式架构+shard+replica。
本文目录一览:- 搜索引擎的分片(shard)和副本(replica)机制(搜索引擎结果)
- 009,elasticsearch--[L10]--shard&replica 机制再次梳理以及单 node 环境中创建 index 图解
- Docker 下,实战 mongodb 副本集(Replication)
- elasticsearch shard 和 replica
- ElasticSearch 基础分布式架构+shard+replica
和副本(replica)机制(搜索引擎结果)")
搜索引擎的分片(shard)和副本(replica)机制(搜索引擎结果)
搜索引擎通过分片(shard)和副本(replica)实现了高性能、高伸缩和高可用。
分片技术为大规模并行索引和搜索提供了支持,极大地提高了索引和搜索的性能,极大地提高了水平扩展能力;
副本技术为数据提供冗余,部分机器故障不影响系统的正常使用,保证了系统的持续高可用。
有2个分片和3份副本的索引结构如下所示:
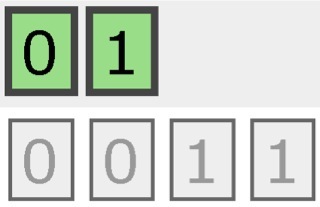
一个完整的索引被切分为0和1两个独立部分,每一部分都有2个副本,即上图的灰色部分。
在 生产环境中,随着数据规模的增大,只需简单地增加硬件机器节点即可,搜索引擎会自动地调整分片数以适应硬件的增加,当部分节点退役的时候,搜索引擎也会自 动调整分片数以适应硬件的减少,同时可以根据硬件的可靠性水平及存储容量的变化随时更改副本数,这一切都是动态的,不需要重启集群,这也是高可用的重要保 障。
![009,elasticsearch--[L10]--shard&replica 机制再次梳理以及单 node 环境中创建 index 图解](http://www.gvkun.com/zb_users/upload/2025/03/b623789c-347b-4302-84de-9837972294ba1742091136833.jpg "009,elasticsearch--[L10]--shard&replica 机制再次梳理以及单 node 环境中创建 index 图解")
009,elasticsearch--[L10]--shard&replica 机制再次梳理以及单 node 环境中创建 index 图解
课程大纲
1、shard&replica 机制再次梳理
2、图解单 node 环境下创建 index 是什么样子的
------------------------------------------------------------------------------------------------
1、shard&replica 机制再次梳理
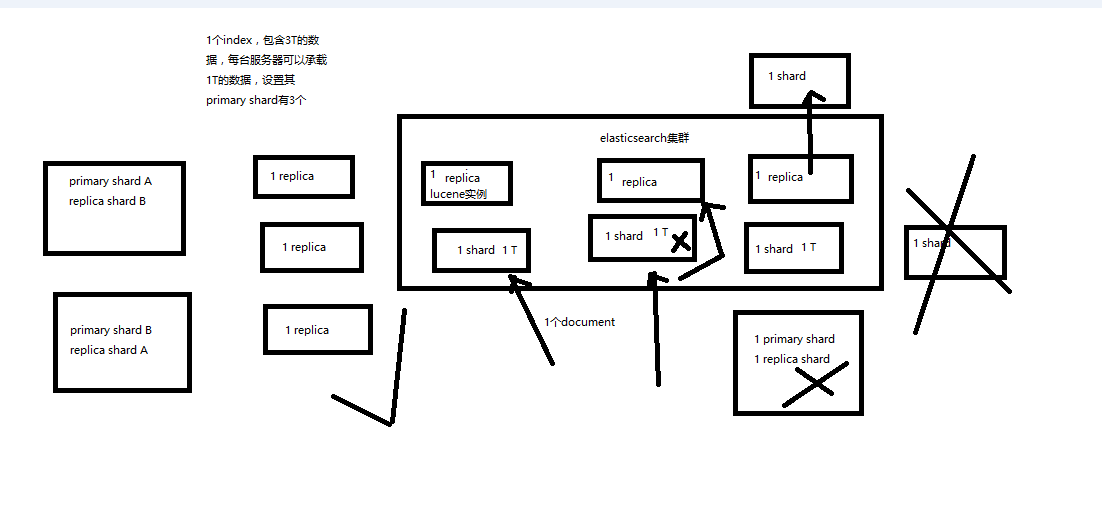
(1)index 包含多个 shard
(2)每个 shard 都是一个最小工作单元,承载部分数据,lucene 实例,完整的建立索引和处理请求的能力
(3)增减节点时,shard 会自动在 nodes 中负载均衡
(4)primary shard 和 replica shard,每个 document 肯定只存在于某一个 primary shard 以及其对应的 replica shard 中,不可能存在于多个 primary shard
(5)replica shard 是 primary shard 的副本,负责容错,以及承担读请求负载
(6)primary shard 的数量在创建索引的时候就固定了,replica shard 的数量可以随时修改
(7)primary shard 的默认数量是 5,replica 默认是 1,默认有 10 个 shard,5 个 primary shard,5 个 replica shard
(8)primary shard 不能和自己的 replica shard 放在同一个节点上(否则节点宕机,primary shard 和副本都丢失,起不到容错的作用),但是可以和其他 primary shard 的 replica shard 放在同一个节点上
------------------------------------------------------------------------------------------------
2、图解单 node 环境下创建 index 是什么样子的
(1)单 node 环境下,创建一个 index,有 3 个 primary shard,3 个 replica shard
(2)集群 status 是 yellow
(3)这个时候,只会将 3 个 primary shard 分配到仅有的一个 node 上去,另外 3 个 replica shard 是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
")
Docker 下,实战 mongodb 副本集(Replication)
在《Docker 下,极速体验 mongodb》一文中我们体验了单机版的 mongodb,实际生产环境中,一般都会通过集群的方式来避免单点故障,今天我们就在 Docker 下实战 mongodb 副本集(Replication)集群环境的搭建;
副本集简介
下图来自 mongodb 官网,说明了副本集的部署和用法:
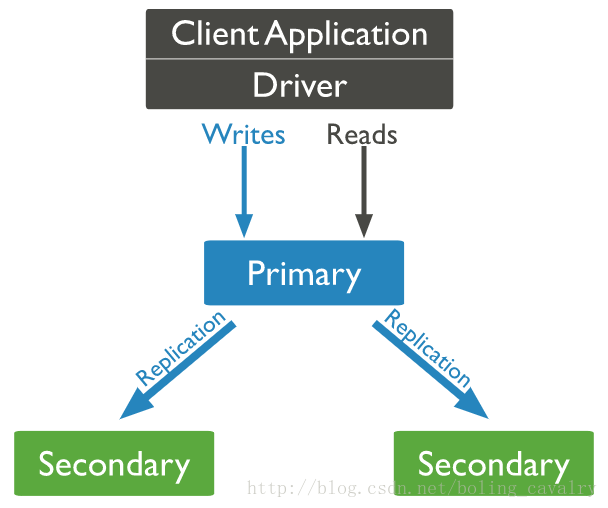
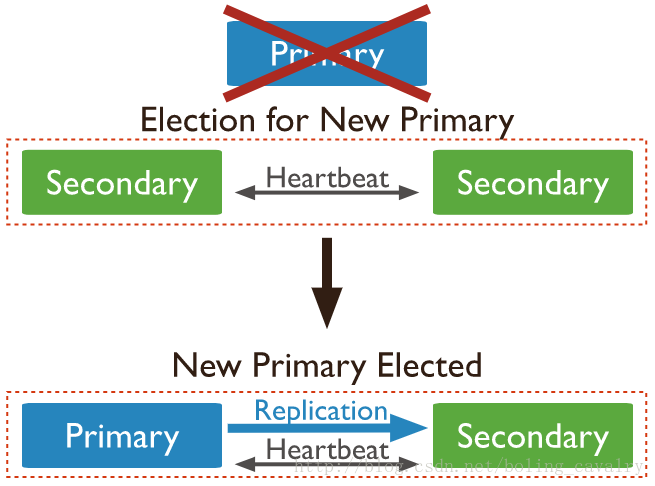
如上图,一共有三个 mongodb server,分别是 Primary、Secondary1、Secondary2,应用服务器的读写都在 Primary 完成,但是数据都会同步到 Secondary1 和 Secondary2 上,当 Primary 不可用时,会通过重新选举得到新的 Primary 机器,以保证整个服务是可用的,如下图:
环境信息
本次实战一共要启动三个容器,它们的身份和 IP 如下表所示:
| 容器名 | ip | 备注 |
|---|---|---|
| m0 | 172.18.0.3 | Primary |
| m1 | 172.18.0.4 | Secondary1 |
| m2 | 172.18.0.2 | Secondary2 |
本次用到的镜像
本次用到的镜像是 bolingcavalry/ubuntu16-mongodb349:0.0.1,这是我自己制作的 mongodb 的镜像,已经上传到 hub.docker.com 网站,可以通过 docker pull bolingcavalry/ubuntu16-mongodb349:0.0.1 命令下载使用,关于此镜像的详情请看《制作 mongodb 的 Docker 镜像文件》;
docker-compose.yml
为了便于集中管理所有容器,我们使用 docker-compose.yml 来管理三个 server,内容如下所示:
version: ''2''
services:
m0:
image: bolingcavalry/ubuntu16-mongodb349:0.0.1
container_name: m0
ports:
- "28017:28017"
command: /bin/sh -c ''mongod --replSet replset0''
restart: always
m1:
image: bolingcavalry/ubuntu16-mongodb349:0.0.1
container_name: m1
command: /bin/sh -c ''mongod --replSet replset0''
restart: always
m2:
image: bolingcavalry/ubuntu16-mongodb349:0.0.1
container_name: m2
command: /bin/sh -c ''mongod --replSet replset0''
restart: always如上所示,三个容器使用了相同的镜像,并且使用了相同的启动命令 /bin/sh -c ‘mongod –replSet replset0’,–replSet replset0 是启动副本集模式服务的参数;
在使用 docker-compose up -d 命令启动的时候遇到一点小问题:启动后用 docker ps 命令查看容器状态,发现三个容器均是”Restarting” 状态,网上搜了一下说有可能是内存不足引起的,于是我重启了电脑,在没有打开其他耗费内存的进程的时候再次执行 docker-compose up -d 命令,这次启动成功了 (我的电脑是 8G 内存的 Mac pro);
关于这个问题,最好的解决方法应该是限制 mongodb 的占用内存,但是好像没有找到控制参数,其次的解决方法是限制 docker 容器的内存大小,这个在执行 docker run 来启动的时候可以通过 - m 来限制,但是在 docker-compose 命令中并没有找到限制内存的参数,所以读者们如果也遇到此问题,请不要用 docker-compose 来启动,用下面三个 docker run 命令也可能达到相同的效果,并且还能通过 - m 参数来限制内存:
docker run --name m0 -idt -p 28017:28017 bolingcavalry/ubuntu16-mongodb349:0.0.1 /bin/bash -c ''mongod --replSet replset0''
docker run --name m1 -idt bolingcavalry/ubuntu16-mongodb349:0.0.1 /bin/bash -c ''mongod --replSet replset0''
docker run --name m2 -idt bolingcavalry/ubuntu16-mongodb349:0.0.1 /bin/bash -c ''mongod --replSet replset0''取得三个容器的 IP
执行以下命令可以得到 hosts 文件信息,里面有容器 IP:
docker exec m1 cat /etc/hosts得到结果如下图所示,红框中的 172.18.0.4 就是容器的 IP:
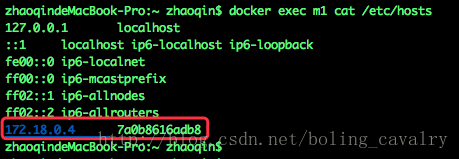
用上述方法可以得到三个容器的 IP:
| 容器名 | ip | 备注 |
|---|---|---|
| m0 | 172.18.0.3 | Primary |
| m1 | 172.18.0.4 | Secondary1 |
| m2 | 172.18.0.2 | Secondary2 |
配置副本集
- 执行 docker exec -it m0 /bin/bash 进入 m0 容器,执行 mongo 进入 mongodb 控制台;
- 执行 use admin, 使用 admin 数据库;
- 执行以下命令,配置机器信息,其中的 use replset0 是启动 mongodb 时候的–replSet 参数,定义副本集的 id:
config = { _id:"replset0", members:[{_id:0,host:"172.18.0.3:27017"},{_id:1,host:"172.18.0.4:27017"},{_id:2,host:"172.18.0.2:27017"}]}控制台输出如下:
> config = { _id:"replset0", members:[{_id:0,host:"172.18.0.3:27017"},{_id:1,host:"172.18.0.4:27017"},{_id:2,host:"172.18.0.2:27017"}]}
{
"_id" : "replset0",
"members" : [
{
"_id" : 0,
"host" : "172.18.0.3:27017"
},
{
"_id" : 1,
"host" : "172.18.0.4:27017"
},
{
"_id" : 2,
"host" : "172.18.0.2:27017"
}
]
}可见三个机器都已经加入集群;
4. 执行 rs.initiate(config) 初始化配置;
5. 执行 rs.status() 查看状态,得到输出如下:
replset0:OTHER> rs.status()
{
"set" : "replset0",
"date" : ISODate("2017-10-08T02:36:19.839Z"),
"myState" : 1,
"term" : NumberLong(1),
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1507430170, 1),
"t" : NumberLong(1)
},
"appliedOpTime" : {
"ts" : Timestamp(1507430170, 1),
"t" : NumberLong(1)
},
"durableOpTime" : {
"ts" : Timestamp(1507430170, 1),
"t" : NumberLong(1)
}
},
"members" : [
{
"_id" : 0,
"name" : "172.18.0.3:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 666,
"optime" : {
"ts" : Timestamp(1507430170, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2017-10-08T02:36:10Z"),
"electionTime" : Timestamp(1507429929, 1),
"electionDate" : ISODate("2017-10-08T02:32:09Z"),
"configVersion" : 1,
"self" : true
},
{
"_id" : 1,
"name" : "172.18.0.4:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 262,
"optime" : {
"ts" : Timestamp(1507430170, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1507430170, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2017-10-08T02:36:10Z"),
"optimeDurableDate" : ISODate("2017-10-08T02:36:10Z"),
"lastHeartbeat" : ISODate("2017-10-08T02:36:19.373Z"),
"lastHeartbeatRecv" : ISODate("2017-10-08T02:36:18.275Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "172.18.0.3:27017",
"configVersion" : 1
},
{
"_id" : 2,
"name" : "172.18.0.2:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 262,
"optime" : {
"ts" : Timestamp(1507430170, 1),
"t" : NumberLong(1)
},
"optimeDurable" : {
"ts" : Timestamp(1507430170, 1),
"t" : NumberLong(1)
},
"optimeDate" : ISODate("2017-10-08T02:36:10Z"),
"optimeDurableDate" : ISODate("2017-10-08T02:36:10Z"),
"lastHeartbeat" : ISODate("2017-10-08T02:36:19.373Z"),
"lastHeartbeatRecv" : ISODate("2017-10-08T02:36:18.274Z"),
"pingMs" : NumberLong(0),
"syncingTo" : "172.18.0.3:27017",
"configVersion" : 1
}
],
"ok" : 1
}可以看到三个容器都已经加入集群,并且 m0 是 Primary;
验证同步
- 在 m0 的 mongodb 控制台执行以下命令,创建数据库 school 并往集合 student 中新增三条记录:
use school
db.student.insert({
name:"Tom", age:16})
db.student.insert({
name:"Jerry", age:15})
db.student.insert({
name:"Mary", age:9})- 进入 m1 容器,执行 mongo 进入 mongodb 的控制台,执行以下命令查看 school 数据库的记录:
use school
db.student.find()控制台直接返回以下错误:
replset0:SECONDARY> db.student.find()
Error: error: {
"ok" : 0,
"errmsg" : "not master and slaveOk=false",
"code" : 13435,
"codeName" : "NotMasterNoSlaveOk"
}发生上述错误是因为 mongodb 默认读写都是在 Primary 上进行的,副本节点不允许读写,可以使用如下命令来允许副本读:
db.getMongo().setSlaveOk()这时候再执行查询,如下:
replset0:SECONDARY> db.student.find()
{ "_id" : ObjectId("59d98fde9740291fac4998fb"), "name" : "Tom", "age" : 16 }
{ "_id" : ObjectId("59d98fe69740291fac4998fc"), "name" : "Jerry", "age" : 15 }
{ "_id" : ObjectId("59d98fed9740291fac4998fd"), "name" : "Mary", "age" : 9 }现在读操作就成功了;
3. 在 m1 上尝试新增一条记录会:
replset0:SECONDARY> db.student.insert({name:"Mike", age:18})
WriteResult({ "writeError" : { "code" : 10107, "errmsg" : "not master" } })新增失败了,因为 m1 不是 Primary,不允许写入;
4. 在 m2 上也执行命令 db.getMongo ().setSlaveOk (),使得 m2 也能读数据;
验证故障转移
副本集模式下,如果 Primary 不可用,整个集群将会选举出新的 Primary 来继续对外提供读写服务,一起来验证一下 m0 不可用的时候的状况:
1. 打开一个终端执行 docker stop m0 停掉 m0 容器;
2. 执行 docker logs -f m1 查看 m1 的标准输出信息,如下图:

日志中显示 m2 现在是 Primary 了;
3. 进入 m2 容器,执行 mongo 进入 mongodb 控制台,新增一条记录:
replset0:SECONDARY> db.student.insert({name:"John", age:10})
WriteResult({ "nInserted" : 1 })如上所示,可以成功;
4. 进入 m1 容器,执行 mongo 进入 mongodb 控制台,查询记录发现新增的数据已经同步过来,但是在 m1 上新增记录依旧失败,如下所示:
replset0:SECONDARY> db.student.find()
{ "_id" : ObjectId("59d98fde9740291fac4998fb"), "name" : "Tom", "age" : 16 }
{ "_id" : ObjectId("59d98fe69740291fac4998fc"), "name" : "Jerry", "age" : 15 }
{ "_id" : ObjectId("59d98fed9740291fac4998fd"), "name" : "Mary", "age" : 9 }
{ "_id" : ObjectId("59d991802c44ff654953dc24"), "name" : "John", "age" : 10 }
replset0:SECONDARY> db.student.insert({name:"Mike", age:18})
WriteResult({ "writeError" : { "code" : 10107, "errmsg" : "not master" } })新增失败,说明 m1 依然是 secondary 身份;
5. 在 m1 或者 m2 的 mongodb 控制台执行 r s.status () 命令,可以看到如下信息:
replset0:SECONDARY> rs.status()
{
"set" : "replset0",
"date" : ISODate("2017-10-08T08:26:11.219Z"),
"myState" : 2,
"term" : NumberLong(2),
"syncingTo" : "172.18.0.2:27017",
"heartbeatIntervalMillis" : NumberLong(2000),
"optimes" : {
"lastCommittedOpTime" : {
"ts" : Timestamp(1507451161, 1),
"t" : NumberLong(2)
},
"appliedOpTime" : {
"ts" : Timestamp(1507451161, 1),
"t" : NumberLong(2)
},
"durableOpTime" : {
"ts" : Timestamp(1507451161, 1),
"t" : NumberLong(2)
}
},
"members" : [
{
"_id" : 0,
"name" : "172.18.0.3:27017",
"health" : 0,
"state" : 8,
"stateStr" : "(not reachable/healthy)",
"uptime" : 0,
"optime" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"optimeDurable" : {
"ts" : Timestamp(0, 0),
"t" : NumberLong(-1)
},
"optimeDate" : ISODate("1970-01-01T00:00:00Z"),
"optimeDurableDate" : ISODate("1970-01-01T00:00:00Z"),
"lastHeartbeat" : ISODate("2017-10-08T08:26:07.898Z"),
"lastHeartbeatRecv" : ISODate("2017-10-08T02:44:51.730Z"),
"pingMs" : NumberLong(0),
"lastHeartbeatMessage" : "No route to host",
"configVersion" : -1
},
{
"_id" : 1,
"name" : "172.18.0.4:27017",
"health" : 1,
"state" : 2,
"stateStr" : "SECONDARY",
"uptime" : 21658,
"optime" : {
"ts" : Timestamp(1507451161, 1),
"t" : NumberLong(2)
},
"optimeDate" : ISODate("2017-10-08T08:26:01Z"),
"syncingTo" : "172.18.0.2:27017",
"configVersion" : 1,
"self" : true
},
{
"_id" : 2,
"name" : "172.18.0.2:27017",
"health" : 1,
"state" : 1,
"stateStr" : "PRIMARY",
"uptime" : 21251,
"optime" : {
"ts" : Timestamp(1507451161, 1),
"t" : NumberLong(2)
},
"optimeDurable" : {
"ts" : Timestamp(1507451161, 1),
"t" : NumberLong(2)
},
"optimeDate" : ISODate("2017-10-08T08:26:01Z"),
"optimeDurableDate" : ISODate("2017-10-08T08:26:01Z"),
"lastHeartbeat" : ISODate("2017-10-08T08:26:10.063Z"),
"lastHeartbeatRecv" : ISODate("2017-10-08T08:26:09.725Z"),
"pingMs" : NumberLong(0),
"electionTime" : Timestamp(1507430703, 1),
"electionDate" : ISODate("2017-10-08T02:45:03Z"),
"configVersion" : 1
}
],
"ok" : 1
}如上所示,m0 节点的配置信息虽然还在,但是 stateStr 属性已经变为 not reachable/healthy,而 m2 的已经成为了 Primary;
至此,Docker 下的 mongodb 副本集实战就完成了,这里依然留下了一个小问题:对于调用 mongodb 服务的应用来说,应该怎么连接 mongodb 呢?一开始直连 m0,等到出了问题再手工切换到 m2 么?还是有自动切换的方法?之后的文章中我们再一起实战吧。
本文分享 CSDN - 程序员欣宸。
如有侵权,请联系 support@oschina.cn 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。

elasticsearch shard 和 replica
(1)index包含多个shard
(2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
(3)增减节点时,shard会自动在nodes中负载均衡
(4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
(7)primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
通过以下方式可以在创建索引时指定 primary shard 和 replica 的数量。
PUT /test_index
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
集群状态变化:
假设有3个节点,9个shard (3个primary shard,每个 primary shard 有 2 个 replica shard),具体分配如下表,假设 Node1 为 master
| Node1 | Node2 | Node3 |
| P0, R1-1, R2-1 | P1, R0-1, R2-2 | P2, R1-2, R0-2 |
1. 如果 Node1 宕机,此时集群状态为 red, 集群会自动选举一个节点为新的 master (假设为 Node2)
2. 新的 master 将 P0-1 这个 replica shard 升级成 primary shard, 此时 集群状态为 yellow
3. 重新启动 Node1 节点, 会自动更新数据,此时集群状态为 green。

ElasticSearch 基础分布式架构+shard+replica
目录
1、Elasticsearch对复杂分布式机制的透明隐藏特性
2、Elasticsearch的垂直扩容与水平扩容
3、增减或减少节点时的数据rebalance
4、master节点
5、节点对等的分布式架构
6、shard&replica机制再次梳理
7、单node环境下创建index是什么样子的
--------------------------------------------------------------------------------------------------------------------
1、Elasticsearch对复杂分布式机制的透明隐藏特性
Elasticsearch是一套分布式的系统,分布式是为了应对大数据量
隐藏了复杂的分布式机制
分片机制(我们之前随随便便就将一些document插入到es集群中去了,我们有没有care过数据怎么进行分片的,数据到哪个shard中去)
cluster discovery(集群发现机制,我们之前在做那个集群status从yellow转green的实验里,直接启动了第二个es进程,那个进程作为一个node自动就发现了集群,并且加入了进去,还接受了部分数据,replica shard)
shard负载均衡(举例,假设现在有3个节点,总共有25个shard要分配到3个节点上去,es会自动进行均匀分配,以保持每个节点的均衡的读写负载请求)
shard副本,请求路由,集群扩容,shard重分配
--------------------------------------------------------------------------------------------------------------------
2、Elasticsearch的垂直扩容与水平扩容
垂直扩容:采购更强大的服务器,成本非常高昂,而且会有瓶颈,假设世界上最强大的服务器容量就是10T,但是当你的总数据量达到5000T的时候,你要采购多少台最强大的服务器啊
水平扩容:业界经常采用的方案,采购越来越多的普通服务器,性能比较一般,但是很多普通服务器组织在一起,就能构成强大的计算和存储能力
普通服务器:1T,1万,100万
强大服务器:10T,50万,500万
扩容对应用程序的透明性
--------------------------------------------------------------------------------------------------------------------
3、增减或减少节点时的数据rebalance
保持负载均衡
--------------------------------------------------------------------------------------------------------------------
4、master节点
(1)创建或删除索引
(2)增加或删除节点
--------------------------------------------------------------------------------------------------------------------
5、节点平等的分布式架构
(1)节点对等,每个节点都能接收所有的请求
(2)自动请求路由
(3)响应收集\

------------------------------------------------------------------------------------------------
6、shard&replica机制再次梳理
(1)index包含多个shard
(2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
(3)增减节点时,shard会自动在nodes中负载均衡
(4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
(7)primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上

------------------------------------------------------------------------------------------------
7、图解单node环境下创建index是什么样子的
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard
(2)集群status是yellow
(3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}

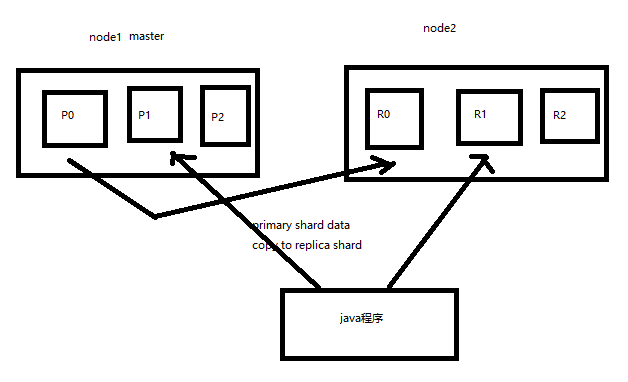
8.2个node环境下replica shard是如何分配的
(1)replica shard分配:3个primary shard,3个replica shard,1 node
(2)primary ---> replica同步
(3)读请求:primary/replica
今天关于搜索引擎的分片和shard和副本的分享就到这里,希望大家有所收获,若想了解更多关于009,elasticsearch--[L10]--shard&replica 机制再次梳理以及单 node 环境中创建 index 图解、Docker 下,实战 mongodb 副本集(Replication)、elasticsearch shard 和 replica、ElasticSearch 基础分布式架构+shard+replica等相关知识,可以在本站进行查询。
本文标签:




