想了解WordPressRESTAPI的基本使用的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于wordpressrestapi教程的相关问题,此外,我们还将为您介绍关于Elasticsea
想了解WordPress REST API的基本使用的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于wordpress rest api教程的相关问题,此外,我们还将为您介绍关于Elasticsearch Java API的基本使用、Envato WordPress 工具包:精明的 WordPress 开发人员必备的工具箱、HTML5中postMessage API的基本使用、kafka api的基本使用的新知识。
本文目录一览:- WordPress REST API的基本使用(wordpress rest api教程)
- Elasticsearch Java API的基本使用
- Envato WordPress 工具包:精明的 WordPress 开发人员必备的工具箱
- HTML5中postMessage API的基本使用
- kafka api的基本使用
")
WordPress REST API的基本使用(wordpress rest api教程)
下面由wordpress/" target="_blank">wordpress教程栏目给大家介绍wordpress rest api的基本使用,希望对需要的朋友有所帮助!

WordPress系统默认开放REST API,也就是说,除了以HTML格式输出内容,
还可以以JSON格式输出文章/用户/评论等数据。
之所以支持JSON数据格式响应,是由于目前各种智能终端设备,如手机/平板/电视/路由器/家电/玩具等,
都要与云端服务器进行数据通信,而终端设备需要的数据,不一定必须经由浏览器解析HTML后呈现给用户。
所以通常使用JSON这种易于编写/阅读/解析的数据格式规范来进行数据通信。
如果你已经部署好WordPress,就可以通过对应的链接得到JSON格式的数据:
链接格式示例:
文章列表
页面列表
用户列表
将示例域名替换为自己的域名,如果页面返回404错误,需要设置WEB代理服务器(Nginx)的重定向规则。
完整的资源API链接,请访问 https://developer.wordpress.org/rest-api/reference/
由此可见,如果网站想为其他设备提供数据接口服务,就可以直接使用,没有开发成本。
如果不期望自己的网站开放REST API,则可以通过安装插件Disable REST API来禁用这个功能。
插件地址: https://wordpress.org/plugins/disable-json-api/
安装启用后,除了已经登陆的管理员,其他用户无权限访问数据。
为了让JSON数据在浏览器里面易于阅读,可以安装相关的扩展:
Chrome :
https://chrome.google.com/webstore/detail/json-viewer/aimiinbnnkboelefkjlenlgimcabobli?utm_source=chrome-ntp-icon
以上就是WordPress REST API的基本使用的详细内容,更多请关注php中文网其它相关文章!

Elasticsearch Java API的基本使用
说明
在明确了ES的基本概念和使用方法后,我们来学习如何使用ES的Java API.
本文假设你已经对ES的基本概念已经有了一个比较全面的认识。
客户端
你可以用Java客户端做很多事情:
- 执行标准的index,get,delete,update,search等操作。
- 在正在运行的集群上执行管理任务。
但是,通过官方文档可以得知,现在存在至少三种Java客户端。
- Transport Client
- Java High Level REST Client
- Java Low Level Rest Client
造成这种混乱的原因是:
-
长久以来,ES并没有官方的Java客户端,并且Java自身是可以简单支持ES的API的,于是就先做成了TransportClient。但是TransportClient的缺点是显而易见的,它没有使用RESTful风格的接口,而是二进制的方式传输数据。
-
之后ES官方推出了Java Low Level REST Client,它支持RESTful,用起来也不错。但是缺点也很明显,因为TransportClient的使用者把代码迁移到Low Level REST Client的工作量比较大。官方文档专门为迁移代码出了一堆文档来提供参考。
-
现在ES官方推出Java High Level REST Client,它是基于Java Low Level REST Client的封装,并且API接收参数和返回值和TransportClient是一样的,使得代码迁移变得容易并且支持了RESTful的风格,兼容了这两种客户端的优点。当然缺点是存在的,就是版本的问题。ES的小版本更新非常频繁,在最理想的情况下,客户端的版本要和ES的版本一致(至少主版本号一致),次版本号不一致的话,基本操作也许可以,但是新API就不支持了。
-
强烈建议ES5及其以后的版本使用Java High Level REST Client。笔者这里使用的是ES5.6.3,下面的文章将基于JDK1.8+Spring Boot+ES5.6.3 Java High Level REST Client+Maven进行示例。
stackoverflow上的问答:
https://stackoverflow.com/questions/47031840/elasticsearchhow-to-choose-java-client/47036028#47036028
详细说明:
https://www.elastic.co/blog/the-elasticsearch-java-high-level-rest-client-is-out
参考资料:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/5.6/java-rest-high.html
Java High Level REST Client 介绍
Java High Level REST Client 是基于Java Low Level REST Client的,每个方法都可以是同步或者异步的。同步方法返回响应对象,而异步方法名以“async”结尾,并需要传入一个监听参数,来确保提醒是否有错误发生。
Java High Level REST Client需要Java1.8版本和ES。并且ES的版本要和客户端版本一致。和TransportClient接收的参数和返回值是一样的。
以下实践均是基于5.6.3的ES集群和Java High Level REST Client的。
Maven 依赖
<dependency>
<groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>5.6.3</version> </dependency> 初始化
//Low Level Client init
RestClient lowLevelRestClient = RestClient.builder(
new HttpHost("localhost", 9200, "http")).build(); //High Level Client init RestHighLevelClient client = new RestHighLevelClient(lowLevelRestClient); High Level REST Client的初始化是依赖Low Level客户端的
Index API
类似HTTP请求,Index API包括index request和index response
Index request的构造
构造一条index request的例子:
IndexRequest request = new IndexRequest(
"posts", //index name
"doc", // type "1"); // doc id String jsonString = "{" + "\"user\":\"kimchy\"," + "\"postDate\":\"2013-01-30\"," + "\"message\":\"trying out Elasticsearch\"" + "}"; request.source(jsonString, XContentType.JSON); 注意到这里是使用的String 类型。
另一种构造的方法:
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("user", "kimchy"); jsonMap.put("postDate", new Date()); jsonMap.put("message", "trying out Elasticsearch"); IndexRequest indexRequest = new IndexRequest("posts", "doc", "1") .source(jsonMap); //Map会自动转成JSON 除了String和Map ,XContentBuilder 类型也是可以的:
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.field("user", "kimchy");
builder.field("postDate", new Date()); builder.field("message", "trying out Elasticsearch"); } builder.endObject(); IndexRequest indexRequest = new IndexRequest("posts", "doc", "1") .source(builder); 更直接一点的,在实例化index request对象时,可以直接给出键值对:
IndexRequest indexRequest = new IndexRequest("posts", "doc", "1")
.source("user", "kimchy", "postDate", new Date(), "message", "trying out Elasticsearch"); index response的获取
同步执行
IndexResponse indexResponse = client.index(request);
异步执行
client.indexAsync(request, new ActionListener<IndexResponse>() {
@Override
public void onResponse(IndexResponse indexResponse) { } @Override public void onFailure(Exception e) { } }); 需要注意的是,异步执行的方法名以Async结尾,并且多了一个Listener参数,并且需要重写回调方法。
在kibana控制台查询得到数据:
{
"_index": "posts",
"_type": "doc",
"_id": "1", "_version": 1, "found": true, "_source": { "user": "kimchy", "postDate": "2017-11-01T05:48:26.648Z", "message": "trying out Elasticsearch" } } index request中的数据已经成功入库。
index response的返回值操作
client.index()方法返回值类型为IndexResponse,我们可以用它来进行如下操作:
String index = indexResponse.getIndex(); //index名称,类型等信息
String type = indexResponse.getType();
String id = indexResponse.getId();
long version = indexResponse.getVersion();
if (indexResponse.getResult() == DocWriteResponse.Result.CREATED) { } else if (indexResponse.getResult() == DocWriteResponse.Result.UPDATED) { } ShardInfo shardInfo = indexResponse.getShardInfo(); //对分片使用的判断 if (shardInfo.getTotal() != shardInfo.getSuccessful()) { } if (shardInfo.getFailed() > 0) { for (ReplicationResponse.ShardInfo.Failure failure : shardInfo.getFailures()) { String reason = failure.reason(); } } 对version冲突的判断:
IndexRequest request = new IndexRequest("posts", "doc", "1")
.source("field", "value") .version(1); try { IndexResponse response = client.index(request); } catch(ElasticsearchException e) { if (e.status() == RestStatus.CONFLICT) { } } 对index动作的判断:
IndexRequest request = new IndexRequest("posts", "doc", "1")
.source("field", "value") .opType(DocWriteRequest.OpType.CREATE);//create or update try { IndexResponse response = client.index(request); } catch(ElasticsearchException e) { if (e.status() == RestStatus.CONFLICT) { } } GET API
GET request
GetRequest getRequest = new GetRequest(
"posts",//index name
"doc", //type "1"); //id GET response
同步方法:
GetResponse getResponse = client.get(getRequest);
异步方法:
client.getAsync(request, new ActionListener<GetResponse>() {
@Override
public void onResponse(GetResponse getResponse) { } @Override public void onFailure(Exception e) { } }); 对返回对象的操作:
String index = getResponse.getIndex();
String type = getResponse.getType();
String id = getResponse.getId();
if (getResponse.isExists()) {
long version = getResponse.getVersion();
String sourceAsString = getResponse.getSourceAsString(); Map<String, Object> sourceAsMap = getResponse.getSourceAsMap(); byte[] sourceAsBytes = getResponse.getSourceAsBytes(); } else { //TODO } 异常处理:
GetRequest request = new GetRequest("does_not_exist", "doc", "1");
try { GetResponse getResponse = client.get(request); } catch (ElasticsearchException e) { if (e.status() == RestStatus.NOT_FOUND) { } if (e.status() == RestStatus.CONFLICT) { } } DELETE API
与Index API和 GET API及其相似
DELETE request
DeleteRequest request = new DeleteRequest(
"posts",
"doc",
"1");
DELETE response
同步:
DeleteResponse deleteResponse = client.delete(request);
异步:
client.deleteAsync(request, new ActionListener<DeleteResponse>() {
@Override
public void onResponse(DeleteResponse deleteResponse) { } @Override public void onFailure(Exception e) { } }); Update API
update request
UpdateRequest updateRequest = new UpdateRequest(
"posts",
"doc",
"1");
update脚本:
在之前我们介绍了如何使用简单的脚本来更新数据
POST /posts/doc/1/_update?pretty
{
"script" : "ctx._source.age += 5"
}
也可以写成:
POST /posts/doc/1/_update?pretty
{
"script" : {
"lang":"painless",
"source":"ctx._source.age += 5" } } 对应代码:
UpdateRequest updateRequest = new UpdateRequest("posts", "doc", "1");
Map<String, Object> parameters = new HashMap<>(); parameters.put("age", 4); Script inline = new Script(ScriptType.INLINE, "painless", "ctx._source.age += params.age", parameters); updateRequest.script(inline); try { UpdateResponse updateResponse = client.update(updateRequest); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } 使用部分文档更新
- String
String jsonString = "{" +
"\"updated\":\"2017-01-02\"," +
"\"reason\":\"easy update\"" +
"}"; updateRequest.doc(jsonString, XContentType.JSON); try { client.update(updateRequest); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } 2.Map
Map<String, Object> jsonMap = new HashMap<>();
jsonMap.put("updated", new Date()); jsonMap.put("reason", "dailys update"); UpdateRequest updateRequest = new UpdateRequest("posts", "doc", "1").doc(jsonMap); try { client.update(updateRequest); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } 3.XContentBuilder
try {
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
builder.field("updated", new Date());
System.out.println(new Date()); builder.field("reason", "daily update"); } builder.endObject(); UpdateRequest request = new UpdateRequest("posts", "doc", "1") .doc(builder); client.update(request); } catch (IOException e) { // TODO: handle exception } 4.键值对
try {
UpdateRequest request = new UpdateRequest("posts", "doc", "1") .doc("updated", new Date(), "reason", "daily updatesss"); client.update(request); } catch (IOException e) { // TODO: handle exception } upsert
如果文档不存在,可以使用upsert来生成这个文档。
String jsonString = "{\"created\":\"2017-01-01\"}";
request.upsert(jsonString, XContentType.JSON);
同样地,upsert可以接Map,Xcontent,键值对参数。
update response
同样地,update response可以是同步的,也可以是异步的
同步执行:
UpdateResponse updateResponse = client.update(request);
异步执行:
client.updateAsync(request, new ActionListener<UpdateResponse>() {
@Override
public void onResponse(UpdateResponse updateResponse) { } @Override public void onFailure(Exception e) { } }); 与其他response类似,update response返回对象可以进行各种判断操作,这里不再赘述。
Bulk API
Bulk request
之前的文档说明过,bulk接口是批量index/update/delete操作
在API中,只需要一个bulk request就可以完成一批请求。
BulkRequest request = new BulkRequest();
request.add(new IndexRequest("posts", "doc", "1") .source(XContentType.JSON,"field", "foo")); request.add(new IndexRequest("posts", "doc", "2") .source(XContentType.JSON,"field", "bar")); request.add(new IndexRequest("posts", "doc", "3") .source(XContentType.JSON,"field", "baz")); - 注意,Bulk API只接受JSON和SMILE格式.其他格式的数据将会报错。
- 不同类型的request可以写在同一个bulk request里。
BulkRequest request = new BulkRequest();
request.add(new DeleteRequest("posts", "doc", "3")); request.add(new UpdateRequest("posts", "doc", "2") .doc(XContentType.JSON,"other", "test")); request.add(new IndexRequest("posts", "doc", "4") .source(XContentType.JSON,"field", "baz")); bulk response
同步执行:
BulkResponse bulkResponse = client.bulk(request);
异步执行:
client.bulkAsync(request, new ActionListener<BulkResponse>() {
@Override
public void onResponse(BulkResponse bulkResponse) { } @Override public void onFailure(Exception e) { } }); 对response的处理与其他类型的response十分类似,在这不再赘述。
bulk processor
BulkProcessor 简化bulk API的使用,并且使整个批量操作透明化。
BulkProcessor 的执行需要三部分组成:
- RestHighLevelClient :执行bulk请求并拿到响应对象。
- BulkProcessor.Listener:在执行bulk request之前、之后和当bulk response发生错误时调用。
- ThreadPool:bulk request在这个线程池中执行操作,这使得每个请求不会被挡住,在其他请求正在执行时,也可以接收新的请求。
示例代码:
Settings settings = Settings.EMPTY;
ThreadPool threadPool = new ThreadPool(settings); //构建新的线程池
BulkProcessor.Listener listener = new BulkProcessor.Listener() {
//构建bulk listener
@Override public void beforeBulk(long executionId, BulkRequest request) { //重写beforeBulk,在每次bulk request发出前执行,在这个方法里面可以知道在本次批量操作中有多少操作数 int numberOfActions = request.numberOfActions(); logger.debug("Executing bulk [{}] with {} requests", executionId, numberOfActions); } @Override public void afterBulk(long executionId, BulkRequest request, BulkResponse response) { //重写afterBulk方法,每次批量请求结束后执行,可以在这里知道是否有错误发生。 if (response.hasFailures()) { logger.warn("Bulk [{}] executed with failures", executionId); } else { logger.debug("Bulk [{}] completed in {} milliseconds", executionId, response.getTook().getMillis()); } } @Override public void afterBulk(long executionId, BulkRequest request, Throwable failure) { //重写方法,如果发生错误就会调用。 logger.error("Failed to execute bulk", failure); } }; BulkProcessor.Builder builder = new BulkProcessor.Builder(client::bulkAsync, listener, threadPool);//使用builder做批量操作的控制 BulkProcessor bulkProcessor = builder.build(); //在这里调用build()方法构造bulkProcessor,在底层实际上是用了bulk的异步操作 builder.setBulkActions(500); //执行多少次动作后刷新bulk.默认1000,-1禁用 builder.setBulkSize(new ByteSizeValue(1L, ByteSizeUnit.MB));//执行的动作大小超过多少时,刷新bulk。默认5M,-1禁用 builder.setConcurrentRequests(0);//最多允许多少请求同时执行。默认是1,0是只允许一个。 builder.setFlushInterval(TimeValue.timeValueSeconds(10L));//设置刷新bulk的时间间隔。默认是不刷新的。 builder.setBackoffPolicy(BackoffPolicy.constantBackoff(TimeValue.timeValueSeconds(1L), 3)); //设置补偿机制参数。由于资源限制(比如线程池满),批量操作可能会失败,在这定义批量操作的重试次数。 //新建三个 index 请求 IndexRequest one = new IndexRequest("posts", "doc", "1"). source(XContentType.JSON, "title", "In which order are my Elasticsearch queries executed?"); IndexRequest two = new IndexRequest("posts", "doc", "2") .source(XContentType.JSON, "title", "Current status and upcoming changes in Elasticsearch"); IndexRequest three = new IndexRequest("posts", "doc", "3") .source(XContentType.JSON, "title", "The Future of Federated Search in Elasticsearch"); //新的三条index请求加入到上面配置好的bulkProcessor里面。 bulkProcessor.add(one); bulkProcessor.add(two); bulkProcessor.add(three); // add many request here. //bulkProcess必须被关闭才能使上面添加的操作生效 bulkProcessor.close(); //立即关闭 //关闭bulkProcess的两种方法: try { //2.调用awaitClose. //简单来说,就是在规定的时间内,是否所有批量操作完成。全部完成,返回true,未完成返//回false boolean terminated = bulkProcessor.awaitClose(30L, TimeUnit.SECONDS); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } Search API
Search request
Search API提供了对文档的查询和聚合的查询。
它的基本形式:
SearchRequest searchRequest = new SearchRequest(); //构造search request .在这里无参,查询全部索引
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//大多数查询参数要写在searchSourceBuilder里
searchSourceBuilder.query(QueryBuilders.matchAllQuery());//增加match_all的条件。 SearchRequest searchRequest = new SearchRequest("posts"); //指定posts索引
searchRequest.types("doc"); //指定doc类型 使用SearchSourceBuilder
大多数的查询控制都可以使用SearchSourceBuilder实现。
举一个简单例子:
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //构造一个默认配置的对象
sourceBuilder.query(QueryBuilders.termQuery("user", "kimchy")); //设置查询 sourceBuilder.from(0); //设置从哪里开始 sourceBuilder.size(5); //每页5条 sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); //设置超时时间 配置好searchSourceBuilder后,将它传入searchRequest里:
SearchRequest searchRequest = new SearchRequest();
searchRequest.source(sourceBuilder);
建立查询
在上面的例子,我们注意到,sourceBuilder构造查询条件时,使用QueryBuilders对象.
在所有ES查询中,它存在于所有ES支持的查询类型中。
使用它的构造体来创建:
MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("user", "kimchy");
这里的代码相当于:
"query": { "match": { "user": "kimchy" } }
相关设置:
matchQueryBuilder.fuzziness(Fuzziness.AUTO); //是否模糊查询
matchQueryBuilder.prefixLength(3); //设置前缀长度
matchQueryBuilder.maxExpansions(10);//设置最大膨胀系数 ??? QueryBuilder还可以使用 QueryBuilders工具类来创造,编程体验比较顺畅:
QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("user", "kimchy")
.fuzziness(Fuzziness.AUTO)
.prefixLength(3)
.maxExpansions(10);
无论QueryBuilder对象是如何创建的,都要将它传入SearchSourceBuilder里面:
searchSourceBuilder.query(matchQueryBuilder);
在之前导入的account数据中,使用match的示例代码:
GET /bank/_search?pretty
{
"query": {
"match": {
"firstname": "Virginia"
}
}
}
JAVA:
@Test
public void test2(){ RestClient lowLevelRestClient = RestClient.builder( new HttpHost("172.16.73.50", 9200, "http")).build(); RestHighLevelClient client = new RestHighLevelClient(lowLevelRestClient); SearchRequest searchRequest = new SearchRequest("bank"); searchRequest.types("account"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); MatchQueryBuilder mqb = QueryBuilders.matchQuery("firstname", "Virginia"); searchSourceBuilder.query(mqb); searchRequest.source(searchSourceBuilder); try { SearchResponse searchResponse = client.search(searchRequest); System.out.println(searchResponse.toString()); } catch (IOException e) { e.printStackTrace(); } } 排序
SearchSourceBuilder可以添加一种或多种SortBuilder。
有四种特殊的排序实现:
- field
- score
- GeoDistance
- scriptSortBuilder
sourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC)); //按照score倒序排列
sourceBuilder.sort(new FieldSortBuilder("_uid").order(SortOrder.ASC)); //并且按照id正序排列 过滤
默认情况下,searchRequest返回文档内容,与REST API一样,这里你可以重写search行为。例如,你可以完全关闭"_source"检索。
sourceBuilder.fetchSource(false);
该方法还接受一个或多个通配符模式的数组,以更细粒度地控制包含或排除哪些字段。
String[] includeFields = new String[] {"title", "user", "innerObject.*"}; String[] excludeFields = new String[] {"_type"}; sourceBuilder.fetchSource(includeFields, excludeFields); 聚合请求
通过配置适当的 AggregationBuilder ,再将它传入SearchSourceBuilder里,就可以完成聚合请求了。
之前的文档里面,我们通过下面这条命令,导入了一千条account信息:
curl -H "Content-Type: application/json" -XPOST ''localhost:9200/bank/account/_bulk?pretty&refresh'' --data-binary "@accounts.json"
随后,我们介绍了如何通过聚合请求进行分组:
GET /bank/_search?pretty
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword" } } } } 我们将这一千条数据根据state字段分组,得到响应:
{
"took": 2,
"timed_out": false,
"_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 999, "max_score": 0, "hits": [] }, "aggregations": { "group_by_state": { "doc_count_error_upper_bound": 20, "sum_other_doc_count": 770, "buckets": [ { "key": "ID", "doc_count": 27 }, { "key": "TX", "doc_count": 27 }, { "key": "AL", "doc_count": 25 }, { "key": "MD", "doc_count": 25 }, { "key": "TN", "doc_count": 23 }, { "key": "MA", "doc_count": 21 }, { "key": "NC", "doc_count": 21 }, { "key": "ND", "doc_count": 21 }, { "key": "MO", "doc_count": 20 }, { "key": "AK", "doc_count": 19 } ] } } } Java实现:
@Test
public void test2(){ RestClient lowLevelRestClient = RestClient.builder( new HttpHost("172.16.73.50", 9200, "http")).build(); RestHighLevelClient client = new RestHighLevelClient(lowLevelRestClient); SearchRequest searchRequest = new SearchRequest("bank"); searchRequest.types("account"); TermsAggregationBuilder aggregation = AggregationBuilders.terms("group_by_state") .field("state.keyword"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.aggregation(aggregation); searchSourceBuilder.size(0); searchRequest.source(searchSourceBuilder); try { SearchResponse searchResponse = client.search(searchRequest); System.out.println(searchResponse.toString()); } catch (IOException e) { e.printStackTrace(); } } 输出:
{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0},"hits":{"total":999,"max_score":0.0,"hits":[]},"aggregations":{"sterms#group_by_state":{"doc_count_error_upper_bound":20,"sum_other_doc_count":770,"buckets":[{"key":"ID","doc_count":27},{"key":"TX","doc_count":27},{"key":"AL","doc_count":25},{"key":"MD","doc_count":25},{"key":"TN","doc_count":23},{"key":"MA","doc_count":21},{"key":"NC","doc_count":21},{"key":"ND","doc_count":21},{"key":"MO","doc_count":20},{"key":"AK","doc_count":19}]}}} 同步执行
SearchResponse searchResponse = client.search(searchRequest);
异步执行
client.searchAsync(searchRequest, new ActionListener<SearchResponse>() {
@Override
public void onResponse(SearchResponse searchResponse) { } @Override public void onFailure(Exception e) { } }); Search response
Search response返回对象与其在API里的一样,返回一些元数据和文档数据。
首先,返回对象里的数据十分重要,因为这是查询的返回结果、使用分片情况、文档数据,HTTP状态码等
RestStatus status = searchResponse.status();
TimeValue took = searchResponse.getTook();
Boolean terminatedEarly = searchResponse.isTerminatedEarly();
boolean timedOut = searchResponse.isTimedOut();
其次,返回对象里面包含关于分片的信息和分片失败的处理:
int totalShards = searchResponse.getTotalShards();
int successfulShards = searchResponse.getSuccessfulShards();
int failedShards = searchResponse.getFailedShards();
for (ShardSearchFailure failure : searchResponse.getShardFailures()) {
// failures should be handled here } 取回searchHit
为了取回文档数据,我们要从search response的返回对象里先得到searchHit对象。
SearchHits hits = searchResponse.getHits();
取回文档数据:
@Test
public void test2(){ RestClient lowLevelRestClient = RestClient.builder( new HttpHost("172.16.73.50", 9200, "http")).build(); RestHighLevelClient client = new RestHighLevelClient(lowLevelRestClient); SearchRequest searchRequest = new SearchRequest("bank"); searchRequest.types("account"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchRequest.source(searchSourceBuilder); try { SearchResponse searchResponse = client.search(searchRequest); SearchHits searchHits = searchResponse.getHits(); SearchHit[] searchHit = searchHits.getHits(); for (SearchHit hit : searchHit) { System.out.println(hit.getSourceAsString()); } } catch (IOException e) { e.printStackTrace(); } } 根据需要,还可以转换成其他数据类型:
String sourceAsString = hit.getSourceAsString();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String documentTitle = (String) sourceAsMap.get("title"); List<Object> users = (List<Object>) sourceAsMap.get("user"); Map<String, Object> innerObject = (Map<String, Object>) sourceAsMap.get("innerObject"); 取回聚合数据
聚合数据可以通过SearchResponse返回对象,取到它的根节点,然后再根据名称取到聚合数据。
GET /bank/_search?pretty
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword" } } } } 响应:
{
"took": 2,
"timed_out": false,
"_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 999, "max_score": 0, "hits": [] }, "aggregations": { "group_by_state": { "doc_count_error_upper_bound": 20, "sum_other_doc_count": 770, "buckets": [ { "key": "ID", "doc_count": 27 }, { "key": "TX", "doc_count": 27 }, { "key": "AL", "doc_count": 25 }, { "key": "MD", "doc_count": 25 }, { "key": "TN", "doc_count": 23 }, { "key": "MA", "doc_count": 21 }, { "key": "NC", "doc_count": 21 }, { "key": "ND", "doc_count": 21 }, { "key": "MO", "doc_count": 20 }, { "key": "AK", "doc_count": 19 } ] } } } Java实现:
@Test
public void test2(){ RestClient lowLevelRestClient = RestClient.builder( new HttpHost("172.16.73.50", 9200, "http")).build(); RestHighLevelClient client = new RestHighLevelClient(lowLevelRestClient); SearchRequest searchRequest = new SearchRequest("bank"); searchRequest.types("account"); TermsAggregationBuilder aggregation = AggregationBuilders.terms("group_by_state") .field("state.keyword"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.aggregation(aggregation); searchSourceBuilder.size(0); searchRequest.source(searchSourceBuilder); try { SearchResponse searchResponse = client.search(searchRequest); Aggregations aggs = searchResponse.getAggregations(); Terms byStateAggs = aggs.get("group_by_state"); Terms.Bucket b = byStateAggs.getBucketByKey("ID"); //只取key是ID的bucket System.out.println(b.getKeyAsString()+","+b.getDocCount()); System.out.println("!!!"); List<? extends Bucket> aggList = byStateAggs.getBuckets();//获取bucket数组里所有数据 for (Bucket bucket : aggList) { System.out.println("key:"+bucket.getKeyAsString()+",docCount:"+bucket.getDocCount());; } } catch (IOException e) { e.printStackTrace(); } } Search Scroll API
search scroll API是用于处理search request里面的大量数据的。
- 使用ES做分页查询有两种方法。一是配置search request的from,size参数。二是使用scroll API。搜索结果建议使用scroll API,查询效率高。
为了使用scroll,按照下面给出的步骤执行:
初始化search scroll上下文
带有scroll参数的search请求必须被执行,来初始化scroll session。ES能检测到scroll参数的存在,保证搜索上下文在相应的时间间隔里存活
SearchRequest searchRequest = new SearchRequest("account"); //从 account 索引中查询
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(matchQuery("first", "Virginia")); //match条件 searchSourceBuilder.size(size); //一次取回多少数据 searchRequest.source(searchSourceBuilder); searchRequest.scroll(TimeValue.timeValueMinutes(1L));//设置scroll间隔 SearchResponse searchResponse = client.search(searchRequest); String scrollId = searchResponse.getScrollId(); //取回这条响应的scroll id,在后续的scroll调用中会用到 SearchHit[] hits = searchResponse.getHits().getHits();//得到文档数组 取回所有相关文档
第二步,得到的scroll id 和新的scroll间隔要设置到 SearchScrollRequest里,再调用searchScroll方法。
ES会返回一批带有新scroll id的查询结果。以此类推,新的scroll id可以用于子查询,来得到另一批新数据。这个过程应该在一个循环内,直到没有数据返回为止,这意味着scroll消耗殆尽,所有匹配上的数据都已经取回。
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId); //传入scroll id并设置间隔。
scrollRequest.scroll(TimeValue.timeValueSeconds(30));
SearchResponse searchScrollResponse = client.searchScroll(scrollRequest);//执行scroll搜索
scrollId = searchScrollResponse.getScrollId(); //得到本次scroll id hits = searchScrollResponse.getHits(); 清理 scroll 上下文
使用Clear scroll API来检测到最后一个scroll id 来释放scroll上下文.虽然在scroll过期时,这个清理行为会最终自动触发,但是最好的实践是当scroll session结束时,马上释放它。
可选参数
scrollRequest.scroll(TimeValue.timeValueSeconds(60L)); //设置60S的scroll存活时间
scrollRequest.scroll("60s"); //字符串参数
如果在scrollRequest不设置的话,会以searchRequest.scroll()设置的为准。
同步执行
SearchResponse searchResponse = client.searchScroll(scrollRequest);
异步执行
client.searchScrollAsync(scrollRequest, new ActionListener<SearchResponse>() {
@Override
public void onResponse(SearchResponse searchResponse) { } @Override public void onFailure(Exception e) { } }); - 需要注意的是,search scroll API的请求响应返回值也是一个searchResponse对象。
完整示例
@Test
public void test3(){ RestClient lowLevelRestClient = RestClient.builder( new HttpHost("172.16.73.50", 9200, "http")).build(); RestHighLevelClient client = new RestHighLevelClient(lowLevelRestClient); SearchRequest searchRequest = new SearchRequest("bank"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); MatchAllQueryBuilder mqb = QueryBuilders.matchAllQuery(); searchSourceBuilder.query(mqb); searchSourceBuilder.size(10); searchRequest.source(searchSourceBuilder); searchRequest.scroll(TimeValue.timeValueMinutes(1L)); try { SearchResponse searchResponse = client.search(searchRequest); String scrollId = searchResponse.getScrollId(); SearchHit[] hits = searchResponse.getHits().getHits(); System.out.println("first scroll:"); for (SearchHit searchHit : hits) { System.out.println(searchHit.getSourceAsString()); } Scroll scroll = new Scroll(TimeValue.timeValueMinutes(1L)); System.out.println("loop scroll:"); while(hits != null && hits.length>0){ SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId); scrollRequest.scroll(scroll); searchResponse = client.searchScroll(scrollRequest); scrollId = searchResponse.getScrollId(); hits = searchResponse.getHits().getHits(); for (SearchHit searchHit : hits) { System.out.println(searchHit.getSourceAsString()); } } ClearScrollRequest clearScrollRequest = new ClearScrollRequest(); clearScrollRequest.addScrollId(scrollId); ClearScrollResponse clearScrollResponse = client.clearScroll(clearScrollRequest); boolean succeeded = clearScrollResponse.isSucceeded(); System.out.println("cleared:"+succeeded); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } Info API
Info API 提供一些关于集群、节点相关的信息查询。
request
MainResponse response = client.info();
response
ClusterName clusterName = response.getClusterName();
String clusterUuid = response.getClusterUuid();
String nodeName = response.getNodeName();
Version version = response.getVersion();
Build build = response.getBuild();
@Test
public void test4(){ RestClient lowLevelRestClient = RestClient.builder( new HttpHost("172.16.73.50", 9200, "http")).build(); RestHighLevelClient client = new RestHighLevelClient(lowLevelRestClient); try { MainResponse response = client.info(); ClusterName clusterName = response.getClusterName(); String clusterUuid = response.getClusterUuid(); String nodeName = response.getNodeName(); Version version = response.getVersion(); Build build = response.getBuild(); System.out.println("cluster name:"+clusterName); System.out.println("cluster uuid:"+clusterUuid); System.out.println("node name:"+nodeName); System.out.println("node version:"+version); System.out.println("node name:"+nodeName); System.out.println("build info:"+build); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } 总结
关于Elasticsearch 的 Java High Level REST Client API的基本用法大概就是这些,一些进阶技巧、概念要随时查阅官方文档。
作者:epicGeek
链接:https://www.jianshu.com/p/5cb91ed22956
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。

Envato WordPress 工具包:精明的 WordPress 开发人员必备的工具箱
您是否曾从 themeforest 购买过主题?你做到了吗?伟大的!但即使您购买了优质的 wordpress 主题,安装该主题可能比安装 wordpress.org 的免费主题花费的时间要长一些。然而,envato 的工作人员找到了一种快速、简单的方法,可以直接从 wordpress 仪表板安装您购买的项目!
在“智能 WordPress 开发人员工具箱”系列的这一部分中,我们将介绍 Envato WordPress 工具包,这是一个用于安装和更新从 ThemeForest 购买的主题的“工具包”。
在 ThemeForest 上购买 WordPress 主题并安装的步骤
我一直认为,大多数从 ThemeForest 购买 WordPress 主题的人可以分为两类:为微型企业购买主题的人,以及为网页设计机构工作的人。让我们为每种类型想象一个故事。
沃尔特是他位于新墨西哥州阿尔伯克基的新店“Blue Rock - 手工硬糖”的店主。另一方面,莉迪亚在柏林的一家中型网页设计机构工作。
沃尔特不希望他的生意被困在阿尔伯克基,并决定通过在线销售他的产品来扩大他的领土。 Lydia 刚刚在 Trello 上为一位新客户(一家名为 Madrigal Elektronik 的大公司)获得了一张新卡。
沃尔特是网页设计领域的新手,但莉迪亚知道她要做什么。当 Walt 正在网上搜索并学习 WordPress 时,Lydia 已经开始在 ThemeForest 上寻找新的企业主题。最终,Walt 确信他会使用 WordPress,并在 WordPress 博客中找到了“2015 年 20 个最佳 WooCommerce 主题”的综述。
Lydia 已使用其代理机构的帐户登录 ThemeForest,将名为 Cartel 的现代专业多功能主题添加到她的购物车中,而 Walt 在决定使用名为 Combo 的外观不错的 WooCommerce 主题后首次注册到 ThemeForest 。他们都通过 PayPal 付款,但沃尔特通过他的附属链接为博客所有者赢得了丰厚的分成。付款后,他们都下载了各自的主题。
Lydia 知道该怎么做,但 Walt 需要检查主题文档才能在他的新 WordPress 网站上安装主题。他仔细阅读说明,在 WordPress 管理面板中上传主题的 ZIP 文件,而 Lydia 则快速解压 ZIP 文件,并通过 FTP 将文件上传到 wp-content/themes 文件夹。 (实际上,Lydia 等待的时间更长,因为她的多功能主题有 600 多个文件,总计达 70 兆字节,而 Walt 上传的单个 ZIP 文件有 4 兆字节。)
上传完成后,Lydia 导航到管理面板中的“外观”页面并激活她的新主题。 Walt 在上传后已经激活了主题,并且已经对他的新主题永无休止的选项面板感到困惑。
将流程减半:Envato WordPress 工具包简介
除了所有这些对传奇电视节目极其微妙的引用之外,您可以看出这两个部分都处理不合理的长主题安装过程。然而,在 Envato WordPress 工具包的帮助下,我们可以将其减半。默默。带着银斧头。 (好吧,这是最后一个。)
安装 Envato WordPress 工具包
Envato WordPress 工具包托管在 GitHub 上,而不是在 WordPress 插件存储库中,因此您需要在此处下载。
下载后,只需通过管理面板(插件 > 添加新的 > 上传插件)上传 ZIP 文件并激活即可;或将 ZIP 解压到您网站的 wp-content/plugins 文件夹中,然后在管理面板中激活该插件。
输入您的 Envato 用户名和秘密 API 密钥
激活插件后,前往主菜单中的新 Envato Toolkit 页面。在此页面中,您应该输入您的 ThemeForest 用户名和 API 密钥:
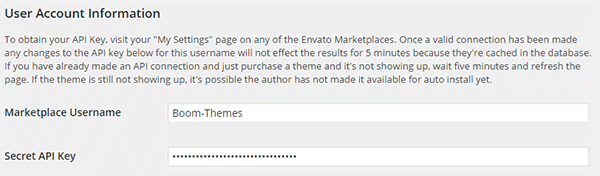
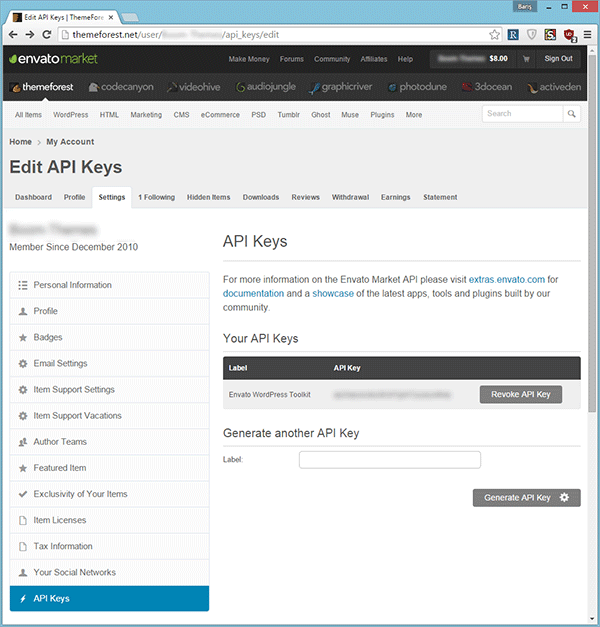
您可以在 ThemeForest 的设置 > API 密钥页面上生成 API 密钥。如果找不到该页面,请将 URL https://themeforest.net/user/USERNAME/api_keys/edit 中的 USERNAME 部分更改为您的用户名,然后导航到该页面。
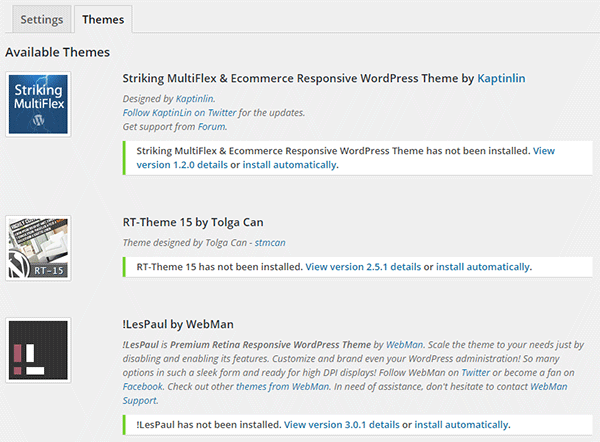
从“主题”选项卡安装主题
使用 Envato WordPress 工具包安装主题实际上比 WordPress.org 主题的内置安装程序更容易。只需转到主题选项卡,您就会看到列出的已购买的主题。点击所需主题的自动安装链接,瞧:您的主题将像常规主题安装程序一样安装。
更新前备份主题
如果您当前的主题版本已过时,并且您想要将主题更新到最新版本,Envato WordPress 工具包也将帮助您完成该过程。但请记住:它将用新版本中的主题文件替换您当前的所有主题文件;因此,如果您对主题文件进行了更改(而不是创建子主题),您可能需要事先备份当前的主题文件。或者您也可以让 Envato WordPress 工具包自动为您完成此操作。
如果已选中,只需取消选中 Envato Toolkit 页面中的以下框即可:

禁用 GitHub 插件更新程序
由于此插件托管在 GitHub 上,因此它需要 WordPress GitHub 插件更新程序的分支来更新自身。但是,如果您出于某种原因不想更新 Envato WordPress Toolkit 插件,您可能需要禁用未来的插件更新。如果是这种情况,您所要做的就是选中以下复选框:
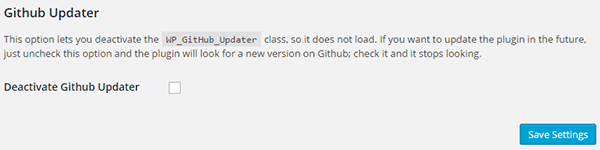
请记住:您不是禁用主题更新,而是禁用插件更新。但说真的:不要这样做。更新很重要——尤其是当它们修复安全漏洞时。
今天总结
ThemeForest 提供了一些很棒的主题,并且创建一个整洁的 WordPress 主题集合并不是很昂贵。话虽这么说,从您的集合中安装主题比从 WordPress.org 安装主题需要更多步骤。这可能会很烦人,特别是如果您需要定期这样做的话。多亏了 Envato WordPress 工具包,这个过程变得短了很多。
您对 Envato WordPress 工具包有何看法?如果您有任何需要补充、纠正或批评的地方,请在下面的评论部分发表评论。如果您喜欢这篇文章,请不要忘记与您的朋友分享!
下一部分见,我们将讨论两个小工具:WXR File Splitter 和 WP Serialized Search & Replace。
以上就是Envato WordPress 工具包:精明的 WordPress 开发人员必备的工具箱的详细内容,更多请关注php中文网其它相关文章!

HTML5中postMessage API的基本使用
window.postmessage经常被人们利用来做跨域数据传递,下面将为大家来介绍html5中的postmessage api基本使用教程,需要的朋友可以参考下
关于postMessage
window.postMessage虽然说是html5的功能,但是支持IE8+,假如你的网站不需要支持IE6和IE7,那么可以使用window.postMessage。关于window.postMessage,很多朋友说他可以支持跨域,不错,window.postMessage是客户端和客户端直接的数据传递,既可以跨域传递,也可以同域传递。
应用场景
我只是简单的举一个应用场景,当然,这个功能很多地方可以使用。
立即学习“前端免费学习笔记(深入)”;
假如你有一个页面,页面中拿到部分用户信息,点击进入另外一个页面,另外的页面默认是取不到用户信息的,你可以通过window.postMessage把部分用户信息传到这个页面中。(当然,你要考虑安全性等方面。)
代码举例
发送信息:
//弹出一个新窗口
var domain = 'http://haorooms.com';
var myPopup = window.open(domain
+ '/windowPostMessageListener.html','myWindow');
//周期性的发送消息
setTimeout(function(){
//var message = '当前时间是 ' + (new Date().getTime());
var message = {name:"站点",sex:"男"}; //你在这里也可以传递一些数据,obj等
console.log('传递的数据是 ' + message);
myPopup.postMessage(message,domain);
},1000);要延迟一下,我们一般用计时器setTimeout延迟再发用。
接受的页面
//监听消息反馈
window.addEventListener('message',function(event) {
if(event.origin !== 'http://haorooms.com') return; //这个判断一下是不是我这个域名跳转过来的
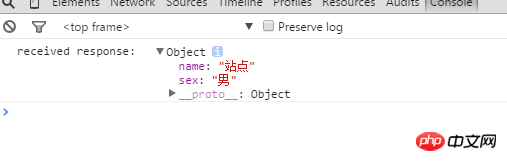
console.log('received response: ',event.data);
},false);如下图,接受页面得到数据
如果是使用iframe,代码应该这样写:
//捕获iframe
var domain = 'http://haorooms.com';
var iframe = document.getElementById('myIFrame').contentWindow;
//发送消息
setTimeout(function(){
//var message = '当前时间是 ' + (new Date().getTime());
var message = {name:"站点",sex:"男"}; //你在这里也可以传递一些数据,obj等
console.log('传递的数据是: ' + message);
//send the message and target URI
iframe.postMessage(message,domain);
},1000);接受数据
//响应事件
window.addEventListener('message',function(event) {
if(event.origin !== 'http://haorooms.com') return;
console.log('message received: ' + event.data,event);
event.source.postMessage('holla back youngin!',event.origin);
},false);上面的代码片段是往消息源反馈信息,确认消息已经收到。下面是几个比较重要的事件属性:
source – 消息源,消息的发送窗口/iframe。
origin – 消息源的URI(可能包含协议、域名和端口),用来验证数据源。
data – 发送方发送给接收方的数据。
调用实例
1. 主线程中创建 Worker 实例,并监听 onmessage 事件
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
<title>Test Web worker</title>
<script type="text/JavaScript">
function init(){
var worker = new Worker('compute.js');
//event 参数中有 data 属性,就是子线程中返回的结果数据
worker.onmessage= function (event) {
// 把子线程返回的结果添加到 p 上
document.getElementById("result").innerHTML +=
event.data+"<br/>";
};
}
</script>
</head>
<body onload="init()">
<p id="result"></p>
</body>
</html>在客户端的 compute.js 中,只是简单的重复多次加和操作,最后通过 postMessage 方法把结果返回给主线程,目的就是等待一段时间。而在这段时间内,主线程不应该被阻塞,用户可以通过拖拽浏览器,变大缩小浏览器窗口等操作测试这一现象。这个非阻塞主线程的结果就是 Web Workers 想达到的目的。
2. compute.js 中调用 postMessage 方法返回计算结果
var i=0;
function timedCount(){
for(var j=0,sum=0;j<100;j++){
for(var i=0;i<100000000;i++){
sum+=i;
}
}
// 调用 postMessage 向主线程发送消息
postMessage(sum);
}
postMessage("Before computing,"+new Date());
timedCount();
postMessage("After computing,"+new Date());以上就是本文的全部内容,希望对大家的学习有所帮助,更多相关内容请关注PHP中文网!
相关推荐:
新增HTML5的八类INPUT输入
如何用HTML5操作WebSQL数据库
以上就是HTML5中postMessage API的基本使用的详细内容,更多请关注php中文网其它相关文章!

kafka api的基本使用
kafka API
kafka Consumer提供两套Java API:高级Consumer API、和低级Consumer API。
高级Consumer API 优点:
- 高级API写起来简单,易用。 不需要自行去管理offset,API已经封装好了offset这块的东西,会通过zookeeper自行管理 不需要管理分区,副本等情况,系统自动管理 消费者断线后会自动根据上次记录在zookeeper中的offset接着消费消息。
高级Consumer API 缺点:
- 不能自行控制offset。
- 不能自行管理分区,副本,zk等相关信息。
低级API 优点:
- 能够让开发者自己维护offset.想从哪里消费就从哪里消费
- 自行控制连接分区,对分区自定义负载均衡
- 对zookeeper的依赖性降低(如 offset 不一定要用zk来存储,可以存在缓存里或者内存中)
缺点: 过于复杂,需要自行控制offset,连接哪个分区,找分区leader等。
简单入门使用
- 引入maven依赖
dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.2.0</version>
</dependency>
- Producer简单使用
package com.sonly.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* <b>package:com.sonly.kafka</b>
* <b>project(项目):kafkaAPIdemo</b>
* <b>class(类)demo</b>
* <b>creat date(创建时间):2019-05-03 12:17</b>
* <b>author(作者):</b>xxydliuyss</br>
* <b>note(备注)):</b>
* If you want to change the file header,please modify zhe File and Code Templates.
*/
public class demo {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"k8s-n1:9092");
properties.put(ProducerConfig.ACKS_CONFIG,"1");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("mytest", Integer.toString(i), Integer.toString(i)));
producer.close();
}
}
带回调函数的生产者
package com.sonly.kafka;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
/**
* <b>package:com.sonly.kafka</b>
* <b>project(项目):kafkaAPIdemo</b>
* <b>class(类)${CLASS_NAME}</b>
* <b>creat date(创建时间):2019-05-03 12:58</b>
* <b>author(作者):</b>xxydliuyss</br>
* <b>note(备注)):</b>
* If you want to change the file header,please modify zhe File and Code Templates.
*/
public class demo1 {
public static void main(String[] args) {
Properties properties = new Properties();
//设置kafka集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"k8s-n1:9092");
//设置brokeACK应答机制
properties.put(ProducerConfig.ACKS_CONFIG,"1");
//设置key序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//设置value序列化
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//设置批量大小
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,"6238");
//设置提交延时
properties.put(ProducerConfig.LINGER_MS_CONFIG,"1");
//设置producer缓存
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,Long.MAX_VALUE);
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
for ( int i = 0; i < 12; i++) {
final int finalI = i;
producer.send(new ProducerRecord<String, String>("mytest", Integer.toString(i), Integer.toString(i)), new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null){
System.out.println("发送成功: " + finalI +","+metadata.partition()+","+ metadata.offset());
}
}
});
}
producer.close();
}
}
结果:
发送成功: 0,0,170
发送成功: 2,0,171
发送成功: 11,0,172
发送成功: 4,1,101
发送成功: 5,2,116
发送成功: 6,2,117
发送成功: 10,2,118
发送成功: 1,3,175
发送成功: 3,3,176
发送成功: 7,3,177
发送成功: 8,3,178
发送成功: 9,3,179
数据不均等的分配到0-3 号分区上 3. 自定义分区发送
package com.sonly.kafka;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* <b>package:com.sonly.kafka</b>
* <b>project(项目):kafkaAPIdemo</b>
* <b>class(类)${CLASS_NAME}</b>
* <b>creat date(创建时间):2019-05-03 13:43</b>
* <b>author(作者):</b>xxydliuyss</br>
* <b>note(备注)):</b>
* If you want to change the file header,please modify zhe File and Code Templates.
*/
public class CustomProducer implements Partitioner {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 0;
}
public void close() {
}
public void configure(Map<String, ?> configs) {
}
}
设置分区
package com.sonly.kafka;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
/**
* <b>package:com.sonly.kafka</b>
* <b>project(项目):kafkaAPIdemo</b>
* <b>class(类)${CLASS_NAME}</b>
* <b>creat date(创建时间):2019-05-03 13:46</b>
* <b>author(作者):</b>xxydliuyss</br>
* <b>note(备注)):</b>
* If you want to change the file header,please modify zhe File and Code Templates.
*/
public class demo2 {
public static void main(String[] args) {
Properties properties = new Properties();
//设置kafka集群
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"k8s-n1:9092");
//设置brokeACK应答机制
properties.put(ProducerConfig.ACKS_CONFIG,"1");
//设置key序列化
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//设置value序列化
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//设置批量大小
properties.put(ProducerConfig.BATCH_SIZE_CONFIG,"6238");
//设置提交延时
properties.put(ProducerConfig.LINGER_MS_CONFIG,"1");
//设置producer缓存
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,Long.MAX_VALUE);
//设置partition
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"com.sonly.kafka.CustomProducer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
for ( int i = 0; i < 12; i++) {
final int finalI = i;
producer.send(new ProducerRecord<String, String>("mytest", Integer.toString(i), Integer.toString(i)), new Callback() {
public void onCompletion(RecordMetadata metadata, Exception exception) {
if(exception==null){
System.out.println("发送成功: " + finalI +","+metadata.partition()+","+ metadata.offset());
}
}
});
}
producer.close();
}
}
消费者高级API:
package com.sonly.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.util.Arrays;
import java.util.Properties;
/**
* <b>package:com.sonly.kafka.consumer</b>
* <b>project(项目):kafkaAPIdemo</b>
* <b>class(类)${CLASS_NAME}</b>
* <b>creat date(创建时间):2019-05-03 13:59</b>
* <b>author(作者):</b>xxydliuyss</br>
* <b>note(备注)):</b>
* If you want to change the file header,please modify zhe File and Code Templates.
*/
public class ConsumerDemo {
public static void main(String[] args) {
Properties properties = new Properties();
//设置kafka集群
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"k8s-n1:9092");
//设置brokeACK应答机制
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"teste3432");
//设置key反序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
//设置value反序列化
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
//设置拿取大小
properties.put(ConsumerConfig.FETCH_MAX_BYTES_CONFIG,100*1024*1024);
//设置自动提交offset
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true);
//设置自动提交延时
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,1000);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Arrays.asList("mytest","test"));
while (true){
ConsumerRecords<String, String> records = consumer.poll(10);
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.topic()+"--"+record.partition()+"--"+record.value());
}
}
}
}
低级API: 1.消费者使用低级API的主要步骤
| 步骤 | 主要工作 |
|---|---|
| 1 | 根据指定分区从topic元数据中找到leader |
| 2 | 获取分区最新的消费进度 |
| 3 | 从主副本中拉取分区消息 |
| 4 | 识别主副本的变化,重试 |
| 2.方法描述: |
| 方法 | 描述 |
|---|---|
| findLeader() | 客户端向种子阶段发送主题元数据,将副本加入备用节点 |
| getLastOffset() | 消费者客户端发送偏移量请求,获取分区最近的偏移量 |
| run() | 消费者低级API拉取消息的方法 |
| findNewLeader() | 当分区主副本节点发生故障时,客户端将要找出新的主副本 |
| 修改pom |
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>1.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.1.1</version>
</dependency>
package com.sonly.kafka.consumer;
import kafka.api.FetchRequest;
import kafka.api.FetchRequestBuilder;
import kafka.api.KAFKA_0_8_1$;
import kafka.cluster.BrokerEndPoint;
import kafka.javaapi.*;
import kafka.javaapi.consumer.SimpleConsumer;
import kafka.javaapi.message.ByteBufferMessageSet;
import kafka.message.MessageAndOffset;
import org.apache.kafka.clients.consumer.Consumer;
import java.nio.ByteBuffer;
import java.util.*;
import java.util.concurrent.TimeUnit;
/**
* <b>package:com.sonly.kafka.consumer</b>
* <b>project(项目):kafkaAPIdemo</b>
* <b>class(类)${CLASS_NAME}</b>
* <b>creat date(创建时间):2019-05-03 15:21</b>
* <b>author(作者):</b>xxydliuyss</br>
* <b>note(备注)):</b>
* If you want to change the file header,please modify zhe File and Code Templates.
*/
public class LowerConsumer {
//保存offset
private long offset;
//保存分区副本
private Map<Integer,List<BrokerEndPoint>> partitionsMap = new HashMap<Integer, List<BrokerEndPoint>>(1024);
public static void main(String[] args) throws InterruptedException {
List<String> brokers = Arrays.asList("k8s-n1", "k8s-n2","k8s-n3");
int port = 9092;
int partition = 1;
long offset=2;
LowerConsumer lowerConsumer = new LowerConsumer();
while(true){
// offset = lowerConsumer.getOffset();
lowerConsumer.getData(brokers,port,"mytest",partition,offset);
TimeUnit.SECONDS.sleep(1);
}
}
public long getOffset() {
return offset;
}
private BrokerEndPoint findLeader(Collection<String> brokers,int port,String topic,int partition){
for (String broker : brokers) {
//创建消费者对象操作每一台服务器
SimpleConsumer getLeader = new SimpleConsumer(broker, port, 10000, 1024 * 24, "getLeader");
//构造元数据请求
TopicMetadataRequest topicMetadataRequest = new TopicMetadataRequest(Collections.singletonList(topic));
//发送元数据请求
TopicMetadataResponse response = getLeader.send(topicMetadataRequest);
//解析元数据
List<TopicMetadata> topicMetadatas = response.topicsMetadata();
//遍历数据
for (TopicMetadata topicMetadata : topicMetadatas) {
//获取分区元数据信息
List<PartitionMetadata> partitionMetadatas = topicMetadata.partitionsMetadata();
//遍历分区元数据
for (PartitionMetadata partitionMetadata : partitionMetadatas) {
if(partition == partitionMetadata.partitionId()){
//保存,分区对应的副本,如果需要主副本挂掉重新获取leader只需要遍历这个缓存即可
List<BrokerEndPoint> isr = partitionMetadata.isr();
this.partitionsMap.put(partition,isr);
return partitionMetadata.leader();
}
}
}
}
return null;
}
private void getData(Collection<String> brokers,int port,String topic,int partition,long offset){
//获取leader
BrokerEndPoint leader = findLeader(brokers, port, topic, partition);
if(leader==null) return;
String host = leader.host();
//获取数据的消费者对象
SimpleConsumer getData = new SimpleConsumer(host, port, 10000, 1024 * 10, "getData");
//构造获取数据request 这里一次可以添加多个topic addFecth 添加即可
FetchRequest fetchRequestBuilder = new FetchRequestBuilder().addFetch(topic, partition, offset, 1024 * 10).build();
//发送获取数据请求
FetchResponse fetchResponse = getData.fetch(fetchRequestBuilder);
//解析元数据返回,这是message的一个set集合
ByteBufferMessageSet messageAndOffsets = fetchResponse.messageSet(topic, partition);
//遍历消息集合
for (MessageAndOffset messageAndOffset : messageAndOffsets) {
long offset1 = messageAndOffset.offset();
this.setOffset(offset);
ByteBuffer payload = messageAndOffset.message().payload();
byte[] buffer = new byte[payload.limit()];
payload.get(buffer);
String message = new String(buffer);
System.out.println("offset:"+ offset1 +"--message:"+ message);
}
}
private void setOffset(long offset) {
this.offset = offset;
}
}
这个低级API在最新的kafka版本中已经不再提供了。
今天的关于WordPress REST API的基本使用和wordpress rest api教程的分享已经结束,谢谢您的关注,如果想了解更多关于Elasticsearch Java API的基本使用、Envato WordPress 工具包:精明的 WordPress 开发人员必备的工具箱、HTML5中postMessage API的基本使用、kafka api的基本使用的相关知识,请在本站进行查询。
本文标签:




