想了解SpringBoot+Netty+Elasticsearch收集日志信息数据存储的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于springboot日志收集的相关问题,此外,我们还将为
想了解SpringBoot+Netty+Elasticsearch收集日志信息数据存储的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于spring boot日志收集的相关问题,此外,我们还将为您介绍关于ElasticSearch (2)---SpringBoot 整合 ElasticSearch、ElasticSearch - 学习笔记 02-springboot 整合 jestclient 操作 elasticSearch、elasticsearch 整合springboot、elasticsearch 集成springboot的新知识。
本文目录一览:- SpringBoot+Netty+Elasticsearch收集日志信息数据存储(spring boot日志收集)
- ElasticSearch (2)---SpringBoot 整合 ElasticSearch
- ElasticSearch - 学习笔记 02-springboot 整合 jestclient 操作 elasticSearch
- elasticsearch 整合springboot
- elasticsearch 集成springboot
")
SpringBoot+Netty+Elasticsearch收集日志信息数据存储(spring boot日志收集)
前言介绍
在实际的开发场景中,我们希望将大量的业务以及用户行为数据存储起来用于分析处理,但是由于数据量较大且需要具备可分析功能所以将数据存储到文件系统更为合理。尤其是一些互联网高并发级应用,往往数据库都采用分库分表设计,那么将这些分散的数据通过binlog汇总到一个统一的文件系统就显得非常有必要。
开发环境
1、jdk1.8【jdk1.7以下只能部分支持netty】
2、Netty4.1.36.Final【netty3.x 4.x 5每次的变化较大,接口类名也随着变化】
3、elasticsearch6.2.2
3.1、windows环境下安装elasticsearch6.2.2
3.2、elasticsearch-head插件安装
代码示例
itstack-demo-netty-2-06
└── src
├── main
│ ├── java
│ │ └── org.itstack.demo.netty
│ │ ├── codec
│ │ │ ├── ObjDecoder.java
│ │ │ └── ObjEncoder.java
│ │ ├── domain
│ │ │ ├── TransportProtocol.java
│ │ │ └── User.java
│ │ ├── server
│ │ │ ├── MyChannelInitializer.java
│ │ │ ├── MyServerHandler.java
│ │ │ └── NettyServer.java
│ │ ├── service
│ │ │ ├── impl
│ │ │ │ └── UserServiceImpl.java
│ │ │ ├── UserRepository.java
│ │ │ └── UserService.java
│ │ ├── util
│ │ │ └── SerializationUtil.java
│ │ ├── web
│ │ │ └── NettyController.java
│ │ └── Application.java
│ └── resources
│ └── application.yml
│
└── test
└── java
└── org.itstack.demo.test
└── ApiTest.java演示部分重点代码块,完整代码下载关注公众号;bugstack虫洞栈
domain/User.java
/**
* 虫洞栈:https://bugstack.cn
* 公众号:bugstack虫洞栈 {获取学习源码}
* Create by fuzhengwei on 2019
*/
@Document(indexName = "stack", type = "group_user")
public class User {
@Id
private String id;
private String name; //姓名
private Integer age; //年龄
private String level; //级别
private Date entryDate;//时间
private String mobile; //电话
private String email; //邮箱
private String address;//地址
public User(String id, String name, Integer age, String level, Date entryDate, String mobile, String email, String address) {
this.id = id;
this.name = name;
this.age = age;
this.level = level;
this.entryDate = entryDate;
this.mobile = mobile;
this.email = email;
this.address = address;
}
... get/set
}server/MyServerHandler.java
/**
* 虫洞栈:https://bugstack.cn
* 公众号:bugstack虫洞栈 {获取学习源码}
* Create by fuzhengwei on 2019
*/
@Service("myServerHandler")
public class MyServerHandler extends ChannelInboundHandlerAdapter {
private Logger logger = LoggerFactory.getLogger(MyServerHandler.class);
@Autowired
private UserService userService;
/**
* 当客户端主动链接服务端的链接后,这个通道就是活跃的了。也就是客户端与服务端建立了通信通道并且可以传输数据
*/
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
SocketChannel channel = (SocketChannel) ctx.channel();
logger.info("链接报告开始");
logger.info("链接报告信息:有一客户端链接到本服务端");
logger.info("链接报告IP:{}", channel.localAddress().getHostString());
logger.info("链接报告Port:{}", channel.localAddress().getPort());
logger.info("链接报告完毕");
}
/**
* 当客户端主动断开服务端的链接后,这个通道就是不活跃的。也就是说客户端与服务端的关闭了通信通道并且不可以传输数据
*/
@Override
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
logger.info("客户端断开链接{}", ctx.channel().localAddress().toString());
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//接收msg消息{与上一章节相比,此处已经不需要自己进行解码}
logger.info(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()) + " 服务端接收到消息:" + JSON.toJSONString(msg));
//接收数据写入到Elasticsearch
TransportProtocol transportProtocol = (TransportProtocol) msg;
userService.save((User) transportProtocol.getObj());
}
/**
* 抓住异常,当发生异常的时候,可以做一些相应的处理,比如打印日志、关闭链接
*/
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
ctx.close();
logger.info("异常信息:\r\n" + cause.getMessage());
}
}service/UserService.java *提供CRUD方法
/**
* 虫洞栈:https://bugstack.cn
* 公众号:bugstack虫洞栈 {获取学习源码}
* Create by fuzhengwei on 2019
*/
public interface UserService {
void save(User user);
void deleteById(String id);
User queryUserById(String id);
Iterable<User> queryAll();
Page<User> findByName(String name, PageRequest request);
}service/UserRepository.java *可以扩展需要的方法,User是表、String是ID
/**
* 虫洞栈:https://bugstack.cn
* 公众号:bugstack虫洞栈 {获取学习源码}
* Create by fuzhengwei on 2019
*/
public interface UserRepository extends ElasticsearchRepository<User, String> {
Page<User> findByName(String name, Pageable pageable);
}service/impl/UserServiceImpl.java *CRUD实现类
/**
* 虫洞栈:https://bugstack.cn
* 公众号:bugstack虫洞栈 {获取学习源码}
* Create by fuzhengwei on 2019
*/
@Service("userService")
public class UserServiceImpl implements UserService {
private UserRepository dataRepository;
@Autowired
public void setDataRepository(UserRepository dataRepository) {
this.dataRepository = dataRepository;
}
@Override
public void save(User user) {
dataRepository.save(user);
}
@Override
public void deleteById(String id) {
dataRepository.deleteById(id);
}
@Override
public User queryUserById(String id) {
Optional<User> optionalUser = dataRepository.findById(id);
return optionalUser.get();
}
@Override
public Iterable<User> queryAll() {
return dataRepository.findAll();
}
@Override
public Page<User> findByName(String name, PageRequest request) {
return dataRepository.findByName(name, request);
}
}Application.java *springboot启动时会同时启动Netty服务
/**
* 虫洞栈:https://bugstack.cn
* 公众号:bugstack虫洞栈 {获取学习源码}
* Create by fuzhengwei on 2019
*/
@SpringBootApplication
public class Application implements CommandLineRunner {
private Logger logger = LoggerFactory.getLogger(Application.class);
@Value("${netty.host}")
private String host;
@Value("${netty.port}")
private int port;
@Resource
private NettyServer nettyServer;
public static void main(String[] args) {
System.setProperty("es.set.netty.runtime.available.processors", "false");
SpringApplication.run(Application.class, args);
}
@Override
public void run(String... args) throws Exception {
InetSocketAddress address = new InetSocketAddress(host, port);
ChannelFuture channelFuture = nettyServer.bing(address);
Runtime.getRuntime().addShutdownHook(new Thread(() -> nettyServer.destroy()));
channelFuture.channel().closeFuture().syncUninterruptibly();
}
}application.properties *配置文件{服务端口、netty、Elasticsearch}
## 服务端口
server.port = 8080
## Netty服务端配置
netty.host = 127.0.0.1
netty.port = 7397
## Elasticsearch配置{更换为自己的cluster-name、cluster-nodes}
spring.data.elasticsearch.cluster-name=es-itstack
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
spring.data.elasticsearch.repositories.enabled=trueApiTest.java *Netty客户端,用于向服务端发送数据
/**
* 虫洞栈:https://bugstack.cn
* 公众号:bugstack虫洞栈 {获取学习源码}
* Create by fuzhengwei on 2019
*/
public class ApiTest {
public static void main(String[] args) {
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
Bootstrap b = new Bootstrap();
b.group(workerGroup);
b.channel(NioSocketChannel.class);
b.option(ChannelOption.AUTO_READ, true);
b.handler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel channel) throws Exception {
//对象传输处理
channel.pipeline().addLast(new ObjDecoder(TransportProtocol.class));
channel.pipeline().addLast(new ObjEncoder(TransportProtocol.class));
// 在管道中添加我们自己的接收数据实现方法
channel.pipeline().addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
}
});
}
});
ChannelFuture f = b.connect("127.0.0.1", 7397).sync();
System.out.println("itstack-demo-netty client start done. {关注公众号:bugstack虫洞栈,获取源码}");
TransportProtocol tp1 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "李小明", 1, "T0-1", new Date(), "13566668888", "184172133@qq.com", "北京"));
TransportProtocol tp2 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "张大明", 2, "T0-2", new Date(), "13566660001", "huahua@qq.com", "南京"));
TransportProtocol tp3 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "李书鹏", 2, "T1-1", new Date(), "13566660002", "xiaobai@qq.com", "榆树"));
TransportProtocol tp4 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "韩小雪", 2, "T2-1", new Date(), "13566660002", "xiaobai@qq.com", "榆树"));
TransportProtocol tp5 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "董叔飞", 2, "T4-1", new Date(), "13566660002", "xiaobai@qq.com", "河北"));
TransportProtocol tp6 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "候明相", 2, "T5-1", new Date(), "13566660002", "xiaobai@qq.com", "下花园"));
TransportProtocol tp7 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "田明明", 2, "T3-1", new Date(), "13566660002", "xiaobai@qq.com", "东平"));
TransportProtocol tp8 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "王大伟", 2, "T4-1", new Date(), "13566660002", "xiaobai@qq.com", "西湖"));
TransportProtocol tp9 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "李雪明", 2, "T1-1", new Date(), "13566660002", "xiaobai@qq.com", "南昌"));
TransportProtocol tp10 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "朱小飞", 2, "T2-1", new Date(), "13566660002", "xiaobai@qq.com", "吉林"));
TransportProtocol tp11 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "牛大明", 2, "T1-1", new Date(), "13566660002", "xiaobai@qq.com", "长春"));
TransportProtocol tp12 = new TransportProtocol(1, new User(UUID.randomUUID().toString(), "关雪儿", 2, "T2-1", new Date(), "13566660002", "xiaobai@qq.com", "深圳"));
//向服务端发送信息
f.channel().writeAndFlush(tp1);
f.channel().writeAndFlush(tp2);
f.channel().writeAndFlush(tp3);
f.channel().writeAndFlush(tp4);
f.channel().writeAndFlush(tp5);
f.channel().writeAndFlush(tp6);
f.channel().writeAndFlush(tp7);
f.channel().writeAndFlush(tp8);
f.channel().writeAndFlush(tp9);
f.channel().writeAndFlush(tp10);
f.channel().writeAndFlush(tp11);
f.channel().writeAndFlush(tp12);
f.channel().closeFuture().syncUninterruptibly();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
workerGroup.shutdownGracefully();
}
}
}测试结果
启动Elasticsearch *也可以直接双击..elasticsearch-6.2.2/bin/elasticsearch.bat
D:\Program Files\elasticsearch\node01\elasticsearch-6.2.2\bin>elasticsearch.bat
[2019-08-10T14:09:26,562][INFO ][o.e.n.Node ] [node01] initializin
g ...
[2019-08-10T14:09:26,770][INFO ][o.e.e.NodeEnvironment ] [node01] using [1] d
ata paths, mounts [[杞欢 (D:)]], net usable_space [301.3gb], net total_space [
407.1gb], types [NTFS]
[2019-08-10T14:09:26,771][INFO ][o.e.e.NodeEnvironment ] [node01] heap size [
990.7mb], compressed ordinary object pointers [true]
[2019-08-10T14:09:26,843][INFO ][o.e.n.Node ] [node01] node name [
node01], node ID [R5wRCDr0SSKsVsgkZwB-Hg]
[2019-08-10T14:09:26,843][INFO ][o.e.n.Node ] [node01] version[6.2
.2], pid[22264], build[10b1edd/2018-02-16T19:01:30.685723Z], OS[Windows 7/6.1/am
d64], JVM[Oracle Corporation/Java HotSpot(TM) 64-Bit Server VM/1.8.0_45/25.45-b0
2]
[2019-08-10T14:09:26,843][INFO ][o.e.n.Node ] [node01] JVM argumen
ts [-Xms1g, -Xmx1g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=
75, -XX:+UseCMSInitiatingOccupancyOnly, -XX:+AlwaysPreTouch, -Xss1m, -Djava.awt.
headless=true, -Dfile.encoding=UTF-8, -Djna.nosys=true, -XX:-OmitStackTraceInFas
tThrow, -Dio.netty.noUnsafe=true, -Dio.netty.noKeySetOptimization=true, -Dio.net启动Elasticsearch-head
D:\Program Files\elasticsearch\head>npm run start
> elasticsearch-head@0.0.0 start D:\Program Files\elasticsearch\head
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100启动StringBoot *Netty服务会随着启动{Application.main}
. ____ _ __ _ _
/\\ / ___''_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | ''_ | ''_| | ''_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
'' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.0.1.RELEASE)
2019-08-10 14:14:49.619 INFO 5976 --- [ main] org.itstack.demo.netty.Application : Starting Application on JRA1W11T0247 with PID 5976 (E:\itstack\GIT\itstack.org\itstack-demo-netty\itstack-demo-netty-2-06\target\classes started by fuzhengwei1 in E:\itstack\GIT\itstack.org\itstack-demo-netty)
2019-08-10 14:14:49.622 INFO 5976 --- [ main] org.itstack.demo.netty.Application : No active profile set, falling back to default profiles: default
2019-08-10 14:14:49.704 INFO 5976 --- [ main] ConfigServletWebServerApplicationContext : Refreshing org.springframework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext@7f010382: startup date [Sat Aug 10 14:14:49 CST 2019]; root of context hierarchy
2019-08-10 14:14:51.341 INFO 5976 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
2019-08-10 14:14:51.367 INFO 5976 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2019-08-10 14:14:51.367 INFO 5976 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet Engine: Apache Tomcat/8.5.29
2019-08-10 14:14:51.377 INFO 5976 --- [ost-startStop-1] o.a.catalina.core.AprLifecycleListener : The APR based Apache Tomcat Native library which allows optimal performance in production environments was not found on the java.library.path: [C:\Program Files\Java\jdk1.8.0_45\bin;C:\windows\Sun\Java\bin;C:\windows\system32;C:\windows;C:\ProgramData\Oracle\Java\javapath;C:\Program Files (x86)\Common Files\NetSarang;C:\Program Files (x86)\Intel\iCLS Client\;C:\Program Files\Intel\iCLS Client\;C:\windows\system32;C:\windows;C:\windows\System32\Wbem;C:\windows\System32\WindowsPowerShell\v1.0\;C:\Program Files\Intel\Intel(R) Management Engine Components\DAL;C:\Program Files\Intel\Intel(R) Management Engine Components\IPT;C:\Program Files (x86)\Intel\Intel(R) Management Engine Components\DAL;C:\Program Files (x86)\Intel\Intel(R) Management Engine Components\IPT;C:\Program Files\Java\jdk1.8.0_45/bin;C:\Program Files\Java\jdk1.8.0_45/jre/bin;D:\Program Files\SlikSvn\bin;D:\Program Files\TortoiseSVN\bin;D:\Program Files (x86)\apache-maven-2.2.1\bin;D:\Program Files\TortoiseGit\bin;D:\Program Files\nodejs\;D:\Program Files (x86)\SSH Communications Security\SSH Secure Shell;C:\Users\fuzhengwei1\AppData\Roaming\npm;;.]
2019-08-10 14:14:51.523 INFO 5976 --- [ost-startStop-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2019-08-10 14:14:51.523 INFO 5976 --- [ost-startStop-1] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 1819 ms
2019-08-10 14:14:51.659 INFO 5976 --- [ost-startStop-1] o.s.b.w.servlet.ServletRegistrationBean : Servlet dispatcherServlet mapped to [/]
2019-08-10 14:14:51.663 INFO 5976 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: ''characterEncodingFilter'' to: [/*]
2019-08-10 14:14:51.664 INFO 5976 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: ''hiddenHttpMethodFilter'' to: [/*]
2019-08-10 14:14:51.664 INFO 5976 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: ''httpPutFormContentFilter'' to: [/*]
2019-08-10 14:14:51.664 INFO 5976 --- [ost-startStop-1] o.s.b.w.servlet.FilterRegistrationBean : Mapping filter: ''requestContextFilter'' to: [/*]
2019-08-10 14:14:52.090 INFO 5976 --- [ main] o.elasticsearch.plugins.PluginsService : no modules loaded
2019-08-10 14:14:52.092 INFO 5976 --- [ main] o.elasticsearch.plugins.PluginsService : loaded plugin [org.elasticsearch.index.reindex.ReindexPlugin]
2019-08-10 14:14:52.092 INFO 5976 --- [ main] o.elasticsearch.plugins.PluginsService : loaded plugin [org.elasticsearch.join.ParentJoinPlugin]
2019-08-10 14:14:52.092 INFO 5976 --- [ main] o.elasticsearch.plugins.PluginsService : loaded plugin [org.elasticsearch.percolator.PercolatorPlugin]
2019-08-10 14:14:52.092 INFO 5976 --- [ main] o.elasticsearch.plugins.PluginsService : loaded plugin [org.elasticsearch.script.mustache.MustachePlugin]
2019-08-10 14:14:52.092 INFO 5976 --- [ main] o.elasticsearch.plugins.PluginsService : loaded plugin [org.elasticsearch.transport.Netty3Plugin]
2019-08-10 14:14:52.092 INFO 5976 --- [ main] o.elasticsearch.plugins.PluginsService : loaded plugin [org.elasticsearch.transport.Netty4Plugin]
2019-08-10 14:14:52.973 INFO 5976 --- [ main] o.s.d.e.c.TransportClientFactoryBean : adding transport node : 127.0.0.1:9300
2019-08-10 14:14:54.486 INFO 5976 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**/favicon.ico] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2019-08-10 14:14:54.730 INFO 5976 --- [ main] s.w.s.m.m.a.RequestMappingHandlerAdapter : Looking for @ControllerAdvice: org.springframework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext@7f010382: startup date [Sat Aug 10 14:14:49 CST 2019]; root of context hierarchy
2019-08-10 14:14:54.800 INFO 5976 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/localAddress]}" onto public java.lang.String org.itstack.demo.netty.web.NettyController.localAddress()
2019-08-10 14:14:54.803 INFO 5976 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error]}" onto public org.springframework.http.ResponseEntity<java.util.Map<java.lang.String, java.lang.Object>> org.springframework.boot.autoconfigure.web.servlet.error.BasicErrorController.error(javax.servlet.http.HttpServletRequest)
2019-08-10 14:14:54.804 INFO 5976 --- [ main] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped "{[/error],produces=[text/html]}" onto public org.springframework.web.servlet.ModelAndView org.springframework.boot.autoconfigure.web.servlet.error.BasicErrorController.errorHtml(javax.servlet.http.HttpServletRequest,javax.servlet.http.HttpServletResponse)
2019-08-10 14:14:54.822 INFO 5976 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/webjars/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2019-08-10 14:14:54.822 INFO 5976 --- [ main] o.s.w.s.handler.SimpleUrlHandlerMapping : Mapped URL path [/**] onto handler of type [class org.springframework.web.servlet.resource.ResourceHttpRequestHandler]
2019-08-10 14:14:54.985 INFO 5976 --- [ main] o.s.j.e.a.AnnotationMBeanExporter : Registering beans for JMX exposure on startup
2019-08-10 14:14:55.013 INFO 5976 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''''
2019-08-10 14:14:55.016 INFO 5976 --- [ main] org.itstack.demo.netty.Application : Started Application in 5.982 seconds (JVM running for 6.516)
2019-08-10 14:14:55.043 INFO 5976 --- [ main] o.itstack.demo.netty.server.NettyServer : itstack-demo-netty server start done. {关注公众号:bugstack虫洞栈,获取源码}启动Netty客户端发送数据 ApiTest.main
itstack-demo-netty client start done. {关注公众号:bugstack虫洞栈,获取源码}
14:16:33.543 [main] DEBUG io.netty.util.Recycler - -Dio.netty.recycler.maxCapacityPerThread: 4096
14:16:33.543 [main] DEBUG io.netty.util.Recycler - -Dio.netty.recycler.maxSharedCapacityFactor: 2
14:16:33.543 [main] DEBUG io.netty.util.Recycler - -Dio.netty.recycler.linkCapacity: 16
14:16:33.543 [main] DEBUG io.netty.util.Recycler - -Dio.netty.recycler.ratio: 8
14:16:33.555 [nioEventLoopGroup-2-1] DEBUG io.netty.buffer.AbstractByteBuf - -Dio.netty.buffer.checkAccessible: true
14:16:33.555 [nioEventLoopGroup-2-1] DEBUG io.netty.buffer.AbstractByteBuf - -Dio.netty.buffer.checkBounds: true
14:16:33.556 [nioEventLoopGroup-2-1] DEBUG io.netty.util.ResourceLeakDetectorFactory - Loaded default ResourceLeakDetector: io.netty.util.ResourceLeakDetector@529fc511执行结果 *数据已经写入到Elasticsearch
微信公众号:bugstack虫洞栈,欢迎您的关注&获取源码!
本文分享自微信公众号 - bugstack虫洞栈(bugstack)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
---SpringBoot 整合 ElasticSearch")
ElasticSearch (2)---SpringBoot 整合 ElasticSearch
SpringBoot 整合 ElasticSearch
一、基于 spring-boot-starter-data-elasticsearch 整合
开发环境:springboot 版本:2.0.1,elasticSearch-5.6.8.jar 版本:5.6.8,服务器部署 ElasticSearch 版本:6.3.2
1、application.properties
spring.data.elasticsearch.cluster-name=elasticsearch
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
spring.data.elasticsearch.repositories.enabled=true2、pom.xml
<!--spring整合elasticsearch包-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!--实体工具包-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--集合工具包-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>3、Notice 实体
@Data
@AllArgsConstructor
@NoArgsConstructor
//indexName代表所以名称,type代表表名称
@Document(indexName = "wantu_notice_info", type = "doc")
public class Notice {
//id
@JsonProperty("auto_id")
private Long id;
//标题
@JsonProperty("title")
private String title;
//公告标签
@JsonProperty("exchange_mc")
private String exchangeMc;
//公告发布时间
@JsonProperty("create_time")
private String originCreateTime;
//公告阅读数量
@JsonProperty("read_count")
private Integer readCount;
}4、NoticeRepository 类
import com.jincou.elasearch.domain.Notice;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Component;
@Component
public interface NoticeRepository extends ElasticsearchRepository<Notice, Long> {
} 5、NoticeController
@RestController
@RequestMapping("/api/v1/article")
public class NoticeController {
@Autowired
private NoticeRepository nticeRepository;
@GetMapping("save")
public CommandResult<Void> save(long id, String title){
Notice article = new Notice();
article.setId(id);
article.setReadCount(123);
article.setTitle("springboot整合elasticsearch,这个是新版本 2018年");
nticeRepository.save(article);
return CommandResult.ofSucceed();
}
/**
* @param title 搜索标题
* @param pageable page = 第几页参数, value = 每页显示条数
*/
@GetMapping("search")
public CommandResult<List<Notice>> search(String title,@PageableDefault(page = 1, value = 10) Pageable pageable){
//按标题进行搜索
QueryBuilder queryBuilder = QueryBuilders.matchQuery("title", title);
//如果实体和数据的名称对应就会自动封装,pageable分页参数
Iterable<Notice> listIt = nticeRepository.search(queryBuilder,pageable);
//Iterable转list
List<Notice> list= Lists.newArrayList(listIt);
return CommandResult.ofSucceed(list);
}
}6、查看运行结果
它会进行中文分词查询,然后安装相识度进行排序

总体步骤还是蛮清晰简单的,因为有 spring-boot-starter-data-elasticsearch 进行了整合,所以我们可以少敲很多代码。
二、 基于 TransportClient 整合
首先明白:如果项目 SpringBoot1.5.X 以下的,那么 elasticSearch.jar 最高是 2.4.4 版本的,只有 SpringBoot2.X+,elasticSearch.jar 才是 5.X+
如果你的 SpringBoot 是 1.5.X 以下,那你又想用 elasticSearch.jar5.X + 怎么办呢,那就不要用 spring-boot-starter-data-elasticsearch,用原生的 TransportClient 实现即可。
这个相当于用原生的去使用 elasticsearch, 这里面并没有用到 spring-boot-starter-data-elasticsearch 相关 jar 包,因为我们公司的 springBoot 版本是 1.5.9。
如果用 spring-boot-starter-data-elasticsearch 的话,那么 elasticsearch 版本最高只有 2.4.4,这也太落后了,现在 elasticsearch 已经到 6.3.2 了,为了用更好的版本有两个方案:
1、提高 springboot 版本到 2.X(不过不现实,船大难掉头),2、用原生的 TransportClient 实现。最终落地实现是通过 TransportClient 实现
把关键代码展示出来。
1、pom.xml
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.7</version>
</dependency>2、创建实体
@Configuration
public class ServerModule {
@Bean
public TransportClient transportClient() {
Settings settings = Settings.builder().put("cluster.name", "biteniuniu").build();
//我用6.3.2版本的时候这里一直报异常说找不到InetSocketTransportAddress类,这应该和jar有关,当我改成5.6.8就不报错了
TransportClient client = new PreBuiltTransportClient(settings);//6.3.2这里TransportAddress代替InetSocketTransportAddress
client.addTransportAddress(new InetSocketTransportAddress(
new InetSocketAddress(InetAddresses.forString("127.0.0.1"), 9300)));
return client;
}
}3、NoticeController 类
@RestController
@RequestMapping("/api/v1/notice")
public class NoticeController {
@Autowired
private TransportClient transportClient;
/**
*利用TransportClient实现搜索功能
* @param title 搜索标题
* @param page = 从第几条结果返回 | Integer(比如一次size=20,page=0,如果要显示下一页20条记录则需要size=20,page=20)这个和之前有点区别, size = 每页显示条数
*/
@RequestMapping(value = "trsearch", method = RequestMethod.GET, produces = MediaType.APPLICATION_JSON_UTF8_VALUE)
public CommandResult<List<Notice>> search(@RequestParam(value = "title", defaultValue = "比特币")String title, @RequestParam(value = "page", defaultValue = "0")Integer page,
@RequestParam(value = "size", defaultValue = "20")Integer size) {
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//按标题进行查找
boolQueryBuilder.must(QueryBuilders.matchQuery("title", title));
//在这里输入索引名称和type类型
SearchResponse response = transportClient.prepareSearch("wantu_notice_info").setTypes("doc")
// 设置查询类型java
.setSearchType(SearchType.DFS_QUERY_THEN_FETCH)
// 设置查询关键词
.setQuery(boolQueryBuilder)
// 设置查询数据的位置,分页用
.setFrom(page)
// 设置查询结果集的最大条数
.setSize(size)
// 设置是否按查询匹配度排序
.setExplain(true)
// 最后就是返回搜索响应信息
.get();
SearchHits searchHits = response.getHits();
List<Notice> list = Lists.newArrayListWithCapacity(size);
for (SearchHit searchHit : searchHits) {
Map<String, Object> sourceAsMap = searchHit.getSourceAsMap();
//获得titie数据
String titles = (String) sourceAsMap.get("title");
//获得阅读量数据
Integer readCount = (Integer) sourceAsMap.get("read_count");
//把数据装入对象中
Notice notice=new Notice();
notice.setTitle(titles);
notice.setReadCount(readCount);
list.add(notice);
}
return CommandResult.ofSucceed(list);
}
}4、运行结果
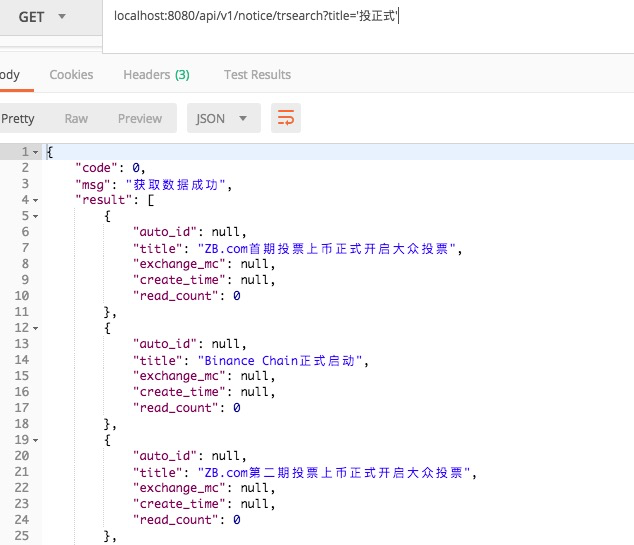
总结下:第一种整合相对简单很多,因为本身封装很多东西,比如分页,封装数据等。第二种的话可以在不用 spring 的情况下使用它。
我只是偶尔安静下来,对过去的种种思忖一番。那些曾经的旧时光里即便有过天真愚钝,也不值得谴责。毕竟,往后的日子,还很长。不断鼓励自己,
天一亮,又是崭新的起点,又是未知的征程(上校 4)

ElasticSearch - 学习笔记 02-springboot 整合 jestclient 操作 elasticSearch


<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.16.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.huarui</groupId>
<artifactId>sb_elasticsearch_jestclient</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>sb_elasticsearch_jestclient</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.7</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
</pluginRepository>
</pluginRepositories>
</project>
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.7</version>
</dependency>
spring.elasticsearch.jest.uris = http://192.168.79.129:9200/
spring.elasticsearch.jest.read-timeout = 10000
spring.elasticsearch.jest.username =
spring.elasticsearch.jest.password =
junit
import com.huarui.entity.User;
import io.searchbox.client.JestClient;
import io.searchbox.client.JestResult;
import io.searchbox.core.*;
import io.searchbox.indices.CreateIndex;
import io.searchbox.indices.DeleteIndex;
import io.searchbox.indices.mapping.GetMapping;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class ElasticApplicationTests {
private static String indexName = "userindex";
private static String typeName = "user";
@Autowired
JestClient jestClient;
/**
* 新增数据
* @return
* @throws Exception
*/
@Test
public void insert() throws Exception {
User user = new User(1L, "张三", 20, "张三是个Java开发工程师","2018-4-25 11:07:42");
Index index = new Index.Builder(user).index(indexName).type(typeName).build();
try{
JestResult jr = jestClient.execute(index);
System.out.println(jr.isSucceeded());
}catch(IOException e){
e.printStackTrace();
}
}
}

elasticsearch 整合springboot
elasticsearch介绍
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
elasticserch应用场景
大型分布式日志分析系统ELK elasticsearch(存储日志)+ logstash(手机日志) + kibana(展示数据) 大型电商商品搜索系统、网站站内搜索(站外搜索)、网盘搜索引擎等。
windows下搭建elasticsearch

将elasticserch 和可视化 插件 kibana进行解压 分别进入 解压好的 bin 文件夹下进行启动
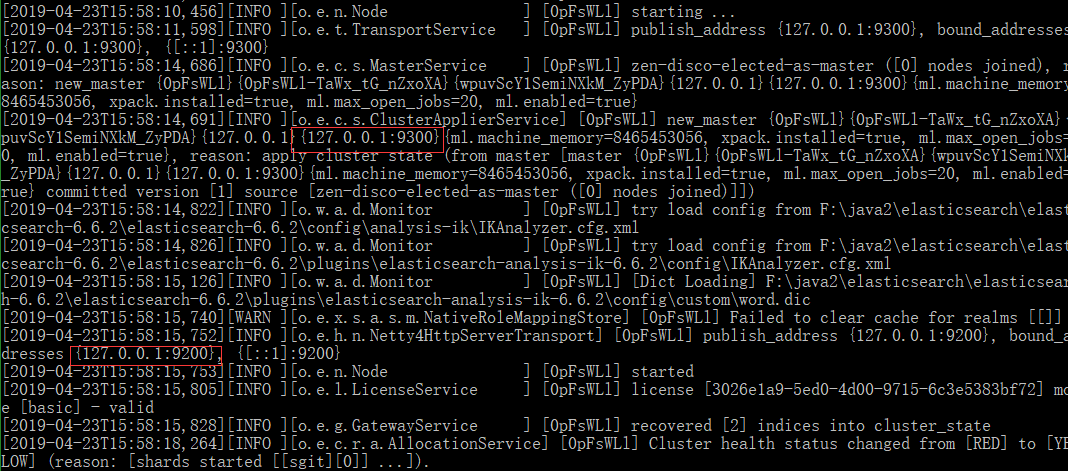
可以看到启动了两个端口 9300端口:ES节点之间通讯使用 9200端口:ES节点和外部通讯使用

kibana启动稍慢

通过浏览器进行访问http://localhost:9200

如图windows下elasticsearch 搭建成功
访问kibana 进行操作http://localhost:5601

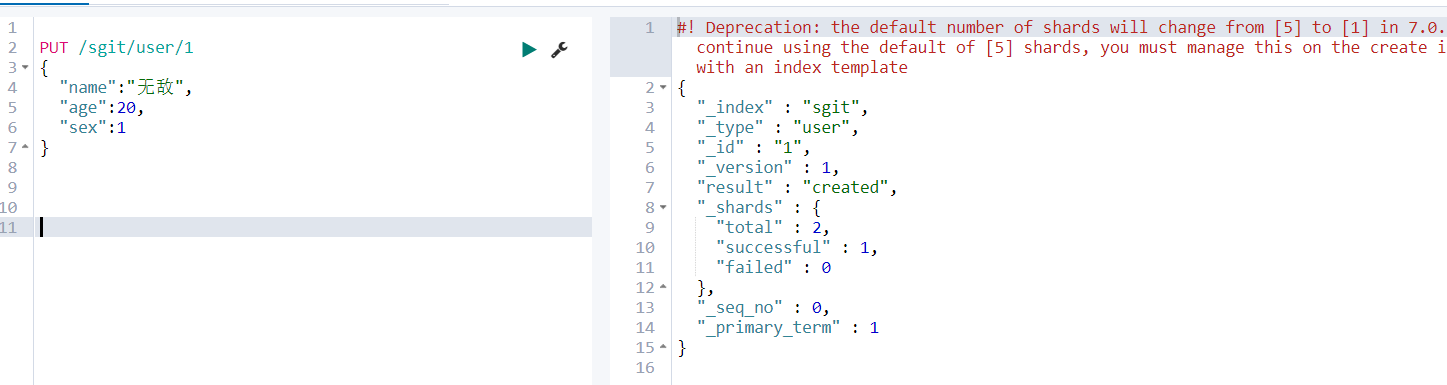
点击 Dev Tools 创建一个索引为 sgit 类型为 user id 为1 的用户
elastic search是文件存储,是面向文档行的数据库 类似于 mongodb 一条数据在这里 就是一个文档,用json作为文档的序列化格式 它和关系
数据库的比较
| 关系数据库 |
数据库 |
表 |
行 |
列 |
| elastic search |
索引(index) |
类型(type) |
文档document |
字段 |
创建索引 PUT /sgit 查索引 GET /sgit 删除索引 DELETE /sgit
springboot 中整合Elasticsearch
1、配置pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.lingyun</groupId>
<artifactId>ly-web-elasticsearch</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>ly-web-elasticsearch</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2、创建实体类
package com.lingyun.model;
import lombok.Data;
import lombok.ToString;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
@Document(indexName = "sgit",type = "user")
@Data
@ToString
public class User {
@Id
private String id;
private String name;
private Integer age;
private Integer sex;
}
3.配置Dao层类
package com.lingyun.dao;
import com.lingyun.model.User;
import org.springframework.data.repository.CrudRepository;
public interface UserDao extends CrudRepository<User,String> {
}4、配置controller层
package com.lingyun.controller;
import com.lingyun.dao.UserDao;
import com.lingyun.model.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Optional;
@RestController
public class UserController {
@Autowired
private UserDao userDao;
@RequestMapping("/findAll")
public Iterable<User> findAll(){
return userDao.findAll();
}
@RequestMapping("/addUser")
public User addUser(@RequestBody User user){
return userDao.save(user);
}
@RequestMapping("/findById")
public Optional<User> finfById(String id){
return userDao.findById(id);
}
}5、配置application.yml文件
spring:
data:
elasticsearch:
cluster-name: myes
cluster-nodes: localhost:9300
需要修改 elasticsearch/config 文件夹下的 elasticsearch.yml
6.启动类
package com.lingyun;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.elasticsearch.repository.config.EnableElasticsearchRepositories;
@SpringBootApplication
@EnableElasticsearchRepositories(basePackages = "com.lingyun.dao")
public class LyWebElasticsearchApplication {
public static void main(String[] args) {
SpringApplication.run(LyWebElasticsearchApplication.class, args);
}
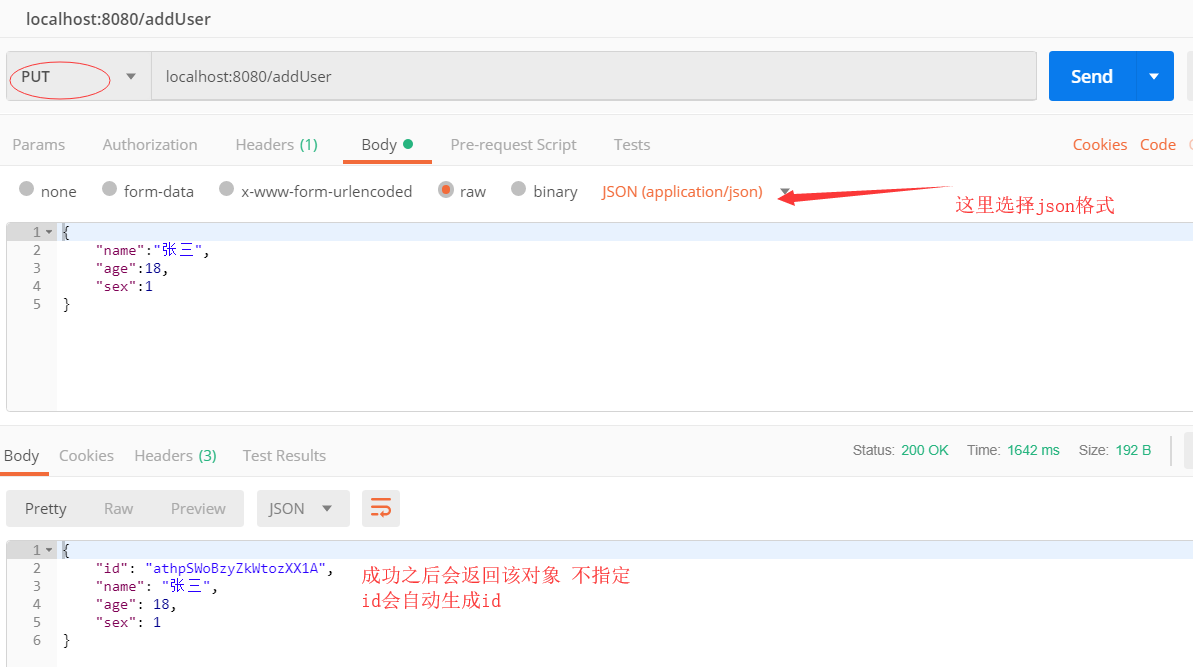
} 用postman进行测试

elasticsearch 集成springboot
和jpa类似,很简单,很强大。
pom
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>application.yml
spring:
data:
elasticsearch:
cluster-name: elasticsearch
cluster-nodes: 192.168.56.101:9300实体类及注解
@Document(indexName = "item",type = "docs", shards = 1, replicas = 0)
public class Item {
@Id
private Long id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title; //标题
@Field(type = FieldType.Keyword)
private String category;// 分类
@Field(type = FieldType.Keyword)
private String brand; // 品牌
@Field(type = FieldType.Double)
private Double price; // 价格
@Field(index = false, type = FieldType.Keyword)
private String images; // 图片地址
}Spring Data通过注解来声明字段的映射属性,有下面的三个注解:
@Document作用在类,标记实体类为文档对象,一般有两个属性- indexName:对应索引库名称
- type:对应在索引库中的类型
- shards:分片数量,默认5
- replicas:副本数量,默认1
@Id作用在成员变量,标记一个字段作为id主键@Field作用在成员变量,标记为文档的字段,并指定字段映射属性:- type:字段类型,取值是枚举:FieldType
- index:是否索引,布尔类型,默认是true
- store:是否存储,布尔类型,默认是false
- analyzer:分词器名称
CRUD基本操作
创建索引和映射
@RunWith(SpringRunner.class)
@SpringBootTest(classes = ItcastElasticsearchApplication.class)
public class IndexTest {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Test
public void testCreate(){
// 创建索引,会根据Item类的@Document注解信息来创建
elasticsearchTemplate.createIndex(Item.class);
// 配置映射,会根据Item类中的id、Field等字段来自动完成映射
elasticsearchTemplate.putMapping(Item.class);
}
}删除索引
@Test
public void deleteIndex() {
esTemplate.deleteIndex("heima");
}
可以根据类名或索引名删除。Repository文档操作
Spring Data 的强大之处,就在于你不用写任何DAO处理,自动根据方法名或类的信息进行CRUD操作。只要你定义一个接口,然后继承Repository提供的一些子接口,就能具备各种基本的CRUD功能。
我们只需要定义接口,然后继承它就OK了。
public interface ItemRepository extends ElasticsearchRepository<Item,Long> {
}新增文档
@Autowired
private ItemRepository itemRepository;
@Test
public void index() {
Item item = new Item(1L, "小米手机7", " 手机",
"小米", 3499.00, "http://image.leyou.com/13123.jpg");
itemRepository.save(item);
}批量新增
@Test
public void indexList() {
List<Item> list = new ArrayList<>();
list.add(new Item(2L, "坚果手机R1", " 手机", "锤子", 3699.00, "http://image.leyou.com/123.jpg"));
list.add(new Item(3L, "华为META10", " 手机", "华为", 4499.00, "http://image.leyou.com/3.jpg"));
// 接收对象集合,实现批量新增
itemRepository.saveAll(list);
}修改文档
修改和新增是同一个接口,区分的依据就是id,这一点跟我们在页面发起PUT请求是类似的。
基本查询
@Test
public void testFind(){
// 查询全部,并安装价格降序排序
Iterable<Item> items = this.itemRepository.findAll(Sort.by(Sort.Direction.DESC, "price"));
items.forEach(item-> System.out.println(item));
}自定义方法
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
比如:你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。
当然,方法名称要符合一定的约定:
| Keyword | Sample | Elasticsearch Query String |
|---|---|---|
And |
findByNameAndPrice |
{"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Or |
findByNameOrPrice |
{"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Is |
findByName |
{"bool" : {"must" : {"field" : {"name" : "?"}}}} |
Not |
findByNameNot |
{"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
Between |
findByPriceBetween |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
LessThanEqual |
findByPriceLessThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
GreaterThanEqual |
findByPriceGreaterThan |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Before |
findByPriceBefore |
{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
After |
findByPriceAfter |
{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Like |
findByNameLike |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
StartingWith |
findByNameStartingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
EndingWith |
findByNameEndingWith |
{"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
Contains/Containing |
findByNameContaining |
{"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}} |
In |
findByNameIn(Collection<String>names) |
{"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
NotIn |
findByNameNotIn(Collection<String>names) |
{"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
Near |
findByStoreNear |
Not Supported Yet ! |
True |
findByAvailableTrue |
{"bool" : {"must" : {"field" : {"available" : true}}}} |
False |
findByAvailableFalse |
{"bool" : {"must" : {"field" : {"available" : false}}}} |
OrderBy |
findByAvailableTrueOrderByNameDesc |
{"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"available" : true}}}} |
例如,我们来按照价格区间查询,定义这样的一个方法:
public interface ItemRepository extends ElasticsearchRepository<Item,Long> {
/**
* 根据价格区间查询
* @param price1
* @param price2
* @return
*/
List<Item> findByPriceBetween(double price1, double price2);
}然后添加一些测试数据:
@Test
public void indexList() {
List<Item> list = new ArrayList<>();
list.add(new Item(1L, "小米手机7", "手机", "小米", 3299.00, "http://image.leyou.com/13123.jpg"));
list.add(new Item(2L, "坚果手机R1", "手机", "锤子", 3699.00, "http://image.leyou.com/13123.jpg"));
list.add(new Item(3L, "华为META10", "手机", "华为", 4499.00, "http://image.leyou.com/13123.jpg"));
list.add(new Item(4L, "小米Mix2S", "手机", "小米", 4299.00, "http://image.leyou.com/13123.jpg"));
list.add(new Item(5L, "荣耀V10", "手机", "华为", 2799.00, "http://image.leyou.com/13123.jpg"));
// 接收对象集合,实现批量新增
itemRepository.saveAll(list);
}不需要写实现类,然后我们直接去运行:
@Test
public void queryByPriceBetween(){
List<Item> list = this.itemRepository.findByPriceBetween(2000.00, 3500.00);
for (Item item : list) {
System.out.println("item = " + item);
}
}虽然基本查询和自定义方法已经很强大了,但是如果是复杂查询(模糊、通配符、词条查询等)就显得力不从心了。此时,我们只能使用原生查询。
高级查询
基本查询
先看看基本玩法
@Test
public void testQuery(){
// 词条查询
MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("title", "小米");
// 执行查询
Iterable<Item> items = this.itemRepository.search(queryBuilder);
items.forEach(System.out::println);
}Repository的search方法需要QueryBuilder参数,elasticSearch为我们提供了一个对象QueryBuilders:
QueryBuilders提供了大量的静态方法,用于生成各种不同类型的查询对象,例如:词条、模糊、通配符等QueryBuilder对象。
elasticsearch提供很多可用的查询方式,但是不够灵活。如果想玩过滤或者聚合查询等就很难了。
自定义查询
先来看最基本的match query:
@Test
public void testNativeQuery(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本的分词查询
queryBuilder.withQuery(QueryBuilders.matchQuery("title", "小米"));
// 执行搜索,获取结果
Page<Item> items = this.itemRepository.search(queryBuilder.build());
// 打印总条数
System.out.println(items.getTotalElements());
// 打印总页数
System.out.println(items.getTotalPages());
items.forEach(System.out::println);
}NativeSearchQueryBuilder:Spring提供的一个查询条件构建器,帮助构建json格式的请求体
Page<item>:默认是分页查询,因此返回的是一个分页的结果对象,包含属性:
- totalElements:总条数
- totalPages:总页数
- Iterator:迭代器,本身实现了Iterator接口,因此可直接迭代得到当前页的数据
- 其它属性:
分页查询
利用NativeSearchQueryBuilder可以方便的实现分页:
@Test
public void testNativeQuery(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本的分词查询
queryBuilder.withQuery(QueryBuilders.termQuery("category", "手机"));
// 初始化分页参数
int page = 0;
int size = 3;
// 设置分页参数
queryBuilder.withPageable(PageRequest.of(page, size));
// 执行搜索,获取结果
Page<Item> items = this.itemRepository.search(queryBuilder.build());
// 打印总条数
System.out.println(items.getTotalElements());
// 打印总页数
System.out.println(items.getTotalPages());
// 每页大小
System.out.println(items.getSize());
// 当前页
System.out.println(items.getNumber());
items.forEach(System.out::println);
}可以发现,**Elasticsearch中的分页是从第0页开始**。
排序
排序也通用通过NativeSearchQueryBuilder完成:
@Test
public void testSort(){
// 构建查询条件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 添加基本的分词查询
queryBuilder.withQuery(QueryBuilders.termQuery("category", "手机"));
// 排序
queryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.DESC));
// 执行搜索,获取结果
Page<Item> items = this.itemRepository.search(queryBuilder.build());
// 打印总条数
System.out.println(items.getTotalElements());
items.forEach(System.out::println);
}聚合
聚合为桶
桶就是分组,比如这里我们按照品牌brand进行分组:
@Test
public void testAgg(){
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 不查询任何结果
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
queryBuilder.addAggregation(
AggregationBuilders.terms("brands").field("brand"));
// 2、查询,需要把结果强转为AggregatedPage类型
AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.itemRepository.search(queryBuilder.build());
// 3、解析
// 3.1、从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation("brands");
// 3.2、获取桶
List<StringTerms.Bucket> buckets = agg.getBuckets();
// 3.3、遍历
for (StringTerms.Bucket bucket : buckets) {
// 3.4、获取桶中的key,即品牌名称
System.out.println(bucket.getKeyAsString());
// 3.5、获取桶中的文档数量
System.out.println(bucket.getDocCount());
}
}关键API:
AggregationBuilders:聚合的构建工厂类。所有聚合都由这个类来构建,看看他的静态方法:
AggregatedPage:聚合查询的结果类。它是Page<T>的子接口:
AggregatedPage在Page功能的基础上,拓展了与聚合相关的功能,它其实就是对聚合结果的一种封装,大家可以对照聚合结果的JSON结构来看。
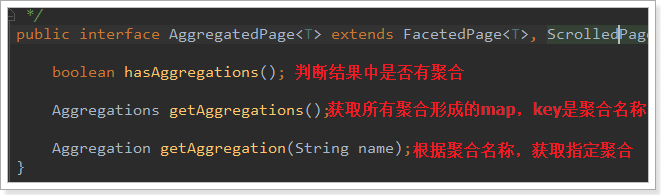
而返回的结果都是Aggregation类型对象,不过根据字段类型不同,又有不同的子类表示
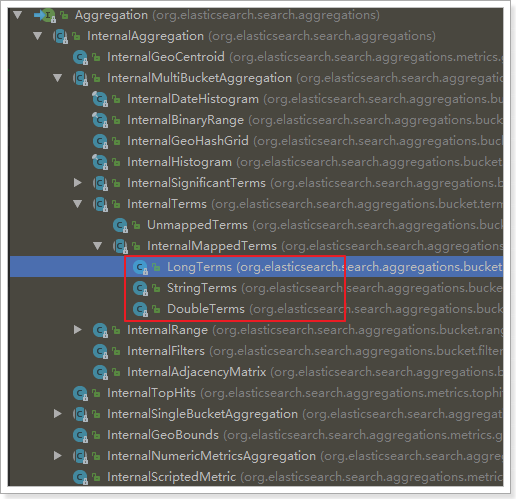
我们看下页面的查询的JSON结果与Java类的对照关系:

嵌套聚合,求平均值
@Test
public void testSubAgg(){
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 不查询任何结果
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null));
// 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand
queryBuilder.addAggregation(
AggregationBuilders.terms("brands").field("brand")
.subAggregation(AggregationBuilders.avg("priceAvg").field("price")) // 在品牌聚合桶内进行嵌套聚合,求平均值
);
// 2、查询,需要把结果强转为AggregatedPage类型
AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.itemRepository.search(queryBuilder.build());
// 3、解析
// 3.1、从结果中取出名为brands的那个聚合,
// 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型
StringTerms agg = (StringTerms) aggPage.getAggregation("brands");
// 3.2、获取桶
List<StringTerms.Bucket> buckets = agg.getBuckets();
// 3.3、遍历
for (StringTerms.Bucket bucket : buckets) {
// 3.4、获取桶中的key,即品牌名称 3.5、获取桶中的文档数量
System.out.println(bucket.getKeyAsString() + ",共" + bucket.getDocCount() + "台");
// 3.6.获取子聚合结果:
InternalAvg avg = (InternalAvg) bucket.getAggregations().asMap().get("priceAvg");
System.out.println("平均售价:" + avg.getValue());
}
}
关于SpringBoot+Netty+Elasticsearch收集日志信息数据存储和spring boot日志收集的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于ElasticSearch (2)---SpringBoot 整合 ElasticSearch、ElasticSearch - 学习笔记 02-springboot 整合 jestclient 操作 elasticSearch、elasticsearch 整合springboot、elasticsearch 集成springboot的相关信息,请在本站寻找。
本文标签:




