这篇文章主要围绕SpringCloud与微服务Ⅱ---微服务概述和springcloud与微服务关系展开,旨在为您提供一份详细的参考资料。我们将全面介绍SpringCloud与微服务Ⅱ---微服务概述
这篇文章主要围绕SpringCloud与微服务Ⅱ --- 微服务概述和springcloud与微服务关系展开,旨在为您提供一份详细的参考资料。我们将全面介绍SpringCloud与微服务Ⅱ --- 微服务概述的优缺点,解答springcloud与微服务关系的相关问题,同时也会为您带来(七十一) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之使用Zuul聚合多个微服务的Swagger文档、(七十三) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之Spring Cloud服务限流详解、(七十二) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之微服务架构下如何获取用户信息并认证?、(七十四) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之服务降级是什么?Spring Cloud如何实现?的实用方法。
本文目录一览:- SpringCloud与微服务Ⅱ --- 微服务概述(springcloud与微服务关系)
- (七十一) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之使用Zuul聚合多个微服务的Swagger文档
- (七十三) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之Spring Cloud服务限流详解
- (七十二) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之微服务架构下如何获取用户信息并认证?
- (七十四) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之服务降级是什么?Spring Cloud如何实现?
")
SpringCloud与微服务Ⅱ --- 微服务概述(springcloud与微服务关系)
一.什么是微服务
1) Martin Fowler论文对微服务的阐述(中文版)
2) 对单一应用进行拆分
3) 每一个独立的应用都有一个独立的进程
4) 拥有自己独立的数据库
5) 微服务化的核心就是讲传统的一站式应用,根据业务拆分成一个一个的服务,彻底地去耦合,每一个微服务提供单个业务功能的服务,一个服务处理一件事,从技术角度就是一种小而独立的处理过程,类似进程的概念,能够自行单独启动或销毁,拥有自己的数据库。
二.微服务与微服务架构
2.1 微服务架构
1) 类似于eclipse工具里面用maven开发的一个个独立的module,具体是使用springboot开发的一个小模块,一个模块就做一件功能。
2) 强调是整体,每一个个体完成一个具体的任务或者功能,把一个个的个体拼接起来,组成一个整体并对外暴露服务。
3) 微服务架构是一种架构模式,它提倡将单一的应用程序划分成一组小的服务,服务之间互相协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务与服务间采用轻量级的通信机制互相协作(通常是基于HTTP协议的RESTful API)。每个服务都围绕着具体业务进行构建,并且能够被独立的部署到生产环境、类生产环境等。另外,应当尽量避免统一的、集中式的服务管理机制。对具体的一个服务而言,应根据业务的上下文,选择合适的语言、工具对其进行构建。
2.2 微服务
强调的是服务的大小,它关注的是某一个点,是具体解决某一个问题/提供落地对应服务的一个服务应用,狭义地看,可以看做Eclipse里面的一个个微服务工程或者Module。
注意,微服务、微服务架构、Spring Cloud是三种不同的概念,不要弄混淆。
三.微服务的优缺点
3.1 微服务的优点
1) 每个服务足够内聚,足够小,代码容易理解这样能聚焦一个指定的业务。单机版的应用由于很多业务耦合在一起,修改代码时往往需要读懂一整块的业务功能,而微服务项目只需要了解其中一小块,由于项目足够小并且都是独立的,代码更容易理解,也更容易维
2) 开发简单,开发效率提高,精力集中,一个服务只做一件事。
3) 小团队也能单独开发,管理容易,管理成本降低。
4) 微服务是松耦合的,是有功能意义的服务,无论是在开发阶段还是在部署阶段都是独立的,这样可以防止某个项目出问题了其他服务项目不会受到影响。
5) 微服务能使用不同语言开发。
6) 易于和第三方集成,微服务允许容易且灵活的方式集成自动部署,通过持续集成工具,例如Jenkins,Hudson,bamboo。
7) 微服务易于被一个开发人员理解,修改和维护,这样小团队能够更关注自己的工作成果。无需通过合作才能体现价值。
8) 微服务允许你利用融合最新技术。
9) 微服务只是业务逻辑代码,不会和HTML,CSS或其他界面组件混合。
10) 每个微服务都有自己的存储能力,可以有自己的数据库,也可以有统一的数据库。可以灵活搭配,连接公共库+连接独立库。
3.2 微服务的缺点
1) 开发人员需要处理分布式系统的复杂性。
2) 多服务运维难度,随着服务的增加,运维的压力也在增大。
3) 系统部署依赖,一个模块调不通有可能影响到其他模块的使用。
4) 服务间通信成本变高。
5) 数据的一致性问题。
6) 系统集成测试变复杂。
7) 性能监控变困难。
四.微服务的技术栈有哪些
微服务技术栈是多种技术的集合体。
-
服务开发:Spring Boot、Spring、Spring MVC
-
服务的配置与管理:Netflix公司的Archaius、阿里的Diamond等
-
服务注册与发现:Eureka、Consul、Zookeeper等
-
服务调用:Rest、RPC、gRPC
-
服务熔断器:Hystrix、Envoy等
-
服务负载均衡:Ribbon、Nginx等
-
服务接口调用(客户端调用服务的简化工具):Feign等
-
消息队列:Kafka、RabbitMQ、ActiveMQ等
-
服务配置中心管理:SpringCloudConfig、Chef等
-
服务路由(API):Zuul等
-
服务监控:Zabbix、Nagios、Metrics、Spectator等
-
全链路追踪:Zipkin、Brave、Dapper等
-
服务部署:Docker、OpenStack、Kubernetes等
-
数据操作开发包:SpringCloud Stream(封装Redis、RabbitMQ、Kafka等发送接收消息)
-
事件消息总栈:Spring Cloud Bus
五.分布式框架的对比
-
选型依据
-
整体解决方案和框架成熟度
-
社区热度
-
可维护性
-
学习曲线
-
-
当前IT公司用的微服务架构有哪些?
-
阿里Dubbo/HSF
-
京东JSF
-
新浪微博Motan
-
当当网DubboX
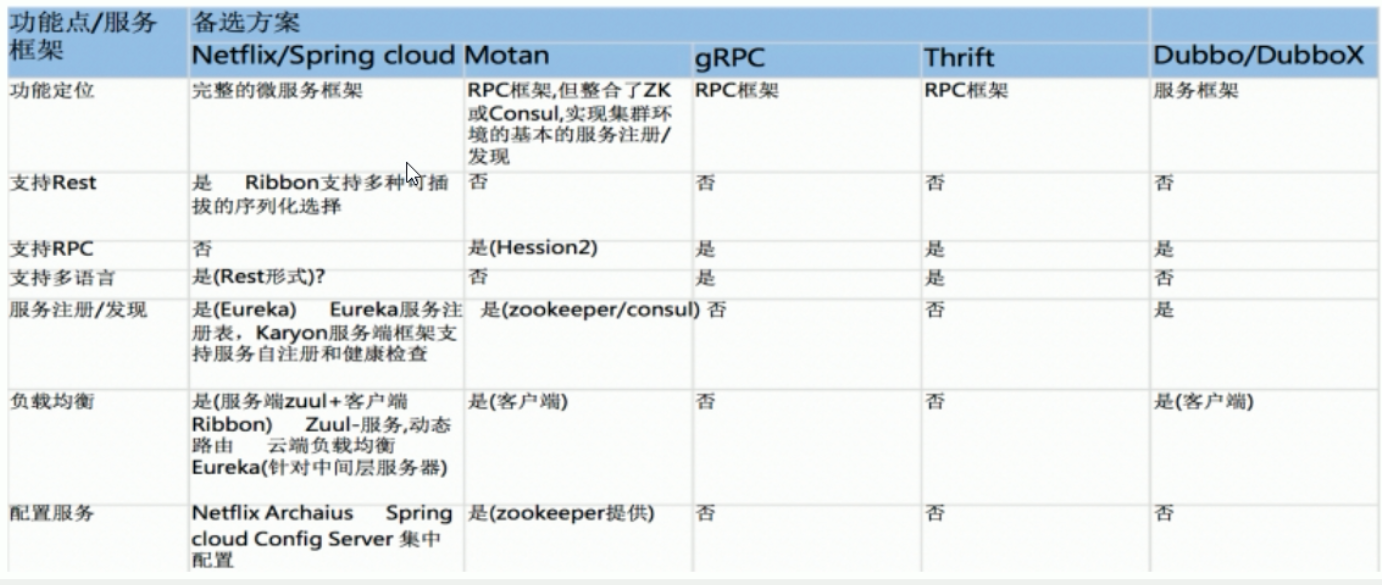

结论:SpringCloud满足几乎所有的微服务技术维度要求。
 springcloud+springcloud+vue+uniapp分布式微服务电商 商城之使用Zuul聚合多个微服务的Swagger文档")
(七十一) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之使用Zuul聚合多个微服务的Swagger文档
在 Zuul 中进行聚合操作的原因是不想每次都去访问独立服务的文档,通过网关统一整合这些服务的文档方便使用。
在网关中加入 Swagger 的Maven 依赖,代码如下所示。
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>自定义配置进行整合,笔者采用了一种比较简单的方式,不是手动的去配置要整合的服务信息,而是直接去读取 Eureka 中的服务信息,只要是 Eureka 中的服务就都能整合进来,代码如下所示。
@EnableSwagger2
@Component
@Primary
public class DocumentationConfig implements SwaggerResourcesProvider {
@Autowired
private DiscoveryClient discoveryClient;
@Value("${spring.application.name}")
private String applicationName;
@Override
public List<SwaggerResource> get() {
List<SwaggerResource> resources = new ArrayList<>();
// 排除自身, 将其他的服务添加进去
discoveryClient.getServices().stream().filter(s -> !s.equals(applicationName)).forEach(name -> {
resources.add(swaggerResource(name, "/" + name + "/v2/api-docs", "2.0"));
});
return resources;
}
private SwaggerResource swaggerResource(String name, String location, String version) {
SwaggerResource swaggerResource = new SwaggerResource();
swaggerResource.setName(name);
swaggerResource.setLocation(location);
swaggerResource.setSwaggerVersion(version);
return swaggerResource;
}
}推荐电子商务源码
 springcloud+springcloud+vue+uniapp分布式微服务电商 商城之Spring Cloud服务限流详解")
(七十三) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之Spring Cloud服务限流详解
高并发系统中有三把利器用来保护系统:缓存、降级和限流。限流的目的是为了保护系统不被大量请求冲垮,通过限制请求的速度来保护系统。在电商的秒杀活动中,限流是必不可少的一个环节。
限流的方式也有多种,可以在 Nginx 层面限流,也可以在应用当中限流,比如在 API 网关中。
限流算法
常见的限流算法有:令牌桶、漏桶。计数器也可以进行限流实现。
1)令牌桶
令牌桶算法是一个存放固定容量令牌的桶,按照固定速率往桶里添加令牌。可以控制流量也可以控制并发量,假如我们想要控制 API 网关的并发量最高为 1000,可以创建一个令牌桶,以固定的速度往桶里添加令牌,超出了 1000 则不添加。
当一个请求到达之后就从桶中获取一个令牌,如果能获取到令牌就可以继续往下请求,获取不到就说明令牌不够,并发量达到了最高,请求就被拦截。
2)漏桶
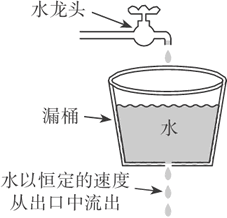
漏桶是一个固定容量的桶,按照固定的速率流出,可以以任意的速率流入到漏桶中,超出了漏桶的容量就被丢弃,总容量是不变的。但是输出的速率是固定的,无论你上面的水流入的多快,下面的出口只有这么大,就像水坝开闸放水一样,如图 1 所示。
单节点限流
单节点限流指的是只对这个节点的并发量进行控制,相对于集群限流来说单节点限流比较简单,稳定性也好,集群限流需要依赖第三方中间件来存储数据,单节点限流数据存储在本地内存中即可,风险性更低。
从应用的角度来说单节点的限流就够用了,如果我们的应用有 3 个节点,总共能扛住 9000 的并发,那么单个节点最大能扛住的量就是 3000,只要单个节点扛住了就没什么问题了。
我们可以用上面讲的令牌桶算法或者漏桶算法来进行单节点的限流操作,算法的实现可以使用 Google Guava 中提供的算法实现类。实际使用中令牌桶算法更适合一些,当然这个得参考业务需求,之所以选择令牌桶算法是因为它可以处理突发的流量,漏桶算法就不行,因为漏桶的速率是固定的。
首先需要依赖 Guava,其实也可以不用,在 Spring Cloud 中好多组件都依赖了 Guava,如果你的项目是 Spring Cloud 技术栈的话可以不用自己配置,间接就已经依赖了,代码如下所示。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>创建一个限流的过滤器,order 返回 0,执行优先级第一,代码如下所示。
public class LimitFilter extends ZuulFilter {
public static volatile RateLimiter rateLimiter = RateLimiter.create(100.0);
public LimitFilter() {
super();
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public Object run() {
// 总体限流rateLimiter.acquire();
return null;
}
}注册限流过滤器,代码如下所示。
@Bean
public LimitFilter limitFilter() {
return new LimitFilter();
}上面的方案有一个致命的问题就是速率值是写死的,往往我们需要根据服务器的配置以及当时的并发量来设置一个合理的值,那么就需要速率这个值能够实时修改,并且生效,这时配置中心又派上用场了。
添加 Apollo 的配置,代码如下所示。
@Data
@Configuration
public class BasicConf {
@Value("${limitRate:10}")
private double limitRate;
}有一个问题是当这个值修改的时候需要重新初始化 RateLimiter,在配置类中实现修改回调的方法代码如下所示。
@Data
@Configuration
public class BasicConf {
@Value("${limitRate:10}")
private double limitRate;
@ApolloConfig
private Config config;
@ApolloConfigChangeListener
public void onChange(ConfigChangeEvent changeEvent) {
if (changeEvent.isChanged("limitRate")) {
// 更 新 RateLimiter
LimitFilter.rateLimiter = RateLimiter.create(config.getDoubleProperty("limitRate", 10.0));
}
}
}我们可以用 ab 来测试一下接口,代码如下所示。
ab -n 1000 -c 30 http://192.168.10.170:2103/fsh-house/house/1
Benchmarking 192.168.10.170 (be patient)
Completed 100 requests
Completed 200 requests
Completed 300 requests
Completed 400 requests
Completed 500 requests
Completed 600 requests
Completed 700 requests
Completed 800 requests
Completed 900 requests
Completed 1000 requests
Finished 1000 requests
Server Software:
Server Hostname: 192.168.10.170
Server Port: 2103
Document Path: /fsh-house/house/1
Document Length: 796 bytes
Concurrency Level: 30
Time taken for tests: 98.989 seconds
Complete requests: 1000
Failed requests: 6
(Connect: 0, Receive: 0, Length: 6, Exceptions: 0)
Total transferred: 1001434 bytes
HTML transferred: 833434 bytes
Requests per second: 10.10 [#/sec] (mean) Time per
request: 2969.679 [ms] (mean) Time per
request: 98.989 [ms] (mean, across all concurrent requests)
Transfer rate: 9.88 [Kbytes/sec] received
- -n 1000 表示总共请求 1000 次
- -c 30 表示并发数量
我们可以看到执行完这 1000 次请求总共花费了 98 秒,Time taken for tests 就是请求所花费的总时间,这是在限流参数为 10 的情况下,我们还可以把参数调到 100 然后测试一下,代码如下所示。
ab -n 1000 -c 30 http://192.168.10.170:2103/fsh-house/house/1
Benchmarking 192.168.10.170 (be patient) Completed 100
requests Completed 200
requests Completed 300
requests Completed 400
requests Completed 500
requests Completed 600
requests Completed 700
requests Completed 800
requests Completed 900
requests Completed 1000 requests Finished 1000 requests Server Software:
Server Hostname: 192.168.10.170
Server Port: 2103
Document Path: /fsh-house/house/1
Document Length: 7035 bytes
Concurrency Level: 30
Time taken for tests: 9.061 seconds
Complete requests: 1000
Failed requests: 30
(Connect: 0, Receive: 0, Length: 30, Exceptions: 0)
Total transferred: 7015830 bytes
HTML transferred: 6847830 bytes
Requests per second: 110.37 [#/sec] (mean)
Time per request: 271.821 [ms] (mean)
Time per request: 9.061 [ms] (mean, across all concurrent requests)
Transfer rate: 756.17 [Kbytes/sec] received
限流的参数调大后,请求 9 秒就完成了,这就证明我们的限流操作起作用了。
集群限流
集群限流可以借助Redis 来实现,至于实现的方式也有很多种,下面我们介绍一种比较简单的限流方式。
我们可以按秒来对并发量进行限制,比如整个集群中每秒只能访问 1000 次。我们可以利用计数器来判断,Redis 的 key 为当前秒的时间戳,value 就是访问次数的累加,当次数超出了我们限制的范围内,直接拒绝即可。需要注意的是集群中服务器的时间必须一致才能没有误差,下面我们来看代码。
首先在我们的 API 网关中集成 Redis 的操作,我们引入 Spring Data Redis 来操作 Redis,代码如下所示。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>属性配置文件中配置 Redis 的连接信息
spring.redis.host=192.168.10.47
spring.redis.port=6379
集成后就直接可以使用 RedisTemplate 来操作 Redis 了,这里配置了一个 RedisTemplate,key 为 String 类型,value 为 Long 类型,用来计数,代码如下所示。
@Configuration
public class RedisConfig {
@Bean(name = "longRedisTemplate")
public RedisTemplate<String, Long> redisTemplate(RedisConnectionFactory jedisConnectionFactory) {
RedisTemplate<String, Long> template = new RedisTemplate<String, Long>();
template.setConnectionFactory(jedisConnectionFactory);
template.setKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(new GenericToStringSerializer<Long>(Long.class));
template.setValueSerializer(new GenericToStringSerializer<Long>(Long.class));
return template;
}
}在之前的限流类的配置中增加集群限流的速率配置,代码如下所示。
@Data
@Configuration
public class BasicConf {
@Value("${clusterLimitRate:10}")
private double clusterLimitRate;
}接下来我们改造之前单体限流用的过滤器 LimitFilter,采用 Redis 来进行限流操作,代码如下所示。
public class LimitFilter extends ZuulFilter {
private Logger log = LoggerFactory.getLogger(LimitFilter.class);
public static volatile RateLimiter rateLimiter = RateLimiter.create(100);
@Autowired
@Qualifier("longRedisTemplate")
private RedisTemplate<String, Long> redisTemplate;
@Autowired
private BasicConf basicConf;
public LimitFilter() {
super();
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
Long currentSecond = System.currentTimeMillis() / 1000;
String key = "fsh-api-rate-limit-" + currentSecond;
try {
if (!redisTemplate.hasKey(key)) {
redisTemplate.opsForValue().set(key, 0L, 100, TimeUnit.SECONDS);
}
int rate = basicConf.getClusterLimitRate();
// 当集群中当前秒的并发量达到了设定的值, 不进行处理
// 注意集群中的网关与所在服务器时间必须同步
if (redisTemplate.opsForValue().increment(key, 1) > rate) {
ctx.setSendZuulResponse(false);
ctx.set("isSuccess", false);
ResponseData data = ResponseData.fail("当前负载太高,请稍后重试", ResponseCode.LIMIT_ERROR_CODE.getCode());
ctx.setResponseBody(JsonUtils.toJson(data));
ctx.getResponse().setContentType("application/json;charset=utf-8");
return null;
}
} catch (Exception e) {
log.error("集群限流异常", e);
// Redis 挂掉等异常处理,可以继续单节点限流
// 单节点限流
rateLimiter.acquire();
}
return null;
}
}我们来看看 run 方法里面的逻辑,首先我们是获取了当前时间的时间戳然后转换成秒,定义了一个 Redis 的 key。判断这个 key 是否存在,不存在则插入一个,初始值为 0,然后通过 increment 来为这个 key 累加计数,并获取累加之后的值,increment 是原子性的,不会有并发问题,如果当前秒的数量超出了我们设定的值那就说明当前的并发量已经达到了极限值,然后直接拒绝请求。
这里还需要进行异常处理,前文推荐用单节点限流的方式来进行就是因为集群性质的限流需要依赖第三方中间件,如果中间件挂了,那么就会影响现有的业务,这里需要处理的是如果操作 Redis 出异常了怎么办?
首先是进行集群的限流,如果 Redis 出现挂了之类的问题,捕获到异常之后立刻启用单节点限流,进行双重保护。当然必须有完整的监控系统,当 Redis 出现问题之后必须马上处理。Redis 在生产环境中必须用集群,当然集群也有可能会出问题,所以单节点限流是一种比较好的方案。
具体服务限流
前面我们学习了如何进行单节点的限流和集群的限流。虽然抗住了整体的并发量,但是会有一个弊端,如果这些并发量都是针对一个服务的,那么这个服务还是会扛不住的,针对具体的服务做具体的限制才是最好的选择。
基于前面的基础,要针对具体的服务做限制是比较简单的事情,针对单节点限流我们的做法如下。
之前是用一个 RateLimiter 来防止整体的并发量,针对具体服务的前期是需要知道当前的请求会被转发到哪个服务里去,知道了这个我们只需要为每个服务创建一个 RateLimiter,不同的服务用不同的 RateLimiter 就可以实现具体服务的限制了。
集群的限流是通过时间的秒作为 key 来计数实现的,如果是针对具体的服务,只需要把服务名称加到 key 中就可以了,即一个服务就是一个 key,限流的操作自然而然是针对具体的服务。
可以用 Zuul 提供的 Route Filter 来做,在 Route Filter 中可以直接获取当前请求是要转发到哪个服务,代码如下所示。
RequestContext ctx = RequestContext.getCurrentContext();
Object serviceId = ctx.get("serviceId");
serviceId 就是 Eureka 中注册的服务名称。
具体接口限流
即使我们做了整体的集群限流,如果某个服务的具体限流持续并发量很大且是同一个接口,那么还会影响到其他接口的使用,华章所有的资源都被这一个接口占用了,其他的接口请求过来只能等待或者抛弃,所以我们需要将限流做得更细,可以针对具体的 API 接口进行并发控制。
具体的接口控制并发量我们将这个控制放到具体的服务中,之所以不放到 API 网关去做控制是因为 API 的量太大了,如果统一到 API 网关来控制那么需要配置很多 API 的并发量信息,如果放到具体的服务上,我们可以通过注解的方式在接口的方法上做文章,添加一个注解就可以实现并发控制,还可以结合我们的 Apollo 来做动态修改,当然也可以在 API 网关做,笔者推荐在具体的服务上做。
首先我们定义一个注解,用来标识某个接口需要进行并发控制,这个注解是通用的,可以放在公共的库中。在注解中定义一个 confKey,这个 key 对应的是 Apollo 中的配置 key,也就是说我们这个并发的数字不写死,而是通过 Apollo 来做关联,到时候可以动态修改,实时生效,代码如下所示。
/**
* 对 API 进行访问速度限制
* 限制的速度值在Apollo配置中通过 key 关联
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface ApiRateLimit {
/**
* Apollo配置中的 key
*
* @return
*/
String confKey();
}接下来我们定义一个启动监听器,这个也是通用的,可以放在公共库中。这个启动监听器的主要作用就是扫描所有的 API 接口类,也就是我们的 Controller。
获取 Controller 中所有加了 ApiRateLimit 注解的信息,然后进行初始化操作,控制并发我们这里用 JDK 自带的 Semaphore 来实现,当然你也可以用之前讲的 RateLimiter,代码如下所示。
@Component
public class InitApiLimitRateListener implements ApplicationContextAware {
public void setApplicationContext(ApplicationContext ctx) throws BeansException {
Environment environment = ctx.getEnvironment();
String defaultLimit = environment.getProperty("open.api.defaultLimit");
Object rate = defaultLimit == null ? 100 : defaultLimit;
ApiLimitAspect.semaphoreMap.put("open.api.defaultLimit", new Semaphore(Integer.parseInt(rate.toString())));
Map<String, Object> beanMap = ctx.getBeansWithAnnotation(RestController.class);
Set<String> keys = beanMap.keySet();
for (String key : keys) {
Class<?> clz = beanMap.get(key).getClass();
String fullName = beanMap.get(key).getClass().getName();
if (fullName.contains("EnhancerBySpringCGLIB") || fullName.contains("$$")) {
fullName = fullName.substring(0, fullName.indexOf("$$"));
try {
clz = Class.forName(fullName);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
Method[] methods = clz.getMethods();
for (Method method : methods) {
if (method.isAnnotationPresent(ApiRateLimit.class)) {
String confKey = method.getAnnotation(ApiRateLimit.class).confKey();
if (environment.getProperty(confKey) != null) {
int limit = Integer.parseInt(environment.getProperty(confKey));
ApiLimitAspect.semaphoreMap.put(confKey, new Semaphore(limit));
}
}
}
}
}
}上面的代码就是初始化的整个逻辑,在最开始的时候就是获取 open.api.defaultLimit 的值,那么这个值会配置在 Apollo 中,如果没有则给予一个默认值。open.api.defaultLimit 是考虑到并不是所有的接口都需要配置具体的限制并发的数量,所以给了一个默认的限制,也就是说没有加 ApiRateLimit 注解的接口就用这个默认的并发限制。
拿到所有的 Controller 类的信息,通过判断类上是否有 RestController 注解来确定这就是一个接口,然后获取类中所有的方法,获取方法上有 ApiRateLimit 注解的 key,通过 key获取配置的值,然后 new 一个 Semaphore 存入控制并发的切面的 map 中,切面下面会定义。
通过切面来对访问的接口进行并发控制,当然也可以用拦截器、过滤器之类的,切面也是共用的,可以放公共库中,代码如下所示。
/**
* 具体 API 并发控制
*/
@Aspect
@Order(value = Ordered.HIGHEST_PRECEDENCE)
public class ApiLimitAspect {
public static Map<String, Semaphore> semaphoreMap = new ConcurrentHashMap<String, Semaphore>();
@Around("execution(*com.biancheng.*.*.controller.*.*(..))")
public Object around(ProceedingJoinPoint joinPoint) {
Object result = null;
Semaphore semap = null;
Class<?> clazz = joinPoint.getTarget().getClass();
String key = getRateLimitKey(clazz, joinPoint.getSignature().getName());
if (key != null) {
semap = semaphoreMap.get(key);
} else {
semap = semaphoreMap.get("open.api.defaultLimit");
}
try {
semap.acquire();
result = joinPoint.proceed();
} catch (Throwable e) {
throw new RuntimeException(e);
} finally {
semap.release();
}
return result;
}
private String getRateLimitKey(Class<?> clazz, String methodName) {
for (Method method : clazz.getDeclaredMethods()) {
if (method.getName().equals(methodName)) {
if (method.isAnnotationPresent(ApiRateLimit.class)) {
String key = method.getAnnotation(ApiRateLimit.class).confKey();
return key;
}
}
}
return null;
}
}整个切面中的代码量不多,但是作用非常大,所有接口的请求都将会经过它,这是一个环绕通知。
第一行是一个 ConcurrentHashMap,用来存储我们之前在监听器里面初始化好的 Semaphore 对象,需要重点关注的是 around 中的逻辑。
首先获取当前访问的目标对象以及方法名称,通过 getRateLimitKey 获取当前访问的方法是否有限制并发的 key,通过 key 从 semaphoreMap 中获取对应的 Semaphore 对象做并发限制。
配置进行并发控制的切面,代码如下所示。
@Configuration
public class BeanConfig {
/**
* 具体的 API 并发控制
*
* @return
*/
@Bean
public ApiLimitAspect apiLimitAspect() {
return new ApiLimitAspect();
}
}到这里整个限制的流程就结束了。启动服务,可以用并发测试工具 Apache ab 来测试效果。将并发数量配置为 1,测试请求 1000 次看需要多长时间,然后调大并发数量,再次请求,虽然比较耗时,但我们可以发现并发配置数量越小的耗时时间越长,这就证明并发控制生效了。
目前没有加我们自定义的注解,所有的接口都是用默认的并发控制数量,如果我们想对某个接口单独做并发控制,只需要在方法上加上 ApiRateLimit 注解即可,具体代码如下所示。
/**
* 获取房产信息
*
* @param houseId 房产编号
* @return
*/
@ApiRateLimit(confKey = "open.api.hosueInfo")
@GetMapping("/{houseId}")
public ResponseData hosueInfo(@PathVariable("houseId") Long houseId, HttpServletRequest request) {
String uid = request.getHeader("uid");
System.err.println("===" + uid);
return ResponseData.ok(houseService.getHouseInfo(houseId));
}ApiRateLimit 中配置的 confKey 要和 Apollo 配置中的 key 对应才行。目前限流的信号量对象是在启动时进行初始化的,如果需要实现在 Apollo 中动态新增或者修改配置也能生效的话,需要对配置的修改进行监听,然后动态创建信号量对象添加到 semaphoreMap 中。
推荐电子商务源码
 springcloud+springcloud+vue+uniapp分布式微服务电商 商城之微服务架构下如何获取用户信息并认证?")
(七十二) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之微服务架构下如何获取用户信息并认证?
在传统的单体项目中,我们对用户的认证通常就在项目里面,当拆分成微服务之后,一个业务操作会涉及多个服务。那么怎么对用户做认证?服务中又是如何获取用户信息的?这些操作都可以在 API 网关中实现。
动态管理不需要拦截的 API 请求
并不是所有的 API 都需要认证,比如登录接口。我们需要一个能够动态添加 API 白名单的功能,凡是在这个白名单当中的,我们就不做认证。这个配置信息需要能够实时生效,这就用上了我们的配置管理 Apollo。
在 API 网关中创建一个 Apollo 的配置类,代码如下所示。
@Data
@Configuration
public class BasicConf {
// API接口白名单, 多个用逗号分隔
@Value("${apiWhiteStr:/zuul-extend-user-service/user/login}")
private String apiWhiteStr;
}编写认证的 Filter,代码如下所示。
/**
* 认证过滤器
**/
public class AuthFilter extends ZuulFilter {
@Autowired
private BasicConf basicConf;
public AuthFilter() {
super();
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 1;
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
String apis = basicConf.getApiWhiteStr();
// 白名单,放过
List<String> whileApis = Arrays.asList(apis.split(","));
String uri = ctx.getRequest().getRequestURI();
if (whileApis.contains(uri)) {
return null;
}
// path uri 处 理
for (String wapi : whileApis) {
if (wapi.contains("{"} && wapi.contains(")")) {
if (wapi.split("/").length == uri.split("/").length) {
String reg = wapi.replaceAll("\\{.*}", ".*{1,}");
Pattern r = Pattern.compile(reg);
Matcher m = r.matcher(uri);
if (m.find()) {
return null;
}
}
}
}
return null;
}
}在 Filter 中注入我们的 BasicConf 配置,在 run 方法里面执行判断的逻辑,将配置的白名单信息转成 List,然后判断当前请求的 URI 是否在白名单中,存在则放过。
下面还有一段是 Path URI 的处理,这是解决 /user/{userId} 这种类型的 URI,URI 中有动态的参数,直接匹配是否相等肯定是不行的。
最后配置 Filter 即可启用,代码如下所示。
@Bean
public AuthFilter authFilter() {
return new AuthFilter();
}当有不需要认证的接口时,直接在 Apollo 后台修改一下配置信息即可实时生效。
创建认证的用户服务
用户服务是每个产品必备的一个服务,可以管理这个产品的用户信息。我们用到的用户服务只是演示认证,所以只提供一个登录的接口即可。
登录接口代码如下所示。
/**
* 用户登录
*
* @param query
* @return
*/
@ApiOperation(value = "用户登录", notes = "企业用户认证接口,参数为必填项")
@PostMapping("/login")
public ResponseData login(@ApiParam(value = "登录参数", required = true) @RequestBody LoginQuery query) {
if (query == null || query.getEid() == null || StringUtils.isBlank(query.getUid())) {
return ResponseData.failByParam("eid 和 uid 不能为空");
}
return ResponseData.ok(enterpriseProductUserService.login(query.getEid(), query.getUid()));
}Service 中的 login 方法用来判断是否成功登录,成功则用 JWT 将用户 ID 加密返回一个 Token。此处只是为了模拟,真实环境中需要去查数据库,代码如下所示。
public String login(Long eid, String uid) {
JWTUtils jwtUtils = JWTUtils.getInstance();
if (eid.equals(1L) && uid.equals("1001")) {
return jwtUtils.getToken(uid);
}
return null;
}路由之前的认证
除了我们之前讲解的,一些 API 由于特殊的需求,不需要做认证,我们可以用配置的方式来放行,其余的都需要认证,只有合法登录后的用户才能调用。当用户调用用户服务中的登录接口,登录成功之后就能拿到 Token,在请求其他的接口时带上 Token,就可以在 Zuul 的 Filter 中对这个 Token 进行认证。
验证逻辑和之前的 API 白名单是在一个 Filter 中进行的,在 path uri 处理之后进行认证,代码如下所示。
// 验证 TOKEN
if (!StringUtils.hasText(token)) {
ctx.setSendZuulResponse(false);
ctx.set("isSuccess", false);
ResponseData data = ResponseData.fail("非法请求【缺少 Authorization 信息】", ResponseCode.NO_AUTH_CODE.getCode());
ctx.setResponseBody(JsonUtils.toJson(data));
ctx.getResponse().setContentType("application/json; charset=utf-8");
return null;
}
JWTUtils.JWTResult jwt = jwtUtils.checkToken(token);
if (!jwt.isStatus()) {
ctx.setSendZuulResponse(false);
ctx.set("isSuccess", false);
ResponseData data = ResponseData.fail(jwt.getMsg(), jwt.getCode());
ctx.setResponseBody(JsonUtils.toJson(data));
ctx.getResponse().setContentType("application/json; charset=utf-8");
return null;
}
ctx.addZuulRequestHeader("uid", jwt.getUid());从请求头中获取 Token,如果没有就拦截并给出友好提示,设置 isSuccess=false 告诉下面的 Filter 不需要执行了。有 Token 则验证 Token 的合法性,合法则放行,不合法就拦截并给出友好提示。
向下游微服务中传递认证之后的用户信息
传统的单体项目中我们通常都是使用 Session 来存储登录后的用户信息,但这样会导致做了集群后的用户信息有问题,在 A 服务上登录了,下次被转发到 B 服务区,又得重新登录一次。为了解决这个问题,通常采用 Session 共享的方式来解决,比如Spring Session 这种框架。
在微服务下如何解决这个问题呢?为了提高并发性能,方便快速扩容,服务都被设计成了无状态的,不需要对每个服务都进行用户是否登录的判断,只需要统一在 API 网关中认证好即可。
在 API 网关中认证之后如何把用户信息传递给下方的服务就是我们需要关注的了,在 Zuul 中可以将认证之后的用户信息通过请求头的方式传递给下方服务,比如如下代码所示的方式。
ctx.addZuulRequestHeader("uid", jwt.getUid());在具体的服务中就可以通过 request 对象来获取传递过来的用户信息,代码如下所示。
@GetMapping("/article/callHello")
public String callHello() {
System.err.println("用户ID:" + request.getHeader("uid"));
return userRemoteClient.hello();
}内部服务间的用户信息传递
关于用户信息的传递问题,我们知道从 API 网关过来的请求,经过认证之后是可以拿到认证后的用户 ID,这时候我们可以通过 addZuulRequestHeader 的方式将用户 ID 传递到我们转发的服务上去,但如果从网关转发到 A 服务,A 服务需要调用 B 服务的接口,那么我想在 B 服务中也能通过 request.getHeader("uid") 去获取用户 ID,这个时候该怎么处理?
关于这种需求,我的建议是直接通过网关转发过去的接口。我们可以通过 request.getHeader("uid") 来获取网关带过来的用户 ID,然后服务之前调用的话可以通过参数的方式告诉被调用的服务,A 服务调用 B 服务的 hello 接口,那么 hello 接口中增加一个 uid 的参数即可,此时的用户 ID 是网关给我们的,已经是认证过的了,可以直接使用。
如果想做成类似于 Session 共享的方式也可以,那么当 A 服务调用 B 服务时,你就得通过在框架层面将用户 ID 传递到 B 服务当中,但是这个不能让每个开发人员去关心,必须封装成统一的处理。
我们可以这样做,首先我们的场景是 API 网关中会通过请求头将用户 ID 传递到转发的服务中,那么我们可以通过过滤器来获取这个值,然后进行传递操作,代码如下所示。
public class HttpHeaderParamFilter implements Filter {
@Override
public void init(FilterConfig filterConfig) throws ServletException {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest httpRequest = (HttpServletRequest) request;
HttpServletResponse httpResponse = (HttpServletResponse) response;
httpResponse.setCharacterEncoding("UTF-8");
httpResponse.setContentType("application/json; charset=utf-8");
String uid = httpRequest.getHeader("uid");
RibbonFilterContextHolder.getCurrentContext().add("uid", uid);
chain.doFilter(httpRequest, response);
}
@Override
public void destroy() {
}
}RibbonFilterContextHolder 是通过 InheritableThreadLocal 在线程之间进行数据传递的。这步走完后请求就转发到了我们具体的接口上面,然后这个接口中就会用 Feign 去调用 B 服务的接口,所以接下来需要用 Feign 的拦截器将刚刚获取的用户 ID 重新传递到 B 服务中,代码如下所示。
public class FeignBasicAuthRequestInterceptor implements RequestInterceptor {
public FeignBasicAuthRequestInterceptor() {
}
@Override
public void apply(RequestTemplate template) {
Map<String, String> attributes = RibbonFilterContextHolder.getCurrentContext().getAttributes();
for (String key : attributes.keySet()) {
String value = attributes.get(key);
template.header(key, value);
}
}
}通过获取 InheritableThreadLocal 中的数据添加到请求头中,这里不用具体的名字去获取数据是为了扩展,这样后面添加任何的参数都能直接传递过去了。
Feign 的拦截器使用需要在 @FeignClient 注解中指定 Feign 的自定义配置,自定义配置类中配置 Feign 的拦截器即可。
拦截器只需要注册下就可以使用了,本套方案不用改变当前任何业务代码,代码如下所示。
public class FeignBasicAuthRequestInterceptor implements RequestInterceptor {
@Bean
public FilterRegistrationBean filterRegistrationBean() {
FilterRegistrationBean registrationBean = new FilterRegistrationBean();
HttpHeaderParamFilter httpHeaderParamFilter = new HttpHeaderParamFilter();
registrationBean.setFilter(httpHeaderParamFilter);
List<String> urlPatterns = new ArrayList<String>(1);
urlPatterns.add("/*");
registrationBean.setUrlPatterns(urlPatterns);
return registrationBean;
}
}推荐电子商务源码
 springcloud+springcloud+vue+uniapp分布式微服务电商 商城之服务降级是什么?Spring Cloud如何实现?")
(七十四) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之服务降级是什么?Spring Cloud如何实现?
当访问量剧增,服务出现问题时,需要做一些处理,比如服务降级。服务降级就是将某些服务停掉或者不进行业务处理,释放资源来维持主要服务的功能。
某电商网站在搞活动时,活动期间压力太大,如果再进行下去,整个系统有可能挂掉,这个时候可以释放掉一些资源,将一些不那么重要的服务采取降级措施,比如登录、注册。登录服务停掉之后就不会有更多的用户抢购,同时释放了一些资源,登录、注册服务就算停掉了也不影响商品抢购。
服务降级有很多种方式,最好的方式就是利用Docker 来实现。当需要对某个服务进行降级时,直接将这个服务所有的容器停掉,需要恢复的时候重新启动就可以了。
还有就是在 API 网关层进行处理,当某个服务被降级了,前端过来的请求就直接拒绝掉,不往内部服务转发,将流量挡回去。
在 Zuul 中对服务进行动态降级,结合我们的配置中心来做。
定义 Apollo 配置类,存储需要降级的服务信息见如下代码。
@Data
@Configuration
public class BasicConf {
// 降级的服务 ID,多个用逗号分隔
@Value("${downGradeServiceStr:default}")
private String downGradeServiceStr;
}编写过滤器来执行降级逻辑,见如下代码。
public class DownGradeFilter extends ZuulFilter {
@Autowired
private BasicConf basicConf;
public DownGradeFilter() {
super();
}
@Override
public boolean shouldFilter() {
RequestContext ctx = RequestContext.getCurrentContext();
Object success = ctx.get("isSuccess");
return success == null ? true : Boolean.parseBoolean(success.toString());
}
@Override
public String filterType() {
return "route";
}
@Override
public int filterOrder() {
return 4;
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
Object serviceId = ctx.get("serviceId");
if (serviceId != null && basicConf != null) {
List<String> serviceIds = Arrays.asList(basicConf.getDownGradeServiceStr().split(","));
if (serviceIds.contains(serviceId.toString())) {
ctx.setSendZuulResponse(false);
ctx.set("isSuccess", false);
ResponseData data = ResponseData.fail("服务降级中", ResponseCode.DOWNGRADE.getCode());
ctx.setResponseBody(JsonUtils.toJson(data));
ctx.getResponse().setContentType("application/json; charset=utf-8");
return null;
}
}
return null;
}
}主要逻辑在 run 方法中,通过 RequestContext 获取即将路由的服务 ID,通过配置信息获取降级的服务信息,如果当前路由的服务在其中,就直接拒绝,返回对应的信息让客户端做对应的处理。
当需要降级的时候,直接在 Apollo 的后台改一下配置就可以马上生效,当然也可以做成自动的,比如监控某些指标,流量、负载等,当达到某些指标后就自动触发降级。
推荐电子商务源码
关于SpringCloud与微服务Ⅱ --- 微服务概述和springcloud与微服务关系的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于(七十一) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之使用Zuul聚合多个微服务的Swagger文档、(七十三) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之Spring Cloud服务限流详解、(七十二) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之微服务架构下如何获取用户信息并认证?、(七十四) springcloud+springcloud+vue+uniapp分布式微服务电商 商城之服务降级是什么?Spring Cloud如何实现?等相关知识的信息别忘了在本站进行查找喔。
本文标签:




