在这里,我们将给大家分享关于python3线程threading.ThreadGIL性能详解(2.3)的知识,让您更了解pythonthreading多线程的本质,同时也会涉及到如何更有效地(转)Py
在这里,我们将给大家分享关于python3 线程 threading.Thread GIL性能详解(2.3)的知识,让您更了解python threading多线程的本质,同时也会涉及到如何更有效地(转)Python3入门之线程threading常用方法、Python (多线程 threading 模块)、python threading ThreadPoolExecutor、python threading ThreadPoolExecutor源码解析的内容。
本文目录一览:- python3 线程 threading.Thread GIL性能详解(2.3)(python threading多线程)
- (转)Python3入门之线程threading常用方法
- Python (多线程 threading 模块)
- python threading ThreadPoolExecutor
- python threading ThreadPoolExecutor源码解析
(python threading多线程)")
python3 线程 threading.Thread GIL性能详解(2.3)(python threading多线程)
<br/><br/>
python3 线程 threading
##最基础的线程的使用
import threading, time
value = 0
lock = threading.Lock()
def change(n):
global value
value += n
value -= n
def thread_fun(n):
for i in range(1000):
lock.acquire()
try:
change(n)
finally:
lock.release()
t1 = threading.Thread(target=thread_fun, args=(2,))
t2 = threading.Thread(target=thread_fun, args=(3,))
t1.start()
t2.start()
t1.join()
t2.join()
print(value)
output: 0
使用一个类, 推荐使用这种方法
import threading, time
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
global n, lock
for i in range(100):
lock.acquire()
try:
print (n , self.name)
n += 1
finally:
lock.release()
if "__main__" == __name__:
n = 1
ThreadList = []
lock = threading.Lock()
for i in range(1, 5):
t = MyThread()
ThreadList.append(t)
for t in ThreadList:
t.start()
for t in ThreadList:
t.join()
性能
python GIL 性能
启动一个执行死循环的线程,CPU占有率可以达到100%
启动与CPU核心数量相同的N个线程,在4核CPU上可以监控到CPU占用率仅有160%,也就是使用不到两核。
即使启动100个线程,使用率也就170%左右,仍然不到两核。
但是用C、C++或Java来改写相同的死循环,直接可以把全部核心跑满,4核就跑到400%,8核就跑到800%,为什么Python不行呢?
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。
所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这样就失去了Python简单易用的特点。
如何决定用不用线程, 如何决定用python还是
IO密集型适合用多线程。涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务,比如Web应用。
IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少,因此,用运行速度极快的C语言替换用Python这样运行速度极低的脚本语言,完全无法提升运行效率。对于IO密集型任务,最合适的语言就是开发效率最高(代码量最少)的语言,脚本语言是首选,C语言最差
注:参考了廖雪峰大神的教程
附一篇备着自己看
python GIL性能详解
(For the sake of focus, I only describe CPython here—not Jython, PyPy, or IronPython. CPython is the Python implementation that working programmers overwhelmingly use.)
Behold, the global interpreter lock Here it is:
static PyThread_type_lock interpreter_lock = 0; /* This is the GIL */
This line of code is in ceval.c, in the CPython 2.7 interpreter''s source code. Guido van Rossum''s comment, "This is the GIL," was added in 2003, but the lock itself dates from his first multithreaded Python interpreter in 1997. On Unix systems, PyThread_type_lock is an alias for the standard C lock, mutex_t. It is initialized when the Python interpreter begins:
void
PyEval_InitThreads(void)
{
interpreter_lock = PyThread_allocate_lock();
PyThread_acquire_lock(interpreter_lock);
}
All C code within the interpreter must hold this lock while executing Python. Guido first built Python this way because it is simple, and every attempt to remove the GIL from CPython has cost single-threaded programs too much performance to be worth the gains for multithreading.
The GIL''s effect on the threads in your program is simple enough that you can write the principle on the back of your hand: "One thread runs Python, while N others sleep or await I/O." Python threads can also wait for a threading.Lock or other synchronization object from the threading module; consider threads in that state to be "sleeping," too.
hand with writing
When do threads switch? Whenever a thread begins sleeping or awaiting network I/O, there is a chance for another thread to take the GIL and execute Python code. This is cooperative multitasking. CPython also has preemptive multitasking: If a thread runs uninterrupted for 1000 bytecode instructions in Python 2, or runs 15 milliseconds in Python 3, then it gives up the GIL and another thread may run. Think of this like time slicing in the olden days when we had many threads but one CPU. I will discuss these two kinds of multitasking in detail.
Think of Python as an old mainframe; many tasks share one CPU.
Cooperative multitasking When it begins a task, such as network I/O, that is of long or uncertain duration and does not require running any Python code, a thread relinquishes the GIL so another thread can take it and run Python. This polite conduct is called cooperative multitasking, and it allows concurrency; many threads can wait for different events at the same time.
Say that two threads each connect a socket:
def do_connect():
s = socket.socket()
s.connect((''python.org'', 80)) # drop the GIL
for i in range(2):
t = threading.Thread(target=do_connect)
t.start()
Only one of these two threads can execute Python at a time, but once the thread has begun connecting, it drops the GIL so the other thread can run. This means that both threads could be waiting for their sockets to connect concurrently, which is a good thing. They can do more work in the same amount of time.
Let''s pry open the box and see how a Python thread actually drops the GIL while it waits for a connection to be established, in socketmodule.c:
/* s.connect((host, port)) method */
static PyObject *
sock_connect(PySocketSockObject *s, PyObject *addro)
{
sock_addr_t addrbuf;
int addrlen;
int res;
/* convert (host, port) tuple to C address */
getsockaddrarg(s, addro, SAS2SA(&addrbuf), &addrlen);
Py_BEGIN_ALLOW_THREADS
res = connect(s->sock_fd, addr, addrlen);
Py_END_ALLOW_THREADS
/* error handling and so on .... */
}
The Py_BEGIN_ALLOW_THREADS macro is where the thread drops the GIL; it is defined simply as:
PyThread_release_lock(interpreter_lock);
And of course Py_END_ALLOW_THREADS reacquires the lock. A thread might block at this spot, waiting for another thread to release the lock; once that happens, the waiting thread grabs the GIL back and resumes executing your Python code. In short: While N threads are blocked on network I/O or waiting to reacquire the GIL, one thread can run Python.
Below, see a complete example that uses cooperative multitasking to fetch many URLs quickly. But before that, let''s contrast cooperative multitasking with the other kind of multitasking.
Preemptive multitasking A Python thread can voluntarily release the GIL, but it can also have the GIL seized from it preemptively.
Let''s back up and talk about how Python is executed. Your program is run in two stages. First, your Python text is compiled into a simpler binary format called bytecode. Second, the Python interpreter''s main loop, a function mellifluously named PyEval_EvalFrameEx(), reads the bytecode and executes the instructions in it one by one.
While the interpreter steps through your bytecode it periodically drops the GIL, without asking permission of the thread whose code it is executing, so other threads can run:
for (;;) {
if (--ticker < 0) {
ticker = check_interval;
/* Give another thread a chance */
PyThread_release_lock(interpreter_lock);
/* Other threads may run now */
PyThread_acquire_lock(interpreter_lock, 1);
}
bytecode = *next_instr++;
switch (bytecode) {
/* execute the next instruction ... */
}
}
By default the check interval is 1000 bytecodes. All threads run this same code and have the lock taken from them periodically in the same way. In Python 3 the GIL''s implementation is more complex, and the check interval is not a fixed number of bytecodes, but 15 milliseconds. For your code, however, these differences are not significant.
Thread safety in Python
Weaving together multiple threads requires skill.
If a thread can lose the GIL at any moment, you must make your code thread-safe. Python programmers think differently about thread safety than C or Java programmers do, however, because many Python operations are atomic.
An example of an atomic operation is calling sort() on a list. A thread cannot be interrupted in the middle of sorting, and other threads never see a partly sorted list, nor see stale data from before the list was sorted. Atomic operations simplify our lives, but there are surprises. For example, += seems simpler than sort(), but += is not atomic. How can you know which operations are atomic and which are not?
Consider this code:
n = 0
def foo(): global n n += 1 We can see the bytecode to which this function compiles, with Python''s standard dis module:
>>> import dis
>>> dis.dis(foo)
LOAD_GLOBAL 0 (n)
LOAD_CONST 1 (1)
INPLACE_ADD
STORE_GLOBAL 0 (n)
One line of code, n += 1, has been compiled to four bytecodes, which do four primitive operations:
load the value of n onto the stack load the constant 1 onto the stack sum the two values at the top of the stack store the sum back into n Remember that every 1000 bytecodes a thread is interrupted by the interpreter taking the GIL away. If the thread is unlucky, this might happen between the time it loads the value of n onto the stack and when it stores it back. How this leads to lost updates is easy see:
threads = []
for i in range(100):
t = threading.Thread(target=foo)
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
print(n)
Usually this code prints 100, because each of the 100 threads has incremented n. But sometimes you see 99 or 98, if one of the threads'' updates was overwritten by another.
So, despite the GIL, you still need locks to protect shared mutable state:
n = 0
lock = threading.Lock()
def foo():
global n
with lock:
n += 1
What if we were using an atomic operation like sort() instead?:
lst = [4, 1, 3, 2]
def foo():
lst.sort()
This function''s bytecode shows that sort() cannot be interrupted, because it is atomic:
>>> dis.dis(foo)
LOAD_GLOBAL 0 (lst)
LOAD_ATTR 1 (sort)
CALL_FUNCTION 0
The one line compiles to three bytecodes:
load the value of lst onto the stack load its sort method onto the stack call the sort method Even though the line lst.sort() takes several steps, the sort call itself is a single bytecode, and thus there is no opportunity for the thread to have the GIL seized from it during the call. We could conclude that we don''t need to lock around sort(). Or, to avoid worrying about which operations are atomic, follow a simple rule: Always lock around reads and writes of shared mutable state. After all, acquiring a threading.Lock in Python is cheap.
Although the GIL does not excuse us from the need for locks, it does mean there is no need for fine-grained locking. In a free-threaded language like Java, programmers make an effort to lock shared data for the shortest time possible, to reduce thread contention and allow maximum parallelism. Because threads cannot run Python in parallel, however, there''s no advantage to fine-grained locking. So long as no thread holds a lock while it sleeps, does I/O, or some other GIL-dropping operation, you should use the coarsest, simplest locks possible. Other threads couldn''t have run in parallel anyway.
Finishing sooner with concurrency I wager what you really came for is to optimize your programs with multi-threading. If your task will finish sooner by awaiting many network operations at once, then multiple threads help, even though only one of them can execute Python at a time. This is concurrency, and threads work nicely in this scenario.
This code runs faster with threads:
import threading
import requests
urls = [...]
def worker():
while True:
try:
url = urls.pop()
except IndexError:
break # Done.
requests.get(url)
for _ in range(10):
t = threading.Thread(target=worker)
t.start()
As we saw above, these threads drop the GIL while waiting for each socket operation involved in fetching a URL over HTTP, so they finish the work sooner than a single thread could.
Parallelism What if your task will finish sooner only by running Python code simultaneously? This kind of scaling is called parallelism, and the GIL prohibits it. You must use multiple processes, which can be more complicated than threading and requires more memory, but it will take advantage of multiple CPUs.
This example finishes sooner by forking 10 processes than it could with only one, because the processes run in parallel on several cores. But it wouldn''t run faster with 10 threads than with one, because only one thread can execute Python at a time:
import os
import sys
nums =[1 for _ in range(1000000)]
chunk_size = len(nums) // 10
readers = []
while nums:
chunk, nums = nums[:chunk_size], nums[chunk_size:]
reader, writer = os.pipe()
if os.fork():
readers.append(reader) # Parent.
else:
subtotal = 0
for i in chunk: # Intentionally slow code.
subtotal += i
print(''subtotal %d'' % subtotal)
os.write(writer, str(subtotal).encode())
sys.exit(0)
Parent.
total = 0
for reader in readers:
subtotal = int(os.read(reader, 1000).decode())
total += subtotal
print("Total: %d" % total)
Because each forked process has a separate GIL, this program can parcel the work out and run multiple computations at once.
(Jython and IronPython provide single-process parallelism, but they are far from full CPython compatibility. PyPy with Software Transactional Memory may some day be fast. Try these interpreters if you''re curious.)
Conclusion Now that you''ve opened the music box and seen the simple mechanism, you know all you need to write fast, thread-safe Python. Use threads for concurrent I/O, and processes for parallel computation. The principle is plain enough that you might not even need to write it on your hand.
A. Jesse Jiryu Davis will be speaking at PyCon 2017, which will be held May 17-25 in Portland, Oregon. Catch his talk, Grok the GIL: Write Fast and Thread-Safe Python, on Friday, May 19.
原文连接:https://opensource.com/article/17/4/grok-gil <br/><br/>
Python3入门之线程threading常用方法")
(转)Python3入门之线程threading常用方法
原文:https://www.cnblogs.com/chengd/articles/7770898.html
https://blog.csdn.net/sunhuaqiang1/article/details/70168015
https://yq.aliyun.com/articles/26041?spm=5176.10695662.1996646101.searchclickresult.5d947f68X55AxH------[python] 专题八.多线程编程之thread和threading
https://yq.aliyun.com/articles/621687?spm=5176.10695662.1996646101.searchclickresult.5d947f68X55AxH---Python多线程threading进阶笔记
https://yq.aliyun.com/articles/558679?spm=5176.10695662.1996646101.searchclickresult.5d947f68X55AxH---threading多线程总结
https://www.u3v3.com/ar/1383-----------python3.6 - threading 多线程编程进阶,线程间并发控制(2)
daemon进程,理解为后台进程。
只要主进程没看到有daemon为None或daemon=False进程,就会把daemon进程杀掉。
if daemon is not None:
self._daemonic = daemon
else:
self._daemonic = current_thread().daemonPython3 线程中常用的两个模块为:
- _thread
- threading(推荐使用)
thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用"thread" 模块。为了兼容性,Python3 将 thread 重命名为 "_thread"。
下面将介绍threading模块常用方法:
1. threading.Lock()
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。
来看看多个线程同时操作一个变量怎么把内容给改乱了(在windows下不会出现内容混乱情况,可能python在Windows下自动加上锁了;不过在Linux 下可以测试出内容会被改乱):

#!/usr/bin/env python3
import time, threading
# 假定这是你的银行存款:
balance = 0
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(100000):
change_it(n)
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
执行结果:
[root@localhost ~]# python3 thread_lock.py
5
[root@localhost ~]# python3 thread_lock.py
5
[root@localhost ~]# python3 thread_lock.py
0
[root@localhost ~]# python3 thread_lock.py
8
[root@localhost ~]# python3 thread_lock.py
-8
[root@localhost ~]# python3 thread_lock.py
5
[root@localhost ~]# python3 thread_lock.py
-8
[root@localhost ~]# python3 thread_lock.py
3
[root@localhost ~]# python3 thread_lock.py
5
我们定义了一个共享变量balance,初始值为0,并且启动两个线程,先存后取,理论上结果应该为0,但是,由于线程的调度是由操作系统决定的,当t1、t2交替执行时,只要循环次数足够多,balance的结果就不一定是0了。
如果我们要确保balance计算正确,就要给change_it()上一把锁,当某个线程开始执行change_it()时,我们说,该线程因为获得了锁,因此其他线程不能同时执行change_it(),只能等待,直到锁被释放后,获得该锁以后才能改。由于锁只有一个,无论多少线程,同一时刻最多只有一个线程持有该锁,所以,不会造成修改的冲突。创建一个锁就是通过threading.Lock()来实现:

#!/usr/bin/env python3
import time, threading
balance = 0
lock = threading.Lock()
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(100000):
# 先要获取锁:
lock.acquire()
try:
# 放心地改吧:
change_it(n)
finally:
# 改完了一定要释放锁:
lock.release()
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
执行结果:
[root@localhost ~]# python3 thread_lock.py
0
[root@localhost ~]# python3 thread_lock.py
0
[root@localhost ~]# python3 thread_lock.py
0
[root@localhost ~]# python3 thread_lock.py
0
[root@localhost ~]# python3 thread_lock.py
0
[root@localhost ~]# python3 thread_lock.py
0
当多个线程同时执行lock.acquire()时,只有一个线程能成功地获取锁,然后继续执行代码,其他线程就继续等待直到获得锁为止。
获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,成为死线程。所以我们用try...finally来确保锁一定会被释放。
锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无法结束,只能靠操作系统强制终止。
2. threading.Rlock()
RLock允许在同一线程中被多次acquire。而Lock却不允许这种情况。注意:如果使用RLock,那么acquire和release必须成对出现,即调用了n次acquire,必须调用n次的release才能真正释放所占用的琐。

import threading
lock = threading.Lock()
#Lock对象
lock.acquire()
lock.acquire()
#产生了死琐。
lock.release()
lock.release()
import threading
rLock = threading.RLock()
#RLock对象
rLock.acquire()
rLock.acquire()
#在同一线程内,程序不会堵塞。
rLock.release()
rLock.release()
3. threading.Condition()
可以把Condiftion理解为一把高级的琐,它提供了比Lock, RLock更高级的功能,允许我们能够控制复杂的线程同步问题。threadiong.Condition在内部维护一个琐对象(默认是RLock),可以在创建Condigtion对象的时候把琐对象作为参数传入。Condition也提供了acquire, release方法,其含义与琐的acquire, release方法一致,其实它只是简单的调用内部琐对象的对应的方法而已。Condition还提供wait方法、notify方法、notifyAll方法(特别要注意:这些方法只有在占用琐(acquire)之后才能调用,否则将会报RuntimeError异常。):
acquire()/release():获得/释放 Lock
wait([timeout]):线程挂起,直到收到一个notify通知或者超时(可选的,浮点数,单位是秒s)才会被唤醒继续运行。wait()必须在已获得Lock前提下才能调用,否则会触发RuntimeError。调用wait()会释放Lock,直至该线程被Notify()、NotifyAll()或者超时线程又重新获得Lock.
notify(n=1):通知其他线程,那些挂起的线程接到这个通知之后会开始运行,默认是通知一个正等待该condition的线程,最多则唤醒n个等待的线程。notify()必须在已获得Lock前提下才能调用,否则会触发RuntimeError。notify()不会主动释放Lock。
notifyAll(): 如果wait状态线程比较多,notifyAll的作用就是通知所有线程(这个一般用得少)
现在写个捉迷藏的游戏来具体介绍threading.Condition的基本使用。假设这个游戏由两个人来玩,一个藏(Hider),一个找(Seeker)。游戏的规则如下:1. 游戏开始之后,Seeker先把自己眼睛蒙上,蒙上眼睛后,就通知Hider;2. Hider接收通知后开始找地方将自己藏起来,藏好之后,再通知Seeker可以找了; 3. Seeker接收到通知之后,就开始找Hider。Hider和Seeker都是独立的个体,在程序中用两个独立的线程来表示,在游戏过程中,两者之间的行为有一定的时序关系,我们通过Condition来控制这种时序关系。

#!/usr/bin/python3.4
# -*- coding: utf-8 -*-
import threading, time
def Seeker(cond, name):
time.sleep(2)
cond.acquire()
print(''%s :我已经把眼睛蒙上了!''% name)
cond.notify()
cond.wait()
for i in range(3):
print(''%s is finding!!!''% name)
time.sleep(2)
cond.notify()
cond.release()
print(''%s :我赢了!''% name)
def Hider(cond, name):
cond.acquire()
cond.wait()
for i in range(2):
print(''%s is hiding!!!''% name)
time.sleep(3)
print(''%s :我已经藏好了,你快来找我吧!''% name)
cond.notify()
cond.wait()
cond.release()
print(''%s :被你找到了,唉~^~!''% name)
if __name__ == ''__main__'':
cond = threading.Condition()
seeker = threading.Thread(target=Seeker, args=(cond, ''seeker''))
hider = threading.Thread(target=Hider, args=(cond, ''hider''))
seeker.start()
hider.start()
执行结果:
seeker :我已经把眼睛蒙上了!
hider is hiding!!!
hider is hiding!!!
hider :我已经藏好了,你快来找我吧!
seeker is finding!!!
seeker is finding!!!
seeker is finding!!!
seeker :我赢了!
hider :被你找到了,唉~^~!
上面不同颜色的notify和wait一一对应关系,通知--->等待;等待--->通知
4. threading.Semaphore和BoundedSemaphore
Semaphore:Semaphore 在内部管理着一个计数器。调用 acquire() 会使这个计数器 -1,release() 则是+1(可以多次release(),所以计数器的值理论上可以无限).计数器的值永远不会小于 0,当计数器到 0 时,再调用 acquire() 就会阻塞,直到其他线程来调用release()

import threading, time
def run(n):
# 获得信号量,信号量减一
semaphore.acquire()
time.sleep(1)
print("run the thread: %s" % n)
# 释放信号量,信号量加一
semaphore.release()
#semaphore.release() # 可以多次释放信号量,每次释放计数器+1
#semaphore.release() # 可以多次释放信号量,每次释放计数器+1
if __name__ == ''__main__'':
num = 0
semaphore = threading.Semaphore(2) # 最多允许2个线程同时运行(即计数器值);在多次释放信号量后,计数器值增加后每次可以运行的线程数也会增加
for i in range(20):
t = threading.Thread(target=run, args=(i,))
t.start()
while threading.active_count() != 1:
pass # print threading.active_count()
else:
print(''----all threads done---'')
print(num)
BoundedSemaphore:类似于Semaphore;不同在于BoundedSemaphore 会检查内部计数器的值,并保证它不会大于初始值,如果超了,就引发一个 ValueError。多数情况下,semaphore 用于守护限制访问(但不限于 1)的资源,如果 semaphore 被 release() 过多次,这意味着存在 bug

import threading, time
def run(n):
semaphore.acquire()
time.sleep(1)
print("run the thread: %s" % n)
semaphore.release()
# 如果再次释放信号量,信号量加一,这是超过限定的信号量数目,这时会报错ValueError: Semaphore released too many times
#semaphore.release()
if __name__ == ''__main__'':
num = 0
semaphore = threading.BoundedSemaphore(2) # 最多允许2个线程同时运行
for i in range(20):
t = threading.Thread(target=run, args=(i,))
t.start()
while threading.active_count() != 1:
pass # print threading.active_count()
else:
print(''----all threads done---'')
print(num)
5. threading.Event
事件处理的机制:全局定义了一个“Flag”,如果“Flag”值为 False,那么当程序执行 event.wait 方法时就会阻塞;如果“Flag”值为True,那么执行event.wait 方法时便不再阻塞。
clear:将“Flag”设置为False
set:将“Flag”设置为True
用 threading.Event 实现线程间通信,使用threading.Event可以使一个线程等待其他线程的通知,我们把这个Event传递到线程对象中,
Event默认内置了一个标志,初始值为False。一旦该线程通过wait()方法进入等待状态,直到另一个线程调用该Event的set()方法将内置标志设置为True时,该Event会通知所有等待状态的线程恢复运行。
通过Event来实现两个或多个线程间的交互,下面是一个红绿灯的例子,即起动一个线程做交通指挥灯,生成几个线程做车辆,车辆行驶按红灯停,绿灯行的规则。

import threading, time
import random
def light():
if not event.isSet(): #初始化evet的flag为真
event.set() #wait就不阻塞 #绿灯状态
count = 0
while True:
if count < 10:
print(''\033[42;1m---green light on---\033[0m'')
elif count < 13:
print(''\033[43;1m---yellow light on---\033[0m'')
elif count < 20:
if event.isSet():
event.clear()
print(''\033[41;1m---red light on---\033[0m'')
else:
count = 0
event.set() #打开绿灯
time.sleep(1)
count += 1
def car(n):
while 1:
time.sleep(random.randrange(3, 10))
#print(event.isSet())
if event.isSet():
print("car [%s] is running..." % n)
else:
print(''car [%s] is waiting for the red light...'' % n)
event.wait() #红灯状态下调用wait方法阻塞,汽车等待状态
if __name__ == ''__main__'':
car_list = [''BMW'', ''AUDI'', ''SANTANA'']
event = threading.Event()
Light = threading.Thread(target=light)
Light.start()
for i in car_list:
t = threading.Thread(target=car, args=(i,))
t.start()
6. threading.active_count()
返回当前存活的线程对象的数量;通过计算len(threading.enumerate())长度而来
The returned count is equal to the length of the list returned by enumerate().

import threading, time
def run():
thread = threading.current_thread()
print(''%s is running...''% thread.getName()) #返回线程名称
time.sleep(10) #休眠10S方便统计存活线程数量
if __name__ == ''__main__'':
#print(''The current number of threads is: %s'' % threading.active_count())
for i in range(10):
print(''The current number of threads is: %s'' % threading.active_count()) #返回当前存活线程数量
thread_alive = threading.Thread(target=run, name=''Thread-***%s***'' % i)
thread_alive.start()
thread_alive.join()
print(''\n%s thread is done...''% threading.current_thread().getName())
7. threading.current_thread()
Return the current Thread object, corresponding to the caller''s thread of control.
返回当前线程对象
>>> threading.current_thread
<function current_thread at 0x00000000029F6C80>
>>> threading.current_thread()
<_MainThread(MainThread, started 4912)>
>>> type(threading.current_thread())
<class ''threading._MainThread''>继承线程threading方法;通过help(threading.current_thread())查看。

import threading, time
def run(n):
thread = threading.current_thread()
thread.setName(''Thread-***%s***'' % n) #自定义线程名称
print(''-''*30)
print("Pid is :%s" % thread.ident) # 返回线程pid
#print(''ThreadName is :%s'' % thread.name) # 返回线程名称
print(''ThreadName is :%s''% thread.getName()) #返回线程名称
time.sleep(2)
if __name__ == ''__main__'':
#print(''The current number of threads is: %s'' % threading.active_count())
for i in range(3):
#print(''The current number of threads is: %s'' % threading.active_count()) #返回当前存活线程数量
thread_alive = threading.Thread(target=run, args=(i,))
thread_alive.start()
thread_alive.join()
print(''\n%s thread is done...''% threading.current_thread().getName())
执行结果:
Pid is :11792
ThreadName is :Thread-***0***
------------------------------
Pid is :12124
ThreadName is :Thread-***1***
------------------------------
Pid is :11060
ThreadName is :Thread-***2***
MainThread thread is done...
8. threading.enumerate()
Return a list of all Thread objects currently alive
返回当前存在的所有线程对象的列表

import threading, time
def run(n):
thread = threading.current_thread()
thread.setName(''Thread-***%s***'' % n)
print(''-''*30)
print("Pid is :%s" % thread.ident) # 返回线程pid
#print(''ThreadName is :%s'' % thread.name) # 返回线程名称
print(''ThreadName is :%s''% threading.enumerate()) #返回所有线程对象列表
time.sleep(2)
if __name__ == ''__main__'':
#print(''The current number of threads is: %s'' % threading.active_count())
threading.main_thread().setName(''Chengd---python'')
for i in range(3):
#print(''The current number of threads is: %s'' % threading.active_count()) #返回当前存活线程数量
thread_alive = threading.Thread(target=run, args=(i,))
thread_alive.start()
thread_alive.join()
print(''\n%s thread is done...''% threading.current_thread().getName())
执行结果:
Pid is :12096
ThreadName is :[<_MainThread(Chengd---python, started 12228)>, <Thread(Thread-***0***, started 12096)>, <Thread(Thread-2, initial)>]
------------------------------
Pid is :10328
ThreadName is :[<_MainThread(Chengd---python, started 12228)>, <Thread(Thread-***0***, started 12096)>, <Thread(Thread-***1***, started 10328)>, <Thread(Thread-3, initial)>]
------------------------------
Pid is :6032
ThreadName is :[<_MainThread(Chengd---python, started 12228)>, <Thread(Thread-***0***, started 12096)>, <Thread(Thread-***1***, started 10328)>, <Thread(Thread-***2***, started 6032)>]
Chengd---python thread is done...
9.threading.get_ident()
返回线程pid

import threading, time
def run(n):
print(''-''*30)
print("Pid is :%s" % threading.get_ident()) # 返回线程pid
if __name__ == ''__main__'':
threading.main_thread().setName(''Chengd---python'') #自定义线程名
for i in range(3):
thread_alive = threading.Thread(target=run, args=(i,))
thread_alive.start()
thread_alive.join()
print(''\n%s thread is done...''% threading.current_thread().getName()) #获取线程名
10. threading.main_thread()
返回主线程对象,类似 threading.current_thread();只不过一个是返回当前线程对象,一个是返回主线程对象

import threading, time
def run(n):
print(''-''*30)
print("Now Pid is :%s" % threading.current_thread().ident) # 返回当前线程pid
print("Main Pid is :%s" % threading.main_thread().ident) # 返回主线程pid
print(''Now thread is %s...'' % threading.current_thread().getName()) # 获取当前线程名
print(''Main thread is %s...'' % threading.main_thread().getName()) # 获取主线程线程名
if __name__ == ''__main__'':
threading.main_thread().setName(''Chengd---python'') #自定义线程名
for i in range(3):
thread_alive = threading.Thread(target=run, args=(i,))
thread_alive.start()
time.sleep(2)
thread_alive.join()
执行结果:
------------------------------
Now Pid is :8984
Main Pid is :3992
Now thread is Thread-1...
Main thread is Chengd---python...
------------------------------
Now Pid is :4828
Main Pid is :3992
Now thread is Thread-2...
Main thread is Chengd---python...
------------------------------
Now Pid is :12080
Main Pid is :3992
Now thread is Thread-3...
Main thread is Chengd---python...
廖大线程讲解
线程常用模块方法
多线程之Condition()
python—threading.Semaphore和BoundedSemaphore
python 多线程之信号机Semaphore示例
alex线程讲解
")
Python (多线程 threading 模块)
day27
参考:http://www.cnblogs.com/yuanchenqi/articles/5733873.html
CPU 像一本书,你不阅读的时候,你室友马上阅读,你准备阅读的时候,你室友记下他当时页码,等下次你不读的时候开始读。
多个线程竞争执行。
进程:A process can have one or many threads. 一个进程有多个线程。
一个线程就是一堆指令集合。
线程和进程是同样的东西。
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。
1 import time
2 import threading
3
4 begin = time.time()
5 def foo(n):
6 print(''foo%s''%n)
7 time.sleep(1)
8
9 def bar(n):
10 print(''bar%s''%n)
11 time.sleep(2)
12
13
14 # foo()
15 # bar()
16 # end = time.time()
17
18 #并发,两个线程竞争执行
19 t1 = threading.Thread(target = foo, args =(1,) )
20 t2 = threading.Thread(target = bar, args =(2,) )
21 t1.start()
22 t2.start()
23
24 t1.join()#t1,t2执行完再往下执行
25 t2.join()
26 #t1,t2同时执行
27 end = time.time()
28
29
30 print(end - begin)并发,两个线程竞争执行执行结果:
foo1
bar2
2.002244710922241
Process finished with exit code 0
IO 密集型任务函数(以上为 IO 密集型)计算效率会被提高,可用多线程
计算密集型任务函数(以下为计算密集型)改成 C 语言
1 import time
2 import threading
3 begin = time.time()
4
5 def add(n):
6 sum = 0
7 for i in range(n):
8 sum += i
9 print(sum)
10
11 # add(50000000)
12 # add(80000000)
13
14 #并发,两个线程竞争执行
15 t1 = threading.Thread(target = add, args =(50000000,) )
16 t2 = threading.Thread(target = add, args =(80000000,) )
17 t1.start()
18 t2.start()
19
20 t1.join()#t1,t2执行完再往下执行
21 t2.join()
22 end = time.time()
23
24 print(end - begin)计算密集型中用并发计算效率并没有提高。
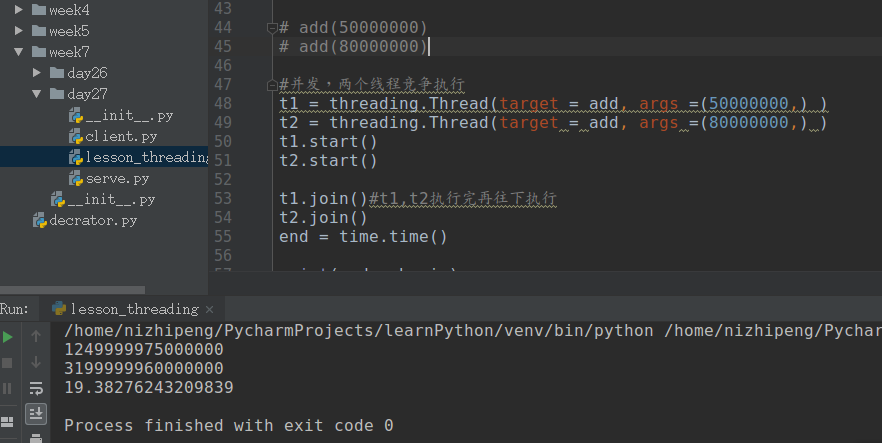
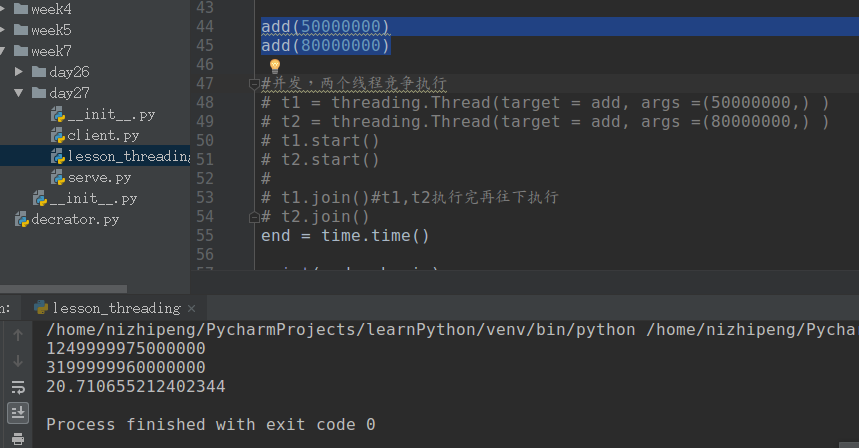
计算效率并没有提高。
GIL
In CPython, due to the Global Interpreter Lock, only one thread can execute Python code at once.
在同一时刻,只能有一个线程。
使之有多个进程就可以解决(如果三个线程无法同时进行,那么把它们分到三个进程里面去,用于解决 GIL 问题,实现并发)。
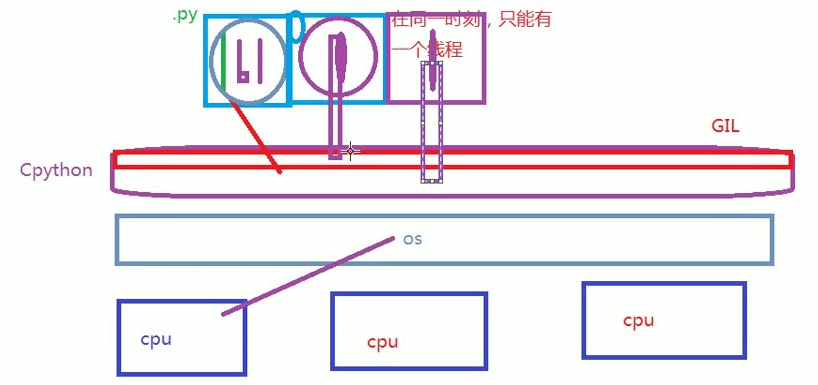
线程与进程的区别:
- Threads share the address space of the process that created it; processes have their own address space.
- Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
- Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
- New threads are easily created; new processes require duplication of the parent process.
- Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
- Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
threading_test.py
1 import threading
2 from time import ctime,sleep
3 import time
4
5 def music(func):
6 for i in range(2):
7 print ("Begin listening to %s. %s" %(func,ctime()))
8 sleep(1)
9 print("end listening %s"%ctime())
10
11 def move(func):
12 for i in range(2):
13 print ("Begin watching at the %s! %s" %(func,ctime()))
14 sleep(5)
15 print(''end watching %s''%ctime())
16
17 threads = []
18 t1 = threading.Thread(target=music,args=(''七里香'',))
19 threads.append(t1)
20 t2 = threading.Thread(target=move,args=(''阿甘正传'',))
21 threads.append(t2)
22
23 if __name__ == ''__main__'':
24
25 for t in threads:#线程加到了列表中
26 # t.setDaemon(True)
27 t.start()
28 # t.join()
29 # t1.join()
30 #t2.join()########考虑这三种join位置下的结果?
31 print ("all over %s" %ctime())
32
33 #一共执行10秒一共只执行 10 秒,因为是同时执行,看哪个时间长。2*5s
执行结果:
Begin listening to 七里香. Fri Nov 2 16:43:09 2018
all over Fri Nov 2 16:43:09 2018
Begin watching at the 阿甘正传! Fri Nov 2 16:43:09 2018
end listening Fri Nov 2 16:43:10 2018
Begin listening to 七里香. Fri Nov 2 16:43:10 2018
end listening Fri Nov 2 16:43:11 2018
end watching Fri Nov 2 16:43:14 2018
Begin watching at the 阿甘正传! Fri Nov 2 16:43:14 2018
end watching Fri Nov 2 16:43:20 2018
Process finished with exit code 0
join
1 import threading
2 from time import ctime,sleep
3 import time
4
5 def music(func):
6 for i in range(2):
7 print ("Begin listening to %s. %s" %(func,ctime()))
8 sleep(2)
9 print("end listening %s"%ctime())
10
11 def move(func):
12 for i in range(2):
13 print ("Begin watching at the %s! %s" %(func,ctime()))
14 sleep(3)
15 print(''end watching %s''%ctime())
16
17 threads = []
18 t1 = threading.Thread(target=music,args=(''七里香'',))
19 threads.append(t1)
20 t2 = threading.Thread(target=move,args=(''阿甘正传'',))
21 threads.append(t2)
22
23 if __name__ == ''__main__'':
24
25 for t in threads:#线程加到了列表中
26 # t.setDaemon(True)
27 t.start()
28 #t.join() #变成了串行 t1已经执行完了,但是t2阻塞了,其中t为t2
29 t1.join() #all over在第四秒就会被打印,因为t1四秒执行完,不再阻塞,而t2还在执行
30 #t2.join()########考虑这三种join位置下的结果?
31 print ("all over %s" %ctime())
32
33 #一共执行6秒
t1.join,t1 执行完才能到下一步,所以 4 秒后才能 print ("all over %s" %ctime())
t2.join,t2 执行结束才能到下一步,所以 6 秒后才能 print ("all over %s" %ctime())
如果将 t.join () 放到 for 循环中,即和串行一样先执行 t1, 再执行 t2。
setDeamon
1 import threading
2 from time import ctime,sleep
3 import time
4
5 def music(func):
6 for i in range(2):
7 print ("Begin listening to %s. %s" %(func,ctime()))
8 sleep(2)
9 print("end listening %s"%ctime())
10
11 def move(func):
12 for i in range(2):
13 print ("Begin watching at the %s! %s" %(func,ctime()))
14 sleep(3)
15 print(''end watching %s''%ctime())
16
17 threads = []
18 t1 = threading.Thread(target=music,args=(''七里香'',))
19 threads.append(t1)
20 t2 = threading.Thread(target=move,args=(''阿甘正传'',))
21 threads.append(t2)
22
23 if __name__ == ''__main__'':
24
25 t2.setDaemon(True)
26 for t in threads:#线程加到了列表中
27 #t.setDaemon(True)
28 t.start()
29
30 print ("all over %s" %ctime())
31
32 #主线程只会等待没设定的子线程t1,t2被设定setDaemon
33 #t1已经执行完(4s),但是t2还没执行完,和主线程一起退出32 #主线程只会等待没设定的子线程t1,t2被设定setDaemon
33 #t1已经执行完(4s),但是t2还没执行完,和主线程一起退出
执行结果:Begin listening to 七里香. Fri Nov 2 17:33:29 2018
Begin watching at the 阿甘正传! Fri Nov 2 17:33:29 2018
all over Fri Nov 2 17:33:29 2018
end listening Fri Nov 2 17:33:31 2018
Begin listening to 七里香. Fri Nov 2 17:33:31 2018
end watching Fri Nov 2 17:33:32 2018
Begin watching at the 阿甘正传! Fri Nov 2 17:33:32 2018
end listening Fri Nov 2 17:33:33 2018
Process finished with exit code 04 秒就结束。
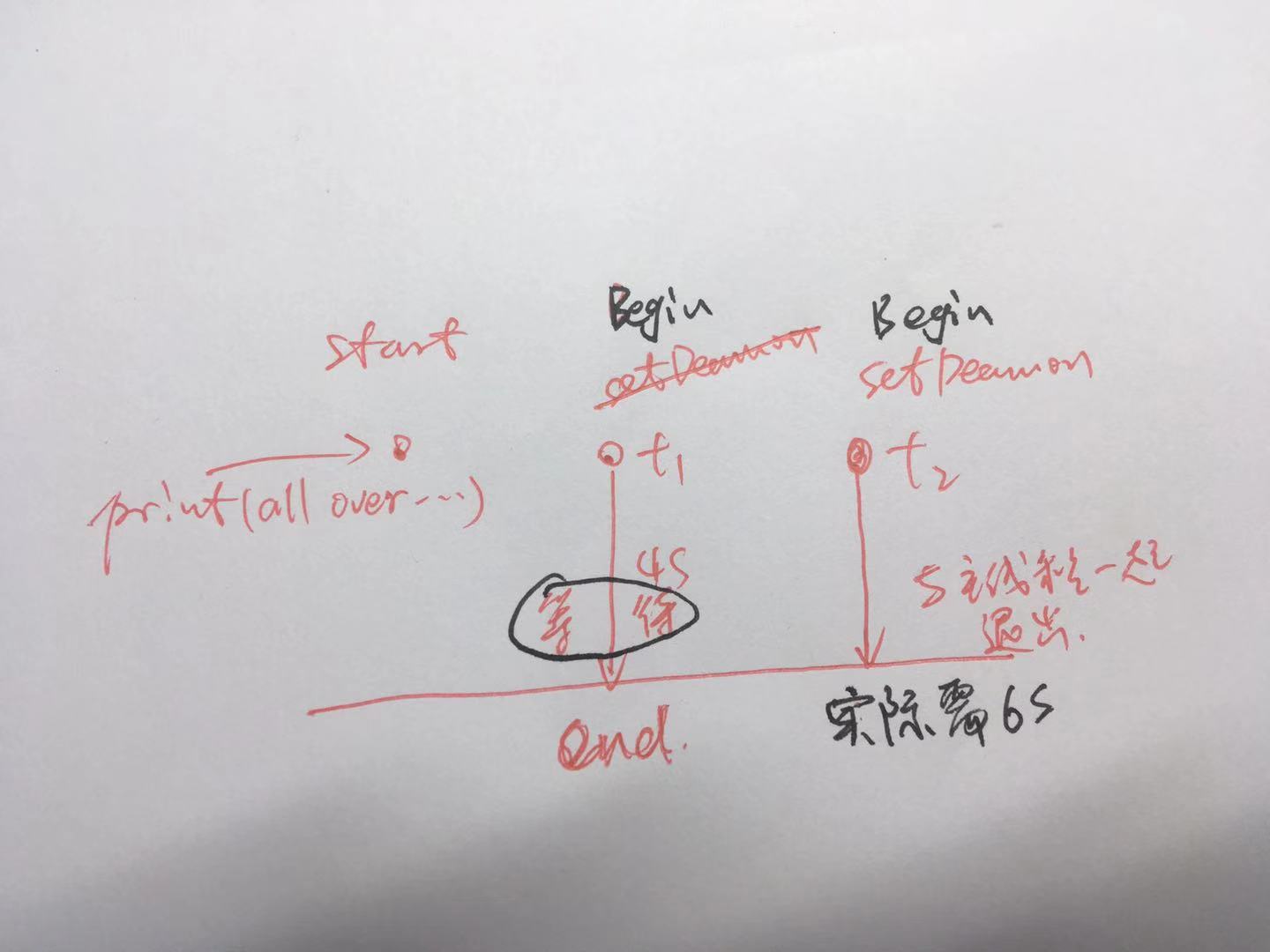
print属于主线程!
继承式调用
1 import threading
2 import time
3
4
5 class MyThread(threading.Thread):#继承
6 def __init__(self, num):
7 threading.Thread.__init__(self)
8 self.num = num
9
10 def run(self): # 定义每个线程要运行的函数
11
12 print("running on number:%s" % self.num)
13
14 time.sleep(3)
15 if __name__ == ''__main__'':
16 t1 = MyThread(1)
17 t2 = MyThread(2)
18 t1.start()
19 t2.start()
同步锁
1 import time
2 import threading
3
4 def addNum():
5 global num #在每个线程中都获取这个全局变量
6
7 temp = num
8
9 time.sleep(0.0001)#在前一次还没执行完,就开始减1
10 num =temp-1 #对此公共变量进行-1操作
14
15 num = 100 #设定一个共享变量
16 thread_list = []
17 r = threading.Lock()#同步锁
18 for i in range(100):
19
20 t = threading.Thread(target=addNum)
21 t.start()
22 thread_list.append(t)
23
24 for t in thread_list: #等待所有线程执行完毕
25 t.join()
26
27 print(''final num:'', num )#有join所有执行完再输出执行结果:
final num: 47
Process finished with exit code 0最终结果不是 0 的原因:由于有 sleep 的原因,100 个减一操作几乎同时进行,前一次还在 sleep 没进行减法运算,全局变量就被后一次线程进行减法运算。
正常情况:100-1=99,99-1=98........1-1 = 0。
有 sleep:100-1=99 (还没减),全局变量 100 被拿走,进行下一线程的运算 100-1=99,造成最后结果不为 0;
解决方法:同步锁,使数据运算部分变成了串行。
1 import time
2 import threading
3
4 def addNum():
5 global num #在每个线程中都获取这个全局变量
6 #num -= 1
7
8 r.acquire()#同步锁,又变成串行
9 temp = num
10 #print(''--get num:'',num )
11 time.sleep(0.0001)#在前一次还没执行完,就开始减1
12 num =temp-1 #对此公共变量进行-1操作
13 r.release()
14 #只是将以上的部分变成了串行
15
16 print(''ok'')
17 #将不是数据的部分内容不放到锁中,100个线程同时拿到ok,这部分将不是串行,而是并发
18
19
20 num = 100 #设定一个共享变量
21 thread_list = []
22 r = threading.Lock()#同步锁
23 for i in range(100):
24
25 t = threading.Thread(target=addNum)
26 t.start()
27 thread_list.append(t)
28
29 for t in thread_list: #等待所有线程执行完毕
30 t.join()
31
32 print(''final num:'', num )#有join所有执锁中的部分变成了串行,只有运行结束才进入下一线程。
但是锁外面的部分 print (''ok'') 还是并发的,100 个线程同时拿到 ok。
死锁和递归锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,因为系统判断这部分资源都正在使用,所有这两个线程在无外力作用下将一直等待下去。
1 import threading,time
2
3 class myThread(threading.Thread):
4 def doA(self):
5 lockA.acquire()
6 print(self.name,"gotlockA",time.ctime())
7 time.sleep(3)#以上部分被A锁住
8
9 lockB.acquire()#下面的也锁住
10 print(self.name,"gotlockB",time.ctime())
11
12 lockB.release()#释放后,执行doB
13 lockA.release()
14
15 def doB(self):
16 #在此过程中,第二个线程进入,因为A,B已经被释放
17 lockB.acquire()#有锁,正常输出,由于第二个进入,所以A(第二个线程),B(第一个线程)几乎同时获取
18 #但是之后第一个线程想要获取A锁的时候,A锁已经被第二个线程占着,造成死锁.
19 print(self.name,"gotlockB",time.ctime())
20 time.sleep(2)
21
22 lockA.acquire()
23 print(self.name,"gotlockA",time.ctime())#没有被打印,反而第二个线程的被打印了
24
25 lockA.release()
26 lockB.release()
27
28 def run(self):
29 self.doA()
30 self.doB()
31
32 if __name__=="__main__":
33
34 lockA=threading.Lock()#两个锁
35 lockB=threading.Lock()
36
37 #lock = threading.RLock()#该锁可以多次获取,多次acquire和release
38 threads=[]
39 for i in range(5):#5个线程
40 threads.append(myThread())
41 for t in threads:
42 t.start()
43 for t in threads:
44 t.join()#等待线程结束,后面再讲。执行结果:
Thread-1 gotlockA Sat Nov 3 13:40:48 2018
Thread-1 gotlockB Sat Nov 3 13:40:51 2018
Thread-1 gotlockB Sat Nov 3 13:40:51 2018
Thread-2 gotlockA Sat Nov 3 13:40:51 2018以上程序卡住不能运行,doA 运行完锁 A 锁 B 都释放,准备运行 doB,休眠 2 秒后,获取锁 A,此时由于线程锁都被释放,可以进入其他线程,如进入线程二,同时也获取锁 A,两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
解决方法:
1 import threading,time
2
3 class myThread(threading.Thread):
4 def doA(self):
5 lock.acquire()
6 print(self.name,"gotlockA",time.ctime())
7 time.sleep(3)#以上部分被A锁住
8
9 lock.acquire()#下面的也锁住
10 print(self.name,"gotlockB",time.ctime())
11
12 lock.release()#释放后,执行doB
13 lock.release()
14
15 def doB(self):
16 #在此过程中,第二个线程进入,因为A,B已经被释放
17 lock.acquire()#有锁,正常输出,由于第二个进入,所以A(第二个线程),B(第一个线程)几乎同时获取
18 #但是之后第一个线程想要获取A锁的时候,A锁已经被第二个线程占着,造成死锁.
19 print(self.name,"gotlockB",time.ctime())
20 time.sleep(2)
21
22 lock.acquire()
23 print(self.name,"gotlockA",time.ctime())#没有被打印,反而第二个线程的被打印了
24
25 lock.release()
26 lock.release()
27
28 def run(self):
29 self.doA()
30 self.doB()
31
32 if __name__=="__main__":
33
34 # lockA=threading.Lock()#两个锁
35 # lockB=threading.Lock()
36
37 lock = threading.RLock()#该锁可以多次获取,多次acquire和release
38 threads=[]
39 for i in range(5):#5个线程
40 threads.append(myThread())
41 for t in threads:
42 t.start()
43 for t in threads:
44 t.join()#等待线程结束,后lock = threading.RLock (),该锁可以重用,只用 lock。不用 lockA,lockB。
执行结果:
Thread-1 gotlockA Sat Nov 3 13:48:04 2018
Thread-1 gotlockB Sat Nov 3 13:48:07 2018
Thread-1 gotlockB Sat Nov 3 13:48:07 2018
Thread-1 gotlockA Sat Nov 3 13:48:09 2018
Thread-3 gotlockA Sat Nov 3 13:48:09 2018
Thread-3 gotlockB Sat Nov 3 13:48:12 2018
Thread-4 gotlockA Sat Nov 3 13:48:12 2018
Thread-4 gotlockB Sat Nov 3 13:48:15 2018
Thread-4 gotlockB Sat Nov 3 13:48:15 2018
Thread-4 gotlockA Sat Nov 3 13:48:17 2018
Thread-2 gotlockA Sat Nov 3 13:48:17 2018
Thread-2 gotlockB Sat Nov 3 13:48:20 2018
Thread-2 gotlockB Sat Nov 3 13:48:20 2018
Thread-2 gotlockA Sat Nov 3 13:48:22 2018
Thread-5 gotlockA Sat Nov 3 13:48:22 2018
Thread-5 gotlockB Sat Nov 3 13:48:25 2018
Thread-3 gotlockB Sat Nov 3 13:48:25 2018
Thread-3 gotlockA Sat Nov 3 13:48:27 2018
Thread-5 gotlockB Sat Nov 3 13:48:27 2018
Thread-5 gotlockA Sat Nov 3 13:48:29 2018
信号量 (Semaphore)
信号量用来控制线程并发数的,BoundedSemaphore 或 Semaphore 管理一个内置的计数 器,每当调用 acquire () 时 - 1,调用 release () 时 + 1。
计数器不能小于 0,当计数器为 0 时,acquire () 将阻塞线程至同步锁定状态,直到其他线程调用 release ()。(类似于停车位的概念)
BoundedSemaphore 与 Semaphore 的唯一区别在于前者将在调用 release () 时检查计数 器的值是否超过了计数器的初始值,如果超过了将抛出一个异常。
1 import threading,time
2 class myThread(threading.Thread):
3 def run(self):
4 if semaphore.acquire():
5 print(self.name)
6 time.sleep(3)
7 semaphore.release()
8 if __name__=="__main__":
9 semaphore=threading.Semaphore(5)
10 thrs=[]
11 for i in range(23):
12 thrs.append(myThread())
13 for t in thrs:
14 t.start()执行结果:
Thread-1
Thread-2
Thread-3
Thread-4
Thread-5
Thread-6
Thread-7
Thread-8
Thread-9
Thread-10
Thread-11
Thread-12
Thread-13
Thread-14
Thread-15
Thread-16
Thread-17
Thread-18
Thread-19
Thread-20
Thread-21
Thread-22
Thread-23
Process finished with exit code 0一次同时输出五个,最后一次输出三个。
条件变量同步 (Condition)
线程间通信的作用
1 import threading,time
2 from random import randint
3 class Producer(threading.Thread):
4 def run(self):
5 global L#一屉
6 while True:
7 val=randint(0,100)
8 print(''生产者'',self.name,":Append"+str(val),L)
9
10 if lock_con.acquire():#锁 ,与lock_con.acquire()一样
11 L.append(val)#做包子,从后面加
12 lock_con.notify()#通知wait,激活wait
13 lock_con.release()
14 time.sleep(3)
15 class Consumer(threading.Thread):
16 def run(self):
17 global L
18 while True:
19 lock_con.acquire()
20 if len(L)==0:#没包子
21 lock_con.wait()#wait阻塞
22
23 print(''消费者'',self.name,":Delete"+str(L[0]),L)
24 del L[0]#从前面吃
25 lock_con.release()
26 time.sleep(0.1)
27
28 if __name__=="__main__":
29
30 L=[]
31 lock_con=threading.Condition()#条件变量的锁
32 threads=[]
33 for i in range(5):#启动五个人在做包子,5个线程
34 threads.append(Producer())
35 threads.append(Consumer())#
36 for t in threads:
37 t.start()
38 for t in threads:
39 t.join()当一屉中有包子的时候,notify 激活 waiting,添加包子,和吃包子时有线程锁。
同步条件 (Event)
1 import threading,time
2
3 class Boss(threading.Thread):
4 def run(self):
5 print("BOSS:今晚大家都要加班到22:00。")
6 event.isSet() or event.set()#set()设为true
7 time.sleep(5)
8 print("BOSS:<22:00>可以下班了。")
9 event.isSet() or event.set()
10
11 class Worker(threading.Thread):
12 def run(self):
13 event.wait()#等待老板决定,阻塞
14 print("Worker:哎……命苦啊!")
15 #event.clear() # 标志位 False 等老板说可以下班, 设为true
16 time.sleep(1)
17 event.clear()#标志位 False 等老板说可以下班, 设为true
18 event.wait()#等老板说别的 ,设为true后
19 print("Worker:OhYeah!") #print Oh,Yeah
20
21 if __name__=="__main__":
22 event=threading.Event()
23 threads=[]
24 for i in range(5):#五个worker
25 threads.append(Worker())
26 threads.append(Boss())#一个老板
27 for t in threads:
28 t.start()
29 for t in threads:
30 t.join()boss 说完后,5 个 worker 马上能有反应。boss 输出后,even.set (),标志位变为 True,worker 中的 event.wait () 才能停止阻塞。之后还需将标志位设为 False,即 event.clear ()。
再次等待 boss 说完话后 even.set () 将标志位变为 True,worker 再次发言。
执行结果:
BOSS:今晚大家都要加班到22:00。
Worker:哎……命苦啊!
Worker:哎……命苦啊!
Worker:哎……命苦啊!
Worker:哎……命苦啊!
Worker:哎……命苦啊!
BOSS:<22:00>可以下班了。
Worker:OhYeah!
Worker:OhYeah!
Worker:OhYeah!
Worker:OhYeah!
Worker:OhYeah!
Process finished with exit code 0

python threading ThreadPoolExecutor
线程池,为什么要使用线程池:
1. 线程中可以获取某一个线程的状态或者某一个任务的状态,以及返回值
2. 当一个线程完成的时候我们主线程能立即知道
3. futures可以让多线程和多进程编码接口一致
获取状态或关闭任务
import time
def get_html(times):
time.sleep(times)
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)# 最大执行线程数
#通过submit函数提交执行的函数到线程池中, submit 是立即返回,不会造成主线程阻塞
task1 = executor.submit(get_html, (3))
task2 = executor.submit(get_html, (2))
print(task1.done()) # 判断任务是否完成
print(task2.cancel()) #取消任务,只能在任务没有开始的时候进行cancel
获取成功的task返回
方法一:
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
def get_html(times):
time.sleep(times)
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4]
all_task = [executor.submit(get_html, (url)) for url in urls]
for future in as_completed(all_task): # 返回已经成功的任务的返回值,不会按照线程执行的顺序返回
data = future.result()
print("get {} page".format(data))
方法二:
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
def get_html(times):
time.sleep(times)
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4]
#通过executor的map获取已经完成的task的值,这个会按照执行线程的顺序执行,会按照执行线程顺序返回
for data in executor.map(get_html, urls):
print("get {} page".format(data))
wait,wait第几个任务执行完了以后才执行主线程,不然的话主线程会一直阻塞
from concurrent.futures import ThreadPoolExecutor, wait
import time
def get_html(times):
time.sleep(times)
print("get page {} success".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4]
all_task = [executor.submit(get_html, (url)) for url in urls]
wait(all_task, return_when=FIRST_COMPLETED)
print("main")

python threading ThreadPoolExecutor源码解析
future: 未来对象,或task的返回容器
1. 当submit后:
def submit(self, fn, *args, **kwargs):
with self._shutdown_lock: # lock是线程锁
if self._shutdown:
raise RuntimeError(''cannot schedule new futures after shutdown'')
f = _base.Future() # 创建future对象
w = _WorkItem(f, fn, args, kwargs) # 线程池执行基本单位
self._work_queue.put(w) #实现的是queue
self._adjust_thread_count() # 这里会进行判断当前执行线程的数量
return f
2. _adjust_thread_count:
def _adjust_thread_count(self):
# When the executor gets lost, the weakref callback will wake up
# the worker threads.
def weakref_cb(_, q=self._work_queue):
q.put(None)
# TODO(bquinlan): Should avoid creating new threads if there are more
# idle threads than items in the work queue.
num_threads = len(self._threads)
if num_threads < self._max_workers:
thread_name = ''%s_%d'' % (self._thread_name_prefix or self,
num_threads)
t = threading.Thread(name=thread_name, target=_worker,
args=(weakref.ref(self, weakref_cb),
self._work_queue)) # 创建线程,并调用_worker方法,传入work queue
t.daemon = True
t.start()
self._threads.add(t)
_threads_queues[t] = self._work_queue
3. _worker:
def _worker(executor_reference, work_queue):
try:
while True:
work_item = work_queue.get(block=True)
if work_item is not None:
work_item.run()
# Delete references to object. See issue16284
del work_item
continue
executor = executor_reference()
# Exit if:
# - The interpreter is shutting down OR
# - The executor that owns the worker has been collected OR
# - The executor that owns the worker has been shutdown.
if _shutdown or executor is None or executor._shutdown:
# Notice other workers
work_queue.put(None)
return
del executor
except BaseException:
_base.LOGGER.critical(''Exception in worker'', exc_info=True)
4. WorkItem
class _WorkItem(object):
def __init__(self, future, fn, args, kwargs):
self.future = future
self.fn = fn
self.args = args
self.kwargs = kwargs
def run(self):
if not self.future.set_running_or_notify_cancel():
return
try:
result = self.fn(*self.args, **self.kwargs)
except BaseException as exc:
self.future.set_exception(exc)
# Break a reference cycle with the exception ''exc''
self = None
else:
self.future.set_result(result)
今天的关于python3 线程 threading.Thread GIL性能详解(2.3)和python threading多线程的分享已经结束,谢谢您的关注,如果想了解更多关于(转)Python3入门之线程threading常用方法、Python (多线程 threading 模块)、python threading ThreadPoolExecutor、python threading ThreadPoolExecutor源码解析的相关知识,请在本站进行查询。
本文标签:




