最近很多小伙伴都在问ASP.NETCore使用Jaeger实现分布式追踪和aspnetcore部署这两个问题,那么本篇文章就来给大家详细解答一下,同时本文还将给你拓展.NETCore分布式链路追踪框架
最近很多小伙伴都在问ASP.NET Core 使用 Jaeger 实现分布式追踪和aspnetcore部署这两个问题,那么本篇文章就来给大家详细解答一下,同时本文还将给你拓展.NET Core分布式链路追踪框架的基本实现原理、.NET Core微服务之基于Ocelot+Butterfly实现分布式追踪、.NET Core微服务之基于Steeltoe使用Zipkin实现分布式追踪、asp.net core mvc基于Redis实现分布式锁,C# WebApi接口防止高并发重复请求,分布式锁的接口幂等性实现等相关知识,下面开始了哦!
本文目录一览:- ASP.NET Core 使用 Jaeger 实现分布式追踪(aspnetcore部署)
- .NET Core分布式链路追踪框架的基本实现原理
- .NET Core微服务之基于Ocelot+Butterfly实现分布式追踪
- .NET Core微服务之基于Steeltoe使用Zipkin实现分布式追踪
- asp.net core mvc基于Redis实现分布式锁,C# WebApi接口防止高并发重复请求,分布式锁的接口幂等性实现
")
ASP.NET Core 使用 Jaeger 实现分布式追踪(aspnetcore部署)
前言
最近我们公司的部分.NET Core 的项目接入了 Jaeger,也算是稍微完善了一下.NET 团队的技术栈。
至于为什么选择 Jaeger 而不是 Skywalking,这个问题我只能回答,大佬们说了算。
前段时间也在 CSharpCorner 写过一篇类似的介绍 Exploring Distributed Tracing Using ASP.NET Core And Jaeger。
下面回到正题,我们先看一下 Jaeger 的简介
Jaeger 的简单介绍

Jaeger 是 Uber 开源的一个分布式追踪的工具,主要为基于微服务的分布式系统提供监测和故障诊断。包含了下面的内容
- Distributed context propagation
- Distributed transaction monitoring
- Root cause analysis
- Service dependency analysis
- Performance / latency optimization
下面就通过一个简单的例子来体验一下。
示例
在这个示例的话,我们只用了 jaegertracing/all-in-one 这个 docker 的镜像来搭建,因为是本地的开发测试环境,不需要搭建额外的存储,这个感觉还是比较贴心的。
我们会用到两个主要的 nuget 包
Jaeger这个是官方的 clientOpenTracing.Contrib.NetCore.Unofficial这个是对.NET Core 探针的处理,从 opentracing-contrib/csharp-netcore 这个项目移植过来的 (这个项目并不活跃,只能自己做扩展)
然后我们会建两个 API 的项目,一个是 AService,一个是 BService。
其中 BService 会提供一个接口,从缓存中读数据,如果读不到就通过 EF Core 去从 sqlite 中读,然后写入缓存,最后再返回结果。
AService 会通过 HttpClient 去调用 BService 的接口,从而会形成调用链。
开始之前,我们先把 docker-compose.yml 配置一下
version: ''3.4''
services:
aservice:
image: ${DOCKER_REGISTRY-}aservice
build:
context: .
dockerfile: AService/Dockerfile
ports:
- "9898:80"
depends_on:
- jagerservice
- bservice
networks:
backend:
bservice:
image: ${DOCKER_REGISTRY-}bservice
build:
context: .
dockerfile: BService/Dockerfile
ports:
- "9899:80"
depends_on:
- jagerservice
networks:
backend:
jagerservice:
image: jaegertracing/all-in-one:latest
environment:
- COLLECTOR_ZIPKIN_HTTP_PORT=9411
ports:
- "5775:5775/udp"
- "6831:6831/udp"
- "6832:6832/udp"
- "5778:5778"
- "16686:16686"
- "14268:14268"
- "9411:9411"
networks:
backend:
networks:
backend:
driver: bridge
然后就在两个项目的 Startup 加入下面的一些配置,主要是和 Jaeger 相关的。
public void ConfigureServices(IServiceCollection services)
{
// others ....
// Adds opentracing
services.AddOpenTracing();
// Adds the Jaeger Tracer.
services.AddSingleton<ITracer>(serviceProvider =>
{
string serviceName = serviceProvider.GetRequiredService<IHostingEnvironment>().ApplicationName;
var loggerFactory = serviceProvider.GetRequiredService<ILoggerFactory>();
var sampler = new ConstSampler(sample: true);
var reporter = new RemoteReporter.Builder()
.WithLoggerFactory(loggerFactory)
.WithSender(new UdpSender("jagerservice", 6831, 0))
.Build();
var tracer = new Tracer.Builder(serviceName)
.WithLoggerFactory(loggerFactory)
.WithSampler(sampler)
.WithReporter(reporter)
.Build();
GlobalTracer.Register(tracer);
return tracer;
});
}
这里需要注意的是我们要根据情况来选择 sampler,演示这里用了最简单的 ConstSampler。
回到 BService 这个项目,我们添加 SQLite 和 EasyCaching 的相关支持。
public void ConfigureServices(IServiceCollection services)
{
// Adds an InMemory-Sqlite DB to show EFCore traces.
services
.AddEntityFrameworkSqlite()
.AddDbContext<BDbContext>(options =>
{
var connectionStringBuilder = new SqliteConnectionStringBuilder
{
DataSource = ":memory:",
Mode = SqliteOpenMode.Memory,
Cache = SqliteCacheMode.Shared
};
var connection = new SqliteConnection(connectionStringBuilder.ConnectionString);
connection.Open();
connection.EnableExtensions(true);
options.UseSqlite(connection);
});
// Add EasyCaching Inmemory provider.
services.AddEasyCaching(options =>
{
options.UseInMemory("m1");
});
}
然后控制器上面就比较简单了。
// GET api/values
[HttpGet]
public async Task<IActionResult> GetAsync()
{
var provider = _providerFactory.GetCachingProvider("m1");
var obj = await provider.GetAsync("mykey", async () => await _dbContext.DemoObjs.ToListAsync(), TimeSpan.FromSeconds(30));
return Ok(obj);
}
AService 就是通过 HttpClient 去调用上面的这个接口即可。
// GET api/values
[HttpGet]
public async Task<string> GetAsync()
{
var res = await GetDemoAsync();
return res;
}
private async Task<string> GetDemoAsync()
{
var client = _clientFactory.CreateClient();
var request = new HttpRequestMessage
{
Method = HttpMethod.Get,
RequestUri = new Uri($"http://bservice/api/values")
};
var response = await client.SendAsync(request);
response.EnsureSuccessStatusCode();
var body = await response.Content.ReadAsStringAsync();
return body;
}
到这里的话,代码这块是 ok 了,下面就来看看效果。
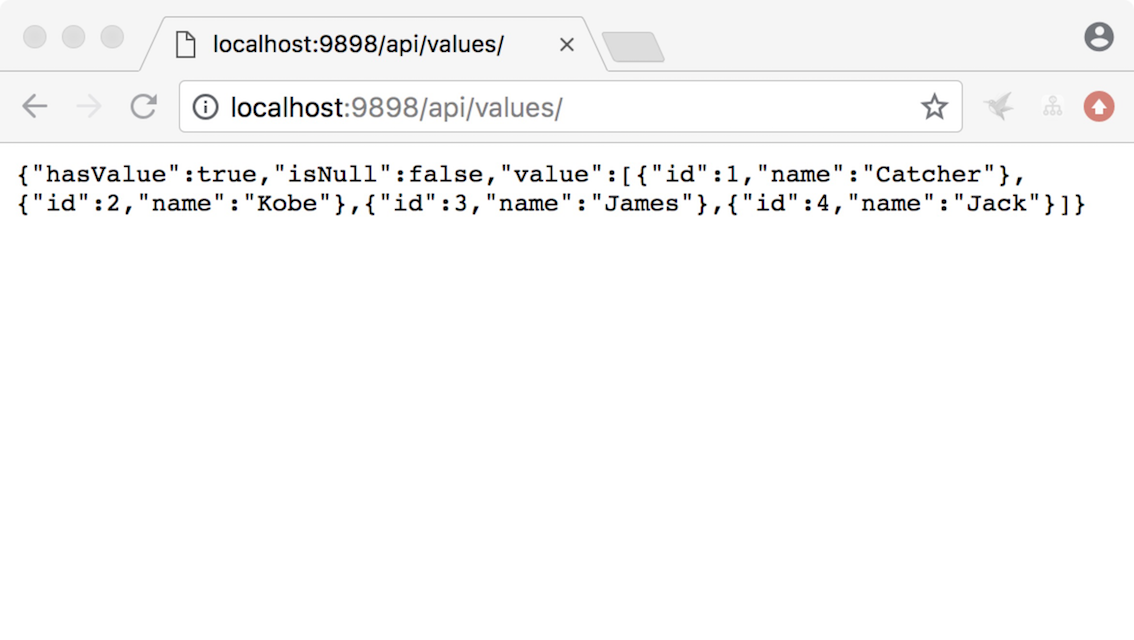
先通过 http://localhost:9898/api/values/ 访问几次 AService
大概能得到一个这样的结果
然后去 Jaeger 的界面上我们可以看到,两个服务已经注册上来了。
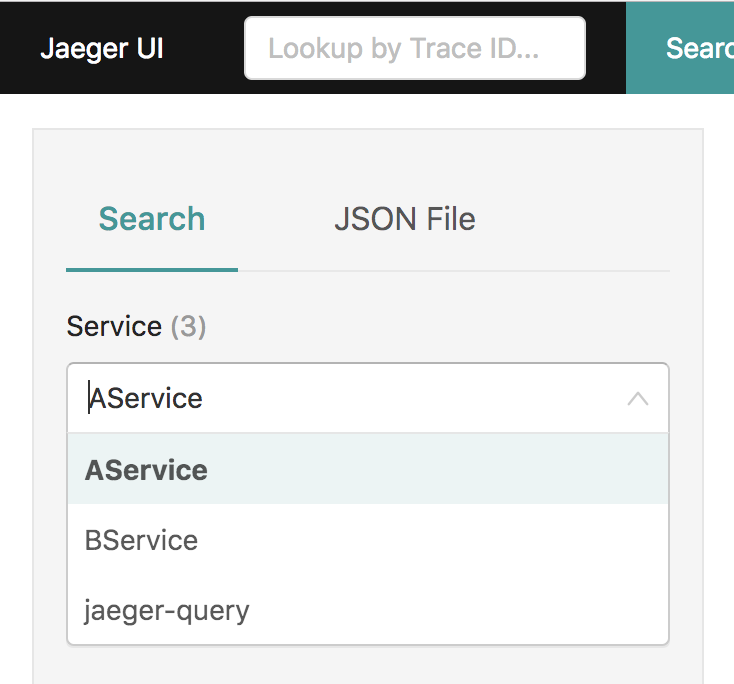
选 A,B 其中一个去搜索,就可以看到下面的结果
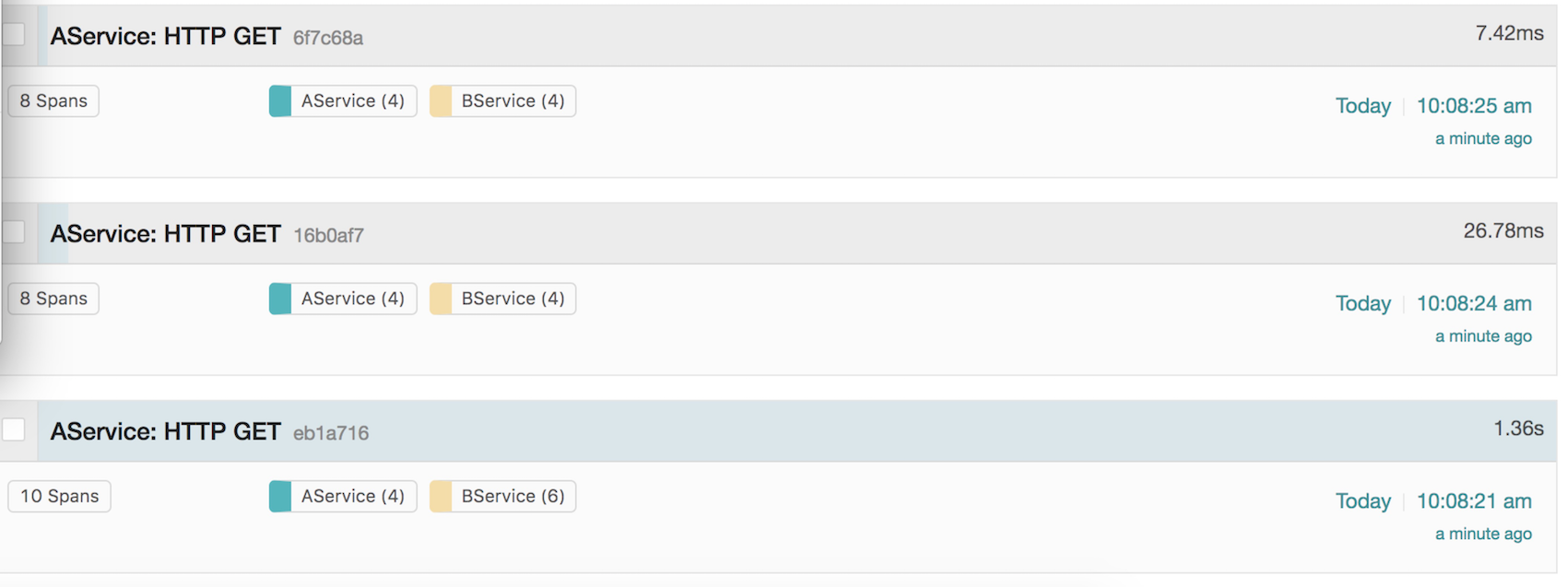
这个就最外层,能看到这些请求一些宏观的信息。
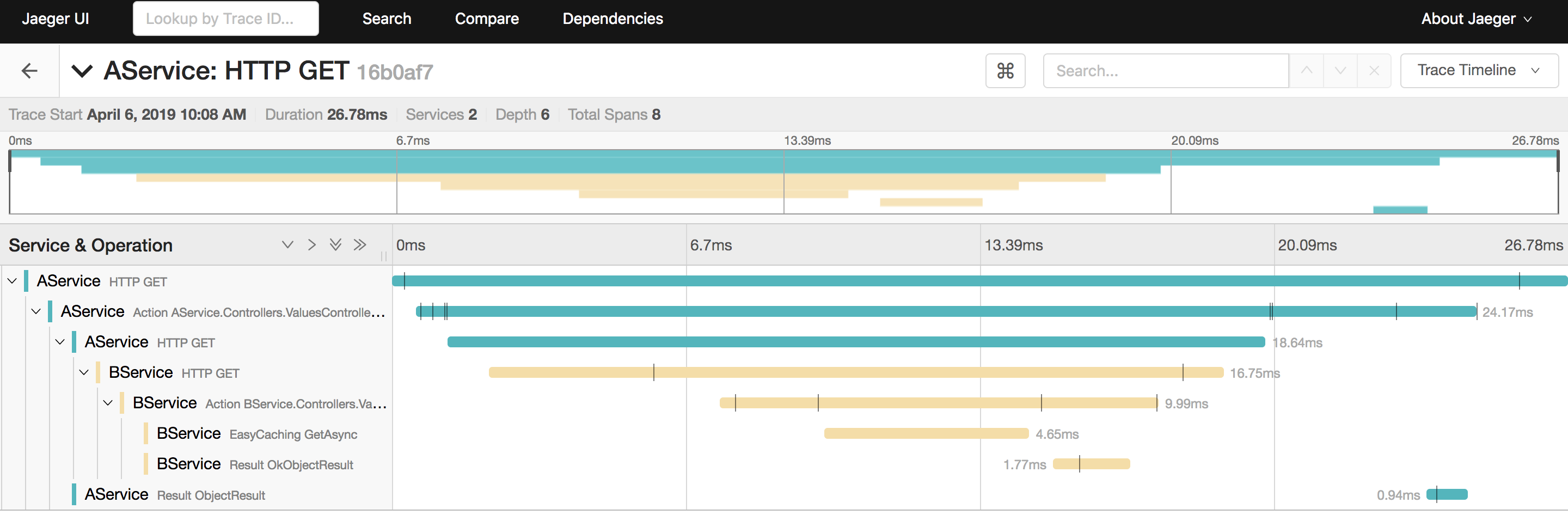
我们选界面上最后一个,也就是第一个请求,进去看看细节
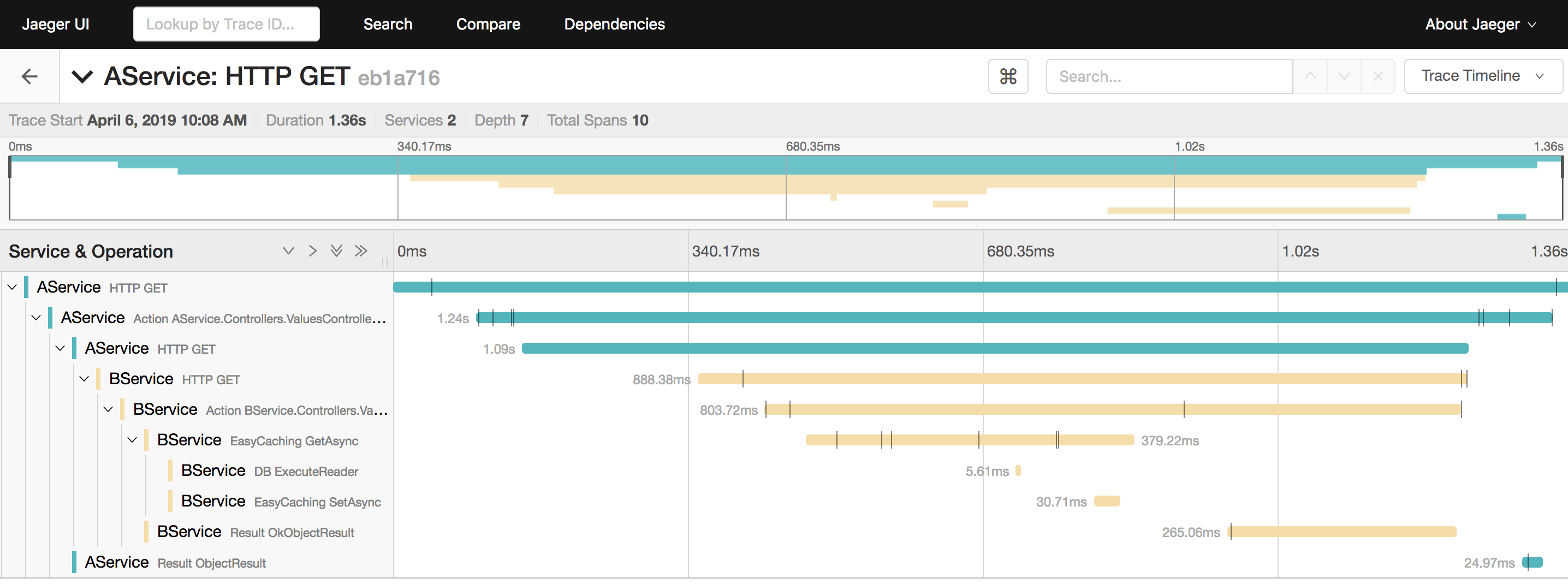
从上面这个图大概也能看出来,做了一些什么操作,请求来到 AService,它就发起了 HTTP 请求到 BService,BService 则是先通过 EasyCaching 去取缓存,显然缓存中没数据,它就去读数据库了。
和另外的请求对比一下,可以发现是少了查数据库这一步操作的。这也是为什么上面的是 10 个 span,而下面的才 8 个。
再来看看两个请求的对比图。
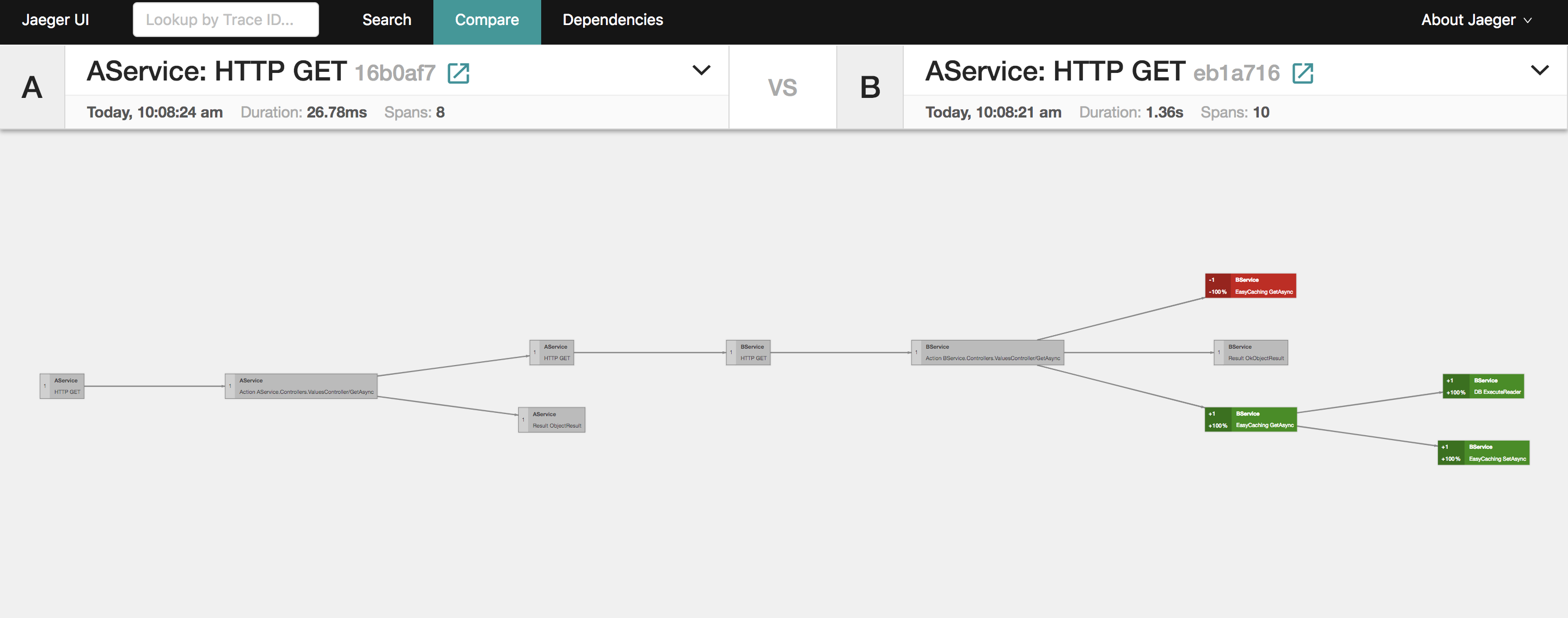
上图中那些红色和绿色的块就是两个请求的差异点了。
回去看看其他细节,可以发现类似下面的内容
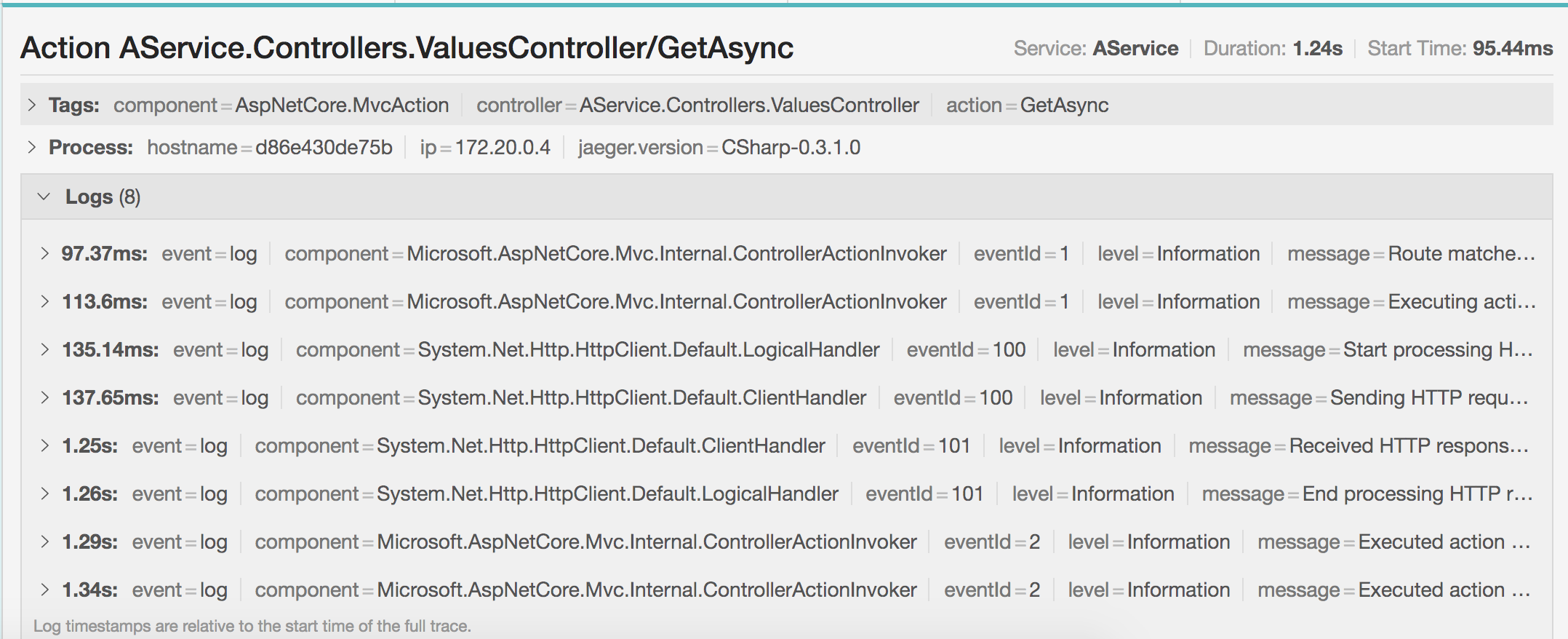
有很多日志相关的东西,这些东西在这里可能没有太多实际的作用,我们可以通过调整日志的级别来不让它写入到 Jaeger 中。
或者是通过下面的方法来过滤
services.AddOpenTracing(new System.Collections.Generic.Dictionary<string,LogLevel>
{
{"AService", LogLevel.Information}
});
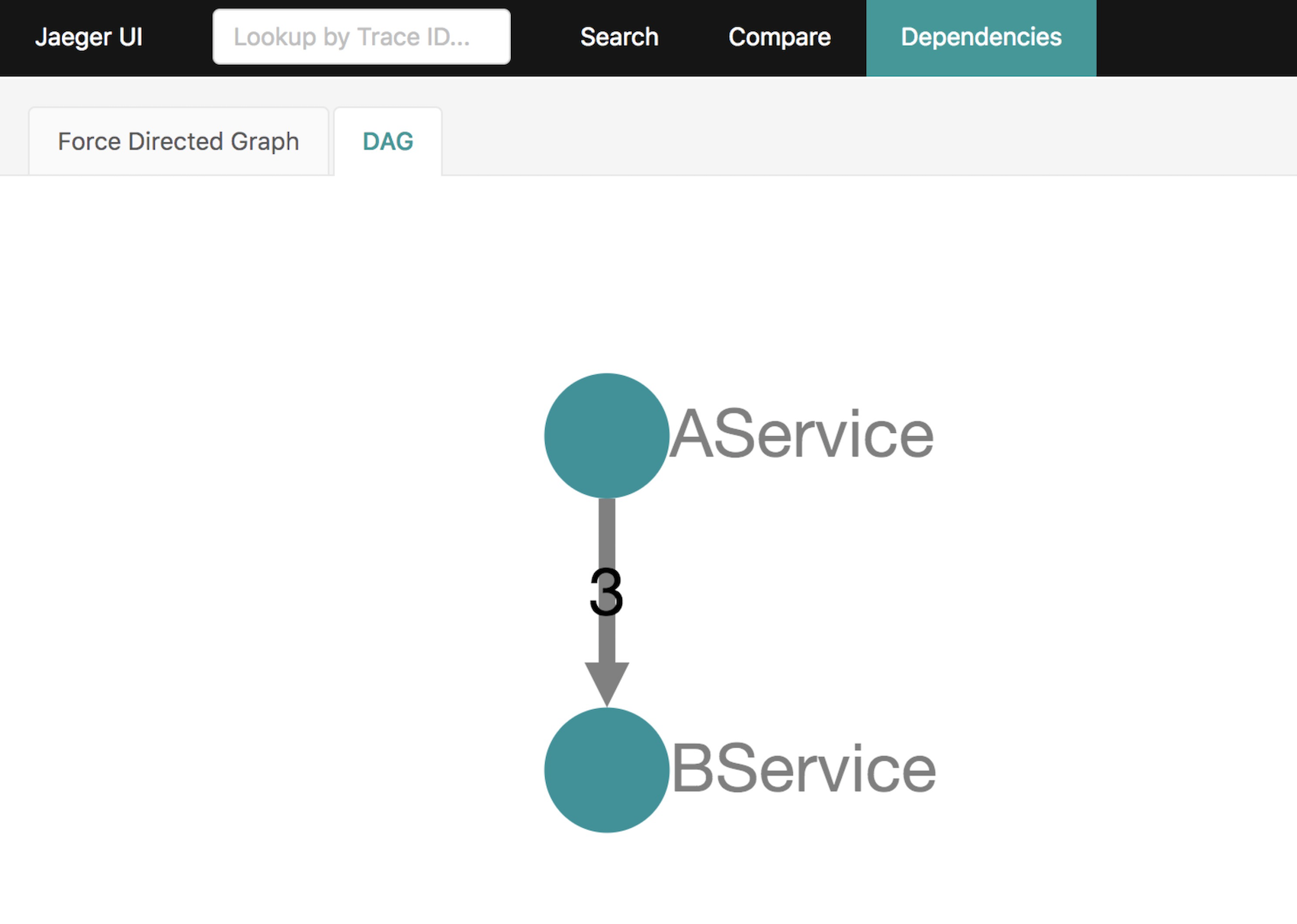
最后就是依赖图了。
写在最后
虽说 Jaeger 用起来挺简单的,但是也是有点美中不足的,不过这个锅不应该是 Jaeger 来背的,主要还是很多我们常用的库没有直接的支持 Diagnostic,所以能监控到的东西还是略少。
不过在 github 发现了 ClrProfiler.Trace 这个项目,可以通过 clrprofiler 来解决上面的问题。
最后是本文的示例代码
JaegerDemo
原文出处:https://www.cnblogs.com/catcher1994/p/10662999.html

.NET Core分布式链路追踪框架的基本实现原理
分布式追踪
什么是分布式追踪
分布式系统
当我们使用 Google 或者 百度搜索时,查询服务会将关键字分发到多台查询服务器,每台服务器在自己的索引范围内进行搜索,搜索引擎可以在短时间内获得大量准确的搜索结果;同时,根据关键字,广告子系统会推送合适的相关广告,还会从竞价排名子系统获得网站权重。通常一个搜索可能需要成千上万台服务器参与,需要经过许多不同的系统提供服务。
多台计算机通过网络组成了一个庞大的系统,这个系统即是分布式系统。
在微服务或者云原生开发中,一般认为分布式系统是通过各种中间件/服务网格连接的,这些中间件提供了共享资源、功能(API等)、文件等,使得整个网络可以当作一台计算机进行工作。
分布式追踪
在分布式系统中,用户的一个请求会被分发到多个子系统中,被不同的服务处理,最后将结果返回给用户。用户发出请求和获得结果这段时间是一个请求周期。
当我们购物时,只需要一个很简单的过程:
获取优惠劵 -> 下单 -> 付款 -> 等待收货
然而在后台系统中,每一个环节都需要经过多个子系统进行协作,并且有严格的流程。例如在下单时,需要检查是否有优惠卷、优惠劵能不能用于当前商品、当前订单是否符合使用优惠劵条件等。
下图是一个用户请求后,系统处理请求的流程。

图中出现了很多箭头,这些箭头指向了下一步要流经的服务/子系统,这些箭头组成了链路网络。
在一个复杂的分布式系统中,任何子系统出现性能不佳的情况,都会影响整个请求周期。根据上图,我们设想:
1.系统中有可能每天都在增加新服务或删除旧服务,也可能进行升级,当系统出现错误,我们如何定位问题?
2.当用户请求时,响应缓慢,怎么定位问题?
3.服务可能由不同的编程语言开发,1、2 定位问题的方式,是否适合所有编程语言?
分布式追踪有什么用呢
随着微服务和云原生开发的兴起,越来越多应用基于分布式进行开发,但是大型应用拆分为微服务后,服务之间的依赖和调用变得越来越复杂,这些服务是不同团队、使用不同语言开发的,部署在不同机器上,他们之间提供的接口可能不同(gRPC、Restful api等)。
为了维护这些服务,软件领域出现了 Observability 思想,在这个思想中,对微服务的维护分为三个部分:
- 度量(
Metrics):用于监控和报警; - 分布式追踪(Tracing):用于记录系统中所有的跟踪信息;
- 日志(Logging):记录每个服务只能中离散的信息;
这三部分并不是独立开来的,例如 Metrics 可以监控 Tracing 、Logging 服务是否正常运行。Tacing 和 Metrics 服务在运行过程中会产生日志。

近年来,出现了 APM 系统,APM 称为 应用程序性能管理系统,可以进行 软件性能监视和性能分析。APM 是一种 Metrics,但是现在有融合 Tracing 的趋势。
回归正题,分布式追踪系统(Tracing)有什么用呢?这里可以以 Jaeger 举例,它可以:
- 分布式跟踪信息传递
- 分布式事务监控
- 服务依赖性分析
- 展示跨进程调用链
- 定位问题
- 性能优化
Jaeger 需要结合后端进行结果分析,jaeger 有个 Jaeger UI,但是功能并不多,因此还需要依赖 Metrics 框架从结果呈现中可视化,以及自定义监控、告警规则,所以很自然 Metrics 可能会把 Tracing 的事情也做了。
Dapper
Dapper 是 Google 内部使用的分布式链路追踪系统,并没有开源。
Dapper 用户接口:

分布式追踪系统的实现
下图是一个由用户 X 请求发起的,穿过多个服务的分布式系统,A、B、C、D、E 表示不同的子系统或处理过程。

在这个图中, A 是前端,B、C 是中间层、D、E 是 C 的后端。这些子系统通过 rpc 协议连接,例如 gRPC。
一个简单实用的分布式链路追踪系统的实现,就是对服务器上每一次请求以及响应收集跟踪标识符(message identifiers)和时间戳(timestamped events)。
分布式服务的跟踪系统需要记录在一次特定的请求后系统中完成的所有工作的信息。用户请求可以是并行的,同一时间可能有大量的动作要处理,一个请求也会经过系统中的多个服务,系统中时时刻刻都在产生各种跟踪信息,必须将一个请求在不同服务中产生的追踪信息关联起来。
为了将所有记录条目与一个给定的发起者X关联上并记录所有信息,现在有两种解决方案,黑盒(black-box)和基于标注(annotation-based)的监控方案。
黑盒方案:
假定需要跟踪的除了上述信息之外没有额外的信息,这样使用统计回归技术来推断两者之间的关系。
基于标注的方案:
依赖于应用程序或中间件明确地标记一个全局ID,从而连接每一条记录和发起者的请求。
优缺点:
虽然黑盒方案比标注方案更轻便,他们需要更多的数据,以获得足够的精度,因为他们依赖于统计推论。基于标注的方案最主要的缺点是,很明显,需要代码植入。在我们的生产环境中,因为所有的应用程序都使用相同的线程模型,控制流和 RPC 系统,我们发现,可以把代码植入限制在一个很小的通用组件库中,从而实现了监测系统的应用对开发人员是有效地透明。
Dapper 基于标注的方案,接下来我们将介绍 Dapper 中的一些概念知识。
跟踪树和 span
从形式上看,Dapper 跟踪模型使用的是树形结构,Span 以及 Annotation。
在前面的图片中,我们可以看到,整个请求网络是一个树形结构,用户请求是树的根节点。在 Dapper 的跟踪树结构中,树节点是整个架构的基本单元。
span 称为跨度,一个节点在收到请求以及完成请求的过程是一个 span,span 记录了在这个过程中产生的各种信息。每个节点处理每个请求时都会生成一个独一无二的的 span id,当 A -> C -> D 时,多个连续的 span 会产生父子关系,那么一个 span 除了保存自己的 span id,也需要关联父、子 span id。生成 span id 必须是高性能的,并且能够明确表示时间顺序,这点在后面介绍 Jaeger 时会介绍。
Annotation 译为注释,在一个 span 中,可以为 span 添加更多的跟踪细节,这些额外的信息可以帮助我们监控系统的行为或者帮助调试问题。Annotation 可以添加任意内容。

到此为止,简单介绍了一些分布式追踪以及 Dapper 的知识,但是这些不足以严谨的说明分布式追踪的知识和概念,建议读者有空时阅读 Dapper 论文。
要实现 Dapper,还需要代码埋点、采样、跟踪收集等,这里就不再细谈了,后面会介绍到,读者也可以看看论文。
Jaeger 和 OpenTracing
OpenTracing
OpenTracing 是与分布式系统无关的API和用于分布式跟踪的工具,它不仅提供了统一标准的 API,还致力于各种工具,帮助开发者或服务提供者开发程序。
OpenTracing 为标准 API 提供了接入 SDK,支持这些语言:Go, JavaScript, Java, Python, Ruby, PHP, Objective-C, C++, C#。
当然,我们也可以自行根据通讯协议,自己封装 SDK。
接下来我们要一点点弄清楚 OpenTracing 中的一些概念和知识点。由于 jaeger 是 OpenTracing 最好的实现,因此后面讲 Jaeger 就是 Opentracing ,不需要将两者严格区分。
Jaeger 结构
首先是 JAEGER 部分,这部分是代码埋点等流程,在分布式系统中处理,当一个跟踪完成后,通过 jaeger-agent 将数据推送到 jaeger-collector。jaeger-collector 负责处理四面八方推送来的跟踪信息,然后存储到后端,可以存储到 ES、数据库等。Jaeger-UI 可以将让用户在界面上看到这些被分析出来的跟踪信息。
OpenTracing API 被封装成编程语言的 SDK(jaeger-client),例如在 C# 中是 .dll ,Java 是 .jar,应用程序代码通过调用 API 实现代码埋点。
jaeger-Agent 是一个监听在 UDP 端口上接收 span 数据的网络守护进程,它会将数据批量发送给 collector。

OpenTracing 数据模型
在 OpenTracing 中,跟踪信息被分为 Trace、Span 两个核心,它们按照一定的结构存储跟踪信息,所以它们是 OpenTracing 中数据模型的核心。
Trace 是一次完整的跟踪,Trace 由多个 Span 组成。下图是一个 Trace 示例,由 8 个 Span 组成。

Tracing:
a Trace can be thought of as a directed acyclic graph (DAG) of Spans。
有点难翻译,大概意思是 Trace 是多个 Span 组成的有向非循环图。
在上面的示例中,一个 Trace 经过了 8 个服务,A -> C -> F -> G 是有严格顺序的,但是从时间上来看,B 、C 是可以并行的。为了准确表示这些 Span 在时间上的关系,我们可以用下图表示:

有个要注意的地方, 并不是 A -> C -> F 表示 A 执行结束,然后 C 开始执行,而是 A 执行过程中,依赖 C,而 C 依赖 F。因此,当 A 依赖 C 的过程完成后,最终回到 A 继续执行。所以上图中 A 的跨度最大。
Span 格式
要深入学习,就必须先了解 Span,请读者认真对照下面的图片和 Json:

json 地址:https://github.com/whuanle/DistributedTracing/issues/1
后续将围绕这张图片和 Json 来举例讲述 Span 相关知识。
Trace
一个简化的 Trace 如下:
注:不同编程语言的字段名称有所差异,gRPC 和 Restful API 的格式也有所差异。
"traceID": "790e003e22209ca4",
"spans":[...],
"processes":{...}前面说到,在 OpenTracing 中,Trace 是一个有向非循环图,那么 Trace 必定有且只有一个起点。
这个起点会创建一个 Trace 对象,这个对象一开始初始化了 trace id 和 process,trace id 是一个 32 个长度的字符串组成,它是一个时间戳,而 process 是起点进程所在主机的信息。
下面笔者来说一些一下 trace id 是怎么生成的。trace id 是 32个字符串组成,而实际上只使用了 16 个,因此,下面请以 16 个字符长度去理解这个过程。
首先获取当前时间戳,例如获得 1611467737781059 共 16 个数字,单位是微秒,表示时间 2021-01-24 13:55:37,秒以下的单位这里就不给出了,明白表示时间就行。
在 C# 中,将当前时间转为这种时间戳的代码:
public static long ToTimestamp(DateTime dateTime)
{
DateTime dt1970 = new DateTime(1970, 1, 1, 0, 0, 0, 0);
return (dateTime.Ticks - dt1970.Ticks)/10;
}
// 结果:1611467737781059如果我们直接使用 Guid 生成或者 string 存储,都会消耗一些性能和内存,而使用 long,刚刚好可以表示时间戳,还可以节约内存。
获得这个时间戳后,要传输到 Jaeger Collector,要转为 byet 数据,为什么要这样不太清楚,按照要求传输就是了。
将 long 转为一个 byte 数组:
var bytes = BitConverter.GetBytes(time);
// 大小端
if (BitConverter.IsLittleEndian)
{
Array.Reverse(bytes);
}long 占 8 个字节,每个 byte 值如下:
0x00 0x05 0xb9 0x9f 0x12 0x13 0xd3 0x43
然后传输到 Jaeger Collector 中,那么获得的是一串二进制,怎么表示为字符串的 trace id?
可以先还原成 long,然后将 long 输出为 16 进制的字符串:
转为字符串(这是C#):
Console.WriteLine(time.ToString("x016"));结果:
0005b99f1213d343
Span id 也是这样转的,每个 id 因为与时间戳相关,所以在时间上是唯一的,生成的字符串也是唯一的。
这就是 trace 中的 trace id 了,而 trace process 是发起请求的机器的信息,用 Key-Value 的形式存储信息,其格式如下:
{
"key": "hostname",
"type": "string",
"value": "Your-PC"
},
{
"key": "ip",
"type": "string",
"value": "172.6.6.6"
},
{
"key": "jaeger.version",
"type": "string",
"value": "CSharp-0.4.2.0"
}Ttace 中的 trace id 和 process 这里说完了,接下来说 trace 的 span。
Span
Span 由以下信息组成:
- An operation name:操作名称,必有;
- A start timestamp:开始时间戳,必有;
- A finish timestamp:结束时间戳,必有;
- Span Tags.:Key-Value 形式表示请求的标签,可选;
- Span Logs:Key-Value 形式表示,记录简单的、结构化的日志,必须是字符串类型,可选;
- SpanContext :跨度上下文,在不同的 span 中传递,建立关系;
- Referencest:引用的其它 Span;
span 之间如果是父子关系,则可以使用 SpanContext 绑定这种关系。父子关系有 ChildOf、FollowsFrom 两种表示,ChildOf 表示 父 Span 在一定程度上依赖子 Span,而 FollowsFrom 表示父 Span 完全不依赖其子Span 的结果。
一个 Span 的简化信息如下(不用理会字段名称大小写):
{
"traceID": "790e003e22209ca4",
"spanID": "4b73f8e8e77fe9dc",
"flags": 1,
"operationName": "print-hello",
"references": [],
"startTime": 1611318628515966,
"duration": 259,
"tags": [
{
"key": "internal.span.format",
"type": "string",
"value": "proto"
}
],
"logs": [
{
"timestamp": 1611318628516206,
"fields": [
{
"key": "event",
"type": "string",
"value": "WriteLine"
}
]
}
]
}OpenTracing API
在 OpenTracing API 中,有三个主要对象:
- Tracer
- Span
- SpanContext
Tracer可以创建Spans并了解如何跨流程边界对它们的元数据进行Inject(序列化)和Extract(反序列化)。它具有以下功能:
- 开始一个新的
Span Inject一个SpanContext到一个载体Extract一个SpanContext从载体
由起点进程创建一个 Tracer,然后启动进程发起请求,每个动作产生一个 Span,如果有父子关系,Tracer 可以将它们关联起来。当请求完成后, Tracer 将跟踪信息推送到 Jaeger-Collector中。

SpanContext 是在不同的 Span 中传递信息的,SpanContext 包含了简单的 Trace id、Span id 等信息。
我们继续以下图作为示例讲解。
A 创建一个 Tracer,然后创建一个 Span,代表自己 (A),再创建两个 Span,分别代表 B、C,然后通过 SpanContext 传递一些信息到 B、C;B 和 C 收到 A 的消息后,也创建一个 Tracer ,用来 Tracer.extract(...) ;其中 B 没有后续,可以直接返回结果;而 C 的 Tracer 继续创建两个 Span,往 D、E 传递 SpanContext。
这个过程比较复杂,笔者讲不好,建议读者参与 OpenTracing 的官方文档。
详细的 OpenTracing API,可以通过编程语言编写相应服务时,去学习各种 API 的使用。
到此这篇关于.NET Core分布式链路追踪框架的基本实现原理的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持。
- .NET Core利用 AsyncLocal 实现共享变量的代码详解
- 浅析C#中的AsnycLocal与ThreadLocal
- ASP.Net Core中的日志与分布式链路追踪
- .NET core项目AsyncLocal在链路追踪中的应用

.NET Core微服务之基于Ocelot+Butterfly实现分布式追踪
Tip: 此篇已加入.NET Core微服务基础系列文章索引
一、什么是Tracing?
微服务的特点决定了功能模块的部署是分布式的,以往在单应用环境下,所有的业务都在同一个服务器上,如果服务器出现错误和异常,我们只要盯住一个点,就可以快速定位和处理问题,但是在微服务的架构下,大部分功能模块都是单独部署运行的,彼此通过总线交互,都是无状态的服务,这种架构下,前后台的业务流会经过很多个微服务的处理和传递,我们会面临以下问题:
- 分散在各个服务器上的日志怎么处理?
- 如果业务流出现了错误和异常,如何定位是哪个点出的问题?
- 如何快速定位问题?
- 如何跟踪业务流的处理顺序和结果?
以前在单应用下的日志监控很简单,在微服务架构下却成为了一个大问题,如果无法跟踪业务流,无法定位问题,我们将耗费大量的时间来查找和定位问题,在复杂的微服务交互关系中,我们就会非常被动。因此,我们需要对其进行追踪,而这个时候Google公司广泛使用了分布式集群,为了应对自身大规模的复杂集群环境,Google公司研发了Dapper分布式跟踪系统,并发表了论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,给行业内分布式跟踪的实现提供了非常有价值的参考,该论文也成为了当前分布式跟踪系统的理论基础。
>>对于基础理论,这里涉及到OpenTracing,推荐看看吴晟的翻译的《OpenTracing文档中文版》。
二、Butterfly的基本使用
2.1 Butterfly简介
Butterfly是一个使用Open Tracing规范来设计追踪数据的开源追踪组件,作者Lemon,也是AspectCore的作者。目前Ocelot已集成Butterfly,我们只需要做很少的配置即可对经过网关的所有API服务进行Tracing。不过,貌似Lemon已不打算继续维护Butterfly而是推荐使用Apache SkyWalking来做生产环境的分布式追踪,同时他也加入了SkyWalking团队共同进行SkyWalking在多语言生态的推动。不过,就学习而言,Butterfly是比较适合学习来了解分布式追踪是个神马玩意儿的,这里呢我暂时不再去学习ApacheSkyWalking了(因为我的目标是了解整个流程,做POC而不是能上生产环境的产品)。
这里是SkyWalking-netcore的GitHub地址:https://github.com/OpenSkywalking/skywalking-netcore

2.2 Butterfly的安装与配置
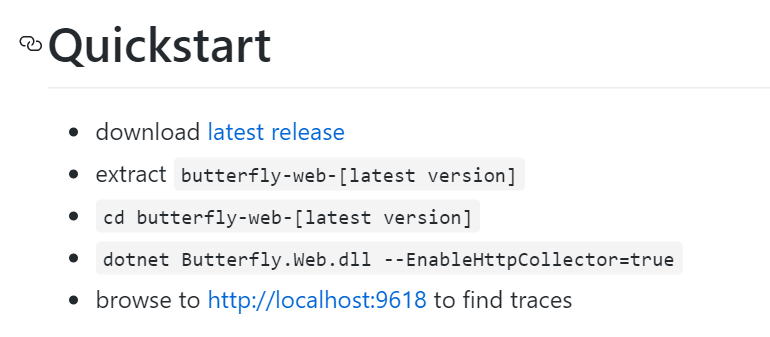
Step1.下载最新的release,目前是preview-0.0.8
Step2.解压并通过命令启动:dotnet Butterfly.Web.dll --EnableHttpCollector=true
Step3.通过默认地址和端口进行查看,如下图所示:(这里没有任何trace,因为还没有任何请求)
三、结合Ocelot的一个Tracing实例
3.1 Ocelot的配置
刚刚说到Ocelot已内集成了Butterfly,所以我们只需要做以下两个配置:
(1)配置文件配置UseTracing
"ReRoutes": [
// API01:CAS.ClientService
// --> service part
{
......
"HttpHandlerOptions": {
"UseTracing": true // use butterfly to tracing request chain
},
......
},
// API02:CAS.ProductService
// --> service part
{
......
"HttpHandlerOptions": {
"UseTracing": true // use butterfly to tracing request chain
},
......
}(2)StartUp类中启用OpenTracing
public void ConfigureServices(IServiceCollection services)
{
// Ocelot
services.AddOcelot(Configuration)
.AddOpenTracing(option =>
{
option.CollectorUrl = Configuration["TracingCenter:Uri"];
option.Service = Configuration["TracingCenter:Name"];
});
......
}json配置文件了配置了Butterfly的Url地址及其显示名:
"TracingCenter": {
"Uri": "http://192.168.80.1:9618", // Tracing Center Address
"Name": "API Gateway" // Display Name
}3.2 案例结构与配置
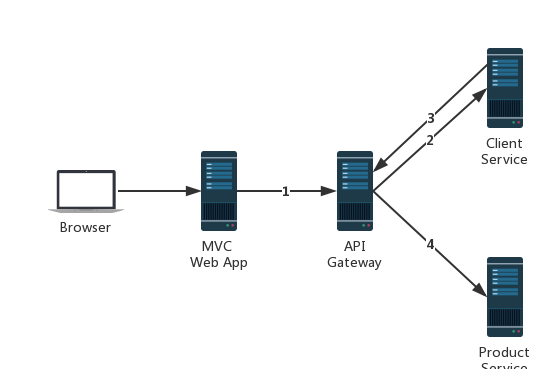
这里我们模拟一个ASP.NET Core MVC Web应用程序中要请求一个ClientService的某个接口,而这个接口又依赖于ProductService的一个接口的返回结果,因此这个请求的请求顺序就如上图所示(标有序号),流程很简单,下面我们就来一一为MVC WebApp、ClientService和ProductService进行Butterfly的配置。
这里我们通过介绍MvcApp的配置(事先创建一个ASP.NET Core MVC应用程序)来说明如何安装和配置Buttefly,至于ClientService和ProductService和MvcApp的安装配置步骤一样,就不再赘述。
(1)NuGet安装Butterfly Client
NuGet>Install-Package Butterfly.Client.AspNetCore
*.这里建议安装0.0.7版本,0.0.8版本测试时始终无法获取请求。
(2)注册Butterfly
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
// Tracing - Butterfly
services.AddButterfly(option =>
{
option.CollectorUrl = Configuration["TracingCenter:Uri"];
option.Service = Configuration["TracingCenter:Name"];
});
services.AddSingleton<HttpClient>(p => new HttpClient(p.GetService<HttpTracingHandler>()));
}这里一起注入了加入了HttpTracingHandler的HttpClient,用来在Controller中调用其他服务接口。
(3)修改Controller中的Action,使其调用ClientService的一个接口:
public class HomeController : Controller
{
private string gatewayUri;
public HomeController(IConfiguration configuration)
{
gatewayUri = $"http://{configuration["Gateway:IP"]}:{configuration["Gateway:Port"]}";
}
......
public IActionResult About([FromServices]HttpClient httpClient)
{
var requestResult = httpClient.GetStreamAsync($"{gatewayUri}/api/clientservice/trace").GetAwaiter().GetResult();
ViewData["Message"] = $"Your request data result : {requestResult}";
return View();
}
......
}(4)在ClientService中,调用ProductService的一个接口:
[Route("api/Trace")]
public class TraceController : Controller
{
private string gatewayUri;
public TraceController(IConfiguration configuration)
{
gatewayUri = $"http://{configuration["Gateway:IP"]}:{configuration["Gateway:Port"]}";
}
[HttpGet]
public string Get([FromServices]HttpClient httpClient)
{
var result = httpClient.GetStringAsync($"{gatewayUri}/api/productservice/values").GetAwaiter().GetResult();
return $"ProductService AccessTime: {DateTime.Now.ToString()}, Result: {result}";
}
}(5)在ProductService中,提供这样的一个接口,返回一些测试字符串
[Route("api/[controller]")]
public class ValuesController : Controller
{
// GET api/values
[HttpGet]
public IEnumerable<string> Get()
{
return new string[] { "ProductService-value1", "ProductService-value2" };
}
......
}3.3 简单测试
(1)浏览器中访问MvcWebApp的About页面
(2)在Butterfly Web页面查看Trace

上图我们可以看到总花费时间,经历了哪些节点等信息。
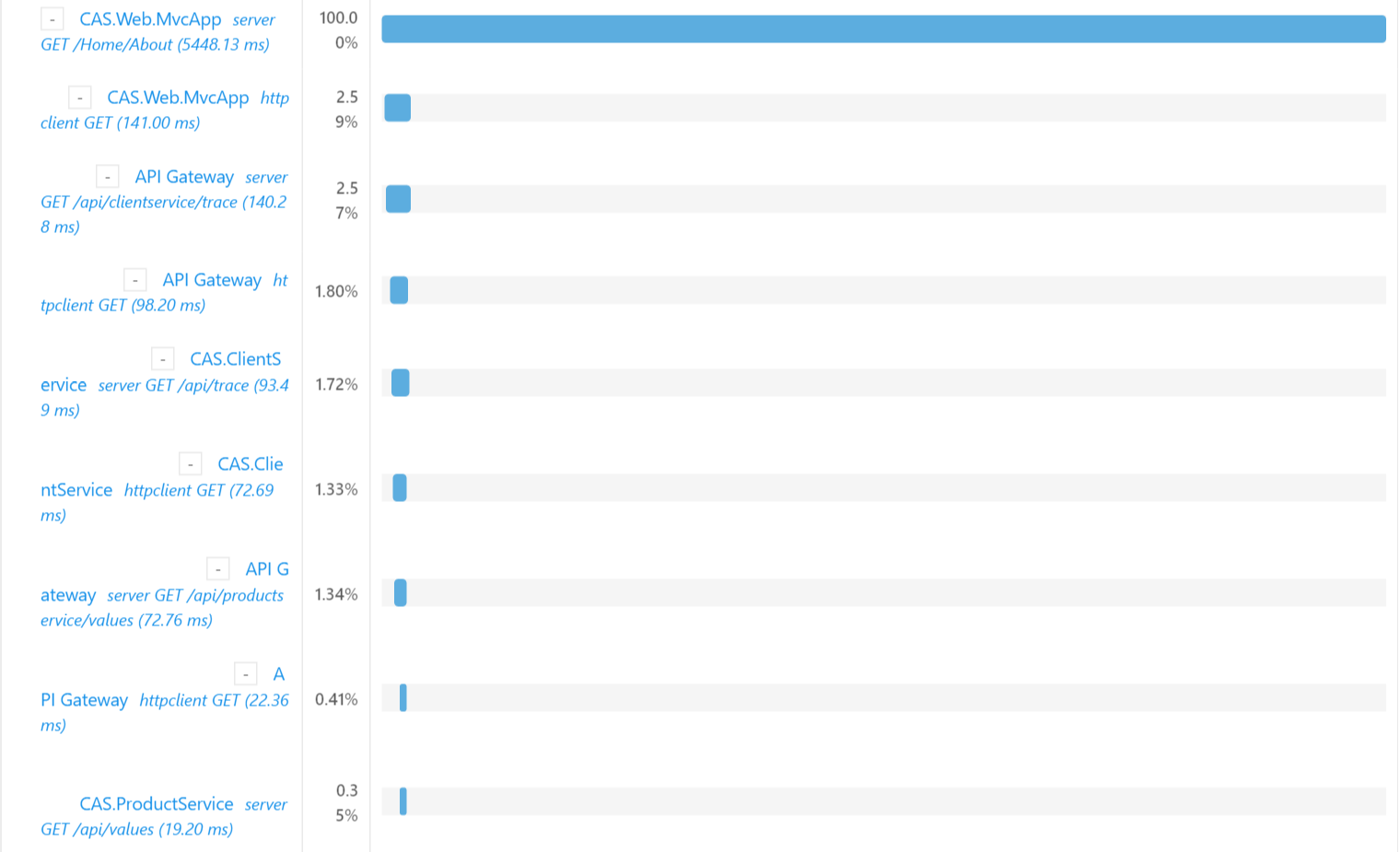
上图我们可以看出调用的顺序,依次经历哪些节点,花费时间,占比等等。
(3)在Butterfly Web页面查看Dependencies
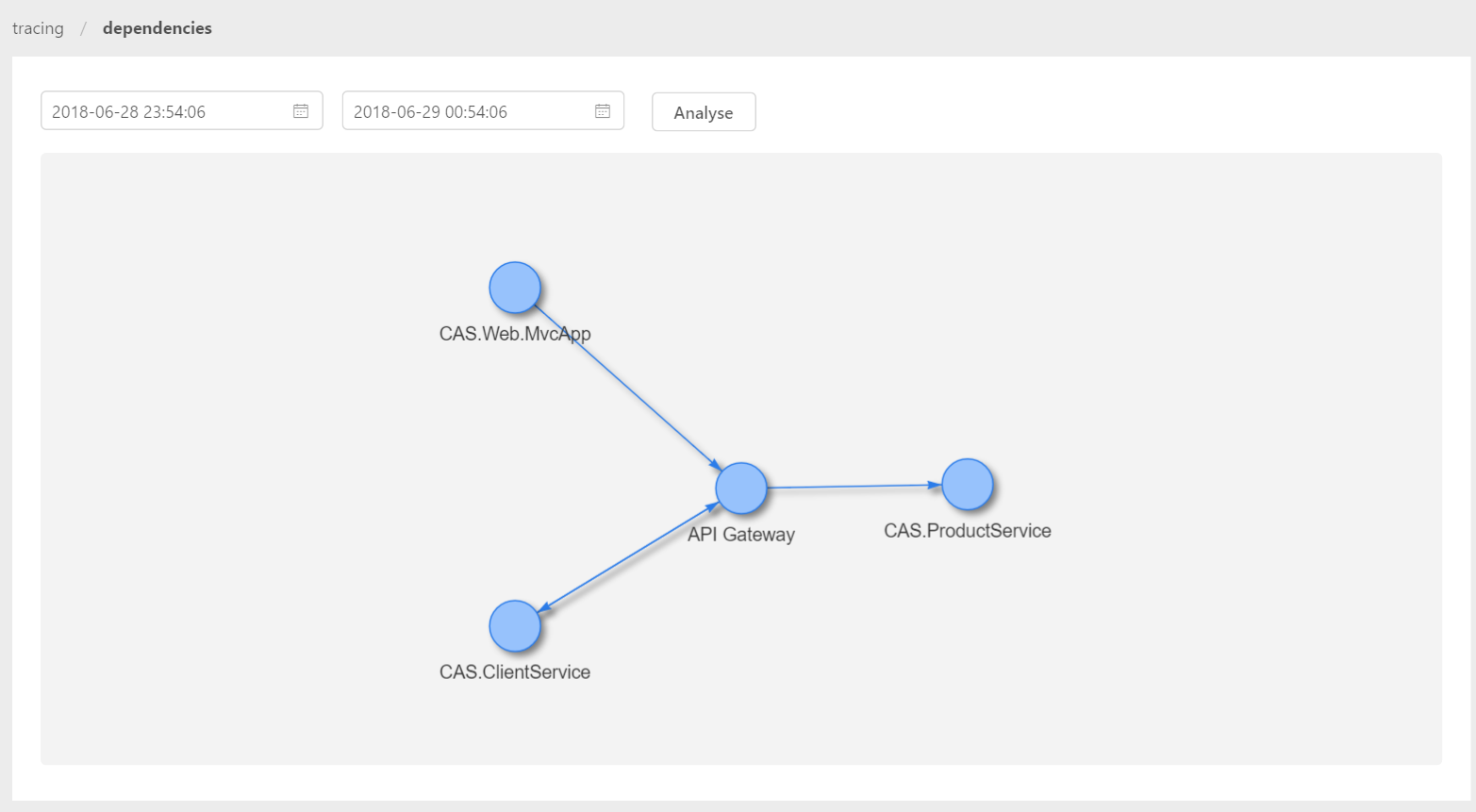
上图我们可以直观地看出这个请求的处理流程(MvcApp->API Gateway->ClientService->API Gateway->ProductService),经过了哪些节点,像API Gateway和ClientService就有一个双向连接,代表各自请求对方。
四、小结
本篇首先介绍了一下追踪(Tracing)的背景以及基本概念,然后介绍了一下一个开源的分布式追踪组件Butterfly,由于Ocelot已经集成了Butterfly,所以我们可以很方便地在Ocelot中使用Butterfly进行追踪。最后,通过一个具体的小实例,介绍了如何在ASP.NET Core微服务环境中如何使用Ocelot+Butterfly进行请求的追踪。不过,Butterfly的作者Lemon已不打算继续维护Butterfly而是推荐使用Apache SkyWalking来做生产环境的分布式追踪,同时他也加入了SkyWalking团队共同进行SkyWalking在多语言生态的推动。所以,学习环境下,可以拿Butterfly了解一下分布式追踪的意义,但是要上实际环境,可以考虑用以下SkyWalking。后续,有机会的话,我也会用SkyWalking来替代Butterfly做追踪,到时有机会也分享一下。
示例代码
Click Here => 点我下载
参考资料
吴晟,《OpenTracing文档中文版》
桂素伟,《Ocelot中使用Butterfly实践》
张善友,《Ocelot集成Butterfly实现分布式追踪》
Butterfly Github:https://github.com/liuhaoyang/butterfly => 作者Lemon,也是AspectCore的作者
出处:http://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。

.NET Core微服务之基于Steeltoe使用Zipkin实现分布式追踪
Tip: 此篇已加入.NET Core微服务基础系列文章索引
=> Steeltoe目录快速导航:
1. 基于Steeltoe使用Spring Cloud Eureka
2. 基于Steeltoe使用Spring Cloud Zuul
3. 基于Steeltoe使用Spring Cloud Hystrix
4. 基于Steeltoe使用Spring Cloud Config
5. 基于Steeltoe使用Zipkin
一、关于Spring Cloud Sleuth与Zipkin
在 SpringCloud 之中提供的 Sleuth 技术可以实现微服务的调用跟踪,也就是说它可以自动的形成一个调用连接线,通过这个连接线使得开发者可以轻松的找到所有微服务间关系,同时也可以获取微服务所耗费的时间, 这样就可以进行微服务调用状态的监控以及相应的数据分析。
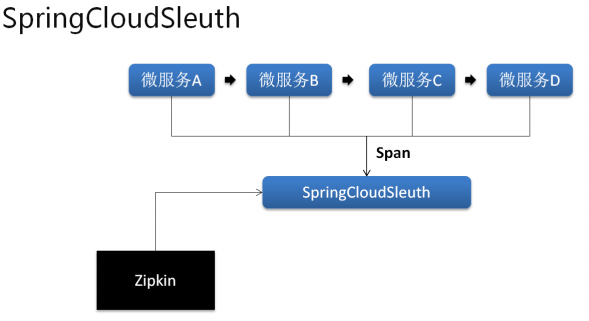
Zipkin是一个分布式追踪系统,它有助于收集解决微服务架构中延迟问题所需的时序数据。它管理这些数据的收集和查找。
应用程序用于向Zipkin报告时间数据。Zipkin UI还提供了一个依赖关系图,显示每个应用程序有多少跟踪请求。如果你正在解决延迟问题或错误问题,则可以根据应用程序,跟踪长度,注释或时间戳过滤或排序所有跟踪。一旦选择了一个跟踪,你可以看到每个跨度所花费的总跟踪时间的百分比,从而可以确定问题应用程序。
二、快速构建Zipkin Server
示例版本:Spring Boot 1.5.15.RELEASE,Spring Cloud Edgware.SR3
(1)pom.xml 添加相关依赖包
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 热启动,热部署依赖包,为了调试方便,加入此包 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
<!-- zipkin -->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
</dependencies>
<!-- spring cloud dependencies -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Edgware.SR3</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>(2)启动类添加相关注解
@SpringBootApplication
@EnableZipkinServer
public class ZipkinServiceApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinServiceApplication.class, args);
}
}(3)配置文件
server:
port: 9411
spring:
application:
name: zipkin-service最终启动后,访问zipkin主界面:
三、ASP.NET Core集成Zipkin
3.1 示例环境准备
这里仍然基于第一篇的示例进行修改,各个项目的角色如下表所示:
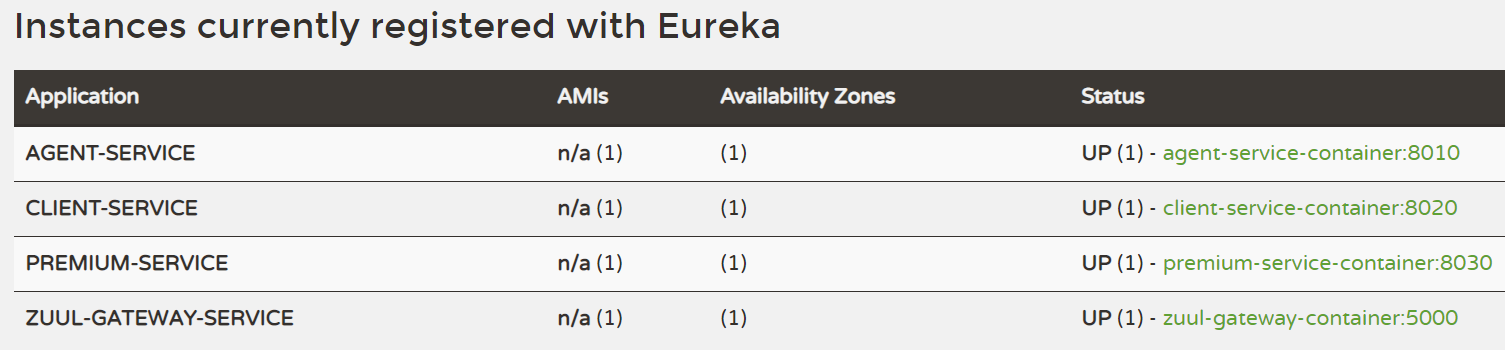
所有相关服务(除zipkin-service外)注册到Eureka之后的服务列表:
3.2 想要测试的服务调用链路
浏览器通过API网关(Zuul)调用Premium-Service的API,在这个API中会调用Client-Service的API,当然,会通过服务发现(Eureka)来获取Client-Service的URL。
3.3 以PremiumService为例添加相关配置
这里以PremiumService为例,其他几个Service参照下面的步骤依次添加配置即可。
(1)添加相关NuGet包
PM> Install-Package Steeltoe.Extensions.Logging.DynamicLogger
PM> Install-Package Steeltoe.Management.ExporterCore
PM> Install-Package Steeltoe.Management.TracingCore
(2)Program类添加动态日志Provider
public class Program
{
......
public static IWebHostBuilder CreateWebHostBuilder(string[] args) =>
WebHost.CreateDefaultBuilder(args)
.UseUrls("http://*:8030")
.UseStartup<Startup>()
.ConfigureLogging((builderContext, loggingBuilder) =>
{
loggingBuilder.AddConfiguration(builderContext.Configuration.GetSection("Logging"));
// Add Steeltoe Dynamic Logging Provider
loggingBuilder.AddDynamicConsole();
});
}Steeltoe的日志提供器是对ASP.NET Core自身日志器的进一步封装,其在原始数据基础上增加了如Spring Cloud Sleuth中一样的额外信息。
(3)Starup启动类中添加相关配置
public class Startup
{
......
public void ConfigureServices(IServiceCollection services)
{
......
// Add Steeltoe Distributed Tracing
services.AddDistributedTracing(Configuration);
// Export traces to Zipkin
services.AddZipkinExporter(Configuration);
services.AddMvc().SetCompatibilityVersion(CompatibilityVersion.Version_2_1);
// Add Hystrix Metrics to container
services.AddHystrixMetricsStream(Configuration);
}
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
......
app.UseMvc();
// Start Hystrix metrics stream service
app.UseHystrixMetricsStream();
// Start up trace exporter
app.UseTracingExporter();
}
}(4)appSettings添加相关配置 => 主要是zipkin server的相关信息
"management": {
"tracing": {
"alwaysSample": true,
"egressIgnorePattern": "/api/v2/spans|/v2/apps/.*/permissions|/eureka/.*|/oauth/.*",
"exporter": {
"zipkin": {
"endpoint": "http://localhost:9411/api/v2/spans",
"validateCertificates": false
}
}
}
}四、快速验证测试
(1)启动Eureka, Zuul, Zipkin以及Premium-Service和Client-Service
(2)通过Zuul调用API

(3)通过Zipkin UI查看Trace
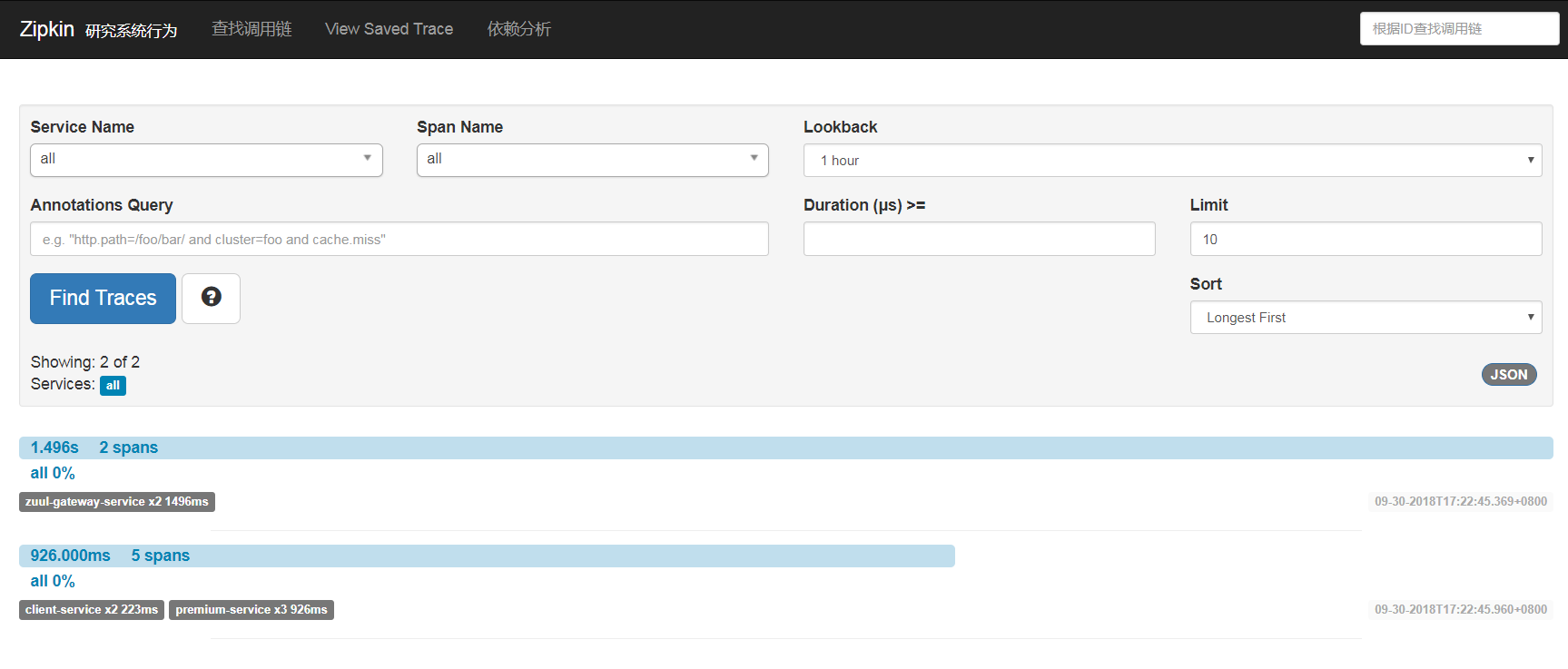
点击具体的Trace查看Details

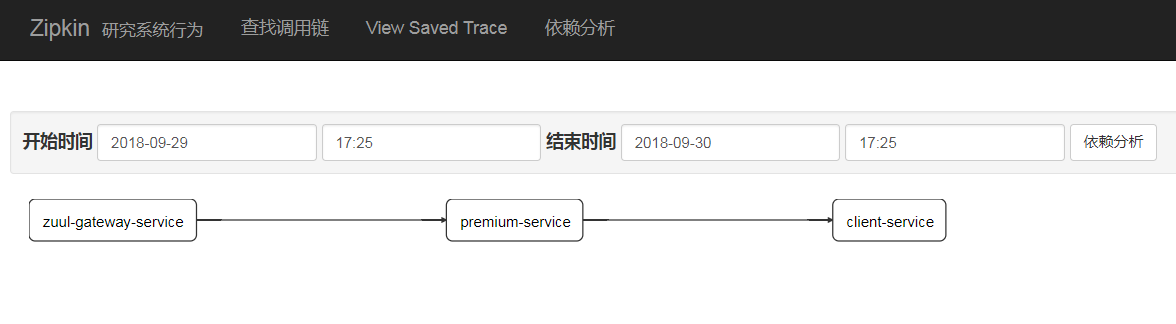
(4)点击“依赖分析”按钮查看依赖图
五、小结
本文简单地介绍了一下Spring Cloud Seluth与Zipkin,然后通过Java快速地构建了一个Zipkin Server,通过在ASP.NET Core中集成Zipkin并做了一个基本的微服务调用追踪Demo。本示例的Zipkin Server的追踪数据是基于内存,实际中应该集成ELK进行持久化。当然,我们也可以直接通过Zipkin的.NET客户端来做。
示例代码
GitHub => https://github.com/EdisonChou/Microservice.PoC.Steeltoe/tree/master/src/Chapter4-ServiceTracing
参考资料
Steeltoe官方文档:《Steeltoe Doc》
Steeltoe官方示例:https://github.com/SteeltoeOSS/Samples
周立,《Spring Cloud与Docker 微服务架构实战》
小不点啊,《SpringCloud系列十二:SpringCloudSleuth(SpringCloudSleuth 简介、SpringCloudSleuth 基本配置、数据采集)》
Ken.W,《Steeltoe之Distributed Tracing篇》
出处:http://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。

asp.net core mvc基于Redis实现分布式锁,C# WebApi接口防止高并发重复请求,分布式锁的接口幂等性实现
使用背景:在使用app或者pc网页时,可能由于网络原因,api接口可能被前端调用一个接口重复2次的情况,但是请求内容是一样的。这样在同一个短暂的时间内,就会有两个相同请求,而程序只希望处理第一个请求,第二个请求是重复的。比如创建订单,相同内容可能出现两次, 这样如果接口不处理,可能用户会创建2个订单。
分布式锁的接口幂等性实现
基于Redis实现分布式锁(前提是单台Redis),如果是多台Redis集群,可能有非同步的异常情况。
实现思路:
利用redis的setnx(key, value):“set if not exits”,若该key-value不存在,则成功加入缓存,并且重新设置缓存时间,并且返回1,否则返回0。
这里超过缓存时间,系统会自动释放缓存。
在有效时间内如果设置成功则获取执行限权,没有那就获取权限失败。
下面贴一个示例代码。
新建一个控制台程序,通过NuGet 添加引用 NServiceKit.Redis 。然后把以下代码copy过去。就可以跑示例。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
namespace RedisCheckTest
{
using NServiceKit.Redis;// 通过nuget添加redis库
class Program
{
static void Main(string[] args)
{
var m = 0;
while (m < 1000000)
{
m++;
///模拟重复发送3次请求
for (var j = 1; j <= 3; j++)
{
CreateOrderApi(j);
}
//for (var i = 1; i <= 3; i++)
//{//模拟重复发送3次请求
// Thread t2 = new Thread(CreateOrderApi);
// t2.Start();
//}
Thread.Sleep(8000);
}
Console.ReadLine();
}
/// <summary>
/// 比如说这是创建订单方法,
/// </summary>
/// <param name="id"></param>
/// <returns></returns>
private static void CreateOrderApi(int request_id)
{
string parmaterid = "p2";//假设这是api请求参数id
var nxkey = "cnx" + parmaterid;
var value = parmaterid;
bool setnx = SetNX(nxkey, value);
if (!setnx)
{
Console.WriteLine("requestid: " + request_id.ToString() + " " + "请求太频繁,请10秒后再试。");
return;
}
//todo: 这里写订单逻辑
Console.WriteLine("requestid: " + request_id.ToString() + " " + "Success");
}
const string host = "127.0.0.1";
const int port = 6379;
public static bool SetNX(string cachekey, string value, int secondsTimeout = 5)
{
string NamespacePrefix = "api01_";
string key = NamespacePrefix + cachekey;
using (var client = new RedisClient(host, port))
{
var byts = System.Text.Encoding.UTF8.GetBytes(value);
var result = client.SetNX(key, byts);
var setnx = (result == 1) ? true : false;
client.Set(key, value, DateTime.Now.AddSeconds(secondsTimeout));//将Key缓存5秒
return setnx;
}
}
}
}
关于ASP.NET Core 使用 Jaeger 实现分布式追踪和aspnetcore部署的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于.NET Core分布式链路追踪框架的基本实现原理、.NET Core微服务之基于Ocelot+Butterfly实现分布式追踪、.NET Core微服务之基于Steeltoe使用Zipkin实现分布式追踪、asp.net core mvc基于Redis实现分布式锁,C# WebApi接口防止高并发重复请求,分布式锁的接口幂等性实现等相关知识的信息别忘了在本站进行查找喔。
本文标签:




