在本文中,我们将为您详细介绍redis06的相关知识,此外,我们还会提供一些关于phpredisHashesredis下载redis集群redis可视化工具、phpredis并发控制redis下载re
在本文中,我们将为您详细介绍redis06的相关知识,此外,我们还会提供一些关于php redis Hashes redis 下载 redis 集群 redis可视化工具、php redis 并发控制 redis 下载 redis 集群 redis可视化工具、Redis00--Redis的基本命令、redis01的有用信息。
本文目录一览:- redis06
- php redis Hashes redis 下载 redis 集群 redis可视化工具
- php redis 并发控制 redis 下载 redis 集群 redis可视化工具
- Redis00--Redis的基本命令
- redis01

redis06
缓存的使用与设计
1.受益
加速读写
CPU L1/L2/L3 Cache、浏览器缓存、Ehcache缓存数据库结果
降低后端负载
后端服务器通过前端缓存降低负载:业务端使用Redis降低后端MySQL的负载
2.成本
数据不一致:缓存层和数据层有时间窗口不一致问题,和更新策略有关
代码维护成本:多了一层缓存逻辑
运维成本:例如Redis Cluster
3.使用场景
降低后端负载
对高消耗的SQL:join结果集/分组统计结果缓存
加速请求响应
利用Redis/Memcache优化IO响应时间
大量写合并为批量写
入计数器先Redis累加再批量写DB
缓存的更新策略
LRU等算法剔除:例如 maxmemory-policy

2.超时剔除:例如expire
3.主动更新:开发控制生命周期
4.两条建议
低一致性数据:最大内存和淘汰策略
高一致性:超时剔除和主动更新结合,最大内存和淘汰策略兜底
缓存粒度问题
通用性:全量属性更好
占用空间:部分属性更好
代码维护:表面上全量属性更好
缓存穿透优化
查询一个不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询
产生原因
业务代码自身问题
恶意攻击、爬虫
发现问题
业务的响应时间,受到恶意攻击时,普遍请求被打到存储层,必会引起响应时间提高,可通过监控发现
业务本身问题
相关指标:总调用数、缓存层命中数、存储层命中数
解决方法1:缓存空对象(设置过期时间)
当存储层查询不到数据后,往cache层中存储一个null,后期再被查询时,可以通过cache返回null。
缺点
cache层需要存储更多的key
缓存层和数据层数据“短期”不一致
1 public String getPassThrough(String key) {
2 String cacheValue = cache.get(key);
3 if( StringUtils.isEmpty(cacheValue) ) {
4 String storageValue = storage.get(key);
5 cache.set(key , storageValue);
6 if( StringUtils.isEmpty(storageValue) ) {
7 cache.expire(key , 60 * 5 );
8 }
9 return storageValue;
10 } else {
11 return cacheValue;
12 }
13 }
解决方法2:布隆过滤器拦截(适合固定的数据)
将所有可能存在的数据哈希到一个足够大的bitmap中,一个不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力
缓存雪崩优化
由于cache服务器承载大量的请求,当cache服务异常脱机,流量直接压向后端组件,造成级联故障。或者缓存集中在一段时间内失效,发生大量的缓存穿透
解决方法1:保证缓存高可用性
做到缓存多节点、多机器、甚至多机房。
Redis Cluster、Redis Sentinel
做二级缓存
解决方法2:依赖隔离组件为后端限流
使用Hystrix做服务降级
解决方法3:提前演练(压力测试)
解决方法4:对不同的key随机设置过期时间
无底洞问题
添加机器时,客户端的性能不但没提升,反而下降
关键点
更多的机器 != 更高的性能
更多的机器 = 数据增长与水平扩展
批量接口需求:一次mget随着机器增多,网络节点访问次数更多。网络节点的时间复杂度由O(1) -> O(node)
优化IO的方法
命令本身优化:减少慢查询命令:keys、hgetall、查询bigKey并进行优化
减少网络通信次数
mget由O(keys),升级为O(node),O(max_slow(node)) , 甚至是O(1)
降低接入成本:例如客户端长连接/连接池、NIO等
热点Key的重建优化
热点Key(访问量比较大) + 较长的重建时间(重建过程中的API或者接口比较费时间)
导致的问题:有大量的线程会去查询数据源并重建缓存,对存储层造成了巨大的压力,响应时间会变得很慢
1.三个目标
减少重建缓存的次数
数据尽可能一致
减少潜在危险:例如死锁、线程池大量被hang住(悬挂)
2.两种解决方案
互斥锁(分布式锁)
第一个线程需要重建时候,对这个Key的重建加入分布式锁,重建完成后进行解锁
这个方法避免了大量的缓存重建与存储层的压力,但是还是会有大量线程的阻塞
jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime)
String get(String key) {
String SET_IF_NOT_EXIST = "NX";
String SET_WITH_EXPIRE_TIME = "PX";
String value = jedis.get(key);
if( null == value ) {
String lockKey = "lockKey:" + key;
if( "OK".equals(jedis.set(lockKey , "1" , SET_IF_NOT_EXIST ,
SET_WITH_EXPIRE_TIME , 180)) ) {
value = db.get(key);
jedis.set(key , value);
jedis.delete(lockKey);
} else {
Thread.sleep(50);
get(key);
}
}
return value;
}
永远不过期
缓存层面:不设置过期时间(不使用expire)
功能层面:为每个value添加逻辑过期时间,单发现超过逻辑过期时间后,会使用单独的线程去重建缓存。
还存在一个数据不一致的情况。可以将逻辑过期时间相对实际过期时间相对减小
Redis规模化的困扰
发布构建繁琐,私搭乱盖
节点&机器等运维成本
监控报警比较低级
CacheCloud的主要功能
一键开启Redis(单点、Sentinel、Cluster)
机器、应用、实例监控和报警
客户端:透明使用、性能上报
可视化运维:配置、扩容、Failover、机器/应用/实例上下线
已存在Redis直接移入和数据迁移
布隆过滤器引出
问题引出:现有50亿个电话号码,有10万个电话号码,要快速准确判断这些电话号码是否已经存在
1. 通过数据库查询:实现快速有点难
2. 数据预先放在内存集合中:50亿 * 8字节 = 40GB(***内存***浪费或不够)
3. hyperloglog:准确有点难
布隆过滤器原理
需要参数
m个二进制向量(m个二进制位数)
n个预备数据(类似于问题中的50亿个电话号码)
k个hash函数(每个数据,逐个进行hash,将指定向量标识为1)
构建布隆过滤器
将n个数据逐个走一遍hash流程
判断元素是否存在
将元素逐个hash进行执行
如果得到的hash结果再向量中全都是1,则表明存在,反之当前元素不存在
布隆过滤器误差率
对的数据的返回结果必然是对的,但是错误的数据也可能是对的
直观因素
m / n 的比例:比例越大,误差率越小
hash函数的个数:个数越多,误差率越小
本地布隆过滤器
实现类库:Guava
1 Funnel<Integer> funnel = Funnels.integerFunnel();
2 int size = 1000_000;
3 double errorChance = 0.001; //错误率
4 BloomFilter<Integer> filter = BloomFilter.create(funnel , size , errorChance);
5 for(int i = 0 ; i < size ; i++ ) {
6 filter.put(i);
7 }
8 for(int i = 0 ; i < size ; i++ ) {
9 if( !filter.mightContain(i) ) {
10 System.out.println("发现不存在的数据 : " + i);
11 }
12 }
布隆过滤器的问题
容量受到限制
多个应用存在多个布隆过滤器,构建同步过滤器复杂
Redis单机布隆过滤器
基于bitmap实现,利用setbit、getbit命令实现
hash函数:
MD5
murmur3_128
murmur3_32
sha1
sha256
sha512
基于Redis单机实现存在的问题
速度慢:与本机比,输在网络
解决方法1:单独部署、与应用同机房甚至同机架部署
解决方法2:使用pipeline
容量限制:Redis最大字符串为512MB、Redis单机容量
解决方法:基于RedisCluster实现
Redis Cluster实现布隆过滤器
多个布隆过滤器:二次路由
基于pipeline提高效率
内存管理
Redis内存消耗
内存使用统计
info memory

2.内存消耗划分
used_memory的组成部分
自身内存(800K左右)
缓冲内存
客户端缓冲区
复制缓冲区
AOF缓冲区
对象内存
Key对象
Value对象
Lua内存
内存碎片 = used_memory_rss - used_memory(申请内存的会超过使用内存,内存预留与内存暂未释放)
3.子进程内存消耗
redis在bgsave与bgrewriteaof时候都会使用fork创建出子进程,fork是copy-on-write的,当发生写操作时,就会复制出一份内存
优化方式
去除THP特性:在kernel 2.6.38中新增的特性。这个特性可以加快fork的速度,但是在复制内存页的时候,会比原来的内存页扩大了512倍。例如原来是4K,扩大后为2M。当写入量比较大时,会造成不必要的阻塞与内存的暴增。
overcommit_memory=1 可以保证fork顺利完成
客户端缓冲区
#查看已连接客户端的基本信息
info clients
#查看所有Redis-Server的所有客户端的详细信息
client list
输入缓冲区
各个客户端执行的Redis命令会存储在Redis的输入缓冲区中,由单线程排队执行
- 注意:输入缓冲区最大1GB,超过后会被强制断开,不可动态配置
输出缓冲区
1 client-output-buffer-limit ${class} ${hard limit} ${soft limit} ${soft seconds}
2 ## class 客户端类型
3 ## normal 普通客户端
4 ## slave 从节点用于复制,伪装成客户端
5 ## pubsub 发布订阅客户端
6 ## hardLimit 如果客户端使用的输出缓冲区大于hardLimit,客户端会被立即关闭
7 ## softLimit 如果客户端使用的输出缓冲区超过了softLimit并且持续了softSeconds秒,客户端会立即关闭
8 ## 其中hardLimit与softLimit为0时不做任何限制
1.普通客户端
默认配置:client-output-buffer-limit normal 0 0 0
注意:需要防止大命令或者monitor,这两种情况会导致输出缓冲区暴增
2.slave客户端
默认配置:client-output-buffer-limit slave 256mb 64mb 60
建议调大:可能主从延迟较高,或者从节点数量过多时,主从复制容易发生阻塞,缓冲区会快速打满。最终导致全量复制
注意:在主从网络中,从节点不要超过2个
3.pubsub客户端
默认配置:client-output-buffer-limit pubsub 32mb 8mb 60
阻塞原因:生产速度大于消费速度
注意:需要根据实际情况进行调试
缓冲内存
1.复制缓冲区
此部分内存独享,默认1MB,考虑部分复制,可以设置更大,可以设置为100MB,牺牲部分内存避免全量复制。
2.AOF缓冲区
无论使用always、everysecs还是no的策略,都会进行刷盘,刷盘前的数据存放在AOF缓冲区中。
另外在AOF重写期间,会分配一块AOF重写缓冲区,重写时的写数据会存放在重写缓冲区当中。
为了避免数据不一致的发生,在重写完成后,会将AOF重写缓冲区的内容,同步到AOF缓冲区中。
AOF相关的缓冲区没有容量限制。
对象内存
Key:不要过长,量大不容忽视,建议控制在39字节之内。(embstr)
Value:尽量控制其内部编码为压缩编码。
内存碎片
在jemalloc中必然存在内存碎片
原因
与jemalloc有关,jemalloc会将内存空间划分为小、大、巨大三个范围;每个范围又划分了许多小的内存块单位;存储数据的时候,会选择大小最合适的内存块进行存储。

redis作者为了更好的性能,在redis中实现了自己的内存分配器来管理内存,不用的内存不会马上返还给OS,从而实现提高性能。
修改cache的值,且修改后的value与原先的value大小差异较大。
优化方法
重启redis服务,
redis4.0以上可以设置自动清理 config set activedefrag yes,也可以通过memory purge手动清理,配置监控使用性能最佳。
修改分配器(不推荐,需要对各个分配器十分了解)
避免频繁更新操作
内存回收策略
1.删除过期键值
惰性删除
1. 访问key
2. expired dict
3. del key
定时删除:每秒运行10次,采样删除
2.maxmemory-policy
Noevition:默认策略,不会删除任何数据,拒绝所有写入操作并返回错误信息。
volatile-lru:根据lru算法删除设置了超时属性的key,直到腾出空间为止。如果没有可删除的key,则将退回到noevition。
allkeys-lru:根据lru算法删除key,不管数据有没有设置超时属性,直到腾出足够空间为止。
allkeys-random:随机删除所有键,直到腾出足够空间为止。
volatile-random:随机删除过期键,直到腾出足够空间为止。
volatile-ttl:根据键值对象的ttl属性,删除最近将要过期的数据。如果没有,回退到noevicition。
客户端缓冲区优化
案例:一次线上事故,主从节点配置的maxmemory都是4GB,发现主节点的使用内存达到了4GB即内存已打满。而从节点只有2GB。
思考方向
考虑Redis的内存自身组成
主从节点之前数据传输不一致(会导致对象内存不一致)
dbsize
查看info replication中的slave_repl_offset
查看缓冲区方面
通过info clients查看最大的缓冲区占用
通过client list查看所有客户端的详细信息
问题发现:
存在一个monitor客户端对命令进行监听,由于Redis的QPS极高,monitor客户端无法及时处理,占用缓冲区。
问题预防
运维层面:线上禁用monitor(rename monitor "")
运维层面:适度限制缓冲区大小
开发层面:理解monitor原理,可以短暂寻找热点key
开发层面:使用CacheCloud可以直接监控到相关信息
内存优化其他建议
不要忽视key的长度:1个亿的key,每个字节都是节省
序列化和压缩方法:拒绝Java原生序列化,可以采用Protobuf、kryo等
不建议使用Redis的场景
数据:大且冷的数据
功能性:关系型查询、消息队列
完

php redis Hashes redis 下载 redis 集群 redis可视化工具

php redis 并发控制 redis 下载 redis 集群 redis可视化工具
针对并发控制可以使用 memcacheq ,redirs channle 等方式处理这里我单单的说一下
redis控制并发主要采用 redis list api 中的
立即学习“PHP免费学习笔记(深入)”;
比如我这边现在有个抢购的需求。一个商品只运行抢200个 大概思路如下

每次查看 redis 消息队列 长度是否已经超过 或 = 200
所以我们这边后端的单独起一个程序做队列处理。如果说数量太多那就后面的不进行处理操作。

当然。这个前端已经进入队列的用户。你不能告诉人家您已经抢到了。应该让他5分钟后再去看看结果。
这样处理的数量不会去超出。当然如果并发太大的话可以专门寻找处理并发架构,
如果要求用户体验友好那就用socket获取后端处理结果告诉用户是否抢到。redis处理还是蛮快的所以不用担心用户等待时间过长。
以上就介绍了php redis 并发控制,包括了redis方面的内容,希望对PHP教程有兴趣的朋友有所帮助。

Redis00--Redis的基本命令
前言
这一篇文章我们主要是来整理下Redis的一些常用命令。
基本命令
- 启动Redis
./src/redis-server redis.conf
- 连接Redis数据库
./src/redis-cli -h 127.0.0.1 -p 6379
字符串相关的操作命令
String 数据类型主要用在做缓存,计数器,分布式锁,分布式ID等等
3. 设置一个字符串类型的值
set key value
例如: set testkey testvalue
- 获取字符串的值
get key
例如:get testkey

5. 删除键
del key
例如:del testkey
- 不存在就插入(not exists),
存在的话就不会插入,这是用Redis做分布式锁的基础。
setnx key value
例如:127.0.0.1:6379> setnx username zhangsan
(integer) 1
- 设置过期时间(expire)
setex key time value
例如:
127.0.0.1:6379> setex username 1 lisi
- 递增
incr key
incrby key increment
例如:127.0.0.1:6379> incr age
- 递减
decr key
decrby key decrement
例如:
127.0.0.1:6379> decr age
(integer) 1
127.0.0.1:6379> decrby age 3
(integer) -2
hash(哈希)
Redis hash 是一个键值对集合,Redis hash是一个String类型的field和value的映射表,hash特别适合存储对象,例如SpringSession中的session信息,存储用户信息,用户主页访问量等等。
6. 设置单个field值
hset key field value
例如:HSET company:1 companyname alibaba
- 设置多个field值
hmset key field1 value1 [field2 value2 field3 value3 ......fieldn valuen]
例如:HMSET user:1 username zhangsna age 12
- 返回key中的field域的值
HGET key field
例如:
127.0.0.1:6379> HGET company:1 companyname
"alibaba"
- 返回key中的field1,field2,fieldN域的值
hmget key field1 field2 fieldN
例如:
127.0.0.1:6379> HMGET user:1 username age
1) "zhangsna"
2) "12"
- 返回key中,所有的域与其值
hgetall key
例如:
127.0.0.1:6379> HGETALL user:1
1) "username"
2) "zhangsna"
3) "age"
4) "12"
- 删除键
hdel key field[field ....]
例如:127.0.0.1:6379> hdel company:1 companyname
(integer) 1
list列表
字符串列表,按照插入顺序,添加一个元素到列表的头部(左边)或者尾部(右边),可以用于微博关注人,微博时间轴列表
充当队列的原理
左侧入队列
stringRedisTemplate.opsForList().leftPush(key, value)
右侧出队列
stringRedisTemplate.opsForList().rightPop(key)
- 将一个或多个值插入到列表头部
lpush key value1 [value2]
例如:127.0.0.1:6379> lpush order 111 222
(integer) 2
- 获取列表指定范围内的数据
lrange key start stop
例如:127.0.0.1:6379> lrange order 0 1
1) "222"
2) "111"
- 移除列表元素
lrem key count value
例如:127.0.0.1:6379> lrem order 1 111
(integer) 1
- 通过索引设置元素列表的值
lset key index value
例如:127.0.0.1:6379> lset order 0 123
OK
- 移除并获取列表最后一个元素
rpop key
例如:127.0.0.1:6379> rpop order
"123"
- 在列表尾部添加一个或者多个元素
rpush key value1 [value2]
例如:127.0.0.1:6379> rpush student zhangsan lisi wanger
(integer) 3
set 集合
set 集合是String类型的无序集合,集合是通过哈希表实现的。所以添加,删除,查找的复杂度都是O(1)。set 集合一般用于,赞,踩,标签等场景
18. 添加一个元素到集合中(集合中的元素无序并且唯一)
sadd key member [member ...]
例如: 127.0.0.1:6379> sadd myset test
(integer) 1
- 查看集合中所有的元素
smembers key
例如:127.0.0.1:6379> smembers myset
1) "test"
- 删除结点中指定的元素
srem key member [member ...]
例如:127.0.0.1:6379> srem myset test
(integer) 1
- scard: 返回集合元素的数量
scard key
例如:127.0.0.1:6379> scard key
(integer) 0
- smove: 将一个集合的元素转移到另一个集合中
smove source destionation member
例如:
127.0.0.1:6379> smembers myset
1) "test1"
127.0.0.1:6379> smembers myset1
(empty list or set)
127.0.0.1:6379> smove myset myset1 test1
(integer) 1
127.0.0.1:6379> smembers myset1
1) "test1"
zset(有序集合)
Redis zset和set一样也是String类型元素的集合,且不允许重复的成员,不同的是每个元素都会关联一个double类型的分数,redis正是通过分数来为集合中的成员进行从小到大的排序的。
23. ZADD: 添加多个元素到有序集合中
ZADD key [NX|XX] [CH] [INCR] score member [score member ...]
例如:127.0.0.1:6379> ZADD city:gdp 95 "beijing" 92 "shanghai" 89 "shengzhen"
(integer) 3
- ZINCRBY: 为分数值加上增量
ZINCRBY key increment member
例如:127.0.0.1:6379> zincrby city:gdp 3 "beijing"
"98"
- ZCARD:获取有序集合中的元素数量
ZCARD key
例如:127.0.0.1:6379> ZCARD city:gdp
(integer) 3
- ZCOUNT: 获取在分数区间内的元素数量
zcount key min max
例如:127.0.0.1:6379> zcount city:gdp 90 99
(integer) 2
- ZREM: 删除有序集合中的多个元素
ZREM key member [member ..]
例如:127.0.0.1:6379> zrem city:gdp "beijing"
(integer) 1
排序
- sort 排序
sort mylist
例如:
127.0.0.1:6379> lpush mylist 1 2 3 4
(integer) 4
127.0.0.1:6379> lpush mylist 1 2 3 4 12 10 9
(integer) 11
127.0.0.1:6379> sort mylist
1) "1"
2) "1"
3) "2"
4) "2"
5) "3"
6) "3"
7) "4"
8) "4"
9) "9"
10) "10"
11) "12"
- 字母排序
sort mylist alpha desc limit 0 2
总结
本文主要介绍了Redis中各种常见的命令,Redis 有五种数据类型,每种数据类型都有不同的操作命令。

redis01
1、redis
1)cookie 与 session
session 本质上也是 cookie,cookie 携带 session 返回给服务端
redis 是一个存储数据库
redis 读写快速,使用简单,常用于存储 session
2)安装
菜鸟网站有安装流程,
安装完成后
执行命令 redis-cli
在 koa 环境下使用 redis 需要安装两个插件
cnpm i koa-generic-session koa-redis
安装完成后需要在 koa 根目录下的 app.js 下引入
const session=require(''koa-generic-session'')
const Redis=require(koa-redis)
接着对 session 进行加密处理:
书写
app.keys=[''keys'',''your keys'']
app.use(session({
key:''mk'',
prefix:''mtpr''// 改变存储的字段名称
store=new Redis()
}))
之后可以在中间件中任意使用:
计算并保留访问次数:
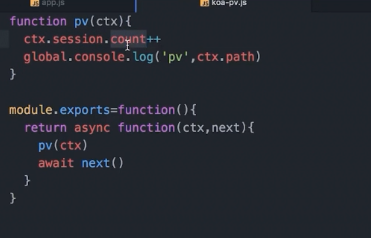
自此我们操作 cookie 都可以通过 ctx.session 来完成
使用 redis-cli 可以查看我们的 session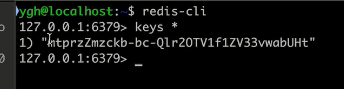
keys * 表示当前所有的 key
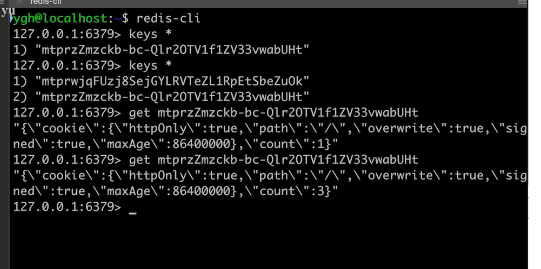
直接操作 redis 数据库
在路由文件中引入 redis 中间件
const Redis=require(''koa-redis'')
新建 redis 客户端
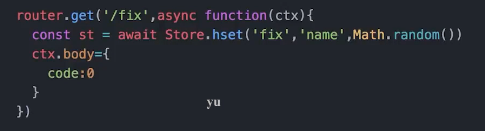
const Store=new Redis().client
关于redis06的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于php redis Hashes redis 下载 redis 集群 redis可视化工具、php redis 并发控制 redis 下载 redis 集群 redis可视化工具、Redis00--Redis的基本命令、redis01等相关知识的信息别忘了在本站进行查找喔。
本文标签:




